
- 1Android Gradle Composing builds 管理三方依赖
- 2android开源日历app,CalendarView
- 3UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd2 in position 25: invalid continuation byte_syntaxerror: (unicode error) 'utf-8' codec can't d
- 4指令微调(Instructional Fine-tuning)
- 5NLP发展及其详解
- 6苹果电脑Mac笔记本听歌神器洛雪音乐+六音音源来了,详细教程,附下载地址!_洛雪音乐mac
- 7Python实现机器学习(下)— 数据预处理、模型训练和模型评估_python 建立模型和模型训练
- 8ClickHouse深度解析 一般有用 看1 速
- 9可见与红外光图像融合论文阅读:Visible and Infrared Image Fusion Using Deep Learning_onvif可见光和红外
- 10手把手写深度学习(16):用CILP预训练模型搭建图文检索系统/以图搜图/关键词检索系统_图文检索模型
五分钟本地部署史上最强开源大模型 Llama3_llmama3 70b 多少显存
赞
踩
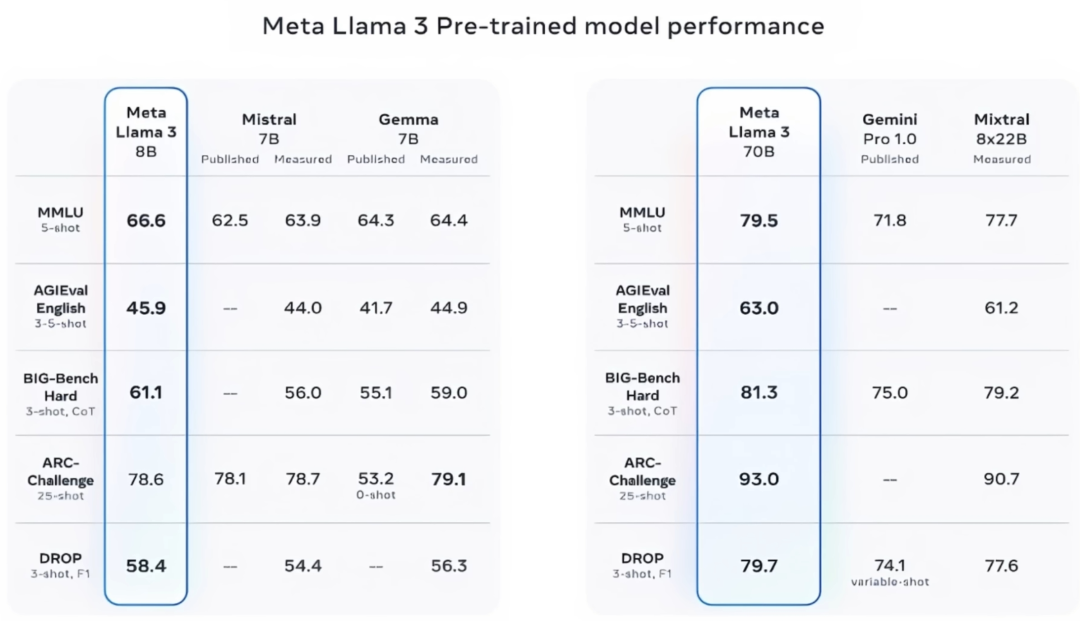
Llama3的最小版本8B和70B已经全面领先其他竞争对手的开源大模型。其中70B的模型相当于GPT-4的水平,其中8B和70B都可以在个人PC上跑起来,8B就是80亿参数的模型只需要8G+的显存就可以流畅跑起来,70B就是700亿参数的模型虽然宣称需要40G+的显存,经测试在个人电脑的16G的显存上也可以跑起来,就是吐字速度慢些。
几天前meta发布了史上最强开源大模型Llama3,要想免费使用Llama3,除了去官网 https://llama.meta.com/llama3/ 在线使用外,还可以本地部署。
本地部署有多种方式,常见的有如下3种方式:
1. github仓库clone后,https://github.com/meta-llama/llama3 安装python,pip相关的包,官网在线填写个人信息申请模型下载链接
2. LL-studio
3. ollama
其中以ollama部署最为便捷和友好,部署时间可在5分钟内完成。本篇就介绍ollama本地部署llama3模型。
step1:ollama官网(https://ollama.com/download)下载ollama,有mac,windows,linux三个版本,选择适合自己机器的版本下载并安装。
图片
step2:命令行执行ollama run llama3 (默认是下载8b的模型,若要下载40b的,执行 ollama run llama3:70b)
图片
Llama3的最小版本8B和70B已经全面领先其他竞争对手的开源大模型。其中70B的模型相当于GPT-4的水平,其中8B和70B都可以在个人PC上跑起来,8B就是80亿参数的模型只需要8G+的显存就可以流畅跑起来,70B就是700亿参数的模型虽然宣称需要40G+的显存,经测试在个人电脑的16G的显存上也可以跑起来,就是吐字速度慢些。
模型下载完成后就进入命令行交互界面,这时候就可以和llama3聊天了。
step3(可选):命令行交互毕竟没有图形化界面友好,可以任选一个界面。目前市面上的界面多如牛毛,这里以开源软件chatbox为例,https://github.com/Bin-Huang/chatbox/releases
下载安装后,进入设置,配置使用本地ollama的llama3模型,之后就可以愉快的聊天了。
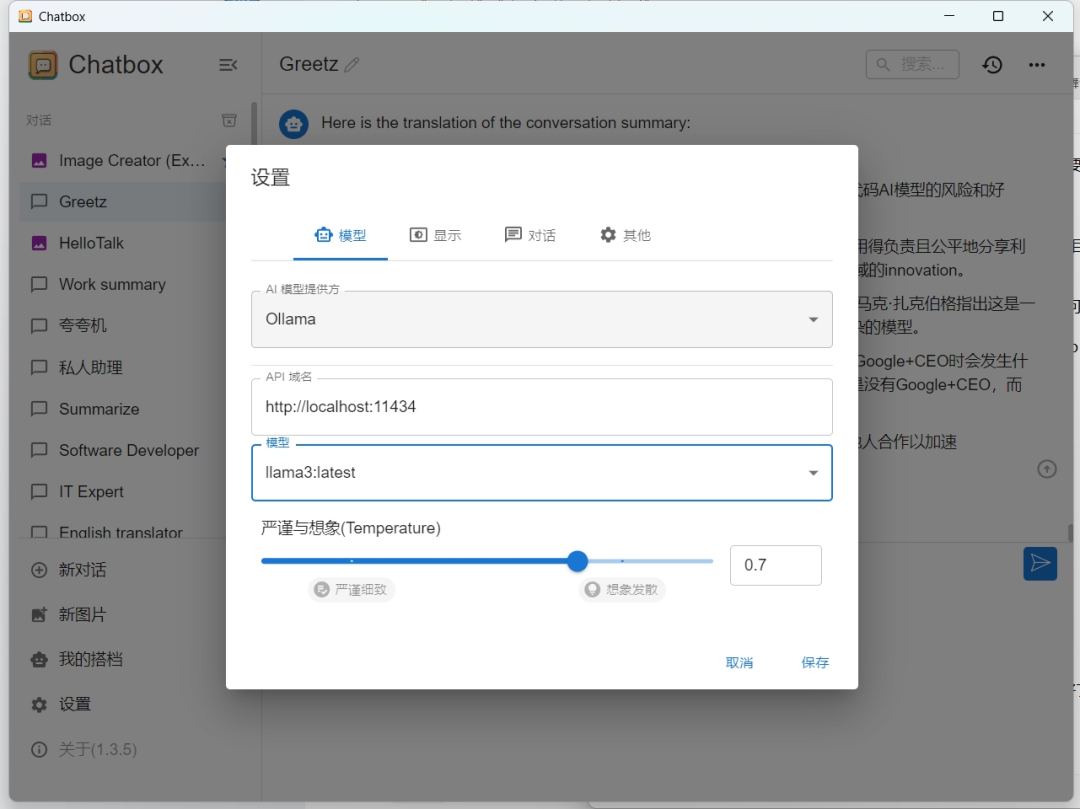
图片
除了通过图形化界面和Llama3聊天外,还可以自己编程调用Llama3 的rest api,自动化让AI完成很多本地工作。
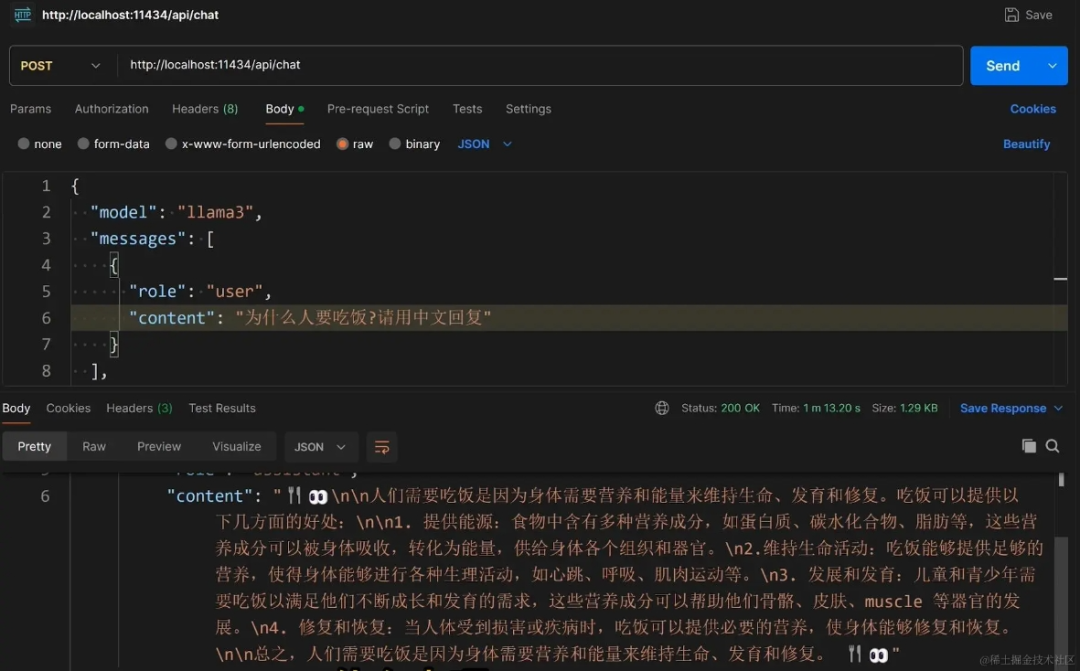
调用llama3 rest api,参考官网说明:https://github.com/ollama/ollama/blob/main/docs/api.md
- curl http://localhost:11434/api/chat -d '{
- "model": "llama3",
- "messages": [
- {
- "role": "user",
- "content": "why is the sky blue?"
- }
- ],
- "stream": false
- }'
图片

