
- 1【动态规划】简单多状态 dp 问题|打劫劫舍|打家劫舍II|删除并获取点数|粉刷房子|最佳买卖股票时机含冷冻期|最佳买卖股票时机含手续费|最佳买卖股票时机III|最佳买卖股票时机IV
- 2Mysql数据库操作-数据库表的基本操作之创建表_mysql create table
- 3HttpCilent进行Post请求form-data接口,服务方接收不到参数
- 4鸿蒙ArkTS开发工具安装,环境配置_鸿蒙 安装 askts失败 如何配置
- 5编写第一个微信小程序界面,前端开发面试问题回答技巧
- 6让 Android 应用在 Chrome 浏览器上运行_浏览器运行apk
- 7用Django全栈开发——12. 重构前端页面编写文章详情页_前端文章页面
- 8三次握手/四次挥手_tcp三四握手,四次挥手syn,seq是什么意思
- 9安卓11-HDMI插拔检测流程_android usb hdmi插入 运行流程
- 10IRQL_NOT_LESS_OR_EUQAL,间歇性蓝屏,4800h笔记本,暗影精灵6,解决办法,蓝屏问题排查_4800h蓝屏
大模型实践笔记(1)——GLM-6B实践_6b glm
赞
踩
目录
在Ubuntu上的配置Git Large File Storage
很多模型在hugging face上面,我们一般采用远程的文件指针形式
在Ubuntu上的配置Git Large File Storage
-
安装Git LFS:
- 在大多数Linux发行版上,您可以使用包管理器来安装Git LFS。例如,在基于Debian的系统上(如Ubuntu),您可以使用以下命令:
sudo apt-get update sudo apt-get install git-lfs - 对于其他操作系统或者如果您希望使用不同的安装方法,可以访问Git LFS的官方网站获取更详细的安装指南:Git LFS 官方网站。
- 在大多数Linux发行版上,您可以使用包管理器来安装Git LFS。例如,在基于Debian的系统上(如Ubuntu),您可以使用以下命令:
-
设置Git LFS:
- 安装完成后,您需要设置Git LFS。在您的仓库目录中运行以下命令来初始化Git LFS:
git lfs install - 这个命令会设置必要的Git钩子(hooks),以便Git LFS可以管理大文件。
- 安装完成后,您需要设置Git LFS。在您的仓库目录中运行以下命令来初始化Git LFS:
-
使用Git LFS:
- 您可以开始使用Git LFS来追踪大文件了。例如,如果您想追踪所有的
.bin文件,您可以使用以下命令:git lfs track "*.bin" - 然后,您可以像平常一样使用
git add和git commit命令提交您的更改。 - 当您克隆一个使用Git LFS的仓库时,您可能需要使用
git lfs pull命令来拉取存储在LFS中的大文件。
- 您可以开始使用Git LFS来追踪大文件了。例如,如果您想追踪所有的
安装GLM-6B
在主要评估LLM模型中文能力的 C-Eval 榜单中,截至6月25日 ChatGLM2 模型以 71.1 的分数位居 Rank 0 ,ChatGLM2-6B 模型以 51.7 的分数位居 Rank 6,是榜单上排名最高的开源模型。
环境依赖
-
CUDA 11.7
-
Python 3.10
-
pytorch 1.13.1+cu117
ChatGLM2-6B介绍
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
-
更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
-
更长的上下文:基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
-
更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
-
更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在获得官方的书面许可后,亦允许商业使用。如果您发现我们的开源模型对您的业务有用,我们欢迎您对下一代模型 ChatGLM3 研发的捐赠。
配置GLM
下载代码
$ git clone https://github.com/THUDM/ChatGLM2-6B构建环境
- $ conda create -n GLM python=3.10 # 创建新环境
- $ conda activate GLM # 激活环境
安装依赖
- $ cd ChatGLM2-6B
- $ pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
本地部署
- $ git lfs install
- $ git clone https://huggingface.co/THUDM/chatglm2-6b
模型的实现仍然处在变动中。如果希望固定使用的模型实现以保证兼容性,可以在 from_pretrained 的调用中增加 revision="v1.0" 参数。v1.0 是当前最新的版本号,完整的版本列表参见 Change Log。
Cli测试
修改cli_demo.py
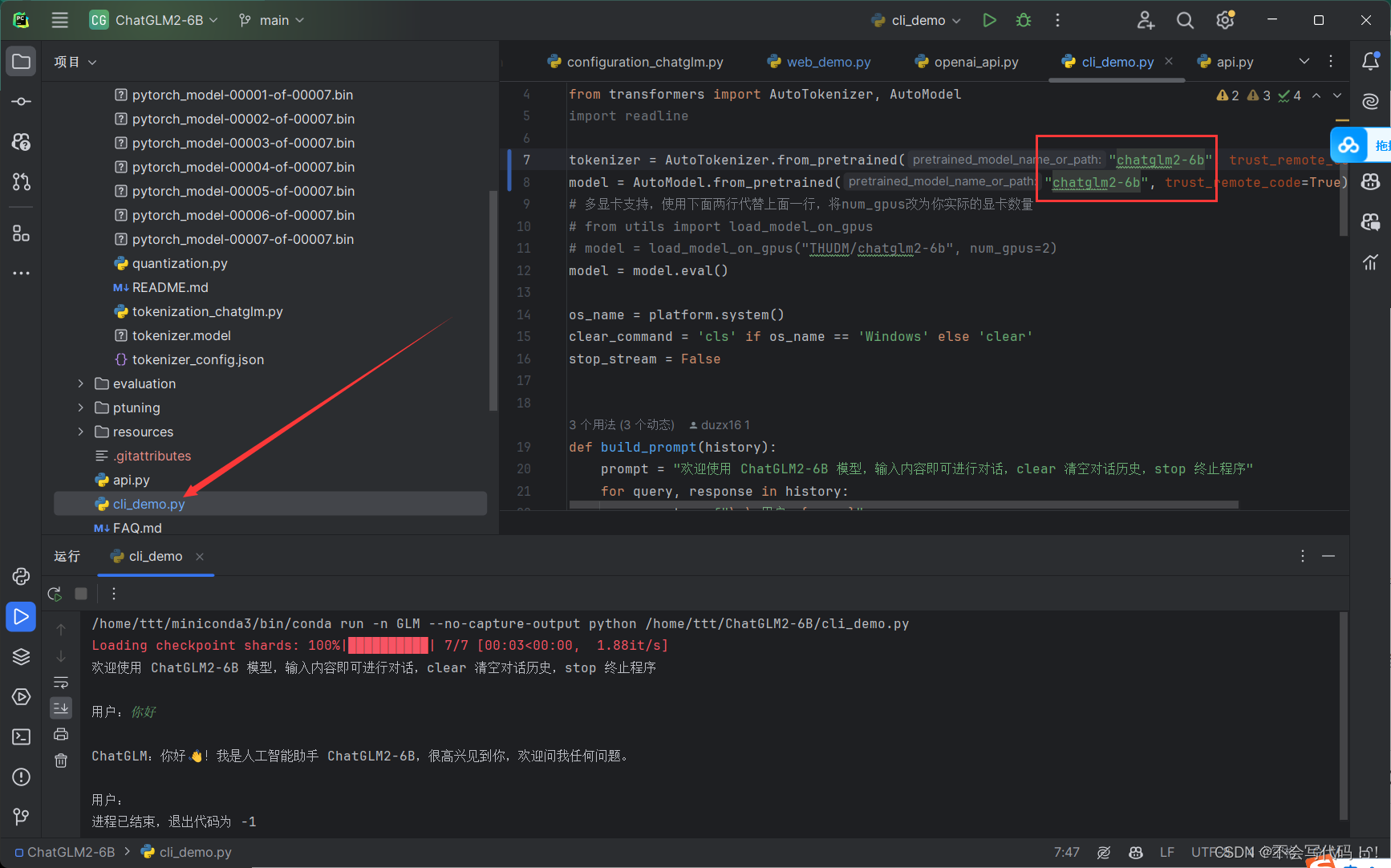
$ python cli_demo.py

