
- 1这个 Charles 爬取微信小程序 HTTPS 请求的技巧,我怎么没早点发现!_charels如何抓取微信
- 2connection could not be acquired from the uderlying database
- 3AFNetworking源码学习
- 4浅析微信小程序的底层架构原理_exparser
- 5chatgpt赋能python:Python大文件切分:解决瓶颈问题
- 6Python str函数_str()
- 7hive安装完成后遇到的问题
- 8大数据从入门到精通(超详细版)之HDFS安装部署 , 跟着部署 , 真的有手就行 !_hdfs部署
- 9【leetcode基础题】刷题清单,刷完算法入门
- 10流程图 自定义函数_任意波形 / 函数发生器能做的25 件日常工作你知道吗?
Apache Kafka简介_docker安装kafka(2),2024年最新神级大数据开发进阶笔记_docker apache kafka
赞
踩
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
1. 概述
在本篇文章中,我将分享 Kafka 的基础知识——任何人都应该知道的用例和核心概念。然后我们就可以研磨关于Kafka更详细的知识。
2. 什么是Kafka
Kafka是由Apache软件基金会开发的开源流处理平台。 我们可以将其用作消息系统来解耦消息生产者和消费者,但与 ActiveMQ 等“经典”消息系统相比,它旨在处理实时数据流,并提供分布式、容错和高度可扩展的架构 用于处理和存储数据。
因此,我们可以在各种用例中使用它:
- 实时数据处理和分析
- 日志和事件数据聚合
- 监控和指标收集
- 点击流数据分析
- 欺诈识别
- 大数据管道中的流处理
3. 设置本地环境
如果我们是第一次接触 Kafka,我们可能希望本地安装来体验它的功能。 在 Docker 的帮助下我们可以快速实现这一点。
3.1 安装Kafka
下载现有镜像并使用以下命令运行容器实例:
docker run -p 9092:9092 -d bashj79/kafka-kraft
这将使所谓的 Kafka 代理在主机系统的端口 9092 上可用。现在,我们想使用 Kafka 客户端连接到代理。 我们可以使用多个客户端。
3.2 使用Kafka CLI
Kafka CLI 是安装的一部分,可在 Docker 容器中使用。 我们可以通过连接到容器的 bash 来使用它。
首先,我们需要使用以下命令找出容器的名称:
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7653830053fa bashj79/kafka-kraft “/bin/start_kafka.sh” 8 weeks ago Up 2 hours 0.0.0.0:9092->9092/tcp awesome_aryabhata
在此示例中,名称为 Awesome_aryabhata。然后我们使用以下命令连接到 bash:
docker exec -it awesome_aryabhata /bin/bash
例如,现在我们可以创建一个主题(稍后我们将澄清这个术语)并使用以下命令列出所有现有主题:
cd /opt/kafka/bin
create topic ‘my-first-topic’
sh kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my-first-topic --partitions 1 --replication-factor 1
list topics
sh kafka-topics.sh --bootstrap-server localhost:9092 --list
send messages to the topic
sh kafka-console-producer.sh --bootstrap-server localhost:9092 --topic my-first-topic
Hello World
The weather is fine
I love Kafka
3.3 使用Kafka Java Client
我们必须将以下 Maven 依赖项添加到我们的项目中:
org.apache.kafka kafka-clients 3.5.1
然后我们可以连接到 Kafka 并消费之前生成的消息:
// specify connection properties
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, “localhost:9092”);
props.put(ConsumerConfig.GROUP_ID_CONFIG, “MyFirstConsumer”);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// receive messages that were sent before the consumer started
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, “earliest”);
// create the consumer using props.
try (final Consumer<Long, String> consumer = new KafkaConsumer<>(props)) {
// subscribe to the topic.
final String topic = “my-first-topic”;
consumer.subscribe(Arrays.asList(topic));
// poll messages from the topic and print them to the console
consumer
.poll(Duration.ofMinutes(1))
.forEach(System.out::println);
}
当然,这是一种Kafka Client在Spring中的集成。
4. 基础概念
4.1 生产者&消费者
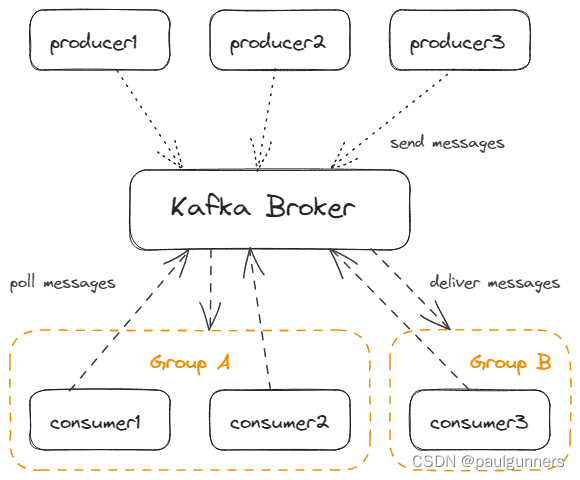
我们可以将 Kafka 客户端区分为消费者和生产者。 生产者向 Kafka 发送消息,而消费者则从 Kafka 接收消息。 他们仅通过主动从 Kafka 轮询来接收消息。 卡夫卡本身就是在以被动的方式行事。 这使得每个消费者都有自己的性能,而不会阻塞 Kafka。
当然,可以同时有多个生产者和多个消费者。当然,一个应用程序可以同时包含生产者和消费者。
消费者是消费者组的一部分,Kafka 通过一个简单的名称来识别消费者组。一个消费者组中只有一个消费者会收到该消息。这允许在保证仅一次消息传递的情况下扩展消费者。
下图是多个生产者和消费者与Kafka一起工作的情况:
4.2 消息
消息(我们也可以将其命名为“记录”或“事件”,具体取决于用例)是 Kafka 处理的数据的基本单位。 其有效负载可以是任何二进制格式以及纯文本、Avro、XML 或 JSON 等文本格式。
每个生产者都必须指定一个序列化器来将消息对象转换为二进制有效负载格式。 每个消费者必须指定相应的反序列化器来将有效负载格式转换回其 JVM 中的对象。 我们将这些组件简称为 SerDes。 有内置的 SerDes,但我们也可以实现自定义 SerDes。
下图展示了payload的序列化和反序列化过程:

此外,消息可以具有以下可选属性:
- 密钥也可以是任何二进制格式。 如果我们使用密钥,我们还需要 SerDes。 Kafka 使用键进行分区(我们将在下一章更详细地讨论这一点)。
- 时间戳指示消息的生成时间。 Kafka 使用时间戳来排序消息或实施保留策略。
- 我们可以应用标头将元数据与有效负载相关联。 例如。 Spring 默认添加用于序列化和反序列化的类型标头。
4.3 主题&分区
主题是生产者发布消息的逻辑通道或类别。消费者订阅一个主题以从其消费者组的上下文中接收消息。
默认情况下,主题的保留策略为 7 天,即 7 天后,Kafka 会自动删除消息,与是否发送给消费者无关。如果需要的话我们可以进行配置。
主题由分区(至少一个)组成。 确切地说,消息存储在主题的一个分区中。 在一个分区内,消息会获得一个顺序号(偏移量)。 这可以确保消息以与存储在分区中相同的顺序传递给消费者。 而且,通过存储消费者组已经收到的偏移量,Kafka 保证只传递一次。
通过处理多个分区,我们可以确定 Kafka 可以在消费者进程池上提供排序保证和负载平衡。
一个消费者在订阅该主题时将被分配到一个分区,例如 使用 Java Kafka 客户端 API,正如我们已经看到的:
String topic = “my-first-topic”; consumer.subscribe(Arrays.asList(topic));
However, for a consumer, it is possible to choose the partition(s) it wants to poll messages from:
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)
[外链图片转存中…(img-D7uEdVLv-1713272360921)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

