
- 1如何讲好ppt演讲技巧(4篇)
- 2FastJson中JSONObject的全面用法与常用方法详解_fastjson jsonobject
- 3用人工智能写论文查重率高吗?_人工智能生成文章查重有多少
- 4求助 git config --add safe directory // 文件目录_git add safe
- 5全网最系统、最清晰 深入微服务架构——Docker和K8s详解
- 6为什么 OpenCV 计算的视频 FPS 是错的_opencv/modules/videoio/src/cap_ffmpeg_impl.hpp:233
- 7基于SpringBoot+Vue+uniapp的房屋租赁平台的详细设计和实现(源码+lw+部署文档+讲解等)_uniapp租房源码
- 8Android10 API 29引入开源项目常见问题以及解决方法_android sdk "android api 29 platform" is missing
- 9Linux网络服务部署yum仓库与NFS网络文件服务_yum install nfs-utils
- 10STM32智能语音学习笔记day03_syn6288e
基于Python实现对情感极性判断分析实验_情感分析用词语集beta版
赞
踩
资源下载地址:https://download.csdn.net/download/sheziqiong/85734418
资源下载地址:https://download.csdn.net/download/sheziqiong/85734418
引言
情感极性分析是对带有感情色彩的主观性文本进行分析、处理、归纳和推理的过程。本次实验中,我基于python语言、pytorch深度学习框架,采用规则方法、统计方法和深度学习方法实现了汉语句子的情感极性判断,最终的测试正确率分别为68.7%,88.7%和91.2%。
实验一:基于规则的文本情感极性分析
1.1 基本原理
对语料进行情感打分,若score>0则为positive,反之为negative,其中涉及到情感词、否定词、程度副词、停用词四种词典。整体算法流程图如下图所示:
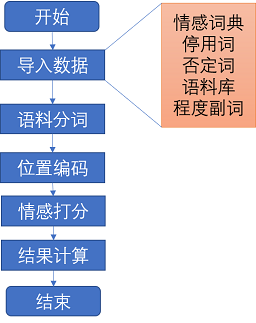
1.2 数据准备
1.2.1 BosonNLP情感词典
词典下载链接:https://kexue.fm/usr/uploads/2017/09/1922797046.zip。 据了解,此情感词典来源于社交媒体文本,适用于处理社交媒体的情感分析,对于其他种类样本进行分析效果不太好。
其用例展示如下:

词后面的数字表示为情感词的情感分数,正向为positive的词,负向为negative的词。
1.2.2 《知网》情感分析用词语集(beta 版):
词典下载链接:https://download.csdn.net/download/liulangdeyuyu/5729931?utm_source=bbsseo
为了增加情感词典的泛化性,我还选取了来自《知网》统计的情感分析用词作为辅助情感词典。
1.2.3 否定词词典
词典下载链接:https://kexue.fm/usr/uploads/2017/09/1922797046.zip
否定词可以直接将文本的内涵反转,而且还存在“否定之否定”这种叠加效果。常见的否定词如:不、没、无、非、难道 等等。
1.2.4 程度副词
该词典来源于《知网》标注语料中的程度副词
基于规则的方法核心是对每个文本进行打分,那么分数的绝对值大小也会表示情感强烈程度。因此,对于程度副词的引入就显得尤为重要。我对每个程度副词程度值进行后处理,数据格式可参考图3。总共两列,第一列为程度副词,第二列为程度数值。规则如下:极其2,超1.8,很1.5,较1.1,稍0.7,欠0.5。这里暂定以上为初始值,后续实验将会探讨该定义对结果影响。
1.5 实验结果
1.5.1 评价指标
为了评价分类器分类效果,我们采用正确率、准确率、错误率、召回率以及F-socre作为实验的评价指标。计算过程如下:
TP,FN,FP,TN = loss(neg_test,pos_test)
acc = (TP+TN)/(len(neg_test)+len(pos_test))
error = (FN+FP)/(len(neg_test)+len(pos_test))
precision = TP/(TP+FP)
recall = TP/(TP+FN)
F_score = 2*precision*recal/(precision+recall)
print("准确率:{:.3f},错误率:{:.3f},精准率:{:.3f},召回率:{:.3f},F-score:{:.3f}".format(acc,error,precision,recall,F_score))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
其中 T P 、 F N 、 F P 、 T N TP、FN、FP、TN TP、FN、FP、TN如下图所示:

1.5.2 单句情感计算
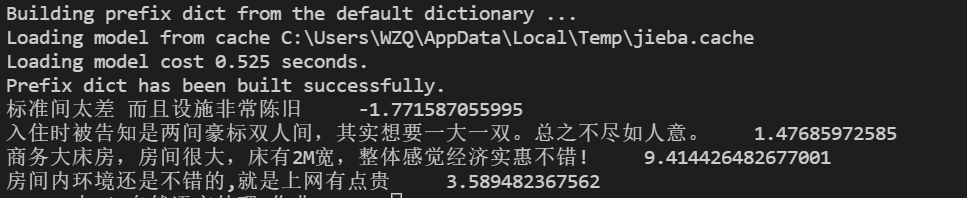
我随机选取了两句正例和两句负例进行情感计算,其预测结果如上图所示,有错有对。
1.5.3 酒店评价数据集情感计算
表1-1 数据集情感计算结果
| 正例(预测) | 负例(预测) | |
|---|---|---|
| 正例(真实) | 2721 | 278 |
| 负例(真实) | 1600 | 1399 |
表1-2 补充结果
| 评价指标 | 数值 |
|---|---|
| accuracy | 0.687 |
| error | 0.313 |
| precision | 0.630 |
| recall | 0.907 |
1.6 对比实验
1.6.1 使用《知网》用词语集(beta版)
相比于BosonNLP数据集,这里的每个词指被标记为负例为-1,正例为+1,没有了针对每个词特殊的情感量,结果如下:
表1-3 使用《知网》用词语集(beta版)结果
| 正例(预测) | 负例(预测) | |
|---|---|---|
| 正例(真实) | 2756 | 243 |
| 负例(真实) | 2536 | 436 |
表1-4 使用《知网》用词语集(beta版)结果
| 评价指标 | 数值 |
|---|---|
| accuracy | 0.532 |
| error | 0.468 |
| precision | 0.518 |
| recall | 0.919 |
由以上两表我们可以发现,使用该数据集后,召回率有近2%的提升,但是正确率却有15%的下降。究其原因,是由于负例预测出现了严重的问题,即竟然有2536个负例被错误预测为正向的情感。而在BosnNLP下的结果中,负例也有55%左右被预测为正向情感,这也说明了对于负向情感的预测才是更有难度的。
1.6.2 调整程度副词标注
-
去除程度副词
表1-5 去除程度副词结果
正例(预测) 负例(预测) 正例(真实) 2721 278 负例(真实) 1600 1399 表1-6 补充结果
评价指标 数值 accuracy 0.687 error 0.313 precision 0.630 recall 0.907 -
微调标注情况
此处调整标注结果为:极其1.8,超1.6,很1.5,较1,稍0.7,欠0.5。
表1-7 微调标注情况结果
| 正例(预测) | 负例(预测) | |
|---|---|---|
| 正例(真实) | 2721 | 278 |
| 负例(真实) | 1600 | 1399 |
表1-8 补充结果
| 评价指标 | 数值 |
|---|---|
| accuracy | 0.687 |
| error | 0.313 |
| precision | 0.630 |
| recall | 0.907 |
结果均没变!从该结果可以发现,对于程度副词来说,其大小对结果的影响微乎其微,也就是说改副词的引入只会对表达情感的强烈程度有关,和结果的情感取向无关,说明该引入是成功的!
1.6.3 删去未经修改的停词集
预处理部分应对停词进行再加工,即删去其中的程度副词和否定词,避免在语料中将其删除。这里不进行再加工,结果如下:
表1-9 删去未经修改的停词集结果
| 正例(预测) | 负例(预测) | |
|---|---|---|
| 正例(真实) | 2703 | 296 |
| 负例(真实) | 1560 | 1439 |
表1-10 补充结果
| 评价指标 | 数值 |
|---|---|
| accuracy | 0.691 |
| error | 0.309 |
| precision | 0.634 |
| recall | 0.901 |
由以上结果可知,相比于之前的结果,正例的预测总数减少,也就证明了停用词中的否定词对于原文本的情感判断是有影响的,需要进行再加工后使用。
实验二:基于朴素贝叶斯的文本情感极性分析
2.1 基本原理
朴素贝叶斯方法是目前公认的一种简单有效的分类方法,它是一种基于概率的算法。被广泛地用于模式识别、自然语言处理、机器学习等领域。
2.1.1 贝叶斯公式
贝叶斯公式就如下一行:
P
(
Y
∣
X
)
=
P
(
X
∣
Y
)
P
(
Y
)
P
(
X
)
P(Y|X)=\frac{P(X|Y)P(Y)}{P(X)}
P(Y∣X)=P(X)P(X∣Y)P(Y)
它其实是由以下的联合概率公式推导出来:
P
(
Y
,
X
)
=
P
(
Y
∣
X
)
P
(
X
)
=
P
(
X
∣
Y
)
P
(
Y
)
P(Y,X) = P(Y|X)P(X)=P(X|Y)P(Y)
P(Y,X)=P(Y∣X)P(X)=P(X∣Y)P(Y)
其中
P
(
Y
)
P(Y)
P(Y)叫做先验概率,
P
(
Y
∣
X
)
P(Y|X)
P(Y∣X)叫做后验概率,
P
(
Y
,
X
)
P(Y,X)
P(Y,X)叫做联合概率。
2.1.2 naive 贝叶斯分类
之所以称为“朴素”,是因为其做了简化假设:属性值在给定实例的分类是条件独立。当该假定成立时,朴素贝叶斯分类器可输出MAP分类。其工作过程如下:
- 对每一个语句,用唯一具有n维属性向量 X = { X 1 , X 2 , … , X n } X=\{X_1,X_2,\dots,X_n\} X={X1,X2,…,Xn}来表示该语句。
- 假定共有m个类别 C 1 , C 2 , … , C m C_1,C_2,\dots,C_m C1,C2,…,Cm,对于给定元组 X X X,分类法将把它预测为属于最高后验概率的类,即:
Y = m a x { P ( C i ∣ X ) } Y =max\{P(C_i|X)\} Y=max{P(Ci∣X)}
根据上文提到的贝叶斯定理:
P
(
C
i
∣
X
)
=
P
(
X
∣
C
i
)
P
(
C
i
)
P
(
X
)
P(C_i|X)=\frac{P(X|C_i)P(C_i)}{P(X)}
P(Ci∣X)=P(X)P(X∣Ci)P(Ci)
- 由于 P ( X ) P(X) P(X)对于所有的类为常量,只需要最大化 P ( X ∣ C i ) P ( C i ) P(X|C_i)P(C_i) P(X∣Ci)P(Ci)即可。如果类的先验概率相等(比如本次实验中利用平衡语料训练),那么最终只需要最大化 P ( X ∣ C i ) P(X|C_i) P(X∣Ci)。
- 对于 P ( X ∣ C i ) P(X|C_i) P(X∣Ci)的计算开销非常大,为降低其计算量引入“朴素的概念”,最终简化为:
P ( X ∣ C i ) = ∏ k = 1 n P ( x k ∣ C i ) P(X|C_i) = \prod_{k=1}^n P(x_k|C_i) P(X∣Ci)=k=1∏nP(xk∣Ci)
- 因为连乘的话最终结果可能非常小,不好比较,故做
l
o
g
(
)
log()
log()处理,如下:
l o g ( P ( X ∣ C i ) ) = ∑ k = 1 n P ( x k ∣ C i ) log(P(X|C_i))= \sum_{k=1}^n P(x_k|C_i) log(P(X∣Ci))=k=1∑nP(xk∣Ci)
2.2 数据准备+预处理
大部分同1.2节、1.3节所述。
2.6 对比实验
2.6.1 不加平滑处理结果
表2-2 不加平滑处理结果分类结果
| 评价指标 | 数值 |
|---|---|
| accuracy | 0.385 |
| error | 0.615 |
| precision | 0.417 |
| recall | 0.580 |
| F-score | 0.485 |
| training duration | 53.92 s |
若不加平滑处理,也就意味着没有能很好利用显著性特征进行分类判断,最终的F-score比加上低了50%,可见该操作对于朴素贝叶斯分类器是多么的重要。
2.6.2 对于分词长度无限制
表2-3 对于分词长度无限制后分类结果
| 评价指标 | 数值 |
|---|---|
| accuracy | 0.885 |
| error | 0.115 |
| precision | 0.884 |
| recall | 0.887 |
| F-score | 0.885 |
| training duration | 53.66 s |
从F值来看,对于无限制和有限制的结果,前者的正确率和F值均率低于后者,而且运行时间边快,所以还是对于模型训练有一定帮助。
2.6.3 引入特征计算
-
特征值(以正面分类器为例,已过滤掉词长为1)
- 未引入特征计算时,频度前18排名如下:

- 引入CHI特征计算后,特征值前18排名如下:

- 引入TF-IDF特征计算后,特征值前18排名如下:

从上述结果可以发现,经过CHI特征处理过后,前18个特征值能较好的代表正例情况,与未作处理相比具有显著提升。经过 D F − I D F DF-IDF DF−IDF提取特征后,结果与未引入时相对大小基本一致。
-
计算结果(CHI)
表2-4 引入特征计算后分类结果(CHI)
| 评价指标 | 数值 |
|---|---|
| accuracy | 0.723 |
| error | 0.277 |
| precision | 0.965 |
| recall | 0.463 |
| F-score | 0.626 |
| training duration | 102.71 s |
- 计算结果(TF-IDF)
表2-5 引入特征计算后分类结果(CHI)
| 评价指标 | 数值 |
|---|---|
| accuracy | 0.885 |
| error | 0.115 |
| precision | 0.884 |
| recall | 0.887 |
| F-score | 0.885 |
| training duration | 154.82 s |
从结果来看,引入CHI特征反而会降低15%左右的F值。但从理论上来讲,因为特征工程的引入使的具有显著性的特征,其特征值较大。据观察,分类结果中的精准度非常高,能达到96.5%,发现是由于负类样本几乎都分对了,但正例样本却出现了40%的正确率。据分析可能是由于,该语料中的表达“好”的特征并不显著,所以分类结果出现这种情况。引入 T F − I D F TF-IDF TF−IDF特征后,结果与未引入前相比影响不大。
2.6.4 top-K
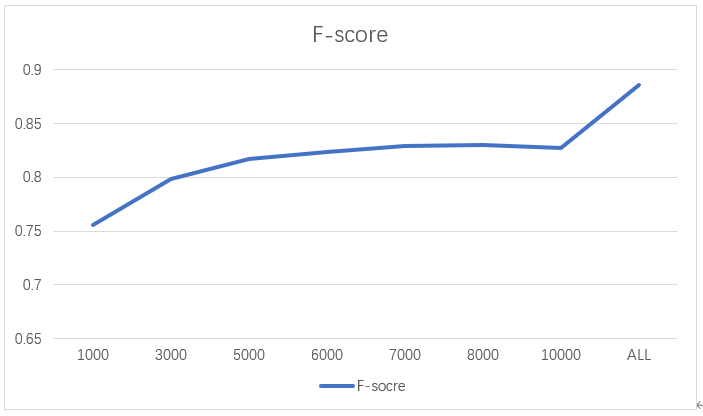
- 频度计算的top-K
- 引入特征计算的top-k
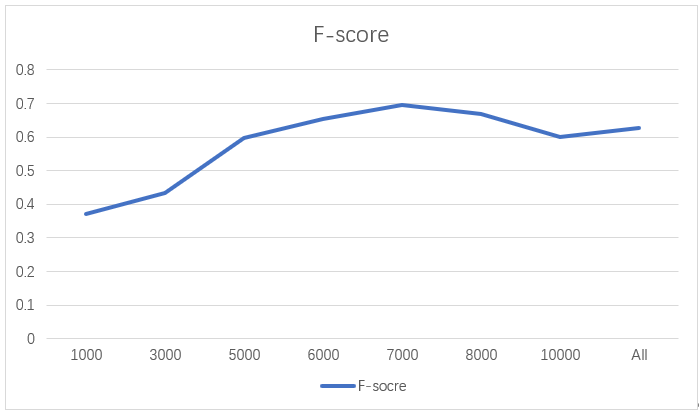
经过数次实验,最终发现在K取7000左右能较好地表达该语料情况。
实验三:基于逻辑回归的情感极性分析
3.1 基本原理
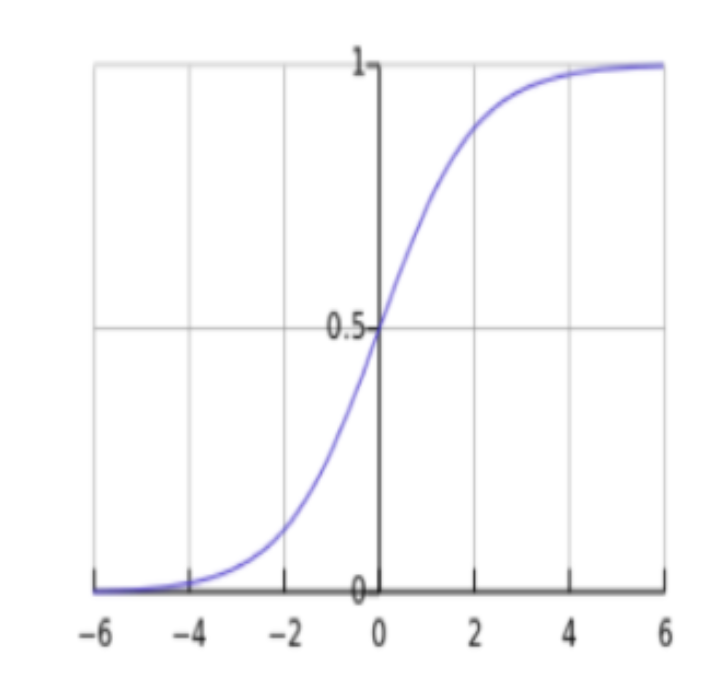
3.1.1 sigmoid函数
其函数形式为:
g
(
x
)
=
1
1
+
e
−
x
g(x)=\frac{1}{1+e^{-x}}
g(x)=1+e−x1
对应函数曲线如下图所示:
3.1.2 Word2vec 词向量
2012年,微软的实习生Mikolov发现了一种用一定维度的向量表示词的含义的方法,他训练了一个神经网络来预测每个目标词附件的共现词。他和他的队友在谷歌发布了创建这些词向量的软件,称为Word2vec。
该模型本质上是一种无监督学习算法,意图教网络预测句子中目标词附近的词,而不是通过带有此含义的标签直接学习目标词的含义。这章相邻词的“标注”来源于数据集本身,不需要手工标注,它能够捕捉更丰富的目标词含义
3.1.3 算法流程图
此处参考老师发在乐学上的PPT文件。

算法流程如上图所示。特别的,首先利用$$gensim.Word2vec$$第三方库进行酒店评论数据词向量的训练,得到300维的特征向量。对训练文本向量进行特征提取后,利用pytorch构建逻辑回归模型,进行模型训练。
- 1
3.2 数据准备+预处理
同样,这里的大部分操作如1.2节和1.3节所述。
3.2.1 词条预处理
在训练词向量模型时,gensim.Word2vec模型接收的输入是一个句子列表,其中每个句子都已经切分为词条。这样可以保证词向量模型不会学习到相邻句子种出现的无关词。训练输入类似于以下结构:
>>> token_list
[
['标准间','太','差','房间','还','3','星',……],
['好久','才','评价','记得','火车站','超近',……],
……
]
- 1
- 2
- 3
- 4
- 5
- 6
3.3 词向量训练
3.3.1 词向量训练
考虑到本数据集与酒店相关,故尝试定制化词向量来提高模型的精确率。为了训练该模型,此处引用gensim第三方库。
模行训练代码如下:
def model_train(token_list): num_features = 300 #向量元素的维度表示的词向量 min_word_count = 3 #最低词频 num_workers = 1 #训练使用的CPU核数 window_size = 3 #上下文窗口大小 subsampling = 1e-3 #高频词条采样率 model = Word2Vec( token_list, workers=num_workers, vector_size=num_features, min_count=min_word_count, window=window_size, sample=subsampling, epochs=50, sg=0 ) model.init_sims(replace=True) #丢弃不需要的输出权重 model_name = "my_word2vec" #模型命名 model.save(model_name) #模型保存 return True

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
其中参数sg代表word2vec模型的选择了。如果是0(默认), 则是CBOW模型,是1则是Skip-Gram模型。
3.3.2 词向量加载及评测
因为模型训练涉及到很多超参数,经过反复调试,最终选定训练轮数50为佳。这里分别尝试了CBOW模型和Skip-Gram模型进行训练。
相关代码如下:
model = Word2Vec.load("my_word2vec")
for e in model.wv.most_similar(positive=['脏'], topn=10):
print(e[0], e[1])
- 1
- 2
- 3
- CBOW(continuous bag of words)
结果如下图所示:

- Skip-gram模型
3.4 回归模型训练
Talk is cheap, show me the code.
3.4.1 划分数据集
这里需要将数据打乱(否则训练的模型就会偏向于最后训练接触的数据),并将数据处理格式为(data,label)的元组类型。数据分割比例仍未特别的,由于在模型训练时,只关注出现词频大于3的词汇,故在vector数据读入时会出现“词汇 does not present"的错误,利用python的异常处理解决。实现代码如下:
def data_split(data,model): ''' split the data for training, validating and testing ''' new = [] for i,x in enumerate(data): sentence = x[0] label = x[1] init = torch.zeros(size=[300]) for word in sentence: try: init += model.wv[word] except: pass new.append((init,label)) lenth_data = len(new) random.shuffle(data) train_dataset = new[:int(0.8*lenth_data)] val_dataset = new[int(0.8*lenth_data):int(0.9*lenth_data)] test_dataset = new[int(0.9*lenth_data):] return train_dataset,val_dataset,test_dataset
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
3.4.2 装载数据
利用torch的dataloader进行数据装载,方便训练时迭代取出计算,代码如下:
# 装载训练集
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
- 1
- 2
- 3
- 4
3.4.3 模型搭建
基于 p y t o r c h pytorch pytorch深度学习框架搭建逻辑回归模型
class logistic_net(nn.Module):
"""
logistic network.
"""
def __init__(self):
super(logistic_net, self).__init__()
self.layer = nn.Sequential(
nn.Linear(300,1),
nn.Sigmoid()
)
def forward(self, x):
x = self.layer(x)
return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3.4.4 模型相关操作
这部分涉及模型训练前的相关定义与初始化操作。
- 参数初始化
for name, param in net.named_parameters():
if 'weight' in name:
init.normal_(param, mean=0, std=0.01)
if 'bias' in name:
init.constant_(param, val=1)
- 1
- 2
- 3
- 4
- 5
- 优化器和损失函数定义
# 优化器选择SGD
optimizor= torch.optim.SGD(net.parameters(),lr=0.04,momentum=0.9)
# 损失函数选择BCE损失,专注于二分类问题
criterion = torch.nn.BCELoss(size_average=False)
- 1
- 2
- 3
- 4
- 其他
# 训练轮数
n_epoches = 500
# batch大小
batch_size = 100
- 1
- 2
- 3
- 4
3.5 实验结果
最终结果如下:
| epoch | batchsize | optimizor | criterion | train\ accuracy | test\ accuracy |
|---|---|---|---|---|---|
| 500 | 100 | SGD$$ | BCE | 0.945 | 0.912 |
训练正确率曲线如下:
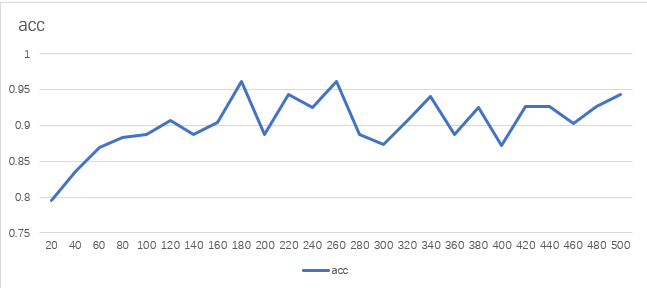
3.6 总结
在实验三中,我利用gensim第三方库完成语料的训练,将训练了300维的vector,并基于 p y t o r c h pytorch pytorch框架构建逻辑回归模型,针对酒店评价数据集进行训练,最终在测试集上达到了**91.2%**的正确率,均高于实验一和实验二中的结果。
实验总结
在本次自然语言处理实验中,我分别基于规则、朴素贝叶斯、逻辑回归进行情感语料极性判断。之所以选择该project是因为之前没有任何相关基础,想先从简单的项目做起,能够较为细致且全面地了解(作为小白而言)相关知识。
现对三个实验做一个总结:
-
实验一:在网上经过大量调研后,我选用酒店评论数据集作为分析对象,BosonNLP情感词典、《知网》情感分析词汇作为规则字典,并对停用词、程度副词、否定词做了相关处理,并进行大量对比试验,最终测试正确率为68.7%。
-
实验二:在第一个实验数据预处理的基础上,进一步做数据集分割。我构建了朴素贝叶斯分类器,并引入CHI特征、TF-IDF特征、Top-k、对数计算、平滑处理等tricks,最终达到了**88.7%**的测试正确率,显著高于实验一中的结果。
-
实验三:基于pytorch深度学习框架构建逻辑回归模型,并完成了数据集重载、模型初始化及模型训练测试等配套代码的撰写工作。同时为了更好地使词向量符合本数据集,我利用gensim进行词向量得训练。最终,模型测试正确率为91.2%,显示出了深度学习的强大。
资源下载地址:https://download.csdn.net/download/sheziqiong/85734418
资源下载地址:https://download.csdn.net/download/sheziqiong/85734418

