
- 1开源大数据工具整理_最全大数据组件整理
- 2Android的四种监听事件处理方式_简述 android 系统基于监听的事件处理机制的 4 种实现方式。
- 3面向文档的代理:矢量数据库、chatgpt、Langchain、FastAPI 和 Docker 之旅,利用 ChromaDB、Langchain 和 ChatGPT:增强大型文档数据库的响应和引用来_docker chromadb
- 4git合并远程库并将代码合并完提交到自己的分支的流程_合并其他人的代码后提交自己的代码
- 5spark概述和scala的安装部署
- 6找到服务器系统日志,查看服务器系统日志
- 7数据结构学习——树形结构之递归遍历二叉树
- 8消费级显卡轻松跑AI,英伟达RTX领跑AI PC竞争
- 9Hive 常用函数_hive lpad
- 10android自定义选年控件,Android精美日历控件CalendarView自定义使用完全解析
机器学习超详细实践攻略(10):随机森林算法详解及小白都能看懂的调参指南_随机森林公式 csdn
赞
踩
一、什么是随机森林
前面我们已经介绍了决策树的基本原理和使用。但是决策树有一个很大的缺陷:因为决策树会非常细致地划分样本,如果决策树分得太多细致,会导致其在训练集上出现过拟合,而如果决策树粗略地划分样本,又不能很好地拟合样本。
为了解决这个两难困境,聪明的专家们想出了这样的思路:既然我增加单棵树的深度会适得其反,那不如我不追求一个树有多高的精确度,而是训练多棵这样的树来一块预测,一棵树的力量再大,也是有限的,当他们聚成一个集体,它的力量可能是难以想象的,也就是我们常说的:“三个臭皮匠赛过诸葛亮”。这便是集成学习的思想。
这里多提一句,正是因为每棵树都能够用比较简单的方法细致地拟合样本,我们可以多用几棵树来搭建准确率更高的算法,后边要说到的一些工业级的算法,比如GBDT、XGBOOST、LGBM都是以决策树为积木搭建出来的。
所以在学习这些算法的过程中,我们也要把决策树算法看成一块块积木,学完了基本的积木算法之后,对于现在常用的那几个工业级的算法,只需要理清两个问题:
1)这个算法利用了哪个集成学习思想
2)这个算法具体怎么把这个思想实现出来的。
随机森林就是决策树们基于bagging集成学习思想搭建起来的。
随机森林的算法实现思路非常简单,只需要记住一句口诀:抽等量样本,选几个特征,构建多棵树。
下面,我们详细解释这个口诀的含义:
1)抽等量样本
随机森林训练每棵树之前,都会从训练集中随机抽出一部分样本来训练。所以说训练每棵树用到的样本其实都是有差别的,这样就保证了不同的树可以重点学习不同的样本。而为了达到抽等量样本的目的,抽样方式一般是有放回的抽样,也就是说,在训练某棵树的时候,这一次被抽到的样本会被放回数据集中,下一次还可能被抽到,因此,原训练集中有的样本会多次被抽出用来训练,而有的样本可能不会被使用到。
但是不用担心有的样本没有用到,只要训练的树的棵数足够多,大多数训练样本总会被取到的。有极少量的样本成为漏网之鱼也不用担心,后边我们会筛选他们出来用来测试模型。
2)选几个特征
在训练某棵树的时候,也不是将样本的所有特征都用来训练,而是会随机选择一部分特征用来训练。这样做的目的就是让不同的树重点关注不同的特征。在scikit-learn中,用“max_features”这个参数来控制训练每棵树选取的样本数。
3)构建多棵树。
通过1)、2)两个步骤,训练多棵树。鲁迅曾经说过:世界上本没有森林,长得树多了,就成了森林。正是一棵棵决策树构成了整个随机森林。具体构建树的数量,在scikit-learn中,用“n_estimators”这个参数来控制。

那最终的预测结果怎么得到呢?随机森林是非常民主的算法,最终的结果由每棵决策树综合给出:如果是分类问题,那么对于每个测试集,树都会预测出一个类别进行投票,最终统计票数多的那个类别为最终类别。看看,这算法俨然是一个遵循:“少数服从多数”的原则的小型民主社会;如果是回归问题,那就更简单了,各个树得到的结果相加求得一个平均值为最终回归结果。
从上边的流程中可以看出,随机森林的随机性主要体现在两个方面:**数据集的随机选取、每棵树所使用特征的随机选取。**以上两个随机性使得随机森林中的决策树都能够彼此不同,提升系统的多样性,从而提升分类性能。
二、随机森林的特点
以上就是随机森林的构建原理,下面,我们说说随机森林算法的优缺点:
1、优点:
1)实现简单,泛化能力强,可以并行实现,因为训练时树与树之间是相互独立的;
2)相比单一决策树,能学习到特征之间的相互影响,且不容易过拟合;
3)能直接特征很多的高维数据,因为在训练过程中依旧会从这些特征中随机选取部分特征用来训练;
4)相比SVM,不是很怕特征缺失,因为待选特征也是随机选取;
5)训练完成后可以给出特征重要性。当然,这个优点主要来源于决策树。因为决策树在训练过程中会计算熵或者是基尼系数,越往树的根部,特征越重要。
2、缺点
1)在噪声过大的分类和处理回归问题时还是容易过拟合;
2)相比于单一决策树,它的随机性让我们难以对模型进行解释。
三、随机森林的使用
和决策树类似,随机森林同样可以分为分类森林(RandomForestClassifier )和回归森林(RandomForestRegressor),在scikit-lean中调用方式和决策树相同。
让我们在手写识别数据集上实现一个分类森林。
#导入必要的包
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split,GridSearchCV,cross_val_score
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import numpy as np
#导入数据集
data = load_digits()
x = data.data
y = data.target
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
用随机森林训练并进行交叉验证:
RF = RandomForestClassifier(random_state = 66)
score = cross_val_score(RF,x,y,cv=10).mean()
print('交叉验证得分: %.4f'%score)
- 1
- 2
- 3
输出:
交叉验证得分: 0.9278
四、随机森林调参
一)随机森林参数介绍
除了和决策树有的参数之外,对于随机森林,只需要掌握8个新增的参数即可,我将这8个参数分成三类:
1、用于调参的参数:
- max_features(最大特征数): 这个参数用来训练每棵树时需要考虑的最大特征个数,超过限制个数的特征都会被舍弃,默认为auto。可填入的值有:int值,float(特征总数目的百分比),“auto”/“sqrt”(总特征个数开平方取整),“log2”(总特征个数取对数取整)。默认值为总特征个数开平方取整。值得一提的是,这个参数在决策树中也有但是不重要,因为其默认为None,即有多少特征用多少特征。为什么要设置这样一个参数呢?原因如下:考虑到训练模型会产生多棵树,如果在训练每棵树的时候都用到所有特征,以来导致运算量加大,二来每棵树训练出来也可能千篇一律,没有太多侧重,所以,设置这个参数,使训练每棵树的时候只随机用到部分特征,在减少整体运算的同时还可以让每棵树更注重自己选到的特征。
- n_estimators:随机森林生成树的个数,默认为100。
2、控制样本抽样参数:
- bootstrap:每次构建树是不是采用有放回样本的方式(bootstrap samples)抽取数据集。可选参数:True和False,默认为True。
- oob_score:是否使用袋外数据来评估模型,默认为False。
boostrap和 oob_score两个参数一般要配合使用。如果boostrap是False,那么每次训练时都用整个数据集训练,如果boostrap是True,那么就会产生袋外数据。
先解释一下袋外数据的概念:
在一个含有n个样本的原始训练集中,我们每次随机取出一个样本并记录,并在抽取下一个样本之前将该样本放回原始训练集,即下次采样时这个样本依然可能被采集到,这样采集n次,最终得到一个和原始训练集一样大的子数据集。
由于是随机采样,这样每次的子数据集和原始数据集都不同,用这些子数据集来各自训练一棵树,这些树的参数自然也就各不相同了。
然而有放回抽样也会有自己的问题。由于是有放回,一些样本可能在同一个自助集中出现多次,而其他一些却可能被忽略,一般来说,每一次抽样,某个样本被抽到的概率是 1/n ,所以不被抽到的概率就是 1-1/n ,所以n个样本都不被抽到的概率就是: ( 1 − 1 n ) n (1-\frac{1}{n})^n (1−n1)n 用洛必达法则化简,可以得到这个概率收敛于(1/e),约等于0.37。
因此,如果数据量足够大的时候,会有约37%的训练数据被浪费掉,没有参与建模,这些数据被称为袋外数据(out of bag data,简写为oob)。
为了这些数据不被浪费,我们也可以把他们用来作为集成算法的测试集。也就是说,在使用随机森林时,我们可以不划分测试集和训练集,只需要用袋外数据来测试我们的模型即可。
当然,这需要样本数据n和分类器个数n_estimators都很大,如果数据集过少,很可能就没有数据掉落在袋外,自然也就无法使用oob数据来测试模型了。
当bootstrap参数取默认值True时,表示抽取数据集时采用这种有放回的随机抽样技术。如果希望用袋外数据来测试,则需要在实例化时就将oob_score这个参数调整为True,训练完毕之后,我们可以用随机森林的另一个重要属性:oob_score_来查看我们的在袋外数据上测试的结果,代码如下:
#训练一个模型,让oob_score=True
RF1 = RandomForestClassifier(n_estimators=25,oob_score=True)
RF1 =RF1.fit(x,y)
#查看oob_score_,即袋外误差
RF1.oob_score_
- 1
- 2
- 3
- 4
- 5
输出:0.9393433500278241
这个就是没有参与训练的数据集在模型上的测试得分。
3、不重要参数
- max_samples:构建每棵树需要抽取的最大样本数据量,默认为None,即每次抽取样本数量和原数据量相同。
- n_jobs::设定fit和predict阶段并列执行的CPU核数,如果设置为-1表示并行执行的任务数等于计算机核数。默认为None,即采用单核计算。
- verbose:控制构建数过程的冗长度,默认为0。一般不需要管这个参数。
- warm_start:当设置为True,重新使用之前的结构去拟合样例并且加入更多的估计器(estimators,在这里就是随机树)到组合器中。默认为 False
以上这几个参数只需要简单了解即可,大多数参数在使用过称重不用调整,只是需要注意一点,n_jobs默认为None,为了加快速度,可以把n_jobs设置为-1。
二)随机森林调参顺序
介绍完了这些参数,接下来就要介绍随机森林的调参顺序了,随机森林的调参顺序一般遵循先重要后次要、先粗放后精细的原则,即先确定需要多少棵树参与建模,再对每棵树做细致的调参,精益求精。
相对于xgboost等算法,随机森林的调参还是相对比较简单,因为各个参数之间互相影响的程度很小,只需要按步骤调整即可。
结合我们决策树文章中提到的参数以及今天所讲的两个参数,随机森林中主要用来调参的参数有6个:
- n_estimators:
- criterion
- max_depth
- min_samples_split
- min_samples_leaf
- max_features
调参顺序如下:
1)选择criterion参数(决策树划分标准)
和决策树一样,这个参数只有两个参数 ‘entropy’(熵) 和 ‘gini’(基尼系数)可选,默认为gini,这里简单测试一下就好
RF = RandomForestClassifier(random_state = 66)
score = cross_val_score(RF,x,y,cv=10).mean()
print('基尼系数得分: %.4f'%score)
RF = RandomForestClassifier(criterion = 'entropy',random_state = 66)
score = cross_val_score(RF,x,y,cv=10).mean()
print('熵得分: %.4f'%score)
- 1
- 2
- 3
- 4
- 5
- 6
输出:
基尼系数得分: 0.9278
熵得分: 0.9249
这里看到,依旧是选用gini系数模型效果更好。
2)探索n_estimators的最佳值。
接下来才是进入真正的调参环节。根据上述调参原则,我们先看看用几棵树模型的表现最好。一般来说,树的棵数越多,模型效果表现越好,但树的棵数达到一定的数量之后,模型精确度不再上升,训练这个模型的计算量却逐渐变大。这个时候,再加树的数量就没必要了。就好比你饿的时候每吃一个馒头就特别顶饱,但是吃到一定数量的馒头之后,再吃就要撑着了。
只要找到这个临界值,这个参数就调好了。为了观察得分随着树增多的变化,我们依然绘制决策树调参时的学习曲线。
###调n_estimators参数
ScoreAll = []
for i in range(10,200,10):
DT = RandomForestClassifier(n_estimators = i,random_state = 66) #,criterion = 'entropy'
score = cross_val_score(DT,data.data,data.target,cv=10).mean()
ScoreAll.append([i,score])
ScoreAll = np.array(ScoreAll)
max_score = np.where(ScoreAll==np.max(ScoreAll[:,1]))[0][0] ##这句话看似很长的,其实就是找出最高得分对应的索引
print("最优参数以及最高得分:",ScoreAll[max_score])
plt.figure(figsize=[20,5])
plt.plot(ScoreAll[:,0],ScoreAll[:,1])
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
输出:
最优参数以及最高得分: [120. 0.95560035]
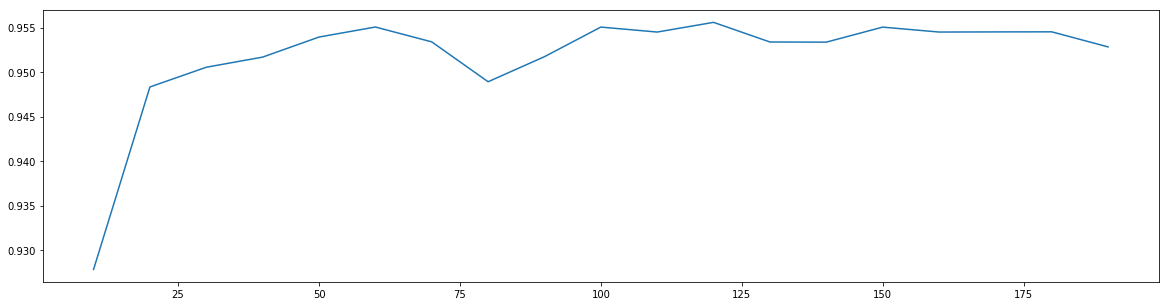
根据曲线,我们进一步缩小范围,搜索100~130之间的得分。(这里可以根据经验自己指定)
###进一步缩小范围,调n_estimators参数
ScoreAll = []
for i in range(100,130):
DT = RandomForestClassifier(n_estimators = i,random_state = 66) #criterion = 'entropy',
score = cross_val_score(DT,data.data,data.target,cv=10).mean()
ScoreAll.append([i,score])
ScoreAll = np.array(ScoreAll)
max_score = np.where(ScoreAll==np.max(ScoreAll[:,1]))[0][0] ##这句话看似很长的,其实就是找出最高得分对应的索引
print("最优参数以及最高得分:",ScoreAll[max_score])
plt.figure(figsize=[20,5])
plt.plot(ScoreAll[:,0],ScoreAll[:,1])
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
输出:
最优参数以及最高得分: [117. 0.95727946]
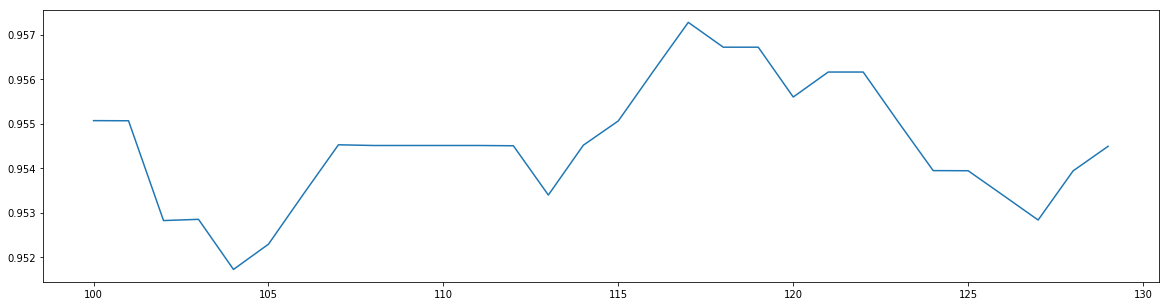
可以看到,117为得分最高点,我们暂定n_estimators为117,接着调下边的参数。
3)探索max_depth(树的最大深度)最佳参数
###粗调max_depth参数
ScoreAll = []
for i in range(10,30,3):
DT = RandomForestClassifier(n_estimators = 117,random_state = 66,max_depth =i ) #,criterion = 'entropy'
score = cross_val_score(DT,data.data,data.target,cv=10).mean()
ScoreAll.append([i,score])
ScoreAll = np.array(ScoreAll)
max_score = np.where(ScoreAll==np.max(ScoreAll[:,1]))[0][0] ##这句话看似很长的,其实就是找出最高得分对应的索引
print("最优参数以及最高得分:",ScoreAll[max_score])
plt.figure(figsize=[20,5])
plt.plot(ScoreAll[:,0],ScoreAll[:,1])
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
输出:
最优参数以及最高得分: [16. 0.95727946]

转折点在16,但是16之后一直没有变化,可以说明就算不限制,所有树的最大深度也就是16左右,因为我们以步长为3搜索的,所以还需要进一步搜索一下16附近的值。
精细搜索之后发现,16这个值就是转折点,所以暂定max_depth = 16。
4)探索min_samples_split(分割内部节点所需的最小样本数)最佳参数
min_samples_split最小值就是2,我们就从2开始调起。
###调min_samples_split参数
ScoreAll = []
for i in range(2,10):
RF = RandomForestClassifier(n_estimators = 117,random_state = 66,max_depth =16,min_samples_split = i ) #,criterion = 'entropy'
score = cross_val_score(RF,data.data,data.target,cv=10).mean()
ScoreAll.append([i,score])
ScoreAll = np.array(ScoreAll)
max_score = np.where(ScoreAll==np.max(ScoreAll[:,1]))[0][0] ##这句话看似很长的,其实就是找出最高得分对应的索引
print("最优参数以及最高得分:",ScoreAll[max_score])
plt.figure(figsize=[20,5])
plt.plot(ScoreAll[:,0],ScoreAll[:,1])
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
输出:
最优参数以及最高得分: [2. 0.95727946]
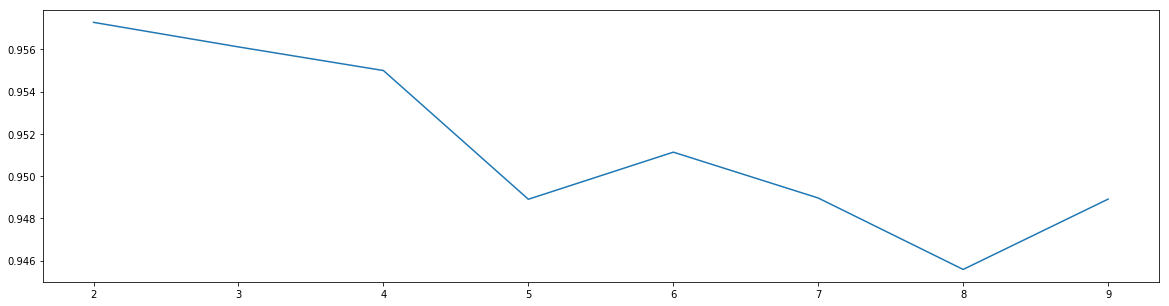
可以看到,随着min_samples_split增大,模型得分下降,说明没有出现过拟合现象,min_samples_split暂定2。
5)探索min_samples_leaf(分割内部节点所需的最小样本数)最佳参数
###调min_samples_leaf参数
ScoreAll = []
for i in range(1,15,2):
DT = RandomForestClassifier(n_estimators = 117,random_state = 66,max_depth =16,min_samples_leaf = i,min_samples_split = 2 )
score = cross_val_score(DT,data.data,data.target,cv=10).mean()
ScoreAll.append([i,score])
ScoreAll = np.array(ScoreAll)
max_score = np.where(ScoreAll==np.max(ScoreAll[:,1]))[0][0] ##这句话看似很长的,其实就是找出最高得分对应的索引
print("最优参数以及最高得分:",ScoreAll[max_score])
plt.figure(figsize=[20,5])
plt.plot(ScoreAll[:,0],ScoreAll[:,1])
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
输出:
最优参数以及最高得分: [1. 0.95727946]

5)对每棵树用到的最大特征数max_features调参:
正常来说,只要这个值不要设置得太小,所有特征都会被整个森林抽取到用来训练, 所以相对来说这个值对整个模型的影响不是太大。但这个值越大,单棵树需要考虑的特征越多,虽然模型的表现可能会更好,但是增加这个值会导致算法运行速度变慢,所以需要我们考虑去找一个平衡值。
#调max_features参数
param_grid = {
'max_features':np.arange(0.1, 1)}
rfc = RandomForestClassifier(random_state=66,n_estimators = 117,max_depth = 16,min_samples_leaf =1 ,min_samples_split =4 )
GS = GridSearchCV(rfc,param_grid,cv=10)
GS.fit(data.data,data.target)
print(GS.best_params_)
print(GS.best_score_)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
输出:
{‘max_features’: 0.1}
0.9560335195530726
如果时间充裕,接下来也可以将min_samples_leaf和min_samples_split作为网格参数联调一下,因为这两个参数会相互影响,这里暂时省略这一步。
此时,我们得到的参数如下:
| 参数 | 值 |
|---|---|
| n_estimators | 117 |
| max_depth | 16 |
| min_samples_leaf | 1 |
| min_samples_split | 2 |
| max_features | 0.1 |
6)在得到的最优参数附近进行小范围网格搜索
因为手动调参时,这些参数可能会相互影响,导致我们得到的参数还不是最优的。所以在最优参数附近进行小范围的网格搜索,排出相互影响的因素,尤其是在数据集量比较少时,小范围搜索一下可能会有意外收获。
import time start = time.time() param_grid = { 'n_estimators':np.arange(140, 150), 'max_depth':np.arange(15, 18), 'min_samples_leaf':np.arange(1, 8), 'min_samples_split':np.arange(2, 5), 'max_features':np.arange(0.1, 1) } rfc = RandomForestClassifier(random_state=66) GS = GridSearchCV(rfc,param_grid,cv=10) GS.fit(data.data,data.target) end = time.time() print("循环运行时间:%.2f秒"%(end-start)) print(GS.best_params_) print(GS.best_score_)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
输出如下:
循环运行时间:3052.67秒
{‘max_depth’: 16, ‘max_features’: 0.1, ‘min_samples_leaf’: 1, ‘min_samples_split’: 3, ‘n_estimators’: 143}
0.9599332220367279
可以看到,精确度又上升了一点,此时,我们得到的新旧参数对比如下:
| 参数 | 旧值 | 新值 |
|---|---|---|
| n_estimators | 117 | 143 |
| max_depth | 16 | 16 |
| min_samples_leaf | 1 | 1 |
| min_samples_split | 2 | 3 |
| max_features | 0.1 | 0.1 |
对比一下新旧参数,可以看到参数变化还是比较大的,尤其是树的棵数这个参数。当然,这里主要原因是我们用来做示例的这个预置的数据集只有1797条数据,导致参数的随机性太大,在实际使用中数据集数量都是十万百万级的,不会出现我们手动调整的参数和小范围网格搜索参数差别这么大的情况。
最后需要说明的一点是:随机森林相对于决策树来说运行较慢,在调参时可以将参数搜索范围设置得小一些。
当然,这只是我个人的调参顺序,仅用来参考,没必要这么固化。实际调参时可以根据实际情况做一些调整。还是那句话:正是调参过程充满的各种不确定性,才是调参的真正魅力所在。

