
- 1金融专业简历(通用18篇)
- 2Runtime Error可能产生的原因_c语言runtime error
- 3开源免费的多数据库客户端智慧工具_chat2db
- 4vivado HLS学习之数据类型使用_ap_int
- 5流程图步骤条
- 6eclipse合并git分支_eclipse git merge一个commit
- 7【Nacos】Nacos原理与实战_nacos 核心原理解读+高性能微服务系统实战
- 8Java-CSS 盒子模型(Box Model)_用java代码绘制盒子
- 9Codeup(云效)手把手教部署SpringCloud项目到私有主机_如何把项目部署到私网
- 10主机发现和端口扫描的基本原理和端口扫描_如何探测访问控制规则
使用ocr识别的具体步骤(详细)
赞
踩
ocr识别 我们这里使用的是GitHub上面提供的一个ocr的识别(只要识别的是营养成分)
首先我们在训练之前需要做的事情 需要准备营养成分表(需要完整一些的),其次需要准备 python环境 下面我会附加一条链接告诉需要下载的东西。
https://github.com/wanghaisheng/awesome-ocr/wiki/Extracting-text-from-an-image-using-Ocropus-%E4%B8%AD%E6%96%87
ocr识别的大致步骤可以分为三个步 首先是将图片进行一个二值化处理,简单的说就是让图片的可读性更强一点。第二步就是将图片里面的一些成分含量进行一个分段 截取 ,然后会生成对象的txt,因为这里面可能会包含中文 默认是识别不了中文的 所以这个时候 我们就需要把带有中文的图片给转换一个(步骤:将对象生成的txt文件,复制,粘贴,然后重命名为后缀名为.gt.txt的文本,然后在将没有对应txt的图片给删除了,到这里还没有全部完成 ,我们还需要修改ocropy-->ocropy-1.3.3/ocrolib/chars.py 如图):
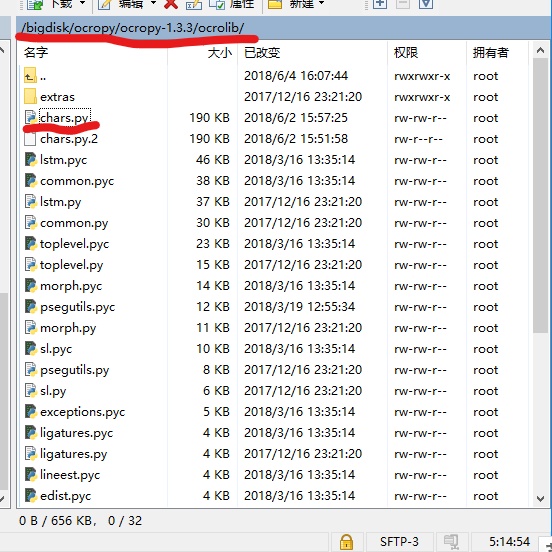
然后打开这个文件去把我们上面.gt.txt里面的内容全部都写到Chinese里面去(记住是全部的.gt.txt都要放入)如图:

第三步就是进行识别。下面附上代码

nohup python -u ocropus-rtrain --load food2-00000100.pyrnn.gz -o food2 food2/0001/*.bin.png 这一命令是当我们训练终止的时候,我们修改完错误 以后可以接着上面的模型继续进行训练
上面是训练模型 下面这一些是识别模型(xx:表示图片名称)
图片预处理,生成bin.png rnm.png
1:python ocropus-nlbin -n test/xx.jpg -o food
图片分割 生成0001目录 里面存放切割好的图片
2:python ocropus-gpageseg -n --maxcolseps 0 food/0001.bin.png
识别切割后的图片 并在0001目录生成识别结果文件,结果文件名:图片名.txt
3:python ocropus-rpred -m en-default.pyrnn.gz food/0001/*.png
然后我们打开分割后生成的txt文件和图片进行对比 即可

