- 1Mac上redis下载安装与配置详细版_mac 从官网下载安装redis
- 2两年半Python练习生~收藏一份练习,建议收藏_python函数练习
- 3spring boot3单模块项目工程搭建-下(个人开发模板)
- 4AI大模型低成本快速定制法宝:RAG和向量数据库_rag ai
- 5什么是网络安全?
- 62021年秋招小米Android面经-已获offer_小米面试共享敲代码
- 7elementUI之el-select选择器赋值为空后无法选中回显_element el-select数据为空的禁止选择
- 8解决Docker运行命令时提示“Got permission denied while trying to connect to the Docker daemon socket“_docker: permission denied while trying to connect
- 9【YOLO】目标检测 YOLO框架之train.py参数含义及配置总结手册(全)
- 10Git详解_git 理论
手把手教你Autodl平台Qwen-7B-Chat FastApi 部署调用_autodl怎么调用api
赞
踩
手把手带你在AutoDL上部署Qwen-7B-Chat FastApi 调用
项目地址:https://github.com/datawhalechina/self-llm.git
如果大家有其他模型想要部署教程,可以来仓库提交issue哦~ 也可以自己提交PR!
如果觉得仓库不错的话欢迎star!!!
Qwen-7B-Chat FastApi 部署调用
如果你前面跟着Qwen-7B-Chat transformers 部署调用的话可以直接跳过环境准备和模型下载不过还得安装依赖包哈(依赖包安装requests过程中出现红色报错可以不管他继续往下走)
环境准备
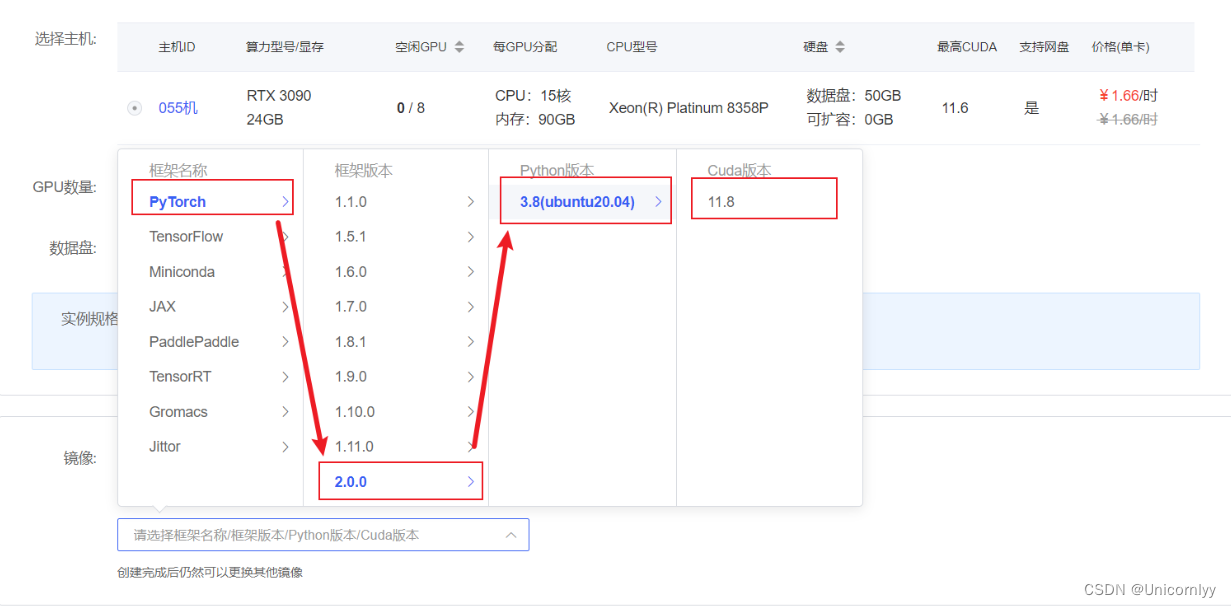
在autoal平台中租一个3090等24G显存的显卡机器,如下图所示镜像选择pytorch–>2.0.0–>3.8(ubuntu20.04)–>11.8(要注意在可支持的最高cuda版本>=11.8)
接下来打开自己刚刚租用服务器的JupyterLab,并且打开其中的终端开始环境配置、模型下载和运行demo.

pip换源和安装依赖包
# 升级pip
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install fastapi==0.104.1
pip install uvicorn==0.24.0.post1
pip install requests==2.25.1
pip install modelscope==1.9.5
pip install transformers==4.35.2
pip install streamlit==1.24.0
pip install sentencepiece==0.1.99
pip install accelerate==0.24.1
pip install transformers_stream_generator==0.0.4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
模型下载
使用modelscope(魔塔社区)中的snapshot_download函数下载模型,第一个参数为模型名称,参数cache_dir为模型的下载路径。
在/root/autodl-tmp路径下新建download.py文件
#将当前工作目录切换到/root/autodl-tmp目录下
cd /root/autodl-tmp
#创建一个名为download.py的空文件
touch download.py
- 1
- 2
- 3
- 4
#然后点击该文件夹进行输入
#或者输入以下命令
vim download.py
点击i进入编辑模式
并在其中输入以下内容:
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
from modelscope import GenerationConfig
model_dir = snapshot_download('qwen/Qwen-7B-Chat', cache_dir='/root/autodl-tmp', revision='v1.1.4')
- 1
- 2
- 3
- 4
粘贴代码后记得保存文件(Ctrl+S),如下图所示。
(如果使用vim命令 粘贴完记得点Esc退出编辑模型然后输入’:wq’回车进行保存退出)


保存后返回终端界面,运行Python /root/autodl-tmp/download.py执行下载,模型大小为15GB,下载模型大概需要10~20分钟。
代码准备
在/root/autodl-tmp路径下新建api.py文件并在其中输入以下内容,粘贴代码后记得保存文件。下面的代码有很详细的注释,大家如有不理解的地方,欢迎提出issue。
from fastapi import FastAPI, Request from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig import uvicorn import json import datetime import torch # 设置设备参数 DEVICE = "cuda" # 使用CUDA DEVICE_ID = "0" # CUDA设备ID,如果未设置则为空 CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE # 组合CUDA设备信息 # 清理GPU内存函数 def torch_gc(): if torch.cuda.is_available(): # 检查是否可用CUDA with torch.cuda.device(CUDA_DEVICE): # 指定CUDA设备 torch.cuda.empty_cache() # 清空CUDA缓存 torch.cuda.ipc_collect() # 收集CUDA内存碎片 # 创建FastAPI应用 app = FastAPI() # 处理POST请求的端点 @app.post("/") async def create_item(request: Request): global model, tokenizer # 声明全局变量以便在函数内部使用模型和分词器 json_post_raw = await request.json() # 获取POST请求的JSON数据 json_post = json.dumps(json_post_raw) # 将JSON数据转换为字符串 json_post_list = json.loads(json_post) # 将字符串转换为Python对象 prompt = json_post_list.get('prompt') # 获取请求中的提示 history = json_post_list.get('history') # 获取请求中的历史记录 max_length = json_post_list.get('max_length') # 获取请求中的最大长度 top_p = json_post_list.get('top_p') # 获取请求中的top_p参数 temperature = json_post_list.get('temperature') # 获取请求中的温度参数 # 调用模型进行对话生成 response, history = model.chat( tokenizer, prompt, history=history, max_length=max_length if max_length else 2048, # 如果未提供最大长度,默认使用2048 top_p=top_p if top_p else 0.7, # 如果未提供top_p参数,默认使用0.7 temperature=temperature if temperature else 0.95 # 如果未提供温度参数,默认使用0.95 ) now = datetime.datetime.now() # 获取当前时间 time = now.strftime("%Y-%m-%d %H:%M:%S") # 格式化时间为字符串 # 构建响应JSON answer = { "response": response, "history": history, "status": 200, "time": time } # 构建日志信息 log = "[" + time + "] " + '", prompt:"' + prompt + '", response:"' + repr(response) + '"' print(log) # 打印日志 torch_gc() # 执行GPU内存清理 return answer # 返回响应 # 主函数入口 if __name__ == '__main__': # 加载预训练的分词器和模型 tokenizer = AutoTokenizer.from_pretrained("/root/autodl-tmp/qwen/Qwen-7B-Chat", trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained("/root/autodl-tmp/qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True).eval() model.generation_config = GenerationConfig.from_pretrained("/root/autodl-tmp/qwen/Qwen-7B-Chat", trust_remote_code=True) # 可指定 model.eval() # 设置模型为评估模式 # 启动FastAPI应用 # 用6006端口可以将autodl的端口映射到本地,从而在本地使用api uvicorn.run(app, host='0.0.0.0', port=6006, workers=1) # 在指定端口和主机上启动应用

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
代码准备
在终端输入以下命令启动api服务
cd /root/autodl-tmp
python api.py
- 1
- 2
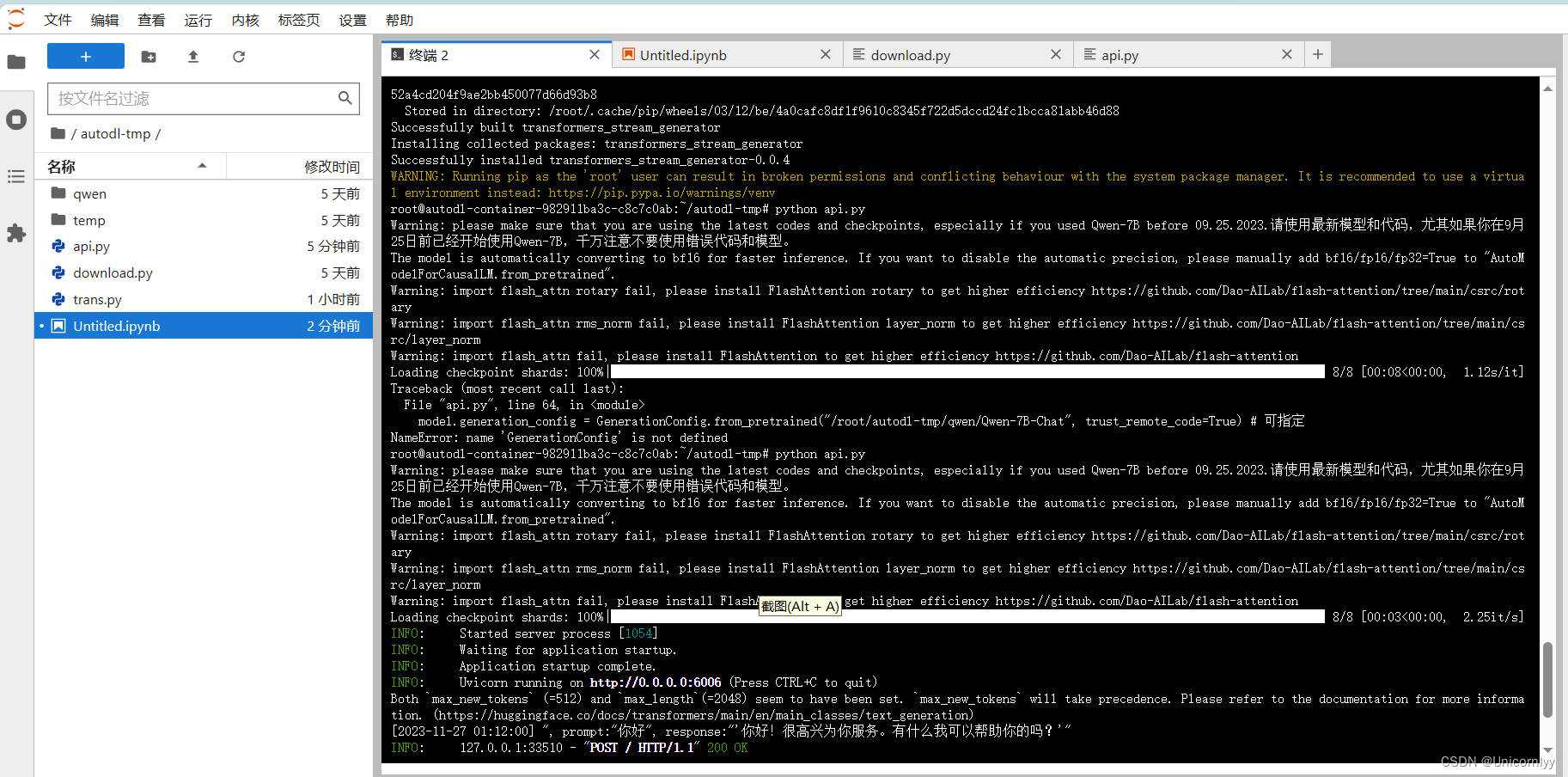
加载完毕后出现如下信息说明成功。
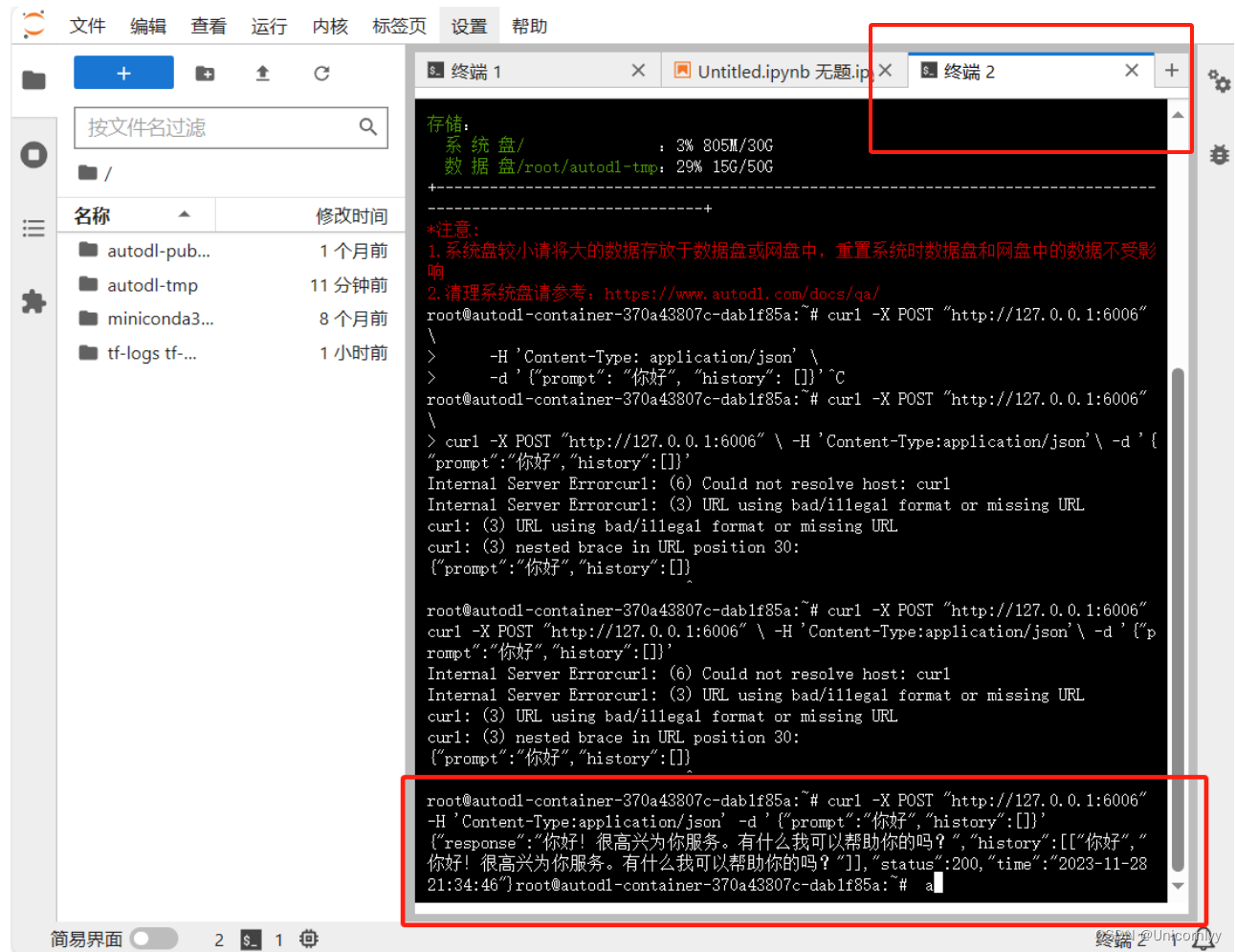
默认部署在 6006 端口,通过 POST 方法进行调用,可以使用curl调用,如下所示:
curl -X POST "http://127.0.0.1:6006" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好", "history": []}'
- 1
- 2
- 3
再打开一个终端,然后输入以上命令,要注意输入格式
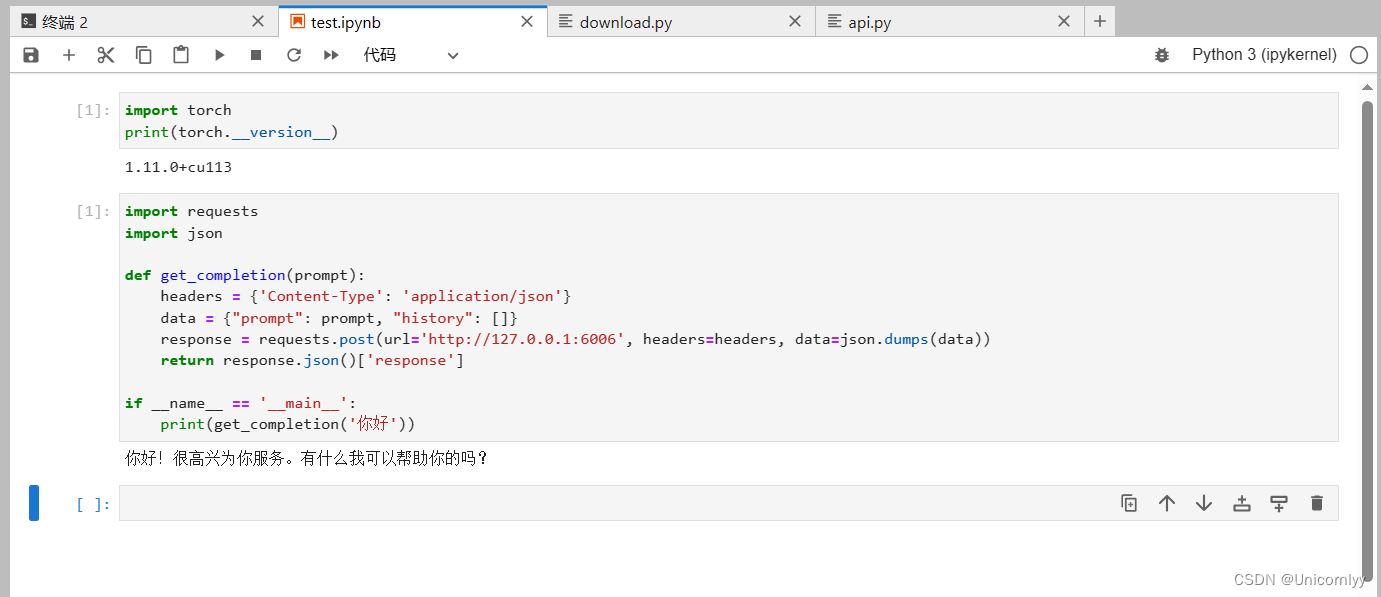
也可以使用python中的requests库进行调用,如下所示:
import requests
import json
def get_completion(prompt):
headers = {'Content-Type': 'application/json'}
data = {"prompt": prompt, "history": []}
response = requests.post(url='http://127.0.0.1:6006', headers=headers, data=json.dumps(data))
return response.json()['response']
if __name__ == '__main__':
print(get_completion('你好'))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
得到的返回值如下所示:
{
"response":"你好!很高兴为你服务。有什么我可以帮助你的吗?",
"history":[["你好","你好!很高兴为你服务。有什么我可以帮助你的吗?"]],
"status":200,
"time":"2023-11-26 1:14:20"
}
- 1
- 2
- 3
- 4
- 5
- 6