- 1RocketMQ(六)高级特性及原理_生产者 发送多次同一条数据的原因
- 2让 Python 更加充分的使用 Sqlite3_python3 sqlite读取性能(1)_python sqlite查找速度
- 3Tensorflow安装教程(完美安装gpu版本的tensorflow)(Windows,Conda,cuda,cudnn版本对应)_tensorflow-gpu清华源安装
- 4原有人陪你颠沛流离——卢思浩_原有人颠簸流离
- 5校招python总结--建议全文背诵_python中有二等对象吗
- 6字节跳动高工面经记,已获 Offer 入职!_字节跳动 背景调查
- 7如何查看本机能够支持的https(TLS)加密算法套件_windows查看tls加密配套
- 8HDFS入门和应用开发:HDFS简介、发展历史、设计目标以及应用场景
- 9【Kafka面试】Kafka消费积压百万数据怎么办?_如何解决kafka数据积压面试题
- 100基础UI设计的人如何快速入门_ui设计0基础入门
重磅!多模态大模型最全综述来了!
赞
踩
丰色 发自 凹非寺
来源 | 量子位 QbitAI
多模态大模型最全综述来了!
由微软7位华人研究员撰写,足足119页——

它从目前已经完善的和还处于最前沿的两类多模态大模型研究方向出发,全面总结了五个具体研究主题:
视觉理解
视觉生成
统一视觉模型
LLM加持的多模态大模型
多模态agent

并重点关注到一个现象:
多模态基础模型已经从专用走向通用。
Ps. 这也是为什么论文开头作者就直接画了一个哆啦A梦的形象。
谁适合阅读这份综述(报告)?
用微软的原话来说:
只要你想学习多模态基础模型的基础知识和最新进展,不管你是专业研究员,还是在校学生,它都是你的“菜”。
一起来看看~
一文摸清多模态大模型现状
这五个具体主题中的前2个为目前已经成熟的领域,后3个则还属于前沿领域。
1、视觉理解
这部分的核心问题是如何预训练一个强大的图像理解backbone。
如下图所示,根据用于训练模型的监督信号的不同,我们可以将方法分为三类:
标签监督、语言监督(以CLIP为代表)和只有图像的自监督。
其中最后一个表示监督信号是从图像本身中挖掘出来的,流行的方法包括对比学习、非对比学习和masked image建模。
在这些方法之外,文章也进一步讨论了多模态融合、区域级和像素级图像理解等类别的预训练方法。
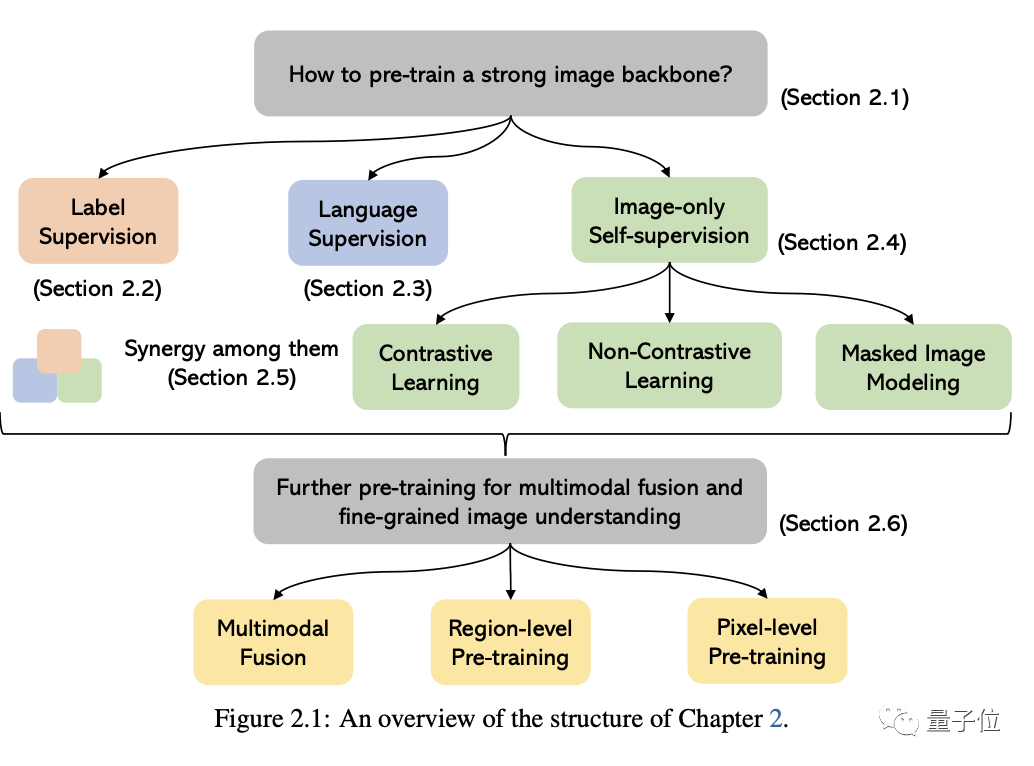
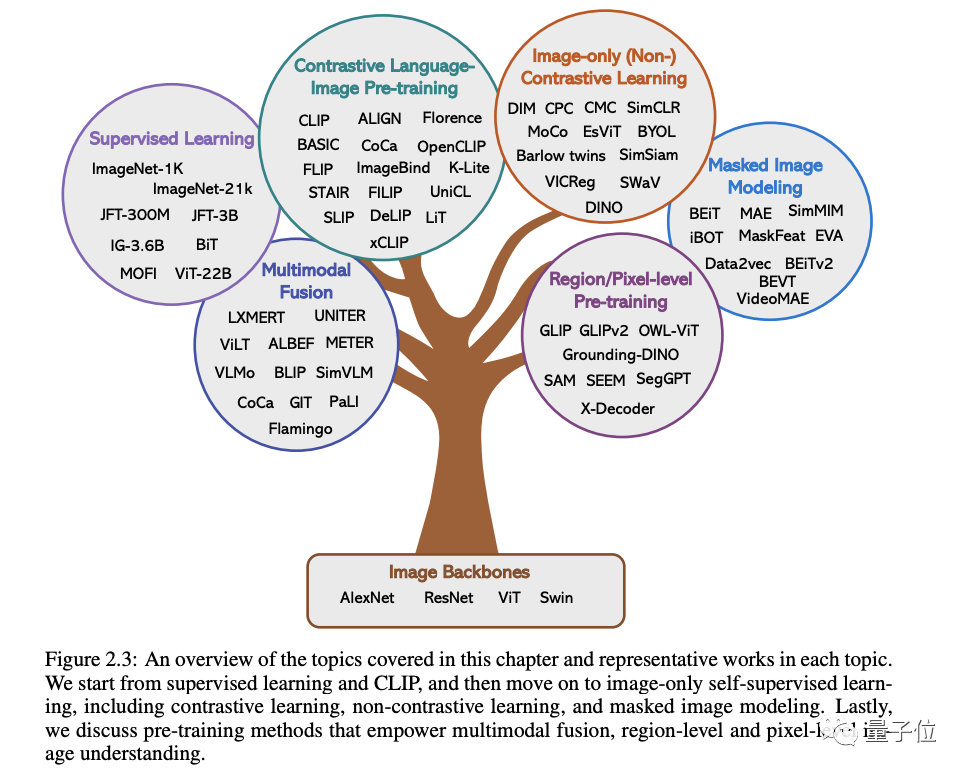
还列出了以上这些方法各自的代表作品。
2、视觉生成
这个主题是AIGC的核心,不限于图像生成,还包括视频、3D点云图等等。
并且它的用处不止于艺术、设计等领域——还非常有助于合成训练数据,直接帮助我们实现多模态内容理解和生成的闭环。
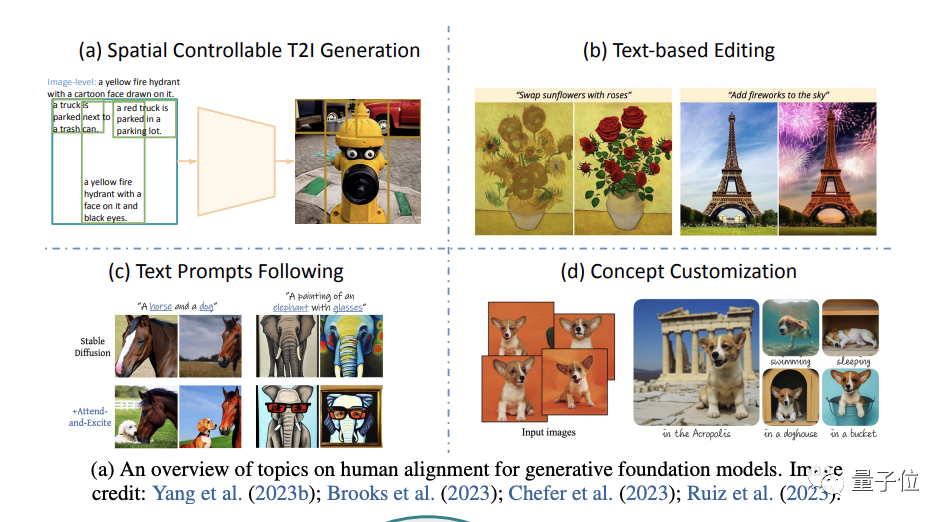
在这部分,作者重点讨论了生成与人类意图严格一致的效果的重要性和方法(重点是图像生成)。
具体则从空间可控生成、基于文本再编辑、更好地遵循文本提示和生成概念定制(concept customization)四个方面展开。
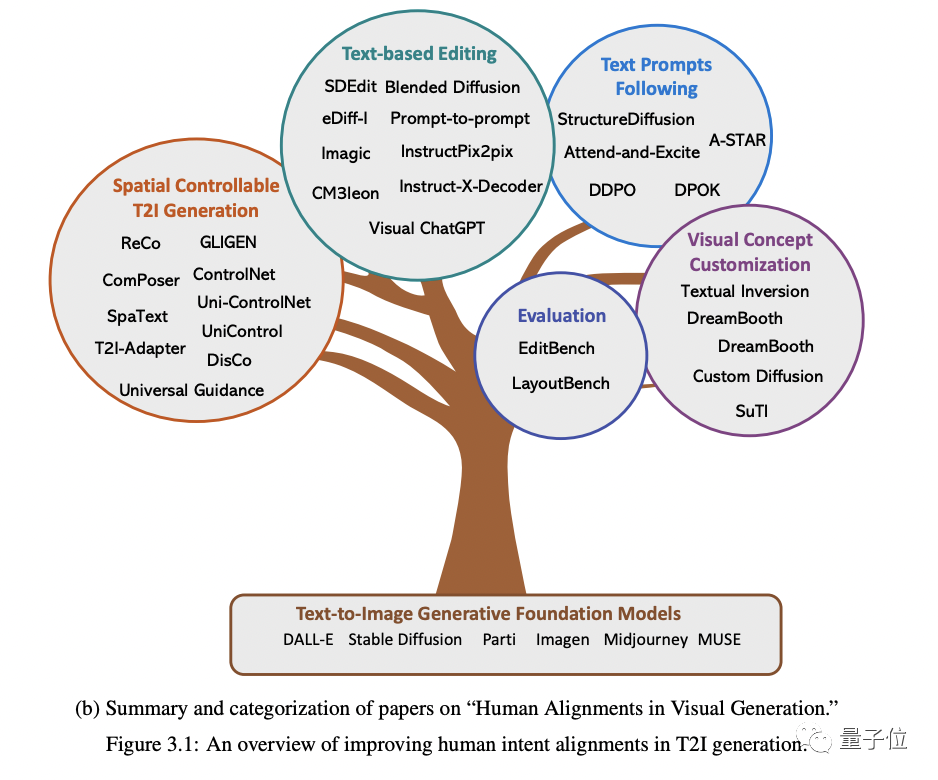
在本节最后,作者还分享了他们对当前研究趋势和短期未来研究方向的看法。
即,开发一个通用的文生图模型,它可以更好地遵循人类的意图,并使上述四个方向都能应用得更加灵活并可替代。
同样列出了四个方向的各自代表作:
3、统一视觉模型
这部分讨论了构建统一视觉模型的挑战:
一是输入类型不同;
二是不同的任务需要不同的粒度,输出也要求不同的格式;
三是在建模之外,数据也有挑战。
比如不同类型的标签注释成本差异很大,收集成本比文本数据高得多,这导致视觉数据的规模通常比文本语料库小得多。
不过,尽管挑战多多,作者指出:
CV领域对于开发通用、统一的视觉系统的兴趣是越来越高涨,还衍生出来三类趋势:
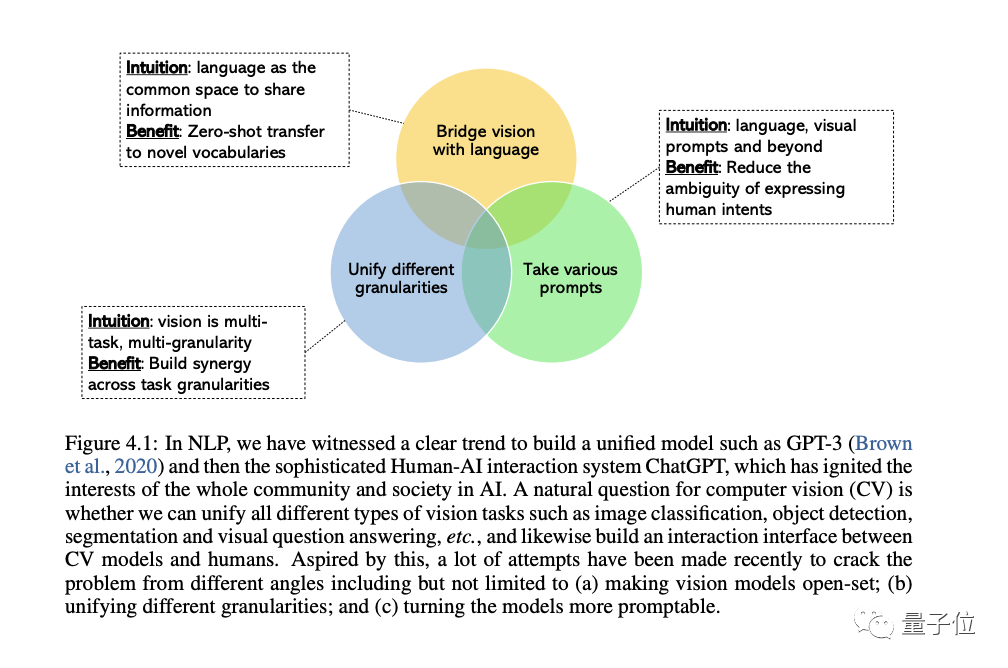
一是从闭集(closed-set)到开集(open-set),它可以更好地将文本和视觉匹配起来。
二是从特定任务到通用能力,这个转变最重要的原因还是因为为每一项新任务都开发一个新模型的成本实在太高了;
三是从静态模型到可提示模型,LLM可以采用不同的语言和上下文提示作为输入,并在不进行微调的情况下产生用户想要的输出。我们要打造的通用视觉模型应该具有相同的上下文学习能力。
4、LLM加持的多模态大模型
本节全面探讨多模态大模型。
先是深入研究背景和代表实例,并讨论OpenAI的多模态研究进展,确定该领域现有的研究空白。
接下来作者详细考察了大语言模型中指令微调的重要性。
再接着,作者探讨了多模态大模型中的指令微调工作,包括原理、意义和应用。
最后,涉及多模态模型领域中的一些高阶主题,方便我们进行更深入的了解,包括:
更多超越视觉和语言的模态、多模态的上下文学习、参数高效训练以及Benchmark等内容。
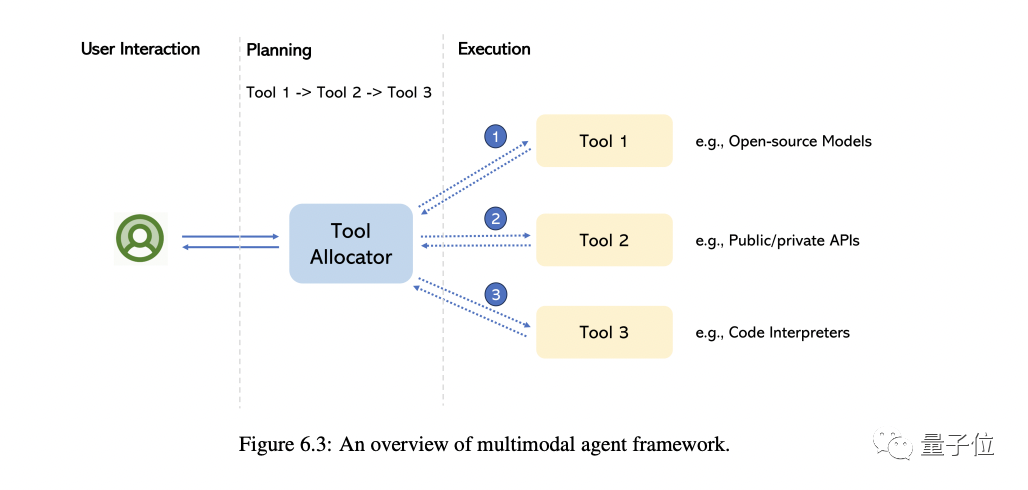
5、多模态agent
所谓多模态agent,就是一种将不同的多模态专家与LLM联系起来解决复杂多模态理解问题的办法。
这部分,作者主要先带大家回顾了这种模式的转变,总结该方法与传统方法的根本差异。
然后以MM-REACT为代表带大家看了这种方法的具体运作方式。
接着全面总结了如何构建多模态agent,它在多模态理解方面的新兴能力,以及如何轻松扩展到包含最新、最强的LLM和潜在的数百万种工具中。
当然,最后也是一些高阶主题讨论,包括如何改进/评估多多模态agent,由它建成的各种应用程序等。
作者介绍
本报告一共7位作者。
发起人和整体负责人为Chunyuan Li。
他是微软雷德蒙德首席研究员,博士毕业于杜克大学,最近研究兴趣为CV和NLP中的大规模预训练。
他负责了开头介绍和结尾总结以及“利用LLM训练的多模态大模型”这章的撰写。

核心作者一共4位:
Zhe Gan
目前已进入Apple AI/ML工作,负责大规模视觉和多模态基础模型研究。此前是Microsoft Azure AI的首席研究员,北大本硕毕业,杜克大学博士毕业。
Zhengyuan Yang
微软高级研究员,罗切斯特大学博士毕业,获得了ACM SIGMM杰出博士奖等荣誉,本科就读于中科大。
Jianwei Yang
微软雷德蒙德研究院深度学习小组首席研究员。佐治亚理工学院博士毕业。
Linjie Li(女)
Microsoft Cloud & AI计算机视觉组研究员,普渡大学硕士毕业。
他们分别负责了剩下四个主题章节的撰写。
综述地址:
https://arxiv.org/abs/2309.10020
END
分享
收藏
点赞
在看