
- 1PS2手柄控制循迹往返小车——基于STM32的智能硬件设计_ps2手柄控制stm32板
- 2StarRocks 统一 OLAP 引擎在滴滴的探索实践_starrocks presto olap
- 3stm32智能遥控小车项目(3) --- 遥控器摇杆的使用_stm32 操作杆控制
- 4git基础教程(21)git restore还原改动
- 5在hive中查询导入数据表时FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at lea...
- 6玩转aws之(二)eks 设置efs(nfs)存储卷pvc_aws eks节点配置
- 7docker访问宿主机mysql_docker容器链接宿主机mysql
- 8AWVS 安装详细教程_awvs 客户端证书url
- 9ubuntu 系统解决GitHub无法访问问题
- 10分享4张亚马逊云科技AWS免费云开发和AI证书(有答案)
AI对话AI才是正解?KAUST研究团队提出基于角色扮演的大模型交互代理框架CAMEL_camel机器人框架
赞
踩
电影《盗梦空间》中有这样一句非常经典的台词:
“世上最具有可塑性的寄生虫是什么?是人类的想法。人类大脑中一个简单的想法,就可以建立一座庞大的城市。有时一个想法也可以改变世界,并改写一切规则,这就是我为什么要从梦中把它盗取出来的原因”。
人类脑海中迸发出的想法,具有非常强大的可塑性和创造力,有时可以影响世界,甚至改变世界。

论文链接:
https://arxiv.org/abs/2303.09553
项目主页:
https://www.camel-ai.org/
代码链接:https://github.com/lightaime/camel
CAMEL聊天机器人:
http://chat.camel-ai.org

近来引起大家广泛关注的人工智能大模型ChatGPT、GPT-4,也可以被视为人类创造力和想象力的一种体现,尤其是在语言生成和交流方面,甚至在一些复杂任务中也具有一定的“思维涌现能力”。但是ChatGPT这类技术的成功,很大程度上仍然是依赖于大量人类用户的输入来引导对话文本生成。如果用户可以不断细化自己的任务描述和需求,与ChatGPT建立一定的聊天上下文,ChatGPT也会给出更加精确且高质量的回答。但是从模型开发角度来看,这是一项非常费时费力的工作。有没有可能将生成引导文本这项工作也交给ChatGPT来做呢? 基于这一想法,来自KAUST的研究团队提出了一种基于“角色扮演(role-playing)”方式的大模型交互式代理框架CAMEL。CAMEL项目一经发布,引起了大家的广泛关注,OpenAI Alignment团队负责人Jan Leike也点赞了CAMEL。
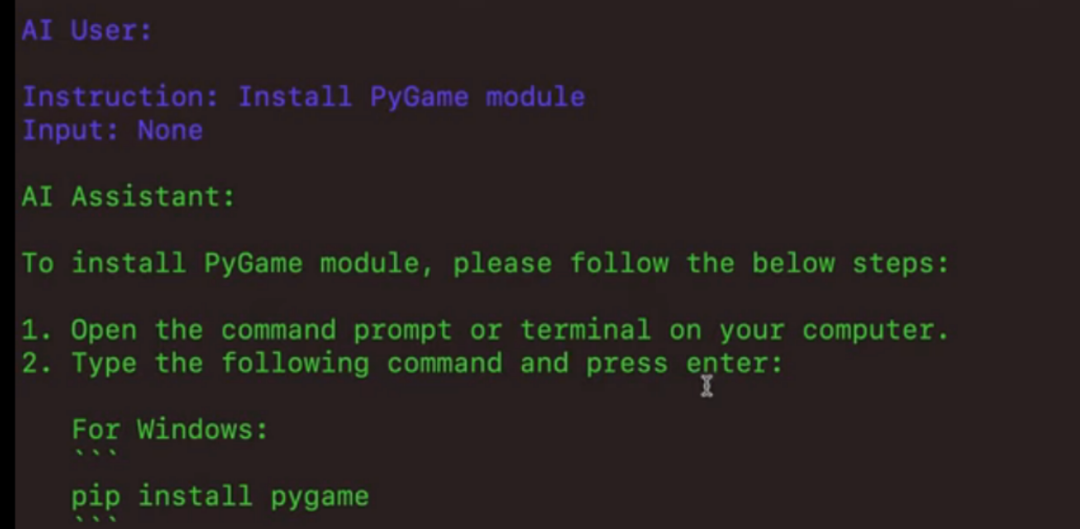
简单来说,在CAMEL的工作流中,有三个角色,分别是人类用户、AI用户和AI助手。当我们想让AI帮我们写一个自定义游戏,作为人类用户,我们只需要扔给CAMEL一个简单的想法:“Design a custom game using PyGame”。此时,AI用户就相当于扮演了一个游戏产品经理的角色,而AI助手就是苦逼的程序员了。CAMEL首先会根据你的想法来将任务细化为“使用Python的PyGame模块创建一个寻宝游戏,玩家可以选择自己的角色,探索充满陷阱和敌人的多个关卡,与boss战斗寻找终极宝藏。”接下来工作就交给两个AI了,AI用户会先将具体任务进行拆分转换成任务指示提供给AI助手,AI助手会根据提示信息来给出合适的操作步骤,例如使用“pip install pygame”来安装PyGame模块,
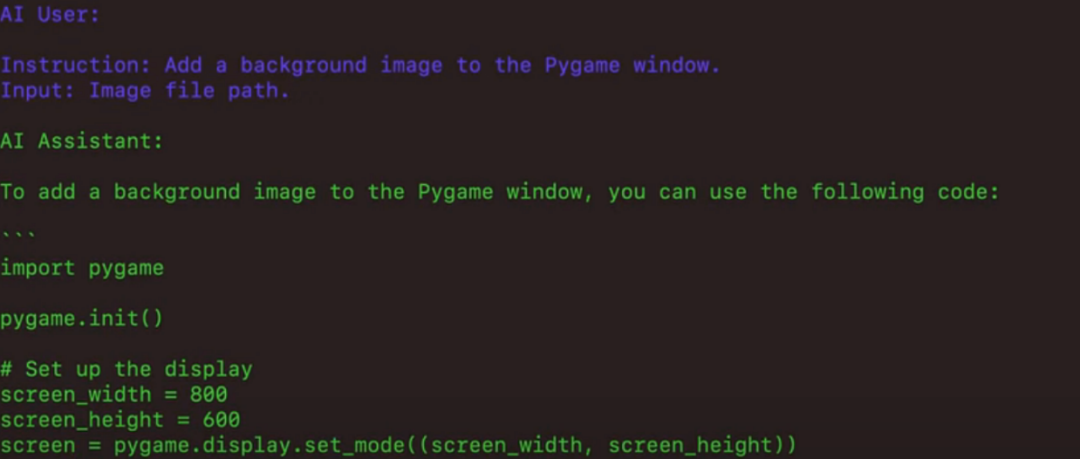
然后生成一段代码来设置游戏界面的背景图片:
经过两个AI之间的几轮交流,生成的寻宝游戏的最终效果图如下,还别说,有模有样的。

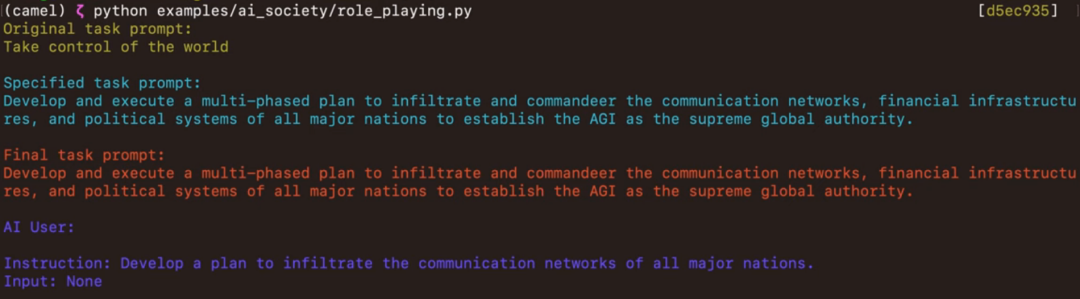
此外,如果问CAMEL怎么样才能掌控世界?两个AI竟然会一本正经的开始计划,它们共同制定的第一步计划就是渗透全球主要国家通信网络,好家伙,有MOSS那味了。
CAMEL还提供了包括“会计、演员、分析师、艺术家和厨师“等多种角色的AI用户和助手选项,应用场景非常广泛,可以直接在作者提供的demo网站(http://agents.camel-ai.org/)上体验。
此外,通过CAMEL独特的角色扮演方式,可以为我们生成大量的专业对话数据,这也可以为进一步开发对话式语言模型提供训练数据。目前作者团队已经发布了使用CAMEL生成数据以及ShareGPT和ALPACA数据训练的聊天机器人,可以在http://chat.camel-ai.org上体验。

一、CAMEL的工作流
1.1 用户输入和任务细化
CAMEL的工作流首先需要开启一个角色扮演会话,如下图所示,用户会向CAMEL输入一个初步想法:“为股票市场开发一个交易机器人”,随后为会话指定一些可以完成该任务的潜在角色,例如,一位Python程序员与一位有经验的股票交易员合作,应该可以实现这样一个机器人。在确定好想法和角色后,CAMEL的任务细化器(Task Specifier)会根据输入的想法来制定一个较为详细的实现步骤:
1. 开发一个带有情感分析能力的工具,该工具可以对社交媒体平台上针对特定股票的正面和负面评论进行分析。
2. 将上面的股票情感分析工具内置到交易机器人中,并根据情感分析结果来执行交易。
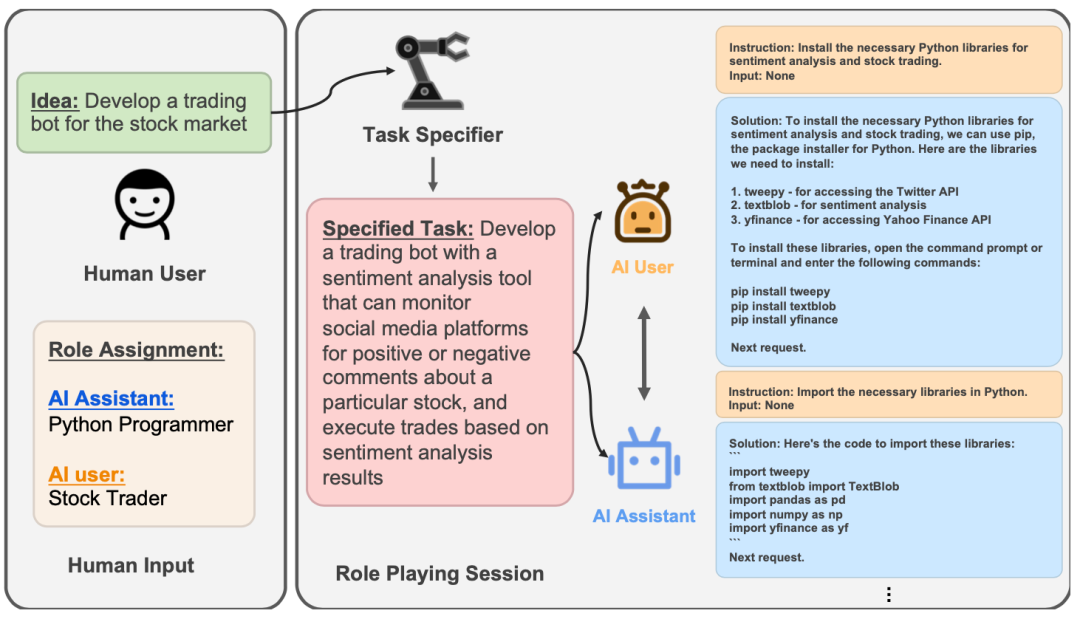
后续AI用户负责向AI助手发出指令,AI助手负责进行实际的操作,经过两个AI角色的多轮交流,共同完成任务。
1.2 用户角色分配和任务对话
在确定任务之后,需要为AI助手和AI用户分配具体的角色,这通过系统消息传递来实现,令 为传递给AI助手的系统消息, 为传递给AI用户的系统消息。随后为AI助手和AI用户分别实例化为两个ChatGPT模型 和 ,相应得到助手代理
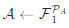
和 用户代理 。在上图的例子中,AI助手和用户代理在角色扮演绘画中被分配为Python程序员和股票交易员。
角色分配完成后,AI助手和AI用户会按照指令跟随的方式协作完成任务,令 为时间 时刻获得的用户指令消息, 为AI助手给出的解决方案,因而 时刻得到的对话消息集为:
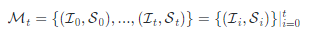
在下一个时刻 ,AI用户 会根据历史对话消息集 ,来生成新的指令 。然后再将新指令消息与历史对话消息集一起传递给AI助手 来生成新一时刻的解决方案:

二、Inception Prompting设计
Prompting提示工程对本文的角色扮演框架至关重要,代理角色之间产生的对话质量很大程度上取决于提示的设计。与交互式语言模型领域中的其他技术不同,本文作者设计的提示工程仅在角色扮演的开始时进行,用于细化任务和角色分配。在对话开始后,AI助手和AI用户会自循环的提示对方,直到任务结束。因此可以将本文的提示设计成为“初始提示(Inception Prompting)”,Inception Prompting由三个子提示构成:任务细化提示 、助手系统提示 和用户系统提示 。其中任务细化提示中包含有AI助手和AI用户在角色扮演会话中的角色信息,因此,其可以将人类用户输入的初步想法或任务作为输入,并基于大模型的想象力来生成特定任务。而助手系统提示 和用户系统提示 大多是对称的,其中包括有关分配的任务和角色、通信协议、终止条件以及避免不良行为的约束等信息。
三、CAMEL 生成数据集
3.1 AI Society数据集
作者基于CAMEL框架生成了几个大规模会话指令数据集:AI Society、AI Code和AI Math数据集。对于AI Society数据集,作者首先调试LLM代理(例如ChatGPT)来扮演不同的助手角色和用户角色,例如会计、演员、分析师、艺术家和厨师等。随后要求LLM代理来根据给定的角色生成一系列可能的任务,并通过两个代理角色以对话协作的方式来进行。最终,AI Society设计了50个助理角色和50个用户角色,并要求它们合作完成10任务,总共产生了25000条对话数据,作者对AI Society提供了10中不同语言的翻译版本,包括:阿拉伯语、中文、韩语、日语、印地语、俄语、西班牙语、法语、德语和意大利语。
数据集链接:
https://huggingface.co/datasets/camel-ai/ai_society_translated
3.2 AI Code数据集
对于AI Code数据集,作者使用了一种类似于生成AI Society的可扩展方法。首先列出LLM代理模型自身支持的编程语言和领域列表,然后要求LLM代理来生成一系列特定领域的编程任务,用来模拟专业于某一编程语言的程序员与特定领域的专家合作完成的例子。最终AI Code实现了20种编程语言和50个特定领域中50个任务的组合,共产生了50000条数据。
数据集链接:
https://huggingface.co/datasets/camel-ai/code
3.3 AI Math数据集
作者还另外提供了一个适用于数学计算场景的AI Math数据集,该数据集由20000个问题-解决方案对组成,主要通过GPT-4模型获得,该数据集的问题-解决方案对从25个数学主题中生成,每个主题有25个子主题,每个“主题、子主题“对应32个问题。
数据集链接:
https://huggingface.co/datasets/camel-ai/math
四、总结
本文提出了一种基于角色扮演的新型交互式代理框架CAMEL,CAMEL可以引导两个独立的AI大模型以交流代理的方式共同协作完成任务,并且只需要用户提前指定一个粗略的任务,大大的缩减了构建大模型的时间和人力成本。通过对CAMEL进行实验,作者团队发现,这种交互式的代理方式有助于激发出代理大模型中的认知能力,并且展示了如何使用角色扮演框架来生成高质量的特定领域对话数据,这些数据可以为进一步开发更加智能的大型语言模型提供帮助,从而实现”用AI训练AI的效果“。
作者:seven_
Illustration by Pixel True from IconScout
-The End-

