
热门标签
热门文章
- 1设置rules属性改变后不立即出发校验_vue watch 晚于 rules 触发
- 2共享内存bug
- 3配置Manjaro Linux_archlinux卸载wps
- 4AI 大模型_ai大模型学习
- 5Linux基础开发工具(yum、vim、gcc/g++、Makefile、gdb、git)_linux yum gcc
- 6Android 点亮屏幕_mainactivity.this.wakeupscreen(10000l);
- 7二分查找最大比较次数
- 8Flink入门和学习总结
- 9FlinkSQL-- sql-client及源码解析 -- flink-1.13.6_如何代码实现sql-client m -f 这样的命令
- 10ROS系列:七、熟练使用rviz_rviz是ros自带的吗?
当前位置: article > 正文
基于Python的jieba库分析《斗破苍穹》文本中的高频词汇
作者:小蓝xlanll | 2024-05-25 12:24:55
赞
踩
基于Python的jieba库分析《斗破苍穹》文本中的高频词汇

分析《斗破苍穹》文本中的高频词汇
在进行文本分析时,了解文本中出现频率较高的词汇对于把握文本的主题和风格非常有帮助。本文将介绍如何使用Python的jieba库对《斗破苍穹》这部小说的文本进行分词处理,并统计高频词汇的出现次数(本文只统计了小说前四百章节的内容)。
背景介绍
《斗破苍穹》是一部非常受欢迎的玄幻小说,由天蚕土豆所著。为了更好地理解这部小说的词汇使用情况,我们决定排除一些常见的虚词和无意义的词汇,同时将一些角色的别名统一为全名,以便于统计。
环境准备
文本资料:微信公众号“码银学编程”后台回复 斗破文本。
在开始之前,请确保你的环境中已经安装了jieba库。如果没有安装,可以通过以下命令安装:
pip install jieba
代码实现
首先,我们定义了一个excluded_words集合,包含了需要排除的词汇。这些词汇大多是一些虚词或在统计中意义不大的词汇。然后,我们定义了一个alias_to_full_name字典,用于将小说中人物的别名映射到全名。
接下来,我们读取了《斗破苍穹》的文本文件,并使用jieba库进行分词。在分词过程中,我们排除了单字词汇和之前定义的排除词汇。最后,我们统计了剩余词汇的出现次数,并对统计结果进行了排序。
以下是完整的代码实现:
- import jieba
- # 定义一个集合,包含需要排除的词汇
- excluded_words = {
- '有些', '便是', '我们', '你们', '如今', '说道', '知道', '起来', '这里', '之中', '能够', '一面', '自己', '怎么', '两个', '没有',
- '不是' ,'不知' ,'这个' ,'咱们' ,'告诉' ,'就是' ,'东西', '他们', '众人', '进来','回来','只是','大家', '老爷', '只见', '听见', '只得'
- ,'这些' ,'不敢' ,'出去' ,'出来' ,'微微','然后', '竟然','之后','已经','不过','心中','身体','一个','虽然','一般','犹如','点头','现在',
- '最后','缓缓','时间','什么','一些','这种','之上','目光','忽然','略微','实力','却是','一声','那些','似乎','一口气','出现','摇头','脸色'
- ,'所以','一抹','有着','手掌','脸庞','体内','这般','旋即','顿时','淡淡的','随着','一道','恐怕','随着','先前','极为','而出','声音','...'
- ,'而出','青色','面前','极为','手中','逐渐','进入','因为','几乎','方才','缓缓的','不会','一名','的话','终于','开始','一眼','能量','火焰'
- ,'斗气','修炼','强者','药师','一下','少年','家族','呵呵','哈哈','丹药','长老','闻言','无奈','家伙'
- ,'一股','需要','帝国','依然','以及','而且','两人','需要','周围','此时'
- # ... 其他排除词汇 ...
- }
-
- # 定义一个映射,将《斗破苍穹》中的别名映射到对应的全名
- alias_to_full_name = {
- ('炎帝', '炎儿'): '萧炎',
- ('药尘'):'药老',
- ('纳兰'):'纳兰嫣然',
- ('嫣然'):'纳兰嫣然',
- ('海波'):'海波东',
- ('萧熏儿'):'萧熏儿',
- ('熏儿'):'萧熏儿',
- ('古熏儿'):'萧熏儿',
-
- }
-
- # 读取文本文件
- try:
- with open("斗破苍穹.txt", "r", encoding="utf-8") as file:
- text = file.read()
- except FileNotFoundError:
- print("文件未找到,请检查文件路径是否正确。")
- exit()
-
- # 使用jieba进行分词
- words = jieba.lcut(text)
-
- # 初始化计数字典
- word_counts = {}
-
- # 统计每个词的出现次数,排除单字和指定的词汇
- for word in words:
- if len(word) == 1 or word in excluded_words:
- continue
- full_name = alias_to_full_name.get(word, word) # 根据别名获取全名
- word_counts[full_name] = word_counts.get(full_name, 0) + 1
-
- # 移除排除词汇的计数
- for word in excluded_words:
- word_counts.pop(word, None)
-
- # 对计数进行排序,并打印前20个结果
- sorted_word_counts = sorted(word_counts.items(), key=lambda item: item[1], reverse=True)
- for word, count in sorted_word_counts[:10]:
- print("{0:<10}{1:>5}".format(word, count))

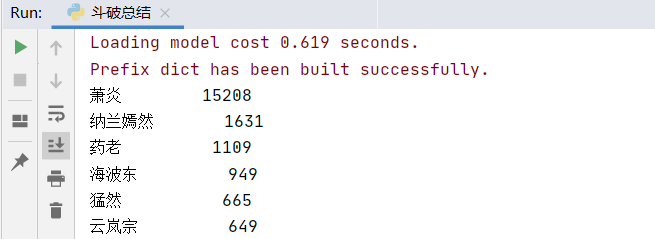
结果分析
运行上述代码后,我们得到了《斗破苍穹》中出现频率最高的100个词汇及其出现次数。这些词汇不仅包括了主要角色的名称,还有一些关键的名词和术语,它们在一定程度上反映了小说的主要内容和风格。
本文仅供学习交流使用,并无其它目的,如有侵权还望告知删除!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小蓝xlanll/article/detail/622039
推荐阅读

相关标签

