
热门标签
热门文章
- 1el-table的各个属性5.17_el-table属性
- 2Dependency ‘org.springframework.cloud:spring-cloud-starter-config:‘ not found_dependency 'org.springframework.cloud:spring-cloud
- 3Windows的cmd运行编译器(cmd运行c/c++、python等)_windows cmd python
- 42023如果纯做业务测试的话,在测试行业有出路吗?_业务测试是不是最简单的
- 5MAC 安装PHP及环境配置 保姆级别_formula.jws.json: update failed, falling back to c
- 6xcode通过链接ssh 链接git_xcode 配置ssh
- 7fastapi响应数据处理_fastapi中間件修改響應
- 8一篇文章带你入门文件上传漏洞_如何利用文件上传漏洞
- 9c语言中输入一个字符串直到遇到回车为止,C语言程序设计实践第四章.pptx
- 10“BS,“ “PL,“ 和 “CF“ 是财务报告中常用的缩写,它们分别代表财务报表的不同部分_bs pl
当前位置: article > 正文
Flink学习(七)-单词统计
作者:小蓝xlanll | 2024-04-22 08:01:25
赞
踩
Flink学习(七)-单词统计
前言
Flink是流批一体的框架。因此既可以处理以流的方式处理,也可以按批次处理。
一、代码基础格式
- //1st 设置执行环境
- xxxEnvironment env = xxxEnvironment.getEnvironment;
-
- //2nd 设置流
- DataSource xxxDS=env.xxxx();
-
- //3rd 设置转换
- Xxx transformation =xxxDS.xxxx();
-
- //4th 设置sink
- transformation.print();
-
- //5th 可能需要
- env.execute();
二、Demo1 批处理
- public static void main(String[] args) throws Exception {
- //1,创建一个执行环境
- ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
- //2,获取输入流
- DataSource<String> lineDS = env.readTextFile("input/word.txt");
- //3,处理数据
- FlatMapOperator<String, Tuple2<String, Integer>> wordDS = lineDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
- @Override
- public void flatMap(String value, Collector<Tuple2<String, Integer>> collector) throws Exception {
- //3.1 分隔字符串
- String[] values = value.split(" ");
- //3.2 汇总统计
- for (String word : values) {
- Tuple2<String, Integer> wordTuple = Tuple2.of(word, 1);
- collector.collect(wordTuple);
- }
- }
- });
- //4,按单词聚合
- UnsortedGrouping<Tuple2<String, Integer>> tuple2UnsortedGrouping = wordDS.groupBy(0);
- //5,分组内聚合
- AggregateOperator<Tuple2<String, Integer>> sum = tuple2UnsortedGrouping.sum(1);
-
- //6,输出结果
- sum.print();
- }


三、Demo2 流处理
- public static void main(String[] args) throws Exception {
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
-
- DataStreamSource<String> lineDS = env.readTextFile("input/word.txt");
-
- SingleOutputStreamOperator<Tuple2<String, Integer>> wordDS = lineDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
- @Override
- public void flatMap(String value, Collector<Tuple2<String, Integer>> collector) throws Exception {
- String[] words = value.split(" ");
- for (String word : words) {
- Tuple2<String, Integer> temp = Tuple2.of(word, 1);
- collector.collect(temp);
- }
- }
- });
-
- KeyedStream<Tuple2<String, Integer>, Tuple> wordCountKeyBy = wordDS.keyBy(0);
- SingleOutputStreamOperator<Tuple2<String, Integer>> sum = wordCountKeyBy.sum(1);
- sum.print();
- env.execute();
-
- }

四、Demo3 无边界流处理
- public static void main(String[] args) throws Exception {
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
-
- DataStreamSource<String> lineDS = env.socketTextStream("192.168.3.11", 9999);
-
- SingleOutputStreamOperator<Tuple2<String, Integer>> sum = lineDS.flatMap(
- (String value, Collector<Tuple2<String, Integer>> out) -> {
- String[] words = value.split(" ");
- for (String word : words) {
- out.collect(Tuple2.of(word, 1));
- }
- }
- ).returns(Types.TUPLE(Types.STRING, Types.INT))
- .keyBy(value -> value.f0)
- .sum(1);
-
- sum.print();
-
- env.execute();
-
- }
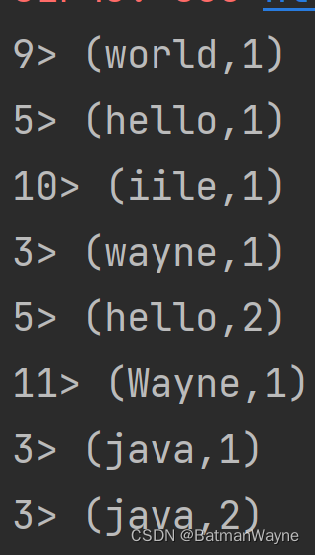
往192.168.3.11的9999端口上持续输送数据流,程序端会出现如下统计
本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

