
- 1移动电视盒子cm311-1a安装armbian 运行MMDVMHost 成功_cm311-1a armbian
- 2RabbitMQ连接错误_rabbitmq连接不上
- 3vc++ Windows Shell 编程 第一章_vc++ shell
- 4【收藏】2019届互联网大厂公司校招薪资汇总,基本年薪都在20万以上_滴滴校招2019薪水 产品
- 5Springboot+Vue项目-基于Java+MySQL的农产品直卖平台(附源码+演示视频+LW)
- 6php调用mysql查询结果_php - 在php脚本中处理select查询结果集
- 7学习FPGA之五:工具链
- 8uni-app App权限配置参数详情_uniapp 通知权限 android.permission.
- 9小白学习微信小程序的图片处理和预览技巧_微信小程序 图片处理
- 10论文笔记--Coupled Layer-wise Graph Convolution for Transportation Demand Prediction_nyctaxi数据集论文
机器学习中的高斯过程简介_高斯过程 各符号的含义
赞
踩
本文符号的意义
X
X
X: 训练样本集输入特征
y
y
y: 训练样本对应的输出值
X
∗
X_*
X∗:待预测样本点输入特征
y
∗
y_*
y∗:带预测样本点的预测值
K
K
K: 核函数
θ
i
\theta_i
θi:核函数的参数
m
m
m: 均值向量
Σ
\Sigma
Σ: 协方差阵
d
d
d: 表征样本之间的相似度,
d
=
X
−
X
′
d=X-X'
d=X−X′
N
\mathcal{N}
N:高斯分布函数
Φ
\Phi
Φ: 累积高斯分布函数
核心思想
输出
y
y
y服从多维高斯分布,特征
X
X
X估计多维高斯分布参数。
GPR :核函数估计
Σ
\Sigma
Σ,构建
y
∗
与
y
y_*与y
y∗与y的联合高斯分布,进而计算得到
y
∗
y_*
y∗的条件概率分布,均值即为预测值,方差即为不确定性估计。
GPC : probabilistic classification,采用logistic函数"squash"隐藏变量
f
f
f(服从高斯分布),然后积分求得概率值。
预备知识
多维高斯分布
多维高斯分布含有两个重要的参数:
均值向量 :均值向量不影响函数形态。
协方差阵 :各个维度上变量间协方差阵决定了函数的形态。
多维高斯分布表达式如下(
μ
为
各
个
变
量
均
值
构
成
的
均
值
向
量
,
Σ
为
协
方
差
阵
\mu为各个变量均值构成的均值向量,\Sigma为协方差阵
μ为各个变量均值构成的均值向量,Σ为协方差阵):
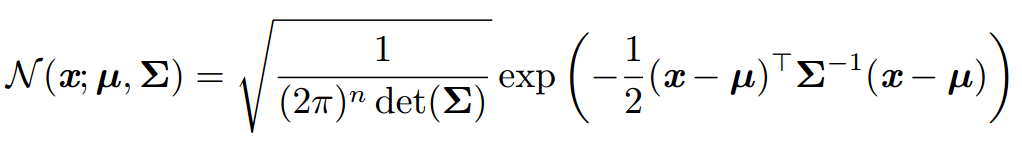

(图片摘自维基百科)
随机过程
随机变量随时间改变的过程称为随机过程。这里的时间泛指过程涉及的所有参数。从动态角度看,一个n维随机变量就是一个随机过程。例如,依次掷6次色子,得到的点数
[
X
1
,
X
2
,
X
3
,
X
4
,
X
5
,
X
6
]
[X1, X2,X3,X4,X5,X6]
[X1,X2,X3,X4,X5,X6](考虑样本二重性,在没有观测时就是随机变量),这就是一次随机过程,该过程的参数就是时间序列
T
=
[
0
,
1
,
2
,
3
,
4
,
5
,
6
]
T=[0,1,2,3,4,5,6]
T=[0,1,2,3,4,5,6](只要点数与时间参数对应即可,可以无序)。一次随机过程产生的观测值(例如
[
1
,
3
,
5
,
2
,
1
,
3
,
6
[1,3,5,2,1,3,6
[1,3,5,2,1,3,6)称之为样本向量。总之,一个样本的产生需要先指定参数,获取统计分布函数,最终生成观测值集合。
据此,给出随机过程的定义如下:
样本空间
Ω
=
{
ω
}
\Omega=\{\omega\}
Ω={ω},参数集
T
∈
(
−
∞
,
+
∞
)
T\in(-\infin,+\infin)
T∈(−∞,+∞),如果对于任意
t
∈
T
t\in T
t∈T,存在随机变量
X
(
ω
,
t
)
X(\omega,t)
X(ω,t),那么随机变量构成的簇
{
X
(
ω
,
t
)
,
t
∈
T
}
\{X(\omega,t),t\in T\}
{X(ω,t),t∈T}(随机变量的集合)就是一个随机过程。
高斯过程
高斯过程就是一个随机过程。随机变量就是 y y y,样本空间就是 y y y的取值范围。 y y y的集合就是一个随机过程。在这个随机过程中,随机变量服从多维高斯分布,相应的参数集 T T T就是 ( m , Σ ) (m,\Sigma) (m,Σ)可以表示为: y = f ( X ) + N ( 0 , σ n 2 ) f ( X ) = g ( m ( X ) , K ( X ) ) y=f(X)+\mathcal{N}(0, \sigma_n^2)\\f(X)=g(m(X), K(X)) y=f(X)+N(0,σn2)f(X)=g(m(X),K(X))其中, f ( X ) f(X) f(X)就是一个特定的多维高斯分布, N ( 0 , σ n 2 ) N(0, \sigma_n^2) N(0,σn2)是噪音项, m ( X ) m(X) m(X)是高斯分布的均值向量,通常在机器学习中设置为零向量。 Σ \Sigma Σ用核函数 K ( X ) K(X) K(X)估计,因此实际模型的超参数主要是核函数的参数 { θ i } \{\theta_i\} {θi}。
核函数
核函数用来估计多维高斯分布的协方差阵,需要设定初始超参数。高斯过程是根据 X 与 X ∗ X与X_* X与X∗的相似度来获取 y 与 y ∗ y与y_* y与y∗的联合分布的,而核函数决定了如何衡量相似度。一方面,基于对样本间相似性的理解,选择合适的核函数,例如存在周期性可选用ExpSineSquared 核函数;另一方面,可以对相似性进行分解,对不同的相似性采用不同的核函数,然后对核函数进行组合,例如可将相似性拆分为总体以及局部两方面等。
常用的核函数

(图片摘自维基百科)
可以发现,大多数核函数均含有一个超参数
l
\mathcal{l}
l,称为length_scale,用以控制smoothness
特点
stationary:核函数的取值仅取决于
d
d
d,与具体的
X
X
X值无关。显然线性核函数是non-stationary
isotropy:核函数取值仅取决于
∣
d
∣
|d|
∣d∣,而与
d
d
d的方向无关。
smoothness:直观地理解就是核函数值对
∣
d
∣
|d|
∣d∣越敏感,smoothness越小
Periodicity:核函数是周期性函数
一个核函数同时满足stationary以及isotropy,则称函数是homogeneous,这类核函数使用较多。
高斯过程回归(GPR)
训练
训练的目的就是获得核函数的参数。
预先设定的核函数参数
{
θ
i
}
\{\theta_i\}
{θi}显然是不够准确的,需要根据样本的信息对参数进行调节,得到后验高斯过程。采用极大似然估计的方法求解核函数的参数。最大化对数边缘似然函数(LML):
L
=
l
o
g
p
(
y
∣
x
,
θ
i
)
=
−
1
2
l
o
g
∣
∑
∣
−
1
2
(
y
−
μ
)
T
∑
−
1
(
y
−
μ
)
−
2
n
l
o
g
(
2
π
)
L=log{p(y∣x,θ_i)}=−\frac12 log∣∑∣−\frac12(y−μ)^T∑^{−1}(y−μ)−2nlog(2π)
L=logp(y∣x,θi)=−21log∣∑∣−21(y−μ)T∑−1(y−μ)−2nlog(2π)(注:参考机器学习中的高斯过程的推导)
预测
假设待预测的样本有
n
∗
n_*
n∗个,
n
∗
个
y
∗
n_*个y_*
n∗个y∗来自
n
∗
n_*
n∗维高斯分布。假设训练数据集中有
n
个
y
n个y
n个y,来自于
n
n
n维高斯分布。根据高斯分布的可加性,
(
y
y
∗
)
\left(
高斯过程分类(GPC)
回归与分类的本质是一致的。我们同样可以进行回归分析,然后采用Sigmoid函数将回归预测值转化为概率值(英文文献通常用"squash"形容这一过程,即将预测值压缩到[0,1]区间),最后通过概率判别所属类即可。例如逻辑斯蒂回归就是先采用线性回归,然后采用logistic函数进行"squash"。逻辑斯蒂回归模型可表示如下 p ( y ∣ X ) = 1 1 + e − y f ( X ) p(y|X)=\frac1{1+e^{-yf(X)}} p(y∣X)=1+e−yf(X)1其中, y ∈ { 1 , − 1 } y\in \{1,-1\} y∈{1,−1}。 f ( X ) = w X f(X)=wX f(X)=wX。先给出初始 w = I w=I w=I,经过训练得到后验的 w w w。
训练
高斯过程与逻辑斯蒂回归类似,同样采用logistic函数进行"squash",只不过将线性回归模型改为先验高斯函数 f ( X ) = N ( 0 , K ( X ) ) f(X)=\mathcal{N}(0, K(X)) f(X)=N(0,K(X)),先给出初始核函数参数 θ \theta θ,经过训练后获得后验最优的核函数超参数。训练过程同GPR,即最大化对数边缘似然函数。
预测
首先获得待预测样本对应的
f
f
f的多维高斯分布(后验分布),不用关心隐藏变量
f
f
f的值,在后续积分中会消除。这不同于逻辑回归,需要计算出线性回归值。即
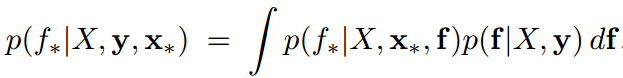
式中,f为训练样本对应的隐藏变量。积分求得概率值,即
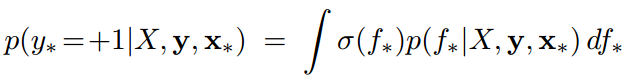
式中,
σ
\sigma
σ即为logistic函数。积分结果为
p
(
y
∗
=
+
1
)
=
Φ
(
μ
∗
1
+
σ
∗
2
)
p(y_*=+1)=\Phi(\frac{\mu_*}{\sqrt{1+\sigma_*^2}})
p(y∗=+1)=Φ(1+σ∗2
μ∗)其中
μ
∗
,
σ
∗
\mu_*,\sigma_*
μ∗,σ∗分别为待预测点对应的均值以及标准差(均值向量以及协方差矩阵的计算同GPR)。
多分类
当用于多分类时,采取的方式与支持向量机多分类方式一致,即"one VS rest"和"one VS one"。注意,采用"one VS one"方式时,n个类的多分类问题的核函数有 C n 2 C_n^2 Cn2个。
Tikhonov正则化
当数据中存在噪声时,为防止过拟合需要进行Tikhonov正则化,即协方差阵的对角元素加上参数alpha(噪声水平),另一种替代方式是在原有核函数基础上加一个WhiteKernel。
优缺点
优点
- 给出预测值的概率,给出置信区间
- 可以个人定制核函数形式
缺点
- 不稀疏,训练过程需要用到所有的样本以及特征
- 高维情况下效率低,尤其当维度超过几十个时
为什么用核函数计算协方差矩阵?
高斯过程的各个变量
y
y
y间是互相联系的,这种联系体现在协方差阵上,我们也是利用待预测点与样本点间的联系来得到预测值的。
假设不用核函数(也就是不使用
y
y
y对应的特征)没办法得到各个样本点间的协方差,协方差矩阵除对角线元素外全部为零,导致自变量
y
y
y之间毫无联系。
例如(参考资料1中举的例子,这里重写一下代码):
import matplotlib.pyplot as plt import numpy as np from itertools import cycle color_cycle = cycle('kbryg') n_variable = 20 n_sample = 5 plt.figure(figsize=(500, 300)) sigma_s = np.eye(n_variable) # 协方差阵为对角矩阵 for _ in range(n_sample): point = np.random.multivariate_normal(np.zeros(n_variable), sigma_s) plt.plot(np.arange(n_variable), point, color=next(color_cycle)) plt.scatter(np.arange(n_variable), point) plt.rcParams['font.sans-serif'] = ['SimHei'] # 正确显示中文 plt.rcParams['axes.unicode_minus'] = False # 正确显示负号 plt.title('不使用核函数的情况', fontsize=24) plt.xticks(np.arange(n_variable)) plt.xlabel('y', fontsize=20) plt.show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21

核函数来估计协方差,能很好反映各个变量
y
y
y间的关系。因为核函数充分考虑了样本间的相似性(大多用
d
d
d度量)。
例如采用squared exponential核函数后,曲线变得平滑了:
xs = np.linspace(0, 1, n_variable) # 构建y对应的特征
sigma_s = np.exp(-(np.expand_dims(xs, axis=0) - np.expand_dims(xs, axis=1)) ** 2 / 2) # 依据特征xs构建协方差阵- 1

代码
重构参考资料1中GPR的示例代码。
import numpy as np from scipy.optimize import minimize from scipy.spatial.distance import pdist, cdist, squareform class Kernel: # RBF核函数 def __init__(self, theta): self.theta = theta def __call__(self, X, Y=None): if Y is None: dists = pdist(X / self.theta, metric='sqeuclidean') K = np.exp(-0.5 * dists) K = squareform(K) np.fill_diagonal(K, 1) else: dists = cdist(X / self.theta, Y / self.theta, metric='sqeuclidean') K = np.exp(-0.5 * dists) return K class GPR: def __init__(self): self.K = None self.X = None self.y = None def log_marginal_likelihood(self, theta): # 计算对数边缘似然函数 K = Kernel(theta) sigma = K(self.X) log_likelihood = np.log(np.linalg.det(sigma)) + \ self.y @ np.linalg.inv(sigma) @ self.y + \ sigma.shape[0] * np.log(2 * np.pi) return - 0.5 * log_likelihood def fit(self, X, y): # 训练,获取核函数最优参数 self.X = X self.y = y def obj_func(theta): return - self.log_marginal_likelihood(theta) theta_opt = minimize(obj_func, np.array([1.0]), method='BFGS') self.K = Kernel(theta_opt.x[0]) def predict(self, X_pred): # 预测,获取y*的条件概率分布 K_pred = self.K(X_pred) K_train = self.K(self.X) K_pred_train = self.K(self.X, X_pred) K_inv = np.linalg.inv(K_train) mu = K_pred_train.T @ K_inv @ self.y sigma = K_pred - K_pred_train.T @ K_inv @ K_pred_train return mu, np.diagonal(sigma) if __name__ == '__main__': import matplotlib.pyplot as plt gpr = GPR() # 生成样本数据 coefs = [6, -2.5, -2.4, -0.1, 0.2, 0.03] def f(x): total = 0 for exp, coef in enumerate(coefs): total += coef * (x ** exp) return total xs = np.linspace(-5.0, 3.5, 100) ys = f(xs) X_train = np.array([-4, -1.5, 0, 1.5, 2.5, 2.7]) y_train = f(X_train) X_train = X_train.reshape(-1, 1) X_pred = np.linspace(-8, 7, 80).reshape((-1, 1)) gpr.fit(X_train, y_train) y_pred, y_std = gpr.predict(X_pred) plt.plot(xs, ys, color='k', linewidth=2, label='True') plt.scatter(X_train, y_train, color='b', marker='*', linewidths=3, label='Train_data') plt.plot(X_pred, y_pred, color='r', label='Pred') plt.fill_between(X_pred.reshape(1, -1)[0], y_pred - y_std, y_pred + y_std, color='darkorange', alpha=0.2) plt.legend() plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
结果如图所示:


