
- 1自然语言处理中的情感分析:技术与应用
- 22023年如何面试大厂?分享阿里、美团、滴滴Java岗面试真题_滴滴出行java面试题
- 3【Spring Boot】使用Websocket实现点对点通信_springboot @sendtouser
- 429.云原生KubeSphere服务网格实战之Istio安装配置_kubesphere安装istio
- 5【Git】git push时出现文件冲突的解决办法_git push 冲突
- 6webservice中常用注解--------------------@WebService @WebMethod
- 7锁相环技术原理及FPGA实现(第二章2.3)_quartus中altfp_abs是什么
- 8python数据结构之字典(dict)——超详细_创建一个字典dic,初始化账号和密码,使用字典的特点,如果输入的账号、密码与di
- 9【C语言三种自定义类型】_c语言当中用户自定义的类型
- 10讯飞语音识别_清晰识别多人混叠的对话!科大讯飞语音识别技术再攀新高
【图像融合】融合算法综述(持续更新)_利用多通道的图像融合技术,实现图像的增强问题的设计方案
赞
踩
按时间顺序,综述近5年的融合算法。重点分析了最近两年的work,欢迎留言探讨
文章目录
- 前言
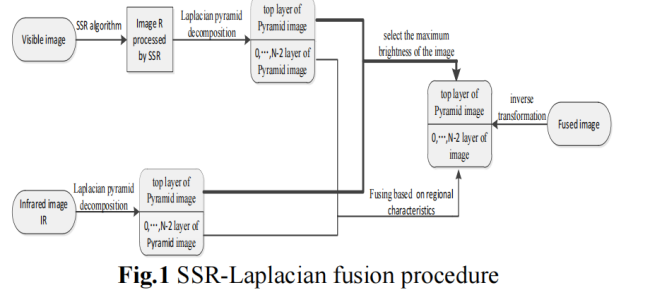
- 1.SSR-Laplacian Image Fusion(2017)
- 2、FusionGAN(2019)
- 3、MBNet(2020)
- 4、DIDFuse(2020)
- 5、DDcGAN(2020)
- 6、GAN(2020)
- 7、NestFuse(2020)
- 8、AUFusion(2021)
- 9、AttentionFGAN
- 10、GANMcC
- 11、DRF(2021)
- 12、SDNet(2021)
- 13、RFN-Nest(2021)
- 14、PIAFusion(2022)
- 15、SeAFusion(2022)
- 16、SwinFusion(2022)
- 17、DIVFusion(2023)
- 18、CDDFuse(CVPR2023)
- 19、DDcGAN:多分辨率图像融合的双识别条件GAN
- 20、GANMcC:多分类约束的红外可见图像融合GAN
- 21.AttentionFGAN:基于注意力GAN的红外和可见图像融合
- 总结
前言
提示:以下是本篇文章正文内容,下面案例可供参考
1.SSR-Laplacian Image Fusion(2017)
论文:R. Wu, D. Yu, J. Liu, H. Wu, W. Chen and Q. Gu, “An improved fusion method for infrared and low-light level visible image,” 2017 14th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), 2017, pp. 147-151.
本文提出了一种融合低照度可见光图像和红外图像的方法。本文主要是增加了图像的预处理步骤,后续过程是一些传统处理方法的组合和延伸。SSR(Single Scale Retinex)算法,一种基于Retinex的人眼生理特征所发展起来的算法,用于提升可见光图像的对比度。

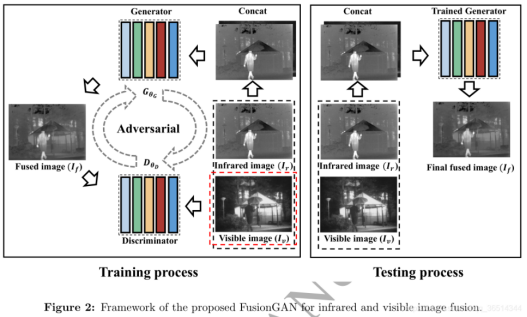
2、FusionGAN(2019)
论文:Jiayi Ma, Wei Yu, Pengwei Liang, Chang Li, and Junjun Jiang. FusionGAN: A generative adversarial network for infrared and visible image fusion. Information Fusion 48, C (Aug 2019), 11–26, 2019.
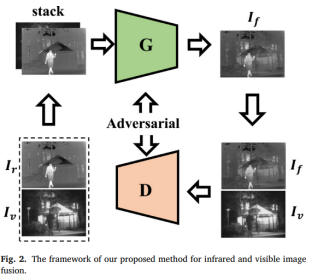
本文提出FusionGAN,将GAN运用到图像融合的任务中。红外图像Ir和可见光图像Iv按通道连接后输入生成器,输出为融合图像If。考虑可见图像中的纹理细节没有被充分提取,将融合后的图像If和可见图像Iv输入鉴别器中,使得If有更多的纹理细节。生成器旨在生成具有显著红外强度和附加可见梯度的融合图像,鉴别器旨在强制融合图像拥有可见图像的更多细节信息。
损失函数
生成器:
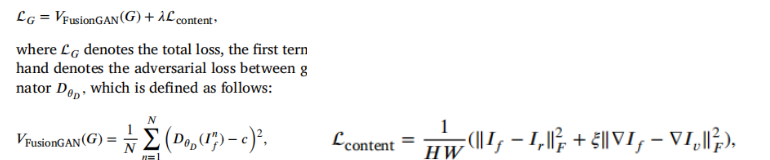
判别器:
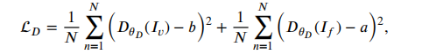
3、MBNet(2020)
Zhou, Kailai et al. “Improving Multispectral Pedestrian Detection by Addressing Modality Imbalance Problems.” European Conference on Computer Vision (2020).
模态不平衡问题主要分为两方面:照明模态不平衡(光照变化)以及特征模态不平衡(红外与可见特征未配准,以及不恰当的融合方式)。本文设计了差分模态感知融合(DMAF,Differential Modality Aware Fusion)模块,使两种模态相互补充。照明感知特征对齐(IAFA,Illumination Aware Feature Alignment Module)模块根据光照条件选择互补特征,并自适应对齐两个模态特征。
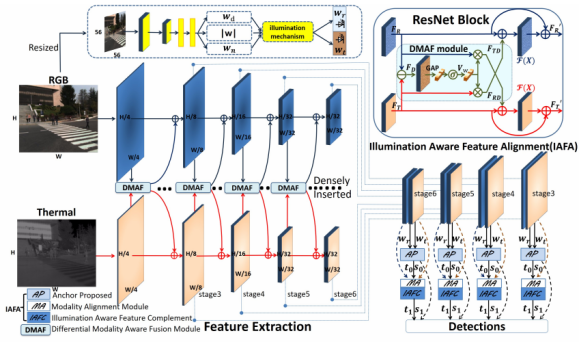
DMAF模块中每个模态都包含共同部分和差异部分。
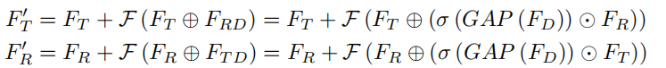
先对两个模态特征直接相减获取差异特征,然后对差异特征做全局平均池化,再进行tanh激活,然后对原始特征进行通道级加权,加权后的特征加到另一模态特征上。
IAFA模块用了一个可以根据可见光图像预测光照条件的小网络,其损失定义如下:
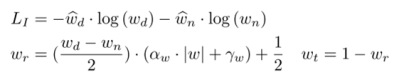
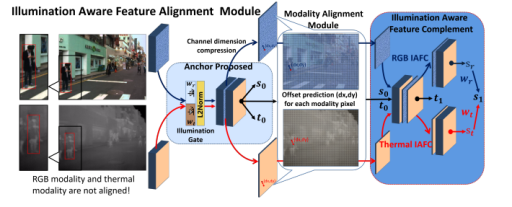
由于红外和可见光相机并不都是同时拍摄的,这就会导致特征无法对齐。故提出了一个模态特征对齐(MA,Modality Alignment)模块来为每种模态的每个像素点(x, y)都预测一个特征偏移(dx, dy),由于特征偏移为浮点数,故采用了双线性插值用邻近点的值进行拟合(x+dx, y+dy)。
IAFA模块先将重赋权的RGB和红外特征拼接,在anchor proposed阶段产生一个大概的anchor位置。在IAFC阶段所预测的回归偏移t0用来产生可变形的anchor来作为位置预测的基本参考。然后可变形的anchors和置信度得分s0进一步通过IAFC阶段进行微调。RGB和红外特征图预测的置信度得分进一步通过光照值进行重新加权。最终的置信度得分和回归偏移值如下:
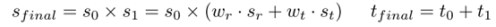
分类损失函数使用了focal loss,来解决样本不平衡问题。
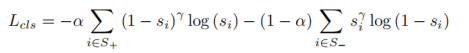
4、DIDFuse(2020)
Zixiang Zhao, Shuang Xu, Chunxia Zhang, Junmin Liu, Jiangshe Zhang and Pengfei Li, DIDFuse: Deep Image Decomposition for Infrared and Visible Image Fusion. IJCAI 2020: 970-976.
本模型有效的利用了先验信息,即base信息代表着大尺度的背景信息, detail信息是互异性较明显的信息,即红外和可见的base信息尽可能接近,两者的detail信息尽可能差异较大。经过训练,模型获得了训练好的encoder和decoder,然后进入测试阶段。在测试过程中,添加一个fusion layer,即融合层,实现和的融合,和的融合,然后把其进行拼接,输入decoder实现图像重构。对于融合策略的选择有以下三种策略:直接相加、给定权重相加和L1-norm(把feature map的L1范数看作其activity measurement,然后通过计算不同feature map的L1-norm来给定不同融合权重)。
损失函数
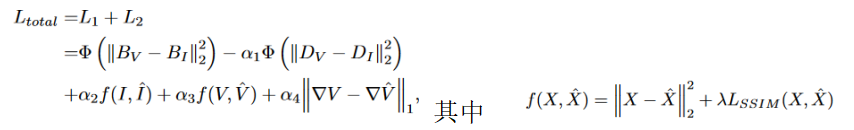
5、DDcGAN(2020)
J. Ma, H. Xu, J. Jiang, X. Mei and X. -P. Zhang, “DDcGAN: A Dual-Discriminator Conditional Generative Adversarial Network for Multi-Resolution Image Fusion,” in IEEE Transactions on Image Processing, vol. 29, pp. 4980-4995, 2020.
本文在FusionGAN的基础上设计了双判别器。为了融合不同分辨率的图像,作者假设可见图像的分辨率是红外图像分辨率的4×4倍,判别器Dv旨在将生成的图像与可见图像区分开,而判别器Di旨在区分原始的低分辨率红外图像和下采样(平均池化)的融合图像。为了在生成器和判别器之间保持平衡,每个判别器的输入层是包含样本数据的单通道,而不是同时包含样本数据和对应的源图像作为条件信息的两通道。
6、GAN(2020)
J. Ma et al.,“Infrared and visible image fusion via detail preserving adversarial learning,” Information Fusion, vol. 54, pp. 85–98, Feb. 2020.
本文的模型用于改善先前GAN模型带来的细节损失问题,并且加入了针对边缘的保护机制。模型的生成器产生融合图像,然后,融合结果与可见光源图像一起送入判别器,判断融合结果是否来自于可见光图像。
损失函数:
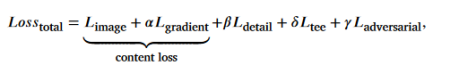

7、NestFuse(2020)
H. Li, X. -J. Wu and T. Durrani, “NestFuse: An Infrared and Visible Image Fusion Architecture Based on Nest Connection and Spatial/Channel Attention Models,” in IEEE Transactions on Instrumentation and Measurement, vol. 69, no. 12, pp. 9645-9656, Dec. 2020.
本文是基于nest connection和空间/通道注意力的红外-可见光融合模型,可以在多尺度方面保留重要信息。模型分为编码器、融合策略和解码器三部分。在融合策略中,空间注意力模型和通道注意力模型分别用来描述深度特征在每个空间位置和通道的重要性。首先输入图像送入编码器提取多尺度特征,融合策略在每个尺度上融合这些特征,最后通过基于nest connection的解码器重构图像。
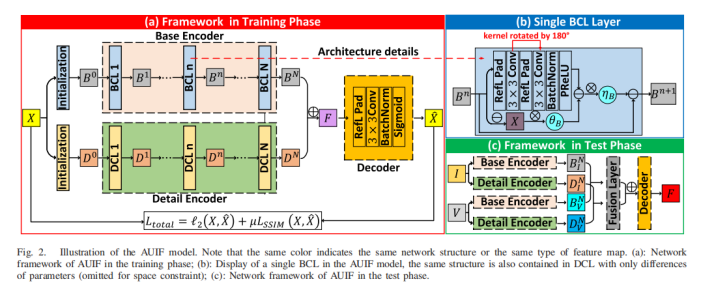
8、AUFusion(2021)
Zixiang Zhao, Shuang Xu, Jiangshe Zhang, Chengyang Liang, Chunxia Zhang and Junmin Liu, “Efficient and Model-Based Infrared and Visible Image Fusion via Algorithm Unrolling,” in IEEE Transactions on Circuits and Systems for Video Technology,2021.
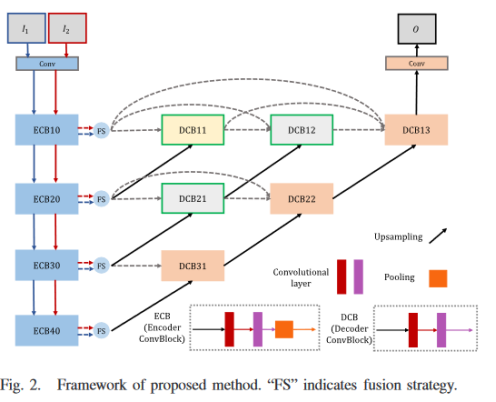
本文利用算法展开的方式构建网络,增加了网络的可解释性。首先预训练一个自编码器用来实现特征提取和图像重建。再采用一些手工设计的融合策略(基于像素的加权平均)来整合从不同源图像中提取的深度特征以实现图像融合。训练时,红外与可见光交替输入网络;测试时,红外与可见成对输入。网络中特征B0和D0分别通过blur和Laplacian滤波器得到。
BCL和DCL模块设计,X表示输入图像,B,D分别表示base feature和detail feature,另外
gBj 表示高通滤波,gDj 表示低通滤波。
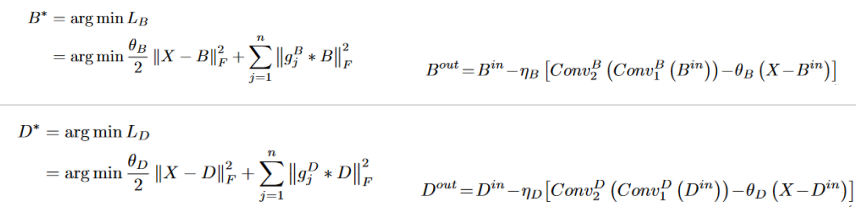
损失函数:
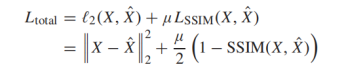
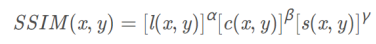
SSIM 衡量两张图片的相似性,该损失使重建图像在亮度、结构和对比度方面接近源图像。
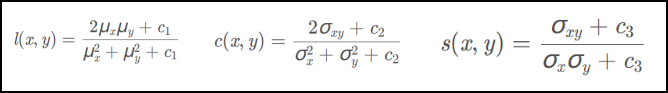
9、AttentionFGAN
J. Li, H. Huo, C. Li, R. Wang and Q. Feng, “AttentionFGAN: Infrared and Visible Image Fusion Using Attention-Based Generative Adversarial Networks,” in IEEE Transactions on Multimedia, vol. 23, pp. 1383-1396, 2021.
本文将多尺度注意力机制加入GAN来进行红外-可见光图像的融合。多尺度注意力机制旨在捕获全面的空间信息,帮助生成器关注红外图像的前景目标信息和可见光图像的背景细节信息,同时约束判别器更多地关注注意区域而不是整个输入图像。生成器部分是两个多尺度注意力模块首先分别获得红外与可见光图像的注意力图,然后将这两个注意力图和源图像在通道维度拼接后送入融合网络。两个判别器分别用来区分融合图像与红外/可见光图像,结构完全相同,但是参数不共享。
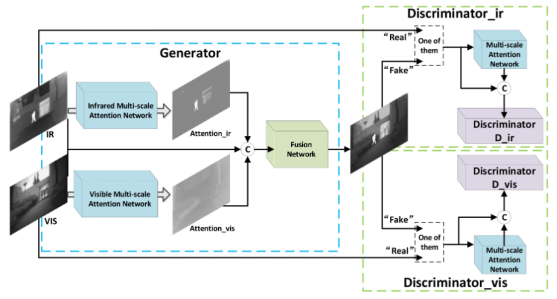
损失函数
生成器:
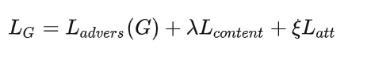
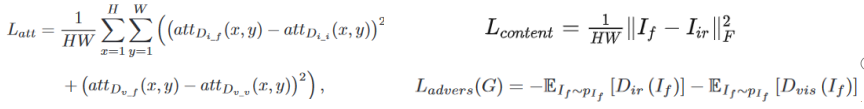
判别器:前两项表示 Wasserstein distance 估计,最后一项是网络正则化的梯度惩罚
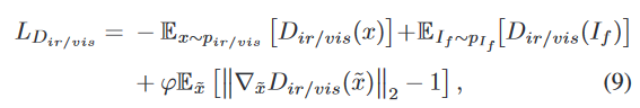
10、GANMcC
J. Ma, H. Zhang, Z. Shao, P. Liang and H. Xu, “GANMcC: A Generative Adversarial Network With Multiclassification Constraints for Infrared and Visible Image Fusion,” in IEEE Transactions on Instrumentation and Measurement, vol. 70, pp. 1-14, 2021.
红外图像的细节信息不一定比可见光差,Rgb图像也有可能对比度优于红外图像。融合图像既有显著的对比度又有丰富的纹理细节,关键是保证源图像的对比度和梯度信息是平衡的,本质上是同时估计两个不同域的分布。GAN可以在无监督情况下更好地估计目标的概率分布,而多分类GAN 可以进一步同时拟合多个分布特征,解决这种不平衡的信息融合。当可见图像过度曝光时,红外图像的相应信息可以弥补,这使得我们的方法能够在保持显著对比度的同时去除高光。
网络架构
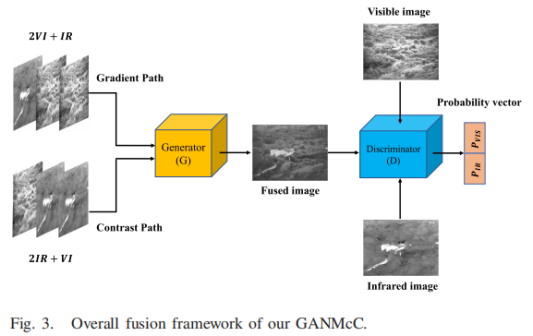
对于生成器,输入也是两个模态的混合输入,由生成器得到融合图像。对于判别器,输入图像(红外/可见光/融合图像任选一个输入)进行分类得到输入图像的类别,输出是一个包含两个概率值的向量。对于融合图像,在多分类约束下,generator期望这两个概率都很高,即判别器认为它既是红外图像又是可见图像,而判别器期望这两个概率同时很小 ,即判别器判断融合图像既不是红外图像也不是可见图像。在此过程中,同时约束这两个概率,以确保融合图像在两个类别中的true/false程度相同。经过不断的对抗学习,生成器可以同时拟合红外图像和可见图像的概率分布,从而产生对比度显着和纹理细节丰富的结果。
损失函数
生成器:通过调整权重β的大小来决定每种信息的保留程度,d设置为1。
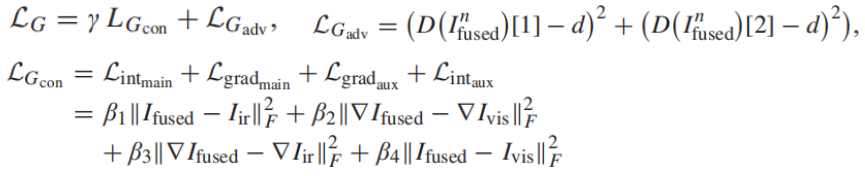
判别器:c设置为0。
11、DRF(2021)
[11]H. Xu, X. Wang and J. Ma, “DRF: Disentangled Representation for Visible and Infrared Image Fusion,” in IEEE Transactions on Instrumentation and Measurement, vol. 70, pp. 1-13, 2021.
本文将Rgb和红外图像通过相应的编码器分解为与场景和传感器模态(属性)相关的表示。两个scene encoder 和两个 attribute encoder 具有相同的结构但是不共享参数。考虑到场景信息与空间和位置直接相关,故scene representation以特征图的形式呈现,而属性与传感器模态相关,不会承载场景信息,故attribute representation以向量形式呈现。然后应用不同的策略(基于像素的加权平均)来融合这些不同类型的表示。最后融合的表示被送入预训练的生成器以生成融合结果。
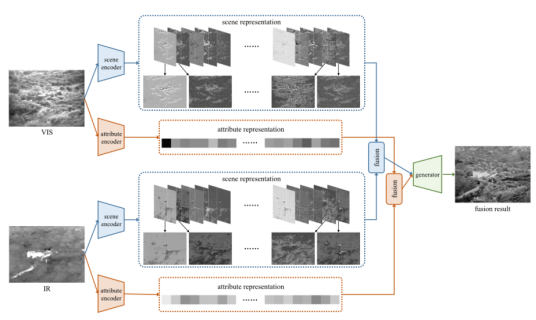
损失函数:

12、SDNet(2021)
Zhang, H. and Ma, J. SDNet: A versatile squeeze-and-decomposition network for real-time image fusion. International Journal of Computer Vision, 129(10), pp.2761-2785,2021
SDNet能实现多模态和数码摄影图像的实时融合。该模型中,为不同的图像融合任务提出了一个通用的损失函数,该函数由在融合图像和两个源图像之间构造的梯度损失项和强度损失项组成。
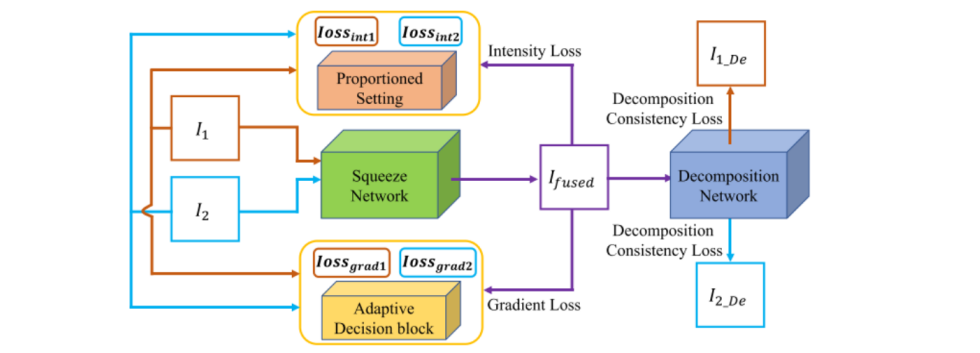
Squeeze network的目的是将源图像融合成一个包含更丰富的纹理内容的单一图像,使用了pseudo-siamese网络和DenseNet的结构,最大化不同源信息的利用。Decomposition network专门用于对融合后的图像进行分解,得到与源图像相似的结果,卷积层都不会改变特征映射的大小。
损失函数

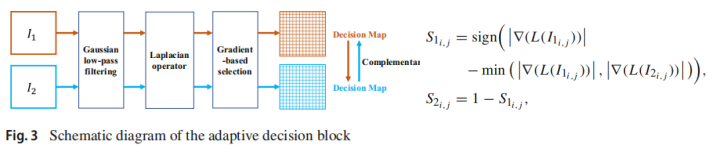
对于梯度信息重建,引入的自适应决策块首先利用高斯低通滤波来降低噪声对决策过程的影响,然后基于梯度丰富度来评估相应像素的重要性,以便生成像素级决策图,该像素级决策图引导融合图像中的纹理以近似具有更丰富纹理的源像素中的纹理。
对于强度信息重建,我们采用比例设置策略。具体地,我们调整融合图像和两个源图像之间的强度损失项的权重比,以满足不同任务对强度分布的要求。
13、RFN-Nest(2021)
Hui Li, Xiao-Jun Wu, and Josef Kittler. RFN-Nest: An end-to-end residual fusion network for infrared and visible images. Information Fusion 73, C (Sep 2021), 72–86,2021
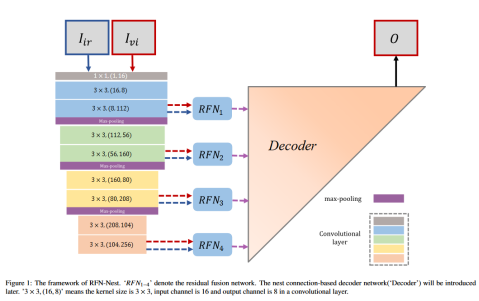
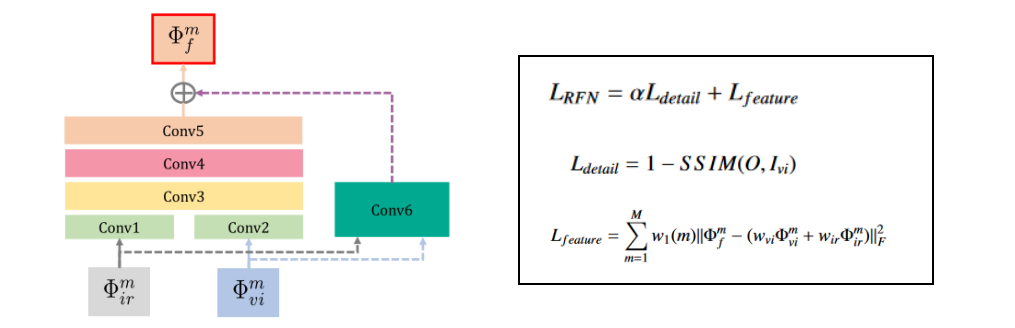
论文和NestFuse总体结构类似,提出了一种基于残差架构的融合网络,由三部分组成,即编码器,解码器和RFN(特征融合网络),这里编码器提取的特征包括4个尺度的特征,然后四个尺度的特征送入到RFN中进行特征融合,再交由解码器进行解码,得到融合图像。在利用单张图片的 像素损失和结构损失 训练编码器和解码器之后,将编码器和解码器的参数固定,再训练RFN模块。
RFN模块的损失函数如下:
14、PIAFusion(2022)
Linfeng Tang, Jiteng Yuan, Hao Zhang, Xingyu Jiang, and Jiayi Ma. “PIAFusion: A progressive infrared and visible image fusion network based on illumination aware”, Information Fusion, 83-84, pp. 79-92, 2022
考虑到照明不平衡问题以及融合图像特征不充分的问题,本文提出了一种基于光照感知的渐进式图像融合网络( PIAFusion ),自适应地保持显著目标的强度分布并保留背景中的纹理信息。具体来说,本文设计了一个光照感知子网络来估计光照分布并计算光照概率。此外,利用光照概率构造光照感知损失来指导融合网络的训练,利用跨模态差分感知融合模块来融合红外和可见特征共同信息和互补信息。另外,本文发布了一个用于红外与可见图像融合的大型基准数据集(MSRS,Multi-Spectral Road Scenarios)。
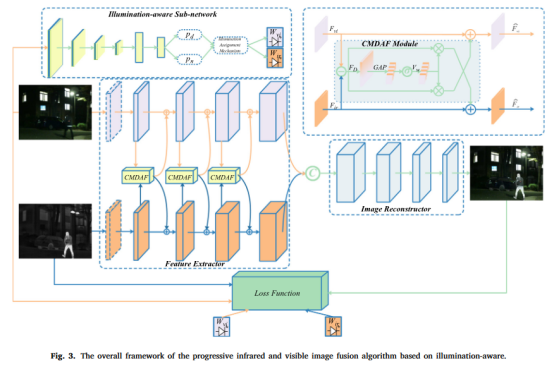
光照感知子网络使用交叉熵损失函数,主干网络损失函数为
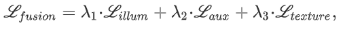
15、SeAFusion(2022)
Tang, Linfeng, Jiteng Yuan, and Jiayi Ma. “Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network.” Information Fusion 82 (2022): 28-42.
论文提出了一个语义感知的图像融合框架,利用高级视觉任务来驱动图像融合。同时考虑到对实时性的要求,在网络设计方面设计了一个轻量级的网络。而且为了增强网络对细粒度细节特征的描述,设计了一个Gradient Residual Dense Block(GRDB)。最后,考虑到现有的评估指标仅利用EN,MI,SF等统计指标来衡量图像融合的好坏。作者还提出了一种任务驱动的评估方式,即利用融合结果在高级视觉任务上的表现来衡量融合结果的质量。
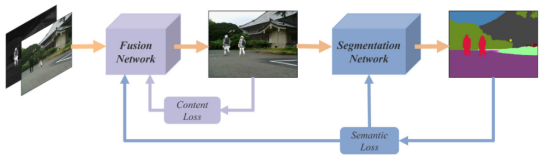
源图像经过融合网络生成融合图像,而融合网络图像在经过一个分割网络得到分割结果。分割结果与labels构造语义损失,融合图像与源图像之前构造内容损失,其中语义损失只用于约束分割网络,而内容损失与语义损失共同约束融合网络的优化。这样语义损失能够将高级视觉任务(分割)所需的语义信息反传回融合网络从而促使融合网络能够有效地保留源图像中的语义信息.
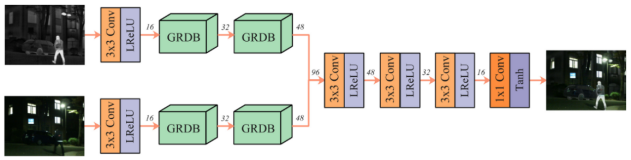
对于融合网络,SeAFusion采用的是双分支特征提取再Concat融合后重建图像的框架,而在GRDB中利用梯度算子提取的特征作为残差连接能够强化网络对于细节特征的提取。
由于图像融合没有groundtruth,无法利用融合结果预训练一个分割模型来指导融合网络的训练,为此作者通过交替训练融合网络以及分割网络,从而维持图像融合以及语义分割之间的平衡,能在保证高级视觉任务性能的同时不降低融合网络的性能。
结果比较:

16、SwinFusion(2022)
J. Ma, L. Tang, F. Fan, J. Huang, X. Mei and Y. Ma, “SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer,” in IEEE/CAA Journal of Automatica Sinica, vol. 9, no. 7, pp. 1200-1217, July 2022.
一方面,本文设计了一个注意力引导的跨域模块,以实现互补信息和全局交互的充分集成。该方法包括一个基于自注意的域内融合单元和一个基于交叉注意的域间融合单元,它在同一域内和跨域内挖掘和整合长依赖关系。通过远程依赖建模,网络能够充分实现特定领域的信息提取和跨领域互补信息集成,并从全局角度保持适当的表观强度。在自注意和交叉注意中引入了shifted window机制,这允许模型接收任意大小的图像。另一方面,将多模态图像融合和数码摄影图像融合都推广到结构、纹理和强度保持的设计中。定义了一个统一的损失函数形式来约束所有的图像融合问题。SwinFusion模型在多模态图像融合与数码摄影图像融合任务中均表现良好。
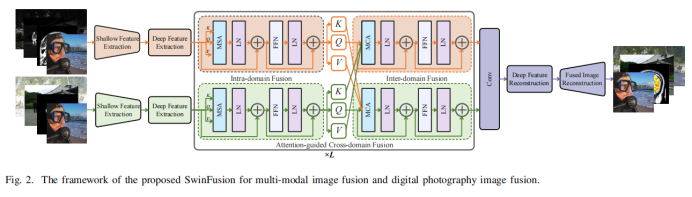

SwinFusion模型可分为特征提取、注意引导的跨域融合和重建三个部分。
17、DIVFusion(2023)
Linfeng Tang, Xinyu Xiang, Hao Zhang, Meiqi Gong, and Jiayi Ma. “DIVFusion: Darkness-free infrared and visible image fusion”, Information Fusion, 91, pp. 477-493, 2023
(1)论文创新点:
目前的图像融合方法都是针对正常照明下的红外和可见光图像设计的。在夜景中,现有的方法由于可见光图像严重退化,导致纹理细节较弱,视觉感知较差,影响了后续的视觉应用。如果将图像增强和图像融合作为独立的任务处理往往会导致不兼容问题,从而导致图像融合效果不佳。本文将低光图像增强技术和图像融合技术相结合,合理地照亮黑暗,促进互补信息聚合,得到良好的视觉感知的融合图像。
(2)总体架构:
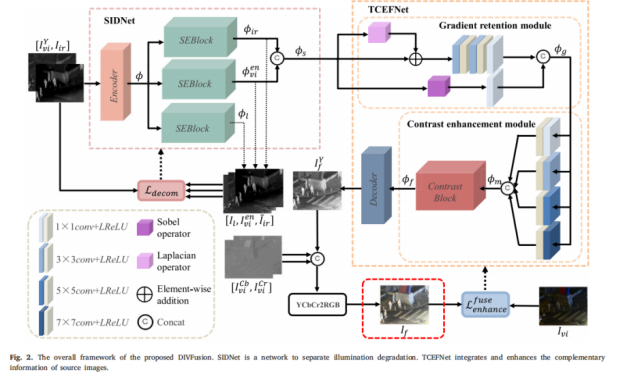
首先设计了一个场景光照解耦网络( SIDNet,scene illumination disentangled network)来去除夜间可见光图像中的光照退化,同时保留源图像的信息特征。为了融合互补信息,增强融合特征的对比度和纹理细节,设计了纹理-对比度增强融合网络( TCEFNet,texture-contrast enhancement fusion network)。所提方法能够以端到端的方式生成具有真实颜色和显著对比度的融合图像。
(3)损失函数
主要分为两阶段训练
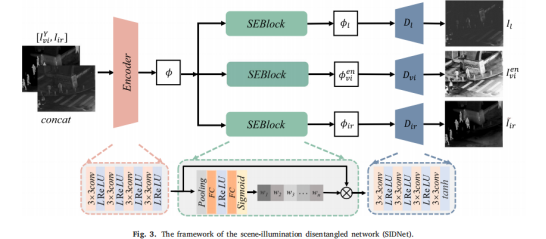
一阶段:SIDNet用于自监督重构原始图像,由编码器、注意力块和解码器组成。解码器只是训练的时候迫使SIDNet可以生成更好的特征,所以当使用模型融合图像时,不需要生成重建的图像。剥离退化的照明特征,将和作为下一阶段的输入。
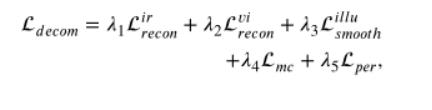
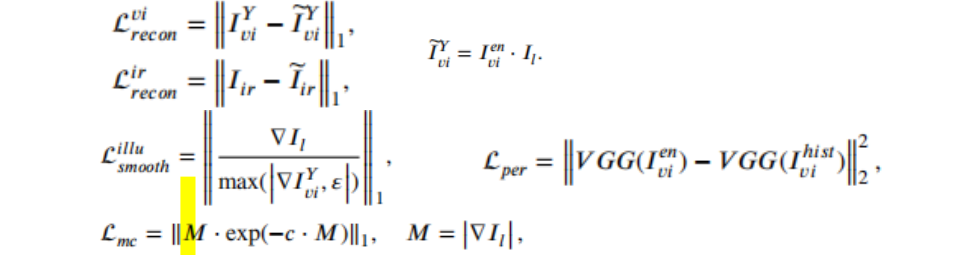
其中,Lper 是将使用直方图均衡增强后的图像作为对比,从而使得可以生成增强的可见光图像。
二阶段:固定SIDNet,训练TCEFNet。
除了强度损失,纹理损失之外,还设计了颜色一致性损失来减轻增强和融合带来的颜色失真。
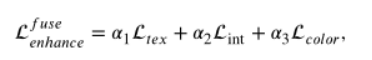
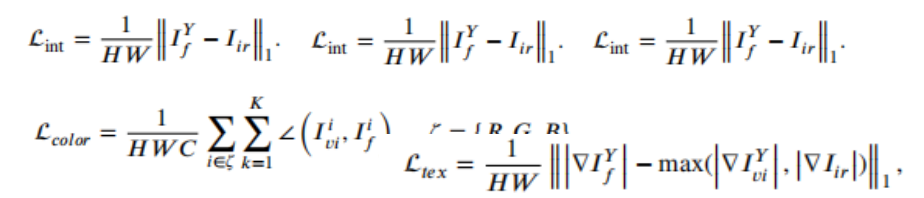
18、CDDFuse(CVPR2023)
Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion
多模态图像融合中的相关驱动的双分支特征分解
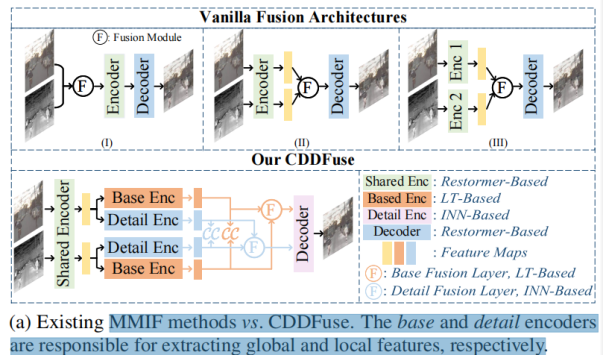
现有的方法图1有三个主要的缺点。首先,cnn的内部工作机制难以控制和解释,导致跨模态特征的提取不足。例如,在图1a中,(I)和(II)中的共享编码器不能区分特定于模态的特征,而(III)中的私有编码器忽略了模态共享的特征。其次,上下文无关的CNN结构只能在相对较小的接受域中提取局部信息,很难处理全局信息提取,生成高质量的融合图像[31]。因此,目前还不清楚CNN的归纳偏差是否能够提取所有输入模式的特征。第三,融合网络的前向传播往往会导致高频信息[38,74]的丢失。
相关驱动的特征分解融合(CDDFuse)模型,通过双分支编码器实现模态特异性和模态共享的特征提取,融合图像由解码器重建:
•1. 目标是对提取的特征增加相关限制,限制解空间,从而提高特征提取的可控性和可解释性,提出了一种双分支Transformer-cnn框架来提取和融合全局和局部特征,它更好地反映了高/低频特征中包含的不同语义信息。
•2. 我们改进了CNN和Transformer块,以更好地适应MMIF任务。我们是第一个利用INN块来进行无损信息传输(INN的设计具有可逆性,通过相互生成输入和输出特征来防止信息丢失,并与我们在融合图像中保持高频特征的目标相一致),并利用LT块来权衡融合质量和计算成本。
•3. 我们提出了一个相关驱动的分解损失函数来强制模态共享/特定特征分解,这使得交叉模态基本特征相关,而不同模态的详细高频特征去关联。(假设是,在MMIF任务中,两种模式的输入特征在低频时是相关的,代表模式共享信息,而高频特征是无关的,代表各自模式的独特特征。以VIF为例,由于红外和可见图像来自同一场景,两种模式的低频信息包含统计上的共现,如背景和大规模环境特征。相反,这两种模态的高频信息是独立的,例如,可见光图像中的纹理和细节信息,以及红外图像中的热辐射信息)
•4. 我们的方法在IVF和MIF中都取得了领先的图像融合性能。我们还提出了一个统一的测量基准,以证明IVF精融合图像如何促进下游MM目标检测和语义分割任务。
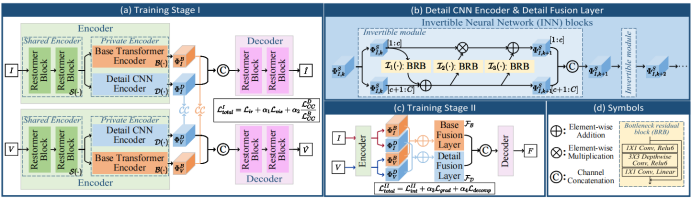
我们的CDDFuse方法的架构(以IVF为例)。(a)训练阶段I的管道,旨在训练结构用于基/细节特征分解和重建源图像。(b)基于INN块的DCE和细节融合层,以及INN仿射耦合层中的BRB块。©训练阶段第二的管道,目的是获得融合图像。
01.概述
我们的CDDFuse包含四个模块,即用于特征提取和分解的双分支编码器,用于重建原始图像(训练阶段一)或生成融合图像(训练阶段二)的解码器,以及融合不同频率特征的基础/细节融合层。具体的工作流程如图2所示。需要注意的是,CDDFuse是一个通用的多模态图像融合网络,我们只以IVF任务为例来解释CDDFuse的工作原理。
02. Encoder
该编码器有三个组成部分:基于Restormer块[66]的共享特征编码器(SFE),基于Lite Transformer(LT)块的基础Transformer编码器(BTE)和基于可逆神经网络(INN)[12]的细节CNN编码器(DCE)。BTE和DCE一起形成了长-短程编码器。定义输入的红外和可见光图像表示为I和V。SFE、BTE和DCE分别用S(·)、B(·)和D(·)表示。
共享功能编码器。SFE的目标是从红外和可见光输入{I,V }中提取浅层特征{Φ _ SI,Φ _ SV },即,
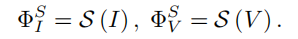
我们在SFE中选择Restormer块的原因是Restormer可以通过应用跨特征维度[67]的自注意,从高分辨率输入图像中提取全局特征。因此,它可以提取跨模态的浅层特征而无需太多计算量。我们使用的Restormer块的体系结构可以在补充材料或原始论文[67]中参考。
基础Transformer编码器。BTE是为了提取从共享特征中获得的低频率基础特征:
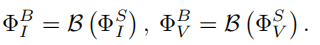
其中,Φ_ B I和Φ _B V分别为I和V的基本特征。为了提取长距离依赖特征,我们决定使用一个具有空间自注意的Transformer。考虑到平衡性能和计算效率,这里我们使用LT块[57]作为BTE的基本单元。通过扁平前馈网络结构扁平了变压器块的瓶颈,LT块在保持相同性能的同时减少嵌入,减少参数的数量,满足我们的需要。
详细的CNN编码器。与BTE相反,DCE从共享特征中提取高频细节信息,其表述为:
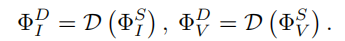
考虑到细节特征上的边缘和纹理信息对于图像融合任务非常重要,我们希望DCE中的CNN体系结构能够保留尽可能多的细节信息。INN [12]模块通过使其输入和输出特征相互生成,可以更好地保存输入信息。因此,它可以看作是一个无损的特征提取模块。我们采用了带有仿射耦合层[12,77]的INN块。在每个可逆层中,变换为:
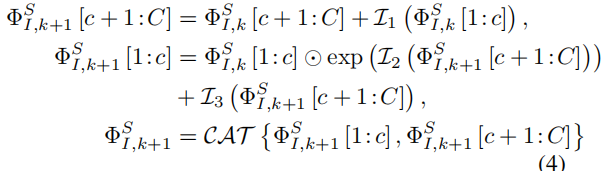
其中⊙是Hadamard积,Φ_SIk[1:c]∈R(h×w×c)是第k个可逆层(k=1,2,…K)输入特征的第1到第c个通道,CAT(·)为通道连接操作,Li (i = 1,2,3)为任意映射函数。计算细节见图2(d)和补充指标。在每个可逆层中,Li 可以设置为任何映射,而不影响该可逆层中的无损信息传输。考虑到计算消耗和特征提取能力之间的权衡,我们使用MobileNetV2 [45]中的瓶颈残差块(BRB)块作为Li。最后,通过替换等式中的下标,同样可以得到Φ_DI = Φ_DIK和Φ_DV(4)从I到V。
03.融合层
考虑到基/细节特征融合的归纳偏差应该类似于编码器中的基/细节特征提取,我们对基融合层和细节融合层采用LT和INN块,其中:
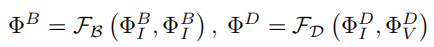
FB和FD分别为基础融合层和细节融合层。
04.解码器
在解码器DC(·)中,将分解后的特征在通道方向拼接作为输入,将原始图像(训练阶段I)或融合图像(训练阶段II)作为解码器的输出,表示为:
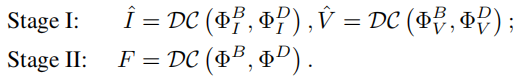
由于这里的输入涉及跨模态和多频特征,我们保持解码器的结构与SFE的设计一致,即使用Restormer块作为解码器的基本单元
05.两阶段训练
MMIF任务缺乏地面真相,先进的监督学习方法是无效的。
训练阶段I。在训练阶段I中,将成对的红外图像和可见光图像{I,V }输入到SFE中,提取浅层特征{Φ S I,Φ S V }。然后利用基于LT块的BTE和基于inn的DCE分别提取两种不同模式的低频基特征{Φ B I,Φ B V }和高频细节特征{Φ D I,Φ D V }。然后,将红外{Φ B I、ΦDI}(或可见{Φ B V、Φ D V })图像的基本特征和细节特征拼接起来,输入解码器,重建原始红外图像Iˆ(或可见图像Vˆ)。
训练阶段Ⅱ。在训练阶段第二阶段,将成对的红外和可见图像{I,V }输入一个几乎训练良好的编码器,以获得分解特征。然后将分解后的基特征{Φ B I、Φ B V }和细节特征{Φ D I、Φ D V }分别输入到融合层FB和FD中。最后,将融合特征{Φ B,Φ D}输入解码器,得到融合图像F。
训练损失。在训练阶段I中,总损失LI总计为:
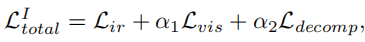
其中Lir和Lvis为红外和可见图像的重建损失,Ldecomp为特征分解损失,重构损失主要保证了在编码和解码过程中图像中包含的信息不丢失。
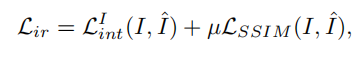
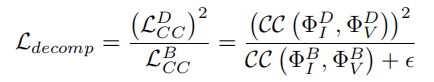
其中,CC(·,·)为相关系数算子,这里的ϵ设为1.01,以确保该项总是为正的。这个损失项的动机是,根据我们的MMIF假设,分解后的特征{Φ B I,Φ B V }将包含更多的模式共享信息,如背景和大规模环境,因此它们通常是高度相关的。相比之下,{Φ D I,Φ D V }表示V中的纹理和细节信息和热辐射,以及I中的清晰的边缘信息,这是特定于模态的。因此,特征映射的相关性较小。从经验上看,在梯度下降中Ldecomp的指导下,L_DCC逐渐趋于0,L_BCC变大,满足了我们对特征分解的直觉。分解效果的可视化情况如图所示。

随后在训练第二阶段,总损失为:
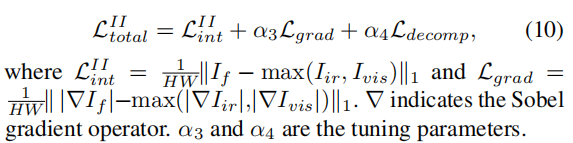
*实验
数据集和指标设置。 IVF实验使用了MSRS [48]、RoadScene [61]和TNO [49]。在MSRS训练集(1083对)上训练我们的网络,在道路场景中使用50对进行验证。采用MSRS测试集(361对)、RoadScene (50对)和TNO(25对)作为测试数据集,可以对其融合性能进行综合验证。微调并没有应用于道路场景和TNO数据集,以验证融合模型的泛化性能。采用8个度量指标:熵(EN)、标准差(SD)、空间频率(SF)、互信息(MI)、差异相关性之和(SCD)、视觉信息可靠性(VIF)、QAB/F和结构相似度指数度量(SSIM)。
实施细节。两个 3090gpu。Pre-train:将训练样本随机裁剪成128个×128个patch。Epoch:120(一阶段40,二阶段80)。Batchsize16。Adam优化器,初始Ir10−4,每20个周期减少0.5。超参数:SFE中的 Restormer块数4个,有8个注意头和64维度。BTE中LT块的尺寸也是64,有8个注意头。Decode的配置与Encode相同。损失函数等式(7)和(10),α1到α4被设置为1、2、10和2,以保持每项相同的数量级。
与SOTA方法的比较。
定性比较。我们的方法更好地集成了红外图像中的热辐射信息和可见光图像中的详细纹理。黑暗区域的物体被清晰地突出显示,因此前景目标可以很容易地与背景区分开来。此外,由于低光照而难以识别的背景细节具有清晰的边缘和丰富的轮廓信息,这有助于我们更好地理解场景。

定量比较。在几乎所有指标上都有良好的性能,证明了我们的方法适用于各种照明和目标类别。特征分解的可视化。

特征分解的可视化。基本特征组中更多的背景信息被激活,激活的高亮区域也是相关的。然而,在细节特征组中,红外特征更关注物体的高光,而可见特征更关注细节和纹理,这表明表明模态特定特征被很好的提取。
消融研究与下游应用
略
19、DDcGAN:多分辨率图像融合的双识别条件GAN
1.摘要
本文提出端到端的 双鉴别器条件生成对抗网络(DDcGAN):生成器基于内容损失生成融合图像,欺骗鉴别器;两个鉴别器区分 fuse 图像和两个源图像之间的结构差异。DDcGAN约束了降采样的融合图像,使其与红外图像具有相似的特性。这可以避免造成热辐射信息模糊或可见的纹理细节损失(常发生在传统的方法中)。DDcGAN可融合不同分辨率的多模态医学图像,例如,一个低分辨率的正电子发射断层扫描图像和一个高分辨率的磁共振图像。
2.问题表述(Problem Formulation)
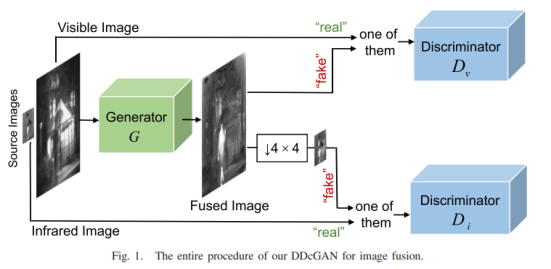
本文假设可见光图像v的分辨率是红外图像i的4×4倍。
DDcGAN过程如图1所示:生成器G 鼓励生成图像G(v,i);同时利用两个对抗性鉴别器Dv和Di,分别生成一个标量,估计从真实数据而不是G输入的概率。与最大池相比,平均池保留了低频信息,因此采用了降采样,热辐射信息主要以这种形式表示。换句话说,为了生成器和鉴别器之间的平衡,除了鉴别器的输入外,我们不将源图像v和i作为额外的/条件信息提供给Dv和Di。
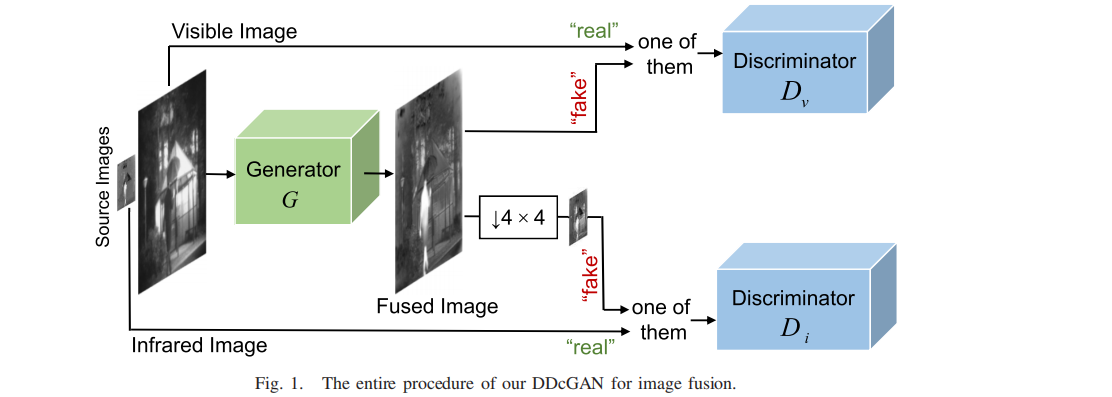
降采样算子ψ保留了低频信息,由两个AvgPool实现,以及3×3邻域卷积,step=2。因此,G的训练目标可以表述为最小化以下对抗性目标。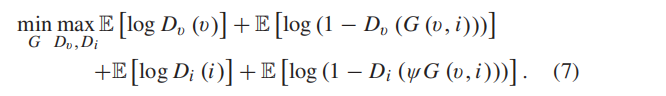
3.损失函数
最初,GANs的成功有限,因为不稳定的训练可能导致 artifacts 和嘈杂或难以理解的结果[33]。解决伪影和问题的一个方案是引入一个内容损失(在网络中包含一组约束)。本文的生成器不仅被训练来欺骗鉴别器,而且还被要求约束在内容中生成的图像和源图像之间的相似性。因此,生成器的损失:

由于热辐射和纹理细节主要以像素强度和梯度变化[17]为特征,我们采用Frobenius 范数约束下采样融合图像具有与红外图像相似的数据保真度项的像素强度。通过约束下采样融合图像与低分辨率红外图像的像素强度的关系,可以大大防止压缩或模糊造成的纹理信息丢失和强制上采样导致的不准确性。根据上述约束条件,热目标在融合的图像中仍然很突出。在正则化项中应用TV 范数[34]来约束融合图像表现出与可见图像相似的梯度变化。与0范数相比,TV范数能够有效地解决非确定性 polynomial-time hard问题。
DDcGAN中的鉴别器,即Dv和Di起着鉴别(原图)和(fuse 图)的作用。鉴别器的对抗性损失可以计算出分布之间的JS散度,从而识别出强度或纹理信息是否不现实,从而鼓励匹配现实分布。对抗性损失的定义如下:
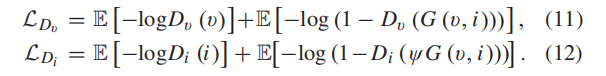
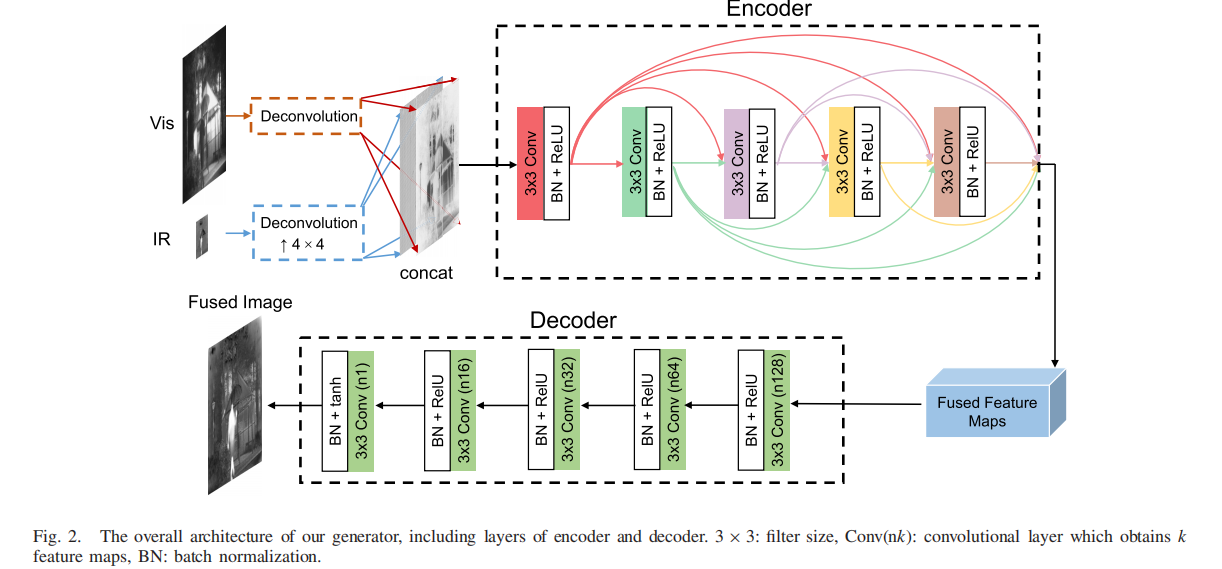
4 .网络结构
我们引入了反褶积层[35]来学习从(低分辨率inf图像)到(高分辨率)的映射;应用了DenseNet [36]以前馈的方式在每个层和所有层之间建立短的直接连接。解码器为5层CNN。
模型中的参数被设置为λ = 0.5和η = 1.2。
20、GANMcC:多分类约束的红外可见图像融合GAN
1.摘要:分类约束的生成对抗网络(GANMcC),网络可以同时保持对比度和纹理细节。设计了一个特定的内容loss 来约束生成器对源图像特征的提取和处理,从而解决了信息利用不足的问题。
fuse 图像被转换为多个分布的同时估计。鉴别器确定 fuse 图像既不是inf 也不是vis。过程中,我们同时约束这两个概率,以确保融合后的图像在两类图像中的真假程度相同。
2.LSGAN:原始GAN的训练过程非常不稳定,生成的图像质量不高。为了改善这一现象,Mao等人[43]提出使用最小二乘损失函数来代替交叉熵损失来指导GAN的优化。损失函数的定义如下:
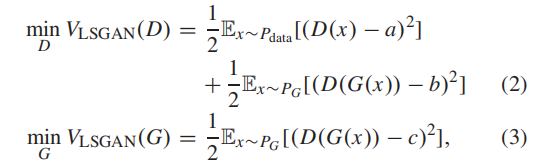
a是真实数据的概率标签,b是生成器的假数据对应的概率标签;c是指导生成器优化的概率标签(c是生成器期望鉴别器确定假数据的标签)。显然,b应该尽可能地接近于0。相反,a和c应该尽可能大,接近于1。
3.损失:fuse 和inf 图像之间的主红外强度损失,而且还构建了辅助梯度损失(因为红外图像也包含纹理细节);fuse 和RGB 图像之间的主梯度损失和辅助强度信息损失。
对比度信息(主要在inf中)由强度表示,纹理信息(主要在RGB中)用梯度表示。
01.G损失函数:G 优化的损失函数由:内容损失LGcon 和约束信息平衡的对抗性损失LGadv 两部分组成
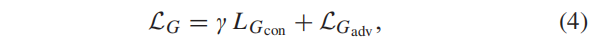
内容丢失遵循了主信息和辅助信息的思想。inf 图像,对场景的热辐射信息具有显著的对比度,可以从背景中突出目标。因此,主要信息是其强度分布,主要强度损失定义为
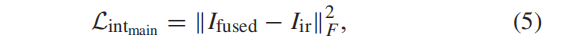
RGB 图像,主要信息是梯度信息,并将主要梯度损失定义为
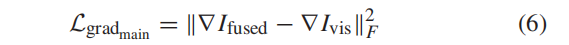
辅助损失:红外图像也有一些纹理细节,可见光图像也包含对比度信息:
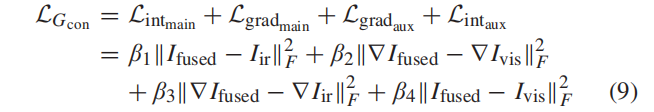
梯度损失项一般小于强度损失项,因此需要调整β
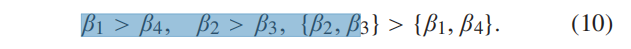
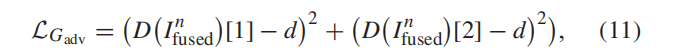
D(·)[1]表示向量的第一项,即融合后的图像成为可见图像的概率。同样,D(·)[2]表示向量的第二项,即融合后的图像成为红外图像的概率。d被设置为1。
02.鉴别器的损失:
LD由可见光图像、红外图像和融合图像的决策损失三部分组成
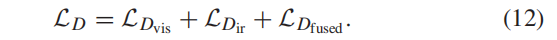
a1 i设置为1, a2设置为0;c是0
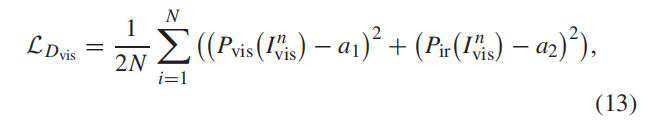
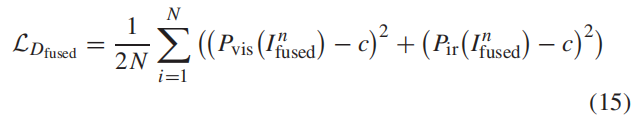
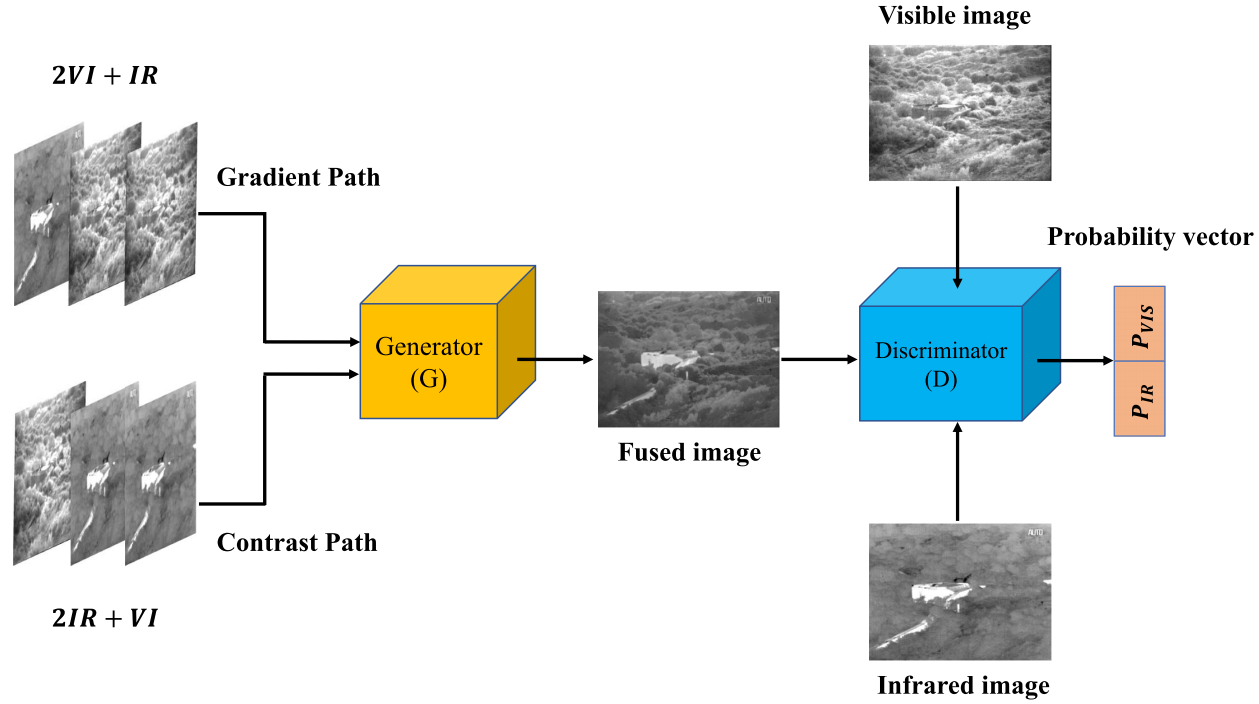
4.网络结构:
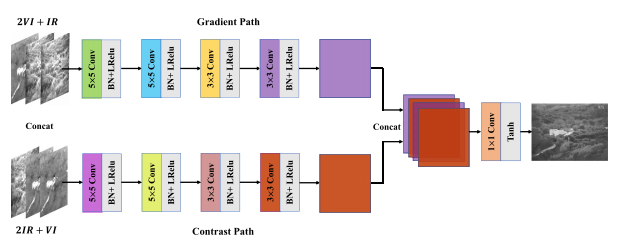
1.梯度路径,我们希望它能负责提取纹理信息,即高频特征。我们认为,纹理信息主要包含在可见光图像中,其次包含在红外图像中。因此,使用主连接策略和次连接策略来构造输入。我们使用两个可见图像和一个红外图像沿着通道连接作为输入。
2.对比度路径,我们期望它负责提取对比度信息,这些信息主要包含在红外图像中,次要信息包含在可见光图像中。因此,我们使用两个红外图像和一个可见光图像沿着通道进行连接
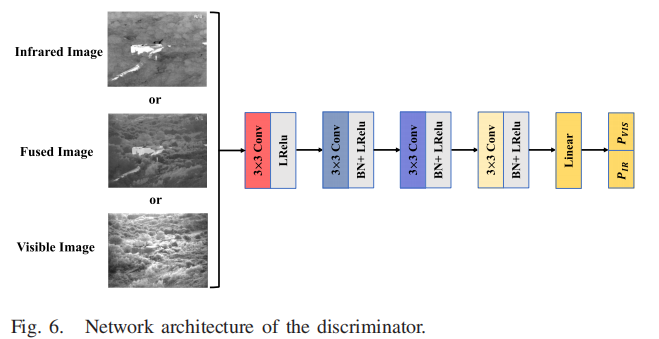
鉴别器的体系结构:鉴别器的结构如图6所示。我们的鉴别器本质上是一个多分类器,它可以估计输入图像的每个类别的概率。它的输出是一个大小为1×2的概率向量。
训练伪代码:

21.AttentionFGAN:基于注意力GAN的红外和可见图像融合
1.摘要
现有的基于 GAN 的红外/可见图像融合方法不能感知最具区别性的区域,因此不能突出红外和可见图像中存在的典型部分。为此,我们将多尺度的注意机制集成到GAN的生成器和鉴别器中来融合图像。多尺度注意机制 不仅是捕获全面的空间信息,帮助生成红外图像的前景目标信息和可见图像的背景细节信息,而且限制鉴别器更多地集中在注意区域,而不是整个输入图像。注意算法的生成器由两个多尺度注意网络和一个图像融合网络组成。两个多尺度注意网络分别捕获红外图像和可见图像的注意图,使融合网络可以通过更多地关注源图像的典型区域来重建融合图像。此外,采用两种鉴别器,迫使融合结果分别从红外和可见图像中保持更多的强度和纹理信息。此外,为了从源图像中获取更多的注意区域信息,还设计了一个注意损失函数。最后,消融实验说明了关键部分的有效性,在三个公共数据集上进行的大量定性和定量实验
2.WGAN
WGAN采用Wasserstein 距离 代替 jensen-shannon(JS)散度来计算真实数据与生成数据之间的差异,这使得训练过程比原始的GAN [32]更加稳定。详细地说,WGAN剪辑了鉴别器的权值,并使权值位于一个紧凑的空间内。然而,由于梯度爆炸的消失,剪权法仍然导致模型难以收敛。因此,古拉贾尼等人用梯度惩罚[33]改进了WGAN,如下
(Wasserstein距离) 通过计算将一个分布转换为另一个分布所需的最小成本来度量差异,而 (Jensen-Shannon散度) 通过计算平均的KL散度来度量差异。
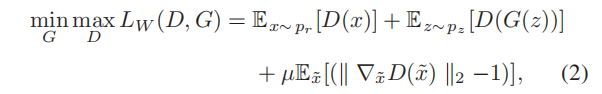
其中前两项表示 Wasserstein距离 估计,最后一项表示梯度惩罚因子,
x
^
\widehat{x}
x
表示生成数据和真实数据对沿直线进行的均匀采样,μ表示惩罚系数。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。

