
- 1Verilog Tutorial (Verilog 教程)
- 2yolov8改进-添加Wise-IoU,yolov8损失改进_wise-iou损失函数结合yolov8
- 3CSDN论文阅读笔记模板框架_csdn博客引入论文作者写什么
- 4Android profiler : 应用启动时间、冷启动、热启动、温启动_app热启动消耗时间
- 5ComfyUI系列教程|从入门到精通_comfyui基础操作
- 6Scala Api 操作 Elasticsearch数据库_scala 操作 elasticsearch
- 7STM32-串口通信波特率计算以及寄存器的配置详解
- 8mysql8.0日期类型_MySQL8.0.13设置日期为0000-00-0000:00:00时出现的问题解决
- 9机器学习(36)
- 10GPU在外卖场景精排模型预估中的应用实践_大模型训练场景gpu需求量如何评估
《数据结构》(C++)_清华(邓俊辉)~ ~讲得很细~_邓俊辉数据结构讲的怎么样
赞
踩
数据结构(上)学堂在线链接.
数据结构下(学堂在线).
B 站 链接.
方法步骤:
1、 看B站视频, 敲代码,做笔记。根据学堂在线分节
2、比较学堂在线视频是否遗漏。
3、做学堂在线习题, 补充笔记。
第-章 绪论
计算
对象: 规律、技巧
目标: 高效,低耗
计算机: 工具和手段
计算 才是 目标
绳索计算机及其算法
- 输入: 任给直线l及其上一点A
- 输出: 经过A做l的一条垂线
算法(古埃及):
1、取12段等长的绳索,首尾连接成环
2、从A点起,将4段绳索沿l抻直并固定于B
3、沿另一方向找到第3段绳索的终点C
4、移动点C,将剩余的3+5段绳索抻直。
- 由勾股定理:三边边长比为3:4:5, 必定组成直角三角形
- 先固定B点(直线已知,比较好确定)。 然后就是C点(注意一条边有3段,一条边有5段,是固定的,所以C点也可以确定)
重复机械地完成过程
尺规计算机及其算法
- 任给平面上线段AB(输入),将其三等分(输出)
算法:
1、从A发出一条与AB不重合的射线ρ
2、在ρ上取AC‘= C‘D‘ = D’B`
3、连接B‘B
4、经D‘做B’B的平行线,交AB于D
5、经C’做B’B的平行线,交AB于C

- 相似三角形定理
分解成若干个步骤,机械执行。
P4
计算 = 信息处理
借助某种工具,遵照一定规则,以明确而机械的形式进行。
算法:特定计算模型下,旨在解决特定问题的指令序列。
输入,输出, 正确性,确定性,可行性,有穷性。
P5

- 偶尔上升,总体下降
int halistone(int n) {// 计算序列Hailstone(n)的长度
int length = 1;
while (n > 1) {
(n % 2) ? n = 3 * n + 1 : n /= 2; length++;
}
return length;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 长度与n并非成正比
有些n结果为无穷, 是否为算法有争议
- 程序 ≠ 算法
- 死循环或者 栈溢出
P6 好算法
效率: 速度尽可能快;存储空间尽可能少。
P7
Data Structure + Algorithm (DSA)
度量
To measure is to know.
If you can not measure it,
you can not improve it.
— Lord Kelvin
P8
成本: 时间 + 存储空间
规模
P9
P10
P11
图灵机模型(Turing Machine,TM)
- Tape(磁带) 依次均匀地划分为单元格, 各注有某一字符,默认为’#’
- Head : 总是对准某一单元格,并可读取和改写其中的字符。 每经过一个节拍,可转向左侧或右侧的邻格。
- state: TM(图灵机) 总是处于有限种状态中的某一种,每经过一个节拍,可(按照规则)转向另一种状态。
- Transition Function: (q, c; d, L/R,p): 若当前状态为q且当前字符为c,则将当前字符改写为d;转向左侧/右侧的邻格;转入p状态。 一旦转入特定的状态’h’, 则停机。
P12 ?
TM : Increase
功能: 将二进制非负整数加一
P13 RAM(Random Access Machine)
1、寄存器顺序编号,总数没有限制。
2、每一基本操作仅需要常数时间


P14 RAM实例 ?



结论:
- 执行过程可以记录为一张表
- 表的行数, 即是所执行基本指令的总条数
P15
Mathematic is more in need of good notations than of new theorems.
----Alan Turing
好的记号 > 新理论
好书不求甚解
每有会意, 便欣然忘食
---- 陶渊明
- 解决大规模问题的潜力(长远)
- 关注主要方面(主流)
对于规模为n输入
1、需要执行的基本操作数: T(n)
2、需占用的存储单元数: S(n) (通常不考虑)
P16
放大
上界:

下界(算法最好的情况)

P17
1、O(1): 不含转向(循环、调用、递归等),必顺序执行
2、 O(logn), 非常有效,复杂度无限接近于常数
3、O(n^c)
4、线性O(n)
5、 T(n) = a^n, 不可忍受
P20

例:2-Subset
S 包含n 个正整数,和为2m
S是否有子集T, 其和为m.
1、直觉算法: 逐一枚举S的每一子集,并统计其中元素的总和。
- 迭代2^n轮
2- Subset is NP-complete
意思是: 就目前的计算模型而言,不存在可在多项式时间内回答此问题的算法
P21


P22
He calculated just as men breathe,
as eagles sustain themselves in the air.
— Francois Arago
eagles: 老鹰
算法分析的两个主要任务:正确性(不变性 × 单调性) + 复杂度。
分支转向
迭代循环
调用 + 递归 (自我调用)
复杂度分析的主要方法:
1、迭代: 级数求和
- (1) 算数级数: 与末项平方同阶
- (2) 幂方级数: 比幂次高出一阶
- (3) 几何级数(a > 1): 与末项同阶。
- (4) 分数级数: O(1)
2、递归: 递归跟踪 + 递推方程
3、猜测+ 验证



P24 循环
矩形面积



例: 取非极端元素
问题:
给定整数子集S, |S|=n >= 3
找出元素a ∈ S, a ≠ max(S) 且 a ≠ min(S)

例: 起泡排序
问题: 给定n个整数,将它们按(非降)序排列。
方法:
扫描交换:依次比较每一对相邻元素,如有必要,交换之
/* 冒泡排序 */
void bubblesort(int A[], int n) {
for (bool sorted = false; sorted = !sorted;n--) /* 翻转, 以及自减*/
for(int i=1; i< n; i++)
if (A[i - 1] > A[i]){
swap(A[i - 1], A[i]);
sorted = false; // 清除全局有序标志
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1、不变性: 经k轮扫描交换后,最大的k个元素必然就位
- 2、单调性: 经k轮扫描交换后,问题规模缩减至n-1
- 3、正确性: 经至多n趟扫描后,算法必然终止,且能给出正确解答
P27 封底估算(Back- Of - The - Envelope Calculation)
P29 迭代和递归
迭代乃人工, 递归方神通。
To iterate is human, to recurse, divine.
迭代在实际应用中有时候更高效
凡治众如治寡,分数是也。
The control of a large force is the same principle as the control of a few men:
it is merely a question of dividing up their numbers.
分而治之: 将大规模分成子块
/* 数组求和: 迭代*/
/* 问题: 计算任意n个整数之和 */
int SumI(int A[], int n) {
int sum = 0; // O(1) // 累加器
for (int i = 0; i < n; i++) //O(n)
sum += A[i]; // O(1)
return sum; // O(1)
}
/* T(n) = O(n)
* S(n) = O(2)
*/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 逐步蚕食,不断削减问题有效规模
P30
减而治之(Decrease- and- conquer) - 两个子问题:其一平凡,另一规模缩减。
平凡的问题: 是指无需进行复杂运算,可以直接给出结果的问题。
P31
/* 数组求和: 线性递归*/
sum(int A[], int n) {
return (n < 1) ? 0 : sum(A, n - 1) + A[n - 1];
}
/*T(n) = O(1) * (n+1) = O(n) */
- 1
- 2
- 3
- 4
- 5
递归追踪(recursion trace)分析
- 检查每个递归实例,累计所需时间(调用语句本身, 计入对应的子实例),其总和即算法执行时间。
递归跟踪:仅适用于简明的递归模式
递推方程: 更适用于复杂的递归模式
P32

- 最后一项是 T(0)-0
例:数组倒置
任给数组A[0, n], 将其前后颠倒
统一接口: void reverse(int *A, int lo, int hi);
/* 数组倒置 */ /* 1、递归版 */ if (lo < hi) // 问题规模的奇偶性不变,需要两个递归基 { swap(A[lo], A[hi]); reverse(A, lo + 1, hi - 1); } else return; /* 迭代原始法 */ next: if (lo < hi) { swap(A[lo], A[hi]); lo++; hi--; goto next; } /* 3、 迭代精简版 */ while (lo < hi) swap(A[lo++], A[hi--]);

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
P34 分而治之
Divide - and - conquer
为求解一个大规模的问题,可以将其划分为若干子问题,规模大体相当,分别求取子问题,由子问题的解,得到原问题的解。
/* 数组求和: 二分递归*/
sum(int A[]. int lo, int hi) {//区间范围A[lo, hi]
if (lo == hi) return A[lo];
int mi = (lo + hi) >> 1;
return sum(A, lo, mi) + sum(A, mi + 1, hi);
}// 入口形式为sum(A, 0, n-1)
- 1
- 2
- 3
- 4
- 5
- 6
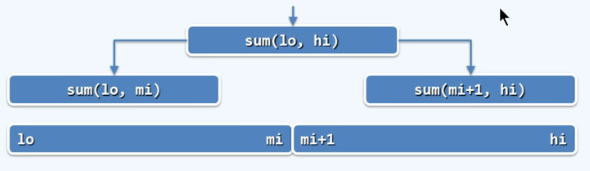


P36
例: 最大的两个数
从数组区间A[lo, hi]中找出最大的两个整数A[x1]和A[x2],且A[x1]≥A[x2]
/* 数组中 top 2元素*/ void max2(int A[], int lo, int hi, int& x1, int& x2) { for (x1 = lo, int i = lo + 1; i < hi; i++) if (A[x1] < A[i]) x1 = i; for (x2 = lo, int i = lo + 1; i < x1; i++) /* 扫描 A[lo, x1]*/ if (A[x2] < A[i]) x2 = i; for (int i = x1 + 1, i < hi; i++) /* 扫描 A[x1, hi]*/ if (A[x2] < A[i]) x2 = i; } /* T(n) = O(2n-3)*/ /* 改进: 维护两个指针 */ void max2(int A[], int lo, int hi, int& x1, int& x2) { if (A[x1 = lo] < A[x2 = lo + 1]) swap(x1, x2); for (int i = lo + 2; i < hi; i++) if (A[x2] < A[i]) // 先和x2比较 if (A[x1] < A[x2 = i]) swap(x1, x2); } /* 最好情况: 1 + (n-2) *1 = n-1 * 最坏情况: 1 + (n-2) * 2 = 2n-3 */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
P37 递归 + 分治
/* Max2: 递归 + 分治 */
void max2(int A[], int lo, int hi, int& x1, int& x2) {
if (lo + 2 == hi) { /*...*/; return; }
if (lo + 3 == hi) {/*...*/; return; }
int mi = (lo + hi) / 2;
int x1L, x2L; max2(A, lo, mi, x1L, x2L);
int x1R, x2R; max2(A, mi, hi, x1R, x2R);
if (A[x1L] > A[x1R]) {
x1 = x1L; x2 = (A[x2L] > A[x1R]) ? x2L : x1R;
}
else {
x1 = x1R; x2 = (A[x1L] > A[x2R]) ? x1L : x2R;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
算法: 迭代、递归
算法策略: Decrease- and - conquer、 divide-and-conquer.
分析: Recursion trace、 Recurrence
补充知识点(重要):
递归基: 是递归函数的一种平凡情况,只有递归基,递归才不会一直进行下去。
减而治之:
- 递归实例分别是: 1个规模为n的实例、1个规模为n-1的实例,1个规模为n-2的实例、…、共有n个
分而治之
- 递归实例分别是:1个规模为n的实例、2个规模为n/2的实例、4个规模为n/4的实例、…,共有 1 + 2 + 4 + 8 + … + n个。
P38
Make it work,
make it right,
make it fast.
—Kent Beck
前两个: 用递归可以实现
fast用迭代。
int fib(n) { return (2 > n) ? n : fib(n - 1) + fib(n - 2); }
/*T(n) = O(2^n) */
- 1
- 2
P41
上楼梯 类似
P42
1、 记忆: memoization(把计算过实例的结果制表备查)
2、动态规划(自小而大,自底而上): dynamic programming.
颠倒计算方向:由自顶向下递归, 改为自底而上迭代。
f = 0; g = 1; // fib(0), fib(1)
while (0 < n--) {
g = g + f;
f = g - f;
}
return g;
/* T(n) = O(n), 而且仅需O(1)空间 */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
例: 最长公共子序列
子序列(Subsequence):由序列中若干字符,按原相对次序构成。
P44
递归 T(n) = O(n^2)
动态规划:T(n) = O(n*m)
1、将所有子问题(假想地)列成一个表
2、颠倒计算方向,从LCS(A[0], B[0])出发一次计算出所有项
P局限(学堂在线)
局限:缓存
不学诗,何以言;不学礼,何以立
He has given signs of himself which are visible to those who seek, and not to those who do not seek him.
P 循环移位
问题:仅用O(1)辅助空间,将数组A[0, n]中的元素向左循环移动k个单元。
void shift(int* A, int n, int k);
- 1
void shift0(int* A, int n, int k)//反复以1为间距循环左移
{
while (k--) shift(A, n, 0, 1);
}// 共迭代k次, O(n*k)
int shift(int* A, int n, int s, int k) {
int b = A[s]; int i = s, j = (s + k) % n; int mov = 0; //mov记录次数
while (s != j) // 从A[s]出发,以k为间隔,依次左移k位
{
A[i] = A[j]; i = j; j = (j + k) % n; mov++;
}
A[i] = b; return mov + 1; //最后,起始元素转入对应位置
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
/* 迭代版本 */
void shift1(int* A, int n, int k) {
for (int s = 0, mov = 0; mov < n; s++)
mov += shift(A, n, s, k);
}// 移动k个位置, 相隔k个元素成环转一圈
- 1
- 2
- 3
- 4
- 5
- 6
P 翻转
/* 倒置版 */
// 借助倒置函数,将数组循环左移K位
void shift2(int* A, int n, int k) {
reverse(A, k); // O(3k/2)
reverse(A + k, n - k); // O(3(n-k)/2)
reverse(A, n); // O(3n/2)
}// O(3n)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
连续访问 Cache
- 数据访问次序尽量在附近
补充笔记:
1、Hailstone问题至今仍未得到证实,即至今没有人证明对所有的正整数,Hailstone(n)过程都可以终止。
2、图灵机是理想的计算模型,其纸带是两端无限延伸的无限长纸带。
3、减而治之: 划分为一个平凡,一个规模缩减的两个子问题。
直接用定义以递归的方式计算fib(n)的时间复杂度是O(2^n)
第二章 向量(Vector)
P48
线性序列(Sequence):Vector + List
Abstract Data Type(ADT)
向量:
元素的 类型不限于基本类型。

P50
有序向量:
search(a), 若存在,直接返回该元素的秩;若不存在, 不大于元素a的元素中的最大值的秩。若是元素a小于全部的元素,返回-1。
/* Vector模板类 */ typedef int Rank; // 秩 #define DEFAULT_CAPACITY 3 //默认初始容量 template<typename T> class Vector {//向量模板类 private: Rank_size; int _capacity; T* _elem; // 规模、容量、数据区 protected: /* ... 内部函数 */ public: /* ... 构造函数*/ Vector(int c = DEFAULT_CAPACITY) { _elem = new T[_capacity = c]; _size = 0; }// 默认 Vector(T const* A, Rank lo, Rank hi)//数组区间复制 { copyFrom(A, lo, hi); } Vector(Vector<T> const& V, Rank lo, Rank hi) //向量区间复制 { copyFrom(V._elem, lo, hi); } Vector(Vector<T> const& V) { copyFrom(V._elem, 0, V._size); //向量整体复制 } /* ... 析构函数*/ ~Vector() { delete[] _elem; } // 释放内部空间 /* ... 只读接口*/ /* ... 可写接口*/ /* ... 遍历接口*/ }; /*********** 复制 *******************/ template <typename T> // T 为基本类型,或已重载赋值操作符 void Vector<T>::copyFrom(T* const A, Rank lo, Rank hi) { _elem = new T[_capacity = 2 * (hi - lo)]; //分配空间 _size = 0; //规模清零 while (lo < hi) _elem[_size++] = A[lo++]; //复制至_elem[0, hi-lo] }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
P53 可扩充向量
静态空间管理
不足:
- 上溢(overflow)
- 下溢(underflow): 向量中元素很少。 装填因子(_size/ _ capacity) << 50%
P54 动态空间管理
蝉: 长大时, 先蜕皮
template <typename T>
void Vector<T>::expand() {// 向量空间不足时扩容
if (_size < _capacity) return; //尚未满员, 不必扩容
_capacity = max(_capacity, DEFAULT_CAPACITY); //不低于最小容量
T* oldElem = _elem; _elem = new T[_capacity <<= 1]; // 容量加倍
for (int i = 0; i < _size; i++)// 复制原向量内容
_elem[i] = oldElem[i]; //T为基本类型,或已重载赋值操作符'='
delete[] oldElem; //释放原空间
}
/* 向量封装了,不会出现野指针*/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
P55
采用 “容量加倍”策略的原因:
其他策略,扩容次数过多,增加时间成本。

蓝色:递增; 紫色‘: 倍增(牺牲空间换取时间)
P57 分摊复杂度(amortized complexity)
P59
元素访问
- V.get( r )
- V.put(r, e)
- A[r]
/* 重载下标操作符 "[ ]"*/
template <typename T> // 0 <= r <= _size
T& Vector<T>:: operator[](Rank r) const { return _elem[r]; }
- 1
- 2
- 3
P60
/* Vector 插入操作 */
template <typename T> // e作为秩为r元素插入, 0<= r <= size
Rank Vector<T>::insert(Rank r, T const& e) {
expand(); // 若有必要,扩容
for (int i = _size; i > r; i--) // 自后向前
_elem[i] = _elem[i - 1] // 后继元素顺次向后移一个单元。
_elem[r] = e; _size++; // 置入新元素,更新容量
return r; // 返回秩
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
P61
/* Vector: 区间删除 */
template <typename T> // 删除区间[lo, hi), 0<= lo <= hi <= size
int Vector<T>::remove(Rank lo, Rank hi) {
if (lo == hi) return 0; // 出于效率考虑,单独处理退化情况
while (hi < _size) _elem[lo++] = _elem[hi++]; // [hi, _size)顺次前移hi-lo位
_size = lo; shrink(); // 更新规模,若有必要则缩容
return hi - lo;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
P62 单元素删除
/* 单元素删除 */
template <typename T >// 删除向量中秩为r的元素, 0<= r <= size
T Vector<T>::remove(Rank r) {
T e = _elem[r]; // 备份被删除的元素
remove(r, r + 1); // 调用区间删除法
return e; // 返回被删除元素
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
P63 查找
/*向量操作: 查找 */
template <typename T>
Rank Vector<T>::find(T const& e, Rank lo, Rank hi) const {
while ((lo < hi--) && e != _elem[hi]); // 逆向查找
return hi;
}
- 1
- 2
- 3
- 4
- 5
- 6
输入敏感: 最好O(1), 最差O(n)
P64
/* Vector操作:去重 */
template <typename T>
int Vector<T>::deduplicate() {
int oldSize = _size;
Rank i = 1;
while (i < _size) // 自前向后逐一考查各元素_elem[i]
(find(_elem[i], 0, i) < 0) ?// 在前缀中找雷同者
i++
: remove(i);
return oldSize - _size; // 删除元素总数
}
/* O(n^2)*/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
优化思路:
1、仿照uniquify()高效版的思路,元素移动的次数可降至O(n),但比较次数依然是O(n^2);而且,稳定性被破坏
2、先对需删除的重复元素做标记,然后再统一删除。稳定性保持,但因查找长度更长,从而导致更多的比对操作。
3、V.sort().uniquify(), O(nlogn)
P65
/* Vector操作:遍历 */
/* 方式一: 利用函数指针机制,只读或局部修改*/
template <typename T>
void Vector<T>::traverse(void (*visit)(T&)) //函数指针
{
for (int i = 0; i < _size; i++) visit(_elem[i]);
}
/* 方式二:利用函数对象机制,可全局修改 */
template <typename T>template <typename VST>
void Vector<T>::traverse(VST& visit)// 函数对象
{
for (int i = 0; i < _size; i++) visit(_elem[i]);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
/* 实现一个可使单个T类型元素加一的类 */
template <typename T>
struct Increase {// 函数对象: 通过重载操作符"()"实现
virtual void operator()(T& e) { e++; }
};
template <typename T> void increase(Vector<T>& V) {
V.traverse(Increase<T>()); // 遍历向量
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
P66:
有序序列中,任意一对相邻元素顺序
无序序列中,总有一对相邻元素逆序
template <typename T>// 返回逆序相邻元素的总数
int Vector<T>::disordered() const {
int n = 0;
for (int i = 1; i < _size; i++) // 逐一检查各对相邻元素
n += (_elem[i - 1] > _elem[i]); // 逆序则计数
return n;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
P67 有序 去重
- 每个区间只需保留单个元素即可
/* Vector: 有序 + 去重 */
template <typename T> int Vector<T>::uniquify() {
int oldSize = _size; int i = 0;
while (i < _size - 1)// 从前往后走,逐一比对各相邻元素
(_elem[i] == _elem[i + 1]) ? remove(i + 1):i++; // 若雷同,则删除后者;否则转至后一元素
return oldSize - _size; // 删除元素总数
}
/* 效率低:O(n^2) */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
P69
- 将删除元素作为整体,成批删除
/* 方法二: 有序 + 去重 */
template <typename T> int Vector<T>::uniquify() {
Rank i = 0; j = 0;
while (++j < _size) // 逐一扫描,直至末元素
if (_elem[i] != _elem[j])
_elem[++i] = _elem[j];
_size = ++i; shrink(); // 直接截除尾部多余元素
return j - i; // 被删除元素总数
}
/* O(n) */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

有序向量, 二分查找
/* 统一接口 */
template <typename T>// 查找算法统一接口 0<= lo< hi<=_size
Rank Vector<T>::search(T const& e, Rank lo, Rank hi) const {
return (rand() % 2) ?
binSearch(_elem, e, lo, hi) // 二分查找算法
: fibSearch(_elem, e, lo, hi); // Fibonacci查找算法
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
P73
template<typename T> // 在有序向量区间[lo, hi]内查找元素
static Rank binSearch(T* A, T const& e, Rank lo, Rank hi) {
while (lo < hi) {
Rank(mi = (lo + hi) >> 1);
if (e < A[mi]) hi = mi; // 小tips: 用小于号,与实际位置相同,便于理解
else if (A[mi] < e) lo = mi + 1;
else return mi;
}
return -1; // 查找失败
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
P77
template <typename T>
static Rank fibSearch(T* A, T const& e, Rank lo, Rank hi) {
Fib fib(hi - lo);
while (lo < hi) {
while (hi - lo < fib.get()) fib.prev();
Rank mi = lo + fib.get() - 1; // 按黄金比例分割
if (e < A[mi]) hi = mi;
else if (A[mi] < e) lo = mi + 1;
else return mi;
}
return -1;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
P83
template <typename T> static Rank binSearch(T* A, T const& e, Rank lo, Rank hi) {
while (1 < hi - lo) {// 有效查找区间的宽度缩减至1时, 算法才会终止
Rank mi = (lo + hi) >> 1;
(e < A[mi]) ? hi = mi : lo = mi; //[lo, mi)或[mi, hi) /* mi包含在右边 区间*/
}// 出口时hi = lo + 1, 查找区间仅含一个元素A[lo]
return (e == A[lo]) ? lo : -1; // 返回 命中元素 的秩或者-1
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
P84
/* 版本C */
template <typename T> static Rank binSearch(T* A, T const& e, Rank lo, Rank hi) {
while (lo < hi) {// A[0, lo) <= e < A[hi, n)
Rank mi = (lo + hi) >> 1;
(e < A[mi]) ? hi = mi : lo = mi + 1; // [lo,mi)或(mi, hi)
}// 出口时,A[lo=hi]为大于e的最大元素
return --lo; // 故lo-1即不大于e的元素的最大秩
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
正确性: 不变性 + 单调性
- 不变性: A[0,lo) <= e < A[hi,n)
P87: 有序, 插值寻找
- Interpolation Search
最坏情况: O(n), 不满足均匀独立分布
最好情况: 稍试即中、初试即中。
平均情况: 每经一次比较,n缩至n^0.5
P90
适用于查找区间极大,或者比较操作成本极高的情况。
可行方式:
首先通过插值查找,将查找范围缩小到一定的范围,然后再进行二分查找。
大规模: 插值查找
中规模: 折半查找
小规模: 顺序查找
向量元素若有序排列,计算效率将大大提升
/* 排序器: 统一接口*/
template <typename T>
void Vector<T>::sort(Rank lo, Rank hi) {// 区间[lo,hi)
switch (rand() % 5) {
case 1: bubbleSort(lo, hi); break; // 气泡排序
case 2: selectionSort(lo, hi); break; // 选择排序
case 3: mergeSort(lo, hi); break; // 归并排序
case 4: heapSort(lo, hi); break; // 堆排序
default: quickSort(lo, hi); break; // 快速排序
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
起泡排序
每一趟扫描交换,都记录下是否存在逆序元素。若存在,当且仅当做过交换。
template <typename T> void Vector<T>::bubbleSort(Rank lo, Rank hi)
{
while (!bubble(lo, hi--)); // 逐趟扫描交换,直至全序
}
/* 改进 */
template <typename T> bool Vector<T>::bubble(Rank lo, Rank hi) {
bool sorted = true; // 整体有序标志
while(++lo < hi)// 自左向右,逐一检查各对相邻元素
if (_elem[lo - 1] > _elem[lo]) {//若逆序,则
sorted = false; //意味着尚未整体有序,并需要
swap(_elem[lo - 1], _elem[lo]); // 交换
}
return sorted;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
P94
/* 再改进 */
template <typename T> Rank Vector<T>::bubble(Rank lo, Rank hi) {
Rank last= lo; // 最右侧的逆序对初始化为[lo-1, lo]
while(++lo < hi)// 自左向右,逐一检查各对相邻元素
if (_elem[lo - 1] > _elem[lo]) {//若逆序,则
last = lo; //更新最右侧逆序对 位置记录,并
swap(_elem[lo - 1], _elem[lo]); // 交换
}
return last;// 返回最右侧的逆序对位置
}
/* T(n) = O(n) */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
算法的稳定性
重复元素在输入、输出序列中的相对次序,是否保持不变。
- 起泡排序 稳定
- 最坏 O(n^2)
P97 归并排序
template<typename T> void Vector<T>::mergeSort(Rank lo, Rank hi) {// [lo, hi) if (hi - lo < 2) return; // 单元区间自然有序 int mi = (lo + hi) >> 1; mergeSort(lo, mi); // 对前半段排序 mergeSort(mi, hi); // 对后半段排序 merge(lo, mi, hi); // 归并 } /* 二路归并 */ /* 将两个有序序列合并为一个有序序列: * S[lo, hi) = S[lo, mi) + S[mi, hi) */ template<typename T> void Vector<T>::merge(Rank lo, Rank mi, Rank hi) { T* A = _elem + lo; // 合并后的向量 A[0, hi-lo) = _elem[lo, hi) int lb = mi - lo; T* B = new T[lb]; // 前子量B[0, lb) = _elem[lo, mi) for (Rank i = 0; i < lb; B[i] = A[i++]); // 复制前子向量B int lc = hi - mi; T* C = _elem + mi; // 后子向量C[0, lc] = _elem[mi, hi) for (Rank i = 0, j = 0, k = 0; (j < lb) || (k < lc)) {// B[j]和C[k]中小者转至A的末尾 if ((j < lb) && (lc <= k || (B[j] <= C[k]))) A[i++] = B[j++]; // C[k]已无或不小 if ((k < lc) && (lb <= j || (C[k] < B[j]))) A[i++] = C[k++]; // B[j]已无或更大 } delete[] B; // 释放临时空间B } /* 后半 元素 C 不需要新开 */ /* 短路求值: (lc <= k || (B[j] <= C[k]))*/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
/* 改进: 若是B提前遍历完成,可以直接终止程序*/
for (Rank i = 0, j = 0, k = 0; j < lb) {
if ((k < lc) && (C[k] < B[j])) A[i++] = C[k++];
if (lc <= k || (B[j] <= C[k])) A[i++] = B[j++];
} // 交换循环体内两句的次序,删除冗余逻辑
- 1
- 2
- 3
- 4
- 5
P 位图(Bitmap) (学堂在线)


小集合 + 大数据
去重
筛选

P补充笔记
- 递归版的空间复杂度等于最大递归深度
2、 分摊复杂度得到的结果比平均复杂度低(×): 分摊复杂度和平均复杂度的结果并没有必然联系。
3、disordered()算法的返回值是相邻逆序对个数。
4、如果(有序)向量中元素的分布满足独立均匀分布(排序前), 插值查找的平均时间复杂度为O(loglog(n))
第三章 列表(list)
P103-P107
Don’t lose the link.
—Robin Milner
前驱: predecessor
后继: successor
首结点: first/front
末节点:last/rear
向量: 循秩访问(call- by- rank)
列表: 循位置访问(call- by- position)

/* 列表结点: ListNode模板类 */
#define Posi(T) ListNode<T>* // 列表结点位置
template<typename T>
struct ListNode {// 列表结点模板类(以双向链表形式实现)
T data; // 数值
Posi(T) pred; // 前驱
Posi(T) succ; // 后继
ListNode() {} // 针对header和trailer的构造
ListNode(T e, Posi(T) p = NULL, Posi(T) s = NULL)
: data(e), pred(p), succ(s) {} // 默认构造器
Posi(T) insertAsPred(T const& e); // 前插入
Posi(T) insertAsSucc(T const& e); // 后插入
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14

/* 列表: List模板类*/
#include "listNode.h" // 引入列表结点类
template<typename T> class List {// 列表模板类
private: int _size; // 规模
Posi(T) header; Posi(T) trailer; // 头、尾哨兵
protected:/* ...内部函数*/
public: /* ...构造函数、析构函数、只读接口、可写接口、遍历接口*/
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

- 头、首、末、尾结点的秩可分别理解为-1, 0, n-1, n
/* 构造 */
template <typename T> void List<T>::init() {// 初始化,创建列表对象时统一调用
header = new ListNode<T>; // 创建头 哨兵结点
trailer = new ListNode<T>; // 创建尾哨兵结点
header->succ = trailer; header-> pred = NULL:
trailer->pred = header; trailer->succ = NULL; // 互联
_size = 0; // 规模
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
-P111 无序列表
P107 循秩访问 列表
重载下标操作符
template <typename T>
T List<T>::operator[](Rank r) const {
Posi(T) p = first();
while (0 < r--) p = p->succ; // 顺数第r个结点即是】
return p->data; // 目标结点
}// 任一结点的秩, 亦即其前驱的总数
- 1
- 2
- 3
- 4
- 5
- 6
P108 查找
/* 在结点p(可能是trailer)的n个(真)前驱中,找到等于e的最后者*/
template<typename T>// 从外部调用时, 0<= n <= rank(p) < _size
Posi(T) List<T>::find(T const& e, int n, Posi(T) p) const {//顺序查找
while (0 < n--) // 从右向左,逐个将p的前驱与e比对
if (e == (p = p->pred)->data) return p; // 直至命中 或 范围越界
return NULL;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
P109
/* 插入 */
template<typename T> Posi(T) List<T>::insertBefore(Posi(T) p, T const& e)
{
_size++; return p->insertAsPred(e); // e 当作p的前驱插入
}
template<typename T> // 前插入算法
Posi(T) ListNode<T>::insertAsPred(T const& e) {
Posi(T) x = new ListNode(e, pred, this);
pred->succ = x; pred = x; return x; // 建立链接, 返回新结点的位置
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
/* 基于复制的构造 */
template <typename T> // 基本接口
void List<T>::copyNodes(Posi(T) p, int n) {
init(); // 创建头、尾哨兵结点并做初始化
while (n--) // 将起自p的n项依次作为末节点插入
{
insertAsLast(p->data); p = p->succ;
}
}
/* insertBefore(trailer)*/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
P110 删除
/* 删除 */
template <typename T>
T List<T>::remove(Posi(T) p) { // O(1)
T e = p->data; // 备份待删除结点数值,用于返回
p->pred->succ = p->succ;
p->succ->pred = p->pred;
delete p; _size--; return e; // 返回备份数值
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
/* 删除列表 */
// 析构
template <typename T> List<T>::~List() // 列表析构
{
clear(); delete header; delete trailer; // 清空列表, 释放头、尾哨兵结点
}
template<typename T> int List::clear() {// 清空列表
int oldSize = _size;
where(0 < _size)// 反复删除首结点, 直至列表变空
remove(header->succ);
return oldSize;
}// O(n), 线性正比于列表规模
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
P111 去重(唯一化)
/* 唯一化 */
template <typename T> int List<T>::deduplicate() {// 删除无序列表中的重复结点
if (_size < 2) return 0;
int oldSize = _size;
Posi(T) p = first(); Rank r = 1; // p从首结点开始
while (trailer != (p = p->succ)) {//
Posi(T) q = find(p->data, r, p); // 在p的前r个(真)前驱中,查找与之雷同者
q ? remove(q): r++; // 若的确存在,则删除之,否则秩递增
}
return oldSize - _size; // 删除元素总数
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
-P114 有序列表
P112
/* 有序列表: 唯一化*/
template<typename T>int List<T>::uniquify() {// 成批剔除重复元素
if (_size < 2) return 0;
int oldSize = _size; //记录原规模
ListNodePosi(T) p = first(); ListNodePosi(T) q; // p为各区段起点,q为其后继
while (trailer != (q = p->succ)) // 反复考查紧邻的结点对(p, q)
if (p->data != q->data) p = q; // 若互异,则转向下一区段
else remove(q); // 否则, 删除后者
return oldSize - _size; // 被删除元素总数
}// 只需遍历整个列表一趟, O(n)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
P114
/* 有序列表: 查找 */
template <typename T> // 在有序列表内结点p的n个(真)前驱中,找到不大于e的最后者
Posi(T) List<T>::search(T const& e, int n, Posi(T) p) const {
while (0 <= n--) // 对于p的最近的n个前驱,从右到左
if (((p = p->pred)->data) <= e) break; //逐个比较
return p; // 直至命中、 数值越界 或 范围越界后, 返回查找终止的位置
}// 最好O(1), 最坏O(n)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
RAM : 循秩访问
图灵机™:call-by-position
列表 排序算法
-P120 选择排序
- 选择最大的
- Bubblesort也是类似思想, 扫描交换,实质也是找最大的。最差O(n^2)
/* 对列表中起始于位置p的连续n个元素做选择排序, valid(p) && rank(p) + n <= size*/
template <typename T> void List<T>::selectionSort(Posi(T) p, int n) {
Posi(T) head = p->pred; Posi(T) tail = p; // 待排序区间(head, tail)
for (int i = 0; i < n; i++) tail = tail->succ; // head/tail可能是头/尾哨兵
while (1 < n) { // 反复从待排序区间找出最大者,并移至有序区间前端
insertBefore(tail, remove(selectMax(head->succ, n)));
tail = tail->pred; n--; // 待排序区间、有序区间的范围,均同步更新
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
new、delete是实际的100倍, 应尽量避免使用
改进思路: 当元素为最后一个元素前驱时,可以不必进行移动操作。但实际上,此种情况出现概率极低, 这样的改进得不偿失。
template<typename T> // 从起始于位置p的n个元素中选出最大者, 1< n
Posi(T) List<T>::seletMax(Posi(T) p, int n) {
Posi(T) max = p; // 最大值暂定为 p
for (Posi(T) cur = p; 1 < n; n--)// 后续结点逐一与max比较
if (!lt((cur = cur->succ)->data, max->data)) // 若 >= max /* !lt: not less than 。比较器*/
max = cur; // 更新最大元素 位置记录 /* 取等号是为了有重复元素时,取更靠后的那个*/
return max; // 返回最大结点位置
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
改进的地方: 元素移动次数远远少于起泡排序

-P128 插入排序

1、有序序列的查找
2、有序序列的插入
/* 对列表中起始于位置p的连续n个元素做插入排序, valid(p) && rank(p) + n <= size*/
template<typename T> void List<T>::insertionSort(Posi(T) p, int n) {
for (int r = 0; r < n; r++) {// 逐一引入各结点,由Sr得到S(r+1)
insertAfter(search(p->data, r, p), p->data); // 查找 + 插入
p = p->succ; remove(p->pred); // 转向下一结点
}// n次迭代, 每次O(r+1)
} // 仅使用O(1)辅助空间,属于就地算法(in place)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
最好情况:一次比较,0次交换, O(n)
最坏情况: 每次插入的都是比排好的小, O(n^2)
- 选择排序,最好和最坏都是 O(n^2)
P127
插入排序平均时间复杂度为O(n^2), 意味着虽然最好情况是O(n), 但这种情况出现的概率极低。
P128 逆序对
- 输入敏感: 插入排序、 希尔排序
P129 习题: LightHouse
分而治之
计算逆序对数
补充笔记
1、对于双向列表,直接访问p->pred即可定位其直接前驱,只需O(1)的时间。对于单向列表, 定位其直接前驱需要从首结点开始逐一访问各结点,最坏情况下需要遍历整个列表,故花费O(n)的时间。
2、长度为n的列表,被等分为n/k段,每段长度为k, 不同段之间的元素不存在逆序,对该列表进行插入排序的最坏时间复杂度为: O(nk)
第四章 栈与队列
P130
A 栈ADT及实现
-P132
栈: 堆叠的椅子或盘子
- 左侧栈顶
- LIFO:后进先出
- 栈为序列的特例,可直接基于向量或列表派生
template<typename T> class Stack : public Vector<T> {//由向量派生
public: // size()、empty()以及其它开放接口均可直接沿用
void push(T const& e) { insert(size(), e); }// 入栈
T pop() { return remove(size() - 1); }// 出栈
T& top() { return (*this)[size() - 1]; }// 取顶
};// 以向量首/末端为 栈底/顶
- 1
- 2
- 3
- 4
- 5
- 6
C 进制转换
-P159

/* 进制转换 */
void convert(Stack<char>& S, __int64 n, int base) {
static char digit[] = //新进制下的数位符号,可视base取值范围适当填充
{ '0','1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F' };
while (n > 0) {// 由低到高,逐一计算出新进制下的各数位
S.push(digit[n % base]); // 余数 入栈
n /= base; // n更新为其对base的除商
}
}
main() {
Stack<char> S; convert(S, n, base); // 用栈记录转换得到的各数位
while (!S.empty()) printf("%c", S.pop()); //逆序输出
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
D 括号匹配
-P141
- 消去一对紧邻的左右括号
思路:
顺序扫描表达式,用栈记录已扫描的部分
- 反复迭代: 凡遇(, 则进栈; 凡遇 ),则出栈
/* 括号匹配 */
bool paren(const char exp[], int lo, int hi) {// exp[lo, hi)
Stack<char> S; // 使用栈记录已发现但尚未匹配的左括号
for (int i = lo; i < hi; i++)// 逐一检查当前字符
if ('(' == exp[i]) S.push(exp[i]); // 遇左括号: 进栈
else if (!S.empty()) S.pop(); // 遇右括号: 若 栈非空,则弹出左括号
else return false; // 遇右括号时栈 已空,必不匹配
return S.empty(); //
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
为什么不用计数器? 为了可以便捷地推广至多种括号并存的情况。
E 栈混洗(Stack permutation)
-P146
- 包含元素的栈A, 过渡栈B,存储结果的栈B
不同的pop()和push()组合会得到不同的结果
栈混洗非法的情况:
每次S.pop()之前, S为空; 或者需弹出的元素在S中,却非顶元素
栈混洗数

F中缀表达式
-P155
栈 + 线性扫描

/* 运算表达式 计算 */ float evaluate(char* S, char* RPN) {// 中缀表达式求值 Stack<float> opnd, Stack<char> optr; // 运算数 栈、 运算符栈 optr.push('\0'); // 尾哨兵'\0'也作为头哨兵首先入栈 while (!optr.empty()) {// 逐个处理各字符,直至运算符栈空 if (isdigit(*S)) // 若当前字符为操作数,则 readNumber(S, opnd); // 读入(可能多位的)操作数 else // 若当前字符为运算符,则视其与栈顶运算符之间优先级的高低 switch (orderBetween(optr.top(), *S)) { /* 分别处理 */ } }// while return opnd.pop(); // 弹出并返回最后的计算结果 } /* 实现优先级表 */ const char pri[N_OPTR][N_OPTR]{// 运算符优先等级 }; switch (orderBetween(optr.top(), *S)) { case '<': // 栈顶优先级更低 optr.push(*S); S++; break; // 计算推迟,当前运算符进栈 case '=': // 优先级相等(当前运算符为右括号,或尾部哨兵'\0') optr.pop(); S++; break; // 脱括号并接收下一个字符 case '>': { // 栈顶运算符优先级更高,实施相应的计算,结果入栈 char op = optr.pop(); // 栈顶运算符出栈,执行对应的运算 if ('!' == op) opnd.push(calcu(op, opnd.pop())); // 一元计算 else { float p0pnd2 = opnd.pop(), p0pnd1 = opnd.pop(); // 二元运算符 opnd.push(calcu(p0pnd1, op, p0pnd2)); // 实施计算,结果入栈 } break; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
P152 - P155 上述 代码的运行实例
G 逆波兰表达式(RPN: Reverse Polish Notation)
-P159
哪个运算符先出现,就先计算
如欲取之,必先予之
infix(中缀)到postfix(前缀):
1、用括号显示地表示优先级
2、将运算符号移到对应的右括号后
3、抹去所有括号
/* infix到postfix: 转换算法*/
float evaluate(char* S, char*& RPN) {// RPN转换
while (!optr.empty()) {//逐个处理各字符,直至运算符栈 空
if (isdigit(*S)) // 若当前字符为操作数
{ readNumber(S, opnd); append(RPN, opnd.top()); } // 接入RPN
else// 若当前字符为运算符
switch (orderBetween(optr.top(), *S)) {
case '>': {
char op = optr.pop(); append(RPN, op); //接入RPN
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
队列ADT及实现
羽毛球桶, 排队
- 一端出,一端入
- 受限:
尾(rear)插入: enqueue() + rear()
头(front)删除: dequeue() + front()
- FIFO: 先进先出
与栈对称
右侧为队头
队列属于序列的特例, 可基于向量或列表派生
/* 队列 */
template <typename T>class Queue : public List<T> {//由列表派生的队列模板类
public: // size()与empty()直接沿用
void enqueue(T const& e) { insertAsLast(e); }// 入队
T dequeue() { return remove(first()); } // 出队
T& front() { return first()->data; } // 队首
}; // 以列表首/末端为队列头/尾
- 1
- 2
- 3
- 4
- 5
- 6
- 7
补充笔记:
习题:



选D ???
习题2:



选A。 ???
第五章 二叉树
A 树
-P169

树:列表的列表。 半线性
- 层次关系
vertex 、 edge
树是特殊的图T= (V, E), 节点数|V| = n, 边数|E| = e
孩子(child)
兄弟(sibling)
父亲(parent)
度(degree)
P167:
通路
路径长度: 边数
连通图(connected)
无环图(acyclic)

空树的高度取为 -1
B 树的表示
P170


C 二叉树
P175
D 二叉树实现
P178
/* BinNode 模板类 */
#define BinNodePosi(T) BinNode<T>* // 结点位置
template <typename T> struct BinNode {
BinNodePosi(T) parent, lChild, rChild; // 父亲、孩子
T data; int height; int size(); // 高度、子树规模
BinNodePosi(T) insertAsLC(T const &); // 作为左孩子插入新结点
BinNodePosi(T) insertAsRC(T const&); // 作为右孩子插入新结点
BinNodePosi(T) succ(); //(中序遍历意义下)当前结点的直接后继
template <typename VST > void travLevel(VST &); // 子树层次遍历
template <typename VST > void travPre(VST &); // 子树先序遍历
template <typename VST > void travIn(VST &); // 子树中序遍历
template <typename VST > void travPost(VST&); // 子树后序遍历
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
/* BinNode 接口实现 */ template <typename T > BinNodePosi(T) BinNode<T>::insertAsLC(T const& e) { return lChild = new BinNode(e, this); }// O(1) template <typename T> BinNodePosi(T) BinNode<T>::insertAsRC(T const& e) { return rChild = new BinNode(e, this); } // O(1) template <typename T> int BinNode<T>::size() { // 后代总数, 亦即以其为根的子树的规模 int s = 1; // 计入本身 if (lChild) s += lChild->size(); // 递归计入左子树规模 if (rChild) s += rChild->size(); // 递归计入右子树规模 return s; }// O(n)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
/* BinTree 模板类 */ template <typename T> class BinTree { protected: int _size; // 规模 BinNodePosi(T) _root; // 根结点 virtual int updateHeight(BinNodePosi(T) x); // 更新结点x的高度 void updateHeightAbove(BinNodePosi(T) x); // 更新x 及祖先的高度 public: int size() const { return _size; } // 规模 bool empty() const { return !_root; } // 判空 BinNodePosi(T) root() const { return _root; }// 树根 /* ... 子树接口、删除和分离接口...*/ /* ... 遍历接口...*/ };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
/* 高度更新 */ # define stature(p) ((p)? (p)->height:-1) // 结点高度---约定空树高度为-1 template <typename T> // 更新结点x高度, 具体规则因树不同而异 int BinTree<T>::updateHeight(BinNodePosi(T) x) { return x->Height = 1 + max(stature(x->lChild), stature(x->rChild)); }// 此处采用常规二叉树规则, O(1) template <typename T> // 更新v及其历代祖先的高度 void BinTree<T>::updateHeightAbove(BinNodePosi(T) x) { while (x) // 可优化:一旦高度围边,即可终止 { updateHeight(x); x = x->parent; } }// O(n = depth(x))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
/* 结点插入 */
template <typename T> BinNodePosi(T)
BinTree<T>::insertAsRC(BinNodePosi(T) x, T const& e) {// insertAsLC对称
_size++; x->insertAsRC(e); // 祖先的高度可能增加,其余结点必然不变
updateHeightAbove(x);
return x->rChild;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
E先序遍历
P183
/* 先序遍历 _递归*/
template <typename T, typename VST>
void traverse(BinNodePosi(T) x, VST& visit) {
if (!x) return;
visit(x->data);
traverse(x->lChild, visit);
traverse(x->rChild, visit);
}// T(n) = O(n)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
/* 先序遍历 _迭代1*/
template <typename T, typename VST>
void travPre_I1(BinNodePosi(T) x, VST& visit) {
Stack <BinNodePosi(T)> S; // 辅助栈
if (x) S.push(x); // 根结点入栈
while (!S.empty()) {// 在栈变空之前反复循环
x = S.pop(); visit(x->data); // 弹出并访问当前结点
if (HasRChild(*x)) S.push(x->rChild); // 右孩子 先入后出
if (HasLChild(*x)) S.push(x->lChild); //左孩子 后入先出
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
/* 先序遍历 _迭代2*/ template <typename T, typename VST>// 分摊O(1) static void visitAlongLeftBranch( BinNodePosi(T) x, VST& visit, Stack <BinNodePosi(T)>& S) { while (x) {// 反复地 visit(x->data); // 访问当前结点 S.push(x->rChild); // 右孩子(右子树)入栈(将来逆序出栈) x = x->lChild; // 沿左侧链下行 } } /* 主算法 */ void travPre_I2(BinNodePosi(T) x, VST& visit) { Stack <BinNodePosi(T)> S; // 辅助栈 while (true) {//以(右)子树为单位,逐批访问结点 visitAlongLeftBranch(x, visit, S); // 访问子树x的左侧链,右子树入栈缓冲 if (S.empty()) break; // 栈空即退出 x = S.pop(); // 弹出下一子树的根 } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
先序遍历的顺序是:先自上而下访问左侧链上的结点,再自下而上访问它们的右子树。
F 中序遍历(inorder traversal)
P192
/* 中序遍历_递归*/
template <typename T, typename VST>
void traverse(BinNodePosi(T) x, VST& visit) {
if (!x) return;
traverse(x->lChild, visit);
visit(x->data);
traverse(x->rChild, visit);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

/* 中序遍历_迭代 */ /* 从根结点开始 谦让控制权 左侧链 直到某个结点无左结点(开始访问的点)*/ /* 访问左侧链结点---> 遍历右子树 (自下而上)*/ template <typename T> static void goAlongLeftBranch(BinNodePosi(T) x, Stack <BinNodePosi(T)>& S) { while (x) { S.push(x); x = x->lChild; } }// 反复的入栈,沿左分支深入 template <typename T, typename V> void travIn_I1(BinNodePosi(T) x, V& visit) { Stack <BinNodePosi(T)> S; // 辅助栈 while (true) {// 反复地 goAlongLeftBranch(x, S); // 从当前结点出发,逐批入栈 if (S.empty()) break; // 直至所有结点处理完毕 x = S.pop(); // x 的左子树或为空,或已遍历(等效于空),故可以 visit(x->data); // 访问 x = x->rChild; // 再转向其右子树 } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
T= O(n)
G 后序遍历(学堂在线)
/* 后序遍历_递归*/
template <typename T, typename VST>
void traverse(BinNodePosi<T> x, VST& visit) {
if (!x) return;
traverse(x->lc, visit);
traverse(x->rc, visit);
visit( x-> data)
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
/* 后序遍历 _ 迭代*/ template <typename T> static void gotoLeftmostLeaf(Stack <BinNodePosi<T>>& S) { while( BinNodePosi<T> x = S.top() ) // 自顶而下反复检查栈顶结点 if (HasLChild(*x)) {// 尽可能向左 if (HasRChild(*x)) // 若有右孩子,则 S.push(x->rc); // 优先入栈 S.push(x->lc); // 然后转向左孩子 } else // 实不得已 S.push(x->rc); // 才转向右孩子 S.pop(); // 返回之前,弹出栈顶的空结点 } template <typename T, typename VST> void travPost_I(BinNodePosi<T> x, VST& visit) { Stack <BinNodePosi<T>> S; // 辅助栈 if (x) S.push(x); // 根结点首先入栈 while (!S.empty()) {// x始终为当前结点 if (S.top() != x->parent) // 若栈顶非x之父(而为右兄) gotoLeftmostLeaf(S); // 则在其右兄子树中找到最靠左的叶子(递归) x = S.pop(); // 弹出栈顶(即前一结点之后继)以更新x visit(x->data); // 随即访问之 } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
H 层次遍历
P199
/* 层次遍历 */
template <typename T> template <typename VST>
void BinNode<T>::travLevel(VST& visit) {// 二叉树层次遍历
Queue<BinNodePosi(T)> Q; // 引入辅助队列
Q.enqueue(this); // 根结点入队
while (!Q.empty()) {// 在队列再次变空之前,反复迭代
BinNodePosi(T) x = Q.dequeue(); // 取出队首结点,并随即
visit(x->data); // 访问之
if (HasLChild(*x)) Q.enqueue(x->lChild); //左孩子入队
if (HasRChild(*x)) Q.enqueue(x->rChild); // 右孩子入队
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
队列: 先进先出
突然不卡了,开始在学堂在线看
I 重构
P202
[先序| 后序] + 中序
若没有中序,无法重构,因为左子树和右子树有可能是空的
J Huffman 树
编码表: protocol
Prefix- Free Code
避免深度差过大
词频差异大:
收益= 高度差 × 频率差
优化编码策略:
- 频率高的尽可能放在高处,频率低的尽可能放在低处(长)
补充笔记:
1、高度为h的完全二叉树结点范围: [2^(h-1)+1
2^(h+1)-1]
2、每上溯一层,深度减小1, 但高度的增加可能大于1,因为结点的高度右其左、右子树中较高者决定。
3、后序遍历: 从根结点开始,对于中途每个结点,能往左就往左,不能往左就往右,若左右都无路可走,则该结点是后序遍历中第一个被访问的结点。
4、设二叉树有n个结点,高度为h,在其中插入一个新的结点,高度发生改变的结点个数为O(h)。
新插入结点到根结点的路径上所有结点(即新结点的祖先)高度都有可能变化。
第六章 图
A
术语(Terminology)、实现(Implementation)、算法(Algorithm)

无向边: undirected edge
无向图: undigraph
有向图:digraph
有向边: directed edge
(u,v): 尾(tail, u),头(head)
路径: 由一系列的顶点,按照依次邻接的关系,构成的一个序列

简单路径: 不含重复结点的路径
有向无环图(DAG, directed acyclic graph)
欧拉环路: 经过所有的边一次,而且恰好一次
哈密顿环路:经过每一个顶点一次,且恰好一次
B 邻接矩阵
/* Graph 模板类*/
template <typename Tv, typename Te> class Graph {//顶点类型,边类型
private:
void reset() {//所有顶点、边的辅助信息复位
for (int i = 0; i < n; i++) {// 顶点
status(i) = UNDISCOVERED; dTime(i) = fTime(i) = -1;
parent(i) = -1; priority(i) = INT_MAX;
for (int j = 0; j < n; j++)// 边
if (exists(i, j)) status(i, j) = UNDETERMINED;
}
}
public: /* ... 顶点操作、边操作、图算法*/
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

无向图 + 邻接矩阵: 冗余
/* Vertex */ typedef enum { UNDISCOVERED, DISCOVERED, VISITED}VStatus; template <typename Tv> struct Vertex {// 顶点对象 Tv data; int inDegree, outDegree; // 数据、出入度数 // 用于 图遍历 VStatus status; // (如上三种)状态 int dTime, fTime; // 时间标签 int parent; // 在遍历树中的父结点 int priority; // 在遍历树中的优先级(最短通路、极短跨边等) Vertex(Tv const& d) : // 构造新顶点 data(d), inDegree(0), outDegree(0), status(UNDISCOVERED), dTime(-1), fTime(-1), parent(-1), priority(INT_MAX) {} };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
/* Edge */
typedef enum { UNDETERMINED, TREE,CROSS, FORWARD, BACKWARD}EStatus;
template <typename Te> struct Edge {// 边对象
Te data; // 数据
int weight; // 权重
EStatus status; // 类型
Edge(Te const& d, int w) : // 构造新边
data(d), weight(w), status(UNDETERMINED) {}
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
/* GraphMatrix*/
template <typename Tv, typename Te>class GraphMatrix :public Graph<Tv, Te> {
private:
Vector< Vertex<Tv> > V; // 顶点集
Vector< Vector< Edge<Te>* >> E; // 边集
public:
/* 操作接口: 顶点相关、边相关....*/
GraphMatrix() { n = e = 0; }// 构造
~GraphMatrix() {// 析构
for (int j = 0; j < n; j++)
for (int k = 0; k < n; k++)
delete E[i][j]; // 清除所有动态申请的边记录。
}
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14

/* 顶点操作 */
// 对于任意顶点i, 枚举其所有的邻接顶点neighbor
int nextNbr(int i, int j) {// 若已枚举至邻居j,则转向下一邻居
while ((-1 < j) && !exists(i, --j)); // 逆向顺序查找,O(n)
return j;
}// 改用邻接表 可提高至 O( 1 + outDegree(i))
int firstNbr(int i) {
return nextNbr(i, n); // n: 假想哨兵
}// 首个邻居
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
P214 边操作
/* 边操作 */ bool exists(int i, int j) {// 判断边(i, j)是否存在 return (0 <= i) && (i < n) && (0 <= j) && (j < n) // i, j合法性比较 && E[i][j] != NULL; // 短路求值 } /* 边插入 */ void insert(Te const& edge, int w, int i, int j) {// 插入(i, j, w) if (exists(i, j)) return; // 忽略已有的边 E[i][j] = new Edge<Te>(edge, w); // 创建新边 e++; // 更新边计数 V[i].outDegree++; // 更新关联顶点i的出度 V[j].inDegree++; // 更新关联顶点j的入度 } /* 边删除 */ Te remove(int i, int j) {// 删除顶点i和j之间的联边(exists(i, j) ) Te eBak = edge(i, j); // 备份边(i, j)的信息 delete E[i][j]; E[i][j] = NULL; // 删除边(i, j) e--; // 更新边计数 V[i].outDegree--; // 更新关联顶点i的出度 V[j].inDegree--; // 更新关联顶点j的入度 return eBak; //返回被删除边的信息 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
/* 引入新顶点 */ int insert(Tv const& vertex) {// 插入顶点,返回编号 for (int j = 0; j < n; j++) E[j].insert(NULL); n++; E.insert( Vector< Edge<Te>*>(n, n, NULL) ); return V.insert(Vertex<Tv>(vertex)); } /* 顶点删除 */ Tv remove(int i) {// 删除顶点及其关联边,返回该顶点信息 for(int j=0; j<n; j++) if (exists(i, j))// 删除所有出边 { delete E[i][j]; V[j].inDegree--; } E.remove(i); n--; // 删除第i行 for(int j=0; j<n; j++) if (exists(j, i))// 删除所有入边及第i列 { delete E[j].remove(i); V[j].outDegree--; } Tv vBak = vertex(i); // 备份顶点i的信息 V.remove(i); // 删除顶点i return vBak; // 返回被删除顶点的信息 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
平面图(planar graph)
满足: v - e + f - c = 1
平面图: e ≤ 3n-6
D 广度优先搜索(Breath-First-Search)
P217

化繁为简

Spanning Tree
树的层次遍历
/* Graph: BFS()广度优先搜索*//* Breath-First-Search*/
template <typename Tv, typename Te>// 顶点类型、边型
void Graph<Tv, Te>::BFS(int v, int& clock) {
Queue<int> Q; status(v) = DISCOVERED; Q.enqueue(v); //初始化
while ( !Q.empty() ) {// 反复地
int v = Q.dequeue();
dTime(v) = ++clock; // 取出队首顶点v, 并
for (int u = firstNbr(v); -1 < u; u = nextNbr(v, u))//考查v的每一邻居u
/* ... 视u的状态,分别处理... */
status(v) = VISITED; // 至此,当前顶点访问完毕
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
/* Graph: BFS()广度优先搜索*//* Breath-First-Search*/ template <typename Tv, typename Te>// 顶点类型、边型 void Graph<Tv, Te>::BFS(int v, int& clock) { Queue<int> Q; status(v) = DISCOVERED; Q.enqueue(v); //初始化 while ( !Q.empty() ) {// 反复地 int v = Q.dequeue(); dTime(v) = ++clock; // 取出队首顶点v, 并 for (int u = firstNbr(v); -1 < u; u = nextNbr(v, u))//考查v的每一邻居u /* ... 视u的状态,分别处理... */ status(v) = VISITED; // 至此,当前顶点访问完毕 } } /// while (!Q.empty()) {// 反复地 int v = Q.dequeue(); dTime(v) = ++clock; // 取出队首顶点v,并 for( int u= firstNbr(v); -1 <u; u=nextNbr(v, u) )// 考查v的每一邻居u if (UNDISCOVERED == status(u)) {// 若u尚未被发现,则 status(u) = DISCOVERED; Q.enqueue(u); // 发现该顶点 status(v, u) = TREE; parent(u) = v; // 引入树边 } else// 若u已被发现(正在队列中), 或者甚至已访问完毕(已出队列),则 status(v, u) = CROSS; // 将(v, u)归类于跨边 status(v) = VISITED; // 至此,当前顶点访问完毕 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
连续、规则、紧凑的组织形式 利于高速缓冲机制发挥作用。
P222 多连通
/* 多连通 */
/* Graph::bfs() */
template <typename Tv, typename Te>// 顶点类型、边类型
void Graph<Tv, Te>::bfs(int s) {// s为起始点
reset(); int clock = 0; int v = s; // 初始化
do // 逐一检查所有顶点,一旦遇到尚未发现的顶点
if (UNDISCOVERED == status(v)) //
BFS(v, clock); // 即从该顶点出发启动一次BFS
while (s != (v = (++v % n)));
// 按序号访问,故不漏不重
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
P224 最短路径
E 深度优先搜索(Depth- First Search)
P225

支撑树
/* Graph:: DFS() */ /* Depth-First Search , 深度优先搜索 */ template Graph<Tv, Te>::DFS(int v, int & clock) { dTime(v) = ++clock; status(v) = DISCOVERED; // 发现当前顶点v for (int u = firstNbr(v); -1 < u; u = nextNbr(v, u)) // 枚举v的每一邻居u /* ... 视u的状态,分别处理... */ /* ... 与BFS不同, 含有递归... */ status(v) = VISITED; fTime(v) = ++clock; // 至此,当前顶点v方向访问完毕 } /*****************/ for( int u = FirstNbr(v); -1< u; u = nextNbr(v, u)) // 枚举v的所有邻居 switch (status(u)) { // 并视其状态分别处理 case UNDISCOVERED: // u尚未发现, 意味着支撑树可在此扩展 status(v, u) = TREE; parent(u) = v; DFS(u, clock); break; // 递归 case DISCOVERED: // u已被发现但尚未访问完毕,应属被后代指向的祖先 status(v, u) = BACKWARD; break; default: // u已被访问完毕(VISITED, 有向图),则视承袭关系分为前向边或跨边 status(v, u) = dTime(v) < dTime(u) ? FORWARD : CROSS; break; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
回溯 back-track
P229 有向图
边分类
P231 括号原理/ 嵌套原理
补充笔记:
1、TREE边的数量总是等于顶点数减去连通分量的数量。
2、对图进行DFS, 有BACKWARD边意味着该图包含环路。
学堂在线:
F1 拓扑排序之零入度算法
拓扑排序:
任给一个有向图(不一定是有向无环图(DAG)),尝试将所有顶点排成一个线性序列,使其次序须与原图相容
- 任何有向无环图中,必有一个零入度的点。
/* 拓扑排序: 顺序输出零入度顶点 */
// 将所有入度为零的顶点存入栈S, 取空队列Q
while (!S.empty()) {
Q.enqueue(v = S.pop()); // 栈顶v转入队列
for each edge(v, u)// v的邻接顶点,若入度仅为1
if (u.inDegree < 2) S.push(u); // 则入栈
G = G\ { v }; // 删除v及其关联边(邻接顶点入度减1)
}
return | G | ? "NOT A DAG" : (? ); // 仅当原图可拓扑排序
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
F2 拓扑排序之零出度算法
- Begin with the end in mind.(以终为始)
- 真正的农夫犯不着焦灼不安…每天完成自己的劳动,并不要求所有的产品都归他所有,他所奉献出的不仅是他的第一个果实,还有他的最后一颗果子。
----选自《瓦尔登湖》
补充笔记
1、含n个顶点的简单无向图中,边的数量最多为: (n-1)×n/2
2、无向图的边数等于各顶点度数之和的一半。
3、A+ D = MM^T:A(简单无向图G的邻接矩阵)、M(G的关联矩阵),D(对角线上第i个元素为顶点i的度的对角矩阵 )
4、用邻接矩阵实现含n个顶点e条边的图的空间复杂度是O(n^2)
5、删除边(i, j)的时间复杂度为 O(1)
6、访问顶点v中存储的数据的时间复杂度O(1)
第七章 图应用 (学堂在线)
A1 双连通分量: 判定准则
信息茧房
关节点(摘除后,连通域个数有所增加)
叶子结点不会是关节点
最高的祖先
A2 双连通分量分解: 算法
/* Graph:: BCC() */ #define hca()( fTime(x)) // 利用此处闲置的fTime template <typename Tv, typename Te> void Graph<Tv, Te>::BCC(int v, int& clock, Stack<int>& S) { hca() = dTime(v) = ++clock; status(v) = DISCOVERED; S.push(v); for (int u = firstNbr(v); -1 < u; u = nextNbr(v, u)) switch (status(u)) { /* ...视u的状态分别处理 ...*/ case UNDISCOVERED: parent(u) = v; type(v, u) = TREE; // 拓展树边 BCC(u, clock, S); // 从u开始遍历,返回后 if (hca(u) < dTime(v))// 若u经后向边指向v的真祖先 hca(v) = min(hca(v), hca(u)); // 则v亦如此 else // 否则,以v为关节点(u以下即是一个BCC, 且其中顶点此时正集中于栈S的顶部) while (u != S.pop()); // 弹出当前BCC中(除v外)的所有结点 // 视需要做进一步处理 break; case DISCOVERED: type(v, u) = BACKWARD; if (u != parent(v)) hca(v) = min(hca(v), dTime(u)); // 更新hca[v], 越小越高 break; default: type(v, u) = dTime(v) < dTime(u) ? FORWARD : CROSS; break; } status(v) = VISITED; // 对v的访问结束 } # undef hca
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
A3 双连通分量分解: 实例
B 优先级搜索(BAG)
template <typename Tv, typename Te> template<typename PU> // 优先级更新器(函数对象) void Graph<Tv, Te>::pfs(int s, PU prioUpdater) { priority(s) = 0; status(s) = VISITED; parent(s) = -1; // 起点s加到PFS树中 while (1) {// 将下一顶点和边加到PFS树中 /* ... 依次引入n-1个顶点(和 n-1条边)*/ for (int w = firstNbr(s); -1 < w; w = nextNbr(s, w)) // 对s各邻居w prioUpdater(this, s, w); // 更新顶点w的优先级及其父顶点 for( int shortest = INT_MAX, w = 0; w < n; w++) if( UNDISCOVERED == status(v) ) // 从尚未加入遍历树的顶点中 if (shortest > priority(w)) // 选出下一个 { shortest = priority(w); s = w; }// 优先级最高的顶点s if (VISITED == status(s)) break; // 直至所有顶点均已加入 status(s) = VISITED; type(parent(s), s) = TREE; // 将s加入遍历树中 }//while }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
C Dijkstra算法( 最短路径法 )
创造工具
减而治之
/* PrioUpdater() */ g->pfs(0, DijkstraPU<char, int>()); // 从顶点0出发,启动Dijkstra算法 template <typename Tv, typename Te>struct DijkPU {// Dijkstra算法的顶点优先级更新器 virtual void operator() { Graph <Tv, Te>* g, int uk, int v } {//对uk的每个 if (UNDISCOVERED != g->status(v)) return; // 尚未被发现的邻居v, 按 if (g->priority(v) > g->priority(uk) + g->weight(uk, v)) {// Dijkstra g->priority(v) = g->priority(uk) + g->weight(uk, v); g->parent(v) = uk; // 做松弛 } } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
D Prim算法(最小生成树问题)
覆盖图中所有结点的最小树:支撑树
权值不能是负数
切割后,权重不会增加
递增式构造
最小生成树不唯一(起始点不同,生成树不同)
先找最短的那条。这样整体不就最短了吗?
/* PrioUpdater()*/
g->pfs(0, PrimPU<char, int>()); // 从顶点出发,启动Prim算法
template <typename Tv, typename Te>struct PrimPU {// Prim算法的顶点优先级更新器
virtual void operator() (Graph<Tv, Te>* g, int uk, int v) {// 对uk的每个
if (UNDISCOVERED != g->status(v)) return; // 尚未被发现的邻居v,按
if (g->priority(v) > g->weight(uk, v)) {// Prim
g->priority(v) = g->weight(uk, v);
g->parent(v) = uk; // 做松弛
}
}
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
第八章 二叉搜索树(Binary Search Tree)
P232
A
定义、特点、规范
 call - by - key
call - by - key
关键码
比较与比对
词条 entry
/* 词条 */
template <typename K, typename V> struct Entry {// 词条模板类
K key; V value; // 关键码、数值
Entry(K k = K(), V v = V())::key(k), value(v) {}; // 默认构造函数
Entry(Entry<K, V> const& e)::key(e.key), value(e.value) {}; // 克隆
// 比较器、判别器
bool operator< (Entry<K, V> const& e) { return key < e.key; } //小于
bool operator> (Entry<K, V> const& e) { return key > e.key; } // 大于
bool operator == (Entry <K, V> const& e) { return key == e.key; } // 等于
bool operator != (Entry <K, V> const& e) { return key != e.key; } // 不等于
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
节点~ 词条~ 关键码
BST的中序遍历序列,必然单调非降
/* BST 模板类 */
template <typename T> class BST : public BinTree<T> {// 由BinTree 派生
public: // 以virtual修饰,以便派生类重写
virtual BinNodePosi(T)& search(const T&); // 查找
virtual BinNodePosi(T) insert(const T&); // 插入
virtual bool remove(const T&); // 删除
protected:
BinNodePosi(T) _hot; // 命中 结点 的父亲
BinNodePosi(T) connect34(// 3 + 4 重构
BinNodePosi(T), BinNodePosi(T), BinNodePosi(T),
BinNodePosi(T), BinNodePosi(T), BinNOdePosi(T), BinNOdePosi(T));
BinNodePosi(T) rotateAt(BinNodePosi(T)); // 旋转调整
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
B1 BST: 查找
P237
减而治之
/* 二叉搜索树: 查找*/
template <typename T> BinNodePosi(T)& BST<T>::search(const T& e)
{
return searchIn(_root, e, _hot = NULL); // 从根结点启动查找
}
static BinNodePosi(T)& searchIn(// 典型的尾递归,可改为爹地啊版
BinNodePosi(T)& v, // 当前(子)树根
const T& e, // 目标关键码
BinNodePosi(T)& hot)// 记忆热点
{
if (!v || (e == v->data)) return v; // 足以确定成败、成功,或者
hot = v; // 先记下当前(非空结点),然后再
return searchIn(((e < e->data) ? v->lChild : v->rChild), e, hot);
}// 运行时间正比于返回结点v的深度,不超过树高O(h)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
增加哨兵结点
B2 BST: 插入
P242
/* 二叉搜索树: 插入*/
template <typename T> BinNodePosi(T) BST<T>::insert(const T& e) {
BinNodePosi(T)& x = search(e); // 查找目标
if (!x) {// 禁止雷同元素, 故仅在查找失败时才实施插入操作
x = new BinNode<T>(e, _hot); // 在x处创建新结点,以_hot为父亲
_size++; updateHeightAbove(x); // 更新全树规模,更新x及其历代祖先的高度
}
return x; // 无论e是否存在于原树中,至此总有 x-> data == e
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
B3 BST: 删除
/* 二叉搜索树: 删除 */
template <typename T> bool BST<T>::remove(const T& e) {
BinNodePosi(T)& x = search(e); // 定位目标结点
if (!x) return false; // 确认目标存在(此时_hot为x的父亲)
// 元素存在 才可以 实施删除
removeAt(x, _hot); // 分两大类情况实施删除,更新全树规模
_size--; // 更新全树规模
updateHeightAbove(_ hot); // 更新_hot及其历代祖先的高度
return true;
}// 删除成功与否,由返回值指示
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
/* 二叉搜索树 删除*/ /* 情况1: *x的某一子树为空,则可将其替换为另一子树 */ template <typename T> static BinNodePosi(T) removeAt(BinNodePosi(T)& x, BinNodePosi(T)& hot) { BinNodePosi(T) w = x; // 实际被摘除的结点,初值同x BinNodePosi(T) succ = NULL; // 实际被删除结点的接替者 if (!HasLChild(*x)) succ = x = x->rChild; // 左子树为空 else if (!HasRChild(*x)) succ = x = x->lChild; // 右子树为空 else { /* ... 左、右子树并存的情况*/ // 情况2 w = w->succ(); swap(x->data, w->data); // 令*x与其后继互换数据 BinNodePosi(T) u = w->parent; // 原问题即转化为, 摘除非二度的结点w (u == x ? u->rChild : u->lChild) = succ = w->rChild; } hot = w->parent; // 记录实际被删除结点的父亲 if (succ) succ->parent = hot; // 将被删除结点的接替者与hot相联 release(w->data); release(w); // 释放被摘除结点 return succ; // 返回接替者 }// O(1) /* 情况2: */ /*1、在右子树中找最小点 交换到待删除结点处, * 2、此时 可以按照 第一种情况 继续对 待删除结点进行处理 */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23

C 平衡
P248

随机生成: O(logn)
随机组成:O(n^0.5), 更可靠
理想平衡:

适度平衡: 高度 渐进地不超过O(logn),即可称作适度平衡。
适度平衡的BST:平衡二叉搜索树(BBST)
中序遍历 歧义
等价BST: 上下可变、左右不乱

D1&2 AVL树: 重平衡
P253

平衡因子 = 左子树高度 - 右子树高度

AVL树 = 适度平衡

/* AVL 接口 */
#define Balanced(x) \ //理想平衡
( stature ( (x).lChild ) == stature( (x).rChild ) )
#define BalFac(x) \ // 平衡因子
( stature( (x).lChild ) - stature ( (x).rChild ) )
#define AvlBalanced(x) \ // AVL平衡条件
( ( -2 < BalFac(x) ) && ( BalFac(x) < 2 ) )
template <typename T> class AVL :public BST<T> {// 由BST派生
public: // BST::search()等接口,可直接沿用
BinNodePosi(T) insert(const T&); // 插入重写
bool remove(cosnt T&); // 删除重写
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
笔记:
- 在AVL树中插入一个结点后失衡结点个数最多为O(lgn)
- 在AVL树中删除一个结点后失衡结点个数最多为O(1)
D3 AVL树: 插入

zagzag
zigzig
O(1)
zigzag
zagzig

/* AVL树: 插入*/
template <typename T> BinNodePosi(T) AVL<T>::insert(const T& e) {
BinNodePosi(T)& x = search(e); if (x) return x; // 若目标尚不存在
x = new BinNode<T>(e, _hot); _size++; BinNodePosi(T) xx = x; // 则创建x
// 从x的父亲出发逐层向上,依次检查各代祖先g
for( BinNodePosi(T) g = x-> parent; g; g= g->parent)
if (!AvlBalanced(*g)) {// 一旦发现g失衡,则通过调整恢复平衡
FromParentIn(*g) = rotateAt( tallerChild( tallerChild(g) ) );
break; // g复衡后,局部子树高度必然复原;其祖先亦必如此,故调整结束
}
else // 否则(在依然平衡的组先处)
updateHeight(g); // 更新其高度
return xx; // 返回新结点: 至多只需一次调整
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
D4AVL树: 删除
P261


/* AVL树: 删除 */
template <typename T> bool AVL<T>::remove(const T& e) {
BinNodePosi(T)& x = search(e); if (!x) return false; // 若目标的确存在
removeAt(x, _hot); _size--; // 则在按BST规则删除之后,_hot及祖先均有可能失衡
// 从_hot出发逐层向上,依次检查各代祖先
for (BinNodePosi(T) g = _hot; g; g = g->parent) {
if ( !AvlBalanced(*g) ) // 一旦发现g失衡,则通过调整恢复平衡
g = FromParentTo(*g) = rotateAt( tallerChild( tallerChild(g) ) );
updateHeight(g); // 更新高度
}
return true; // 删除成功
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
AVL树中删除结点引发失衡,经旋转调整后重新平衡,此时包含g,p,v的子树高度有可能不变也有可能减小1。
在AVL树中修正删除结点引发的失衡有可能出现失衡传播
在AVL树中修正插入结点引发的失衡不会出现失衡传播
D5 AVL树: 3+4重构
P264
魔方组装
中序遍历
/* 3 + 4 重构 */
template <typename T> BinNodePosi(T) BST<T>::connect34(
BinNodePosi(T) a, BinNodePosi(T) b, BinNodePosi(T) c,
BinNodePosi(T) T0, BinNodePosi(T) T1, BinNodePosi(T) T2, BinNodePosi(T) T3)
{
a->lChild = T0; if (T0) T0->parent = a;
a->rChild = T1; if (T1) T1->parent = a; updateHeight(a);
c->lChild = T2; if (T2) T2->parent = c;
c->rChild = T3; if (T3) T3->parent = c; updateHeight(c);
b->lChild = a; a->parent = b;
b->rChild = c; c->parent = b; updateHeight(b);
return b; // 该子树新的根结点
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
template<typename T> BinNodePosi(T) BST<T>::rotateAt(BinNodePosi(T) v) {
BinNodePosi(T) p = v->parent, g = p->parent; // 父亲、祖父
if (isLChild(*p))// zig
if (IsLChild(*v)) {// zig-zig(v,p都是左孩子)
p->parent = g->parent;// 向上联结
return connect34(v, p, g,
v->lChild, v->rChild, p->rChild, g->rChild);
}
else {// zig-zag(p是左孩子,v是右子树)
v->parent = g->parent; //向上联结
return connect34(p, v, g,
p->lChild, v->lChild, v->rChild, g->rChild);
}
else { /* ..zag-zig & zag-zag ..*/}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15

二叉搜索树的高度和结点个数满足h = O(n),在其上进行查找的最坏时间复杂度为O(n);
平衡二叉搜索树的n和h满足关系h = O(lgn), 在其上进行查找的最坏时间复杂度为O(lgn)。
第十章 高级搜索树
P268
伸展树 局部性
A1 伸展树:逐层伸展

将刚访问过的结点 转移到树根

一步一步往上爬:逐层单旋
A2 伸展树: 双层伸展
向上追溯两层,而非一层
反复考查祖孙三代
两次旋转,上升两层
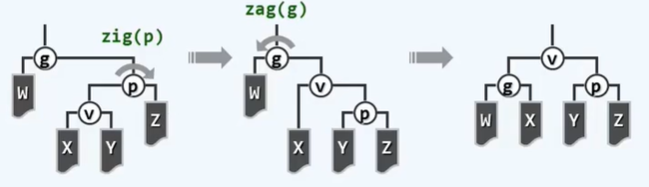
适用于zig-zig和zag-zag
逐层:
双层


双层伸展后,树高缩减为原来的一半
路径折叠
分摊O(logn)
A3 伸展树: 算法实现
P282
/* 伸展树接口 */
template <typename T>
class Splay : public BST<T> {// 由BST派生
protected: BinNodePosi(T) splay(BinNodePosi(T) v); // 将v伸展至根
public:
BinNodePosi(T)& search(const T& e); // 查找
BinNodePosi(T) insert(const T& e); // 插入
bool remove(const T& e); // 删除
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
/* 伸展算法 */ template <typename T> BinNodePosi(T) Splay<T>::splay(BinNodePosi(T) v) { if (!v) return NULL; BinNodePosi(T) p; BinNodePosi(T) g; // 父亲、祖父 while ((p = v->parent) && (g = p->parent)) {// 自下而上,反复双层伸展 BinNodePosi(T) gg = g->parent; // 每轮之后。v都将以原曾祖父为父 if( IsLChild( * v)) if (IsLChild(*p)) { /* zig-zig*/ } else {/*zig-zag*/} else if (IsRChild(*p)) {/*zag-zag*/ } else {/*zag-zig*/} if (!gg) v->parent = NULL; // 若无曾祖父gg,则v现即为树根;否则此后应以v为左或右 else(g == gg->lc) ? attachAsLChild(gg, v) : attachAsRChild(gg, v); // 孩子 updateHeight(g); updateHeight(gg, v); updateHeight(v); }// 双层伸展结束时,必有g==NULL,但p可能非空 if (p = v->parent) {/*若p果真是根, 只需再额外单旋(至多一次)*/ } v->parent = NULL; return v; // 伸展完成,v抵达树根 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
if (IsLChild(*v)) {
if (IsLChild(*p)) {// zig-zig
attachAsLChild(g, p->rc);
attachAsLChild(p, v->rc);
attachAsRChild(p, g);
attachAsRChild(v, p);
}else { /* zig-zag*/}
}
else {
if (IsRChild(*p)) { /* zag-zag */}
else { /* zag-zig*/}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
/* 查找 */
template <typename T> BinNodePosi(T)& Splay<T>::search(const T& e) {
// 调用标准BST的内部接口定位目标结点
BinNodePosi(T) p = searchIn(_root, e, _hot = NULL);
// 无论成功与否,最后被访问的结点都将伸展至根
_root = splay(p ? p : _hot); // 成功、失败
// 总是返回根结点
return _root;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
局部性
插入:
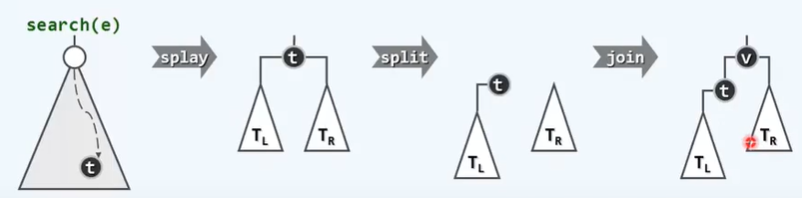
删除:

综合评价:

B1 B-树: 大数据
P289
实现高效I/O
640k ought to be enough for anybody.
—B.Gates, 1981
高速缓存
批量式访问

B2 B-树:结构
P295
更宽,更矮
平衡的多路搜索树
P297
2-4树 红黑树
结点: 向量,序列
/* BTNode*/
template <typename T> struct BTNode {// B-树结点
BTNodePosi(T) parent; // 父
Vector<T> key; // 数值向量
Vector < BTNodePosi(T) > child; // 孩子向量(其长度总比key多1)
BTNode() { parent = NULL; child.insert(0, NULL); }
BTNode(T e, BTNodePosi(T) lc = NULL, BTNodePosi(T) rc = NULL) {
parent = NULL; // 作为根结点,而且初始时
key.insert(0, e); // 仅一个关键码,以及
child.insert(0, lc); child.insert(1, rc); // 两个孩子
if (lc) lc->parent = this; if (rc) rc->parent = this;
}
};
/* 两个向量 */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
/* BT树*/
#define BTNodePosi(T) BTNode<T>* // B-树结点位置
template <typename T> class BTree {// B-树
protected:
int _size; int _order; BTNodePosi(T) _root; // 关键码总数、阶次、根
BTNodePosi(T) _hot; // search()最后访问的非空结点(辅助动态操作)
void solveOverflow( BTNodePosi(T) ); // 因插入而上溢后的分裂处理
void solveUnderflow( BTNodePosi(T) ); // 因删除而下溢后的合并处理
public:
BTNodePosi(T) search(const T & e); // 查找
bool insert(const T& e); // 插入
bool remove(const T& e); // 删除
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
B树的层数少有助于减少I/O 次数
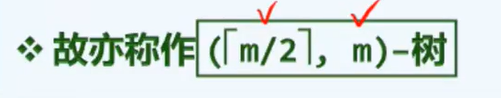
B3 B-树:查找
P303
一次读入性的I/O操作
一次顺序查找
失败查找必终止于外部结点
/* 查找 */
template <typename T> BTNodePosi(T) BTree<T>::search(const T& e) {
BTNodePosi(T) v = _root; _hot = NULL; // 从根结点出发
while (v) {// 逐层查找
Rank r = v->key.search(e); // 在当前结点对应的向量中顺序查找
if (0 <= r && e == v->key[r]) return v; // 若成功,则返回; 否则
_hot = v; v = v->child[r + 1]; // 沿引用转至对应的下层子树,并载入其根I/O
}//若因 !v 而退出,则意味着抵达外部结点
return NULL; // 失败
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
树的高度 h
N个成功情况, N+1个失败情况。
B4 B-树:插入
P309
/* 插入 */
template <typename T>
bool BTree<T>::insert(const T& e) {
BTNodePosi(T) v = serach(e);
if (v) return false; // 确认e不存在
Rank r = _hot->key.search(e); // 在结点-hot中确定插入位置
_hot->key.insert(r + 1, e); // 将关键码插至对应的位置
_hot->child.insert(r + 2, NULL); // 创建一个空指针
_size++; solveOverflow(_hot); // 如发生上溢,需做分裂
return true; // 插入成功
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

T= O(h)
B5 B-树:删除
P315
/* 删除 */
template <typename T>
bool BTree<T>::remove(const T& e) {
BTNodePosi(T) v = search( e );
if ( ! v ) return false; // 确认e存在
Rank r = v->key.search(e); // 确认e在v中的秩
if (v->child[0]) {// 若v非叶子
BTNodePosi(T) u = v->child[r + 1]; // 在右子树中一直向左
while (u->child[0]) u = u->child[0]; // 找到e的后继(必属于某个叶结点)
v->key[r] = u->key[0]; v = u; r = 0; // 并与之交换位置
}// 至此,v必然位于最底层,且其中第r个关键码就是待删除者
v->key.remove( r ); v->child.remove( r + 1 ); _size--;
solveUnderflow(v); return true; // 如有必要,需做旋转或合并
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
左顾右盼,无法旋转,则考虑合并
B树高度的减少只会发生于根结点的两个孩子合并。
1、插入操作的时间花费主要来自于search(e)
- 在B树中,跨节点访问的时间花费(I/O操作)远大于在结点内部的顺序访问
2、删除操作的时间花费主要来自search(e)以及查找后继结点所花的时间,后继的查找还要往下进行跨节点范问。删除操作更费时
最坏情况下,两者花费相等。
C1 红黑树:动机
P319

版本号
一致性结构/持久性
P321 关联性
大量共享,少量更新
P322

C2 红黑树:结构
P323

红黑树是BBST的特例

/* 红黑树 接口 定义 */
template <typename T> class RedBlack : public BST<T> {//红黑树
public: // BST::search()等其余接口可直接沿用
BinNodePosi(T) insert(const T& e); // 插入
bool remove(const T& e); // 删除
protected:
void solveDoubleRed(BinNodePosi(T) x); // 双红修正
void solveDoubleBlack(BinNodePosi(T) x); // 双黑修正
int updateHeight(BinNodePosi(T) x); // 更新结点x的高度, 黑高度
};
template <typename T> int RedBlack<T>::updateHeight(BinNodePosi(T) x) {
x->height = max(stature(x->lc), stature(x->rc));
if (IsBlack(x)) x->height++; return x->height; // 只计黑结点
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
C3 红黑树:插入
P330
/* 处理 双红缺陷 */
template <typename T> BinNodePosi(T) RedBlack<T>::insert(const T& e) {
// 确认目标结点不存在
BinNodePosi(T)& x = serach(e); if (x) return x;
// 创建红结点x, 以_hot为父,黑高度-1
x = new BinNode<T>(e, _hot, NULL, -1); _size++;
// 如有必要,需做双红修正
solveDoubleRed(x);
// 返回插入的结点
return x ? x : _hot->parent;
}// 无论原树中是否存在e, 返回时总有x-> data ==e
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14






C4 红黑树:删除
双黑: 被删除的点为黑, 导致某些路径上黑结点的个数减1
BB-1


BB- 2B

BB- 3

总结

补充笔记
1、伸展树单次查找操作的最坏时间复杂度比AVL树大
2、
大规模数据(不能全部存放于内存中)的存取: B-树
易于实现,各接口的分摊复杂度为O(lgn):伸展树
处理和几何有关的问题: kd-树
扩充后可支持对历史版本的访问: 红黑树
P11 词典
P345
A 散列
服务电话

Hashing:译作散列
桶: bucket
桶数组 bucket array / 散列表 hash table
B 散列函数
P351
散列函数:
1、确定:同一关键码总是被映射到同一地址
2、快速
3、满射
4、均匀,避免聚集现象
1、除余法
- hash(key) = key % M
- M为素数时, 数据对散列表的覆盖最充分,分布最均匀

除余法缺陷:
- 不动点: 总有 hash(0) = 0
- 零阶均匀: [0,R)的关键码,平均分配到M个桶;但相邻关键码的散列地址也必相邻
一阶均匀: 邻近的关键码,散列地址不再邻近
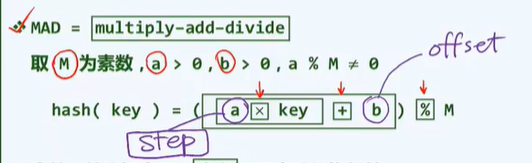
2、MAD法
3、数字分析
4、平方取中
取中的原因: 中间的数是更多数位累积而成
5、折叠法
6、位异或法




- 伪随机数发生器的实现,因平台不同会不同,可移植性差
P359
/* 多项式法: 适用于 英文字符串 */
static size_t hashCode(char s[]) {//近似多项式
int h = 0;
for (size_t n = strlen(s), i = 0; i < n; i++) {
h = (h << 5) | (h >> 27);
h += (int)s[i];
}
return (size_t) h;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
C 排解冲突(1)(2)
P362
动态维护,散列冲突不可避免
1、多槽位
2、独立链


open addressing / closed hashing
3、线性试探 Linear probing : 一旦冲突,试探紧邻桶单元

lazy removal: 仅做删除标记,查找链不必续接
线性试探不足: 试探距离过近
4、平方试探Quadratic probing
- 可缓解聚集现象
5、双向平方试探
M素数= 4k + 3


双平方定理(费马):任一素数p可表示为一对整数的平方和,当且仅当 p % 4 = 1



D 桶排序
P375
分配
F 计数排序
P377
N个待排序元素的取值范围是[1,M],计数排序的时间复杂度为: O(M+N)
补充笔记:
1、用开放定址排解冲突,词条的实际位置不一定是对应的散列函数值
第十二章 优先级队列
P378
A1 需求与动机
夜间门诊
多任务调度

循优先级访问
/* 优先级队列 */
template <typename T> struct PQ { // priority queue
virtual void insert(T) = 0; // 按照优先级次序插入词条
virtual T getMax() = 0; //取出优先级最高的词条
virtual T delMax() = 0; // 删除优先级最高的词条
};// 优先级队列: 抽象数据类型
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

A2 基本实现
P381
兼顾成本和效率
Vector:
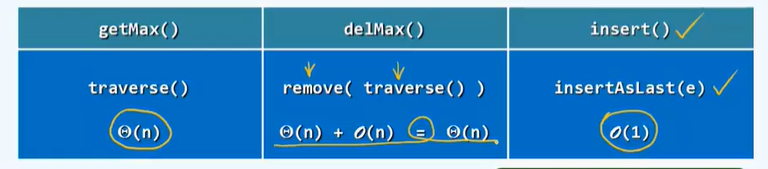

Sorted Vector



极值元, 偏序
B1 完全二叉堆: 结构
P384

完全二叉树:complete Binary Tree: 平衡因子处处非负的AVL
逻辑上,等同于完全二叉树
物理上,直接借助向量实现
完全二叉堆 Complete Binary Tree
#define Parent(i) ( (i-1) >> 1)
# define LChild(i)( 1 + ((i) << 1)) // 奇数
#define RChild(i) ( ( 1 + ( i) ) << 1) // 偶数
- 1
- 2
- 3
- 4
多重继承
/* PQ_ComplHeap = PQ + Vector*/
template <typename T> class PQ_ComlHeap : public PQ<T>, public Vector<T> {
protected: Rank percolateDown(Rank n, Rank i); // 下滤
Rank percolateUp(Rank i); // 上滤
void heapify(Rank n); // Floyd建堆算法
public:
PQ_ComplHeap(T* A, Rank n)// 批量构造
{
copyFrom(A, 0, n); heapiffy(n);
}
void insert(T); // 按照比较器确定的优先级次序,插入词条
T getMax() { return _elem[0]; } // 读取优先级最高的词条
T delMax(); // 删除优先级最高的词条
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
堆序性

/* H[0] 即是 全局最大元素 */
template <typename T> T
PQ_ComplHeap<T>::getMax() { return _elem[0]; }
- 1
- 2
- 3
- 4
B2 完全二叉堆: 插入与上滤(percolate up)
P388
插入词条e: 将e作为末元素接入向量(可能破坏堆序性),然后上滤
/* 堆 插入 */
template <typename T> void PQ_ComplHeap<T>::insert(T e)// 插入
{
Vector<T> ::insert(e); percolateUp(_size - 1);
}
template <typename T>// 对第i个词条实施上滤, i< _size
Rank PQ_ComplHeap<T>::percolateUp(Rank i) {
while ( ParentValid(i) ) { // 只要i有父亲(尚未抵达堆顶),则
Rank j = Parent(i); // 将i之父记作j
if (lt(_elem[i], _elem[j])) break; // 一旦父子不再逆序,上滤完成
swap(_elem[i], _elem[j]); i = j; // 否则,交换父子位置,并上升一层
}// while
return i; // 返回上滤最终抵达的位置
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
h = O(logn)
swap: 3次交换。
改进:先将e备份,确定位置后,做一次交换
B3 完全二叉堆: 删除与下滤
P392
结构性与堆序性
末元素替换,然后下滤
/* 堆: 删除*/ template <typename T> T PQ_ComplHeap<T>::delMax() {// 删除 T maxElem = _elem[0]; _elem[0] = _elem[--_size]; // 摘除堆顶,代之以末词条 percolateDown(_size, 0); // 对新堆顶实施下滤 return maxElem; // 返回此前备份的最大词条 } template <typename T>// 对前n个词条中的第i个实施下滤, i<n Rank PQ_ComplHeap<T>::percolateDown(Rank n, Rank i) { Rank j; // 父 while (i != (j = ProperParent(_elem, n, i))) // 只要i非j,则 { swap(_elem[i], _elem[j]); i = j; // 换位, 并继续考察i } return i; // 返回下滤抵达的位置 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
效率:
比较
交换 3logn
B4 完全二叉堆: 批量建堆
P396
Heapification
1、自上而下的上滤
/* 自上而下的上滤 */
PQ_ComplHeap(T* A, Rank n) { coptFrom(A, 0, n); heapify(n); }
template <typename T> void PQ_ComplHeap<T>::heapify(Rank n) {
for (int i = 1, i < n; i++) // 按照层次遍历 一个结点时不需要上滤,所以从1开始
percolateUp(i); // 经上滤 插入各结点
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
T(n) = nlogn
2、自下而上的下滤
偏序
将小堆合并成大堆
delMax()
template <typename T>
void PQ_ComplHeap<T>::heapify(Rank n) {//
for (int i = LastInternal(n); i >= 0; i--) // 自下而上,自右而左, 依次
percolateDown(n, i); // 下滤各内部结点
} // 子堆的逐层合并
- 1
- 2
- 3
- 4
- 5

越靠近底层,结点更多(蛮力法)
C 堆排序
P401


就地O(1)
交换 + 下滤
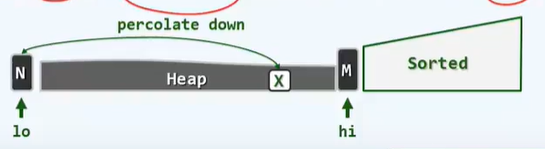
/* 堆排序 */
template <typename T> // 对向量[lo,hi)做就地排序
void Vector<T>::heapSort(Rank lo, Rank hi) {
PQ_ComplHeap<T> H(_elem + lo, hi - lo); // 待排序区间建堆, O(n)
while (!H.empty()) // 反复地摘除最大元并归入已排序的后缀,直至堆空
_elem[--hi] = H.delMax(); // 等效于堆顶与末元素对换后下滤
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
堆排序: 建堆后不断调用delMax()
F1&2 左式堆:结构
P405
为了有效完成堆合并


空结点路径长度 Null Path Length
- 引入所有的外部结点: 消除一度结点,转为真二叉树
结点的高度


F3 左式堆:合并算法
P411
/* LeftHeap */
template <typename T> // 基于二叉树,以左式堆形式实现的优先级队列
class PQ_LeftHeap : public PQ<T>, punlic BinTree<T> {
public:
void insert(T); // (按比较器确定的优先级次序)插入元素
T getMax() { return _root->data; } // 取出优先级最高的元素
T delMax(); // 删除优先级最高的元素
};
template <typename T>
static BinNodePosi(T) merge(BinNodePosi(T), BinNodePosi(T));
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
左式堆不满足结构性,物理结构不再保持紧凑性,派生至树结构即可
/* 左式堆: 合并*/
template <typename T>
static BinNodePosi(T) merge(BinNodePosi(T) a, BinNodePosi(T) b) {
if (!a) return b; // 递归基
if (!b) return a; // 递归基
if (lt(a->data, b->data)) swap(b, a); // 一般情况: 首先确保b不大,a要是大的
a->rc = merge(a->rc, b); // 将a的右子堆,与b合并
a->rc->parent = a; // 更新父子关系
if (!a->lc || a->lc->npl < a->rc->npl) // 若有必要
swap(a->lc, a->rc); // 交换a的左、右子堆,以确保右子堆的npl不大
a->npl = a->rc ? a->rc->npl + 1 : 1; // 更新a的npl
return a; // 返回合并后的堆顶
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14


F4 左式堆:插入+ 删除
P415
插入即是合并
/* 插入*/
template <typename T>
void PQ_LeftHeap<T>::insert(T e) { // O(logn)
BinNodePosi(T) v = new BinNode<T>(e); // 为e创建一个二叉树结点
_root = merge(_root, v); // 通过合并完成新结点的插入
_root->parent = NULL; //
_size++; //更新规模
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
删除:
/* delMax() */
template <typename T> T PQ_LeftHeap<T>::delMax() {// O(logn)
BinNodePosi(T) lHeap = _root->lc; // 左子堆
BinNodePosi(T) rHeap = _root->rc; // 右子堆
T e = _root->data; // 备份堆顶处的最大元素
delete _root; _size--; // 删除根结点
_root = merge(lHeap, rHeap); // 原左、右子堆合并
if (_root) _root->parent = NULL; // 更新父子连接
return e; // 返回原根结点的数据项
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
补充笔记
1、用平衡二叉搜索树实现的优先级队列的insert,getMax,delMax接口均可达到O(lgn)的时间复杂度。
第十三章 串
P417
A. ADT

字符串在结构上相当于Vector 向量
B. 模式匹配
串匹配
文本串T, n; 模式串P, m
1、蛮力匹配
自左向右,以 字符为单位,依次移动模式串
/* 蛮力匹配: 版本1*/
int match(char* P, char* T) {
size_t n = strlen(T), i = 0;
size_t m = strlen(P), j = 0;
while( j < m && i < n)//自左向右逐个比对字符
if (T[i] == T[j]) { i++; j++; } // 若匹配,则转到下一对字符
else { i -= j - 1; j = 0; } // 否则 T回退,P复位
return i - j;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
/* 蛮力匹配: 版本2*/
int match(char* P, char* T) {
size_t n = strlen(T), i = 0; // T[i]与P[0]对齐
size_t m = strlen(P), j; // T[i+j]与P[j]对齐
for (i = 0; i < n - m + 1; i++) { // T从第i个字符起
for (j = 0; j < m; j++)// P中对应的字符逐个
if (T[i + j] != P[j]) break; //若失配,P整体右移一个字符,重新比对
if (m <= j) break; // 找到匹配字串
}
return i;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
最好情况: O(m)
最坏情况: O(n×m)
C1. KMP算法: 记忆法
P426
最坏 O(n)
蛮力方法低效的原因: T回退,P复位之后,此前比对过的字符,将再次参与比对。
?根据P扫描T,标记能匹配的,再进行判断,如何呢
C2. KMP算法: 查询表
P430
做好充分的预案
/* KMP主算法 */ /* 在蛮力法版本一基础上修改*/
int match(char* P, char* T) {
int* next = buildNext(p); // 构造next表
int n = (int)strlen(T), i = 0; // 文本串指针
int m = (int)strlen(P), j = 0; // 模式串指针
while( j < m && i < n)// 自左向右,逐个比对字符
if (0 > j || T[i] == P[j]) {// 若匹配
i++; j++; // 则携手共进
}
else// 否则,P右移,T不回退
j = next[j];
delete[] next; // 释放next表
return i - j;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
C3. KMP算法: next[]表
P433
自匹配 = 快速右移
最长自匹配 = 快速右移 + 避免回退
Next[0] = -1, 哨兵
虚拟实验
C4. KMP算法: 构造next[]表
P436
递推
next[j]: 在P[0,j)中,最大自匹配的真前缀和真后缀的长度。
前缀的自相似性
/* next[]表*/
int* buildNext(char* P) {// 构造模式串P的netx[]表 , 模式串自身的匹配
size_t m = strlen(P), j = 0; // 主串指针
int* N = new int(m); // next表
int t = N[0] = -1; // 模式串指针(P[-1]通配符)
while (j < m - 1)
if (0 > t || P[j] == P[t]) // 匹配
N[++j] = ++t;
else // 失配
t = N[t];
return N;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
C5. KMP算法: 分摊分析
P439
O(n)
对长度为n的文本串和长度为m的模式串,KMP算法的时间复杂度为O(m + n)
C6. KMP算法: 再改进
P441
以卵击石
next查询表 控制程序进程
/* next表: 改进版本*/
int* buildNext(char* P) {
size_t m = strlen(P), j = 0; // 主串指针
int* N = new int[m]; // next表
int t = N[0] = -1; // 模式串指针
while( j < m-1)
if (0 > t || P[j] == P[t]) {//匹配
j++; t++; N[j] = P[j] != P[t] ? t : N[t];
}
else// 失配
t = N[t];
return N;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
二进制串: KMP
D. BM_BC算法
D1. BM_BC算法:以终为始
P446
坏字符策略

关注失败的比对
让更大的失败更早暴露
D2. BM_BC算法:坏字符
P450
巧选其一,避免回溯
哨兵

D3. BM_BC算法:构造bc[]
P452
/* 构造bc[]表 */
int* buildBC(char* P) {
int* bc = new int[256]; // bc[]表,比字母表等长
for (size_t j = 0; j < 256; j++) bc[j] = -1; //初始化(统一指向通配符)
for (size_t m = strlen(P), j = 0; j < m; j++)// 自左向右扫描
bc[P[j]] = j; //刷新P[j]的出现位置记录(画家算法:后来覆盖以往)
return bc;
}// 第二个循环,通过引用临时变量m, 避免反复调用strlen()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
D4. BM_BC算法:性能分析
P454
最好情况 O(n/m)



最坏情况
O(n×m)

E: BM_GS算法
P455
好后缀
经验 = 匹配的后缀
在所有前缀P[0,t)中, 取与U的后缀匹配的最长者



F: Karp-Rabin算法
P461
串即是整数
凡物皆数
f2: 散列
模余函数
O(1)时间内排除
补充笔记:
1、蛮力串匹配方法匹配成功/失败时的返回值分别为:P在T中首次出现的位置/一个大于n-m的数
P14 排序
P468

快速排序
分而治之
快速排序: 将所有元素逐个转换为轴点的过程。

不稳定
就地

平均性能

a4: 快速排序变种
P476
/* 快速排序 */ template <typename T> void Vector<T>::quickSort(Rank lo, Rank hi) { if (hi - lo < 2) return; // 单元素区间自然有序,否则 Rank mi = partition(lo, hi - 1); // 先构造轴点 quickSort(lo, mi); // 前缀排序 quickSort(mi + 1, hi); // 后缀排序 } template <typename T> Rank Vector<T>::partition(Rank lo, Rank hi) { //[lo, hi] swap(_elem[lo], elem[lo + rand() % (hi - lo + 1)]); // 随机交换 T pivot = _elem[lo]; int mi = lo; for (int k = lo + 1; k <= hi; k++)// 自左向右考查每个[k] if (_lem[k] < pivot) // 若[k] 小于轴点,则 swap(_elem[++mi], _elem[k]); // 与[mi]交换,L向右扩展 swap(_elem[lo], _elem[mi]); // 候选轴点归位 return mi; // 返回轴点的秩 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
不稳定

选取
第k大的元素
居中的元素
选取众数
P481
中位数
遍历 + 计数 + 取极值
template <typename T> bool majority(Vector<T> A, T& maj)
{
return majEleCheck(A, maj = median(A));
}
- 1
- 2
- 3
- 4
template <typename T> bool najiority(Vector<T> A, T& maj)
{
return majElecheck(A, maj = mode(A));
}
template <typename T> bool majority(Vector<T> A, T& maj)
{
return majEleCheck(A, maj = majEleCandidate(A));
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
减而治之
template <typename T> T majEleCandidate(Vector<T> A) {
T maj; //众数候选者
// 线性扫描:借助计数器c, 记录maj与其他元素的数量差额
for(int c=0; i < A.size(); i++)
if (0 == c) {// 每当c归零,都意味着此时的前缀p可以剪除
maj = A[i]; c = 1; // 众数候选者改为新的当前元素
}
else// 否则
maj == A[i] ? c++ : c--; // 相应地更新差额计数器
return maj; //
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
quickSelect
P486
/* quickSelect()算法 */
template <typename T> void quickSelect(Vector<T>& A, Rank k) {
for (Rank lo = 0, hi = A.size() - 1; lo < hi;) {
Rank i = lo, j = hi; T pivot = A[lo];
while (i < j) {// O(hi - lo + 1) = O(n)
while (i < j && pivot <= A[j]) j--; A[i] = A[j];
while (i < j && A[i] <= pivot) i++; A[j] = A[i];
}
A[i] = pivot;
if (k <= i) hi = i - 1;
if (i <= k) lo = i + 1;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
从规模为n的向量中选取中位数,quickselect算法的最坏时间复杂度是 O(n^2)
linearSelect()算法
P487
希尔排序
P491
1959
矩阵重排: 逻辑上排序即可(call-by-Rank)
插入排序
步长序列

互素
插入排序对输入序列的有序程度敏感
邮资问题
凑邮资
线性组合
定理K(knuth)
任何一个原先已是g-ordered的序列,在此后经过h-sorting之后,依然保持是g-ordered。
有序序列的线性组合仍是有序的。

插入排序:逆序列的总数会不断持续的减小,输入敏感,线性正比于逆序对数目。
稳定:归并
不稳定: 快速、堆、希尔
线性时间的中位数选取算法实际效率非常低。
防止快速排序因为选取到不平衡的轴点而变得低效:
方法一: 三者取中
方法二: 将堆排序与快速排序结合


