
热门标签
热门文章
- 1一文带你直观感受,BPM管理系统如何在低代码平台实现搭建_.net bpm系统开发
- 2时频分析之STFT:短时傅里叶变换的原理与代码实现(非调用Matlab API)
- 3c++实现socket以json格式传输图片_c++ tcpip 传送 json \
- 4Mysql查询性能优化_update inner join select 优化
- 5axios 传递参数的方式(data 与 params 的区别)_axios post data
- 6从webstrom转到vscode(vscode插件推荐)_vscode webstorm插件
- 7《软件设计师教程:计算机网络浅了解计算机之间相互运运作的模式》
- 8c语言编程求所有四位可逆素数,四位可逆素数
- 9Cache-Control 的含义_@cachecontrol
- 10Github 2024-03-29 开源项目日报Top10_github ai 项目star top10
当前位置: article > 正文
经典卷积网络之ResNet的论文解读及代码实现_resnet表达式
作者:小蓝xlanll | 2024-05-20 15:11:30
赞
踩
resnet表达式
文章背景
随着深度学习的快速发展,在一些竞赛或者论文中出现的神经网络层数也越来越深,那么问题来了:得到一个好的网络模型就是简单的堆砌网络层数吗?事实并非如此,实验证明,随着网络深度的增加,会导致梯度爆炸。也有文章提出,解决这个问题的方法是:通过对数据的正则化和初始化以及中间正则化层。这种方法使拥有数十层的神经网络通过反向传播收敛于随机梯度下降(SGD)。但这样会导致另外一个问题:随着网路深度的增加,结果精度在达到饱和之后突然下降,而且这种下降不是过拟合导致的。
思想
一个网络要保证:后面的一层不应该不前面的一层产生更大的误差。所以提出了优化残差的思路:不是将网络层向期望结果的方向优化,而是向实际输出与理想输出残差为零的方向优化,实验证明,这种方式更容易优化,而且”短连接层“不带入参数和增加计算复杂度(只是简单的相加)整个网络仍然可以通过基于反向传播的随机梯度下降的算法来优化。
网络结构
将输入定义为x,理想结果定义为H(x),那么残差为F(x)=H(x)-x;ResNet就是以F(x)=0为目标对模型进行训练,由表达式可以看出,F(x)与x的维度必须一致,一般我们将步长stride设置为1,这样保证输入输出一致,如果stride不为1,那么需要对x进行处理。ResNet的网络结构如下图所示:
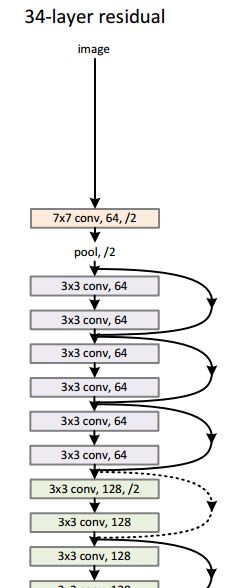
代码实现
Basic Block

class BasicBlock(layers.layer): def __init__(self, filter_num, stride = 1): super(BasicBlock, self).__init__() #将conv + batchnormalization + 激活函数叫做一层 self.conv1 = layers.Conv2D(filter_num, kernel_size=[3, 3], stride=stride, padding='same') self.bn1 = layers.BatchNormalization() self.relu = layers.Activation('relu') self.conv1 = layers.Conv2D(filter_num, kernel_size=[3, 3], stride=1, padding='same') self.bn2 = layers.BatchNormalization() # identity 连接线 if stride != 1: self.downsample = Sequential() self.downsample.add(layers.Conv2D(filter_num, kernel_size=[1, 1], stride=stride, padding='same') ) else: self.downsample = lambda x:x def call(self, input, training = None): # input = [c, h, w, n] out = self.conv1(input) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) identity = self.dowansample(input) output = layers.add([out, identity]) output = tf.nn.relu(output) return output

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ResBlock
def build_resblock(self, filter_num, blocks, stride=1):
res_blocks= Sequential()
#只在 第一个Basicblock中进行下采样
res_blocks.add(BasicBlock(filter_num, stride = stride))
for _ in range(1, blocks):
res_blocks.add(BasicBlock(filter_num, stride = 1))
- 1
- 2
- 3
- 4
- 5
- 6
ResNet 18
class ResNet(keras.Model): def __init__(self, layer_dims, num_class=100): super(ResNet, self).__init__() # layer_dims=[2,2,2,2]:有四个res_blocks,每个包含两个BasicBlock # 第一层:预处理层 self.stem = Sequential([layers.Conv2D(64, kernal_size=[3,3], layers.BatchNormalization(), layers.Activation('relu'), layers.MaxPool2D(pool_size=[2,2]), strides=2, padding='same')]) # unit 2 self.layer1 = self.build_resblock(64, layer_dims[0], stride=2) # unit 3 self.layer2 = self.build_resblock(128, layer_dims[1], stride=2) # unit 4 self.layer3 = self.build_resblock(256, layer_dims[2], stride=2) # unit 5 self.layer4 = self.build_resblock(512, layer_dims[3], stride=2) #全连接层 # output:[b, 512, h, w] self.avgpool=layers.GlobalAveragePooling2D() self.fc = layers.Dense(num_classes) def call(self, input, training=None): x = self.stem(input) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) #[b, c, h, w] -> [b, c] x = self.avgpool(x) #[b, c] -> [b, num_classes] output = self.fc(x) return output
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/小蓝xlanll/article/detail/598161
推荐阅读
相关标签

