
- 1mysql 创建学生表、课程表、学生选课表_学生表选课表课程表
- 2使用pandas的compare()方法做excel数据对比_pandas两个表格对比
- 3国内外大语言模型调研(更新到2023.09.12)_书生浦语内测
- 4【网安AIGC专题10.11】论文1:生成式模型GPT\CodeX填充式模型CodeT5\INCODER+大模型自动程序修复(生成整个修复函数、修复代码填充、单行代码生产、生成的修复代码排序和过滤)_codex+codet
- 5面试官问你MyBatis SQL是如何执行的?把这篇文章甩给他_mybatis实现了sql语句与代码分离
- 6LINUX【网络编程】UDP程序绑定发送主机IP及端口
- 7libVLC 提取视频帧使用QWidget渲染
- 84条出路,35岁高龄程序员也能实现职业发展与退休规划!_45岁程序员的出路
- 9网络安全应急响应有哪些相关知识?_网络安全灾难恢复是从损失中恢复,这种响应灾难的方式是主动还是被动
- 10文献速递:深度学习肝脏肿瘤诊断---基于深度学习的肝细胞结节性病变在整片组织病理图像上的分类
文本分析 ※文本转向量+TF-IDF提取关键词+cosine相似度计算+word2vec_tfidfvectorizer cosin similar
赞
踩
①文本转向量代码:
from collections import Counter import pandas as pd import jieba bag_of_words = [ ] text1 = "年少不知软饭香" text2 = "错把青春插稻秧" text =[text1, text2] for i in text: content = jieba.cut(i) bag_of_words.append(Counter(content)) # Counter的输入是一系列对象,对对象计数,返回一部字典 df_bows = pd.DataFrame.from_records(bag_of_words) # from_records的输入是一个字典的序列,为所有键构建列,值被加入到适合的表格中。 df_bows = df_bows.fillna(0).astype(int) print(df_bows) tf-idf构建向量 from sklearn.feature_extraction.text import TfidfVectorizer vectorizer = TfidfVectorizer(analyzer='word', max_features=4000, lowercase=False) vectorizer.fit(words)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
②统计 按需词频 (根据业务需求不同,统计条件不同)
具体情况:
文本单一词 在不同类型文本 出现次数和
-“我爱你 我爱你 我爱你” “我爱你”算一次
-“我爱你 我爱你 我爱你” “我爱你”算三次
文本单一词 出现总次数:
-“我爱你 我爱你 我爱你” 这句话出现40次 “我爱你”算(1*40)次
-“我爱你 我爱你 我爱你” 这句话出现40次 “我爱你”算(3*40)次
# 构建 统计字典 dict为在不同类型文本 出现次数和 dict2为出现总次数 dict={} dict2={} #遍历处理每一条数据 for i in range(len(data)): str=data.loc[i, "question"] #获取该条数据对应的文本 num=int(data.loc[i,"question_count"]) #获取该文本出现次数 lis=jieba.cut(str) #分词 word = [] for ii in lis: #算一次还是算三次的条件。算三次则无需加该判断 if ii not in word: word.append(ii) for i in range(len(word)): if dict.get(word[i]): dict[word[i]]+=1 else: dict[word[i]]=1 if dict2.get(word[i]): dict2[word[i]]+=num else: dict2[word[i]]=num #按照出现频次从大到小排列 d1 = zip(dict.values(), dict.keys()) print(sorted(d, reverse=True)) d2 = zip(dict2.values(), dict2.keys()) print(sorted(d2, reverse=True))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
③TF-IDF(Term Frequency-Inverse Document Frequency)提取关键词。
TF-IDF模型中
TF为词频 IDF为逆文档频率 计算公式:

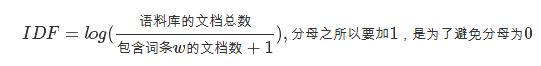
#引入包 import numpy as np import pandas as pd #定义数据和预处理 如果是中文句子则进行jieba分词 ③部分有 docA= "The cat sat on my bed" docB= "The dog sat on my knees" #词袋 bowA = docA.split(" ") bowB = docB.split(" ") wordSet = set(bowA).union(set(bowB)) #构建词库,统计 #进行次数统计,统计字典保存词出现的次数 wordDictA = dict.fromkeys(wordSet, 0) for word in bowA: wordDictA[word] += 1 wordDictB = dict.fromkeys(wordSet, 0) for word in bowB: wordDictB[word] += 1 pd.DataFrame([wordDictA,worldDictB]) #计算词频TF 传入参数:(统计好的字典,词袋) def computeTF (wordDict, bow): tfDict = {} nbowCount =len(bow) for word,count in wordDict.items(): tfDict[word] = count / nbowCount return tfDict #计算逆文档频率 def computeIDF(wordDictList): idfDict = dict.fromkeys(wordDictList[0], 0) N = len(wordDictList) import math for wordDict in wordDictList: #遍历字典中的每个词汇,统计Ni for word,count in worldDict.items(): if count>0: idfDict[word] +=1 for word, ni in idfDict.items(): idfDict[word] = math.log10((N+1)/(ni+1)) return idfDict #计算TF-IDF def computeTFIDF(tf, idf): tfidf={} for word,value in tf.items(): tfidf[word]=value*idf[word] return tfidf 使用: tfA=computeTF(wordDictA, bowA) #A的词频 idfs=computeIDF([wordDictA, wordDictB]) #逆文档频率 print(computeTFIDF(tfA, idfs)) #A的TFIDF列表
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
④cosine相似度判断函数:
余弦相似度的值越接近1,两个向量之间的夹角就越小
余弦相似度为0表示两个向量之间没有共享任何分量
示例:
import jieba 依赖包 可以切分中文关键词 #a, b为需要判断的两个字符串 def sim_compute(a, b): str1=jieba.cut(a) str2=jieba.cut(b) #分别将结果转存为两个列表 word1=[] word2=[] for i in str1: word1.append(i) for i in str2: word2.append(i) #合并word1与word2 word = set(word1) for value in word2: word.add(value) #初始化两个单词的向量并统计出现次数 word1_vec={} for value in word: word1_vec[value]=0 for value in word1: if word1_vec.get(value): word1_vec[value]+=1 else: word1_vec[value]=1 word2_vec={} for value in word: word2_vec[value]=0 for value in word2: if word2_vec.get(value): word2_vec[value]+=1 else: word2_vec[value]=1 #统计结果转化为向量 vec_1=[] vec_2=[] for i in word: vec_1.append(word1_vec[i]) vec_2.append(word2_vec[i]) #公式计算cosine相似度 sum = 0 sq1 = 0 sq2 = 0 for i in range(len(vec_1)): sum += vec_1[i] * vec_2[i] sq1 += pow(vec_1[i], 2) sq2 += pow(vec_2[i], 2) try: result = round(float(sum) / (math.sqrt(sq1) * math.sqrt(sq2)), 2) except ZeroDivisionError: result = 0.0 return result
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
简化:
import math
def cosine_sim(vec1, vec2):
vec1 = [val for val in vec1.values()]
vec2 = [val for val in vec2.values()]
dot_prod=0
for i, v in enumerate(vec1):
dot+prod += v*vec2[i]
mag_1 = math.sqrt(sum([x**2 for x in vec1]))
mag_2 = math.sqrt(sum([x**2 for x in vec2]))
return dot_prod / (mag_1 * mag_2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
调包:
a.dot(b) == np.linalg.norm(a) * np.linalg.norm(b) / np.cos(theta) 求解cos(theta)关系
- 1
⑤过滤停用词
#停用词表
stopwords=pd.read_csv("stopwords.txt", index_col=False, sep="\t", quoting=3,names=['stopword'])
def drop_stopwords(contents, stopwords):
contents_clean = []
all_words = []
for line in contents:
line_clean = []
for word in line:
if word in stopwords:
continue
line_clean.append(word)
all_words.append(str(word))
contents_clean.append(line_clean)
return contents_clean,all_words
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
齐普夫定律:任何一个词的频率与它在频率表的排名成反比。
关键词搜索:
query = "how long does it take to get to the store?" query_vec = copy.copy(zero_vector) tokens = tokenizer.tokenize(query.lower()) token_counts = Counter(tokens) for key, value in token_counts.items(): docs_containing = 0 for _doc in documents: if key in_doc.lower(): docs_containing_key += 1 #统计逆文档频数 if docs_containing_key==0: continue tf = value / len(tokens) #计算词频 idf = len(documents) / docs_containing_key query_vec[key] = tf*idf consine_sim(query_vec, document_tfidf_vector[0]) consine_sim(query_vec, document_tfidf_vector[1]) 自动化处理工具: from sklearn.feature_extraction.text import TdidfVectorizer corpus = docs vectorizer = TfidfVectorizer(min_df=1) model = vectorizer.fit_transform(corpus) print(model.todense().round(1)) #.todense方法将稀疏矩阵转换成常规的numpy矩阵。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
word2vec
输入词项的独热向量表示与权重的 点积 代表 词向量嵌入。
1.skip-gram方法
中心词预测周围词 如果使用skip-gram窗口大小为2来训练word2vec模型,则需要考虑每个目标词前后的两个词。
适应:小型语料库和一些罕见的词项比较适用。
2.CBOW
周围词预测中心词
计算技巧:
①高频2-gram:
②高频词条降采样:为了减少像停用词这样的高频词的影响,可以在训练过程中对词进行与其出现频率成反比的采样。
③负采样:只在输出向量中选取少量的负样本进行权重更新,而不去更新词窗口以外所有其他词的权重。
生成定制化词向量表示:
模型接收的输入是一个句子列表,其中每个句子切分为词条。
①预处理阶段
②训练面向特定领域的word2vec模型
#首先加载word2vec模块: from gensim.models.word2vec import Word2Vec
Word2vec模型训练参数:
num_features = 300 #向量元素的维度
min_word_count = 3 #模型中词的最低词频
num_workers = 2 #训练使用的cpu核数
windows = 6 #上下文窗口大小
subsampling = le-3 #高频词条降采样率
- 1
- 2
- 3
- 4
- 5
Word2vec模型实例化:
model = Word2Vec(token_list, workers=num_workers, size=num_features,
min_count=min_word_count, window=window_size, sample=subsampling)
model.init_sims(replace=True) #冻结模型,存储隐藏层的权重并丢弃用于预测共现词的输出权重。
#保存模型
model_name = "my_domain_specific"
model.save(model_name)
#加载保存的Word2vec模型
from gensim.models.word2vec import Word2Vec
model_name = "my_domain_specific_word2vec_model"
model = Word2Vec.load(model_name)
model.most_similar('radiology')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

