
- 1谷歌前CEO Eric Schmidt:这就是人工智能未来改变科学研究的方式
- 2Docker Compose 通信超时问题及其解决方案_docker compose 超时
- 3OpenCV——彩色空间互转(python实现和c++实现)_实验一色彩空间转换与直方图处理e3、配置python+opencv的开发环境。“ 二、编写一
- 4Redis面试总结_mysql里有2000w数据,redis中只存20w的数据
- 5adb---调试连接设备_adb连接设备
- 6【数据结构】第十五弹---C语言实现直接插入排序
- 7重新定义大模型的学习方式:为什么算力和数据胜过代码?_学普通算法好 还是大模型算法好
- 8shiro反序列化漏洞原理分析及漏洞复现(Shiro-550/Shiro-721反序列化)_shiro550和shiro721的区别
- 92024年免费无限制使用的多功能ChatGPT中文平台_免费gpt
- 10华为OD机考题HJ1 字符串最后一个单词的长度
AIGC系列之:升级版的Stable Diffusion之SDXL介绍_sd xl base 1.0.safetensors[31e35c80fc]
赞
踩
目录
AIGC工具对比
在目前的三大新兴文本转图像模型中,Stable Diffusion诞生得最晚,但由于拥有发展良好的开源社区,它的用户关注度和应用广度都超越Midjourney和DALL-E。
DALL-E
2021 年 1 月,OpenAI 推出了 DALL-E 模型,通过 120 亿参数版本的 GPT-3 Transformer 模型来理解自然语言输入并生成相应的图片。但是它的推出主要用于研究,所以访问权限仅限于小部分测试版用户。这个模型不稳定对于细节理解处理不完善,且会出现严重的逻辑或者事实错误,但是作为开创者,还是得专门提出来的。
在发布 DALL-E 时还发布了 CLIP (Contrastive Language-Image Pre-training,对比图文预训练)。CLIP 是一种神经网络,为输入的图像返回最佳的标题。它所做的事情与 DALL-E 所做的相反 —— 它是将图像转换为文本,而 DALL-E 是将文本转换为图像。引入 CLIP 的目的是为了学习物体的视觉和文字表示之间的联系。
2022 年 4 月,OpenAI 发布了新版本的 DALL-E 2 ,它是 DALL-E 的升级版本,另外能对所生成的图像进行二次编辑,现在即使是新用户也需要充值才能生成新图。
2023年的9月21日,Open Ai发布了其dall-e系列中的最新一代产品,DALL-3相比于上一代的dall-2来说,进行了一次全方面的升级。但dall-3可以通过只通过文字描述来完美生成图片,完全通过文字来控制画面,这代表着,用户再也不需要去学习如何构建关键词,只需要一段语言描述就可以生成一张完全符合这段语言描述的画面。这对目前的AI绘画来说将会是一个巨大的冲击,同时也代表了接下来AI绘画的方向。
MidJourney
MidJourney 的 v1 是 2022 年 2 月发布的,它火出圈是由于 22 年 7 月份的 v3 版本。它的特点是综合能力比较全面,艺术性很强,非常像艺术家制作的作品,另外图像生成速度更快,早期主要是很多艺术家会借助 Midjourney 作为创作灵感。另外,因为 Midjourney 搭载在 Discord 频道上,所以有非常良好的社区讨论环境和用户基础。
第二次火其实就是今年 3 月份发布 V5, 官方说这个版本在生成图像的人物真实程度、手指细节等方面都有了显著改善,并且在提示词理解的准确性、审美多样性和语言理解方面也都取得了进步。
Stable Diffusion
2022年7月Stable Diffusion的问世则震惊了全球,相比前辈们,Stable Diffusion已经成功的解决了细节及效率问题,通过算法迭代将AI绘图的精细度提升到了艺术品级别,并将生产效率提升到了秒级,创作所需的设备门槛也被拉到了民用水准。
2022年8月对于AI绘图来说,革命性的时刻已经来临,也得益于Stable Diffusion的开源性质,全球AI绘图产品迎来了日新月异的发展。这次AI创作大讨论,正是公众们直观地感受到了技术浪潮带来的影响,AI绘图正在走进千家万户,舆论热潮也随之而来。
2023 年 4 月,Stability AI 发布了 Beta 版本的 Stable Diffusion XL ,并提到在训练结束后参数稳定后会开源,并改善了需要输入非常长的提示词 (prompts),对于人体结构的处理有瑕疵,经常出现动作和人体结构异常。
2023年7月27日,Stability AI正式发布了下一代文生图模型—SDXL 1.0。SDXL 1.0拥有目前所有开放式图像模型中最大的参数数量,采用了创新的新架构,包括一个拥有35亿参数的基础模型和一个66亿参数的优化模型,这也是本文要介绍的重点,接下来一起看一下吧~
相关资料
论文:《SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis》
组织:Stability AI, Applied Research
论文地址:https://arxiv.org/pdf/2307.01952.pdf
代码地址:https://github.com/Stability-AI/generative-models
模型权重:https://huggingface.co/stabilit
试用地址:https://huggingface.co/spaces/google/sdxl
SDXL介绍
2023年7月27日,Stability AI正式发布了下一代文生图模型—SDXL 1.0。SDXL 1.0拥有目前所有开放式图像模型中最大的参数数量,采用了创新的新架构,包括一个拥有35亿参数的基础模型和一个66亿参数的优化模型。
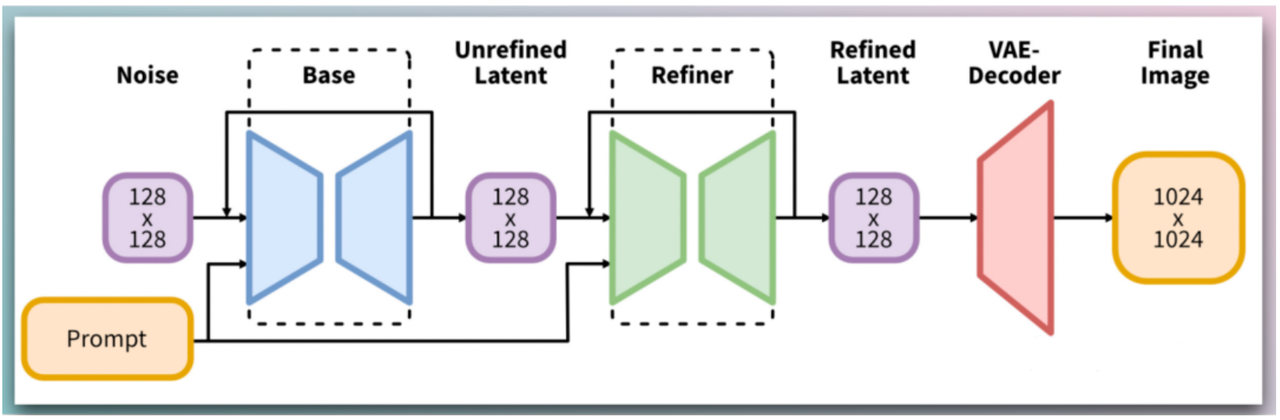
SDXL 1.0包括两种不同的模型:
sdxl-base-1.0:生成1024 x 1024图像的基本文本到图像模型。基本模型使用OpenCLIP-ViT/G和CLIP-ViT/L进行文本编码。
sdxl-refiner-1.0:一个图像到图像的模型,用于细化基本模型的潜在输出,可以生成更高保真度的图像。细化模型只使用OpenCLIP-ViT/G模型。SDXL 1.0的refiner是基于OpenCLIP-ViT/G的具有6.6B参数模型,是目前可用的最强大的开放访问图像模型之一。
对于 Stable Diffusion 的U-Net、VAE、CLIP Text Encoder三大组件都做了改进。
-
U-Net 增加 Transformer Blocks (自注意力 + 交叉注意力) 来增强特征提取和融合能力;
-
VAE 增加条件变分自编码器来提升潜在空间的表达能力;
-
CLIP Text Encoder 增加两个大小不同的编码器来提升文本理解和匹配能力。
增加单独基于 Latent 的 Refiner 模型,来提升图像的精细化程度。Refiner 模型也是一个潜在扩散模型,接收基础模型生成的图像 Latent 特征作为输入,进一步去噪和优化,使得最终输出的图像更加清晰和锐利。
设计了很多训练 Tricks,包括图像尺寸条件化策略,图像裁剪参数条件化以及多尺度训练等。这些 Tricks 可以提高模型的泛化能力和稳定性,使得模型能够适应不同的分辨率和宽高比,以及不同的图像内容和风格。
预先发布 SDXL 0.9 测试版本,基于用户使用体验和生成图片的情况,针对性增加数据集和使用 RLHF 技术优化迭代推出 SDXL 1.0 正式版。RLHF 是一种基于强化学习的图像质量评估技术,可以根据人类的偏好来调整模型的参数,使得生成图像的色彩,对比度,光线以及阴影方面更加符合人类的审美。
SDXL生图效果
SDXL的生图稳定性更好,细节更加丰富,真实,可控性比SD1.5也大大提升
生图效果1:
lora:AP-xl:1, AP, no humans, cat, realistic, animal focus, animal, blurry, simple background, whiskers, newspaper, gray background, ragdoll, wear sunglasses,
Negative prompt: (worst quality, low quality:1.4), (malformed hands:1.4),(poorly drawn hands:1.4),(mutated fingers:1.4),(extra limbs:1.35),(poorly drawn face:1.4), missing legs,(extra legs:1.4),missing arms, extra arm,ugly, huge eyes, fat, worst face,(close shot:1.1), text, watermark, blurry eyes,
Steps: 35, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 3539483990, Size: 512x512, Model hash: 31e35c80fc, Model: sd_xl_base_1.0, VAE hash: 63aeecb90f, VAE: sdxl_vae.safetensors, Lora hashes: "AP-xl: f5f7e8a091b0", Refiner: sd_xl_refiner_1.0_0.9vae [8d0ce6c016], Refiner switch at: 0.8, Version: v1.6.0-2-g4afaaf8a
Time taken: 1 min. 0.6 sec.




生图效果2:
lora:AP-xl:1, AP, no humans, dog, (sit on the toilet:1.4), (smoking in mouse and watch newspaper:1.5), realistic, animal focus, animal, blurry, simple background, whiskers, gray background, ragdoll, wear sunglasses,
Negative prompt: (worst quality, low quality:1.4), (malformed hands:1.4),(poorly drawn hands:1.4),(mutated fingers:1.4),(extra limbs:1.35),(poorly drawn face:1.4), missing legs,(extra legs:1.4),missing arms, extra arm,ugly, huge eyes, fat, worst face,(close shot:1.1), text, watermark, blurry eyes,
Steps: 36, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 1930821284, Size: 512x512, Model hash: 31e35c80fc, Model: sd_xl_base_1.0, VAE hash: 63aeecb90f, VAE: sdxl_vae.safetensors, Lora hashes: "AP-xl: f5f7e8a091b0", Refiner: sd_xl_refiner_1.0_0.9vae [8d0ce6c016], Refiner switch at: 0.8, Version: v1.6.0-2-g4afaaf8a
Time taken: 57.6 sec.




SDXL训练LoRA流程
后续还会更新一下SDXL+LoRA的生图效果,从以上效果中可以看出SDXL的生图效果比SD更加精细,效果更好,对文本的稳定性也更好。但这同时也带来了较长的生成时间,因为SDXL需要较大的步数进行采样,一般约在30步以上才能生成的比较精美。而SD一般只需要20步左右就可以生成出来。因此大家如果一直在用SD1.5或者2.0生图的可以试试SDXL,相信会有一个不一样的体会。

