
- 12021-03-07_wxid微信号在线转换
- 2实用篇| huggingface网络不通_hugging face api requests.exceptions.connectionerr
- 3Android系统安全权限
- 4雷达模块开发学习教程(一)——检测人员信息_雷达软件开发的全过程
- 5Java编程:排序算法——基数排序
- 6ZBar源码分析——video.c(二) | 2021SC@SDUSC_zbar y800
- 7Springboot 多数据源 dynamic-datasource动态添加移除数据源_dynamicdatasource
- 8怎么将多张图片合成一个pdf文件_ps怎么把多张图片合成一个pdf
- 9[trouble-shooting]android 无法启动X86模式虚拟机的问题解决。
- 10开源与闭源:数字时代大模型之辩
【AI】文本转语音 变声 音色克隆 数字人音视频口型同步AI应用_克隆音色,自动匹配视频口型
赞
踩
文本转语音
项目地址:https://github.com/coqui-ai/TTS
环境安装:
- 下载项目;
- 安装Python,安装项目依赖:
pip install TTS1. 下载安装AI模型:
https://github.com/facebookresearch/fairseq/tree/main/examples/mms
模型文件放到:C:\Users\Administrator\AppData\Local\tts
2. 将文本转换为语音:
tts --text “要转换的文本内容” --model_name “指定语音模型” --out_path .\outFile.wav
语音模型可通过命令tts –list_models列出
示例(使用中文语音模型):
tts --text "你好,中文。" --model_name "tts_models/zh-CN/baker/tacotron2-DDC-GST" --out_path .\test.wav3. 自定义人声:
就是给定一段语音,生成语音的音色就会与给定语音相似。也就是自定义人声。
自定义人声需要依赖xtts模型,下载地址:https://huggingface.co/coqui/XTTS-v2/tree/main
也可以通过以下命令行下载:
- git lfs install
- git clone https://huggingface.co/coqui/XTTS-v2
下载的模型文件必须放到特定文件夹:C:\Users\Administrator\AppData\Local\tts\tts_models--multilingual--multi-dataset--xtts_v2
使用以下命令生成自定义人声的语音:
tts --model_name tts_models/multilingual/multi-dataset/xtts_v2 --language_idx zh-cn --speaker_wav ./out/output.wav --text "感谢榜一大哥,王思春送来的一发火箭。" --out_path ./out/ai_output.wav语音转语音(变声)
项目地址:https://github.com/voicepaw/so-vits-svc-fork
1. 环境安装:
- 下载项目;
- 安装依赖:pip install –r requirements.txt
- 下载语音模型:
https://huggingface.co/models?search=so-vits-svc
https://civitai.com/?query=so-vits-svc
模型存放目录结构configs/模型文件.pth;configs/44k/config.json
2. 使用方法:
1. GUI使用:
命令: svc gui打开UI界面
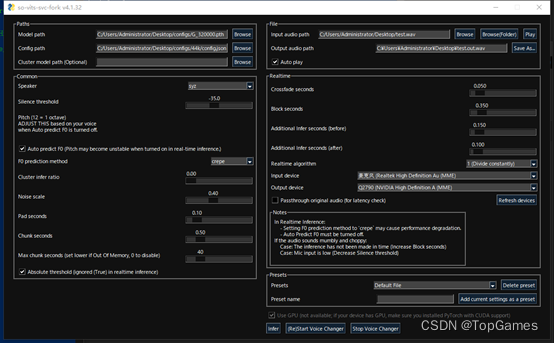
选择模型文件、模型配置文件、原语音文件wav;
点击Infer按钮生成语音文件;
2. 使用命令行:
svc infer C:\Users\Administrator\Desktop\test.wav -m "C:\Users\Administrator\Desktop\configs"
视频同步语音口型
项目地址:https://github.com/OpenTalker/video-retalking
1. 环境安装:
- 下载项目;
- 安装conda:Index of /anaconda/miniconda/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
- 使用conda创建python环境:
conda create -n video_retalking python=3.8
conda activate video_retalking
- 安装依赖:
conda install ffmpeg
pip install -r requirements.txt在项目工程下新建checkpoints文件夹并将模型全部文件放入文件夹;
2. 使用方法:
.\inference --face 3.mp4 --audio D:\Workspace\TTS-0.21.3\test.wav --outfile C:\Users\Administrator\Desktop\out_3.mp4
