
- 1Android里面,button按钮怎么设置圆角?_android button圆角
- 259、服务攻防——中间件安全&CVE复现&IIS&Apache&Tomcat&Nginx
- 3Win11电脑重装系统后,安装或重装Microsoft office办公软件_重装系统后装office
- 4EasyExcel导入导出的数据格式转换_java easyexcel导入转化excel是否的中文为01数字
- 5docker 服务器挂掉Error: OCI runtime error: container_linux.go:345: starting container process caused “err_oci runtime exec failed: exec failed: container_li
- 6网格搜索多个监督学习模型上的超参数,包括神经网络、随机森林和树集合模型(Matlab代码实现)_matlab神经网络交叉验证超参数
- 7Thinstation搭建以及编译镜像---心得
- 8黑马Hive+Spark离线数仓工业项目-服务器性能监控Prometheus_hive prometheus
- 9transformers理论解释_transformer和transformers 区别
- 10如何将本地项目上传至Gitee仓库(详细教程)_将项目上传到gitee
布隆过滤器(Bloom Filter)详解,以及Java代码实现_java guava bloomfilter 和实体
赞
踩
基本概念
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
Google爬虫 它要判断。哪些网页是被爬过来了的。
如果想要判断一个元素是不是在一个集合里,一般想到的是将所有元素保存起来,然后通过比较确定。链表,树等等数据结构都是这种思路. 但是随着集合中元素的增加,我们需要的存储空间越来越大,检索速度也越来越慢(O(n),O(logn))。不过世界上还有一种叫作散列表(又叫哈希表,Hash table)的数据结构(有一个动态数组,+ 一个hash函数)。它可以通过一个Hash函数将一个元素映射成一个位阵列(Bit array)中的一个点。这样一来,我们只要看看这个点是不是1就可以知道集合中有没有它了。这就是布隆过滤器的基本思想。
Hash面临的问题就是冲突。假设Hash函数是良好的,如果我们的位阵列长度为m个点,那么如果我们想将冲突率降低到例如 1%, 这个散列表就只能容纳m / 100个元素。显然这就不叫空间效率了(Space-efficient)了。解决方法也简单,就是使用多个Hash,如果它们有一个说元素不在集合中,那肯定就不在。如果它们都说在,虽然也有一定可能性它们在说谎,不过直觉上判断这种事情的概率是比较低的。Bloom Filter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,BloomFilter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
总结起来说:bloomfilter,布隆过滤器:迅速判断一个元素是不是在一个庞大的集合内,但是他有一个弱点:它有一定的误判率
误判率:原本不存在于该集合的元素,布隆过滤器有可能会判断说它存在,但是,如果布隆过滤器判断说某一个元素不存在该集合,那么该元素就一定不在该集合内。
优缺点
优点
- 时间复杂度低,增加和查询元素的时间复杂为O(N),(N为哈希函数的个数,通常情况比较小)
- 保密性强,布隆过滤器不存储元素本身
- 存储空间小,如果允许存在一定的误判,布隆过滤器是非常节省空间的(相比其他数据结构如Set集合)
缺点
- 有点一定的误判率,但是可以通过调整参数来降低
- 无法获取元素本身
- 很难删除元素
实现原理
布隆过滤器需要的是一个位数组(和位图类似, bytes数组)和K个映射函数(和Hash表类似),在初始状态时,对于长度为m的位数组array,它的所有位被置0。
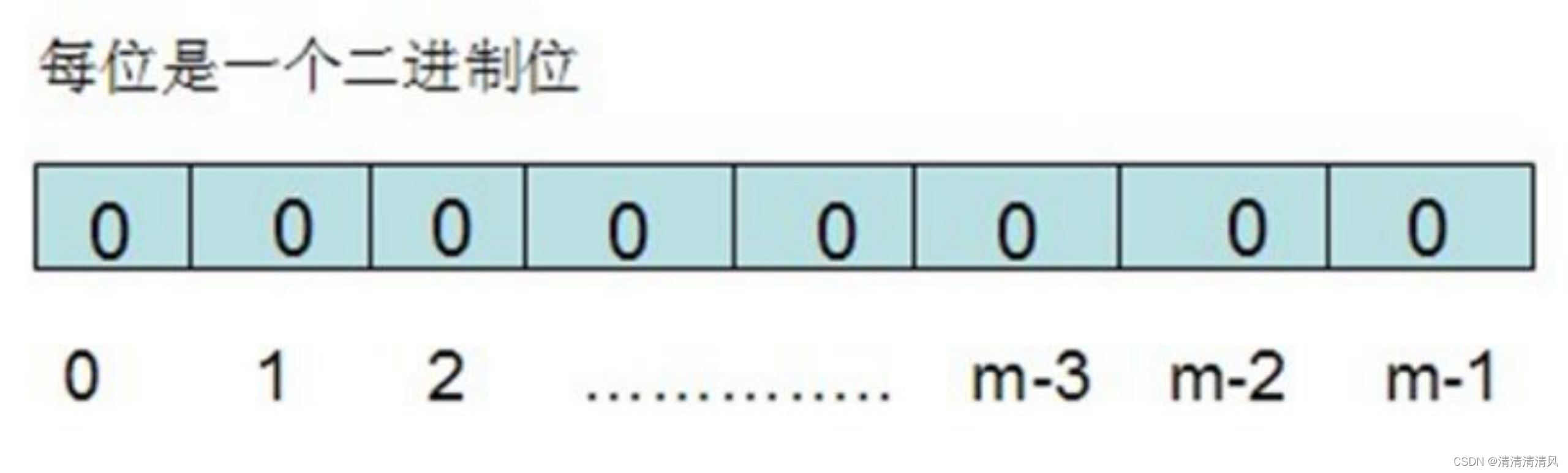
当要向布隆过滤器增加元素时:
对于有n个元素的集合S={S1,S2…Sn},通过k个映射函数{f1,f2,…fk},将集合S中的每个元素Sj(1<=j<=n)映射为K个值{g1,g2…gk},然后再将位数组array中相对应的array[g1],array[g2]…array[gk]置为1。
当要向布隆过滤器查询某个元素是否存在时:
要查找某个元素item是否在S中,则通过映射函数{f1,f2,…fk}得到k个值{g1,g2…gk},然后再判断array[g1],array[g2]…array[gk]是否都为1,若全为1,则item在S中,否则item不在S中。
布隆过滤器会造成一定的误判,因为集合中的若干个元素通过映射之后得到的数值恰巧包括g1,g2,…gk,在这种情况下可能会造成误判,但是概率很小。
误判率分析
在布隆过滤器增加元素之前,首先需要初始化布隆过滤器的空间,也就是上面说的二进制数组,除此之外还需要计算无偏hash函数的个数。布隆过滤器提供了两个参数,分别是预计加入元素的大小n,运行的错误率f。布隆过滤器中有算法根据这两个参数会计算出二进制数组的大小l,以及无偏hash函数的个数k。
它们之间的关系比较简单:
错误率越低,位数组越长,控件占用较大
错误率越低,无偏hash函数越多,计算耗时较长
推荐一个免费的在线布隆过滤器在线计算的网址:

Hash函数/哈希表
概念
哈希表中元素是由哈希函数确定的。将数据元素的关键字K作为自变量,通过一定的函数关系(称为哈希函数),计算出的值,即为该元素的存储地址,也即一个元素在哈希表中的位置是由哈希函数决定的。
特点
- 如果两个散列值是不相同的(根据同一函数),那么这两个散列值的原始输入也是不相同的。
- 散列函数的输入和输出不是唯一对应关系的,如果两个散列值相同,两个输入值很可能是相同的。但也可能不同,这种情况称为 “散列碰撞”(或者 “散列冲突”)。
Hash构造函数
- 直接定址法
- 数字分析法
- 平方取中法
- 折叠法
- 除留余数法
- 随机数法
解决Hash碰撞
- 拉链法
拉出一个动态链表代替静态顺序存储结构,可以避免哈希函数的冲突,不过缺点就是链表的设计过于麻烦,增加了编程复杂度。此法可以完全避免哈希函数的冲突。 - 多哈希法
设计二种甚至多种哈希函数,可以避免冲突,但是冲突几率还是有的,函数设计的越好或越多都可以将几率降到最低(除非人品太差,否则几乎不可能冲突)。 - 开放地址法
开放地址法有一个公式:Hi=(H(key)+di) MOD m i=1,2,…,k(k<=m-1)
其中,m为哈希表的表长。di 是产生冲突的时候的增量序列。如果di值可能为1,2,3,…m-1,称线性探测再散列。
如果di取1,则每次冲突之后,向后移动1个位置.如果di取值可能为1,-1,4,-4,9,-9,16,-16,…kk,-kk(k<=m/2)
称二次探测再散列。如果di取值可能为伪随机数列。称伪随机探测再散列。
4、 建域法
假设哈希函数的值域为[0,m-1],则设向量HashTable[0…m-1]为基本表,另外设立存储空间向量OverTable[0…v]用以存储发生冲突的记录。
Java实现Bloom Filter
各位,用chatGPT生成的简单DEMO,方便理解,哈哈。
import java.util.BitSet; import java.util.Random; public class BloomFilter { private BitSet filter; private int size; private int hashFunctions; private Random random; /** * 构造函数,初始化布隆过滤器 * @param size 布隆过滤器的大小 * @param hashFunctions 布隆过滤器使用的哈希函数数量 */ public BloomFilter(int size, int hashFunctions) { this.filter = new BitSet(size); this.size = size; this.hashFunctions = hashFunctions; this.random = new Random(); } /** * 添加元素到布隆过滤器 * @param element 要添加的元素 */ public void addElement(String element) { for (int i = 0; i < this.hashFunctions; i++) { int hash = Math.abs((element + i).hashCode() % this.size); this.filter.set(hash, true); } } /** * 检查元素是否存在于布隆过滤器 * @param element 要检查的元素 * @return 如果元素可能存在于布隆过滤器中,则返回 true,否则返回 false */ public boolean checkElement(String element) { for (int i = 0; i < this.hashFunctions; i++) { int hash = Math.abs((element + i).hashCode() % this.size); if (!this.filter.get(hash)) { return false; } } return true; } /** * 生成一个随机字符串 * @param length 字符串的长度 * @return 随机字符串 */ public static String generateRandomString(int length) { StringBuilder builder = new StringBuilder(); Random random = new Random(); for (int i = 0; i < length; i++) { builder.append((char) ('a' + random.nextInt(26))); } return builder.toString(); } /** * 测试布隆过滤器 * @param args 命令行参数 */ public static void main(String[] args) { int size = 1000000; int hashFunctions = 5; BloomFilter filter = new BloomFilter(size, hashFunctions); // 添加一些随机字符串到布隆过滤器 for (int i = 0; i < 10000; i++) { filter.addElement(generateRandomString(10)); } // 检查一些随机字符串是否在布隆过滤器中 for (int i = 0; i < 100; i++) { String randomString = generateRandomString(10); if (filter.checkElement(randomString)) { System.out.println(randomString + " may be in the filter."); } else { System.out.println(randomString + " is not in the filter."); } } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
开源实现Guava BloomFilter
goole在Guava框架中直接实现了Bloom Filter,使得我们不用再根据Bloom Filter的原理自行实现。
创建Bloom Filter
Bloom Filter提供了四个静态的create方法来创造实例:
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, int expectedInsertions, double fpp);
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions, double fpp);
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, int expectedInsertions);
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions);
- 1
- 2
- 3
- 4
上述四种方式中都调用了一个统一的create方法:
static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions, double fpp, Strategy strategy);
// 参数含义:
// funnel 指定布隆过滤器中存的是什么类型的数据,有:IntegerFunnel,LongFunnel,StringCharsetFunnel。
// expectedInsertions 预期需要存储的数据量
// fpp 误判率,默认是 0.03。
- 1
- 2
- 3
- 4
- 5
Bloom Filter中的数组空间大小、hash函数的个数都由参数expectedInsertions 、fdd共同确定:
long numBits = optimalNumOfBits(expectedInsertions, fpp);
static long optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
static int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int)Math.round((double)m / (double)n * Math.log(2.0D)));
}
- 1
- 2
- 3
- 4
使用
Bloom Filter中包含put、mightContain方法,添加元素和判断元素是否存在。
filter.put(value);
filter.mightContain(value);
- 1
- 2
google直接给我们提供一个现成的bloom Filter,直接包含了数组长度和hash函数个数的确定方法,进而免去了构造Bloom Filter时我们自己不好确定的两个参数。
最后把guava的maven依赖如下,可自行选择版本:
<!-- https://mvnrepository.com/artifact/com.google.guava/guava -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>xxx</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6


