
- 1首起针对国内金融企业的开源组件投毒攻击事件_组件投毒 数据库
- 2项目体检(Health Check)升级上线
- 3Mac系统安装及配置python_macbook如何安装python2
- 4python读程序写结果-31.Python:文件读写
- 5Git+TortoiseGit详细安装教程(HTTP方式)_tortoisegit http
- 6Python的日志输出_python日志输出到文件
- 7Springboot+Vue项目-基于Java+MySQL的图书馆管理系统(附源码+演示视频+LW)
- 8阅读小车循迹论文笔记:灰度传感器、仿生处理器、路径跟踪机制()_灰度传感器原理图
- 9SIDE:开启研发新的颠覆式的开发体验
- 10Flask-SQLAlchemy的使用(详解)_flask sqlalchemy options
自己整理博哥爱运维0817-----k8s集成GitLib流水线_博哥爱运维 今日头条
赞
踩
#视频来源---今日头条博哥爱运维视频----受益良多
第3关 二进制高可用安装k8s生产级集群*
1.每个节点安装ansible-----centos
yum install ansible -y yum install -y git
2.node01下载安装脚本:
如果在这里面不好复杂的话,可以直接到我的github仓库里面下载这个脚本,地址: git clone https://github.com/bogeit/LearnK8s.git
3.进入目录、执行脚本格式
sh k8s_install_new.sh Tb123456 172.24.75 149\ 155\ 152\ 154\ 150\ 151\ 148\ 153 docker calico test
4.如果遇到error,别灰心,一直执行、多执行几次下面的命令,因为在github网络超时很常见
./ezdown -D
5.下载好了在继续执行
sh k8s_install_new.sh Tb123456 172.24.75 119\ 118\ 117\ 115\ 116\ 114 docker calico test
6.安装完成后重新加载下环境变量以实现kubectl命令补齐
# 安装完成后重新加载下环境变量以实现kubectl命令补齐 . ~/.bashrc
7.查看所有pods状态:
kubectl get pods -A
第4关 K8s最得意的小弟Docker
Dockerfile:
1.python--dockerfile格式
FROM python:3.7-slim-stretch
MAINTAINER boge <netsos@qq.com>
WORKDIR /app
COPY requirements.txt .
RUN sed -i 's/deb.debian.org/ftp.cn.debian.org/g' /etc/apt/sources.list \
&& sed -i 's/security.debian.org/ftp.cn.debian.org/g' /etc/apt/sources.list \
&& apt-get update -y \
&& apt-get install -y wget gcc libsm6 libxext6 libglib2.0-0 libxrender1 git vim \
&& apt-get clean && apt-get autoremove -y && rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir -i https://mirrors.aliyun.com/pypi/simple -r requirements.txt \
&& rm requirements.txt
COPY . .
EXPOSE 5000
HEALTHCHECK CMD curl --fail http://localhost:5000 || exit 1
ENTRYPOINT ["gunicorn", "app:app", "-c", "gunicorn_config.py"]
2.golang--dockerfile格式
# stage 1: build src code to binary
FROM golang:1.13-alpine3.10 as builder
MAINTAINER boge <netsos@qq.com>
ENV GOPROXY https://goproxy.cn
# ENV GO111MODULE on
COPY *.go /app/
RUN cd /app && CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build -ldflags "-s -w" -o hellogo .
# stage 2: use alpine as base image
FROM alpine:3.10
RUN sed -i 's/dl-cdn.alpinelinux.org/mirrors.aliyun.com/g' /etc/apk/repositories && \
apk update && \
apk --no-cache add tzdata ca-certificates && \
cp -f /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \
# apk del tzdata && \
rm -rf /var/cache/apk/*
COPY --from=builder /app/hellogo /hellogo
CMD ["/hellogo"]
3.nodejs格式
FROM node:12.6.0-alpine
MAINTAINER boge <netsos@qq.com>
WORKDIR /app
COPY package.json .
RUN sed -i 's/dl-cdn.alpinelinux.org/mirrors.aliyun.com/g' /etc/apk/repositories && \
apk update && \
yarn config set registry https://registry.npm.taobao.org && \
yarn install
RUN yarn build
COPY . .
EXPOSE 6868
ENTRYPOINT ["yarn", "start"]
4.java--dockerfile格式 FROM maven:3.6.3-adoptopenjdk-8 as target ENV MAVEN_HOME /usr/share/maven ENV PATH $MAVEN_HOME/bin:$PATH COPY settings.xml /usr/share/maven/conf/ WORKDIR /build COPY pom.xml . RUN mvn dependency:go-offline # use docker cache COPY src/ /build/src/ RUN mvn clean package -Dmaven.test.skip=true FROM java:8 WORKDIR /app RUN rm /etc/localtime && cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime COPY --from=target /build/target/*.jar /app/app.jar EXPOSE 8080 ENTRYPOINT ["java","-Xmx768m","-Xms256m","-Djava.security.egd=file:/dev/./urandom","-jar","/app/app.jar"]
5.docker的整个生命周期展示 docker login "仓库地址" -u "仓库用户名" -p "仓库密码" docker pull "仓库地址"/"仓库命名空间"/"镜像名称":latest || true docker build --network host --build-arg PYPI_IP="xx.xx.xx.xx" --cache-from "仓库地址"/"仓库命名空间"/"镜像名称":latest --tag "仓库地址"/"仓库命名空间"/"镜像名称":"镜像版本号" --tag "仓库地址"/"仓库命名空间"/"镜像名称":latest . docker push "仓库地址"/"仓库命名空间"/"镜像名称":"镜像版本号" docker push "仓库地址"/"仓库命名空间"/"镜像名称":latest # 基于redis的镜像运行一个docker实例 docker run --name myredis --net host -d redis:6.0.2-alpine3.11 redis-server --requirepass boGe666
6.dockerfile实战 我这里将上面的flask和golang项目上传到了网盘,地址如下 https://cloud.189.cn/t/M36fYrIrEbui (访问码:hy47) # 解压 unzip docker-file.zip # 先打包python项目的镜像并运行测试 cd python docker build -t python/flask:v0.0.1 . docker run -d -p 80:5000 python/flask:v0.0.1 # 再打包golang项目的镜像并运行测试 docker build -t boge/golang:v0.0.1 . docker run -d -p80:3000 boge/golang:v0.0.1
第5关 K8s攻克作战攻略之一
善用-h命令!!!
第3关我们以二进制的形式部署好了一套K8S集群,现在我们就来会会K8S吧
1.生产中的小技巧:k8s删除namespaces状态一直为terminating问题处理、执行下面脚本
2.执行格式bash 1.sh kubevirt(namespace名字)
#!/bin/bash
set -eo pipefail
die() { echo "$*" 1>&2 ; exit 1; }
need() {
which "$1" &>/dev/null || die "Binary '$1' is missing but required"
}
# checking pre-reqs
need "jq"
need "curl"
need "kubectl"
PROJECT="$1"
shift
test -n "$PROJECT" || die "Missing arguments: kill-ns <namespace>"
kubectl proxy &>/dev/null &
PROXY_PID=$!
killproxy () {
kill $PROXY_PID
}
trap killproxy EXIT
sleep 1 # give the proxy a second
kubectl get namespace "$PROJECT" -o json | jq 'del(.spec.finalizers[] | select("kubernetes"))' | curl -s -k -H "Content-Type: application/json" -X PUT -o /dev/null --data-binary @- http://localhost:8001/api/v1/namespaces/$PROJECT/finalize && echo "Killed namespace: $PROJECT"
Pod
1.擅用-h 帮助参数 kubectl run -h kubectl get pod -w -o wide 查看pod详细信息
2.进入容器内部 kubectl -it exec nginx -- sh
3.查看pod详细信息、可以用来排错 kubectl describe pod nginx
4.查看可用镜像版本:生产小技巧 来源cat /opt/kube/bin/docker-tag 先source加载一下,docker+双按tab+tab source ~/.bashrc 用法:docker-tag tags nginx
第5关 K8s攻克作战攻略之二-Deployment
Deployment扩容以及回滚
善用-h
1.善用-h kubectl create deployment -h kubectl create deployment nginx --image=nginx 2.查看创建结果: kubectl get deployments.apps 3.看下自动关联创建的副本集replicaset--- kubectl get rs 4.扩容pod的数量、善用-h kubectl scale -h kubectl scale deployment nginx --replicas=2 5.查看pod在哪里运行、pod状态等 kubectl get pod -o wide 6.善用--record、对版本回滚很重要! kubectl set image deployment/nginx nginx=nginx:1.9.9 --record # 升级nginx的版本 # kubectl set image deployments/nginx nginx=nginx:1.19.5 --record 7.查看历史版本、回归依据 # kubectl rollout history deployment nginx deployment.apps/nginx REVISION CHANGE-CAUSE 1 <none> 2 kubectl set image deployments/nginx nginx=nginx:1.9.9 --record=true 3 kubectl set image deployments/nginx nginx=nginx:1.19.5 --record=true 8.回滚到特定版本 kubectl rollout undo deployment nginx --to-revision=2 查看版本历史 kubectl rollout history deployment nginx
补充 1.禁止pod调度到该节点上 kubectl cordon 2.驱逐该节点上的所有pod kubectl drain
生成yaml文件的方法: kubectl create deployment nginx --image=nginx --dry-run -o yaml > nginx.yaml
第5关 K8s攻克作战攻略之三-服务pod的健康检测
大家好,我是博哥爱运维,这节课内容给大家讲解下在K8S上,我们如果对我们的业务服务进行健康检测。
Liveness
#继续接受文件尝试重新创建---外部访问可能回404
#例子:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness
spec:
restartPolicy: OnFailure
containers:
- name: liveness
image: busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600
livenessProbe:
#readinessProbe: # 这里将livenessProbe换成readinessProbe即可,其它配置都一样
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 10 # 容器启动 10 秒之后开始检测
periodSeconds: 5 # 每隔 5 秒再检测一次
Readiness
一般用这个探针比较多,**Readiness**将容器设置为不可用 配置和上面一样见上面注释:在containers:后面加存活探针readinessProbe: **Readiness**的特点不在接受服务,不在导入流量到pod内 两者可以同时使用:可以单独使用,也可以同时使用
接下来我们详细分析下滚动更新的原理,为什么上面服务新版本创建的pod数量是7个,同时只销毁了3个旧版本的pod呢?
我们不显式配置这段的话,默认值均是25%
strategy:
rollingUpdate:
maxSurge: 35%
maxUnavailable: 35%
#按正常的生产处理流程,在获取足够的新版本错误信息提交给开发分析后,我们可以通过kubectl rollout undo 来回滚到上一个正常的服务版本: #查看历史版本: kubectl rollout history deployment mytest #回滚到特定版本 kubectl rollout undo deployment mytest --to-revision=1
第5关 k8s架构师课程攻克作战攻略之四-Service
这节课内容给大家讲解下在K8S上如何来使用service做内部服务pod的流量负载均衡。
pod的IP每次重启都会发生改变,所以我们不应该期望K8s的pod是健壮的
并且流量入口这块用一个能固定IP的service来充当抽象的内部负载均衡器,提供pod的访问
1.创建一个svc来暴露deploy---nginx端口,会生成svc
kubectl expose deployment nginx --port=80 --target-port=80 --dry-run=client -o yaml
2.查看svc
kubectl get svc
看下自动关联生成的endpoint
kubectl get endpoints nginx
3.测试下svc的负载均衡效果
分别进入几个容器内部修改nginx主页文件---如果没有多个nginx自己扩容下deploy善用-h指令
# kubectl exec -it nginx-6799fc88d8-2kgn8 -- bash
root@nginx-f89759699-bzwd2:/# echo nginx-6799fc88d8-2kgn8 > /usr/share/nginx/html/index.html
4.测试svc的负载均衡效果
查看SVC
kubectl get svc
访问svc发现每次返回都不一样,达到负载均衡
curl 10.68.121.237
5.提供外网访问,外部访问:
kubectl patch svc nginx -p '{"spec":{"type":"NodePort"}}'
查看NodePort端口
kubectl get svc
尝试访问访问
nginx NodePort 10.68.121.237 <none> 80:32012/TCP 12m app=nginx
查看看下kube-proxy的配置 cat /etc/systemd/system/kube-proxy.service cat /var/lib/kube-proxy/kube-proxy-config.yaml 查看ipvs的虚拟网卡:ip addr |grep ipv 查看lvs都武器列表:ipvsadm -ln 可以看见ipvs的轮询策略 [Service] WorkingDirectory=/var/lib/kube-proxy ExecStart=/opt/kube/bin/kube-proxy \ --bind-address=10.0.1.202 \ --cluster-cidr=172.20.0.0/16 \ --hostname-override=10.0.1.202 \ --kubeconfig=/etc/kubernetes/kube-proxy.kubeconfig \ --logtostderr=true \ --proxy-mode=ipvs
还可以用K8s的DNS来访问、除了直接用cluster ip,以及上面说到的NodePort模式来访问Service,我们还可以用K8s的DNS来访问 我们前面装好的CoreDNS,来提供K8s集群的内部DNS访问 查看一下coreDNS kubectl -n kube-system get deployment,pod|grep dns serviceName.namespaceName coredns是一个DNS服务器,每当有新的Service被创建的时候,coredns就会添加该Service的DNS记录,然后我们通过serviceName.namespaceName就可以来访问到对应的pod了,下面来演示下: 它可以从容器内部ping外部的svc [root@node01 LearnK8s]# kubectl run -it --rm busybox --image=busybox -- sh If you don't see a command prompt, try pressing enter. / # ping nginx.default ##default可以省略 PING nginx.default (10.68.121.237): 56 data bytes 64 bytes from 10.68.121.237: seq=0 ttl=64 time=0.041 ms 64 bytes from 10.68.121.237: seq=1 ttl=64 time=0.074 ms
service生产小技巧 通过svc来访问非K8s上的服务
创建service后,会自动创建对应的endpoint\\\也可以手动创建endpoint
在生产中,我们可以通过创建不带selector的Service,然后创建同样名称的endpoint,来关联K8s集群以外的服务
我们可以直接复用K8s上的ingress(这个后面会讲到,现在我们就当它是一个nginx代理),来访问K8s集群以外的服务,省去了自己搭建前面Nginx代理服务器的麻烦
开始实践测试
这里我们挑选node-2节点,用python运行一个简易web服务器
[root@node-2 mnt]# python -m SimpleHTTPServer 9999
Serving HTTP on 0.0.0.0 port 9999 ...
在node01上配置svc和endpoints
注意Service和Endpoints的名称必须一致
# 注意我这里把两个资源的yaml写在一个文件内,在实际生产中,我们经常会这么做,方便对一个服务的所有资源进行统一管理,不同资源之间用"---"来分隔
apiVersion: v1
kind: Service
metadata:
name: mysvc
namespace: default
spec:
type: ClusterIP
ports:
- port: 80
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
name: mysvc
namespace: default
subsets:
- addresses:
#启动测试服务的节点,我这里是node2
- ip: 172.24.75.118
nodeName: 172.24.75.118
ports:
- port: 9999
protocol: TCP
开始创建并测试: # kubectl apply -f mysvc.yaml service/mysvc created endpoints/mysvc created # kubectl get svc,endpoints |grep mysvc service/mysvc ClusterIP 10.68.71.166 <none> 80/TCP 14s endpoints/mysvc 10.0.1.202:9999 14s # curl 10.68.71.166 mysvc # 我们回到node-2节点上,可以看到有一条刚才的访问日志打印出来了 10.0.1.201 - - [25/Nov/2020 14:42:45] "GET / HTTP/1.1" 200 - #也可以修改yaml文件外网访问加端口查看结果 查看nodeport端口范围 cat /etc/systemd/system/kube-apiserver.service|grep service #--service-node-port-range=30000-32767 \
service生产调优:
kubectl patch svc nginx -p '{"spec":{"externalTrafficPolicy":"Local"}}'
service/nginx patched
现在通过非pod所在node节点的IP来访问是不通了
通过所在node的IP发起请求正常
可以看到日志显示的来源IP就是201,这才是我们想要的结果
# 去掉这个优化配置也很简单
# kubectl patch svc nginx -p '{"spec":{"externalTrafficPolicy":""}}'
第6关 k8s架构师课程之流量入口Ingress上部
大家好,这节课带来k8s的流量入口ingres\本课程带给大家的都是基于生产中实战经验,所以这里我们用的ingress-nginx不是普通的社区版本,而是经过了超大生产流量检验,国内最大的云平台阿里云基于社区版分支出来,进行了魔改而成,更符合生产,基本属于开箱即用,下面是aliyun-ingress-controller的介绍:
下面介绍只截取了最新的一部分,更多文档资源可以查阅官档: K8S Ingress Controller 发布公告-阿里云开发者社区
如果不支持配置动态更新,对于在高频率变化的场景下,Nginx频繁Reload会带来较明显的请求访问问题:
-
造成一定的QPS抖动和访问失败情况
-
对于长连接服务会被频繁断掉
-
造成大量的处于shutting down的Nginx Worker进程,进而引起内存膨胀
-
详细原理分析见这篇文章: 通过阿里云K8S Ingress Controller实现路由配置的动态更新-阿里云开发者社区
生产中在用的yaml配置:
aliyun-ingress-nginx.yaml kubectl apply -f aliyun-ingress-nginx.yaml #配置见下一个文件 我们查看下pod,会发现空空如也,为什么会这样呢? kubectl -n ingress-nginx get pod kind: DaemonSet 注意yaml配置里面DaemonSet的配置,我使用了节点选择配置,只有打了我指定lable标签的node节点,也会被允许调度pod上去运行、需要的标签是 boge/ingress-controller-ready=true 打标签的方法: 在哪个节点打标签、就会在哪个节点运行ds(Daemonset)、 Daemonset的特点是在每个Node上只能运行一个: kubectl label node 172.24.75.119 boge/ingress-controller-ready=true kubectl label node 172.24.75.118 boge/ingress-controller-ready=true ...你可以把每个node都打上标签、不想用标签你可以注释掉自己的nodeSelctor 打完标签、接着可以看到pod就被调到这两台node上启动了 尝试注释掉aliyun-ingress-nginx.yaml的节点选择、会发现每个节点就会自动生成一个ds、 #nodeSelector: # boge/ingress-controller-ready: "true" 查看ds kubectl get ds -n ingress-nginx
如果是自建机房,我们通常会在至少2台node节点上运行有ingress-nginx的pod\\\ 也就是说会生成多个nginx-ingress-controller 不妨注释掉nodeSelector: 让每个节点自动生成nginx-ingress-controller kubectl get ds -n ingress-nginx nginx-ingress-controller 6
#我们准备来部署aliyun-ingress-controller,下面直接是生产中在用的yaml配置,我们保存了aliyun-ingress-nginx.yaml准备开始部署:详细讲解下面yaml配置的每个部分
apiVersion: v1
kind: Namespace
metadata:
name: ingress-nginx
labels:
app: ingress-nginx
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: nginx-ingress-controller
namespace: ingress-nginx
labels:
app: ingress-nginx
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: nginx-ingress-controller
labels:
app: ingress-nginx
rules:
- apiGroups:
- ""
resources:
- configmaps
- endpoints
- nodes
- pods
- secrets
- namespaces
- services
verbs:
- get
- list
- watch
- apiGroups:
- "extensions"
- "networking.k8s.io"
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- events
verbs:
- create
- patch
- apiGroups:
- "extensions"
- "networking.k8s.io"
resources:
- ingresses/status
verbs:
- update
- apiGroups:
- ""
resources:
- configmaps
verbs:
- create
- apiGroups:
- ""
resources:
- configmaps
resourceNames:
- "ingress-controller-leader-nginx"
verbs:
- get
- update
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: nginx-ingress-controller
labels:
app: ingress-nginx
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: nginx-ingress-controller
subjects:
- kind: ServiceAccount
name: nginx-ingress-controller
namespace: ingress-nginx
---
apiVersion: v1
kind: Service
metadata:
labels:
app: ingress-nginx
name: nginx-ingress-lb
namespace: ingress-nginx
spec:
# DaemonSet need:
# ----------------
type: ClusterIP
# ----------------
# Deployment need:
# ----------------
# type: NodePort
# ----------------
ports:
- name: http
port: 80
targetPort: 80
protocol: TCP
- name: https
port: 443
targetPort: 443
protocol: TCP
- name: metrics
port: 10254
protocol: TCP
targetPort: 10254
selector:
app: ingress-nginx
---
kind: ConfigMap
apiVersion: v1
metadata:
name: nginx-configuration
namespace: ingress-nginx
labels:
app: ingress-nginx
data:
keep-alive: "75"
keep-alive-requests: "100"
upstream-keepalive-connections: "10000"
upstream-keepalive-requests: "100"
upstream-keepalive-timeout: "60"
allow-backend-server-header: "true"
enable-underscores-in-headers: "true"
generate-request-id: "true"
http-redirect-code: "301"
ignore-invalid-headers: "true"
log-format-upstream: '{"@timestamp": "$time_iso8601","remote_addr": "$remote_addr","x-forward-for": "$proxy_add_x_forwarded_for","request_id": "$req_id","remote_user": "$remote_user","bytes_sent": $bytes_sent,"request_time": $request_time,"status": $status,"vhost": "$host","request_proto": "$server_protocol","path": "$uri","request_query": "$args","request_length": $request_length,"duration": $request_time,"method": "$request_method","http_referrer": "$http_referer","http_user_agent": "$http_user_agent","upstream-sever":"$proxy_upstream_name","proxy_alternative_upstream_name":"$proxy_alternative_upstream_name","upstream_addr":"$upstream_addr","upstream_response_length":$upstream_response_length,"upstream_response_time":$upstream_response_time,"upstream_status":$upstream_status}'
max-worker-connections: "65536"
worker-processes: "2"
proxy-body-size: 20m
proxy-connect-timeout: "10"
proxy_next_upstream: error timeout http_502
reuse-port: "true"
server-tokens: "false"
ssl-ciphers: ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-DSS-AES128-SHA256:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:AES:CAMELLIA:DES-CBC3-SHA:!aNULL:!eNULL:!EXPORT:!DES:!RC4:!MD5:!PSK:!aECDH:!EDH-DSS-DES-CBC3-SHA:!EDH-RSA-DES-CBC3-SHA:!KRB5-DES-CBC3-SHA
ssl-protocols: TLSv1 TLSv1.1 TLSv1.2
ssl-redirect: "false"
worker-cpu-affinity: auto
---
kind: ConfigMap
apiVersion: v1
metadata:
name: tcp-services
namespace: ingress-nginx
labels:
app: ingress-nginx
---
kind: ConfigMap
apiVersion: v1
metadata:
name: udp-services
namespace: ingress-nginx
labels:
app: ingress-nginx
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nginx-ingress-controller
namespace: ingress-nginx
labels:
app: ingress-nginx
annotations:
component.version: "v0.30.0"
component.revision: "v1"
spec:
# Deployment need:
# ----------------
# replicas: 1
# ----------------
selector:
matchLabels:
app: ingress-nginx
template:
metadata:
labels:
app: ingress-nginx
annotations:
prometheus.io/port: "10254"
prometheus.io/scrape: "true"
scheduler.alpha.kubernetes.io/critical-pod: ""
spec:
# DaemonSet need:
# ----------------
hostNetwork: true
# ----------------
serviceAccountName: nginx-ingress-controller
priorityClassName: system-node-critical
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- ingress-nginx
topologyKey: kubernetes.io/hostname
weight: 100
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: type
operator: NotIn
values:
- virtual-kubelet
containers:
- name: nginx-ingress-controller
image: registry.cn-beijing.aliyuncs.com/acs/aliyun-ingress-controller:v0.30.0.2-9597b3685-aliyun
args:
- /nginx-ingress-controller
- --configmap=$(POD_NAMESPACE)/nginx-configuration
- --tcp-services-configmap=$(POD_NAMESPACE)/tcp-services
- --udp-services-configmap=$(POD_NAMESPACE)/udp-services
- --publish-service=$(POD_NAMESPACE)/nginx-ingress-lb
- --annotations-prefix=nginx.ingress.kubernetes.io
- --enable-dynamic-certificates=true
- --v=2
securityContext:
allowPrivilegeEscalation: true
capabilities:
drop:
- ALL
add:
- NET_BIND_SERVICE
runAsUser: 101
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
ports:
- name: http
containerPort: 80
- name: https
containerPort: 443
livenessProbe:
failureThreshold: 3
httpGet:
path: /healthz
port: 10254
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 10
readinessProbe:
failureThreshold: 3
httpGet:
path: /healthz
port: 10254
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 10
# resources:
# limits:
# cpu: "1"
# memory: 2Gi
# requests:
# cpu: "1"
# memory: 2Gi
volumeMounts:
- mountPath: /etc/localtime
name: localtime
readOnly: true
volumes:
- name: localtime
hostPath:
path: /etc/localtime
type: File
nodeSelector:
boge/ingress-controller-ready: "true"
tolerations:
- operator: Exists
initContainers:
- command:
- /bin/sh
- -c
- |
mount -o remount rw /proc/sys
sysctl -w net.core.somaxconn=65535
sysctl -w net.ipv4.ip_local_port_range="1024 65535"
sysctl -w fs.file-max=1048576
sysctl -w fs.inotify.max_user_instances=16384
sysctl -w fs.inotify.max_user_watches=524288
sysctl -w fs.inotify.max_queued_events=16384
image: registry.cn-beijing.aliyuncs.com/acs/busybox:v1.29.2
imagePullPolicy: Always
name: init-sysctl
securityContext:
privileged: true
procMount: Default
---
## Deployment need for aliyun'k8s:
#apiVersion: v1
#kind: Service
#metadata:
# annotations:
# service.beta.kubernetes.io/alibaba-cloud-loadbalancer-id: "lb-xxxxxxxxxxxxxxxxxxx"
# service.beta.kubernetes.io/alibaba-cloud-loadbalancer-force-override-listeners: "true"
# labels:
# app: nginx-ingress-lb
# name: nginx-ingress-lb-local
# namespace: ingress-nginx
#spec:
# externalTrafficPolicy: Local
# ports:
# - name: http
# port: 80
# protocol: TCP
# targetPort: 80
# - name: https
# port: 443
# protocol: TCP
# targetPort: 443
# selector:
# app: ingress-nginx
# type: LoadBalancer
先部署aliyun-ingress-controller才能部署下面的一对测试
我们基于前面学到的deployment和service,来创建一个nginx的相应服务资源,保存为nginx.yaml:
注意:记得把前面测试的资源删除掉,以防冲突
生成文件后执行kubectl apply -f nginx.yaml文件内容如下:
apiVersion: v1
kind: Service
metadata:
labels:
app: nginx
name: nginx
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: nginx
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx # Deployment 如何跟 Service 关联的????
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
然后准备nginx的ingress配置,保留为nginx-ingress.yaml,并执行它:
kubectl apply -f nginx-ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: nginx-ingress
spec:
rules:
- host: nginx.boge.com
http:
paths:
- backend:
serviceName: nginx # 与service做关联????
servicePort: 80
path: /
我们在其它节点上,加下本地hosts,来测试下效果 echo "172.24.75.119 nginx.boge.com" >> /etc/hosts 可以多在几个节点上添加尝试通过ingress访问 curl nginx.boge.com 回到主节点上,看下ingress-nginx的日志、这里要注意你pod运行的node来找pod kubectl get pods -n ingress-nginx -o wide 多节点通过curl访问以后、可以看到访问日志 kubectl -n ingress-nginx logs --tail=2 nginx-ingress-controller-5lntz -o wide
如果是自建机房,我们通常会在至少2台node节点上运行有ingress-nginx的pod\ 一般两台也够了 那么有必要在这两台node上面部署负载均衡软件做调度,来起到高可用的作用,这里我们用haproxy+keepalived,如果你的生产环境是在云上,假设是阿里云,那么你只需要购买一个负载均衡器SLB\ 将运行有ingress-nginx的pod的节点服务器加到这个SLB的后端来,然后将请求域名和这个SLB的公网IP做好解析即可, 注意在每台node节点上有已经部署有了个haproxy软件,来转发apiserver的请求的,那么,我们只需要选取两台节点,部署keepalived软件并重新配置haproxy,来生成**VIP**达到ha的效果,这里我们选择在其中两台node节点(172.24.75.118、117)上部署
查看node上现在已有的haproxy配置:
这个配置在worker节点node3\4\5才有。在master是没有的
cat /etc/haproxy/haproxy.cfg
开始新增ingress端口的转发,修改haproxy配置如下(注意两台节点都记得修改):
vim /etc/haproxy/haproxy.cfg
在最后加
listen ingress-http
bind 0.0.0.0:80
mode tcp
option tcplog
option dontlognull
option dontlog-normal
balance roundrobin
server 172.24.75.117 172.24.75.117:80 check inter 2000 fall 2 rise 2 weight 1
server 172.24.75.118 172.24.75.118:80 check inter 2000 fall 2 rise 2 weight 1
server 172.24.75.119 172.24.75.119:80 check inter 2000 fall 2 rise 2 weight 1
listen ingress-https
bind 0.0.0.0:443
mode tcp
option tcplog
option dontlognull
option dontlog-normal
balance roundrobin
server 172.24.75.117 172.24.75.117:443 check inter 2000 fall 2 rise 2 weight 1
server 172.24.75.118 172.24.75.118:443 check inter 2000 fall 2 rise 2 weight 1
server 172.24.75.119 172.24.75.119:443 check inter 2000 fall 2 rise 2 weight 1
配置完后重启服务
systemctl restart haproxy.service
然后在两台node上分别安装keepalived并进行配置:
yum install -y keepalived
ip r 查看网卡接口 可能是eth0也可能是ens32,是哪个就写哪个
生成vip漂移
修改keepalived配置文件
vi /etc/keepalived/keepalived.conf
全部删除、在重新加上下面的、注意修改***eth0或者ens32*** ip r 查看网卡
注意改成自己的node IP
三个node的keepalive都要改、IP记得轮流换、在哪个机上unicast_src_ip就写哪个机的内网、交换
所以下面的配置三个机上都要换unicast_src_ip和unicast_peer
配置完成后重启keepalive
systemctl restart haproxy.service
systemctl restart keepalived.service
配置完成后查看VIP正在哪个node上:
ip a |grep 222
看到这次VIP 222在node04上
换一个node节点(worker)测试
将VIP和域名写入hosts
echo "172.24.75.222 nginx.boge.com" >> /etc/hosts
global_defs {
router_id lb-master
}
vrrp_script check-haproxy {
script "killall -0 haproxy"
interval 5
weight -60
}
vrrp_instance VI-kube-master {
state MASTER
priority 120
unicast_src_ip 172.24.75.115
unicast_peer {
172.24.75.116
172.24.75.114
}
dont_track_primary
interface eth0 # 注意这里的网卡名称修改成你机器真实的内网网卡名称,可用命令ip addr查看
virtual_router_id 111
advert_int 3
track_script {
check-haproxy
}
virtual_ipaddress {
172.24.75.222
}
}
因为http属于是明文传输数据不安全,在生产中我们通常会配置https加密通信,现在实战下Ingress的tls配置
# 这里我先自签一个https的证书
#1. 先生成私钥key
openssl genrsa -out tls.key 2048
#2.再基于key生成tls证书(注意:这里我用的*.boge.com,这是生成泛域名的证书,后面所有新增加的三级域名都是可以用这个证书的)
openssl req -new -x509 -key tls.key -out tls.cert -days 360 -subj /CN=*.boge.com
# 在K8s上创建tls的secret(注意默认ns是default)
kubectl create secret tls mytls --cert=tls.cert --key=tls.key
# 然后修改先的ingress的yaml配置
# cat nginx-ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/rewrite-target: / # 注意这里需要把进来到服务的请求重定向到/,这个和传统的nginx配置是一样的,不配会404
name: nginx-ingress
spec:
rules:
- host: nginx.boge.com
http:
paths:
- backend:
serviceName: nginx
servicePort: 80
path: /nginx # 注意这里的路由名称要是唯一的
- backend: # 从这里开始是新增加的
serviceName: web
servicePort: 80
path: /web # 注意这里的路由名称要是唯一的
tls: # 增加下面这段,注意缩进格式
- hosts:
- nginx.boge.com # 这里域名和上面的对应
secretName: mytls # 这是我先生成的secret
# 进行更新
# kubectl apply -f nginx-ingress.yaml
第7关 k8s架构师课程之HPA 自动水平伸缩pod
HPA
我们在生产中通常用得最多的就是基于服务pod的cpu使用率metrics来自动扩容pod数量,下面来以生产的标准来实战测试下(注意:使用HPA前我们要确保K8s集群的dns服务和metrics服务是正常运行的,并且我们所创建的服务需要配置指标分配)
# pod内资源分配的配置格式如下:
# 默认可以只配置requests,但根据生产中的经验,建议把limits资源限制也加上,因为对K8s来说,只有这两个都配置了且配置的值都要一样,这个pod资源的优先级才是最高的,在node资源不够的情况下,首先是把没有任何资源分配配置的pod资源给干掉,其次是只配置了requests的,最后才是两个都配置的情况,仔细品品
resources:
limits: # 限制单个pod最多能使用1核(1000m 毫核)cpu以及2G内存
cpu: "1"
memory: 2Gi
requests: # 保证这个pod初始就能分配这么多资源
cpu: "1"
memory: 2Gi
我们先不做上面配置的改动,看看直接创建hpa会产生什么情况: 为deployment资源web创建hpa,pod数量上限3个,最低1个,在pod平均CPU达到50%后开始扩容 kubectl autoscale deployment web --max=3 --min=1 --cpu-percent=50
编辑配置vi web.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx
name: nginx
resources:
limits: # 因为我这里是测试环境,所以这里CPU只分配50毫核(0.05核CPU)和20M的内存
cpu: "50m"
memory: 20Mi
requests: # 保证这个pod初始就能分配这么多资源
cpu: "50m"
memory: 20Mi
自动扩容 kubectl autoscale deployment web --max=3 --min=1 --cpu-percent=50 # 等待一会,可以看到相关的hpa信息(K8s上metrics服务收集所有pod资源的时间间隔大概在60s的时间) # kubectl get hpa -w # 我们启动一个临时pod,来模拟大量请求 # kubectl run -it --rm busybox --image=busybox -- sh / # while :;do wget -q -O- http://web;done # kubectl get hpa -w 看到自动扩容了
第8关 k8s架构师课程之持久化存储第一节
大家好,我是博哥爱运维,K8s是如何来管理存储资源的呢?跟着博哥来会会它们吧!
Volume
emptyDir
我们先开始讲讲emptyDir,生产中它的最实际实用是提供Pod内多容器的volume数据共享
emptyDir的使用示例
# 我们继续用上面的web服务的配置,在里面新增volume配置
# cat web.yaml
kubectl apply -f web.yaml
kubectl get svc
# 可以看到每次访问都是被写入当前最新时间的页面内容
[root@node-1 ~]# curl 10.68.229.231
# cat web.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx
name: nginx
resources:
limits:
cpu: "50m"
memory: 20Mi
requests:
cpu: "50m"
memory: 20Mi
volumeMounts: # 准备将pod的目录进行卷挂载
- name: html-files # 自定个名称,容器内可以类似这样挂载多个卷
mountPath: "/usr/share/nginx/html"
- name: busybox # 在pod内再跑一个容器,每秒把当时时间写到nginx默认页面上
image: busybox
args:
- /bin/sh
- -c
- >
while :; do
if [ -f /html/index.html ];then
echo "[$(date +%F\ %T)] hello" > /html/index.html
sleep 1
else
touch /html/index.html
fi
done
volumeMounts:
- name: html-files # 注意这里的名称和上面nginx容器保持一样,这样才能相互进行访问
mountPath: "/html" # 将数据挂载到当前这个容器的这个目录下
volumes:
- name: html-files # 最后定义这个卷的名称也保持和上面一样
emptyDir: # 这就是使用emptyDir卷类型了
medium: Memory # 这里将文件写入内存中保存,这样速度会很快,配置为medium: "" 就是代表默认的使用本地磁盘空间来进行存储
sizeLimit: 10Mi # 因为内存比较珍贵,注意限制使用大小
第8关 k8s架构师课程之持久化存储第二节PV和PVC
大家好,我是博哥爱运维\\有了pvc,我们在K8s进行卷挂载就只需要考虑要多少容量了,而不用关心真正的空间是用什么存储系统做的等一些底层细节信息,pv这些只有存储管理员才应用去关心它。
K8s支持多种类型的pv,我们这里就以生产中常用的NFS来作演示(在云上的话就用NAS),生产中如果对存储要求不是太高的话,建议就用NFS,这样出问题也比较容易解决,如果有性能需求,可以看看rook的ceph,以及Rancher的Longhorn,
开始部署NFS-SERVER
# 我们这里在10.0.1.201上安装(在生产中,大家要提供作好NFS-SERVER环境的规划) yum -y install nfs-utils # 创建NFS挂载目录 mkdir /nfs_dir chown nobody.nobody /nfs_dir # 修改NFS-SERVER配置 echo '/nfs_dir *(rw,sync,no_root_squash)' > /etc/exports # 重启服务 systemctl restart rpcbind.service systemctl restart nfs-utils.service systemctl restart nfs-server.service # 增加NFS-SERVER开机自启动 systemctl enable nfs-server.service Created symlink from /etc/systemd/system/multi-user.target.wants/nfs-server.service to /usr/lib/systemd/system/nfs-server.service. # 验证NFS-SERVER是否能正常访问 showmount -e 10.0.1.201 Export list for 10.0.1.201: /nfs_dir *
创建基于NFS的PV
首先在NFS-SERVER的挂载目录里面创建一个目录
mkdir /nfs_dir/pv1
接着准备好pv的yaml配置,保存为pv1.yaml
cat pv1.yaml
查看pv状态
kubectl get pv
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv1
labels:
type: test-claim # 这里建议打上一个独有的标签,方便在多个pv的时候方便提供pvc选择挂载
spec:
capacity:
storage: 1Gi # <---------- 1
accessModes:
- ReadWriteOnce # <---------- 2
persistentVolumeReclaimPolicy: Recycle # <---------- 3
storageClassName: nfs # <---------- 4
nfs:
path: /nfs_dir/pv1 # <---------- 5
server: 10.0.1.201
接着准备PVC的yaml,保存为pvc1.yaml
# cat pvc1.yaml
kubectl apply -f pvc1.yaml
查看pvc状态、已经bound
kubectl get pvc
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pvc1
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: nfs
selector:
matchLabels:
type: test-claim
下面我们准备pod服务来挂载这个pvc
这里就以上面最开始演示用的nginx的deployment的yaml配置来作修改
cat nginx.yaml
kubectl apply -f nginx.yaml
kubectl get pod
kubectl get svc
curl nginxip
卷挂载后会把当前已经存在这个目录的文件给覆盖掉,这个和传统机器上的磁盘目录挂载道理是一样的
# 我们来自己创建一个index.html页面
# echo 'hello, world!' > /nfs_dir/pv1/index.html
# 再请求下看看,已经正常了
# curl 10.68.238.54
# 我们来手动删除这个nginx的pod,看下容器内的修改是否是持久的呢?
# kubectl delete pod nginx-569546db98-4nmmg
# 等待一会,等新的pod被创建好
# 再测试一下,可以看到,容器内的修改现在已经被持久化了
# 后面我们再想修改有两种方式,一个是exec进到pod内进行修改,还有一个是直接修改挂载在NFS目录下的文件
# echo 111 > /nfs_dir/pv1/index.html
apiVersion: v1
kind: Service
metadata:
labels:
app: nginx
name: nginx
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: nginx
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
volumeMounts: # 我们这里将nginx容器默认的页面目录挂载
- name: html-files
mountPath: "/usr/share/nginx/html"
volumes:
- name: html-files
persistentVolumeClaim: # 卷类型使用pvc,同时下面名称处填先创建好的pvc1
claimName: pvc1
***注意及时备份数据,注意及时备份数据,注意及时备份数据*** PVC以及PV的回收 # 这里删除时会一直卡着,我们按ctrl+c看看怎么回事 # kubectl delete pvc pvc1 persistentvolumeclaim "pvc1" deleted ^C # 看下pvc发现STATUS是Terminating删除中的状态,我分析是因为服务pod还在占用这个pvc使用中 # kubectl get pvc # 先删除这个pod # kubectl delete pod nginx-569546db98-99qpq # 再看先删除的pvc已经没有了 # kubectl get pvc
第8关 k8s架构师课程之持久化存储StorageClass
大家好,我是博哥爱运维,k8s持久化存储的第三节,给大家带来 StorageClass动态存储的讲解。
我这是直接拿生产中用的实例来作演示,利用**********nfs-client-provisioner*******来生成一个基于nfs的StorageClass,部署配置yaml配置如下,保持为nfs-sc.yaml:
开始创建这个StorageClass:
kubectl apply -f nfs-sc.yaml
# 注意这个是在放kube-system的namespace下面,这里面放置一些偏系统类的服务
kubectl -n kube-system get pod -w
kubectl get sc
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
namespace: kube-system
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["list", "watch", "create", "update", "patch"]
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: kube-system
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Deployment
apiVersion: apps/v1
metadata:
name: nfs-provisioner-01
namespace: kube-system
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-provisioner-01
template:
metadata:
labels:
app: nfs-provisioner-01
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: jmgao1983/nfs-client-provisioner:latest
imagePullPolicy: IfNotPresent
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: nfs-provisioner-01 # 此处供应者名字供storageclass调用
- name: NFS_SERVER
value: 172.24.75.119 # 填入NFS的地址
- name: NFS_PATH
value: /nfs_dir # 填入NFS挂载的目录
volumes:
- name: nfs-client-root
nfs:
server: 172.24.75.119 # 填入NFS的地址
path: /nfs_dir # 填入NFS挂载的目录
---
###这里才是storageClass
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-boge
provisioner: nfs-provisioner-01
# Supported policies: Delete、 Retain , default is Delete
reclaimPolicy: Retain
我们来基于StorageClass创建一个pvc,看看动态生成的pv是什么效果:
vim pvc-sc.yaml
kubectl apply -f pvc-sc.yaml
kubectl get pvc
kubectl get pv
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pvc-sc
spec:
storageClassName: nfs-boge
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Mi
我们修改下nginx的yaml配置,将pvc的名称换成上面的pvc-sc: 修改最后一行就行 kubectl apply -f nginx.yaml # 这里注意下,因为是动态生成的pv,所以它的目录基于是一串随机字符串生成的,这时我们直接进到pod内来创建访问页面 kubectl get pods # kubectl exec -it nginx-57cdc6d9b4-n497g -- bash root@nginx-57cdc6d9b4-n497g:/# echo 'storageClass used' > /usr/share/nginx/html/index.html root@nginx-57cdc6d9b4-n497g:/# exit # curl 10.68.238.54 storageClass used # 我们看下NFS挂载的目录、发现已经出现 # ll /nfs_dir/
第9关 k8s架构师课程之有状态服务StatefulSet
大家好,我是博哥爱运维,K8s是如何来管理有状态服务的呢?跟着博哥来会会它们吧!
1、创建pv
-------------------------------------------
root@node1:~# cat web-pv.yaml
# mkdir -p /nfs_dir/{web-pv0,web-pv1}
apiVersion: v1
kind: PersistentVolume
metadata:
name: web-pv0
labels:
type: web-pv0
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: my-storage-class
nfs:
path: /nfs_dir/web-pv0
server: 10.0.1.201
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: web-pv1
labels:
type: web-pv1
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: my-storage-class
nfs:
path: /nfs_dir/web-pv1
server: 10.0.1.201
2、创建pvc(这一步可以省去让其自动创建,这里手动创建是为了让大家能更清楚在sts里面pvc的创建过程)
-------------------------------------------
这一步非常非常的关键,因为如果创建的PVC的名称和StatefulSet中的名称没有对应上,
那么StatefulSet中的Pod就肯定创建不成功.
3、创建Service 和 StatefulSet
-------------------------------------------
在上一步中我们已经创建了名为www-web-0的PVC了,接下来创建一个service和statefulset,
service的名称可以随意取,但是statefulset的名称已经定死了,为web,
并且statefulset中的volumeClaimTemplates_name必须为www,volumeMounts_name也必须为www。
只有这样,statefulset中的pod才能通过命名来匹配到PVC,否则会创建失败。
root@node1:~# cat web.yaml
apiVersion: v1
kind: Service
metadata:
name: web-headless
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: v1
kind: Service
metadata:
name: web
labels:
app: nginx
spec:
ports:
- port: 80
name: web
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx # has to match .spec.template.metadata.labels
serviceName: "nginx"
replicas: 2 # by default is 1
template:
metadata:
labels:
app: nginx # has to match .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "my-storage-class"
resources:
requests:
storage: 1Gi
第10关 k8s架构师课程之一次性和定时任务
原创2021-03-21 20:14·博哥爱运维
Job, CronJob
cronjob
上面的job是一次性任务,
apiVersion: batch/v1beta1 # <--------- 当前 CronJob 的 apiVersion
kind: CronJob # <--------- 当前资源的类型
metadata:
name: hello
spec:
schedule: "* * * * *" # <--------- schedule 指定什么时候运行 Job,其格式与 Linux crontab 一致,这里 * * * * * 的含义是每一分钟启动一次
jobTemplate: # <--------- 定义 Job 的模板,格式与前面 Job 一致
spec:
template:
spec:
containers:
- name: hello
image: busybox
command: ["echo","boge like cronjob."]
restartPolicy: OnFailure
第11关 k8s架构师课程之RBAC角色访问控制
原创2021-03-22 21:30·博哥爱运维
RBAC 基于角色(Role)的访问控制
控制访问权限
第一类的实战这里先暂时以早期的helm2来作下讲解
titller相当于helm的服务端,它是需要有权限在K8s中创建各类资源的,在初始安装使用时,如果没有配置RBAC权限,我们会看到如下报错:
root@node1:~# helm install stable/mysql Error: no available release name found
管理员权限查看 cat /root/.kube/config
这时,我们可以来快速解决这个问题,创建sa关联K8s自带的最高权限的ClusterRole(生产中建议不要这样做,权限太高有安全隐患,这个就和linux的root管理帐号一样,一般都是建议通过sudo来控制帐号权限)
kubectl create serviceaccount --namespace kube-system tiller
kubectl create clusterrolebinding tiller-cluster-rule --clusterrole=cluster-admin --serviceaccount=kube-system:tiller
kubectl patch deploy --namespace kube-system tiller-deploy -p '{"spec":{"template":{"spec":{"serviceAccount":"tiller"}}}}'
第二类,我这里就直接以我在生产中实施的完整脚本来做讲解及实战,相信会给大家带来一个全新的学习感受,并能很快掌握它们
***这是超大的福利*** 0.用法、生成后权限查看 1.某个namespace所有权限的脚本(新建namespace) 2.创建已经存在的namespace的权限的脚本 3.创建只读权限 4.创建多集群融合配置(把脚本拿到每个集群跑生成配置)
0.用法 sh 1.sh Use 1.sh NAMESPACE ENDPOINT SH 1.SH 命名空间名称 访问地址 [root@node01 mnt]# bash 1.sh All namespaces is here: default ingress-nginx kube-node-lease kube-public kube-system endpoint server if local network you can use https://172.24.75.119:6443 Use 1.sh NAMESPACE ENDPOINT 结果: [root@node01 mnt]# sh 1.sh webbobo https://172.24.75.119:6443 All namespaces is here: default ingress-nginx kube-node-lease kube-public kube-system webbobo endpoint server if local network you can use https://172.24.75.119:6443 webbobo namespace: webbobo was exist. serviceaccount/webbobo-user created Warning: rbac.authorization.k8s.io/v1beta1 Role is deprecated in v1.17+, unavailable in v1.22+; use rbac.authorization.k8s.io/v1 Role role.rbac.authorization.k8s.io/webbobo-user-full-access created Warning: rbac.authorization.k8s.io/v1beta1 RoleBinding is deprecated in v1.17+, unavailable in v1.22+; use rbac.authorization.k8s.io/v1 RoleBinding rolebinding.rbac.authorization.k8s.io/webbobo-user-view created resourcequota/webbobo-compute-resources created Name: webbobo-compute-resources Namespace: webbobo Resource Used Hard -------- ---- ---- limits.cpu 0 2 limits.memory 0 4Gi persistentvolumeclaims 0 5 pods 0 10 requests.cpu 0 1 requests.memory 0 2Gi services 0 10 查看访问配置权限 cat ./kube_config/webbobo.kube.conf 使用: kubectl --kubeconfig=./kube_config/web.kube.conf get nodes #Forbidden代表权限不足 kubectl --kubeconfig=./kube_config/web.kube.conf get pods #可用 kubectl --kubeconfig=./kube_config/webbobo.kube.conf get pods kubectl get sa -n webbobo kubectl get role -n webbobo kubectl get rolebings -n webbobo kubectl get delete -n webbobo
1.创建对指定(新建)namespace有***所有权限***的kube-config(新建)
#!/bin/bash
#
# This Script based on https://jeremievallee.com/2018/05/28/kubernetes-rbac-namespace-user.html
# K8s'RBAC doc: https://kubernetes.io/docs/reference/access-authn-authz/rbac
# Gitlab'CI/CD doc: hhttps://docs.gitlab.com/ee/user/permissions.html#running-pipelines-on-protected-branches
#
# In honor of the remarkable Windson
BASEDIR="$(dirname "$0")"
folder="$BASEDIR/kube_config"
echo -e "All namespaces is here: \n$(kubectl get ns|awk 'NR!=1{print $1}')"
echo "endpoint server if local network you can use $(kubectl cluster-info |awk '/Kubernetes/{print $NF}')"
#打印api的地址
namespace=$1
endpoint=$(echo "$2" | sed -e 's,https\?://,,g')
#能够访问到的api地址
if [[ -z "$endpoint" || -z "$namespace" ]]; then
echo "Use "$(basename "$0")" NAMESPACE ENDPOINT";
exit 1;
fi
#缺少参数则退出
if ! kubectl get ns|awk 'NR!=1{print $1}'|grep -w "$namespace";then kubectl create ns "$namespace";else echo "namespace: $namespace was exist.";exit 1 ;fi
#命名空间是否存在
#1.创建账号
echo "---
apiVersion: v1
kind: ServiceAccount
metadata:
name: $namespace-user
namespace: $namespace
---
#2.创建角色Role对指定的namespace生效、CLU role对生效
kind: Role
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: $namespace-user-full-access
namespace: $namespace
rules:
#所有权限用*代替
- apiGroups: ['', 'extensions', 'apps', 'metrics.k8s.io']
resources: ['*']
verbs: ['*']
- apiGroups: ['batch']
resources:
- jobs
- cronjobs
verbs: ['*']
---
#3.角色绑定
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: $namespace-user-view
namespace: $namespace
subjects:
- kind: ServiceAccount
name: $namespace-user
namespace: $namespace
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: $namespace-user-full-access
---
# https://kubernetes.io/zh/docs/concepts/policy/resource-quotas/
apiVersion: v1
kind: ResourceQuota
metadata:
name: $namespace-compute-resources
namespace: $namespace
spec:
#做资源限制
hard:
pods: "10"
services: "10"
persistentvolumeclaims: "5"
requests.cpu: "1"
requests.memory: 2Gi
limits.cpu: "2"
limits.memory: 4Gi" | kubectl apply -f -
kubectl -n $namespace describe quota $namespace-compute-resources
mkdir -p $folder
#基于账号提取密钥名称、Token、证书
tokenName=$(kubectl get sa $namespace-user -n $namespace -o "jsonpath={.secrets[0].name}")
token=$(kubectl get secret $tokenName -n $namespace -o "jsonpath={.data.token}" | base64 --decode)
certificate=$(kubectl get secret $tokenName -n $namespace -o "jsonpath={.data['ca\.crt']}")
echo "apiVersion: v1
kind: Config
preferences: {}
clusters:
- cluster:
certificate-authority-data: $certificate
server: https://$endpoint
name: $namespace-cluster
users:
- name: $namespace-user
user:
as-user-extra: {}
client-key-data: $certificate
token: $token
contexts:
- context:
cluster: $namespace-cluster
namespace: $namespace
user: $namespace-user
name: $namespace
current-context: $namespace" > $folder/$namespace.kube.conf
2.创建对指定namespace有所有权限的kube-config(在已有的namespace中创建)
#!/bin/bash
BASEDIR="$(dirname "$0")"
folder="$BASEDIR/kube_config"
echo -e "All namespaces is here: \n$(kubectl get ns|awk 'NR!=1{print $1}')"
echo "endpoint server if local network you can use $(kubectl cluster-info |awk '/Kubernetes/{print $NF}')"
namespace=$1
endpoint=$(echo "$2" | sed -e 's,https\?://,,g')
if [[ -z "$endpoint" || -z "$namespace" ]]; then
echo "Use "$(basename "$0")" NAMESPACE ENDPOINT";
exit 1;
fi
echo "---
apiVersion: v1
kind: ServiceAccount
metadata:
name: $namespace-user
namespace: $namespace
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: $namespace-user-full-access
namespace: $namespace
rules:
- apiGroups: ['', 'extensions', 'apps', 'metrics.k8s.io']
resources: ['*']
verbs: ['*']
- apiGroups: ['batch']
resources:
- jobs
- cronjobs
verbs: ['*']
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: $namespace-user-view
namespace: $namespace
subjects:
- kind: ServiceAccount
name: $namespace-user
namespace: $namespace
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: $namespace-user-full-access" | kubectl apply -f -
mkdir -p $folder
tokenName=$(kubectl get sa $namespace-user -n $namespace -o "jsonpath={.secrets[0].name}")
token=$(kubectl get secret $tokenName -n $namespace -o "jsonpath={.data.token}" | base64 --decode)
certificate=$(kubectl get secret $tokenName -n $namespace -o "jsonpath={.data['ca\.crt']}")
echo "apiVersion: v1
kind: Config
preferences: {}
clusters:
- cluster:
certificate-authority-data: $certificate
server: https://$endpoint
name: $namespace-cluster
users:
- name: $namespace-user
user:
as-user-extra: {}
client-key-data: $certificate
token: $token
contexts:
- context:
cluster: $namespace-cluster
namespace: $namespace
user: $namespace-user
name: $namespace
current-context: $namespace" > $folder/$namespace.kube.conf
3.创建只读权限的、主要就是改了verbs
#!/bin/bash
BASEDIR="$(dirname "$0")"
folder="$BASEDIR/kube_config"
echo -e "All namespaces is here: \n$(kubectl get ns|awk 'NR!=1{print $1}')"
echo "endpoint server if local network you can use $(kubectl cluster-info |awk '/Kubernetes/{print $NF}')"
namespace=$1
endpoint=$(echo "$2" | sed -e 's,https\?://,,g')
if [[ -z "$endpoint" || -z "$namespace" ]]; then
echo "Use "$(basename "$0")" NAMESPACE ENDPOINT";
exit 1;
fi
echo "---
apiVersion: v1
kind: ServiceAccount
metadata:
name: $namespace-user-readonly
namespace: $namespace
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: $namespace-user-readonly-access
namespace: $namespace
rules:
- apiGroups: ['', 'extensions', 'apps', 'metrics.k8s.io']
resources: ['pods', 'pods/log']
verbs: ['get', 'list', 'watch']
- apiGroups: ['batch']
resources: ['jobs', 'cronjobs']
verbs: ['get', 'list', 'watch']
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: $namespace-user-view-readonly
namespace: $namespace
subjects:
- kind: ServiceAccount
name: $namespace-user-readonly
namespace: $namespace
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: $namespace-user-readonly-access" | kubectl apply -f -
mkdir -p $folder
tokenName=$(kubectl get sa $namespace-user-readonly -n $namespace -o "jsonpath={.secrets[0].name}")
token=$(kubectl get secret $tokenName -n $namespace -o "jsonpath={.data.token}" | base64 --decode)
certificate=$(kubectl get secret $tokenName -n $namespace -o "jsonpath={.data['ca\.crt']}")
echo "apiVersion: v1
kind: Config
preferences: {}
clusters:
- cluster:
certificate-authority-data: $certificate
server: https://$endpoint
name: $namespace-cluster-readonly
users:
- name: $namespace-user-readonly
user:
as-user-extra: {}
client-key-data: $certificate
token: $token
contexts:
- context:
cluster: $namespace-cluster-readonly
namespace: $namespace
user: $namespace-user-readonly
name: $namespace
current-context: $namespace" > $folder/$namespace-readonly.kube.conf
4.大招---多集群融合配置
#!/bin/bash
# describe: create k8s cluster all namespaces resources with readonly clusterrole, no exec 、delete ...
# look system default to study:
# kubectl describe clusterrole view
# restore all change:
#kubectl -n kube-system delete sa all-readonly-${clustername}
#kubectl delete clusterrolebinding all-readonly-${clustername}
#kubectl delete clusterrole all-readonly-${clustername}
clustername=$1
Help(){
echo "Use "$(basename "$0")" ClusterName(example: k8s1|k8s2|k8s3|delk8s1|delk8s2|delk8s3|3in1)";
exit 1;
}
if [[ -z "${clustername}" ]]; then
Help
fi
case ${clustername} in
#二进制安装时指定名称
#查看命令kubectl config get-contexts
k8s1)
endpoint="https://x.x.x.x:123456"
;;
k8s2)
endpoint="https://x.x.x.x:123456"
;;
k8s3)
endpoint="https://x.x.x.x:123456"
;;
delk8s1)
kubectl -n kube-system delete sa all-readonly-k8s1
kubectl delete clusterrolebinding all-readonly-k8s1
kubectl delete clusterrole all-readonly-k8s1
echo "${clustername} successful."
exit 0
;;
delk8s2)
kubectl -n kube-system delete sa all-readonly-k8s2
kubectl delete clusterrolebinding all-readonly-k8s2
kubectl delete clusterrole all-readonly-k8s2
echo "${clustername} successful."
exit 0
;;
delk8s3)
kubectl -n kube-system delete sa all-readonly-k8s3
kubectl delete clusterrolebinding all-readonly-k8s3
kubectl delete clusterrole all-readonly-k8s3
echo "${clustername} successful."
exit 0
;;
3in1)
KUBECONFIG=./all-readonly-k8s1.conf:all-readonly-k8s2.conf:all-readonly-k8s3.conf kubectl config view --flatten > ./all-readonly-3in1.conf
kubectl --kubeconfig=./all-readonly-3in1.conf config use-context "k8s3"
kubectl --kubeconfig=./all-readonly-3in1.conf config set-context "k8s3" --namespace="default"
kubectl --kubeconfig=./all-readonly-3in1.conf config get-contexts
echo -e "\n\n\n"
cat ./all-readonly-3in1.conf |base64 -w 0
exit 0
;;
*)
Help
esac
echo "---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: all-readonly-${clustername}
rules:
- apiGroups:
- ''
resources:
- configmaps
- endpoints
- persistentvolumes
- persistentvolumeclaims
- pods
- replicationcontrollers
- replicationcontrollers/scale
- serviceaccounts
- services
- nodes
verbs:
- get
- list
- watch
- apiGroups:
- ''
resources:
- bindings
- events
- limitranges
- namespaces/status
- pods/log
- pods/status
- replicationcontrollers/status
- resourcequotas
- resourcequotas/status
verbs:
- get
- list
- watch
- apiGroups:
- ''
resources:
- namespaces
verbs:
- get
- list
- watch
- apiGroups:
- apps
resources:
- controllerrevisions
- daemonsets
- deployments
- deployments/scale
- replicasets
- replicasets/scale
- statefulsets
- statefulsets/scale
verbs:
- get
- list
- watch
- apiGroups:
- autoscaling
resources:
- horizontalpodautoscalers
verbs:
- get
- list
- watch
- apiGroups:
- batch
resources:
- cronjobs
- jobs
verbs:
- get
- list
- watch
- apiGroups:
- extensions
resources:
- daemonsets
- deployments
- deployments/scale
- ingresses
- networkpolicies
- replicasets
- replicasets/scale
- replicationcontrollers/scale
verbs:
- get
- list
- watch
- apiGroups:
- policy
resources:
- poddisruptionbudgets
verbs:
- get
- list
- watch
- apiGroups:
- networking.k8s.io
resources:
- networkpolicies
verbs:
- get
- list
- watch
- apiGroups:
- metrics.k8s.io
resources:
- pods
verbs:
- get
- list
- watch" | kubectl apply -f -
kubectl -n kube-system create sa all-readonly-${clustername}
kubectl create clusterrolebinding all-readonly-${clustername} --clusterrole=all-readonly-${clustername} --serviceaccount=kube-system:all-readonly-${clustername}
tokenName=$(kubectl -n kube-system get sa all-readonly-${clustername} -o "jsonpath={.secrets[0].name}")
token=$(kubectl -n kube-system get secret $tokenName -o "jsonpath={.data.token}" | base64 --decode)
certificate=$(kubectl -n kube-system get secret $tokenName -o "jsonpath={.data['ca\.crt']}")
echo "apiVersion: v1
kind: Config
preferences: {}
clusters:
- cluster:
certificate-authority-data: $certificate
server: $endpoint
name: all-readonly-${clustername}-cluster
users:
- name: all-readonly-${clustername}
user:
as-user-extra: {}
client-key-data: $certificate
token: $token
contexts:
- context:
cluster: all-readonly-${clustername}-cluster
user: all-readonly-${clustername}
name: ${clustername}
current-context: ${clustername}" > ./all-readonly-${clustername}.conf
第12关 k8s架构师课程之业务日志收集上节介绍、下节实战
业务日志
原创2021-03-24 21:30·博哥爱运维
elasticsearch log-pilot kibana 、 prometheus-oprator grafana webhook
日志收集
现在市面上大多数课程都是以EFK来作来K8s项目的日志解决方案,它包括三个组件:Elasticsearch, Fluentd(filebeat), Kibana;Elasticsearch 是日志存储和日志搜索引擎,Fluentd 负责把k8s集群的日志发送给 Elasticsearch, Kibana 则是可视化界面查看和检索存储在 Elasticsearch 的数据。
但根据生产中实际使用情况来看,它有以下弊端:
1、日志收集系统 EFK是在每个kubernetes的NODE节点以daemonset的形式启动一个fluentd的pod,来收集NODE节点上的日志,如容器日志(/var/log/containers/*.log),但里面无法作细分,想要的和不想要的都收集进来了,带来的后面就是磁盘IO压力会比较大,日志过滤麻烦。
2、无法收集对应POD里面的业务日志 上面第1点只能收集pod的stdout(打印的日志、而不是业务日志)日志,但是pod内如有需要收集的业务日志,像pod内的/tmp/datalog/*.log,那EFK是无能为力的,只能是在pod内启动多个容器(filebeat)去收集容器内日志,但这又会带来的是pod多容器性能的损耗,这个接下来会详细讲到。
3、fluentd的采集速率性能较低,只能不到filebeat的1/10的性能。
基于此,我通过调研发现了阿里开源的智能容器采集工具 Log-Pilot,github地址: GitHub - AliyunContainerService/log-pilot: Collect logs for docker containers
下面以sidecar 模式和log-pilot这两种方式的日志收集形式做个详细对比说明:
sidecar 模式,这种需要我们在每个 Pod 中都附带一个 logging 容器来进行本 Pod 内部容器的日志采集,一般采用共享卷的方式,但是对于这一种模式来说,很明显的一个问题就是占用的资源比较多,尤其是在集群规模比较大的情况下,
另一种模式是 Node 模式,这种模式是我们在每个 Node 节点上仅需部署一个 logging 容器来进行本 Node 所有容器的日志采集。这样跟前面的模式相比最明显的优势就是占用资源比较少,同样在集群规模比较大的情况下表现出的优势越明显,同时这也是社区推荐的一种模式。
经过多方面测试,log-pilot对现有业务pod侵入性很小,只需要在原有pod的内传入几行env环境变量,即可对此pod相关的日志进行收集,已经测试了后端接收的工具有logstash、elasticsearch、kafka、redis、file,均OK,下面开始部署整个日志收集环境。
1.我们这里用一个tomcat服务来模拟业务服务,用log-pilot分别收集它的stdout以及容器内的业务数据日志文件到指定后端存储(这里分别以elasticsearch、kafka的这两种企业常用的接收工具来做示例)
1.只传个环境变量就能收集日志了
准备好相应的yaml配置
vim tomcat-test.yaml
kubectl apply -f tomcat-test.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: tomcat
name: tomcat
spec:
replicas: 1
selector:
matchLabels:
app: tomcat
template:
metadata:
labels:
app: tomcat
spec:
tolerations:
- key: "node-role.kubernetes.io/master"
effect: "NoSchedule"
containers:
- name: tomcat
image: "tomcat:7.0"
env: # 注意点一,添加相应的环境变量(下面收集了两块日志1、stdout 2、/usr/local/tomcat/logs/catalina.*.log)
- name: aliyun_logs_tomcat-syslog # 如日志发送到es,那index名称为 tomcat-syslog
value: "stdout"
- name: aliyun_logs_tomcat-access # 如日志发送到es,那index名称为 tomcat-access
value: "/usr/local/tomcat/logs/catalina.*.log"
volumeMounts:
# 注意点二,对pod内要收集的业务日志目录需要进行共享,可以收集多个目录下的日志文件
#挂载
- name: tomcat-log
mountPath: /usr/local/tomcat/logs
volumes:
- name: tomcat-log
emptyDir: {}
2.创建es6.yaml es和kibana 是一起的
2.3.4是一起的
接收工具ES、es和kibana的版本号要一样
vim elasticsearch.6.8.13-statefulset.yaml
kubectl apply -f elasticsearch.6.8.13-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
k8s-app: elasticsearch-logging
version: v6.8.13
name: elasticsearch-logging
# namespace: logging
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
k8s-app: elasticsearch-logging
version: v6.8.13
serviceName: elasticsearch-logging
template:
metadata:
labels:
k8s-app: elasticsearch-logging
version: v6.8.13
spec:
#nodeSelector: #测试不用这个节点选择选项
# esnode: "true" ## 注意给想要运行到的node打上相应labels
containers:
- env:
- name: NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
- name: cluster.name
value: elasticsearch-logging-0
- name: ES_JAVA_OPTS
value: "-Xms256m -Xmx256m"
image: elastic/elasticsearch:6.8.13
name: elasticsearch-logging
ports:
- containerPort: 9200
name: db
protocol: TCP
- containerPort: 9300
name: transport
protocol: TCP
volumeMounts:
- mountPath: /usr/share/elasticsearch/data
name: elasticsearch-logging
dnsConfig:
options:
- name: single-request-reopen
initContainers:
- command:
- /bin/sysctl
- -w
- vm.max_map_count=262144
image: busybox
imagePullPolicy: IfNotPresent
name: elasticsearch-logging-init
resources: {}
securityContext:
privileged: true
- name: fix-permissions
image: busybox
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: elasticsearch-logging
mountPath: /usr/share/elasticsearch/data
volumes:
- name: elasticsearch-logging
hostPath:
path: /esdata
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: elasticsearch-logging
name: elasticsearch
# namespace: logging
spec:
ports:
- port: 9200
protocol: TCP
targetPort: db
selector:
k8s-app: elasticsearch-logging
type: ClusterIP
3.创建kibana、2.3.4是一起的
vim kibana.6.8.13.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
# namespace: logging
labels:
app: kibana
spec:
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: elastic/kibana:6.8.13
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_URL
value: http://elasticsearch:9200
#elasticsearch的地址就是elasticsearch的svc地址
ports:
- containerPort: 5601
---
apiVersion: v1
kind: Service
metadata:
name: kibana
# namespace: logging
labels:
app: kibana
spec:
ports:
- port: 5601
protocol: TCP
targetPort: 5601
type: ClusterIP
selector:
app: kibana
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kibana
# namespace: logging
spec:
rules:
- host: kibana.boge.com
###域名自己换
http:
paths:
- path: /
backend:
serviceName: kibana
servicePort: 5601
[ClusterIP变成NodePort] https://blog.csdn.net/wang725/article/details/104318949?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166047532416782391844700%2522%252C%2522scm%2522%
 AGE
elasticsearch ClusterIP 10.68.10.41 <none> 9200/TCP 45m
kibana NodePort 10.68.127.151 <none> 5601:30752/TCP 43m
vim log-pilot.yml # 后端输出的elasticsearch
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: log-pilot
labels:
app: log-pilot
# 设置期望部署的namespace
# namespace: ns-elastic
spec:
selector:
matchLabels:
app: log-pilot
updateStrategy:
type: RollingUpdate
template:
metadata:
labels:
app: log-pilot
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
# 是否允许部署到Master节点上
#tolerations:
#- key: node-role.kubernetes.io/master
# effect: NoSchedule
containers:
- name: log-pilot
# 版本请参考https://github.com/AliyunContainerService/log-pilot/releases
image: registry.cn-hangzhou.aliyuncs.com/acs/log-pilot:0.9.7-filebeat
resources:
limits:
memory: 500Mi
requests:
cpu: 200m
memory: 200Mi
env:
- name: "NODE_NAME"
valueFrom:
fieldRef:
fieldPath: spec.nodeName
##--------------------------------
# - name: "LOGGING_OUTPUT"
# value: "logstash"
# - name: "LOGSTASH_HOST"
# value: "logstash-g1"
# - name: "LOGSTASH_PORT"
# value: "5044"
##--------------------------------
- name: "LOGGING_OUTPUT"
value: "elasticsearch"
## 请确保集群到ES网络可达
- name: "ELASTICSEARCH_HOSTS"
value: "elasticsearch:9200"
## 配置ES访问权限
#- name: "ELASTICSEARCH_USER"
# value: "{es_username}"
#- name: "ELASTICSEARCH_PASSWORD"
# value: "{es_password}"
##--------------------------------
## https://github.com/AliyunContainerService/log-pilot/blob/master/docs/filebeat/docs.md
## to file need configure 1
# - name: LOGGING_OUTPUT
# value: file
# - name: FILE_PATH
# value: /tmp
# - name: FILE_NAME
# value: filebeat.log
volumeMounts:
- name: sock
mountPath: /var/run/docker.sock
- name: root
mountPath: /host
readOnly: true
- name: varlib
mountPath: /var/lib/filebeat
- name: varlog
mountPath: /var/log/filebeat
- name: localtime
mountPath: /etc/localtime
readOnly: true
## to file need configure 2
# - mountPath: /tmp
# name: mylog
livenessProbe:
failureThreshold: 3
exec:
command:
- /pilot/healthz
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 2
securityContext:
capabilities:
add:
- SYS_ADMIN
terminationGracePeriodSeconds: 30
volumes:
- name: sock
hostPath:
path: /var/run/docker.sock
- name: root
hostPath:
path: /
- name: varlib
hostPath:
path: /var/lib/filebeat
type: DirectoryOrCreate
- name: varlog
hostPath:
path: /var/log/filebeat
type: DirectoryOrCreate
- name: localtime
hostPath:
path: /etc/localtime
## to file need configure 3
# - hostPath:
# path: /tmp/mylog
# type: ""
# name: mylog
5.6是一起的
5.独立的、、、部署log-pilot2-kafka.yaml----后端输出带哦kafka---node01
资源不足可以把es和kibana删掉
记得该ip
vi log-pilot2-kafka.yaml #后端输出到kafka
:%s+configMapKeyRee+configMapKeyRef+g批量替换
---
apiVersion: v1
kind: ConfigMap
metadata:
name: log-pilot2-configuration
#namespace: ns-elastic
data:
logging_output: "kafka"
kafka_brokers: "172.24.75.115:9092"
kafka_version: "0.10.0"
# configure all valid topics in kafka
# when disable auto-create topic
kafka_topics: "tomcat-syslog,tomcat-access"
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: log-pilot2
#namespace: ns-elastic
labels:
k8s-app: log-pilot2
spec:
selector:
matchLabels:
k8s-app: log-pilot2
updateStrategy:
type: RollingUpdate
template:
metadata:
labels:
k8s-app: log-pilot2
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: log-pilot2
#
# wget https://github.com/AliyunContainerService/log-pilot/archive/v0.9.7.zip
# unzip log-pilot-0.9.7.zip
# vim ./log-pilot-0.9.7/assets/filebeat/config.filebeat
# ...
# output.kafka:
# hosts: [$KAFKA_BROKERS]
# topic: '%{[topic]}'
# codec.format:
# string: '%{[message]}'
# ...
image: registry.cn-hangzhou.aliyuncs.com/acs/log-pilot:0.9.7-filebeat
env:
- name: "LOGGING_OUTPUT"
valueFrom:
configMapKeyRef:
name: log-pilot2-configuration
key: logging_output
- name: "KAFKA_BROKERS"
valueFrom:
configMapKeyRef:
name: log-pilot2-configuration
key: kafka_brokers
- name: "KAFKA_VERSION"
valueFrom:
configMapKeyRef:
name: log-pilot2-configuration
key: kafka_version
- name: "NODE_NAME"
valueFrom:
fieldRef:
fieldPath: spec.nodeName
volumeMounts:
- name: sock
mountPath: /var/run/docker.sock
- name: logs
mountPath: /var/log/filebeat
- name: state
mountPath: /var/lib/filebeat
- name: root
mountPath: /host
readOnly: true
- name: localtime
mountPath: /etc/localtime
# configure all valid topics in kafka
# when disable auto-create topic
- name: config-volume
mountPath: /etc/filebeat/config
securityContext:
capabilities:
add:
- SYS_ADMIN
terminationGracePeriodSeconds: 30
volumes:
- name: sock
hostPath:
path: /var/run/docker.sock
type: Socket
- name: logs
hostPath:
path: /var/log/filebeat
type: DirectoryOrCreate
- name: state
hostPath:
path: /var/lib/filebeat
type: DirectoryOrCreate
- name: root
hostPath:
path: /
type: Directory
- name: localtime
hostPath:
path: /etc/localtime
type: File
# kubelet sync period
- name: config-volume
configMap:
name: log-pilot2-configuration
items:
- key: kafka_topics
path: kafka_topics
6.部署kafka集群---node04
把docker-copose装好
scp /etc/kubeasz/bin/docker-compose 172.24.75.115:/bin
cd /tmp
mkdir /kafka
# 部署前准备
# 0. 先把代码pull到本地
# https://github.com/wurstmeister/kafka-docker
# 修改docker-compose.yml为:
#——------------------------------
version: '2'
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
kafka:
#build: .
image: wurstmeister/kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 172.24.75.114 # docker运行的机器IP
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- /nfs_storageclass/kafka:/kafka
#——------------------------------
6.补充创建kafka后的操作--node04
-----运行docker-compose
# 1. docker-compose setup:
# docker-compose up -d
Recreating kafka-docker-compose_kafka_1 ... done
Starting kafka-docker-compose_zookeeper_1 ... done
# 2. result look:---看到zook和kafka都起来
# docker-compose ps
Name Command State Ports
--------------------------------------------------------------------------------------------------------------------
kafka-docker-compose_kafka_1 start-kafka.sh Up 0.0.0.0:9092->9092/tcp
kafka-docker-compose_zookeeper_1 /bin/sh -c /usr/sbin/sshd ... Up 0.0.0.0:2181->2181/tcp, 22/tcp,
2888/tcp, 3888/tcp
# 3. run test-docker进入kafka
bash-4.4# docker run --rm -v /var/run/docker.sock:/var/run/docker.sock -e HOST_IP=172.24.75.115 -e ZK=172.24.75.115:2181 -i -t wurstmeister/kafka /bin/bash
# 4. list topic---列出kafka---topic
bash-4.4# kafka-topics.sh --zookeeper 172.24.75.115:2181 --list
tomcat-access
tomcat-syslog
# 5. consumer topic data:
bash-4.4# kafka-console-consumer.sh --bootstrap-server 172.24.75.115:9092 --topic tomcat-access --from-beginning
第13关 k8s架构师课程之私有镜像仓库-Harbor
原创2021-03-26 17:36·博哥爱运维
大家好,我是博哥爱运维,建议是不要将harbor部署在k8s上,这里博哥就直接以第一种离线的方式来安装harbor
# 离线形式安装harbor私有镜像仓库---node04 1.创建目录及下载harbor离线包----node04 mkdir /data && cd /data wget https://github.com/goharbor/harbor/releases/download/v2.2.0/harbor-offline-installer-v2.2.0.tgz---------离线包自己下载了保存好 tar xf harbor-offline-installer-v2.2.0.tgz && rm harbor-offline-installer-v2.2.0.tgz ## 修改harbor配置 cd /data/harbor cp harbor.yml.tmpl harbor.yml 5 hostname: harbor.boge.com 17 certificate: /data/harbor/ssl/tls.cert 18 private_key: /data/harbor/ssl/tls.key 34 harbor_admin_password: boge666 2.创建harbor访问域名证书 mkdir /data/harbor/ssl && cd /data/harbor/ssl openssl genrsa -out tls.key 2048 openssl req -new -x509 -key tls.key -out tls.cert -days 360 -subj /CN=*.boge.com 3.准备好单机编排工具`docker-compose` > 从二进制安装k8s项目的bin目录拷贝过来-----从node01拷---->node04 scp /etc/kubeasz/bin/docker-compose 172.24.75.115:/usr/bin/ > 也可以在docker官方进行下载 https://docs.docker.com/compose/install/ 4. 开始安装 ./install.sh 5. 推送镜像到harbor 每个节点都要加hosts ##node04的ip(跑harbor的ip) echo '172.24.75.141 harbor.boge.com' >> /etc/hosts 先打标签、在登陆push docker login harbor.boge.com docker tag nginx:latest harbor.boge.com/library/nginx:latest docker push harbor.boge.com/library/nginx:1.18.0-alpine ###浏览器进入harbor控制台:---node04的ip+/harbor 47.103.13.111/harbor 部署harbor公网地址/harbor 6.在其他节点上面拉取harbor镜像 > 在集群每个 node 节点进行如下配置 > ssh to 10.0.1.201(centos7) 7.所有节点都要做 每个节点都要加hosts ##node04的ip(跑harbor的ip) echo '172.24.75.141 harbor.boge.com' >> /etc/hosts mkdir -p /etc/docker/certs.d/harbor.boge.com # node04的ip--跑harbor的ip scp 172.24.75.141:/data/harbor/ssl/tls.cert /etc/docker/certs.d/harbor.boge.com/ca.crt docker pull harbor.boge.com/library/nginx:latest 8 看看harbor正常不---不正常就重启harbor---node04 docker-compose ps docker-compose down -v docker-compose up -d docker ps|grep harbor ## 附(引用自 https://github.com/easzlab/kubeasz): containerd配置信任harbor证书 在集群每个 node 节点进行如下配置(假设ca.pem为自建harbor的CA证书) ubuntu 1604: cp ca.pem /usr/share/ca-certificates/harbor-ca.crt echo harbor-ca.crt >> /etc/ca-certificates.conf update-ca-certificates CentOS 7: cp ca.pem /etc/pki/ca-trust/source/anchors/harbor-ca.crt update-ca-trust 上述配置完成后,重启 containerd 即可 systemctl restart containerd 8.harbor的备份: /data挂载独立SSD
第14关k8s架构师课程之业务Prometheus监控实战一
原创2021-03-28 20:30·博哥爱运维
服务监控
在传统服务里面,我们通常会到zabbix、open-falcon、netdata来做服务的监控,但对于目前主流的K8s平台来说,由于服务pod会被调度到任何机器上运行,且pod挂掉后会被自动重启,并且我们也需要有更好的自动服务发现功能来实现服务报警的自动接入,实现更高效的运维报警,这里我们需要用到K8s的监控实现Prometheus,它是基于Google内部监控系统的开源实现。
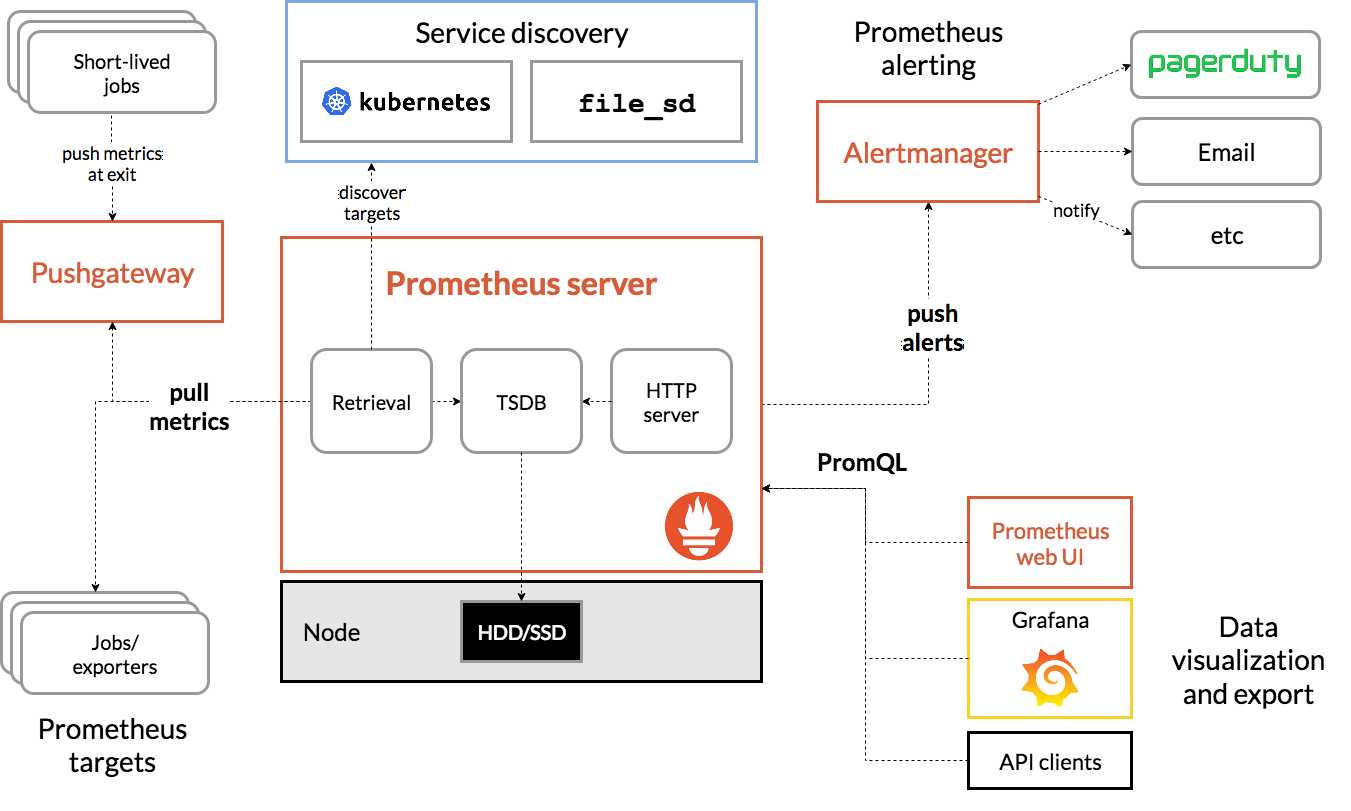
Prometheus Operator的工作原理
在Kubernetes中我们使用Deployment、DamenSet,StatefulSet来管理应用Workload,使用Service,Ingress来管理应用的访问方式,使用ConfigMap和Secret来管理应用配置。我们在集群中对这些资源的创建,更新,删除的动作都会被转换为事件(Event),Kubernetes的Controller Manager负责监听这些事件并触发相应的任务来满足用户的期望。这种方式我们成为声明式,用户只需要关心应用程序的最终状态,其它的都通过Kubernetes来帮助我们完成,通过这种方式可以大大简化应用的配置管理复杂度。
实战操作篇一
在K8s集群中部署Prometheus Operator
我们这里用prometheus-operator来安装整套prometheus服务,建议直接用master分支即可,这也是官方所推荐的荐的
开始安装
安装包和离线镜像包下载
天翼云盘 珍藏美好生活 家庭云|网盘|文件备份|资源分享 (访问码:0nsj)
1. 解压下载的代码包---node1
cd /mnt/
unzip kube-prometheus-master.zip
rm -f kube-prometheus-master.zip && cd kube-prometheus-master
2. 每个节点导入镜像包离线镜像包都导入
docker load -i xxx.tar
这里建议先看下有哪些镜像,便于在下载镜像快的节点上先收集好所有需要的离线docker镜像
# find ./ -type f |xargs grep 'image: '|sort|uniq|awk '{print $3}'|grep ^[a-zA-Z]|grep -Evw 'error|kubeRbacProxy'|sort -rn|uniq
quay.io/prometheus/prometheus:v2.22.1
quay.io/prometheus-operator/prometheus-operator:v0.43.2
quay.io/prometheus/node-exporter:v1.0.1
quay.io/prometheus/alertmanager:v0.21.0
quay.io/fabxc/prometheus_demo_service
quay.io/coreos/kube-state-metrics:v1.9.7
quay.io/brancz/kube-rbac-proxy:v0.8.0
grafana/grafana:7.3.4
gcr.io/google_containers/metrics-server-amd64:v0.2.01
directxman12/k8s-prometheus-adapter:v0.8.2
在测试的几个node上把这些离线镜像包都导入 docker load -i xxx.tar
3. 开始创建所有服务--node01
cd /mnt/kube-prometheus-master
kubectl create -f manifests/setup
kubectl create -f manifests/
过一会查看创建结果:
kubectl -n monitoring get all
确认每一个都正常
# 附:清空上面部署的prometheus所有服务:
kubectl delete --ignore-not-found=true -f manifests/ -f manifests/setup
2.访问Prometheus的界面
生产小技巧,强制删除删不掉的pods
kubectl delete pod node-exporter-nglzp --grace-period=0 --force -n monitoring
2.1修改下prometheus UI的service模式,便于我们外网访问
kubectl -n monitoring patch svc prometheus-k8s -p '{"spec":{"type":"NodePort"}}'
2.2查看svc和端口、通过浏览器访问外网端口
kubectl -n monitoring get svc prometheus-k8s
2.3点击上方菜单栏Status — Targets ,我们发现kube-controller-manager和kube-scheduler未发现
opreator部署都会有这个问题
注:只要不全不是【::】就得改、如果发现下面不是监控的127.0.0.1,并且通过下面地址可以获取metric指标输出,那么这个改IP这一步可以不用操作
curl 10.0.1.201:10251/metrics curl 10.0.1.201:10252/metrics
3.解决kube-controller-manager和kube-scheduler未发现的问题 查看两服务监听的IP ss -tlnp|egrep 'controller|schedule' 4.有几个master就改几个、如果大家前面是按我设计的4台NODE节点,其中2台作master的话,那就在这2台master上把systemcd配置改一下 所有master分别改ip sed -ri 's+172.24.75.117+0.0.0.0+g' /etc/systemd/system/kube-controller-manager.service sed -ri 's+172.24.75.117+0.0.0.0+g' /etc/systemd/system/kube-scheduler.service systemctl daemon-reload systemctl restart kube-controller-manager.service systemctl restart kube-scheduler.service 5.xiu该完毕再次尝试访问\\OK 通了、、但是还没完全通、看第6步 curl 172.24.75.119:10251/metrics curl 172.24.75.119:10252/metrics
6.6.然后因为K8s的这两上核心组件我们是以二进制形式部署的,为了能让K8s上的prometheus能发现,我们还需要来创建相应的service和endpoints来将其关联起来
注意:我们需要将endpoints里面的NODE IP换成我们实际情况的
将上面的yaml配置保存为repair-prometheus.yaml,然后创建它---node01
vi repair-prometheus.yaml
kubectl apply -f repair-prometheus.yaml
创建完确认下
kubectl -n kube-system get svc |egrep 'controller|scheduler'
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager
labels:
k8s-app: kube-controller-manager
spec:
type: ClusterIP
clusterIP: None
ports:
- name: http-metrics
port: 10252
targetPort: 10252
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-controller-manager
name: kube-controller-manager
namespace: kube-system
subsets:
- addresses:
- ip: 172.24.75.119
- ip: 172.24.75.118
- ip: 172.24.75.117
ports:
- name: http-metrics
port: 10252
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
k8s-app: kube-scheduler
spec:
type: ClusterIP
clusterIP: None
ports:
- name: http-metrics
port: 10251
targetPort: 10251
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-scheduler
name: kube-scheduler
namespace: kube-system
subsets:
- addresses:
- ip: 172.24.75.119
- ip: 172.24.75.118
- ip: 172.24.75.117
ports:
- name: http-metrics
port: 10251
protocol: TCP
7.记得还要修改一个地方
kubectl -n monitoring edit servicemonitors.monitoring.coreos.com kube-scheduler
# 将下面两个地方的https换成http
port: https-metrics
scheme: https
kubectl -n monitoring edit servicemonitors.monitoring.coreos.com kube-controller-manager
# 将下面两个地方的https换成http
port: https-metrics
scheme: https
8.然后再返回prometheus UI处,耐心等待几分钟,就能看到已经被发现了、、、完美解决
kubectl get svc -n monitoring
http://101.133.227.28:30838/targets
成功截图:
第14关k8s架构师课程之业务Prometheus监控实战二
原创2021-03-29 23:59·博哥爱运维
使用prometheus来监控ingress-nginx
大家好,我是博哥爱运维。我们前面部署过ingress-nginx,这个是整个K8s上所有服务的流量入口组件很关键,因此把它的metrics指标收集到prometheus来做好相关监控至关重要,因为前面ingress-nginx服务是以daemonset形式部署的,并且映射了自己的端口到宿主机上,那么我可以直接用pod运行NODE上的IP来看下metrics
curl 10.0.1.201:10254/metrics
1.创建 servicemonitor配置让prometheus能发现ingress-nginx的metrics
# vi servicemonitor.yaml
kubectl apply -f servicemonitor.yaml
kubectl -n ingress-nginx get servicemonitors.monitoring.coreos.com
如果指标没收集上来、看下报错、指标一直没收集上来,看看proemtheus服务的日志,发现报错如下:
kubectl -n monitoring logs prometheus-k8s-0 -c prometheus |grep error
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app: ingress-nginx
name: nginx-ingress-scraping
namespace: ingress-nginx
spec:
endpoints:
- interval: 30s
path: /metrics
port: metrics
jobLabel: app
namespaceSelector:
matchNames:
- ingress-nginx
selector:
matchLabels:
app: ingress-nginx
2.指标一直没收集上来,看看proemtheus服务的日志,发现报错如下:一堆error kubectl -n monitoring logs prometheus-k8s-0 -c prometheus |grep error 3.需要修改prometheus的clusterrole# ###从rules开始复制!! kubectl edit clusterrole prometheus-k8s 4.再到prometheus UI上看下,发现已经有了 apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: prometheus-k8s ####从rules开始复制!!! rules: - apiGroups: - "" resources: - nodes - services - endpoints - pods - nodes/proxy verbs: - get - list - watch - apiGroups: - "" resources: - configmaps - nodes/metrics verbs: - get - nonResourceURLs: - /metrics verbs: - get
使用Prometheus来监控二进制部署的ETCD集群
作为K8s所有资源存储的关键服务ETCD,我们也有必要把它给监控起来,正好借这个机会,完整的演示一次利用Prometheus来监控非K8s集群服务的步骤
在前面部署K8s集群的时候,我们是用二进制的方式部署的ETCD集群,并且利用自签证书来配置访问ETCD,正如前面所说,现在关键的服务基本都会留有指标metrics接口支持prometheus的监控,利用下面命令,我们可以看到ETCD都暴露出了哪些监控指标出来
1.查看ETCD是默认暴露---node1 curl --cacert /etc/kubernetes/ssl/ca.pem --cert /etc/kubeasz/clusters/testbobo/ssl/etcd.pem --key /etc/kubeasz/clusters/testbobo/ssl/etcd-key.pem https://172.24.75.117:2379/metrics 1 ##改版之后的位置在这: ll /etc/kubeasz/clusters/testbobo/ssl/etcd.pem 2.进行配置使ETCD能被prometheus发现并监控 2.1首先把ETCD的证书创建为secret----记得修改为自己的集群名字 kubectl -n monitoring create secret generic etcd-certs --from-file=/etc/kubeasz/clusters/test/ssl/etcd.pem --from-file=//etc/kubeasz/clusters/test/ssl/etcd-key.pem --from-file=/etc/kubernetes/ssl/ca.pem 2.2 接着在prometheus里面引用这个secrets kubectl -n monitoring edit prometheus k8s spec: ##加中间两个在最后,version:v2.22.1后面 ... secrets: - etcd-certs 2.3保存退出后,prometheus会自动重启服务pod以加载这个secret配置,过一会,我们进pod来查看下是不是已经加载到ETCD的证书了 kubectl -n monitoring exec -it prometheus-k8s-0 -c prometheus -- sh ###修改配置自动重启,所以多进去几次,这里没问题 /prometheus $ ls /etc/prometheus/secrets/etcd-certs/ ca.pem etcd-key.pem etcd.pem
3.接下来准备创建service、endpoints以及ServiceMonitor的yaml配置
注意替换下面的NODE节点IP为实际ETCD所在NODE内网IP
vi prometheus-etcd.yaml
kubectl apply -f prometheus-etcd.yaml
4.过一会,就可以在prometheus UI上面看到ETCD集群被监控了
apiVersion: v1
kind: Service
metadata:
name: etcd-k8s
namespace: monitoring
labels:
k8s-app: etcd
spec:
type: ClusterIP
clusterIP: None
ports:
- name: api
port: 2379
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
name: etcd-k8s
namespace: monitoring
labels:
k8s-app: etcd
subsets:
- addresses:
- ip: 172.24.75.119
- ip: 172.24.75.118
- ip: 172.24.75.117
ports:
- name: api
port: 2379
protocol: TCP
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: etcd-k8s
namespace: monitoring
labels:
k8s-app: etcd-k8s
spec:
jobLabel: k8s-app
endpoints:
- port: api
interval: 30s
scheme: https
tlsConfig:
caFile: /etc/prometheus/secrets/etcd-certs/ca.pem
certFile: /etc/prometheus/secrets/etcd-certs/etcd.pem
keyFile: /etc/prometheus/secrets/etcd-certs/etcd-key.pem
#use insecureSkipVerify only if you cannot use a Subject Alternative Name
insecureSkipVerify: true
selector:
matchLabels:
k8s-app: etcd
namespaceSelector:
matchNames:
- monitoring
5.接下来我们用grafana来展示被监控的ETCD指标接下来我们用grafana来展示被监控的ETCD指标 5.1. 在grafana官网模板中心搜索etcd,下载这个json格式的模板文件 https://grafana.com/dashboards/3070 5.2.然后打开自己先部署的grafana首页, kubectl get svc -n monitoring |grep gra ##初始密码admin 点击左边菜单栏四个小正方形方块HOME --- Manage 再点击右边 Import dashboard --- 点击Upload .json File 按钮,上传上面下载好的json文件 etcd_rev3.json, 然后在prometheus选择数据来源 点击Import,即可显示etcd集群的图形监控信息
成功截图:
第14关k8s架构师课`程之业务Prometheus监控实战三
原创2021-03-31 21:11·博哥爱运维
prometheus监控数据以及grafana配置持久化存储配置
大家好,我是博哥爱运维。这节实战课给大家讲解下如果配置prometheus以及grafana的数据持久化。
prometheus数据持久化配置
1.注意这下面的statefulset服务就是我们需要做数据持久化的地方
kubectl -n monitoring get statefulset,pod|grep prometheus-k8s
2.看下我们之前准备的StorageClass动态存储
kubectl get sc
root@node01 mnt]# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
nfs-boge nfs-provisioner-01 Retain Immediate false 11h
3.准备prometheus持久化的pvc配置---加到version最后
kubectl -n monitoring edit prometheus k8s
spec:
......
#从storage开始加
storage:
volumeClaimTemplate:
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "nfs-boge"
#下面三行去掉不然新版本报错
#selector:
# matchLabels:
# app: my-example-prometheus
resources:
requests:
storage: 1Gi
4.# 上面修改保存退出后,过一会我们查看下pvc创建情况,以及pod内的数据挂载情况
kubectl -n monitoring get pvc
[root@node01 mnt]# kubectl -n monitoring get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
prometheus-k8s-db-prometheus-k8s-0 Bound pvc-71e2655a-a1dc-487d-8cfe-f29d02d3035e 1Gi RWO nfs-boge 101s
prometheus-k8s-db-prometheus-k8s-1 Bound pvc-4326dac9-385b-4aa8-91b0-60a77b79e625 1Gi RWO nfs-boge 101s
5.# kubectl -n monitoring exec -it prometheus-k8s-0 -c prometheus -- sh
/prometheus $ df -Th
......
10.0.1.201:/nfs_dir/monitoring-prometheus-k8s-db-prometheus-k8s-0-pvc-055e6b11-31b7-4503-ba2b-4f292ba7bd06/prometheus-db
nfs4 97.7G 9.4G 88.2G 10% /prometheus
grafana配置持久化存储配置
1.保存pvc为grafana-pvc.yaml
vi grafana-pvc.yaml
#vi grafana-pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: grafana
namespace: monitoring
spec:
storageClassName: nfs-boge
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
# 开始创建pvc
kubectl apply -f grafana-pvc.yaml
# 看下创建的pvc
kubectl -n monitoring get pvc
# 编辑grafana的deployment资源配置
kubectl -n monitoring edit deployments.apps grafana
# 旧的配置
volumes:
- emptyDir: {}
name: grafana-storage
# 替换成新的配置---131行
volumes:
- name: grafana-storage
persistentVolumeClaim:
claimName: grafana
# 同时加入下面的env环境变量,将登陆密码进行固定修改
spec:
containers:
......
#env和port对齐---插到47行
env:
- name: GF_SECURITY_ADMIN_USER
value: admin
- name: GF_SECURITY_ADMIN_PASSWORD
value: admin321
# 过一会,等grafana重启完成后,用上面的新密码进行登陆
kubectl -n monitoring get pod -w|grep grafana
grafana-5698bf94f4-prbr2 0/1 Running 0 3s
grafana-5698bf94f4-prbr2 1/1 Running 0 4s
# 因为先前的数据并未持久化,所以会发现先导入的ETCD模板已消失,这时重新再导入一次,后面重启也不会丢了
第14关k8s架构师课程之业务Prometheus监控实战四
原创2021-04-01 20:35·博哥爱运维
prometheus发送报警
大家好,我是博哥爱运维所以目前在生产中用得更为多的是基于webhook来转发报警内容到企业中用的聊天工具中,比如钉钉、企业微信、飞书等。
prometheus的报警组件是Alertmanager,它支持自定义webhook的方式来接受它发出的报警,它发出的日志json字段比较多,我们需要根据需要接收的app来做相应的日志清洗转发
这里博哥将用golang结合Gin网络框架来编写一个日志清洗转发工具,分别对这几种常用的报警方式作详细地说明及实战
下载boge-webhook.zip
天翼云盘 珍藏美好生活 家庭云|网盘|文件备份|资源分享 (访问码:h1wx)
首先看下报警规则及报警发送配置是什么样的
prometheus-operator的规则非常齐全,基本属于开箱即用类型,大家可以根据日常收到的报警,对里面的rules报警规则作针对性的调整,比如把报警观察时长缩短一点等
1.第一步上传,上传完成后1.1看看就行,直接看第二步---node1
上传webhook到/mnt
ll /mnt/boge-webhook
1.2注意事先在配置文件 alertmanager.yaml 里面编辑好收件人等信息 ,再执行下面的命令
注意配置收件人的命名空间
##钉钉、飞书、微信
receivers:
- name: 'webhook'
webhook_configs:
# namespace(如果在default就删掉后面的)
# 修改url后要当重新删除alert pods
- url: 'http://alertmanaer-dingtalk-svc.kube-system//b01bdc063/boge/getjson'
# svc.default.svc
send_resolved: true
##看一下log有没有报错##看一下log有没有报错
kubectl logs alertmanager-main-0 -c alertmanager -n monitoring
kubectl logs alertmanaer-dingtalk-dp-84768f8464-vnpg8 -n monitoring
[GIN-debug] GET /status --> mycli/libs.MyWebServer.func1 (3 handlers)
[GIN-debug] POST /b01bdc063/boge/getjson --> mycli/libs.MyWebServer.func2 (3 handlers)
[GIN-debug] POST /7332f19/prometheus/dingtalk --> mycli/libs.MyWebServer.func3 (3 handlers)
[GIN-debug] POST /1bdc0637/prometheus/feishu --> mycli/libs.MyWebServer.func4 (3 handlers)
[GIN-debug] POST /5e00fc1a/prometheus/weixin --> mycli/libs.MyWebServer.func5 (3 handlers
1.1监控报警规划修改文件位置(看一下,现在不用真的改)
find / -name prometheus-rules.yaml
/mnt/kube-prometheus-master/manifests/prometheus-rules.yaml
修改完成记得更新 kubectl apply -f ./manifests/prometheus/prometheus-rules.yaml
# 通过这里可以获取需要创建的报警配置secret名称
# kubectl -n monitoring edit statefulsets.apps alertmanager-main
...
volumes:
- name: config-volume
secret:
defaultMode: 420
secretName: alertmanager-main
...
###
2.1删除原来的---node1-----每更新一次alertmanager.yaml,就要重新执行2.1----2.1、、或者重启pods
kubectl delete secrets alertmanager-main -n monitoring
2.2执行新的---在webhook文件夹
kubectl create secret generic alertmanager-main --from-file=alertmanager.yaml -n monitoring
secret/alertmanager-main created
##看一下log有没有报错##看一下log有没有报错
kubectl logs alertmanager-main-0 -c alertmanager -n monitoring
3.构建根据DockerFile镜像----记得改仓库名字、
docker build -t harbor.boge.com/product/alertmanaer-webhook:1.0 .
4.推送镜像
4.1先登录
docker login
4.2去服务器创建哥私有镜像仓库
4.3如果这里报错,去node04看看nginx的端口是不是被haproxy占用了ss -luntp|grep 443
如果被占用systemctl stop haproxy 然后在node04 cd /data/harbor ./install.sh重装harbor不会覆盖原来的数据-----------解决问题的感觉太爽了然后就可以访问了---提示查看svc
47.103.13.111/harbor/
回到node01
cd /mnt/boge-webhook
docker push harbor.boge.com/product/alertmanaer-webhook:1.0
5.vim alertmanaer-webhook.yaml-----也可以配置微信钉钉token
如果要拉私有仓库先在imagePullSecret建立密钥,在他的上一行有指定命令
配置钉钉地址/微信信息token
报警过滤把
imagePullSecrets:
- name: boge-secret
放到最后
6.所有节点做域名解析
echo "172.24.75.115 harbor.boge.com" >> /etc/hosts
7.创建secret命令格式
kubectl create secret docker-registry boge-secret --docker-server=harbor.boge.com --docker-username=admin --docker-password=boge666 --docker-email=admin@boge.com
kubectl apply -f alertmanaer-webhook.yamls
8.在转发查看日志
kubectl logs alertmanaer-dingtalk-dp-84768f8464-ktzx7
##看一下log有没有报错##看一下log有没有报错 kubectl logs alertmanager-main-0 -c alertmanager -n monitoring 每次修改alertmanger文件,都要重新创建sercert,删除main-pod重新生成
成功的截图,不报错

