- 1黑盒测试案例设计技术_网上银行支付交易系统的基本流和备选流的描述
- 2技术分享 某下一代防火墙远程命令执行漏洞分析及防护绕过_深信服下一代防火墙ngaf login远程命令执行漏洞_博达下一代防火墙 存在远程代码执行
- 3pl/sql developer 编码格式设置_plsql developer 配置编码格式utf-8
- 4版本控制工具--git_git版本控制工具的优缺点
- 5VMware虚拟机屏幕大小(屏幕分辨率)调整_vmix调整输出分辨率
- 6微信小程序自定义tabbar_微信小程序 自定义 tabbar
- 7邓俊辉数据结构学习笔记3-二叉树_b-ary tree
- 8《统计学简易速速上手小册》第5章:回归分析(2024 最新版)
- 9AI绘画专栏之Stablediffusion webui Controlnet SDXL 插件之segment-anything(40)
- 10DeepSpeed使用体会_deepspeed评测
tera term 使用方法_不同文本向量化方法应用于聚类任务效果对比-再论文本向量化不靠谱...
赞
踩

如果基于word2vec,transformer真的那么成功,那么在聚类上的表现应该也很突出才对,做了下边的聚类实验后,我们就知道为啥那些牛上天的模型都不做聚类评测任务的原因,因为效果实在拿不出手,如果聚类不行,那么分类也好不到哪儿去,全指着最后一层softmax分类,解决不了实质问题,那跟用逻辑回归有啥区别呢,速度还不行,给维度意义也不知道,如果嵌入表示真的那么行,那些利用矩阵分解做特征表示的方法,早就成功了,现在已然没人提那些方法了,各维度的词语都不知道是啥了,就别再美其名曰语义了。。。这里,我们分别用词袋模型表示法、word2vec表示法、universal sentence embedding表示法作为向量化方法,在聚类任务上评测效果,有关词袋表示法参考:https://zhuanlan.zhihu.com/p/70314114,有关word2vec表示法参考:https://zhuanlan.zhihu.com/p/80637885,有关universal sentence embedding参考:https://zhuanlan.zhihu.com/p/137219778。
1 聚类评价指标
(1)轮廓系数
详细参考:https://zhuanlan.zhihu.com/p/108163834
特点:基于距离度量,反映簇内紧密度,簇间分散度。
(2)调整兰德系数
详细参考:https://zhuanlan.zhihu.com/p/145856959
特点:基于RI指数,反映实例类别划分与聚类划分的重叠程度。
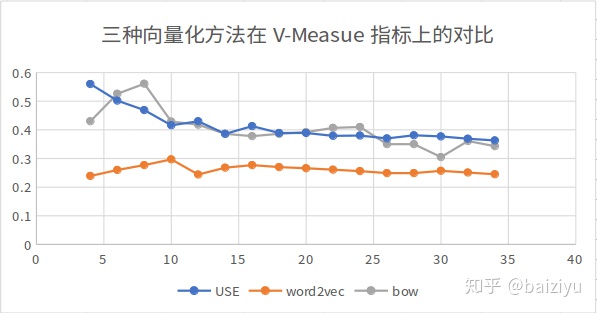
(3)V-Measure
详细参考:https://zhuanlan.zhihu.com/p/145989213
特点:基于条件熵,反映实例类别划分与聚类划分的重叠程度。
2. 实验设置
(1)语料
- 英语:sklearn自带的20newsgroups新闻语料,有关新闻语料的加载使用参考https://zhuanlan.zhihu.com/p/127132840,这里跟官网聚类示例一样,选择4个类目的数据。
- 汉语:社交媒体语料,22个类目,有关数据加载参考:https://zhuanlan.zhihu.com/p/94456813。

(2)效果对比
这里就放sklearn的20newsgroups的实验结果吧