- 1Win 10 UEFI + Ubuntu 18.04 UEFI 双系统 (by quqi99)_active命令只能用于固定mbr磁盘
- 2ChatGPT 能拯救程序员吗?
- 3【MySQL篇】第五篇——表的约束_mysql建表约束
- 4DDoS的攻击原理与防御方法_ddos攻击防御
- 5动态规划【2020第一版】_动态规划segmentation
- 6MariaDB 10.5,MySQL乱码问题,设置字符编码UTF8
- 7小白如何进入IT行业及如何选择培训机构_想学it怎样筛选培训机构
- 8Springboot计算机毕业设计基于微信小程序民宿预订系统【附源码】开题+论文+mysql+程序+部署
- 9领导暗示你辞职的五个方式,遇到了你是乖乖离开还是死扛到底?_老板暗示主动辞职如何应对
- 10分布式主键?雪花算法?号段模式?一文搞懂目前主流分布式主键解决方法
Logistic - 逻辑斯蒂回归(对数回归) - 分类问题_逻辑斯特回归 线性化
赞
踩
一: 逻辑斯蒂回归原理
(一): 似然函数
每个样本的概率:
P
(
y
∣
x
;
θ
)
=
(
h
θ
(
x
)
)
y
(
1
−
h
θ
(
x
)
)
1
−
y
P(y|x;\theta)=(h_{\theta}(x))^y(1-h_\theta (x))^{1-y}
P(y∣x;θ)=(hθ(x))y(1−hθ(x))1−y
事件的概率(所有样本属于真实标记的概率)
L
(
θ
)
=
∏
i
=
1
n
P
(
y
i
∣
x
i
;
θ
)
L(\theta)= \prod_{i=1}^nP(y_i|x_i;\theta)
L(θ)=i=1∏nP(yi∣xi;θ)
L ( θ ) = ∏ i = 1 n ( h θ ( x i ) ) y i ( 1 − h θ ( x i ) ) 1 − y i L(\theta)= \prod_{i=1}^n(h_{\theta}(x_i))^{y_i}(1-h_\theta (x_i))^{1-{y_i}} L(θ)=i=1∏n(hθ(xi))yi(1−hθ(xi))1−yi
似然函数解决二分类问题:
当y=1时:
P
(
1
∣
x
i
;
θ
)
=
(
h
θ
(
x
i
)
)
1
(
1
−
h
θ
(
x
i
)
)
1
−
1
P(1|x_i;\theta)=(h_{\theta}(x_i))^1(1-h_\theta (x_i))^{1-1}
P(1∣xi;θ)=(hθ(xi))1(1−hθ(xi))1−1
P ( 1 ∣ x i ; θ ) = h θ ( x i ) P(1|x_i;\theta)=h_{\theta}(x_i) P(1∣xi;θ)=hθ(xi)
当y=0时:
P
(
0
∣
x
i
;
θ
)
=
(
h
θ
(
x
i
)
)
0
(
1
−
h
θ
(
x
i
)
)
1
−
0
P(0|x_i;\theta)=(h_{\theta}(x_i))^0(1-h_\theta (x_i))^{1-0}
P(0∣xi;θ)=(hθ(xi))0(1−hθ(xi))1−0
P ( 0 ∣ x i ; θ ) = 1 − h θ ( x i ) P(0|x_i;\theta)=1-h_\theta (x_i) P(0∣xi;θ)=1−hθ(xi)
举个栗子:
假如有一个罐子,里面有黑白两种颜色的球,数目多少不知,两种颜色的比例也不知。我们想知道罐中白球和黑球的比例,但我们不能把罐中的球全部拿出来数。现在我们可以每次任意从已经摇匀的罐中拿一个球出来,记录球的颜色,然后把拿出来的球再放回罐中。这个过程可以重复,我们可以用记录的球的颜色来估计罐中黑白球的比例。假如在前面的一百次重复记录中,有七十次是白球,请问罐中白球所占的比例最有可能是多少?
解:
设每次取到白球的概率为p, 则取到黑球的概率为(1-p), 则100次中70次取到白球的概率为:
P
=
C
100
70
p
70
(
1
−
p
)
30
P=C_{100}^{70}p^{70}(1-p)^{30}
P=C10070p70(1−p)30
P ′ = ( p 70 ) ′ ( 1 − p ) 30 + p 70 ( ( 1 − p ) 30 ) ′ × ( 1 − p ) ′ P'=(p^{70})'(1-p)^{30}+p^{70}((1-p)^{30})'\times(1-p)' P′=(p70)′(1−p)30+p70((1−p)30)′×(1−p)′
P ′ = 70 p 69 ( 1 − p ) 30 − p 70 30 ( 1 − p ) 29 P'=70p^{69}(1-p)^{30}-p^{70}30(1-p)^{29} P′=70p69(1−p)30−p7030(1−p)29
此时令导数为零求最大值:
0
=
70
p
69
(
1
−
p
)
30
−
p
70
30
(
1
−
p
)
29
0=70p^{69}(1-p)^{30}-p^{70}30(1-p)^{29}
0=70p69(1−p)30−p7030(1−p)29
化简:
0
=
70
(
1
−
p
)
−
30
p
0=70(1-p)-30p
0=70(1−p)−30p
100 p = 70 100p=70 100p=70
所以:
p
=
70
÷
100
p=70\div100
p=70÷100
(二): 逻辑斯蒂回归原理和损失函数
分类问题其实都是概率问题, 逻辑斯蒂函数就是概率函数,无论给的值多大多小都会转变到0-1之间进行比较,并得出概率进行分类
sigmoid函数:
S
(
t
)
=
1
1
+
e
−
t
S(t) = \frac{1}{1+e^{-t}}
S(t)=1+e−t1
线性回归方程:
一
般
模
式
:
f
(
x
)
=
θ
x
+
b
一般模式: f(x) = {\theta}x+b
一般模式:f(x)=θx+b
矩 阵 模 式 : f ( X ) = ∑ i = 1 n x i θ i + b 矩阵模式: f(X) = \sum\limits _{i=1}^nx_i{\theta}_i+b 矩阵模式:f(X)=i=1∑nxiθi+b
1: 逻辑斯蒂回归原理
逻辑斯蒂回归 = 线性回归 + sigmoid
方程结合 - 预测函数:
一
般
形
式
:
h
θ
(
x
)
=
1
1
+
e
−
x
θ
一般形式: h_{\theta}(x)=\frac{1}{1+e^{-x\theta}}
一般形式:hθ(x)=1+e−xθ1
矩 阵 模 式 : h θ ( X ) = 1 1 + e − X θ 矩阵模式: h_{\theta}(X)=\frac{1}{1+e^{-X\theta}} 矩阵模式:hθ(X)=1+e−Xθ1
2: 最大似然估计法求损失函数
最大似然估计公式求对数:
l
(
θ
)
=
l
n
(
L
(
θ
)
)
=
l
n
[
∏
i
=
1
n
(
h
θ
(
x
i
)
)
y
i
(
1
−
h
θ
(
x
i
)
)
1
−
y
i
]
l(\theta) = ln(L(\theta)) =ln[ \prod_{i=1}^n(h_{\theta}(x_i))^{y_i}(1-h_\theta (x_i))^{1-{y_i}}]
l(θ)=ln(L(θ))=ln[i=1∏n(hθ(xi))yi(1−hθ(xi))1−yi]
乘积的对数可以转换成加法:
l
(
θ
)
=
∑
i
=
1
n
[
y
i
l
n
(
h
θ
(
x
i
)
)
+
(
1
−
y
i
)
l
n
(
1
−
h
θ
(
x
i
)
)
]
l(\theta)= \sum_{i=1}^n[y_iln(h_{\theta}(x_i))+(1-{y_i})ln(1-h_\theta (x_i))]
l(θ)=i=1∑n[yiln(hθ(xi))+(1−yi)ln(1−hθ(xi))]
最大似然估计就是要求得使
l
(
θ
)
l(\theta)
l(θ) 取最大值时的
θ
\theta
θ ,其实这里可以使用梯度上升法求解,求得的
θ
\theta
θ 就是要求的最佳参数
对似然函数对数化取反的表达式,即损失函数表达式
J
(
θ
)
=
−
l
(
θ
)
=
−
∑
i
=
1
n
[
y
i
l
n
(
h
θ
(
x
i
)
)
+
(
1
−
y
i
)
l
n
(
1
−
h
θ
(
x
i
)
)
]
J(\theta) = -l(\theta) = -\sum_{i=1}^n[y_iln(h_{\theta}(x_i))+(1-{y_i})ln(1-h_\theta (x_i))]
J(θ)=−l(θ)=−i=1∑n[yiln(hθ(xi))+(1−yi)ln(1−hθ(xi))]
损失函数
J
(
θ
)
J(\theta)
J(θ) 对
θ
\theta
θ 求导:
J
′
(
θ
)
=
∂
J
(
θ
)
∂
θ
J'(\theta) = \frac{\partial J(\theta)}{\partial\theta}
J′(θ)=∂θ∂J(θ)
∂
J
(
θ
)
∂
θ
=
−
∑
i
=
1
n
[
y
i
1
h
θ
(
x
i
)
∂
h
θ
(
x
i
)
∂
θ
+
(
1
−
y
i
)
1
1
−
h
θ
(
x
i
)
∂
(
1
−
h
θ
(
x
i
)
)
∂
θ
]
注
释
:
l
n
(
x
)
′
=
1
x
=
−
∑
i
=
1
n
[
y
i
1
h
θ
(
x
i
)
∂
h
θ
(
x
i
)
∂
θ
−
(
1
−
y
i
)
1
1
−
h
θ
(
x
i
)
∂
h
θ
(
x
i
)
∂
θ
]
=
−
∑
i
=
1
n
[
y
i
1
h
θ
(
x
i
)
−
(
1
−
y
i
)
1
1
−
h
θ
(
x
i
)
]
∂
h
θ
(
x
i
)
∂
θ
注
释
:
∂
h
θ
(
x
i
)
∂
θ
的
推
导
过
程
详
见
下
文
=
−
∑
i
=
1
n
[
y
i
1
h
θ
(
x
i
)
−
(
1
−
y
i
)
1
1
−
h
θ
(
x
i
)
]
x
i
h
θ
(
x
i
)
(
1
−
h
θ
(
x
i
)
)
=
−
∑
i
=
1
n
[
y
i
(
1
−
h
θ
(
x
i
)
)
−
(
1
−
y
i
)
h
θ
(
x
i
)
]
x
i
=
−
∑
i
=
1
n
[
y
i
−
h
θ
(
x
i
)
]
x
i
=
∑
i
=
1
n
[
h
θ
(
x
i
)
−
y
i
]
x
i
推导
∂
h
θ
(
x
i
)
∂
θ
\frac{\partial h_\theta(x_i)}{\partial\theta}
∂θ∂hθ(xi) 的过程:
∂
h
θ
(
x
i
)
∂
θ
=
h
θ
′
(
x
i
)
=
(
1
1
+
e
−
x
i
θ
)
′
=
(
1
1
+
e
−
θ
T
x
i
)
′
=
[
(
1
+
e
−
θ
T
x
i
)
−
1
]
′
注
释
:
(
e
x
)
′
=
e
x
=
−
(
1
+
e
−
θ
T
x
i
)
−
2
e
−
θ
T
x
i
(
−
x
i
)
=
(
1
+
e
−
θ
T
x
i
)
−
2
e
−
θ
T
x
i
x
i
=
x
i
e
−
θ
T
x
i
(
1
+
e
−
θ
T
x
i
)
2
=
x
i
1
(
1
+
e
−
θ
T
x
i
)
e
−
θ
T
x
i
(
1
+
e
−
θ
T
x
i
)
=
x
i
h
θ
(
x
i
)
e
−
θ
T
x
i
(
1
+
e
−
θ
T
x
i
)
=
x
i
h
θ
(
x
i
)
1
+
e
−
θ
T
x
i
−
1
(
1
+
e
−
θ
T
x
i
)
=
x
i
h
θ
(
x
i
)
[
1
+
e
−
θ
T
x
i
(
1
+
e
−
θ
T
x
i
)
−
1
(
1
+
e
−
θ
T
x
i
)
]
=
x
i
h
θ
(
x
i
)
[
1
−
1
(
1
+
e
−
θ
T
x
i
)
]
=
x
i
h
θ
(
x
i
)
(
1
−
h
θ
(
x
i
)
)
此时使用梯度下降优化算法, 其系数的更新规则为:
θ
=
θ
−
ϵ
∂
J
(
θ
)
∂
θ
\theta = \theta - \epsilon\frac{\partial J(\theta)}{\partial\theta}
θ=θ−ϵ∂θ∂J(θ)
二: 逻辑斯蒂回归的应用
(一): 简单应用 - 鸢尾花分类
import numpy as np from sklearn.linear_model import LogisticRegression from sklearn import datasets, metrics from sklearn.model_selection import train_test_split # 鸢尾花数据 iris = datasets.load_iris() # 花萼长度, 花萼宽度, 花瓣长度, 花瓣宽度 X = iris['data'] y = iris['target'] # train_test_split随机打乱数据顺序, random_state使得每次随机的数值是一样的 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=512) lr = LogisticRegression(max_iter=1000) # max_iter=1000, 学习次数 lr.fit(X_train, y_train) y_ = lr.predict(X_test) print('实际数据:y_test:\n', y_test) print('预测数据:y_:\n', y_) ''' 实际数据:y_test: [0 1 1 1 2 0 0 2 0 2 1 1 1 0 2 0 2 0 1 1 0 1 0 1 0 2 1 1 1 2] 预测数据:y_: [0 1 1 2 2 0 0 2 0 2 1 1 1 0 2 0 2 0 1 1 0 1 0 2 0 2 1 1 1 2] '''

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
(二): 二分类问题
import numpy as np from sklearn.linear_model import LogisticRegression from sklearn import datasets X,y = datasets.load_iris(True) # True代表只获取数据和目标值 cond = y!=0 # 只留下两个类别,将类别0 删除 X = X[cond] y = y[cond] lr = LogisticRegression() lr.fit(X,y) # 算法,训练数据,找X和y之间的规律,方程 y_ = lr.predict(X) # 规律找到之后,使用规律,进行计算 # 将类别减少之后, 分类后的结果和真实值相差很小,说明类别越少,分类的准确度越高 (y_ == y).mean() # 计算准确率 print(y_) ''' array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]) ''' proba_ = lr.predict_proba(X) # 计算的概率 proba_[:10] # 将概率转化成类别 ''' array([[0.99153216, 0.00846784], [0.9908928 , 0.0091072 ], [0.99355185, 0.00644815], [0.99086387, 0.00913613], [0.99219814, 0.00780186], [0.98268555, 0.01731445], [0.99252002, 0.00747998], [0.9899949 , 0.0100051 ], [0.99259338, 0.00740662], [0.99028393, 0.00971607]]) 每组数据有两种分类的可能性, 每种可能性对应的概率不同,系统在判别的时候会选择概率较大的那个类别 ''' proba_.argmax(axis=1)+1 # 将概率转换为类别; .argmax(axis=1)获取同一行中较大的值(概率)的下标;加1是因为之前的类别0已经被删除了,而这里的下标还有可能是0 ''' array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2], dtype=int64) ''' # 以上是用算法模型得出的分类结果(y_)和概率手动计算概率(proba_),现在我们用代码实现以上效果: w_ = lr.coef_ b_ = lr.intercept_ print('方程系数',lr.coef_) print('方程截距',lr.intercept_) ''' 方程系数 [[ 0.48498493 -0.34086327 1.8278232 0.83365156]] 方程截距 [-8.76905997] ''' def fun(X):#线性方程,矩阵,批量计算 return X.dot(w_[0]) + b_[0] def sigmoid(x):#fun就是线性方程的返回值 return 1/(1+np.e**-x) f = fun(X) p_1 = sigmoid(f) # 求出二分类中一类的概率 p_0 = 1 - p_1 # 求出二分类中另外一类的概率(二分类中凌总可能性的和为1) p_ = np.c_[p_0,p_1] # 将两个概率连接起来 # np.r_:是按列连接两个矩阵,就是把两矩阵上下相加,要求列数相等,类似于pandas中的concat()。 # np.c_:是按行连接两个矩阵,就是把两矩阵左右相加,要求行数相等,类似于pandas中的merge()。 p_[:10] ''' array([[0.99153216, 0.00846784], [0.9908928 , 0.0091072 ], [0.99355185, 0.00644815], [0.99086387, 0.00913613], [0.99219814, 0.00780186], [0.98268555, 0.01731445], [0.99252002, 0.00747998], [0.9899949 , 0.0100051 ], [0.99259338, 0.00740662], [0.99028393, 0.00971607]]) ''' # 对比发现p_和proba_所得到的结果是一致的;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
(三): 多分类问题
import numpy as np from sklearn.linear_model import LogisticRegression from sklearn import datasets, metrics X,y = datasets.load_iris(True) # 打乱顺序 index = np.arange(150) np.random.shuffle(index) X = X[index] y = y[index] lr = LogisticRegression(max_iter=200) # 定义模型 lr.fit(X,y) # 训练模型 # 是3分类问题, 三个方程(每一类对应一个方程),三组斜率,每组斜率有4个属性; 三个截距, w_ = lr.coef_ b_ = lr.intercept_ print('斜率:\n',w_) print('截距:\n',b_) ''' 斜率: [[-0.42294389 0.9669724 -2.51691851 -1.08061335] [ 0.53406236 -0.32159608 -0.20649198 -0.94361292] [-0.11111847 -0.64537632 2.72341049 2.02422627]] 截距: [ 9.84788649 2.2391674 -12.08705389] ''' y_ = lr.predict(X) proba_ = lr.predict_proba(X) # 概率 print('y_:\n', y_) print('proba_:\n', proba_) print(proba_.argmax(axis = 1)) # argmax获取最大值的下标(类别) ''' y_: [2 0 1 2 1 1 0 0 2 1 2 2 1 1 1 0 0 0 0 1 2 1 2 2 2 2 2 0 1 0 2 1 1 1 2 0 0 2 0 1 2 1 2 0 1 2 2 0 1 0 0 2 0 2 0 1 1 1 0 0 0 2 1 1 1 0 0 2 0 2 2 2 2 1 0 1 0 1 2 1 0 2 1 1 2 0 2 1 0 2 1 2 0 1 0 0 2 1 2 1 0 1 0 0 0 1 1 2 1 2 1 1 1 2 0 2 0 2 1 0 0 2 0 0 2 1 0 0 2 1 1 2 0 2 2 2 0 1 2 2 0 0 0 2 2 0 1 2 1 2] proba_: [[2.42893049e-04 1.62572543e-01 8.37184564e-01] [9.76236359e-01 2.37636218e-02 1.93734447e-08] [1.02308731e-02 7.50874989e-01 2.38894138e-01] [6.22245105e-07 2.13422648e-02 9.78657113e-01] ...... [9.08742683e-03 9.76589206e-01 1.43233676e-02] [1.06469379e-06 2.91941988e-02 9.70804737e-01] [2.43372229e-01 7.55336793e-01 1.29097800e-03] [2.27109807e-04 2.51919829e-01 7.47853061e-01]] proba_.argmax(axis = 1): array([2, 0, 1, 2, 1, 1, 0, 0, 2, 1, 2, 2, 1, 1, 1, 0, 0, 0, 0, 1, 2, 1, 2, 2, 2, 2, 2, 0, 1, 0, 2, 1, 1, 1, 2, 0, 0, 2, 0, 1, 2, 1, 2, 0, 1, 2, 2, 0, 1, 0, 0, 2, 0, 2, 0, 1, 1, 1, 0, 0, 0, 2, 1, 1, 1, 0, 0, 2, 0, 2, 2, 2, 2, 1, 0, 1, 0, 1, 2, 1, 0, 2, 1, 1, 2, 0, 2, 1, 0, 2, 1, 2, 0, 1, 0, 0, 2, 1, 2, 1, 0, 1, 0, 0, 0, 1, 1, 2, 1, 2, 1, 1, 1, 2, 0, 2, 0, 2, 1, 0, 0, 2, 0, 0, 2, 1, 0, 0, 2, 1, 1, 2, 0, 2, 2, 2, 0, 1, 2, 2, 0, 0, 0, 2, 2, 0, 1, 2, 1, 2], dtype=int64) 以上proba_.argmax(axis = 1)的分类结果和模型预测的结果一致; ''' # 手动计算 # 定义线性函数 def linear(x): y = x.dot(w_.T)+b_ return y # 将的到的目标值转换成概率(同一组目标值内的概率和为1) def softmax(x): # 详细公式见下文 return np.e**x/((np.e**x).sum(axis=1).reshape(-1,1)) # reshape之后分母的形状由单独的一行,变成一列;变成一列之后回根据分子的形状由第一列进行广播(广播出来的列和原来的一列相同,只是为了对应分支的数据形状,方便进行运算) # 如果我只需要特定的行数,列数我无所谓多少,我只需要指定行数,列数用-1代替就行了,计算机帮我算应该有多少列,反之亦然。所以-1在这里应该可以理解为一个正整数通配符,它代替任何正整数。 y_pred = linear(X) y_pred = softmax(y_pred) y_pred[:10] ''' array([[2.42893049e-04, 1.62572543e-01, 8.37184564e-01], [9.76236359e-01, 2.37636218e-02, 1.93734447e-08], [1.02308731e-02, 7.50874989e-01, 2.38894138e-01], [6.22245105e-07, 2.13422648e-02, 9.78657113e-01], [8.71627591e-03, 7.74658724e-01, 2.16625000e-01], [5.07829679e-03, 9.20088614e-01, 7.48330891e-02], [9.84437320e-01, 1.55626715e-02, 8.01740090e-09], [9.85693639e-01, 1.43063452e-02, 1.55226004e-08], [9.96558465e-05, 1.20579040e-01, 8.79321304e-01], [2.39486316e-02, 9.59459247e-01, 1.65921216e-02]]) ''' # 得到的概率和模型计算的概率相同
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
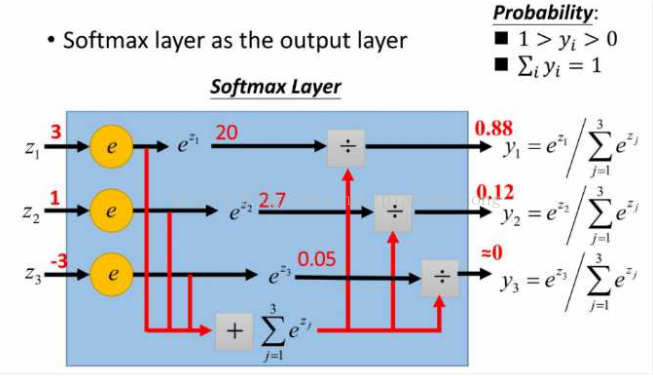
以上代码段中softmax(x)用到的公式:
softmax函数的计算原理 :
e
x
i
÷
∑
i
=
1
n
e
x
i
e^{x_i}\div\sum_{i=1}^n e^{x_i}
exi÷i=1∑nexi