
- 1【C语言__编译和链接__复习篇2】
- 2Linux中verilog-mode使用方法总结_linux emacs+verilog mode
- 3Git学习记录
- 4初级java程序员要求_java初级程序猿需要具备的能力?
- 5Element drawer无法上下滚动_arco design drawer弹出其他区域无法滚动
- 6最详细的ubuntu 安装 docker教程,文末获取实用干货大礼包!_ubuntu docker
- 7基于YOLOv8的摄像头下铁路工人安全作业检测(工人、反光背心和安全帽)系统
- 8C# DataTable 总结常用方法
- 9Qt_Note21_QML_访问复杂控件中的组件
- 10基于Springboot实现Kafka消费数据_springboot kafka消费
nlp(贪心学院)——信息抽取
赞
踩
任务188: 信息抽取介绍

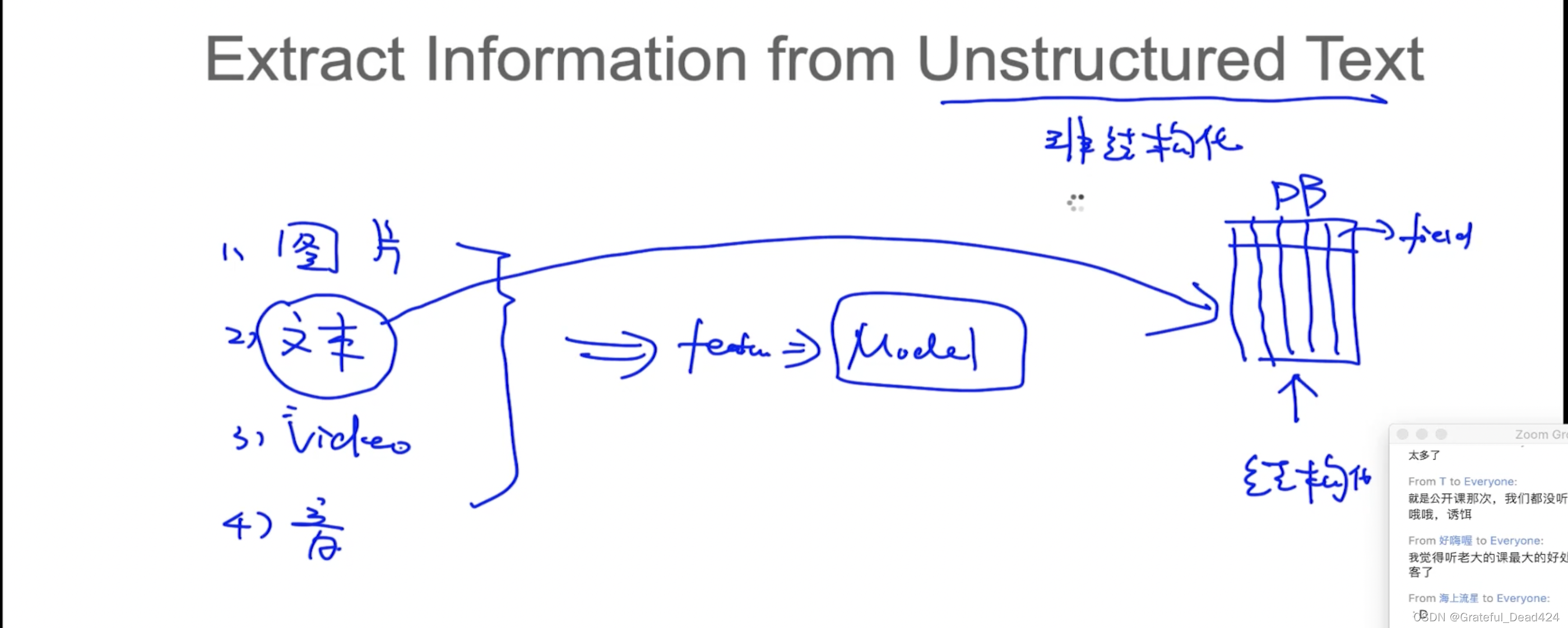

先抽取实体——>再抽取关系

1)标记实体,实体分类(方便抽取关系)
2)关系抽取(关系是人为定义的)
3)指代消解,一个代词指代多个内容的时候分别到底是指拿个内容
4)实体统一(实体链接)
5)实体消歧


任务189: 命名实体识别介绍


意图识别:先规则,规则不行用模型


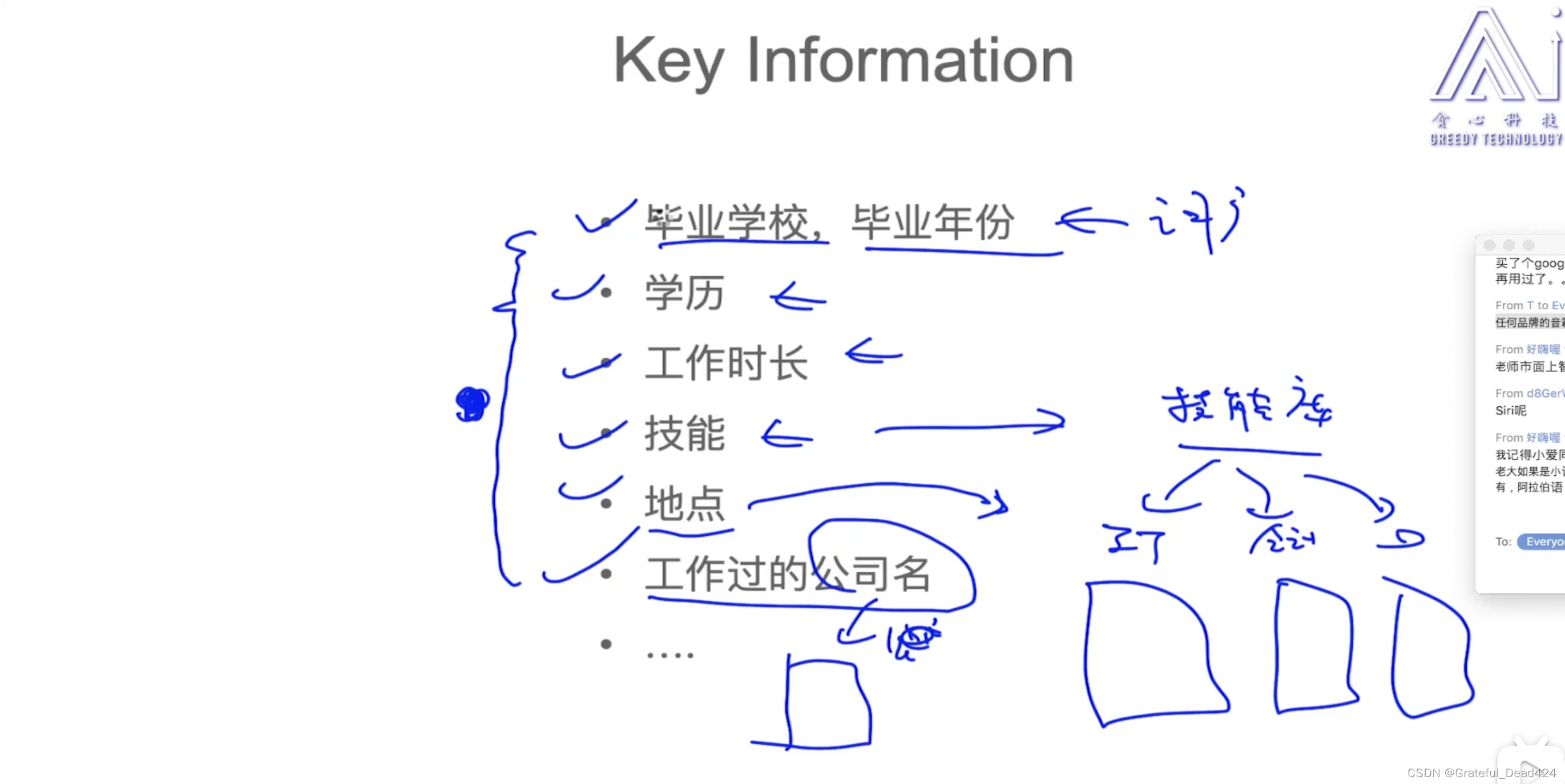
任务190: 简历分析场景

主要是定义我关心的实体类别(可能需要大量的词库)
任务191: 搭建NER分类器

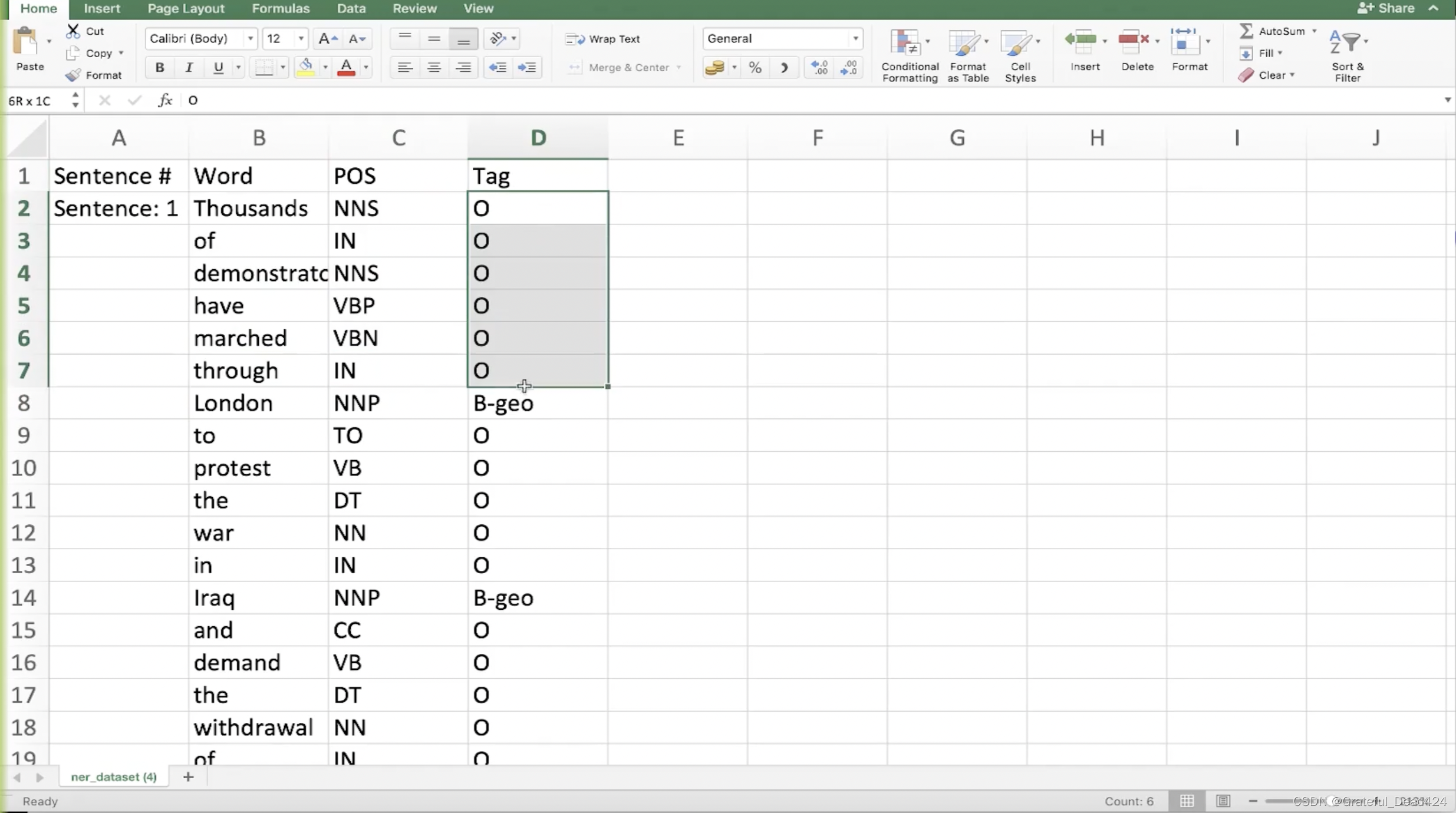
一个单词有一种词性,但是有可能几个单词共同组成一个实体,B指开头,I指不是开头相当于后面的单词


任务192: 方法介绍

任务193: 基于规则的方法

任务194: 投票决策方法(也叫baseline)

import pandas as pd
import numpy as np
data = pd.read_csv("ner_dataset.csv", encoding="latin1")
data = data.fillna(method="ffill")
data.tail(10)
- 1
- 2
- 3
- 4
- 5
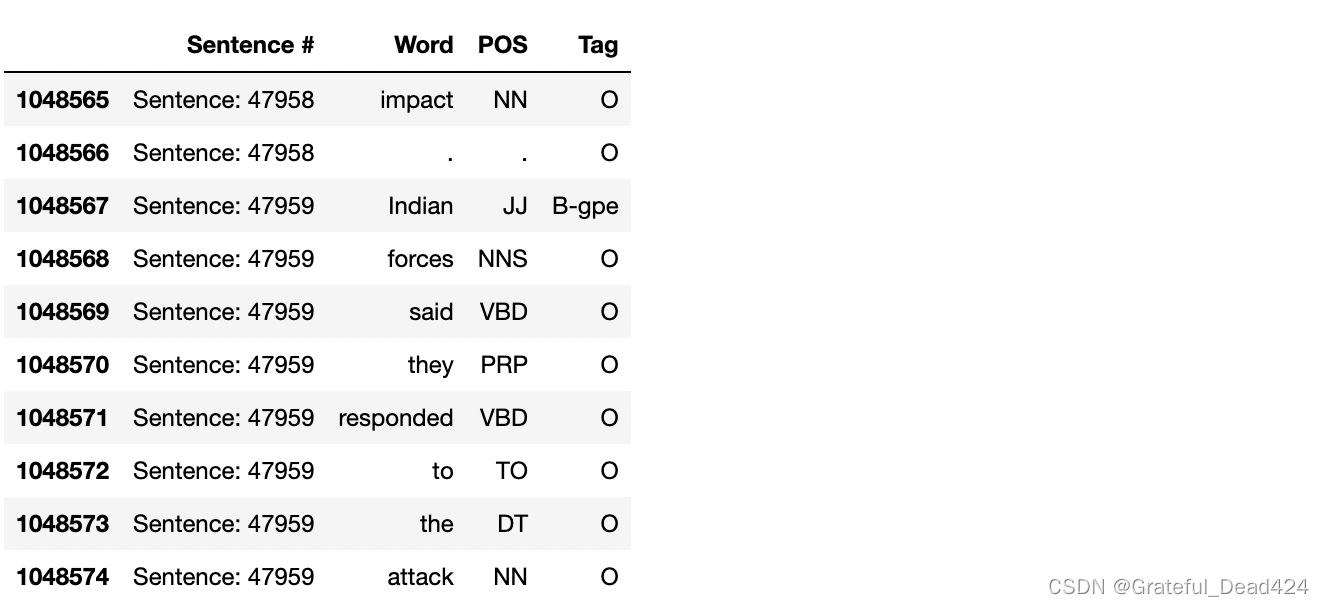
words = list(set(data["Word"].values))
n_words = len(words)
n_words
#35178
- 1
- 2
- 3
- 4
from sklearn.base import BaseEstimator, TransformerMixin class MajorityVotingTagger(BaseEstimator, TransformerMixin): def fit(self, X, y): """ X: list of words y: list of tags """ word2cnt = {} self.tags = [] for x, t in zip(X, y): if t not in self.tags: self.tags.append(t) if x in word2cnt: if t in word2cnt[x]: word2cnt[x][t] += 1 else: word2cnt[x][t] = 1 else: word2cnt[x] = {t: 1} self.mjvote = {} for k, d in word2cnt.items(): self.mjvote[k] = max(d, key=d.get) def predict(self, X, y=None): ''' Predict the the tag from memory. If word is unknown, predict 'O'. ''' return [self.mjvote.get(x, 'O') for x in X] words = data["Word"].values.tolist() tags = data["Tag"].values.tolist() from sklearn.model_selection import cross_val_predict from sklearn.metrics import classification_report pred = cross_val_predict(estimator=MajorityVotingTagger(), X=words, y=tags, cv=5) report = classification_report(y_pred=pred, y_true=tags) print(report) # precision recall f1-score support # B-art 0.20 0.05 0.09 402 # B-eve 0.54 0.25 0.34 308 # B-geo 0.78 0.85 0.81 37644 # B-gpe 0.94 0.93 0.94 15870 # B-nat 0.42 0.28 0.33 201 # B-org 0.67 0.49 0.56 20143 # B-per 0.78 0.65 0.71 16990 # B-tim 0.87 0.77 0.82 20333 # I-art 0.04 0.01 0.01 297 # I-eve 0.39 0.12 0.18 253 # I-geo 0.73 0.58 0.65 7414 # I-gpe 0.62 0.45 0.52 198 # I-nat 0.00 0.00 0.00 51 # I-org 0.69 0.53 0.60 16784 # I-per 0.73 0.65 0.69 17251 # I-tim 0.58 0.13 0.21 6528 # O 0.97 0.99 0.98 887908 # micro avg 0.95 0.95 0.95 1048575 # macro avg 0.59 0.45 0.50 1048575 # weighted avg 0.94 0.95 0.94 1048575

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
任务195: 特征工程与特征表示01

from sklearn.ensemble import RandomForestClassifier def get_feature(word): return np.array([word.istitle(), word.islower(), word.isupper(), len(word), word.isdigit(), word.isalpha()]) words = [get_feature(w) for w in data["Word"].values.tolist()] tags = data["Tag"].values.tolist() from sklearn.model_selection import cross_val_predict from sklearn.metrics import classification_report pred = cross_val_predict(RandomForestClassifier(n_estimators=20), X=words, y=tags, cv=5) report = classification_report(y_pred=pred, y_true=tags) print(report) # precision recall f1-score support # B-art 0.00 0.00 0.00 402 # B-eve 0.00 0.00 0.00 308 # B-geo 0.26 0.80 0.40 37644 # B-gpe 0.25 0.03 0.05 15870 # B-nat 0.00 0.00 0.00 201 # B-org 0.65 0.17 0.27 20143 # B-per 0.96 0.20 0.33 16990 # B-tim 0.29 0.32 0.30 20333 # I-art 0.00 0.00 0.00 297 # I-eve 0.00 0.00 0.00 253 # I-geo 0.00 0.00 0.00 7414 # I-gpe 0.00 0.00 0.00 198 # I-nat 0.00 0.00 0.00 51 # I-org 0.36 0.03 0.06 16784 # I-per 0.47 0.02 0.04 17251 # I-tim 0.50 0.06 0.11 6528 # O 0.97 0.98 0.97 887908 # accuracy 0.87 1048575 # macro avg 0.28 0.15 0.15 1048575 # weighted avg 0.88 0.87 0.86 1048575
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
比baseline还低,因为只考虑单词本身的信息,没有考虑上下文的信息

def get_sentences(data): agg_func = lambda s: [(w, p, t) for w, p, t in zip(s["Word"].values.tolist(), s["POS"].values.tolist(), s["Tag"].values.tolist())] sentence_grouped = data.groupby("Sentence #").apply(agg_func) return [s for s in sentence_grouped] sentences = get_sentences(data) from sklearn.preprocessing import LabelEncoder out = [] y = [] mv_tagger = MajorityVotingTagger() tag_encoder = LabelEncoder() pos_encoder = LabelEncoder() words = data["Word"].values.tolist() pos = data["POS"].values.tolist() tags = data["Tag"].values.tolist() mv_tagger.fit(words, tags) tag_encoder.fit(tags) pos_encoder.fit(pos) for sentence in sentences: for i in range(len(sentence)): w, p, t = sentence[i][0], sentence[i][1], sentence[i][2] if i < len(sentence)-1: # 如果不是最后一个单词,则可以用到下文的信息 mem_tag_r = tag_encoder.transform(mv_tagger.predict([sentence[i+1][0]]))[0] true_pos_r = pos_encoder.transform([sentence[i+1][1]])[0] else: mem_tag_r = tag_encoder.transform(['O'])[0] true_pos_r = pos_encoder.transform(['.'])[0] if i > 0: # 如果不是第一个单词,则可以用到上文的信息 mem_tag_l = tag_encoder.transform(mv_tagger.predict([sentence[i-1][0]]))[0] true_pos_l = pos_encoder.transform([sentence[i-1][1]])[0] else: mem_tag_l = tag_encoder.transform(['O'])[0] true_pos_l = pos_encoder.transform(['.'])[0] #print (mem_tag_r, true_pos_r, mem_tag_l, true_pos_l) out.append(np.array([w.istitle(), w.islower(), w.isupper(), len(w), w.isdigit(), w.isalpha(), tag_encoder.transform(mv_tagger.predict([sentence[i][0]])), pos_encoder.transform([p])[0], mem_tag_r, true_pos_r, mem_tag_l, true_pos_l])) y.append(t) from sklearn.model_selection import cross_val_predict from sklearn.metrics import classification_report pred = cross_val_predict(RandomForestClassifier(n_estimators=20), X=out, y=y, cv=5) report = classification_report(y_pred=pred, y_true=y) print(report) # precision recall f1-score support # # B-art 0.56 0.35 0.43 402 # B-eve 0.56 0.35 0.43 308 # B-geo 0.85 0.91 0.88 37644 # B-gpe 0.98 0.94 0.96 15870 # B-nat 0.50 0.30 0.37 201 # B-org 0.79 0.73 0.76 20143 # B-per 0.87 0.87 0.87 16990 # B-tim 0.90 0.83 0.86 20333 # I-art 0.44 0.15 0.23 297 # I-eve 0.40 0.21 0.28 253 # I-geo 0.81 0.74 0.77 7414 # I-gpe 0.86 0.58 0.69 198 # I-nat 0.81 0.25 0.39 51 # I-org 0.81 0.77 0.79 16784 # I-per 0.89 0.90 0.89 17251 # I-tim 0.85 0.55 0.67 6528 # O 0.99 1.00 0.99 887908 # # accuracy 0.97 1048575 # macro avg 0.76 0.61 0.66 1048575 #weighted avg 0.97 0.97 0.97 1048575
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74

连续变量离散化:加入非线性因素
任务196: 特征工程与特征表示02
ordinal/ranking feature只有顺序意义,没有大小意义 A-B!=B-C

ordinal/ranking feature处理方法
(1)直接用
(2)当作类别变量用
import pandas as pd import numpy as np data = pd.read_csv("ner_dataset.csv", encoding="latin1") data = data.fillna(method="ffill") words = list(set(data["Word"].values)) n_words = len(words) def get_sentences(data): agg_func = lambda s: [(w, p, t) for w, p, t in zip(s["Word"].values.tolist(), s["POS"].values.tolist(), s["Tag"].values.tolist())] sentence_grouped = data.groupby("Sentence #").apply(agg_func) return [s for s in sentence_grouped] sentences = get_sentences(data) def word2features(sent, i): word = sent[i][0] postag = sent[i][1] features = { 'bias': 1.0, 'word.lower()': word.lower(), 'word[-3:]': word[-3:], 'word[-2:]': word[-2:], 'word.isupper()': word.isupper(), 'word.istitle()': word.istitle(), 'word.isdigit()': word.isdigit(), 'postag': postag, 'postag[:2]': postag[:2], } if i > 0: # word_prev, word_curr word1 = sent[i-1][0] postag1 = sent[i-1][1] features.update({ '-1:word.lower()': word1.lower(), '-1:word.istitle()': word1.istitle(), '-1:word.isupper()': word1.isupper(), '-1:postag': postag1, '-1:postag[:2]': postag1[:2], }) else: features['BOS'] = True if i < len(sent)-1: word1 = sent[i+1][0] postag1 = sent[i+1][1] features.update({ '+1:word.lower()': word1.lower(), '+1:word.istitle()': word1.istitle(), '+1:word.isupper()': word1.isupper(), '+1:postag': postag1, '+1:postag[:2]': postag1[:2], }) else: features['EOS'] = True return features def sent2features(sent): return [word2features(sent, i) for i in range(len(sent))] def sent2labels(sent): return [label for token, postag, label in sent] def sent2tokens(sent): return [token for token, postag, label in sent] X = [sent2features(s) for s in sentences] y = [sent2labels(s) for s in sentences] from sklearn_crfsuite import CRF crf = CRF(algorithm='lbfgs', c1=0.1, c2=0.1, max_iterations=100) from sklearn.model_selection import cross_val_predict from sklearn_crfsuite.metrics import flat_classification_report pred = cross_val_predict(estimator=crf, X=X, y=y, cv=5) from sklearn_crfsuite.metrics import flat_classification_report report = flat_classification_report(y_pred=pred, y_true=y) print(report)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
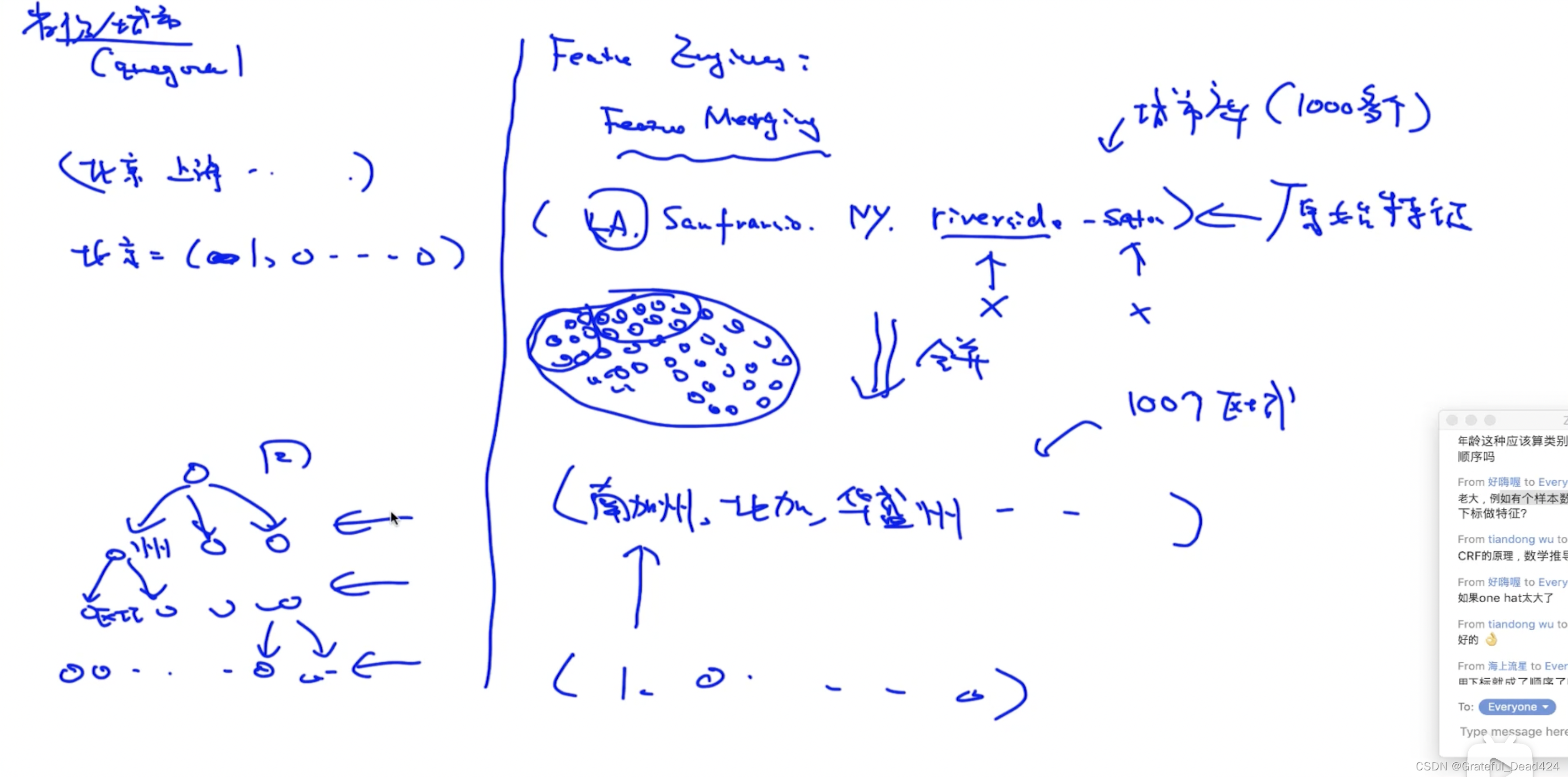
特征合并
城市——>区域——>州——>国家(选择哪个level?)
任务198: 信息抽取介绍
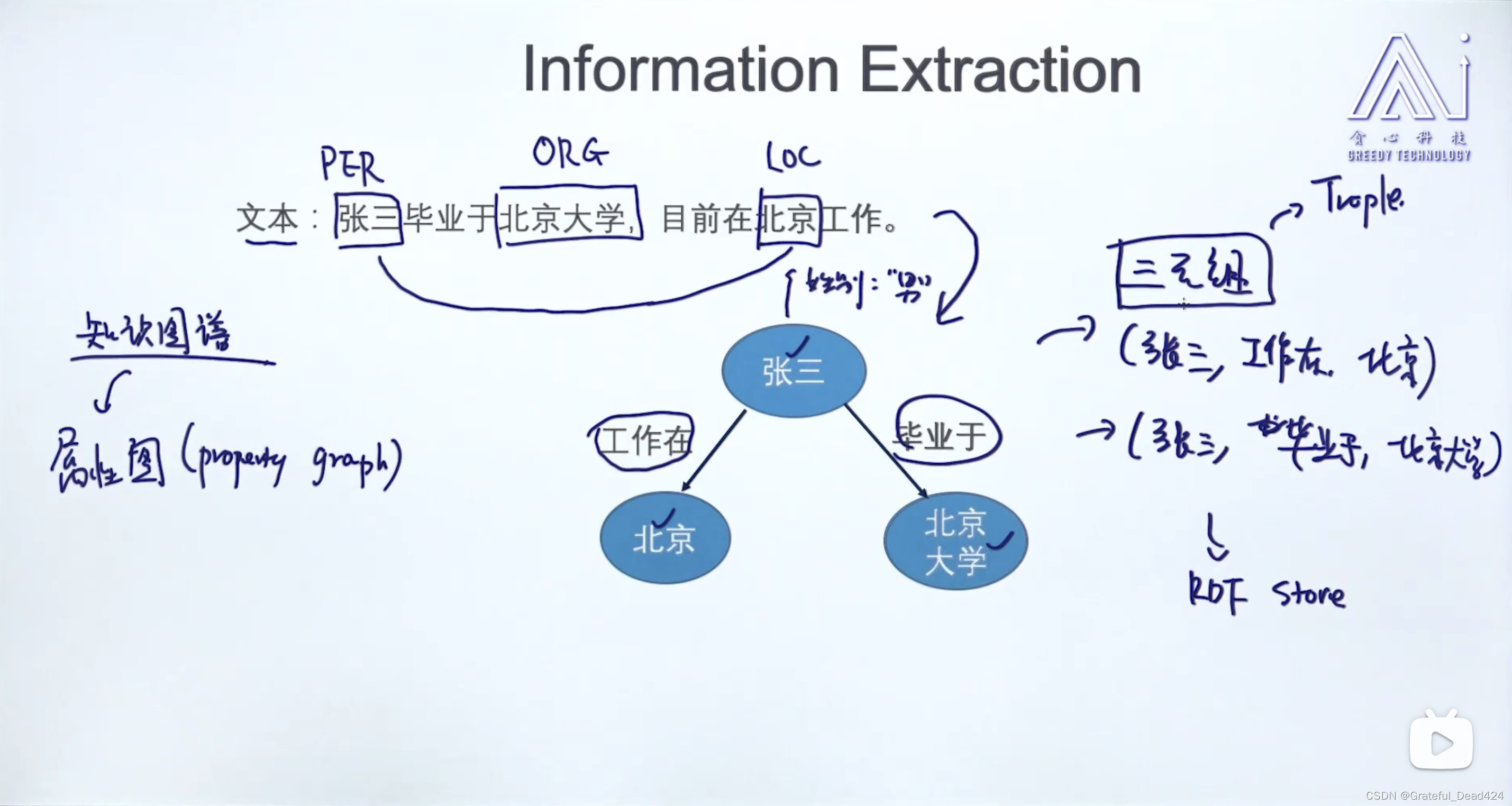
先抽取实体:张三、北京大学、北京,再抽取关系:毕业于、工作在。
得到了非常简单的知识图谱,可以通过三元组的方式描述
(张三,工作在,北京)
(张三,毕业于,北京大学)
就形成了知识图谱
还可以补充一些关于实体、关系的属性,成为了属性图

信息抽取是一个很泛的概念,有些时候抽取左边的实体就行,有些时候既要抽取实体又要抽取关系像右边

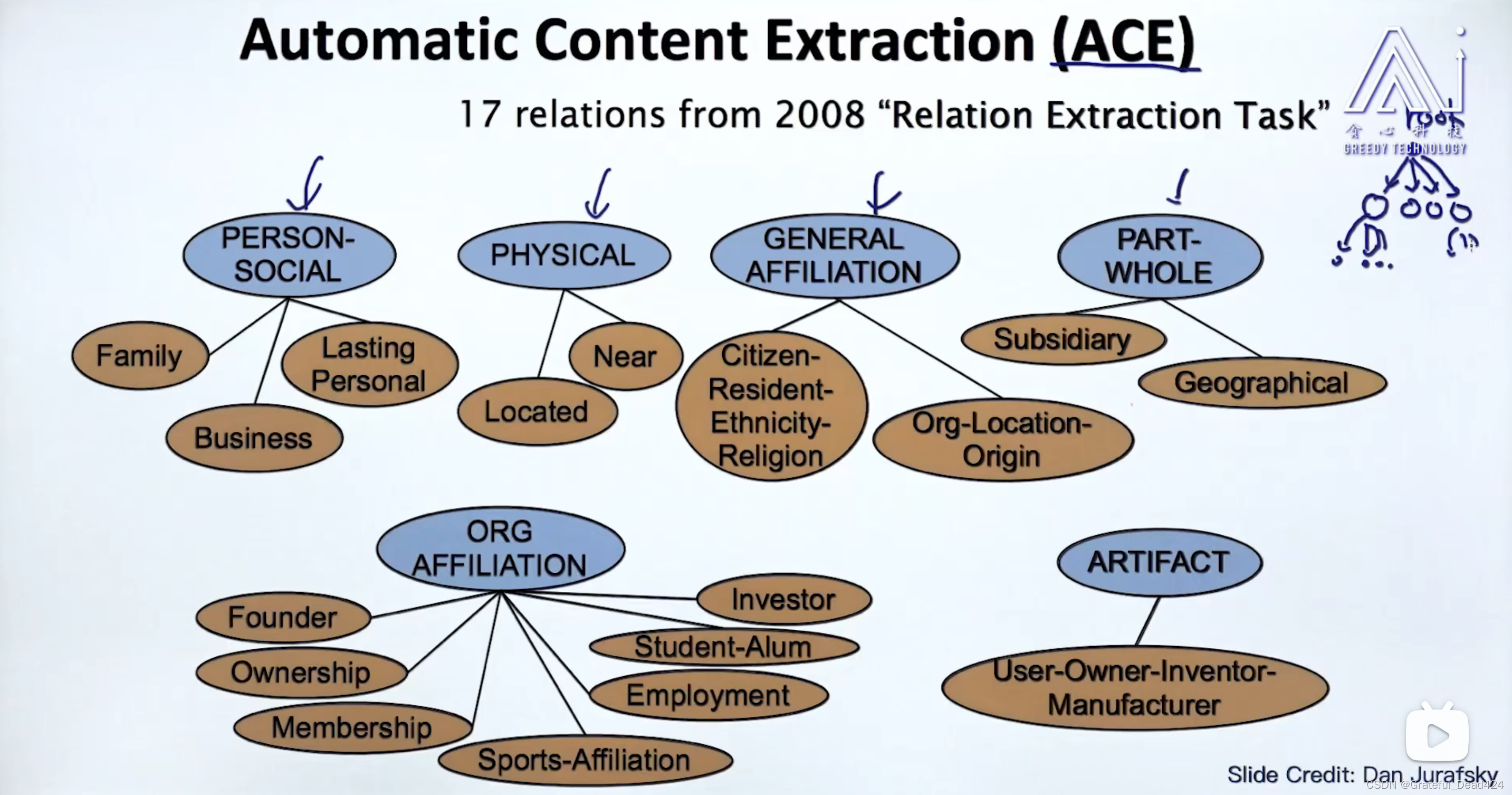

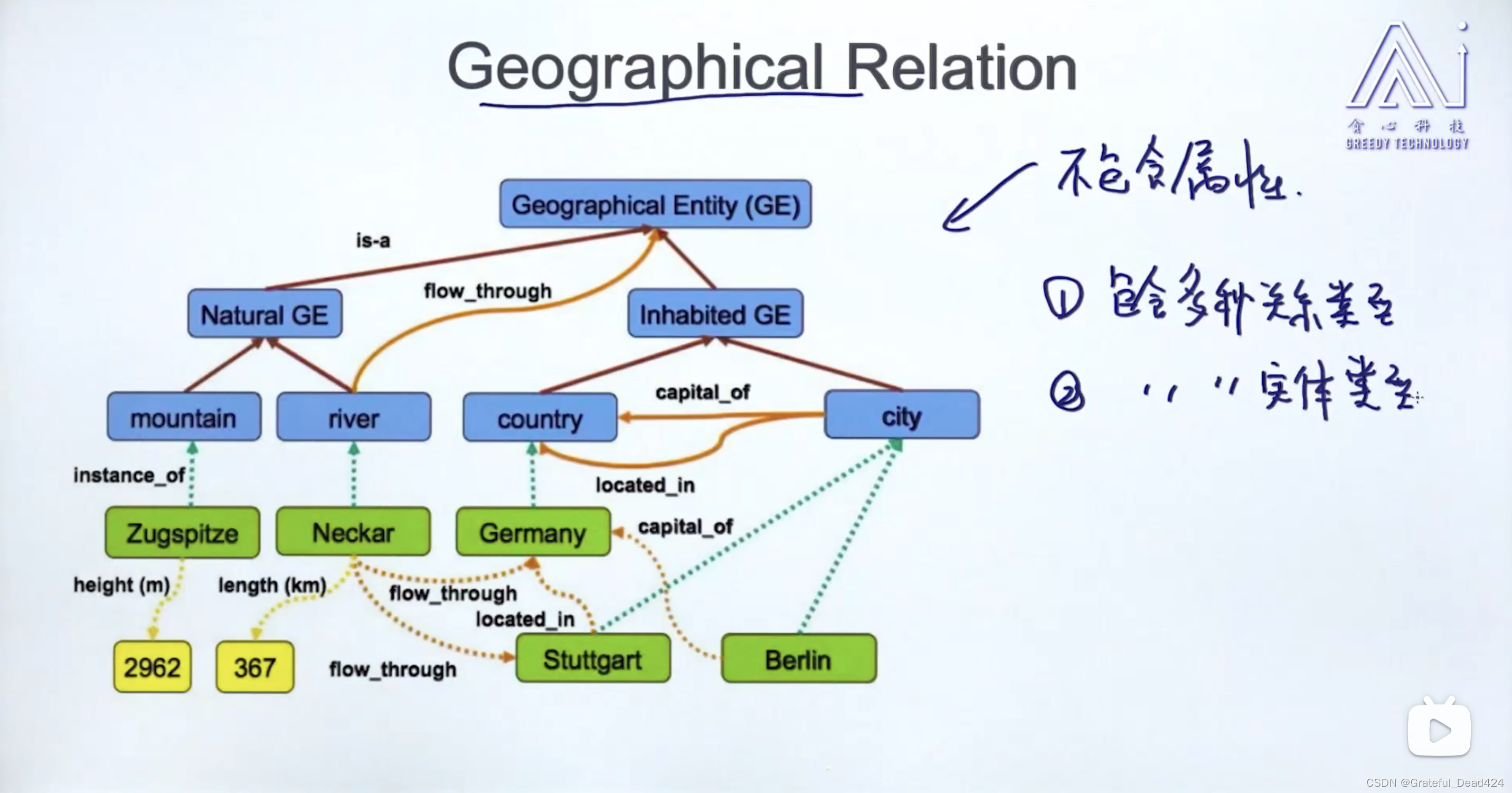
任务199: Ontological Relation(本体论关系)


任务200: 关系抽取方法介绍

任务201: 基于规则的方法

找is-a关系:
(1)定义关系:is a;such as;including;especially。。。都是is a关系一样的关系
(2)在文档里边,先进行实体识别,看实体之间的关系是否在定义的关系当中,把实体整理出来

在水果的范围内找符合is-a关系的实体:
X such as y——先对X过滤,只和水果有关

任务202: 基于监督学习的方法



前面一页的特征工程通常比较好使,后面一页一般用得少
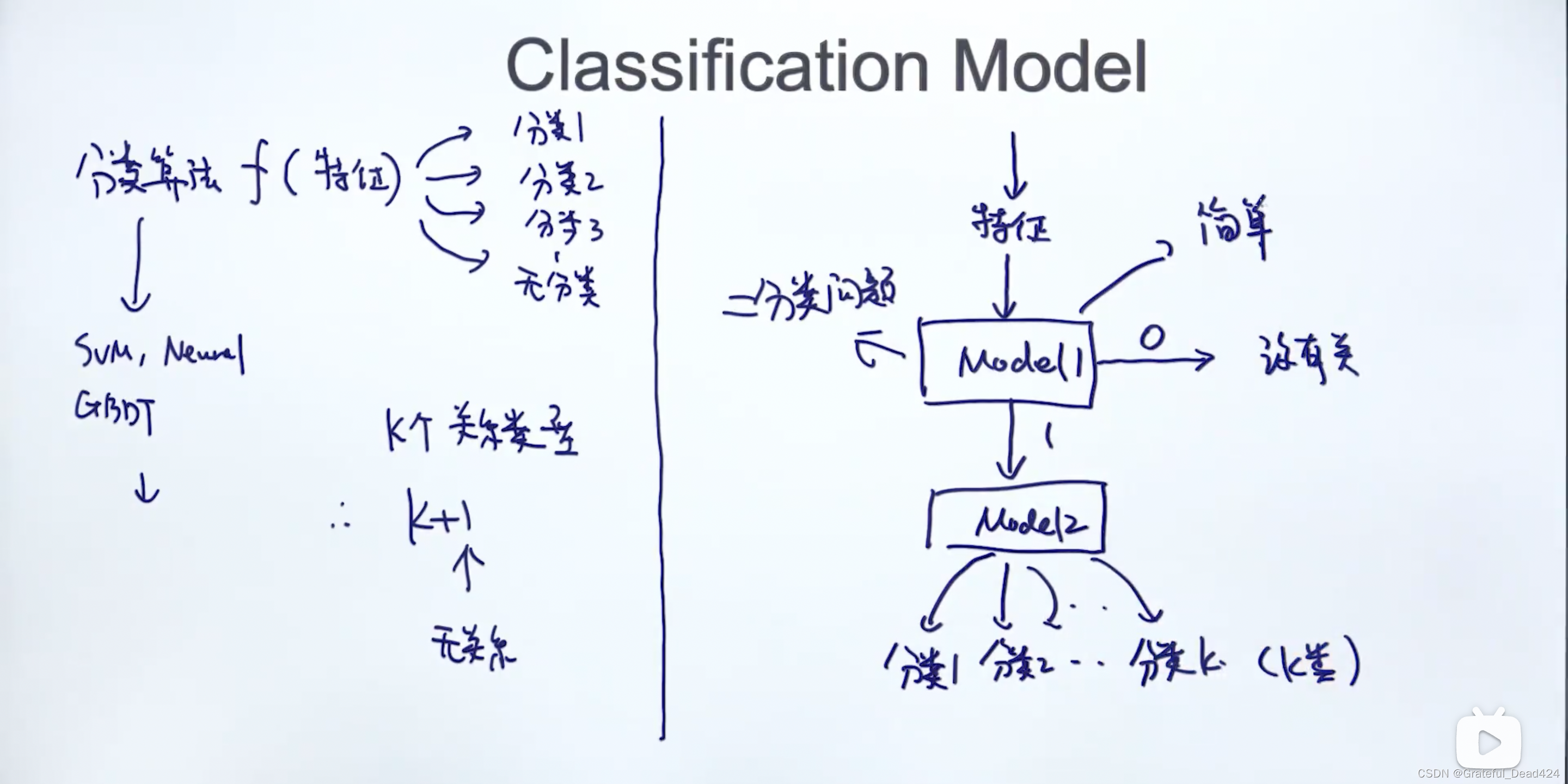
有关系的实体是少数,因此我们能把左边这个过程改变一下,变成右边这个过程,model1是一个二分类问题,模型较简单,大多数结果都是没关系,不用进入model2
任务205: 关系抽取

有一个文本,根据seed tuple,寻找新的规则出来
规则是自动生成的。第一步:已知一个seed tuple,根据文本和seed tuple自动形成规则,放到规则库里面;第二步:根据规则,在新的文本里,寻找出新tuple。第一步第二步反复循环
缺点:
(1)李航在做机器学习方面研究,这句话和作者和书无关,会导致出现的有些规则特别弱
(2)实体之间单词有很多没用的
(3)完全匹配
任务206: bootstrap算法的缺点
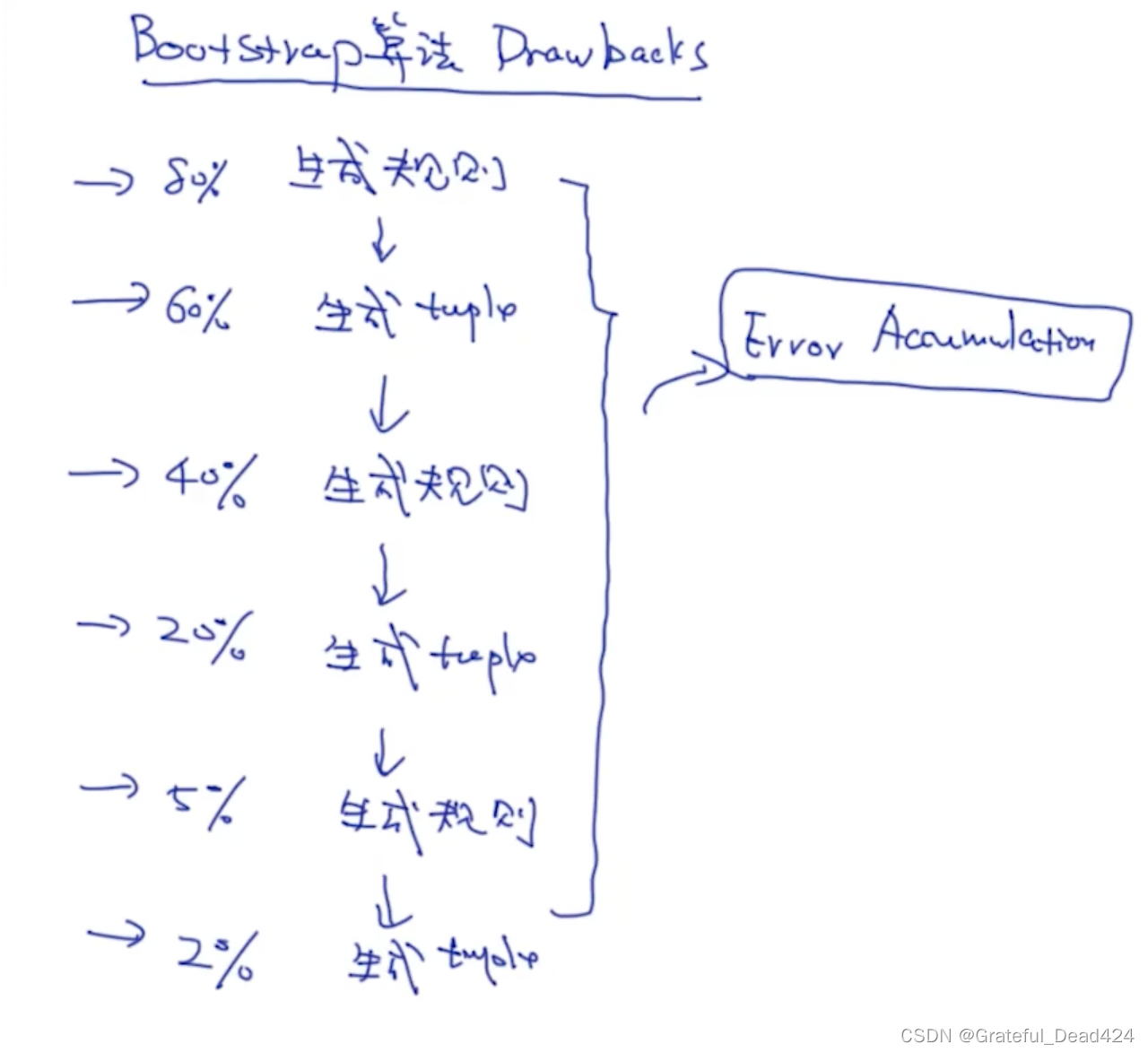
针对精准匹配和error accumulation的问题snow ball对bootstrap进行了改进

任务207: SnowBall算法
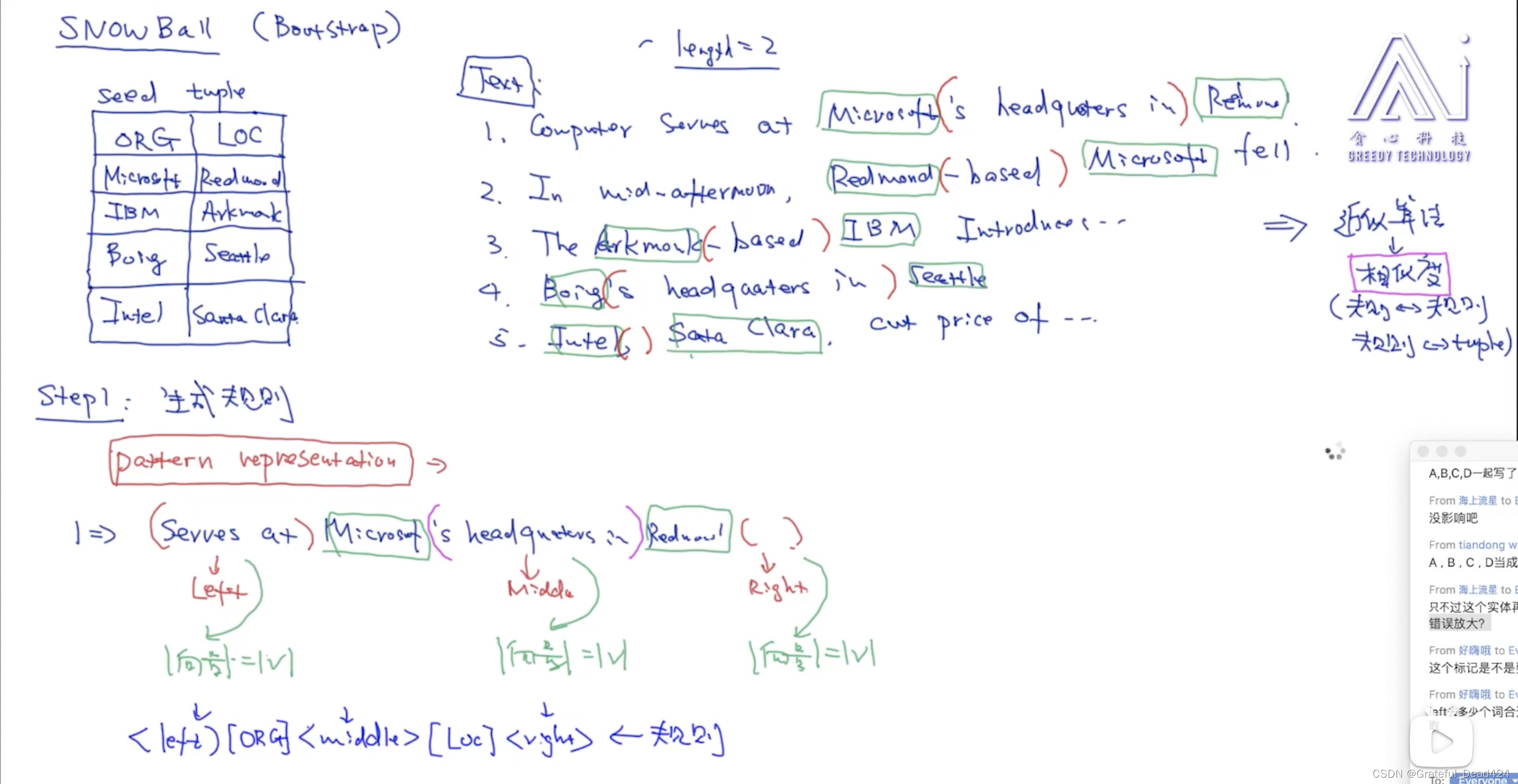

五元组:
两个实体+实体中间的关系+第一个实体前面两个词+后一个实体后面两个词(假设length=2)
如何计算相似度:
(1)先看实体类别是否一致,不一致的话相似度=0
(2)然后再计算L1L2的相似度(内积表示,长度已经为1,故不需要除以长度,下面一样),M1M2的相似度(内积表示),R1R2的相似度(内积表示),然后加权求和。
任务208: 生成模板

任务209: 生成tuple与模板评估

模版里面的x和y是实体类型,通过实体识别以及分类器先在text里寻找x和y,然后把五元组找出来,非实体部分转化成向量。就可以计算这个五元组,和模版五元组的相似度(任一个),相似度大于一定阈值,可以添加seed tuple。
pattern evaluation
任务210: 评估记录+过滤
tuple evaluation
(1)pattern置信度越高,生成的tuple置信度越高
(1)相同的规则数目下,哪个规则更靠谱
(2)不同的规则数目下,哪个规则更多
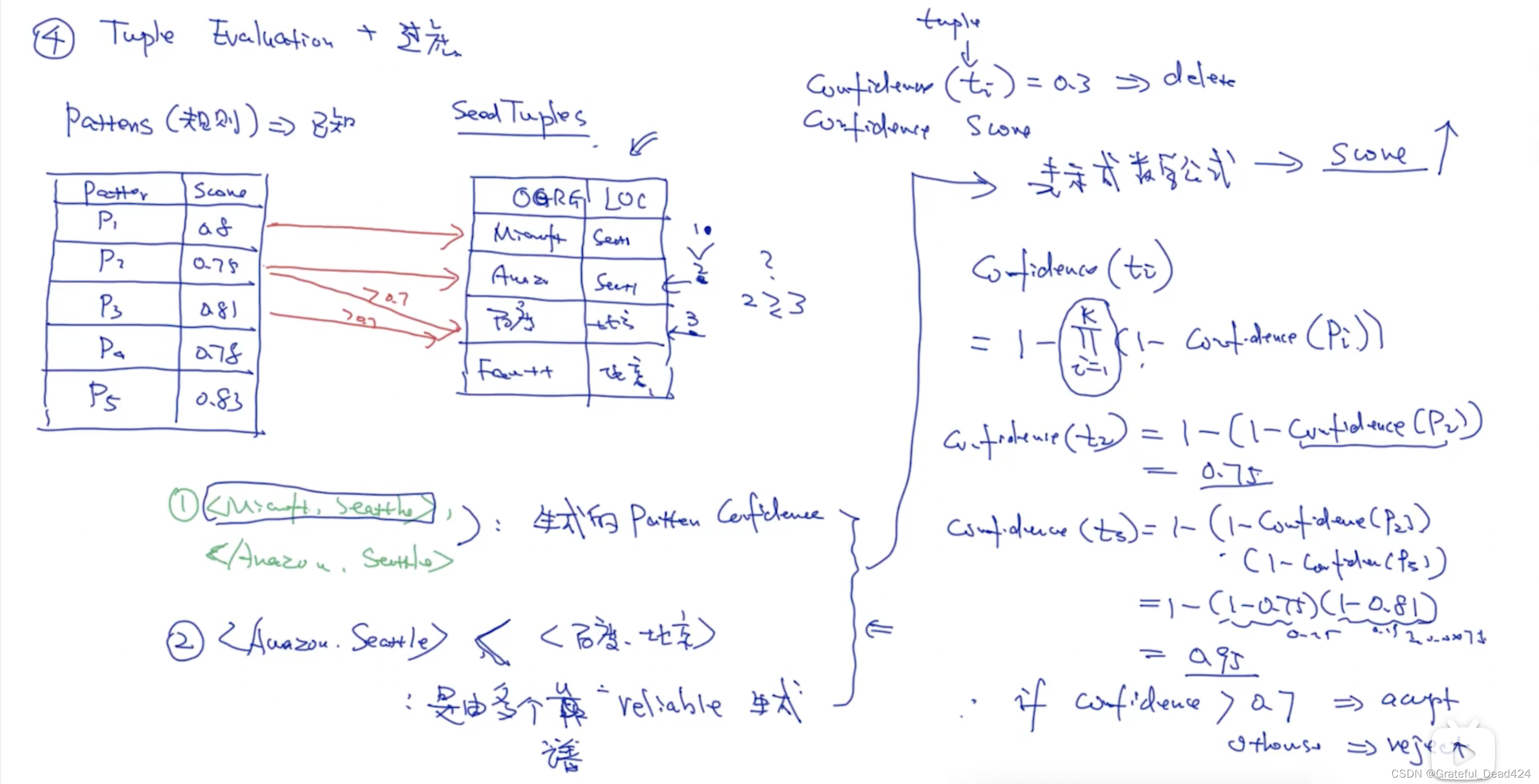
任务211: SnowBall总结



