
- 1hive01--hive的安装及配置_第1关:hive的安装与配置
- 2本关任务:输入N个字符串,编写程序将它们按照字符串长度大小进行升序排列。_输入n个不同长度的短语,根据短语长度,从小到大进行排序。
- 3【阿里云 centos7安装python3.12遇到的坑,openssl】Could not build the ssl module! Python requires a OpenSSL 1.1.1_python requires a openssl 1.1.1 or newer
- 4AP Autosar平台设计 13 更新和配置管理 Update and Config Management_ap autosar的ucm master和ucm
- 5基于springboot的智能家居系统_基于springboot智能家电管理系统
- 6vba数据类型,运算符,内置函数,循环判断语句,窗体控件_vba 数据类型
- 7数据结构实验报告3————栈和队列及其应用_栈和队列的应用实验报告
- 8通过packstack快速安装openstack_applying puppet manifests
- 9hive sql常用函数
- 10C++ 冒泡排序/选择排序/插入排序/快速排序/希尔排序_c++冒泡排序记录原序号
深度学习_PyCharm入门_pycharm深度学习
赞
踩
文章目录
学习来源:小破绽-我是土堆
环境安装
安装anaconda(工具包的整合)
一个环境,由conda prompt进行交互,后面的pycharm就是基于这个环境进行编译;
pycharm的terminal和conda prompt起相同作用
检查显卡
https://www.nvidia.cn/geforce/technologies/cuda/supported-gpus/

看gpu是否支持CUDA
创建虚拟环境
打开 anaconda prompt
应付多版本情况
# 创建环境 (base) C:\Users\xuwenxing>conda create -n pytorch python=3.8 done # # To activate this environment, use # # $ conda activate pytorch # # To deactivate an active environment, use # # $ conda deactivate # 激活创建的环境 (base) C:\Users\xuwenxing>conda activate pytorch (pytorch) C:\Users\xuwenxing> # 查看该环境下的工具包列表 (pytorch) C:\Users\xuwenxing>pip list Package Version ------------ ----------- certifi 2022.5.18.1 pip 21.2.2 setuptools 61.2.0 wheel 0.37.1 wincertstore 0.2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
激活环境,安装pytorch框架
https://pytorch.org/

打开conda prompt
# 安装
(pytorch) C:\Users\xuwenxing>conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
# 查看 有torch即可
(pytorch) C:\Users\xuwenxing>pip list
# 进入python环境,验证torch
(pytorch) C:\Users\xuwenxing>python
Python 3.8.13 (default, Mar 28 2022, 06:59:08) [MSC v.1916 64 bit (AMD64)] :: Anaconda, Inc. on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
# 验证gpu能否使用
>>> torch.cuda.is_available()
True
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
编辑器
PyCharm
下载安装
PyCharm: the Python IDE for Professional Developers by JetBrains
创建项目
编译环境选择上面已安装激活好的conda的pytorch环境

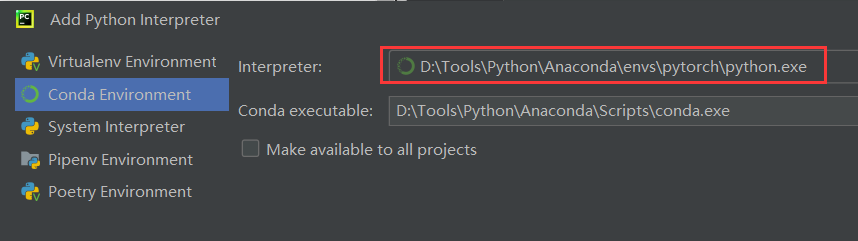
验证环境
进入工作台(Python Console)

终端(terminal)类似conda prompt

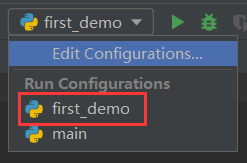
first_demo
新建.py文件后,配置相应python解释器

解释器配置后,可选择对应文件运行
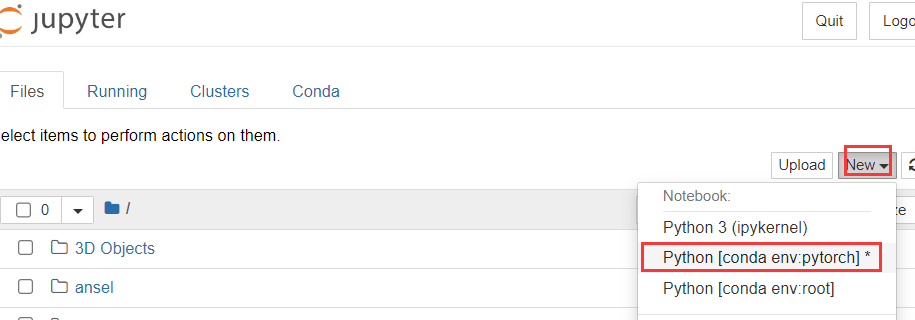
Jupyter
安装了anaconda自带jupyter notebook
问题:
jupyter默认安装在base虚拟环境中,但base没有安装pytorch
解决:
base环境再装一次pytorch;
pytorch虚拟环境安装jupyter.
jupyter所依赖的包,在自己创建的pytorch虚拟环境是没有的

进入pytorch环境安装此包
> conda activate pytorch
> conda install nb_conda
# 打开jupyter
> jupyter notebook
- 1
- 2
- 3
- 4
换自己创建的pytorch虚拟环境
**shift + enter :**指定当前命令并跳转到新的代码块

创建项目
打开jupyter
> conda activate pytorch
> jupyter notebook
- 1
- 2
选择环境
常用函数
dir()
打开,知道工具箱以及工具箱的分隔区有什么东西(一个虚拟环境看作一个工具箱)
help()
对工具箱的说明书
# 在jupyter里,查看工具描述信息的两种方法
help(Dataset)
Dataset??
- 1
- 2
- 3
数据可视化
TensorBoard
项目名:01_learn_pytorch/02_test_tensorboard.py
TensorBoard是TensorFlow自带的一个强大的可视化工具,也是一个Web应用程序套件。TensorBoard目前支持7种可视化,Scalars,Images,Audio,Graphs,Distributions,Histograms和Embeddings。其中可视化的主要功能如下。
(1)Scalars:展示训练过程中的准确率、损失值、权重/偏置的变化情况。
(2)Images:展示训练过程中记录的图像。
(3)Audio:展示训练过程中记录的音频。
(4)Graphs:展示模型的数据流图,以及训练在各个设备上消耗的内存和时间。
(5)Distributions:展示训练过程中记录的数据的分部图。
(6)Histograms:展示训练过程中记录的数据的柱状图。
(7)Embeddings:展示词向量后的投影分部
安装TensorBoard包
在conda prompt或pycharm终端
> pip install tensorboard
- 1
绘表 add_scalar()
tensorboard用于可视化,有图像(image)/标量(scalar)可视化两种,分别制图/绘表
def add_scalar( self, tag, scalar_value, //纵坐标 global_step=None, //横坐标 walltime=None, new_style=False, double_precision=False, ):
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
代码
from torch.utils.tensorboard import SummaryWriter
# 指定日志文件路径,后续可根据该日志文件查看对应网页信息
writer = SummaryWriter("logs")
# writer.add_image()
for i in range(100):
writer.add_scalar("y=x",i,i)
writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
查看表格信息
- 在终端或者conda prompt中打开日志文件
>tensorboard --logdir=logs
TensorBoard 2.9.1 at http://localhost:6006/ (Press CTRL+C to quit)
- 1
- 2
- 点击网址

- 为防止端口冲突,可指定端口
>tensorboard --logdir=logs --port=6
007
TensorBoard 2.9.1 at http://localhost:6007/ (Press CTRL+C to quit)
- 1
- 2
- 3
制图 add_image()
def add_image( self, tag, //图像数据类型(torch.Tensor, numpy.array, or string/blobname) img_tensor, global_step=None, walltime=None, dataformats='CHW' ):
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
PIL.Image读取的数据集的类型不符合规定的类型。查看数据集的类型
from PIL import Image
img = Image.open("dataset/train/ants/0013035.jpg")
print(type(img))
<class 'PIL.JpegImagePlugin.JpegImageFile'>
- 1
- 2
- 3
- 4
采用opencv读取的数据集是numpy型,下面代码没用opencv,用的是numpy库
安装opencv
在终端安装
>pip install opencv-python
- 1
转换图片类型(numpy)
# from PIL import Image
# img = Image.open("dataset/train/ants/0013035.jpg")
# print(type(img))
# <class 'PIL.JpegImagePlugin.JpegImageFile'>
import numpy as np
img_array = np.array(img)
print(type(img_array))
## 输出
<class 'numpy.ndarray'>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
图片格式(shape)相关问题
# 根据add_image()的说明文档 # Shape: # img_tensor: Default is :math:`(3, H, W)` # 默认是CHW,而数据集的shap是HWC,需要转换 # If you have non-default dimension setting, set the dataformats argument. # writer.add_image('my_image_HWC', img_HWC, 0, dataformats='HWC') img_path = "dataset/train/ants/0013035.jpg" img_PIL = Image.open(img_path) img_array = np.array(img_PIL) print(type(img_array)) print(img_array.shape) ## 输出 <class 'numpy.ndarray'> (512, 768, 3)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18

代码
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as np
img_path = "dataset/train/ants/0013035.jpg"
img_PIL = Image.open(img_path)
img_array = np.array(img_PIL)
print(type(img_array))
print(img_array.shape)
img_PIL.show()
writer = SummaryWriter("logs")
writer.add_image("test",img_array,1,dataformats='HWC')
writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
查看图片信息
进入终端
tensorboard --logdir=logs --port=6
007
- 1
- 2

绘结构图add_graph()
项目:02_DataSet/08_nn_sequential.py
import torch import torch.nn as nn from torch.nn import Conv2d, MaxPool2d, Linear, Flatten from torch.utils.tensorboard import SummaryWriter class my_nn(nn.Module): def __init__(self) -> None: super().__init__() self.module1 = nn.Sequential( Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2), MaxPool2d(2), Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2), MaxPool2d(2), Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2), MaxPool2d(2), Flatten(), Linear(1024, 64), Linear(64, 10) ) def forward(self,x): self.module1(x) return x ## 输出网络结构 nn = my_nn() print(nn) ## 创建模拟数据,验证网络结构是否正确,如:将16行修改为10240就会报错 input = torch.ones((64,3,32,32)) output = nn(input) print(output.shape) writer = SummaryWriter("./log_08") writer.add_graph(nn,input) writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37

图像处理
1_图片类型
项目名:01_learn_pytorch/03_transforms.py
就是一个工具箱,里面有很多类(工具),将特定格式的图片通过工具得到预期的图片变换,将学习到:
-
tensor数据类型相较于普通数据类型的区别
- 为什么需要tensor类型
可理解为包装了神经网络所需要的理论基础的参数

-
使用类ToTensor来演绎Transforms如何使用

Tips
不知道当前变量的数据类型时
print(img)
print(type(img))
debug
- 1
- 2
- 3
Tensor类型
from PIL import Image from torchvision import transforms img_path = "dataset/train/ants/0013035.jpg" img = Image.open(img_path) # 实例化transforms里的ToTensor类(创建工具) tensor_object = transforms.ToTensor() # 内置函数可以直接传参 相当于 tensor_object().call(img) ; 魔法方法,满足条件自动调用(使用工具) img_tensor = tensor_object(img) print(img_tensor)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
输出

numpy.ndarray
采用opencv库
# 终端安装opencv包
(pytorch) D:\Desktop\workspaces\PyCharm\learn_pytorch>pip install opencv-python
- 1
- 2
import cv2
from PIL import Image
img_path = "dataset/train/ants/0013035.jpg"
img_cv = cv2.imread(img_path)
print(type(img_cv))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
采用numpy库
import numpy as np
img_path = "dataset/train/ants/0013035.jpg"
img = Image.open("dataset/train/ants/0013035.jpg")
img_array = np.array(img)
print(type(img_array))
## 输出
<class 'numpy.ndarray'>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
PIL Image
PIL库
from PIL import Image
img_path = "dataset/train/ants/0013035.jpg"
img = Image.open(img_path)
- 1
- 2
- 3
- 4
类型总结

2_Transform.py
torchvison.transforms
项目名:01_learn_pytorch/04_transforms_Function.py
结合tensorboard讲解主要方法以便直观展示
import numpy from PIL import Image from torchvision import transforms from torch.utils.tensorboard import SummaryWriter writer = SummaryWriter("logs") img = Image.open("dataset/train/bees/16838648_415acd9e3f.jpg") # (500,450) print(img.size) ## ToTensor # 实例化工具并调用方法 totensor = transforms.ToTensor() img_tensor = totensor(img) # tensorboard可视化 writer.add_image("ToTensor",img_tensor) ## Normalize 需传入Tensor类型的图像 # 实例化工具 norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 对象调用对应方法,将传入的tensor图像正则化,返回一个tensor img_tensor_norm = norm.forward(img_tensor) # 采用tensorboard进行可视化查看 writer.add_image("tensor_normalize",img_tensor_norm,1) ## Resize 缩放图片 # 实例化工具 # 如果只有一个参数,smaller edge of the image will be matched to this number.长短边比例不变 resize = transforms.Resize((1024, 1024)) # 使用工具 Resize工具可接受PIL和Tensord类型的;但tensorboard不接受PIL,这里采用Tensor类型 img_resize = resize(img_tensor) # 可视化 writer.add_image("Resize",img_resize,2) ## Compose 多个操作依次执行 Resize_2 ; 先resize_2再totensor;后面的输入必须是前一个的输出 # 实例化工具 resize_2 = transforms.Resize(256) compose = transforms.Compose([resize_2, totensor]) # 使用工具 img_compose = compose(img) writer.add_image("Resize",img_compose,1) ## RandomCrop 随机裁剪一块
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
3_DataSet批处理
项目名:02_DataSet/01_dataset_transform.py
Transform、Tensorboard就是来自Torchvision模块
本小节将学习到:
- dataset和transform联合使用,批量处理图像
import torchvision from torch.utils.tensorboard import SummaryWriter dataset_trainsform = torchvision.transforms.Compose([ torchvision.transforms.ToTensor() ]) # 数据集的下载和预处理(转为tensor类型) train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True,transform=dataset_trainsform,download=True) test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False,transform=dataset_trainsform,download=True) # 可视化 writer = SummaryWriter("log_01") for i in range(10): img,target = test_set[i] writer.add_image("test_set",img,i) writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
Dataset
项目名:01_learn_pytorch/read_data.py
https://pytorch.org/vision/stable/datasets.html
提供一种方式去获取数据及其label,将学习到:
- 如何获取每一个数据及其label
- 告诉我们总共有多少数据
使用 hymenoptera_data 数据集,复制到项目learn_pytorch中
from torch.utils.data import Dataset from PIL import Image import os class MyData(Dataset): # 构造函数 def __init__(self,root_dir,label_dir): self.root_dir = root_dir self.label_dir = label_dir self.path = os.path.join(self.root_dir,self.label_dir) self.img_list = os.listdir(self.path) def __getitem__(self, index): img_name = self.img_list[index] # 拼接路径,windows的路径要转义 'dataset/train\\ants' img_item_path = os.path.join(self.path,img_name) # 通过图片路径获取图片 img = Image.open(img_item_path) label = self.label_dir return img,label def __len__(self): return len(self.img_list) # 创建实例 root_dir = "dataset/train" ants_label_dir = "ants" bees_label_dir = "bees" ants_dataset = MyData(root_dir,ants_label_dir) bees_dataset = MyData(root_dir,bees_label_dir) # print(ants_dataset[0]) 内置函数,可直接传参,和下一行代码一个意思 img_1,label_1 = ants_dataset.__getitem__(0) print(img_1,label_1) print(len(ants_dataset)) # img_1.show() # train_dataset = ants_dataset + bees_dataset
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36

Dataloader
项目名:02_DataSet/02_dataloader.py
为后面的网络提供不同的数据形式
作用:从dataset取图片、加载到神经网络
DataSet和DataLoader的返回值类型及如何获取元素见问题汇总
循环多少次
比如CIFAR10有10000张图,设置的batch_size是64,则有迭代器中有10000/64个序列,drop_last=True时,最后一个序列不满64张则删除,shuffer=True时每一轮筛选的图片是随机的。drop_last参数设置的效果如下

import torchvision from torch.utils.data import DataLoader # 测试数据集 from torch.utils.tensorboard import SummaryWriter test_set = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),download=False) test_loader = DataLoader(test_set, batch_size=64, shuffle=True, num_workers=0, drop_last=False) img,target = test_set[0] print(img.shape) print(target) ## 迭代器获取dataloader的元素 # data = test_loader.__iter__() # imgs,targets = data.__next__() # print(imgs) # print(targets) writer = SummaryWriter("log_02") step = 1 # for循环获取dataloader的元素,循环次数见上方解释 for data in test_loader: imgs,targets = data # print(imgs.shape) # print(targets) writer.add_images("DataLoader",imgs,step) step = step + 1 writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
Torch.nn.functinal
https://pytorch.org/docs/stable/nn.functional.html
本节学习搭建基本神经网络骨架的基本操作(neural network)
Conv2d
二维卷积
项目名:02_DataSet/03_nn_conv2d.py
torch.nn.functional.conv2d的基本参数:

input:输入张量、
weight:卷积核、
bias:偏置;对卷积后的结果再加上一个常数
stride:步长、
padding:图像填充;padding=1,周围补零,可以让卷积后大小不变
dilation:控制卷积核之间的距离,用于空洞卷积,默认是1即相邻
groups:通常为1;改动的情况是分组卷积
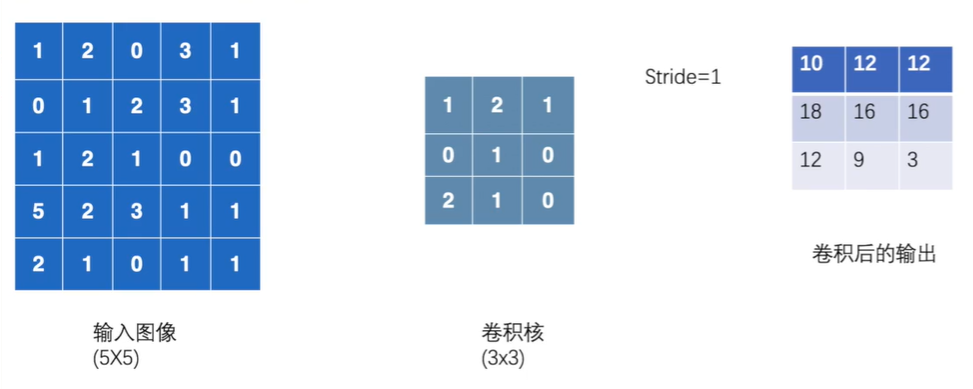
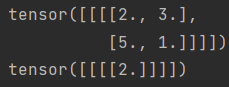
3 = 5 - 3 + 1
import torch.nn.functional as F import torch # 定义输入图像张量 input = torch.tensor([ [1, 2, 0, 3, 1], [0, 1, 2, 3, 1], [1, 2, 1, 0, 0], [5, 2, 3, 1, 1], [2, 1, 0, 1, 1]]) # 定义权重/卷积核张量 kernel = torch.tensor([ [1,2,1], [0,1,0], [2,1,0] ]) # 官方文档input和weight的shape有规定 input_reshape = torch.reshape(input, [1, 1, 5, 5]) kernel_reshape = torch.reshape(kernel, [1, 1, 3, 3]) # 二维卷积 output = F.conv2d(input=input_reshape, weight=kernel_reshape, stride=1) print(output.shape) print(output)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
输出:

Torch.nn
Conv2d
https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html#torch.nn.Conv2d
项目名:02_DataSet/04_nn.conv2d.py
参数:
N是批量大小

shape:



通道数变化
output_channel可自己设置,output_size是自动计算得到
2个1*3*3的卷积核,对input一个个卷积得到2个1*3*3叠起来。3(输出的尺寸) = 5(输入的尺寸) - 3(卷积核大小) + 1
通道数越多就越厚(长)
import torch import torch.nn as nn from torch.utils.data import DataLoader import torchvision.datasets ## 获取、加载数据 from torch.utils.tensorboard import SummaryWriter dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True) dataloader = DataLoader(dataset=dataset, batch_size=64, shuffle=True, num_workers=0, drop_last=False) ## 搭建神经网络 class NN(nn.Module): def __init__(self) -> None: super().__init__() ## 定义全局变量 # 第一层卷积层 self.conv1 = nn.Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0) ## 前向传播 def forward(self,input): x = self.conv1(input) return x ## 初始化网络 nn = NN() print(nn) writer = SummaryWriter("./log_04") step = 1 for data in dataloader: imgs,targets = data output = nn(imgs) # torch.Size([64, 3, 32, 32]) print(imgs.shape) # torch.Size([64, 6, 30, 30]) print(output.shape) writer.add_images("Input",imgs,step) # 6通道的输出无法显示,因此reshape至3通道;第一个in_channel设为"-1"能根据后面的值自动计算 output = torch.reshape(output, [-1, 3, 30, 30]) writer.add_images("Outnput",output,step) step = step + 1 writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
输出:
输出的大小 30 = 32 - 3 + 1
通道由3变为6
MaxPool2d
https://pytorch.org/docs/stable/generated/torch.nn.MaxPool2d.html#torch.nn.MaxPool2d
下采样/最大池化
尽可能保留输入的特征同时减少数据量
经过**池化操作通道数不变**
项目名:02_DataSet/05_nn_maxpool.py
参数:

ceil_mode:默认是False。ceil天花板向上取整(保留),floor向下取整(不保留)。解释如下图:
步长默认=kernel_size=3
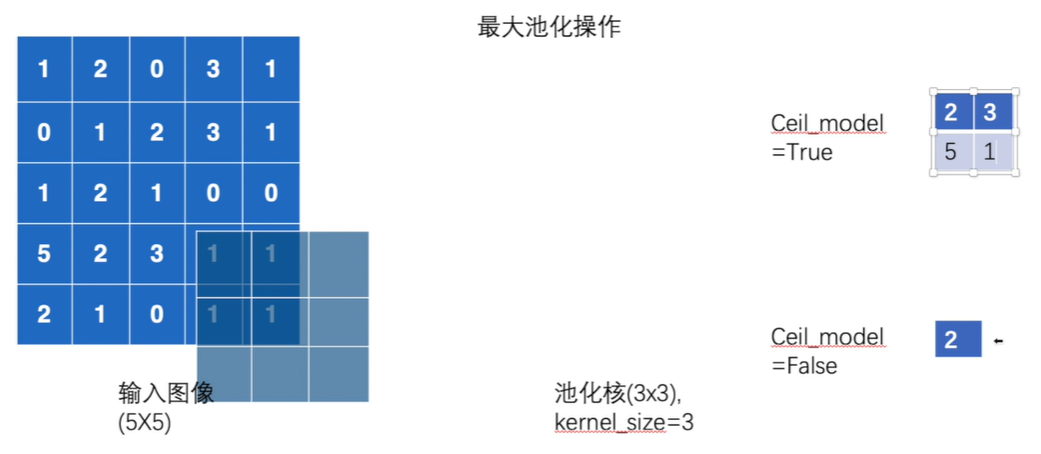
shape:

import torch.nn as nn import torchvision # 定义输入图像张量 # 报错:RuntimeError: "max_pool2d" not implemented for 'Long' 转换为浮点数类型 input = torch.tensor([ [1, 2, 0, 3, 1], [0, 1, 2, 3, 1], [1, 2, 1, 0, 0], [5, 2, 3, 1, 1], [2, 1, 0, 1, 1]],dtype=torch.float32) ## 官方文档有shape类型的指定 # (N,C,H,W) # -1是模糊类型,根据后面的值自动计算批量大小 input = torch.reshape(input, (-1, 1, 5, 5)) ## 构造神经网络 class NN(nn.Module): def __init__(self) -> None: super().__init__() self.maxpool_ceil_true = nn.MaxPool2d(kernel_size=3,ceil_mode=True) self.maxpool_ceil_false = nn.MaxPool2d(kernel_size=3,ceil_mode=False) def forward(self,input): output_1 = self.maxpool_ceil_true(input) output_2 = self.maxpool_ceil_false(input) return output_1,output_2 ## 实例化网络 nn = NN() output_1,output_2 = nn(input) print(output_1) print(output_2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
输出
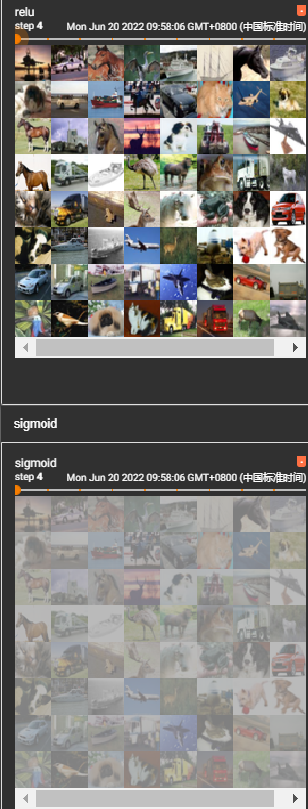
ReLu/Sigmoid
https://pytorch.org/docs/stable/generated/torch.nn.ReLU.html#torch.nn.ReLU
https://pytorch.org/docs/stable/generated/torch.nn.Sigmoid.html#torch.nn.Sigmoid
项目:02_DataSet/06_relu.py
非线性激活(Non-linear Activations)
给网络引入非线性特征,越多越能训练出符合各种特征的模型,提高泛化能力
relu
参数:
inplace : can optionally do the operation in-place. Default:
False。是否替换,一般设置为false,可保留原始参数shape:
- Input: (*), where *∗ means any number of dimensions.
- Output: (*), same shape as the input.
对张量的作用:
比0小的设置为0,比0大的不变
输入:
输出:


import torch.nn as nn import torchvision from torch.nn import ReLU, Sigmoid from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter writer = SummaryWriter("log_05") ## 获取,加载数据集 dataset = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True) input = DataLoader(dataset=dataset, batch_size=64, num_workers=0, drop_last=False) ## 构建网络结构 class nn(nn.Module): def __init__(self) -> None: super().__init__() self.relu = ReLU() self.sigmoid = Sigmoid() def forward(self,input): output_relu = self.relu(input) output_sigmoid = self.sigmoid(input) return output_relu,output_sigmoid ## 测试 network = nn() step = 1 for data in input: imgs,targets = data out_relu,out_sig = network(imgs) writer.add_images("relu",out_relu,step) writer.add_images("sigmoid",out_sig,step) step = step + 1 writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
输出:
Linear
线性激活,多层感知机,全连接层
https://pytorch.org/docs/stable/nn.html#linear-layers
项目:02_DataSet/07_linear.py

in_features即图片的W(宽)
将图片平摊,宽是196608,torch.flatten
for data in input: imgs,targets = data ## 平摊图片 print(imgs.shape) input = flatten(imgs) print(input.shape) output = network(input) print(output.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

本结,对input进行平摊再经过线性层

import torch import torch.nn as nn import torchvision from torch.nn import ReLU, Sigmoid, Linear from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter from torch import flatten writer = SummaryWriter("log_07") ## 获取,加载数据集 dataset = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True) input = DataLoader(dataset=dataset, batch_size=64, num_workers=0, drop_last=False) ## 构建网络结构 class nn(nn.Module): def __init__(self) -> None: super().__init__() self.linear = Linear(196608,10) def forward(self,input): output = self.linear(input) return output network = nn() step = 1 for data in input: imgs,targets = data ## 平摊图片 print(imgs.shape) input = torch.reshape(imgs,(1,1,1,-1)) print(input.shape) output = network(input) print(output.shape) writer.add_images("flatten",input,step) writer.add_images("linear",output,step) step = step + 1 writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42

可视化输出失败,日后解决

sequential
Sequential — PyTorch 1.11.0 documentation
项目:02_DataSet/08_nn_sequential.py
本节结合torch.nn.sequential(Containers)实战CIFAR10-quick model
sequential容器(序列)类似于torchvison.transforms的compose方法
model = nn.Sequential( nn.Conv2d(1,20,5), nn.ReLU(), nn.Conv2d(20,64,5), nn.ReLU() ) # Using Sequential with OrderedDict. This is functionally the # same as the above code model = nn.Sequential(OrderedDict([ ('conv1', nn.Conv2d(1,20,5)), ('relu1', nn.ReLU()), ('conv2', nn.Conv2d(20,64,5)), ('relu2', nn.ReLU()) ]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
本节CIFAR10网络结构如下
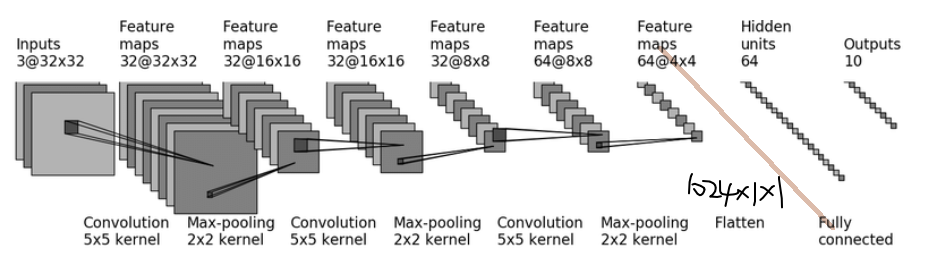
步骤详解
1、3×32×32 经过5×5卷积得到 32×32×32,维持了尺寸不变,要计算其他参数
取**stride=1(默认),pad=2**

2、 32×32×32 64×8×8 32×16×16
设置kernel_size=2即可其他默认,stride默认=kernel_size

3、32×16×16 经过5×5卷积得到 32×16×16,尺寸不变和步骤1一样计算得
padding=2
4、32×16×16 经过2×2池化得到 32×8×8
5、32×8×8 经过5×5卷积得到 64×8×8,尺寸不变padding=2
6、64×8×8 经过2×2池化得到 64×4×4
7、平铺 flatten 有64×4×4=1024×1×1 即通道数为1024,有1024种特征表示

8、1024个数据经过两层线性激活/全连接
1024 --> 64
64 --> 10
10就是CIFAR10要测试的10个类别
代码
- 构造模拟数据验证网络结构参数是否正确很重要
import torch import torch.nn as nn from torch.nn import Conv2d, MaxPool2d, Linear, Flatten class my_nn(nn.Module): def __init__(self) -> None: super().__init__() self.conv1 = Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2) self.maxpool1 = MaxPool2d(2) self.conv2 = Conv2d(in_channels=32,out_channels=32,kernel_size=5,padding=2) self.maxpool2 = MaxPool2d(2) self.conv3 = Conv2d(in_channels=32,out_channels=64,kernel_size=5,padding=2) self.maxpool3 = MaxPool2d(2) self.flatten = Flatten() self.linear1 = Linear(1024,64) self.linear2 = Linear(64,10) self.module1 = nn.Sequential( Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2), MaxPool2d(2), Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2), MaxPool2d(2), Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2), MaxPool2d(2), Flatten(), Linear(1024, 64), Linear(64, 10) ) def forward(self,x): x = self.conv1(x) x = self.maxpool1(x) x = self.conv2(x) x = self.maxpool2(x) x = self.conv3(x) x = self.maxpool3(x) x = self.flatten(x) x = self.linear1(x) x = self.linear2(x) return x ## 输出网络结构 nn = my_nn() print(nn) ## 创建模拟数据,验证网络结构是否正确,如:将16行修改为10240就会报错 input = torch.ones((64,3,32,32)) output = nn(input) print(output.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
输出:
-
Sequential用法
定义一个sequential全局变量就行,不用定义conv1…那么多,代码会简洁很多
网络各层数会自动标号
import torch import torch.nn as nn from torch.nn import Conv2d, MaxPool2d, Linear, Flatten class my_nn(nn.Module): def __init__(self) -> None: super().__init__() self.module1 = nn.Sequential( Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2), MaxPool2d(2), Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2), MaxPool2d(2), Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2), MaxPool2d(2), Flatten(), Linear(1024, 64), Linear(64, 10) ) def forward(self,x): self.module1(x) return x ## 输出网络结构 nn = my_nn() print(nn) ## 创建模拟数据,验证网络结构是否正确,如:将16行修改为10240就会报错 input = torch.ones((64,3,32,32)) output = nn(input) print(output.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
输出:

网络结构图绘制:

Loss Functions
损失函数作用如下:
- 计算实际输出和目标之间的差距
- 反向传播,为更新输出提供一定的依据
只需确定输入和输出的情况
输入一般根据官网的shape进行reshape
loss小试
https://pytorch.org/docs/stable/generated/torch.nn.L1Loss.html#torch.nn.L1Loss
import torch.nn as nn import torch input = torch.tensor([1, 2, 3],dtype=float) target = torch.tensor([1, 2, 5],dtype=float) input = torch.reshape(input,(1,1,1,3)) target = torch.reshape(target,(1,1,1,3)) loss = nn.L1Loss() result = loss(input, target) loss_mse = nn.MSELoss() result_mse = loss_mse(input, target) print(result) print(result_mse)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
输出:
计算实际输出和目标之间的差距
https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html#torch.nn.CrossEntropyLoss
项目:02_DataSet/09_loss.py
交叉熵损失+网络结构(sequential)
- 获取/下载数据集
- 网络结构定义
- 构造网络实例、损失函数实例
- 对download的每个imgs元素进行网络训练得到输出output
- 计算output和download的targets元素的损失
import torch import torch.nn as nn import torchvision.datasets from torch.nn import Conv2d, MaxPool2d, Linear, Flatten from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter test_set = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True) test_loader = DataLoader(test_set, batch_size=1, shuffle=True, num_workers=0, drop_last=True) class NN(nn.Module): def __init__(self) -> None: super(NN,self).__init__() self.module1 = nn.Sequential( Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2), MaxPool2d(2), Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2), MaxPool2d(2), Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2), MaxPool2d(2), Flatten(), Linear(1024, 64), Linear(64, 10) ) def forward(self, x): x = self.module1(x) return x loss = nn.CrossEntropyLoss() network = NN() for data in test_loader: imgs,targets = data output = network(imgs) # print(output) # print(targets) # print(imgs.shape) # print(output.shape) # print(targets) result_loss = loss(output, targets) print(result_loss) print("ok")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
反向传播
grad(梯度)
为更新输出提供一定的依据,和网络中的forward(前向传播形成照应)
对已计算的损失进行反向传播,可以获得各个梯度节点的参数,接下来就是用优化器去优化梯度参数,让每一次的方向尽可能最优
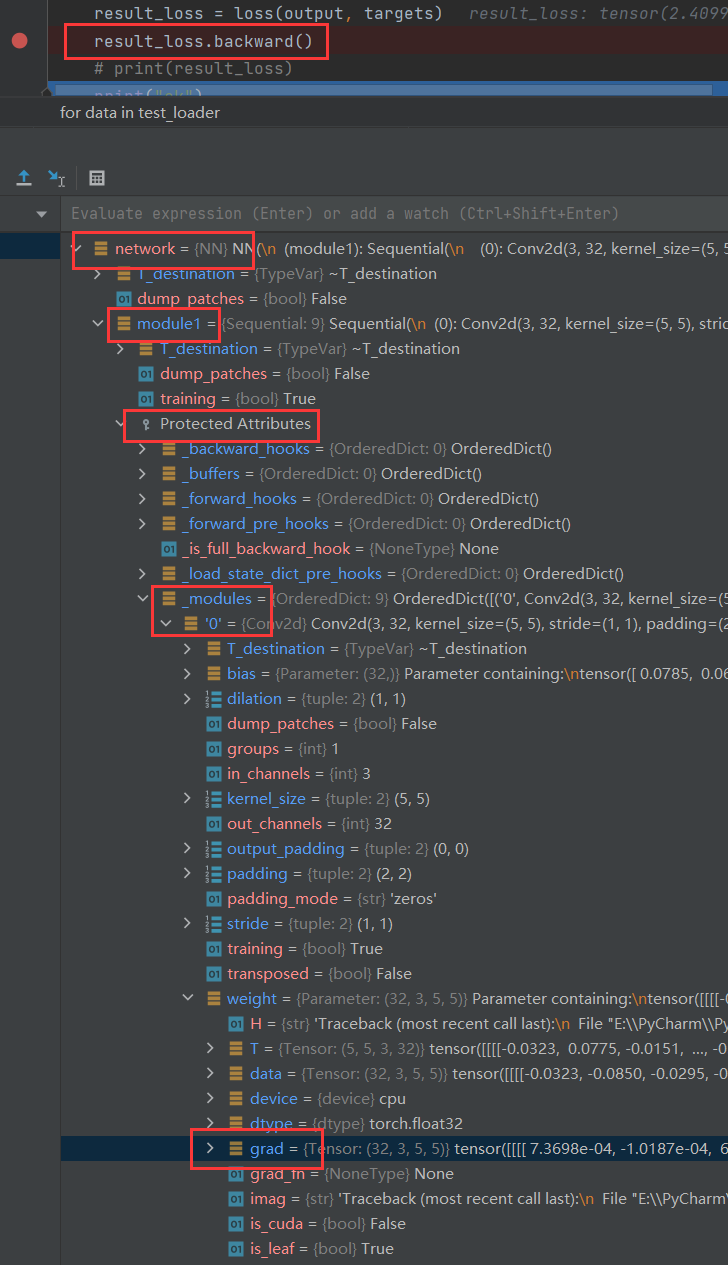
优化器
https://pytorch.org/docs/stable/optim.html
项目:02_DataSet/10_nn_optim.py
import torch import torch.nn as nn import torchvision.datasets from torch.nn import Conv2d, MaxPool2d, Linear, Flatten from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter test_set = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True) test_loader = DataLoader(test_set, batch_size=1, shuffle=True, num_workers=0, drop_last=True) class NN(nn.Module): def __init__(self) -> None: super(NN,self).__init__() self.module1 = nn.Sequential( Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2), MaxPool2d(2), Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2), MaxPool2d(2), Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2), MaxPool2d(2), Flatten(), Linear(1024, 64), Linear(64, 10) ) def forward(self, x): x = self.module1(x) return x loss = nn.CrossEntropyLoss() network = NN() ## 优化器,选择随机梯度下降算法 optim = torch.optim.SGD(network.parameters(), 0.01) # 多学习几轮 for epoc in range(20): running_loss = 0.0 for data in test_loader: imgs,targets = data # 模型训练图片获得输出 outputs = network(imgs) # 计算输出和目标的损失 result_loss = loss(outputs, targets) # 每一次循环结束都要把上一层的参数归零,上一层的梯度对这一层是没有用的 optim.zero_grad() # 反向传播,计算梯度参数 result_loss.backward() # 调用优化器,优化参数 optim.step() running_loss = running_loss + result_loss # 学习一轮后的损失总和,最后比较学习了20轮的损失 print(running_loss)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
输出:
VGG16使用及修改
本节学习
- 如何调用环境内置的网络结构VGG16
- 如何修改参数
VGG16 torchvison.models
项目:02_DataSet/11_VGG_pretrained.py

使用
安装scipy包(ImageNet所需)
(pytorch) D:\Desktop\workspaces\PyCharm\02_DataSet>conda install scipy
- 1

调用模型
VGG分类1000种,当数据集如CIFAR10分类为10时如何去应用模型?
- out_features改为10
- 线性层再加1000,input=1000,output=10
-

import torchvision
import os
os.environ['TORCH_HOME']='D:/DownLoad/Data/torch-model'
# train_data = torchvision.datasets.ImageNet("./dataset",split="train",transform=torchvision.transforms.ToTensor,download=True)
vgg16_false = torchvision.models.vgg16(False, True)
vgg16_true = torchvision.models.vgg16(True, True)
print(vgg16_true)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
修改参数
增加线性层
线性层再加1000,input=1000,output=10
**一、**添加层
add_module()修改网络结构
vgg16_true.add_module('add_linear',nn.Linear(1000,10))
- 1

参数module:以下的一层结构和一个序列都是module

二、在classifier里添加层
vgg16_true.classifier.add_module('add_linear',nn.Linear(1000,10))
- 1

修改已有层
已有的最后一层线性层的参数out_feature修改为10
vgg16_false.classifier[6] = nn.Linear(in_features=4096,out_features=10)
- 1


模型的保存和加载
项目:
两个对照着看
D:\Desktop\workspaces\PyCharm\02_DataSet\12_model_save.py
D:\Desktop\workspaces\PyCharm\02_DataSet\13_model_load.py
import torch import torchvision vgg16 = torchvision.models.vgg16(pretrained=False) ## 保存方式1 # 保存网络模型结构 torch.save(vgg16,"D:\\DownLoad\Data\\torch-model\\vgg16_method1.pth") ## 保存方式2 # 保存网络模型参数为字典型(官方推荐,该方式保存的文件更小) torch.save(vgg16.state_dict(),"D:\\DownLoad\Data\\torch-model\\vgg16_method2.pth") -------------------------------------------------------------------------------------- import torch import torchvision ## 保存方式1 --> 加载 model = torch.load("D:\\DownLoad\Data\\torch-model\\vgg16_method1.pth") # print(model) ## 保存方式2 --> 加载 # 加载模型参数 args_dict = torch.load("D:\\DownLoad\Data\\torch-model\\vgg16_method2.pth") # 还原网络模型,定义网络结构,导入参数 vgg_16 = torchvision.models.vgg16(pretrained=False) vgg_16.load_state_dict(args_dict) print(vgg_16)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
方式一保存形式:
方式二保存形式: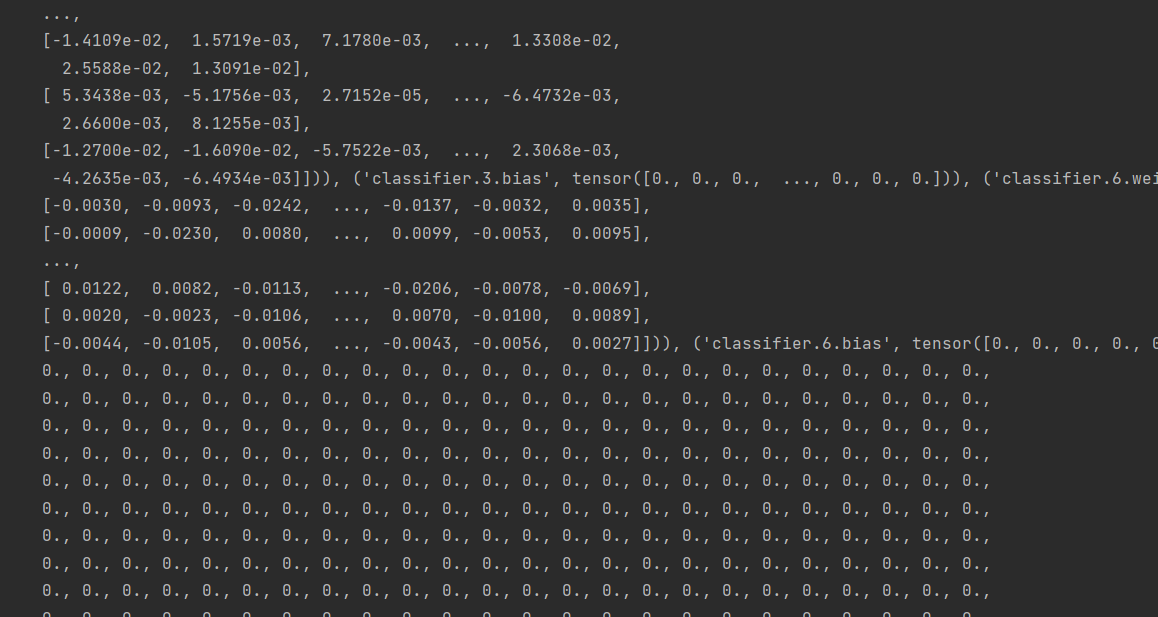
注意:
自己定义的网络结构保存后,其他文件要加载需要引入类 from file_name import class_name
完整模型训练套路
以CIFAR10数据集十分类,实操完整训练套路
**项目:02_DataSet/14_train.py ** 02_DataSet/model.py
网络结构类
import os import torch import torch.nn as nn from torch.nn import Conv2d, MaxPool2d, Flatten, Linear os.environ['TORCH_HOME'] = 'D:/DownLoad/Data/torch-model' ## 搭建神经网络 class my_nn(nn.Module): def __init__(self) -> None: super().__init__() self.module1 = nn.Sequential( Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2), MaxPool2d(2), Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2), MaxPool2d(2), Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2), MaxPool2d(2), Flatten(), Linear(1024, 64), Linear(64, 10) ) def forward(self,x): x = self.module1(x) return x if __name__ == '__main__': my_net = my_nn() ## 测试网络正确性 input = torch.ones((64, 3, 32, 32)) output = my_net(input) print(output.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
训练代码
import os import torch.optim from torch import nn import torchvision from torch.nn import Conv2d, MaxPool2d, Flatten, Linear from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter from model import XUX os.environ['TORCH_HOME'] = 'D:/DownLoad/Data/torch-model' writer = SummaryWriter("./log_14") ## 准备数据集 train_data = torchvision.datasets.CIFAR10("./dataset", train=True, transform=torchvision.transforms.ToTensor(), download=True) test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True) train_dataload = DataLoader(train_data, batch_size=64) test_dataload = DataLoader(test_data, batch_size=64) ## 数据集长度 total_train_step = len(train_data) test_data_size = len(test_data) # 字符串格式化 print("训练数据集的长度为:{}".format(total_train_step)) print("测试数据集的长度为:{}".format(test_data_size)) ## 创建网络模型 xux = XUX() ## 创建损失函数 loss_fun = nn.CrossEntropyLoss() ## 优化器 随机梯度下降 # 1e-2 = 1 * 10^(-2) = 1/100 learning_rate = 1e-2 optimizer = torch.optim.SGD(params=xux.parameters(), lr=learning_rate) ## 设置训练网络的参数 # 记录训练次数,测试次数 total_train_step = 0 total_test_step = 0 # 训练轮数 epoch = 10 for i in range(epoch): print("---------第{}轮训练开始---------".format(i+1)) ###训练步骤开始 xux.train() for data in train_dataload: ## 计算损失 imgs,targets = data outputs = xux(imgs) loss = loss_fun(outputs,targets) ## 优化 # 梯度清零 optimizer.zero_grad() # 反向传播,获取梯度参数 loss.backward() # 优化参数 optimizer.step() total_train_step = total_train_step + 1 if total_train_step % 100 == 0: print("训练次数{},Loss:{}".format(total_train_step,loss.item())) #item可将tensor型转为一个真实的数字tensor(5)-->5 writer.add_scalar("train_loss",scalar_value=loss.item(),global_step=total_train_step) ###测试步骤开始 ## 训练完一轮后在测试集进行评估,判断网络是否训练好 # 不涉及梯度,不用调优,在现有已训练完的部分进行测试 xux.eval() total_test_loss = 0 total_accuracy = 0 # 只需要测试,不需要梯度 with torch.no_grad(): for data in test_dataload: imgs,targets = data outputs = xux(imgs) loss = loss_fun(outputs, targets) total_test_loss = total_test_loss + loss.item() # 当前一组数据的正确个数 accuracy = (outputs.argmax(1) == targets).sum() # 整个数据集一轮下来的正确个数 total_accuracy = total_accuracy + accuracy # 一轮下来 print("整体测试集上的损失:{}".format(total_test_loss)) # 正确率:正确个数/测试集数据总数 print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size)) writer.add_scalar("test_loss", scalar_value=total_test_loss, global_step=total_test_step) writer.add_scalar("test_accuracy", scalar_value=total_accuracy/test_data_size, global_step=total_test_step) total_test_step = total_test_step + 1 ###每一轮的模型保存起来 torch.save(xux,"D:\\DownLoad\\Data\\xux_{}.pth".format(i)) print("模型已保存") writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
结果

Argmax
对于outputs的处理,outputs的各个类得分和targes作比较,计算出正确预测的类的百分比
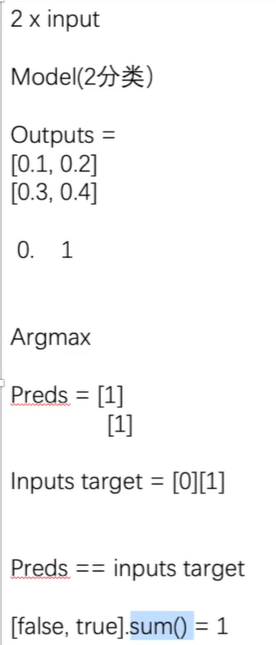
import torch
outputs = torch.Tensor([[0.1,0.2],
[0.3,0.4]])
## 1为x轴方向,0为y轴方向
# 第一行下标为1的是最大值,第二行下标为1的是最大值,输出[1,1]
print(outputs.argmax(1))
preds = outputs.argmax(1)
targets = torch.Tensor([0,1])
print(preds == targets)
# false==0,true==1 合为1代表预测正确的个数为1
print((preds == targets).sum())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

常见误区
https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module
有些代码会有如下,不是所有都需要,当网络结构有Dropout、BatchNorm层时可以加下面的代码
nn = NN()
# 调整为训练模式
nn.train()
# 调整为测试模式
nn.eval()
- 1
- 2
- 3
- 4
- 5


GPU使用
项目:02_DataSet/15_train_gpu_1.py
网络模型
数据(输入、标注)(for循环里的imgs、targets)
损失函数
.cuda()覆盖原来的值即可
查看gpu信息
(pytorch) D:\Desktop\workspaces\PyCharm\02_DataSet>nvidia-smi
- 1
法一
*.cuda()
- 1
自己的显卡
import os import torch.optim from torch import nn import torchvision from torch.nn import Conv2d, MaxPool2d, Flatten, Linear from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter os.environ['TORCH_HOME'] = 'D:/DownLoad/Data/torch-model' writer = SummaryWriter("./log_14_gpu1") ## 准备数据集 train_data = torchvision.datasets.CIFAR10("./dataset", train=True, transform=torchvision.transforms.ToTensor(), download=True) test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True) train_dataload = DataLoader(train_data, batch_size=64) test_dataload = DataLoader(test_data, batch_size=64) ## 数据集长度 total_train_step = len(train_data) test_data_size = len(test_data) # 字符串格式化 print("训练数据集的长度为:{}".format(total_train_step)) print("测试数据集的长度为:{}".format(test_data_size)) ## 创建网络模型 class XUX(nn.Module): def __init__(self) -> None: super().__init__() self.module1 = nn.Sequential( Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2), MaxPool2d(2), Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2), MaxPool2d(2), Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2), MaxPool2d(2), Flatten(), Linear(1024, 64), Linear(64, 10) ) def forward(self,x): x = self.module1(x) return x xux = XUX() # gpu加速网络 xux = xux.cuda() ## 创建损失函数 loss_fun = nn.CrossEntropyLoss() # gpu加速损失函数 loss_fun = loss_fun.cuda() ## 优化器 随机梯度下降 # 1e-2 = 1 * 10^(-2) = 1/100 learning_rate = 1e-2 optimizer = torch.optim.SGD(params=xux.parameters(), lr=learning_rate) ## 设置训练网络的参数 # 记录训练次数,测试次数 total_train_step = 0 total_test_step = 0 # 训练轮数 epoch = 10 for i in range(epoch): print("---------第{}轮训练开始---------".format(i+1)) ###训练步骤开始 xux.train() for data in train_dataload: ## 计算损失 imgs,targets = data # gpu加速 imgs = imgs.cuda() targets = targets.cuda() outputs = xux(imgs) loss = loss_fun(outputs,targets) ## 优化 # 梯度清零 optimizer.zero_grad() # 反向传播,获取梯度参数 loss.backward() # 优化参数 optimizer.step() total_train_step = total_train_step + 1 if total_train_step % 100 == 0: print("训练次数{},Loss:{}".format(total_train_step,loss.item())) #item可将tensor型转为一个真实的数字tensor(5)-->5 writer.add_scalar("train_loss",scalar_value=loss.item(),global_step=total_train_step) ###测试步骤开始 ## 训练完一轮后在测试集进行评估,判断网络是否训练好 # 不涉及梯度,不用调优,在现有已训练完的部分进行测试 xux.eval() total_test_loss = 0 total_accuracy = 0 with torch.no_grad(): for data in test_dataload: imgs,targets = data # gpu加速 imgs = imgs.cuda() targets = targets.cuda() outputs = xux(imgs) loss = loss_fun(outputs, targets) total_test_loss = total_test_loss + loss.item() # 当前一组数据的正确个数 accuracy = (outputs.argmax(1) == targets).sum() # 整个数据集一轮下来的正确个数 total_accuracy = total_accuracy + accuracy # 一轮下来 print("整体测试集上的损失:{}".format(total_test_loss)) # 正确率:正确个数/测试集数据总数 print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size)) writer.add_scalar("test_loss", scalar_value=total_test_loss, global_step=total_test_step) writer.add_scalar("test_accuracy", scalar_value=total_accuracy/test_data_size, global_step=total_test_step) total_test_step = total_test_step + 1 ###每一轮的模型保存起来 torch.save(xux,"D:\\DownLoad\\Data\\xux_{}.pth".format(i)) print("模型已保存") writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
google的显卡
https://colab.research.google.com/drive/1vRYFGnep7gh63AQ1cjZQNqCDom4xR6tP


代码复制可直接跑

法二
device = torch.device("cpu")
*.to(device)
- 1
- 2
- 3
- 4

