
Redis也能玩向量:基于Tair Vector实现图文多模态检索_redis 向量检索
赞
踩
本文中提到的支持向量检索的数据库Tair,目前在阿里云可免费使用3个月,领取方式请点击:
本文介绍基于Tair Vector和CLIP实现实时高性能图文多模态检索的解决方案。
背景信息
在互联网中,大量信息(例如图片、文本等)通常以非结构化的形式存在。达摩院的CLIP开源模型内置了Text transformer、ResNet等模型,支持对图片、文本等非结构化数据进行特征提取,并解析成结构化数据。
您可以先通过CLIP模型将图片、文档等数据预处理,然后将CLIP的预处理结果存入Tair中,根据Vector提供的近邻检索功能,实现高效的图文多模态检索。更多关于Tair Vector的信息,请参见Vector。
方案概述
-
下载图片数据。
本示例使用的测试数据:
-
图片:为开源的宠物图片数据集,包含7000多张各种形态的宠物图片。
-
文本:“狗”、“白色的狗”和“奔跑的白色的狗”。
-
-
连接Tair实例,具体实现可参见示例代码中的
get_tair函数。 -
在Tair中分别为图片(Images)和文字(Texts)创建向量索引,具体实现可参见示例代码中的
create_index函数。 -
写入图片和文本数据。
通过CLIP模型对图片、文本数据进行预处理,并通过Vector的TVS.HSET命令,将其名称和其特征信息存入Tair中。具体实现可参见示例代码中的
insert_images函数(写入图片)和upsert_text函数(写入文本)。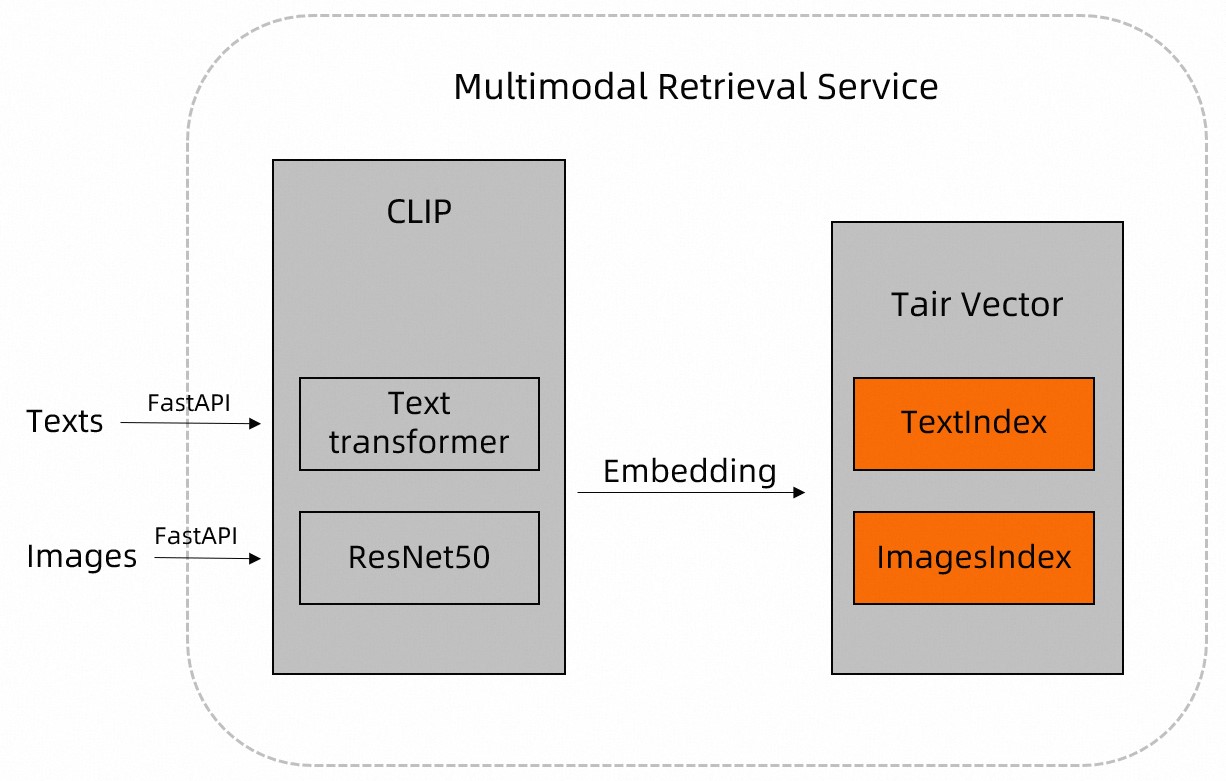
-
进行多模态查询。
-
以文搜图
通过CLIP模型将待查询的文本内容进行预处理,然后通过Vector的TVS.KNNSEARCH命令,查询Tair数据库与该文本描述最为相似的图片。具体实现可参见示例代码中的
query_images_by_text函数。 -
以图搜文
通过CLIP模型将待查询的图片内容进行预处理,然后通过Vector的TVS.KNNSEARCH命令,查询Tair数据库中与该图片最为吻合的文本。具体实现可参见示例代码中的
query_texts_by_image函数。
-
查询的文本或图片无需存入TairVector中。
-
TVS.KNNSEARCH支持指定返回的结果数量(
topK),返回的相似距离(distance)越小,表示相似度越高。
-
示例代码
本示例的Python版本为3.8,且需安装Tair-py、torch、Image、pylab、plt、CLIP等依赖,其中Tair-py的快捷安装命令为:pip3 install tair。
- # -*- coding: utf-8 -*-
- # !/usr/bin/env python
- from tair import Tair
- from tair.tairvector import DistanceMetric
- from tair import ResponseError
-
- from typing import List
- import torch
- from PIL import Image
- import pylab
- from matplotlib import pyplot as plt
- import os
- import cn_clip.clip as clip
- from cn_clip.clip import available_models
-
-
- def get_tair() -> Tair:
- """
- 该方法用于连接Tair实例。
- * host:Tair实例连接地址。
- * port:Tair实例的端口号,默认为6379。
- * password:Tair实例的密码(默认账号)。若通过自定义账号连接,则密码格式为“username:password”。
- """
- tair: Tair = Tair(
- host="r-8vbehg90y9rlk9****pd.redis.rds.aliyuncs.com",
- port=6379,
- db=0,
- password="D******3",
- decode_responses=True
- )
- return tair
-
-
- def create_index():
- """
- 创建存储图片、文本向量的Vector索引:
- * 图片Key名称为"index_images"、文本Key名称为"index_texts"。
- * 向量维度为1024。
- * 计算向量距离函数为IP。
- * 索引算法为HNSW。
- """
- ret = tair.tvs_get_index("index_images")
- if ret is None:
- tair.tvs_create_index("index_images", 1024, distance_type="IP",
- index_type="HNSW")
- ret = tair.tvs_get_index("index_texts")
- if ret is None:
- tair.tvs_create_index("index_texts", 1024, distance_type="IP",
- index_type="HNSW")
-
-
- def insert_images(image_dir):
- """
- 您需要输入图片的路径,该方法会自动遍历路径下的图片文件。
- 同时,该方法会调用extract_image_features方法(通过CLIP模型对图片文件进行预处理,并返回图片的特征信息),并行将返回的特征信息存入TairVector中。
- 存入Tair的格式为:
- * 向量索引名称为“index_images”(固定)。
- * Key为图片路径及其文件名,例如“test/images/boxer_18.jpg”。
- * 特征信息为1024维向量。
- """
- file_names = [f for f in os.listdir(image_dir) if (f.endswith('.jpg') or f.endswith('.jpeg'))]
- for file_name in file_names:
- image_feature = extract_image_features(image_dir + "/" + file_name)
- tair.tvs_hset("index_images", image_dir + "/" + file_name, image_feature)
-
-
- def extract_image_features(img_name):
- """
- 该方法将通过CLIP模型对图片文件进行预处理,并返回图片的特征信息(1024维向量)。
- """
- image_data = Image.open(img_name).convert("RGB")
- infer_data = preprocess(image_data)
- infer_data = infer_data.unsqueeze(0).to("cuda")
- with torch.no_grad():
- image_features = model.encode_image(infer_data)
- image_features /= image_features.norm(dim=-1, keepdim=True)
- return image_features.cpu().numpy()[0] # [1, 1024]
-
-
- def upsert_text(text):
- """
- 您需要输入需存储的文本,该方法会调用extract_text_features方法(通过CLIP模型对文本进行预处理,并返回文本的特征信息),并行将返回的特征信息存入TairVector中。
- 存入Tair的格式为:
- * 向量索引名称为“index_texts”(固定)。
- * Key为文本内容,例如“奔跑的狗”。
- * 特征信息为1024维向量。
- """
- text_features = extract_text_features(text)
- tair.tvs_hset("index_texts", text, text_features)
-
-
- def extract_text_features(text):
- """
- 该方法将通过CLIP模型对文本进行预处理,并返回文本的特征信息(1024维向量)。
- """
- text_data = clip.tokenize([text]).to("cuda")
- with torch.no_grad():
- text_features = model.encode_text(text_data)
- text_features /= text_features.norm(dim=-1, keepdim=True)
- return text_features.cpu().numpy()[0] # [1, 1024]
-
-
- def query_images_by_text(text, topK):
- """
- 该方法将用于以文搜图。
- 您需要输入待搜索的文本内容(text)和返回的结果数量(topK)。
- 该方法会通过CLIP 模型将待查询的文本内容进行预处理,然后通过Vector的TVS.KNNSEARCH命令,查询Tair数据库中与该文本描述最为相似的图片。
- 将返回目标图片的Key名称和相似距离(distance),其中相似距离(distance)越小,表示相似度越高。
- """
- text_feature = extract_text_features(text)
- result = tair.tvs_knnsearch("index_images", topK, text_feature)
- for k, s in result:
- print(f'key : {k}, distance : {s}')
- img = Image.open(k.decode('utf-8'))
- plt.imshow(img)
- pylab.show()
-
-
- def query_texts_by_image(image_path, topK=3):
- """
- 该方法将用于以图搜文。
- 您需要输入待查询图片的路径和返回的结果数量(topK)。
- 该方法会通过CLIP 模型将待查询的图片内容进行预处理,然后通过Vector的TVS.KNNSEARCH命令,查询Tair数据库中与该图片最为吻合的文本。
- 将返回目标文本的Key名称和相似距离(distance),其中相似距离(distance)越小,表示相似度越高。
- """
- image_feature = extract_image_features(image_path)
- result = tair.tvs_knnsearch("index_texts", topK, image_feature)
- for k, s in result:
- print(f'text : {k}, distance : {s}')
-
- if __name__ == "__main__":
- # 连接Tair数据库,并分别创建存储图片和文本的向量索引。
- tair = get_tair()
- create_index()
- # 加载Chinese-CLIP模型。
- model, preprocess = clip.load_from_name("RN50", device="cuda", download_root="./")
- model.eval()
-
- # 例如宠物图片数据集的路径为“/home/CLIP_Demo”,写入图片数据。
- insert_images("/home/CLIP_Demo")
- # 写入文本示例数据("狗"、"白色的狗"、"奔跑的白色的狗")。
- upsert_text("狗")
- upsert_text("白色的狗")
- upsert_text("奔跑的白色的狗")
-
- # 以文搜图,查询最符合文本"奔跑的狗"的三张图。
- query_images_by_text("奔跑的狗", 3)
- # 以图搜文,指定图片路径,查询比较符合图片描述的文本。
- query_texts_by_image("/home/CLIP_Demo/boxer_18.jpg",3)

结果展示
-
以文搜图,查询最符合文本"奔跑的狗"的三张图,结果如下。
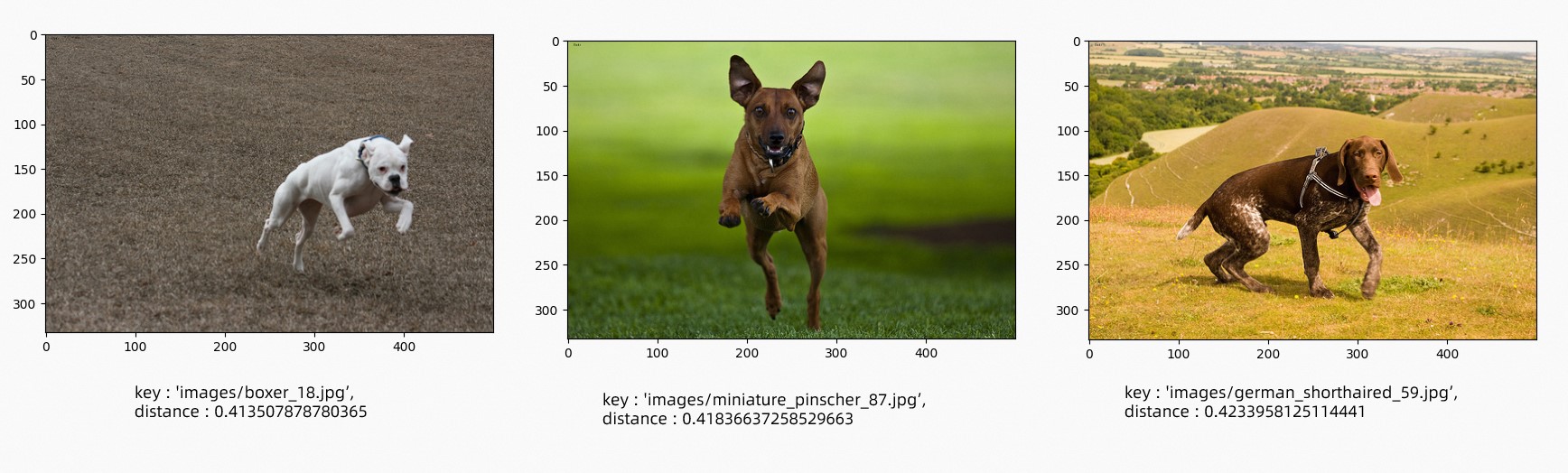
-
以图搜文,指定查询图片如下。

查询结果如下。
- {
- "results":[
- {
- "text":"奔跑的白色的狗”,
- "distance": "0.4052203893661499"
- },
- {
- "text":"白色的狗",
- "distance": "0.44666868448257446"
- },
- {
- "text":"狗",
- "distance": "0.4553511142730713"
- }
- ]
- }
总结
Tair作为纯内存数据库,内置了HNSW等索引算法加快了检索的速度。
采用CLIP与Tair Vector进行多模态检索,既可以进行以文搜图(例如商品推荐场景),也可以进行以图搜文(例如写作场景)。同时,您也可以采用其他的模型取代CLIP模型,实现以文本搜索视频、音频等更多模态的检索功能。
本文中提到的支持向量检索的数据库Tair,目前在阿里云可免费使用3个月,领取方式请点击:

