
- 18个居家兼职,帮助自己在家搞副业
- 2Python-VBA函数之旅-globals函数_vba global用法
- 3Linux环境安装PostgreSQL-12.2_postgresql-12.2.tar.gz
- 4【网络原理】HTTP 协议的基本格式和 fiddler 抓包工具的用法
- 5案例研究|众乐邦将MeterSphere持续测试平台融入DevOps流水线
- 6解读Lawyer LLaMA,延申专业领域大模型微调:数据集构建,模型训练
- 7机器学习算法(7)—— 朴素贝叶斯算法
- 8数据结构 绪论 的思维导图_数据结构教程绪论的思维导图
- 9springboot+vue element UI 实现:大文件分片上传、极速秒传_springboot+element-ui 分片上传
- 10PGSQL中SQL语句_pgsql left join
自然语言处理(NLP)学习路线总结,该如何高效实用Kotlin_nlp 文本提取学习路线
赞
踩
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新软件测试全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

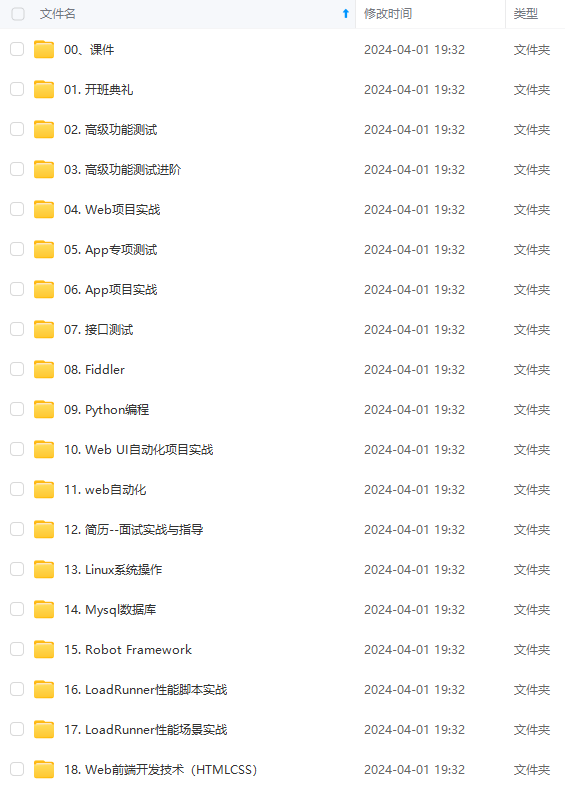
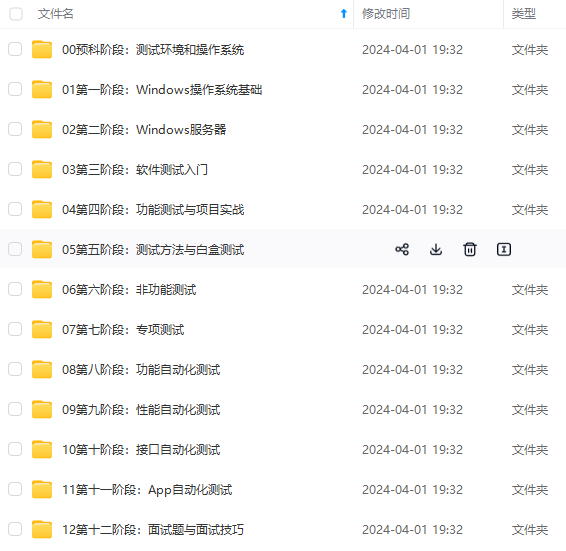
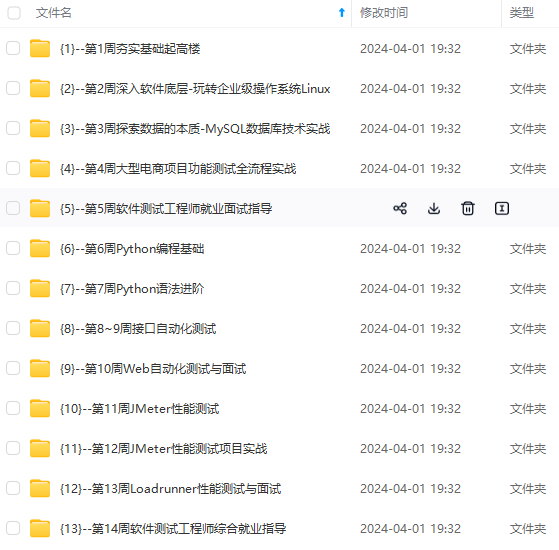
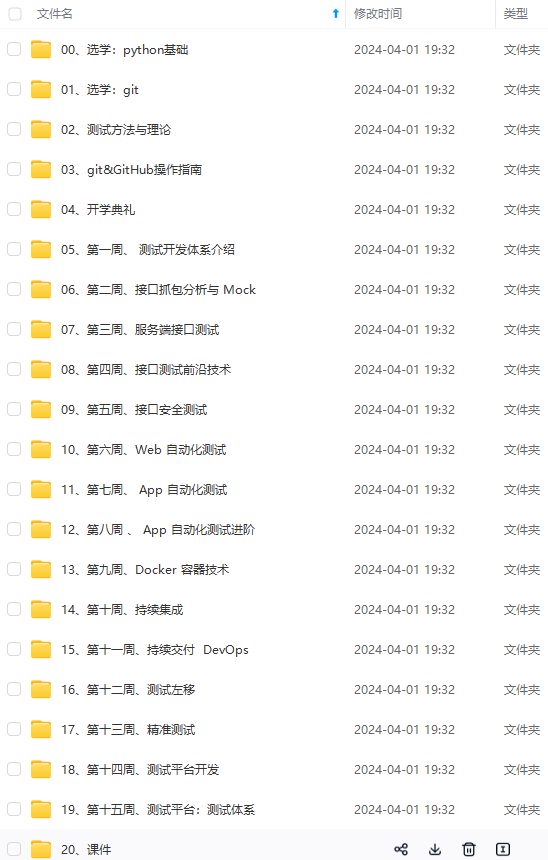
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注软件测试)

正文
(2)概率论
随机试验、条件概率、全概率、贝叶斯定理、信息论
(3)统计学
图形可视化(饼图、条形图、热力图、折线图、箱线图、散点图、雷达图、仪表盘)
数据度量标准(平均数、中位数、众数、期望、方差、标准差)
概率分布(几何分布、二项分布、正态分布、泊松分布)
统计假设检验
2.2 语言学基础
语音、词汇、语法
2.3 Python基础
廖雪峰教程,Python从入门到实践
2.4 机器学习基础
统计学习方法、机器学习周志华、机器学习实战
2.5 深度学习基础
CNN、RNN、LSTM
2.6 自然语言处理的理论基础
统计自然语言处理(宗成庆第二版)、Python自然语言处理、数学之美(第二版)
3、自然语言处理的主要技术范畴
3.1 语义文本相似度分析
语义文本相似度分析是对两段文本的意义和本质之间的相似度进行分析的过程。
3.2 信息检索(Information Retrieval, IR)
信息检索是指将信息按一定的方式加以组织,并通过信息查找满足用户的信息需求的过程和技术。
3.3 信息抽取(Information Extraction)
信息抽取是指从非结构化/半结构化文本(如网页、新闻、 论文文献、微博等)中提取指定类型的信息(如实体、属性、关系、事件、商品记录等),并通过信息归并、冗余消除和冲突消解等手段将非结构化文本转换为结构化信息的一项综合技术。
3.4 文本分类(Text Categorization)
文本分类的任务是根据给定文档的内容或主题,自动分配预先定义的类别标签。
3.5 文本挖掘(Text Mining)
文本挖掘是信息挖掘的一个研究分支,用于基于文本信息的知识发现。文本挖掘的准备工作由文本收集、文本分析和特征修剪三个步骤组成。目前研究和应用最多的几种文本挖掘技术有:文档聚类、文档分类和摘要抽取。
3.6 文本情感分析(Textual Affective Analysis)
情感分析是一种广泛的主观分析,它使用自然语言处理技术来识别客户评论的语义情感,语句表达的情绪正负面以及通过语音分析或书面文字判断其表达的情感等。
3.7 问答系统(Question Answering, QA)
自动问答是指利用计算机自动回答用户所提出的问题以满足用户知识需求的任务。不同于现有搜索引擎,问答系统是信息服务的一种高级形式,系统返回用户的不再是基于关键词匹配排序的文档列表,而是精准的自然语言答案。
3.8 机器翻译(Machine Translation,MT)
机器翻译是指利用计算机实现从一种自然语言到另外一种自然语言的自动翻译。被翻译的语言称为源语言(source language),翻译到的语言称作目标语言(target language)。
机器翻译研究的目标就是建立有效的自动翻译方法、模型和系统,打破语言壁垒,最终实现任意时间、任意地点和任意语言的自动翻译,完成人们无障碍自由交流的梦想。
3.9 自动摘要(Automatic Summarization)
自动文摘(又称自动文档摘要)是指通过自动分析给定的一篇文档或多篇文档,提炼、总结其中的要点信息,最终输出一篇长度较短、可读性良好的摘要(通常包含几句话或数百字),该摘要中的句子可直接出自原文,也可重新撰写所得。
根据输入文本的数量划分,文本摘要技术可以分为单文档摘要和多文档摘要。
在单文档摘要系统中,一般都采取基于抽取的方法。而对于多文档而言,由于在同一个主题中的不同文档中不可避免地存在信息交叠和信息差异,因此如何避免信息冗余,同时反映出来自不同文档的信息差异是多文档文摘中的首要目标,而要实现这个目标通常以为着要在句子层以下做工作,如对句子进行压缩,合并,切分等。另外,单文档的输出句子一般是按照句子在原文中出现的顺序排列,而在多文档摘要中,大多采用时间顺序排列句子,如何准确的得到每个句子的时间信息,也是多文档摘要需要解决的一个问题。
3.10 语音识别(Speech Recognition)
语言识别指的是将不同语言的文本区分出来。其利用语言的统计和语法属性来执行此任务。语言识别也可以被认为是文本分类的特殊情况

4、自然语言处理基本点
4.1 语料库(Corpus)
语料库中存放的是在语言的实际使用中真实出现过的语言材料;语料库是以电子计算机为载体承载语言知识的基础资源;真实语料需要经过加工(分析和处理),才能成为有用的资源。
4.2 中文分词(Chinese Word egmentation)
(1)中文分词指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。
(2)现有的分词方法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法、基于统计的分词方法和基于深度学习的中文分词。推荐
(3)比较流行的中文分词工具:jieba、StanfordNLP、HanLP、SnowNLP、THULAC、NLPIR
4.3 词性标注(Part-of-speech tagging)
(1)词性标注是指为给定句子中的每个词赋予正确的词法标记,给定一个切好词的句子,词性标注的目的是为每一个词赋予一个类别,这个类别称为词性标记(part-of-speech tag),比如,名词(noun)、动词(verb)、形容词(adjective)等。
(2)词性标注是一个非常典型的序列标注问题。最初采用的方法是隐马尔科夫生成式模型, 然后是判别式的最大熵模型、支持向量机模型,目前学术界通常采用的结构是感知器模型和条件随机场模型。近年来,随着深度学习技术的发展,研究者们也提出了很多有效的基于深层神经网络的词性标注方法。
4.4 句法分析(Parsing)
(1)基于规则的句法结构分析
(2)基于统计的语法结构分析
4.5 词干提取(Stemming)
词干提取是将词语去除变化或衍生形式,转换为词干或原型形式的过程。词干提取的目标是将相关词语还原为同样的词干。
4.6 词形还原(Lemmatization)
词形还原是将一组词语还原为词源或词典的词目形式的过程。
4.7 停用词过滤
停用词过滤是指在文本中频繁出现且对文本信息的内容或分类类别贡献不大甚至无贡献的词语,如常见的介词、冠词、助词、情态动词、代词以及连词等。
4.8 词向量化(Word Vector)
词向量化是用一组实数构成的向量代表自然语言的叫法。这种技术非常实用,因为电脑无法处理自然语言。词向量化可以捕捉到自然语言和实数间的本质关系。通过词向量化,一个词语或者一段短语可以用一个定维的向量表示。(word2vec)
from gensim.models import Word2Vec
4.9 命名实体消歧(Named Entity Disambiguation)
命名实体消岐是对句子中的提到的实体识别的过程。
例如,对句子“Apple earned a revenue of 200 Billion USD in 2016”,命名实体消岐会推断出句子中的Apple是苹果公司而不是指一种水果。一般来说,命名实体要求有一个实体知识库,能够将句子中提到的实体和知识库联系起来。
4.10 命名实体识别(named entity recognition)
命名实体识别是识别一个句子中有特定意义的实体并将其区分为人名,机构名,日期,地名,时间等类别的任务。
三种主流算法:CRF,字典法和混合方法
5、特征处理
5.1 特征提取(Feature Extraction)
特征提取是指将机器学习算法不能识别的原始数据转化为算法可以识别的特征的过程。
举例(文本分类特征提取步骤):
(1)对训练数据集的每篇文章,我们进行词语的统计,以形成一个词典向量。词典向量里包含了训练数据里的所有词语(假设停用词已去除),且每个词语代表词典向量中的一个元素。
(2)在经过第一步的处理后,每篇文章都可以用词典向量来表示。这样一来,每篇文章都可以被看作是元素相同且长度相同的向量,不同的文章具有不同的向量值。这也就是表示文本的词袋模型(bag of words)。
(3)针对于特定的文章,如何给表示它的向量的每一个元素赋值呢?最简单直接的办法就是0-1法了。简单来说,对于每一篇文章,我们扫描它的词语集合,如果某一个词语出现在了词典中,那么该词语在词典向量中对应的元素置为1,否则为0。
5.2 特征选择( Feature Selection)
当数据预处理完成后,我们需要选择有意义的特征输入机器学习的算法和模型进行训练。特征选择是指去掉无关特征,保留相关特征的过程,也可以认为是从所有的特征中选择一个最好的特征子集。特征选择本质上可以认为是降维的过程。
from sklearn.feature_extraction.text import TfidfVectorizer
5.3 降维(Dimension Reduction)
6、模型选择
6.1 马尔可夫模型、隐马尔可夫模型、层次化隐马尔可夫模型、马尔可夫网络
(1)应用:词类标注、语音识别、局部句法剖析、语块分析、命名实体识别、信息抽取等。应用于自然科学、工程技术、生物科技、公用事业、信道编码等多个领域。
(2)马尔可夫链:在随机过程中,每个语言符号的出现概率不相互独立,每个随机试验的当前状态依赖于此前状态,这种链就是马尔可夫链。
(3)多元马尔科夫链:考虑前一个语言符号对后一个语言符号出现概率的影响,这样得出的语言成分的链叫做一重马尔可夫链,也是二元语法。二重马尔可夫链,也是三元语法,三重马尔可夫链,也是四元语法
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注软件测试)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
马尔可夫链,也是三元语法,三重马尔可夫链,也是四元语法
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注软件测试)
[外链图片转存中…(img-d9B9t2uD-1713599065181)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

