
- 1Jmeter性能测试 -3数据驱动实战_jmeter的多线程及数据驱动
- 2vue使用iframe标签预览本地pdf文档_ifream预览选中的文件
- 3ChatGPT写作提示词指令大全_chatgpt4.0写电视剧点评指令
- 4各类国外热门网站的镜像网站汇总_油管镜像网站
- 5开发知识点-JAVA-Jeecgboot_jeecg-boot/sys/ng-alain/getdictitemsbytable/'%20fr
- 6借助 Keras 3 轻松上手 Gemma 模型
- 7一文搞懂NLP框架之RNN、LSTM、Transformer结构原理!_lstm的工作原理
- 8windows环境下安装RabbitMQ
- 9NEO4J全文检索架构_neo4j-elasticsearch
- 10如何写一篇综述论文、浅谈_如果让你写一篇综述论文,该如何入手
【python学习笔记】Sklearn库的应用
赞
踩
一、sklearn库
Scikit-learn(简称sklearn)是一个用于机器学习的Python库。
二、机器学习的基本流程:
(一) 机器学习的4个基本步骤:
- 数据预处理:数据的归一化、标准化、缺失值处理和特征提取等
- 模型选择和训练:使用收集到的数据对模型进行训练,常用的模型有:knn、决策树、线性回归等
- 模型评估:评估所使用的模型的表现
- 模型部署和优化:将模型部署到实际应用中
(二)sklearn在机器学习中的应用流程(通过实例进行学习)
- 数据集划分:
常用函数:train_test_split()
- # 2数据集划分
- X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_stae=42)
2.模型选择以及(训练模型)投喂模型:方法.fit() —— knn为例
- from sklearn.neighbors import KNeighborsClassifier
-
- # 3模型选择,常用的有knn、决策树、线性回归等方法
- knn = KNeighborsClassifier()
-
- # 4投喂数据
- knn.fit(X_train, Y_train)
3 预测模型:方法.predict()
knn分类算法
- # 5预测数据
- data = pd.DataFrame()
- data['True_label'] = Y_test
- data['Prediction'] = knn.predict(X_test)
线性回归算法
- from sklearn.linear_model import LinearRegression
- lr = LinearRegression()
SVM分类方法
- from sklearn.svm import SVC
- classifier = SVC()
4 模型评估:
- from sklearn.metrics import classification_report
-
- # 6模型评估__包含了
- print(classification_report(data['True_label'], data['Prediction']))
完整代码如下:
- import pandas as pd
- from sklearn import datasets
- from sklearn.model_selection import train_test_split
- from sklearn.neighbors import KNeighborsClassifier
- from sklearn.metrics import classification_report
-
- # 1数据准备
- iris = datasets.load_iris()
- iris_X = iris.data
- iris_Y = iris.target
- iris_data = pd.DataFrame(iris.data, columns=['花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度'])
- iris_data['种类'] = iris.target
- iris_data.to_excel('鸢尾花数据集.xlsx', index=None)
- iris = pd.read_excel('鸢尾花数据集.xlsx')
- X = iris[['花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度']]
- Y = iris['种类']
-
- # 2数据集划分
- X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_stae=42)
-
- # 3模型选择,常用的有knn、决策树、线性回归等方法
- knn = KNeighborsClassifier()
-
- # 4投喂数据
- knn.fit(X_train, Y_train)
-
- # 5预测数据
- data = pd.DataFrame()
- data['True_label'] = Y_test
- data['Prediction'] = knn.predict(X_test)
-
- # 6模型评估__包含了
- print(classification_report(data['True_label'], data['Prediction']))

(三)sklearn数据预处理的方法
- sklearn.preprocessing:数据预处理模块
- sklearn.impute:缺失值的填充
- 统一步骤:
1 实例化:确定使用的方法
2拟合转换数据 fit_transform
1.数据归一化和标准化:
归一化和标准化的具体区别:
(1)归一化是将样本的特征值转换到同一量纲下把数据映射到[0,1]或者[-1, 1]区间内,仅由变量的极值决定,因区间放缩法是归一化的一种。而标准化是依照特征矩阵的列处理数据,其通过求z-score的方法,转换为标准正态分布,和整体样本分布相关,每个样本点都能对标准化产生影响。
(2)从输出范围角度来看, 归一化的输出结果必须在 0-1 间。而标准化的输出范围不受限制。通常情况下在机器学习中,标准化是更常用的手段,归一化的应用场景是有限的。标准化更好保持了样本间距,且更符合统计学假设。
归一化和标准化的相同点:
它们的相同点在于都能取消由于量纲不同引起的误差;都是一种线性变换,都是对向量X按照比例压缩再进行平移。
2.数据归一化和标准化的方法及应用:
- Z-score标准化:
- Max-Min归一化:
- MaxAbs标准化:
- from sklearn import preprocessing
-
- zscore = preprocessing.StandardScaler()#设置Zscore标准化对象
- X_scaled=zscore.fit_transform((X_train))#数据标准化处理,fit是拟合,transform是变换
-
- minmax=preprocessing.MinMaxScaler()#设置MaxMin归一化对象
- X_scaled=minmax.fit_transform((X_train))#数据归一化处理
-
- maxabs=preprocessing.MaxAbsScaler()#设置MaxAbs归一化对象
- X_scaled=maxabs.fit_transform(X_train)#数据归一化处理
面对数值型数据,把数据统一标准非常重要,机器学习中需要用到归一化的算法有:
- 需要归一化:线性回归、knn、kmeans、支持向量机等,基于距离度量的算法,
- 不需要归一化:朴素贝叶斯、决策树、随机森林,基于概率进行计算,不依赖特征的距离或线性计算
2. 缺失值填充
- 查询字段是否有缺失值:data.info() __ 注意data需要是dataframe的格式
- 填充column:(保证数据是二维的)
- 可以进行中位数、均值、众数以及常数填充
- from sklearn.impute import SimpleImputer
-
- imp_mean = SimpleImputer()#实例化。默认均值填补
- imp_median = SimpleImputer(strategy="median")#用中位数填补
- imp_0 = SimpleImputer(strategy="constant",fill_value=0)#用0填补imp_mode=SimpleImpute(strategy="most_frequent")#众数填充
-
- #最后进行拟合变化:__.fit_transform()
-
- imp_mean = imp_mean .fit_transform()
- imp_median = imp_median .fit_transform()
- imp_0 = imp_0 .fit_transform()
- imp_mode=imp_mode.fit_transform()
补充:pandas和numpy也可以进行缺失值的填充以及删除
填充
- data1.loc[:,"Age"]=data1.loc[:,"Age"].fillna(data1.loc[:,"Age"].median())#使用中位数填充
- #.fillna 直接在DataFrame里进行填充
删除
- data1.dropna(axis=0,inplace=True)
- #参数inplace,为True表示在原数据集上进行修改,为False表示生成一个复制对象,不修改原数据,默认False
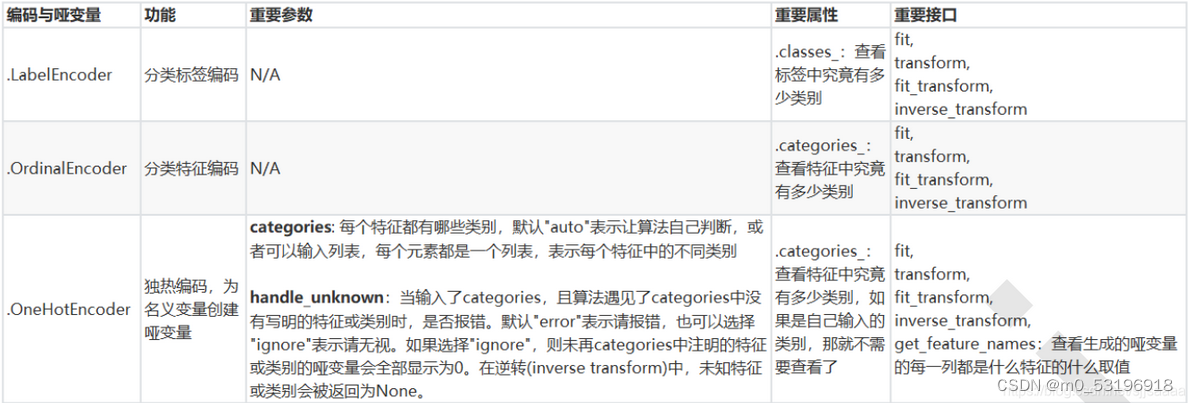
3.分类型特征:编码与哑变量
-
为什么要进行数据编码?
机器学习中的大多数算法是基于数值型数据,在fit的时候要求导入数组或矩阵,不能处理文字数据(sklearn中有专门用来处理文字的算法除外)。因此要对文字性数据进行编码,使用算法和库。
-
怎么进行编码呢?
1)对标签进行编码
- from sklearn.preprocessing import LableEncoder
-
-
- le=LableEncoder()#实例化
- num_label=le.fit_transform(data)#拟合转换数据
-
- text_label=le.inverse_transform(label)#逆转,变回原始标签
2)对分类特征进行编码
有序变量
将分类特征转换称为分类数值。
- from sklearn.preprocessing import OrdinalEncoder
-
- feature_encoder=OrdinalEncoder() #实例化
- data=feature_encoder.fit_transform(data)#拟合并转换
-
- #熟练之后可以写成:
- data=OrdinalEncoder().fit_transform(data)
哑变量:“有你就没有我”的不等概念 —— 独热编码
如性别,需要转换为哑变量。
- from sklearn.preprocessing import OneHotEncoder
-
- OneHotEncoder(categories="auto").fit_transform(X).toarray()#将结果转成数组,显示结果
-
- #inverte_transform()依旧可以还原数组
总结:分类标签编码、分类特征编码、独热编码
4.处理连续型特征:二值化与分段
(1)二值化
例如:将年龄特征,大于30岁以上的标为1,小于的标为0
- from sklearn.preprocessing import Binarizer
-
-
- transformer = Binarizer(threshold=30).fit_transform(x)#将30以上的化为1,30以下的化为0
先学这么多吧 学无止境~感觉sklearn才认识了个皮毛~~~~
学习来源:以下是我学习的两篇文章,结合起来对sklearn学习,代码小白学习数据分析的笔记心得,大神路过求指点,同道中人一块进步
sklearn学习,一步步带你做出三个入门案例鸢尾花分类、波士顿房价预测、手写数字识别,简单易懂。_基于scikit-learn库的分类算法做波士顿房价预测-CSDN博客


