
- 1探索3D科研绘图:从学术图表入门到精通_3d科研绘图从入门到精通
- 2Matlab通信仿真系列——带限信道的信号传输_信号经过信道通信的matlab
- 3XCode 15.3 编译私有库 报错问题_xcode15.3 报错“phasescriptexecution failed with a no
- 4详解分布式共识(一致性)算法Raft_raft 共识总称
- 5阿里云生活物联网平台中Android Demo运行_阿里云生活物联网app开源
- 6区块链浏览器_aelf区块链浏览器概述及使用说明
- 7DOS命令集
- 8多元线性回归算法python实现(非常经典)_import numpy as np import matplotlib.pyplot as plt
- 9探秘DeBERTa:微软开源的预训练语言模型
- 10IntelliJ IDEA License Server 安装使用 Mac篇
Python爬虫之旅(一):小白也能懂的爬虫入门_里的东西如何获取
赞
踩
里的东西如何获取
爬虫是什么
爬虫就是按照一定的规则,去抓取网页中的信息。爬虫流程大致分为以下几步:
- 向目标网页发送请求
- 获取请求的响应内容
- 按照一定的规则解析返回的响应内容,获得想要的信息
- 将获取的信息保存下来
战前准备
在正式开始前,我们先看下我们需要准备些什么:
- 开发环境:Python3.6
- 开发工具:PyCharm
- 使用框架:requests2.21.0、lxml4.3.3
以上是本次开发中使用到的东西,使用 PyCharm 在 Python3.6 下开发,开发使用到两个框架 requests 和 lxml,非常简单。
开战
创建项目
-
创建一个 Pure Python(纯净的Python项目) 项目即可,不需要使用其他框架,项目名随意,我在例子中取的是
py-spiderman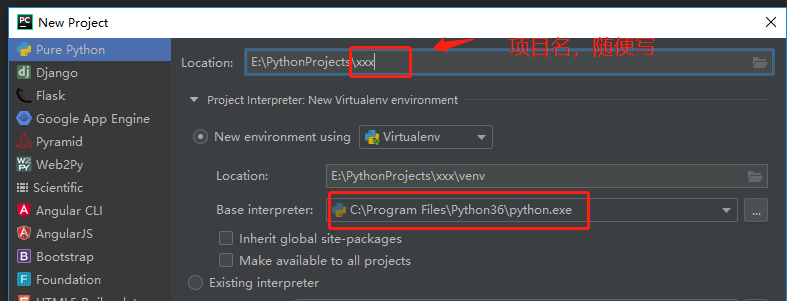
-
创建一个python文件,文件名随意,我在例子中取的是
first_spider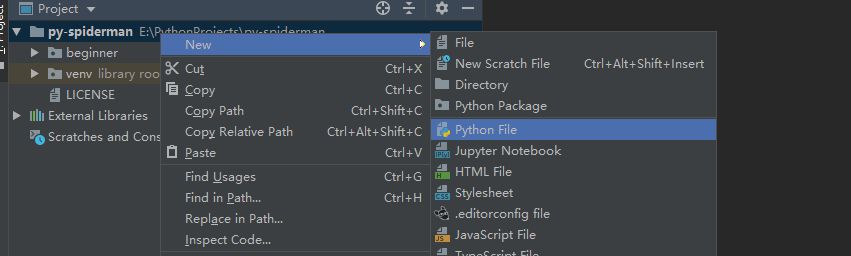
安装 requests 和 lxml
-
requests 是 Python 中非常强大的一个网络请求模块,简单易用,
直接在 PyCharm 的 Terminal 中输入pip install requests即可。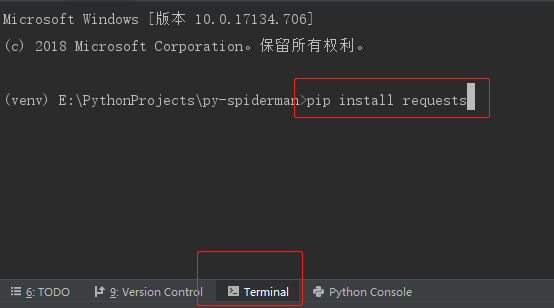
-
lxml 是我们用来解析请求的响应内容的模块,使用 XPath 语法,非常强大。安装方法同上,在 Terminal 中输入
pip install lxml即可。
开始编程
开始编程前,我们先选择一个目标网页,本示例的目标网页是 https://www.archdaily.cn/cn/915495/luo-shan-ji-guo-ji-ji-chang-xin-lu-ke-jie-yun-xi-tong-yi-dong-gong
我们需要抓取网页中的文章标题、时间、作者以及内容文本信息。

我们在创建的 python 文件中,先导入需要使用到的模块,再创建一个名为 SimpleSpider 的 class,然后在 class 编写爬虫方法
- # 导入系统信息模块,用于获取项目根目录
- import os
- # 导入网络请求库,用于请求目标网页,获取网页内容
- import requests
- # 导入时间库,用于获取当前时间
- from datetime import datetime
- # 导入 lxml 的 etree 模块,用于解析请求返回的 html
- from lxml import etree
-
- # 创建一个爬虫类
- class SimpleSpider:
python 中方法使用 def 进行标识,方法前添加双下滑线表示方法为类的私有方法,不得被外部访问。requests 的 get() 方法可以直接向网页发送一个 get 请求,并返回一个 response 对象。
- def __get_target_response(self, target):
- """
- 发送请求,获取响应内容
- :param target(str): 目标网页链接
- """
- # 向目标 url 发送一个 get 请求,返回一个 response 对象
- res = requests.get(target)
- # 返回目标 url 的网页 html 文本
- return res.text
在解析响应内容前,我们先使用Chrome浏览器打开目标网页,并打开网页源码,点击键盘的 F12 即可,然后在源码中寻在我们需要的信息,比如说标题,如下图: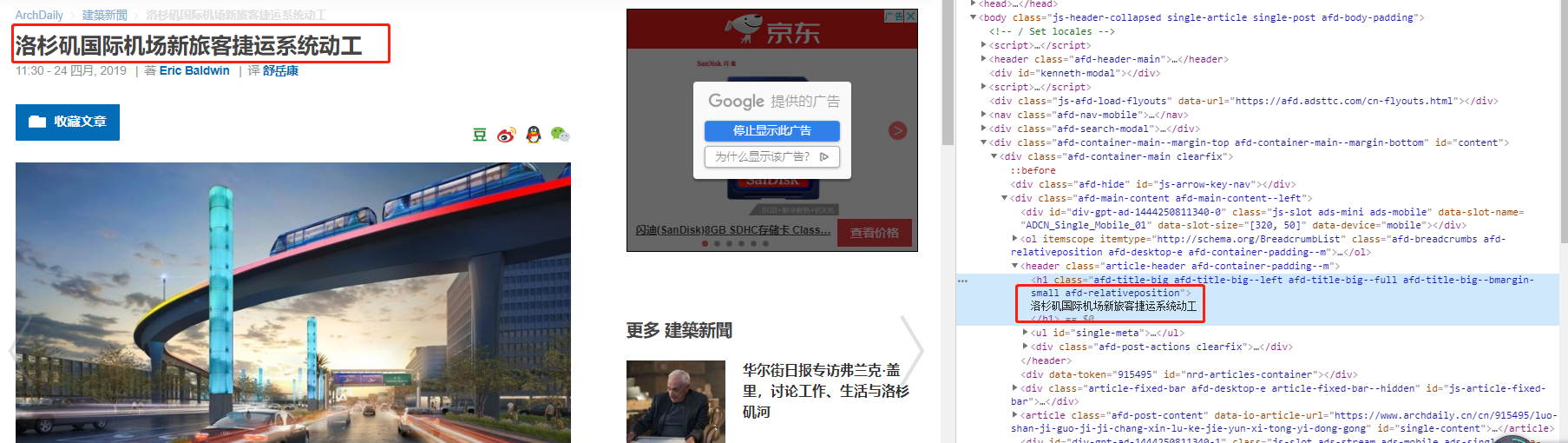

从图中可知,标题在 header 标签下的 h1 标签中,那么我们如何提取出来呢?这时就需要用到我们导入的 lxml 库中的 etree 模块,那么 etree 如何使用呢?
- 首先我们先通过 etree.HTML() 的方法创建一个 基于XPath的解析对象,这里如果不懂 XPath 的去花一分钟时间了解下,很简单 。
dom = etree.HTML(上述方法返回的响应内容文本)
这里的 dom 对象就是将 html 文本转换后的 html 内容元素
- 然后就可以开始解析了,如下
title = dom.xpath('//h1/text()')[0]
//h1/text()是一句 XPath语句,//指当前节点下的所有子孙节点,你可以简单的理解为 <html> 标签下的所有节点,//h1 就是指 <html> 节点下的所有 <h1> 标签,h1/text() 则是指 <h1> 标签下的文本内容,但是仅仅是第一层级的文本内容,例:<h1> ABC </h1>的 h1/text() 值为 ABC,但是 <h1> ABC <span> SS </span></h1> 的h1/text() 值还是 ABC,而不是 ABCSS,因为 SS 被 <span> 标签包裹,属于第二层级了。
所以以上 //h1/text() 的意思就是获取 <html> 标签下所有 <h1> 标签下的第一层的文本内容,如果有多个 <h1> 标签就会按 <h1> 标签在 html 中的顺序返回一个文本内容数组。如果只有一个 <h1> 标签,还是返回一个数组,不过里面只有一个文本内容。在当前网页中,只有一个 <h1> 标签,所以返回一个只有一个元素的数组,[0]则表示获取数组中的第一个元素。
完整的解析代码如下:
- def __parse_html(self, res):
- """
- 解析响应内容,使用 XPath 解析 html 文本,并保存
- :param res(str): 目标网页的 html 文本
- """
- # 初始化生成一个 XPath 解析对象,获取 html 内容元素
- dom = etree.HTML(res)
- # 获取 h1 标签中的文字内容,其中 dom.xpath('//h1/text()')返回的是数组,提取一个元素
- title = dom.xpath('//h1/text()')[0]
- # 获取 class="theDate" 的 li 标签中的文字内容
- date = dom.xpath('//li[@class="theDate"]/text()')[0]
- # 获取 rel="author" 的 a 标签中的文字内容
- author = dom.xpath('//a[@rel="author"]/strong/text()')[0]
- # 获取 rel="author" 的 a 标签中的 href 属性内容
- author_link = 'https://www.archdaily.cn/' + dom.xpath('//a[@rel="author"]/@href')[0]
- # 获取 article 标签下的所有不含属性的 p 标签元素
- p_arr = dom.xpath('//article/p[not(@*)]')
- # 创建一个数组用于存储文章中的段落文本
- paragraphs = []
- # 遍历 p 标签数组
- for p in p_arr:
- # 提取 p 标签下的所有文本内容
- p_txt = p.xpath('string(.)')
- if p_txt.strip() != '':
- paragraphs.append(p_txt)
- paragraphs = paragraphs

此部分是拼接上一部分代码,属于方法 __parse_html(self, res) ,为了更好理解爬虫流程,故此拆分。我们将信息写入一个txt文件,文件名是字符串 first 后面拼接当前时间字符串,文件所在目录为项目的根目录。
- # 如果文件不存在会自动创建
- # os.getcwd() 获取项目的根目录
- # datetime.now().strftime('%Y%m%d%H%M%S')获取当前的时间字符串
- with open('{}/first{}.txt'.format(os.getcwd(), datetime.now().strftime('%Y%m%d%H%M%S')), 'w') as ft:
- ft.write('标题:{}\n'.format(title))
- ft.write('时间:{}\n'.format(date))
- ft.write('作者:{}({})\n\n'.format(author, author_link))
- ft.write('正文:\n')
- for txt in paragraphs:
- ft.write(txt + '\n\n')
既然基本方法都写好了,那么我们先把所有方法串联起来,我们可以另写一个方法将上述方法连接起来:
- def crawl_web_content(self, target):
- """
- 爬虫执行方法
- :param target(str): 目标网页链接
- """
- # 调用网络请求方法,并返回一个 response
- res = self.__get_target_response(target)
- # 调用解析 response 方法
- self.__parse_html(res)
然后我们编写一个执行方法
- if __name__ == '__main__':
- url = 'https://www.archdaily.cn/cn/915495/luo-shan-ji-guo-ji-ji-chang-xin-lu-ke-jie-yun-xi-tong-yi-dong-gong'
- spider = SimpleSpider()
- spider.crawl_web_content(url)
保存下来的txt的文本内容如下:
- 标题:
- 洛杉矶国际机场新旅客捷运系统动工
-
- 时间:11:30 - 24 四月, 2019
- 作者:Eric Baldwin(https://www.archdaily.cn//cn/author/eric-baldwin)
-
- 正文:
- 洛杉矶国际机场的新旅客捷运系统现已开工。建成后,地上火车将帮助旅客穿梭于洛杉矶轻轨与机场。上周,洛杉矶市长Eric Garcetti 参加了为庆祝工程开工的市政活动,LAX希望该项目能提升航站楼之间的联系,并且减少进出机场的机动车拥堵。作为世界上最繁忙的机场之一,新系统将刚落成的租车设施串联起来,旨在为LAX减少交通压力。
-
- 捷运系统破土动工仪式于上周四举行。去年,城市委员会同意了LAX联合捷运方案,整个工程将花费49亿美元。作为全球第四大繁忙的机场,LAX正在寻找降低机动车出入依赖的方式。LAWA的官员预计新系统建成后,每年访客的流量将达8500万次。新系统将在 6 个站点停留,其中有3 个站点在机场航站楼中。
-
- 正如LAWA申明,捷运系统期望连接绿线地铁(the Metro Green)、Crenshaw/ LAX轻轨线以及固定的租车中心,目标是将超过20个租车办公室集中在一个地点。这个设施将减少因租车需求而进出中心航站楼区域的免费通行车辆,并且每天减少约3200辆进出机场的机动车。地上火车约两分钟一班,每班可载客200人。
-
- 捷运系统预计2023年完工。翻译:彭莉
传送门
Github:https://github.com/albert-lii/py-spiderman
总结
以上是本文的全部内容,只是个简单的爬虫示例,在后续文章中会逐渐进行升级爬虫功能,比如同时爬取多个网页内容,如何提高效率,如何使用强大的爬虫框架 scrapy 等。


