
- 1用GVIM/VIM写Verilog——VIM配置分享_gvim svstemverilog 插件
- 2深度学习之RNN循环神经网络(理论+图解+Python代码部分)
- 3数据流分析(一)_数据流分析怎么写
- 4python 之弗洛伊德算法_floyd-warshall算法python代码
- 5FPGA 静态时序分析与约束(2)_quartus unconstrained path
- 6微信小程序开发与应用——字体样式设置_微信小程序style属性
- 7多无人机对组网雷达的协同干扰问题 数学建模
- 8Python实现mysql数据库验证_python3 构建一个源和目的都是mysql的数据校验程序
- 9Win10安装安卓模拟器入坑记_exagear win10
- 10岛屿数量(dfs)
hive数据仓库--Hive介绍_hive数据库
赞
踩
1 什么是Hive
Hive是基于Hadoop的⼀个数据仓库⼯具,⽤来进⾏数据提取、转化、加载,这是⼀
种可以存储、查询和分析存储在Hadoop中的⼤规模数据的机制。Hive数据仓库⼯具能
将结构化的数据⽂件映射为⼀张数据库表,并提供类SQL的查询功能,能将SQL语句转
变成 MapReduce 任务来执⾏。它是由Facebook开发,⽤于解决海量结构化⽇志的
数据统计⼯具。
2 Hive的本质
Hive通过HQL语⾔进⾏数据查询,本质上是将HQL语句转化为MapReduce任务。
下图展示HQL的查询过程。
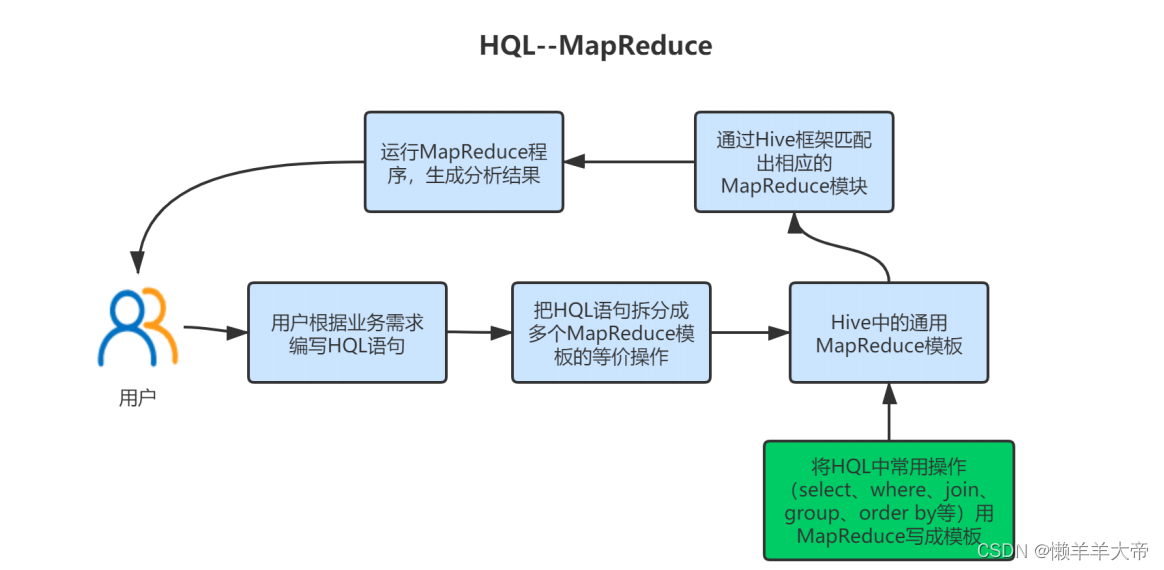
Hive中的数据存储在HDFS上
Hive分析数据是通过MapReduce实现的
Hive是运⾏在Yarn上的
所以Hive是运⾏在Hadoop之上的⼀种数据仓库⼯具。
3 Hive的优缺点
3.1 优点
Hive的查询采⽤类 SQL 的HQL语⾔,提供快速开发的能⼒(简单、容易上⼿)。
HQL可以⾃动转化成多个MapReduce任务,通过执⾏MapReduce任务达到数据操
作的⽬的。避免了开发⼈员去写 MapReduce的过程,学习成本低。
Hive 的执⾏延迟⽐较⾼,因此 Hive 常⽤于数据分析,对实时性要求不⾼的场合。
Hive⼗分适合对数据仓库进⾏统计分析。
Hive 优势在于处理⼤数据,对于处理⼩数据没有优势,因为 Hive 的执⾏延迟⽐较
⾼。
Hive ⽀持⽤户⾃定义函数,⽤户可以根据⾃⼰的需求来实现⾃⼰的函数。
Hive具有良好的可申缩性、可扩展性、容错性、输⼊格式的松散耦合。
3.2 缺点
Hive不适合⽤于联机事务处理(OLTP),也不提供实时查询功能。对实时性要求较
⾼的OLAP也不适⽤。
Hive 的 HQL 语⾔表达能⼒不⾜
⽆法表达迭代式算法
不擅⻓数据挖掘⼯作,由于 MapReduce 数据处理流程的限制,效率更⾼的算法
⽆法实现。
Hive 的效率⽐较低
Hive ⾃动⽣成的 MapReduce 作业不够智能化,存在任务冗余及任务调度不合理
情况。
Hive 调优⽐较困难,粒度较粗。
4 Hive架构
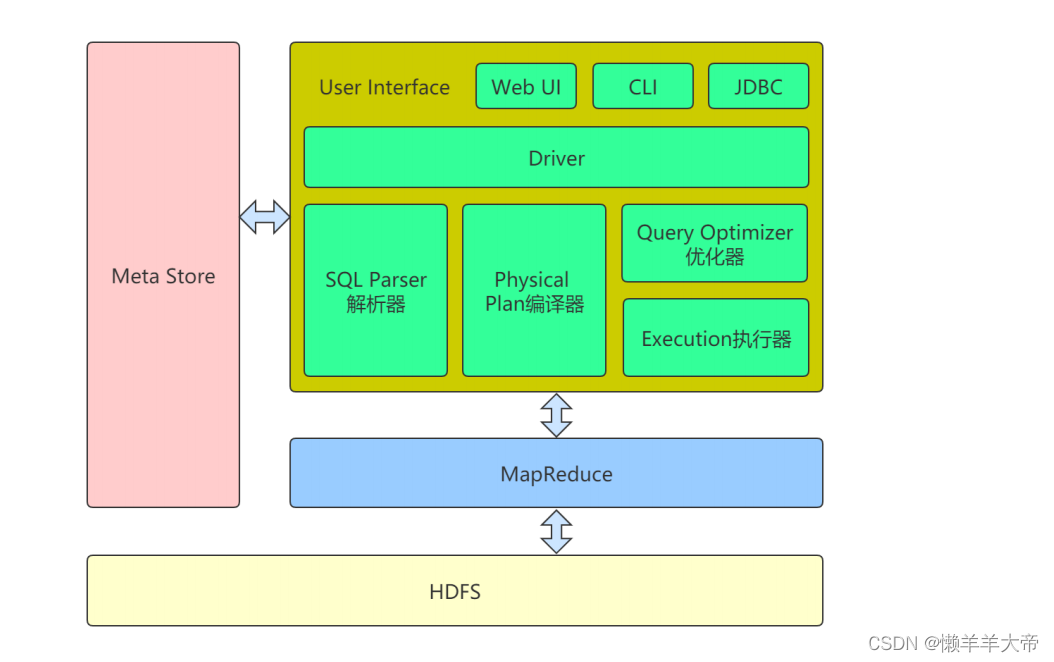
(1) ⽤户接⼝(User Interface)
⽤户访问Hive的接⼝,包括CLI(Command-Line Interface)、JDBC/ODBC(jdbc 访问 hive)、WebUI(浏览器访问 hive)⼏种形式。
(2) Driver
jdbc驱动程序
(3) SQL Parser解析器
将 SQL 字符串转换成抽象语法树 AST,这⼀步⼀般都⽤第 三⽅⼯具库完成,⽐如
antlr;对 AST 进⾏语法分析,⽐如表是否存在、字段是否存在、SQL 语义是否有误。
(4) Physical Plan编译器
将 AST 编译⽣成逻辑执⾏计划。
(5) Query Optimizer优化器
对逻辑执⾏计划进⾏优化。
(6) Execution执⾏器
把逻辑执⾏计划转换成可以运⾏的物理计划。对于 Hive 来 说,就是MapReduce。
(7) Meta Store (元数据)
元数据包括表名、表所属的数据库(默认是 default)、表的拥有者、列/分区字
段、 表的类型(是否是外部表)、表的数据所在⽬录等。默认存储在⾃带的 derby 数
据库中,推荐使⽤ MySQL 存储 Metastore。
4.1 Hive和Hadoop之间的⼯作流程
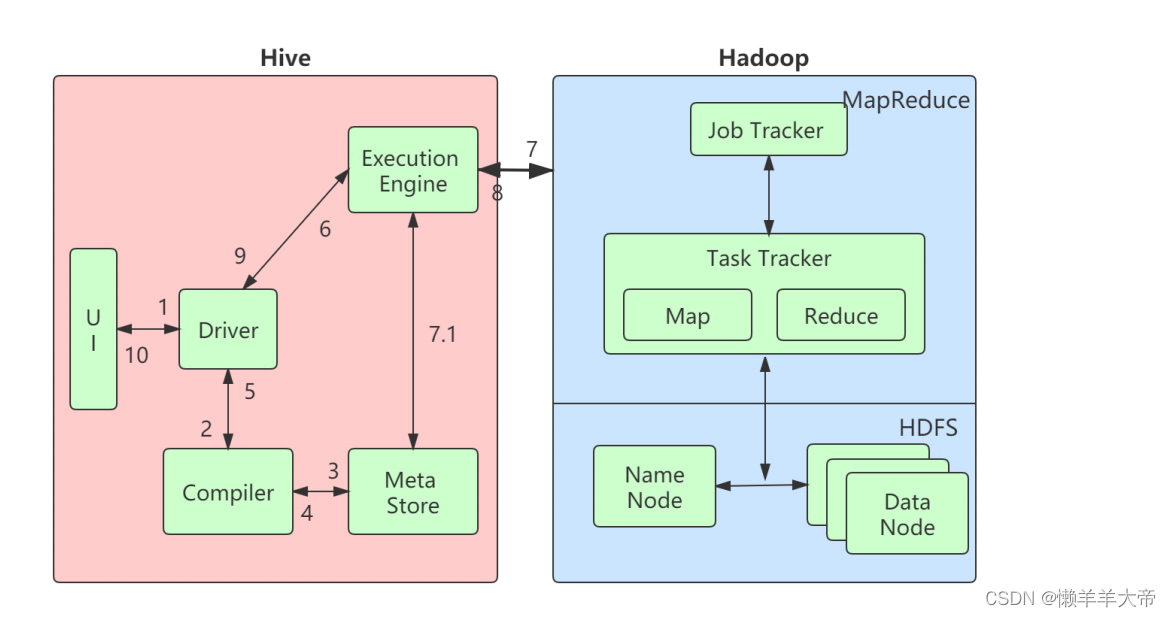
下表定义了Hive如何与Hadoop框架交互:
步骤号 操作
1 ”执⾏查询” Hive接⼝(如命令⾏或Web UI)向Driver(任何数据库驱动程
序,如JDBC,ODBC等)发送查询以执⾏。
2 ”获取计划” 驱动程序在查询编译器的帮助下解析查询以检查语法和查询计
划或查询的要求。
3 ”获取元数据” 编译器将元数据请求发送到Metastore(任何数据库)。
4
”发送元数据” Metastore将元数据作为响应发送给编译器。
5
”发送计划” 编译器检查需求并将计划重新发送给驱动程序。到此为⽌,查
询的解析和编译已完成。
6
”执⾏计划” 驱动程序将执⾏计划发送给执⾏引擎。
7 ”执⾏作业” 在内部,执⾏作业的过程是⼀个MapReduce作业。执⾏引擎
将作业发送到名称节点中的JobTracker,并将该作业分配给数据节点中的
TaskTracker。在这⾥,查询执⾏MapReduce作业。
7.1 ”元数据操作” 同时在执⾏时,执⾏引擎可以使⽤Metastore执⾏元数据操
作。
8 ”取结果” 执⾏引擎从Data节点接收结果。
9 ”发送结果” 执⾏引擎将这些结果值发送给驱动程序。
10 ”发送结果” 驱动程序将结果发送给Hive Interfaces。
5 Hive与数据库的⽐较
Hive虽然采⽤了类似SQL的查询语⾔HQL(Hive Query Language),但除了查询
语⾔相似之外,不要把Hive理解成是⼀种数据库。
数据库主要应⽤于在线事务处理(OLTP)和在线分析处理(OLAP),强调的是
事务的时效性与可靠性。⽽Hive是⼀种数据仓库技术,主要⽤应于对时效性要求不⾼的
批量数据统计分析,它强调的是数据处理的吞吐率。
下⾯介绍两者之间的主要差别:
5.1 数据规模⽅⾯
Hive集群采⽤的是分布式计算技术,天然⽀持并⾏计算,具有很好的申缩性、可扩
展性、安全性。因此可以⽀持很⼤规模的数据。
数据库集群⼀般采⽤的是分库分表的技术,⽀持纵向扩展,但难以进⾏横向扩展,
集群规模较⼩,所以数据库可以⽀持的数据规模较⼩,申缩性、可扩展性不好。
5.2 查询语⾔⽅⾯
SQL被⼴泛的应⽤于数据库技术中,有着⼴泛的⽤户群体,为了降低初学者的学习
成本。因此,把Hive的查询语⾔HQL设计成了类 SQL 的查询语⾔。熟悉 SQL 的开发者
可以很⽅便地使⽤ Hive。
5.3 数据更新⽅⾯
Hive数据仓库具有读多写少的特点。因此,Hive不建议对数据进⾏改写,所有的数
据都是在加载的时候确定好的。原因是Hive是建⽴在Hadoop基础上的,⽽HDFS是只⽀
持追加数据不⽀持修改数据。
数据库中的数据要保证能够随时查询、新增、修改和删除。
5.4 执⾏延时⽅⾯
Hive执⾏延时⾼主要有两个原因:
(1)查询⼀般不使⽤索引,需要扫描整个表
(2)采⽤ MapReduce 框架。由于 MapReduce 本身具有较⾼的延迟,因此Hive也
有较⾼的延迟。
数据库的执⾏延迟较低是有条件的,即数据规模较⼩,当数据规模⼤到超过数据库
的处理能⼒的时候,Hive 的并⾏计算就能体现出优势。
5.5 应⽤场景⽅⾯
Hive主要应⽤于时实性要求不⾼的⼤规模数据的统计分析;数据库主要应⽤于数据
规模较⼩、实时性要求较⾼的在线事务处理(OLTP)和在线分析处理(OLAP)。

