
- 1xss-labs靶场通关_xsslabs通关挑战
- 2php编写网站页面_用php写一个网页页面(1),2024年最新Linux运维 MVP模式详解_php页面
- 3计算机网络(6) ICMP协议
- 4远程桌面连接出现身份验证错误解决办法_远程桌面出现身份验证错误
- 5XSS平台(四) Pikachu_pikachu平台
- 6【Java数据结构】ArrayList详解_java中的 arraylist 是什么结构
- 7一文深度剖析 ColBERT_colbert算法
- 8【华为OD机考 统一考试机试C卷】结队编程(Java题解)_某部门计划通过结队编程来进行项目开发,已知该部门有n名员工,每个员工有独一
- 9Microsoft 数据仓库架构 !_microsoft 数仓bids
- 10全网最全面最深入 剖析华为“五看三定”战略神器中的“五看”(即市场洞察)(长文干货,建议收藏)_华为的五看三定是什么
Stable Diffusion安装及入门教程(全面导引)_vram estimator
赞
踩
目录
一、Stable Diffusion基础概念
网上有许多关于SD的教程,我再出详细教程有点多此一举,不过我的教程特点是适合小白入门,顺序渐进且做好引导,会让你跳转链接去……去看别人的教程。
可别小看这一举措,有时候因为不理解概念而到处胡乱寻找资料,可是要花掉大把时间的。
所以,我的教程特点是:不教,只做导引。
1.名词解释
Checkpoint(大模型)
定义与作用:Checkpoint是Stable Diffusion中的核心组件,是预训练的大型模型,包含了丰富的图像和风格数据。它决定了生成图像的基本风格和质量,是图像生成过程的基础。
选择合适的Checkpoint:选择合适的checkpoint对于生成期望风格的图像至关重要。用户应根据自己的需求(如写实风格、漫画风格等)选择相应的checkpoint。通常,checkpoint的文件名后缀为.ckpt和.safetensors,模型大小从2GB到8GB不等。
checkpoint文件放置路径:\models\Stable-diffusion
Lora模型
定义与作用:Lora模型是一种微调技术,可以在不显著增加计算成本的情况下,调整生成图像的特定细节。它主要用于雕刻人物特征、控制画风、固定特征动作等,提高图像的细节和质量。
使用场景:Lora模型适用于需要对图像的特定部分进行微调的场景。用户可以根据需要选择是否使用Lora模型,并通过特定的触发词激活其效果。Lora模型的文件名后缀通常为.safetensors,大小在20MB到300MB不等。
Lora放置路径:\models\lora
Embedding
定义与作用:Embedding是一种特殊的文本处理技术,它允许用户通过简单的词语来代表一连串的复杂概念或属性。这种方法简化了创建复杂prompt的过程,使得用户可以更容易地控制生成图像的细节。
简化Prompt创建:通过使用embedding,用户可以将复杂的描述简化为单一或少数几个词语。例如,如果已有“皮卡丘”的embedding,用户只需输入“皮卡丘”,而不需要详细描述其特征。
embedding文件放置路径:\embedding
VAE(变分自编码器)
定义与作用:VAE是Stable Diffusion中的另一个关键组件,主要用于调整图像的色彩和细节,以达到更自然和真实的效果。它相当于给图像加载一个滤镜,修正最终输出的图片色彩。
应用方法:VAE的使用可以根据需要自动或手动进行。在某些情况下,特别是当图像出现色彩失真时,使用VAE可以显著改善图像质量。VAE文件的后缀一般为.downloading、.safetensors、.ckpt、.pt。
VAE文件的放置路径:\models\vae
ControlNet
边缘检测模型或线稿模型提取线稿(可提取参考图片线稿,或者手绘线稿),再根据提示词和风格模型对图像进行着色和风格化。 应用模型: Canny、SoftEdge、Lineart。 Canny 边缘检测: Canny 是比较常用的一种线稿提取方式,该模型能够很好的识别出图像内各对象的边缘轮廓。
2.一些概念
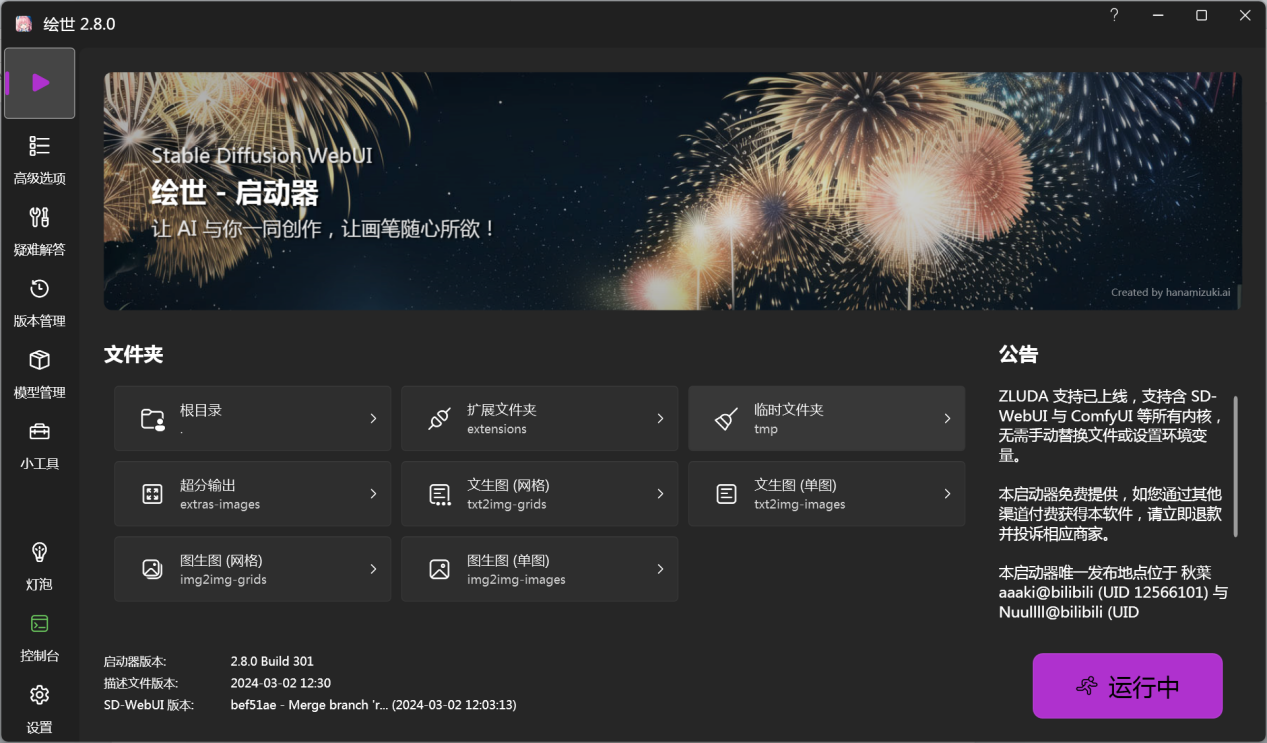
目前我们所使用的是秋叶启动器,原本SD是一系列的代码和命令行,有了WebUI版本之后才有了界面,但操作还是困难,现在有了秋叶启动器,封装了所有的功能,变成简单易操作的可视化界面,并向公众免费。
在此感恩秋叶大佬!
秋叶B站官网链接:
【AI绘画】绘世启动器正式发布!一键启动/修复/更新/模型下载管理全支持!_哔哩哔哩_bilibili
WebUI下载:AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI (github.com)
截止至今日,还有SDXL、CompyUI、forge等其它模型和UI,后面有时间再介绍。
二、下载及安装
秋叶启动器下载地址:
链接:https://pan.baidu.com/s/10oc_OtEpybeUc8fhjtUhmw?pwd=XYSD
提取码:XYSD

下载完了之后,把压缩包解开,然后点击“启动器运行依赖”的蓝色图标。
把controlnet文件夹中的文件复制到:models/ControlNet
这是 ControlNet(ControlNet是一款用于控制出图内容的可选插件)的模型。
按以上操作完成之后,点击那个二次元的图标,便可以运行。
以为这样就结束了吗?呵呵~
三、界面说明
1.绘世启动器(秋叶)
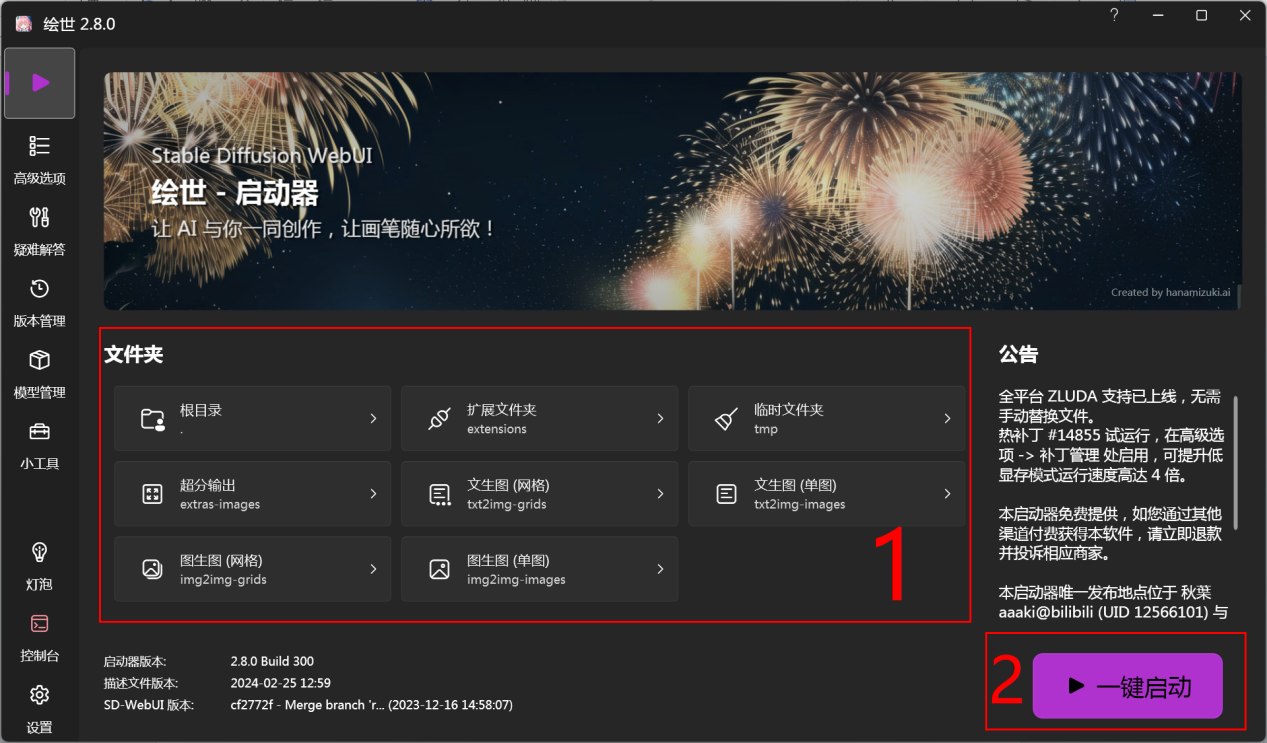
- 所有生成后文件存放目录,定期清理;
- 启动。
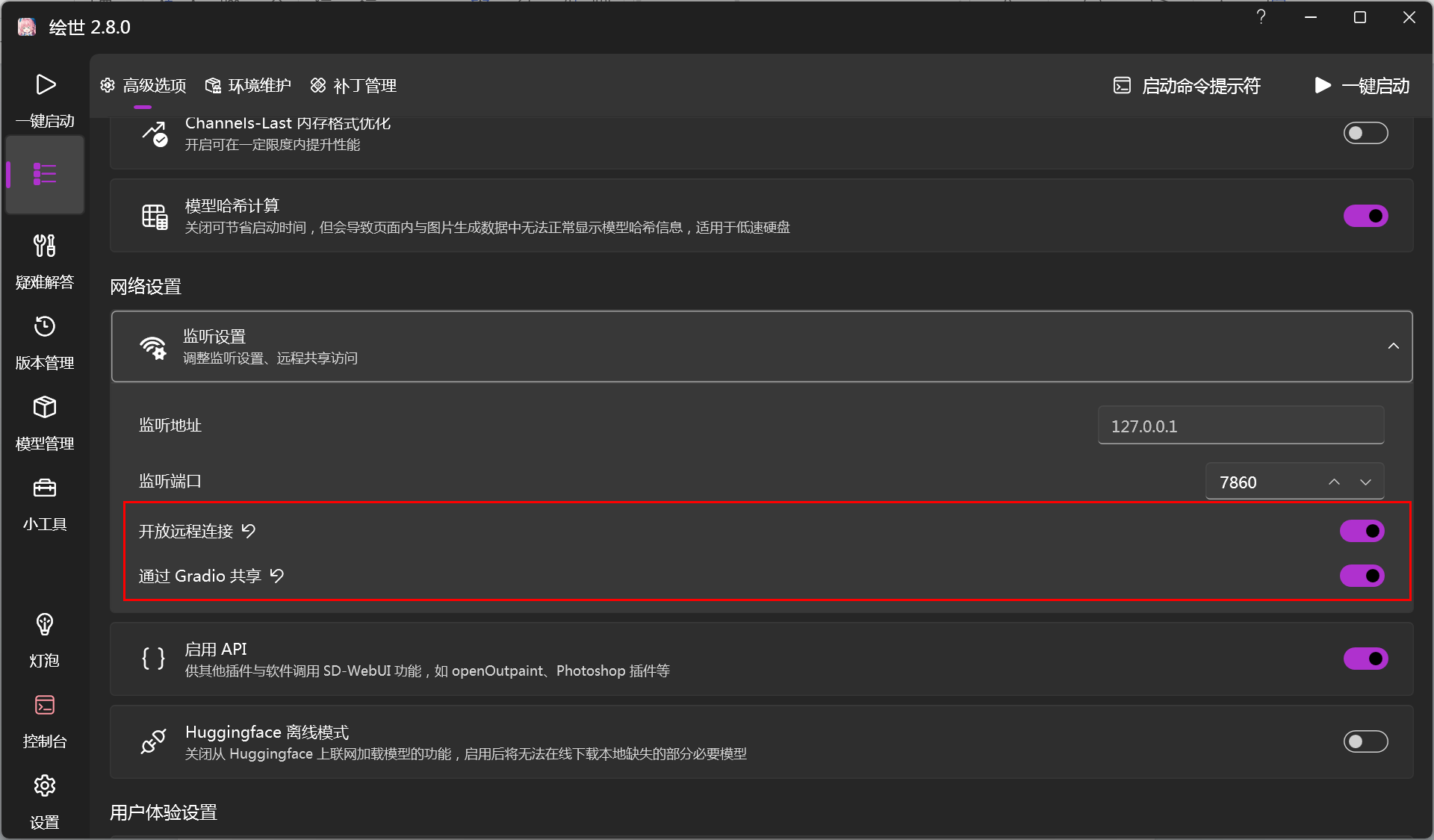
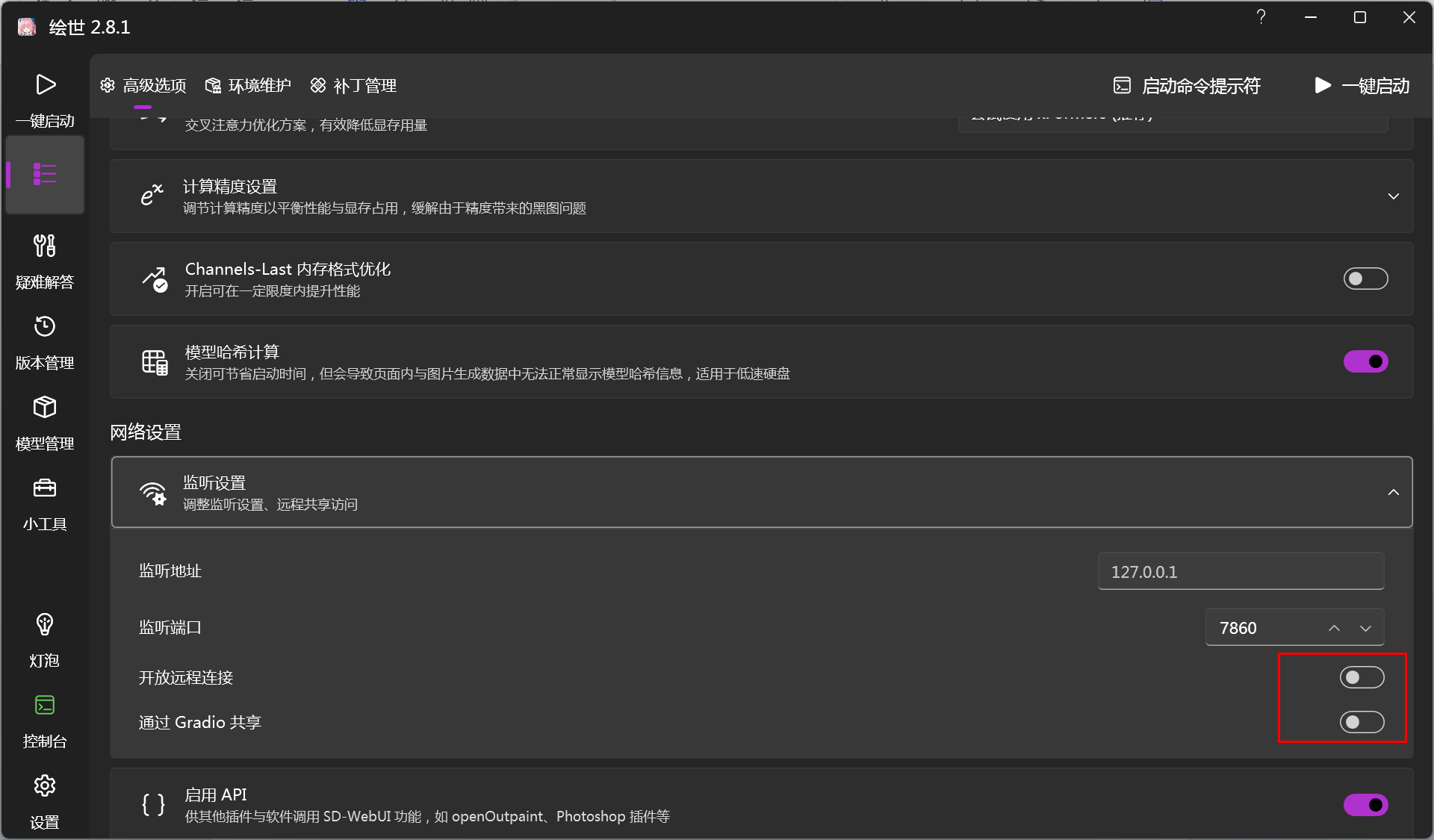
若需要在局域网应用,这两个要打开,但需要下载安装扩展时,此处要关闭。
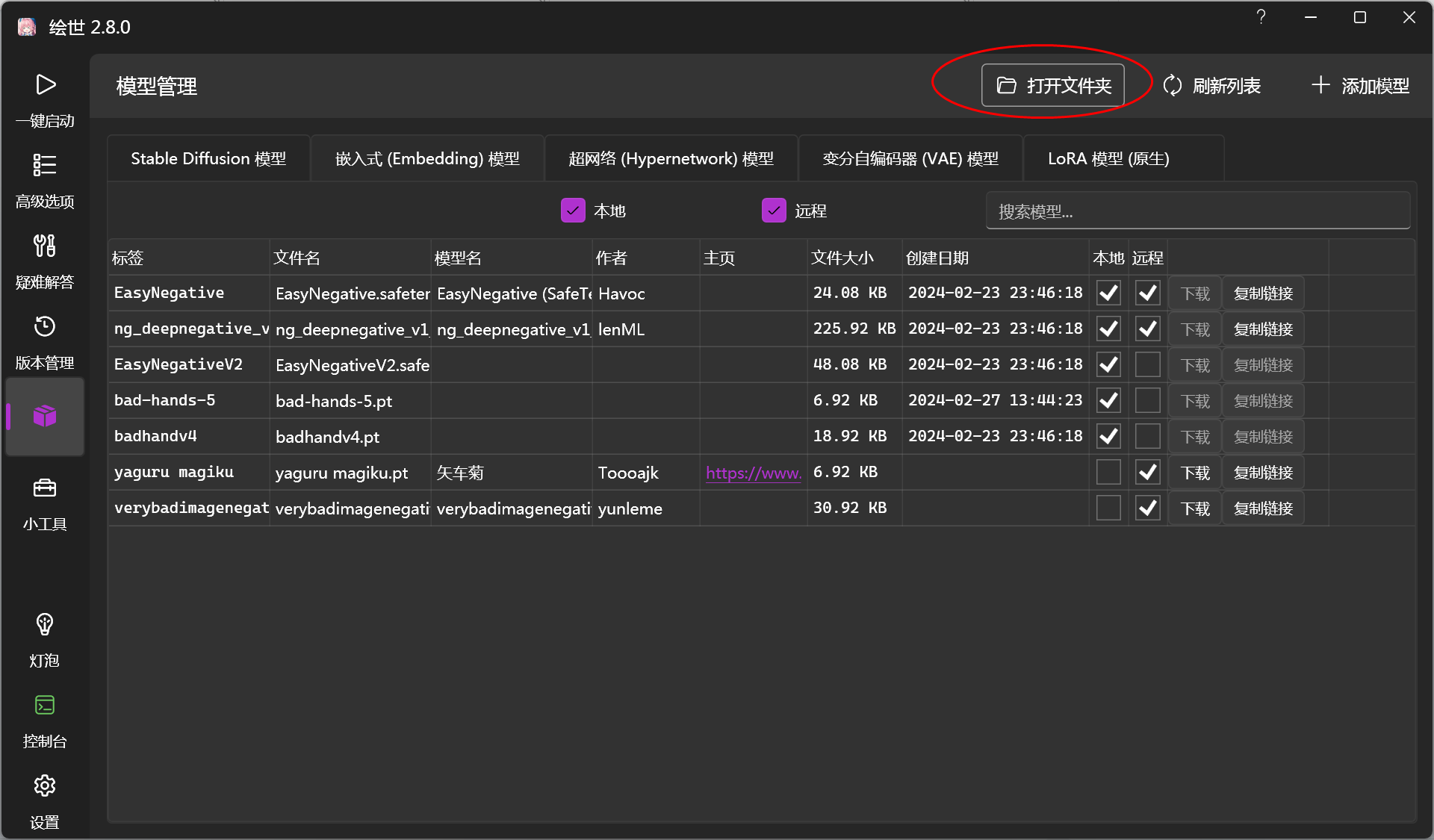
所有模型目录可在这里点击进入,如果你从其它网站下载好模型之后,可以点击右上角的“+添加模型”导入。
2.SD WebUI界面说明
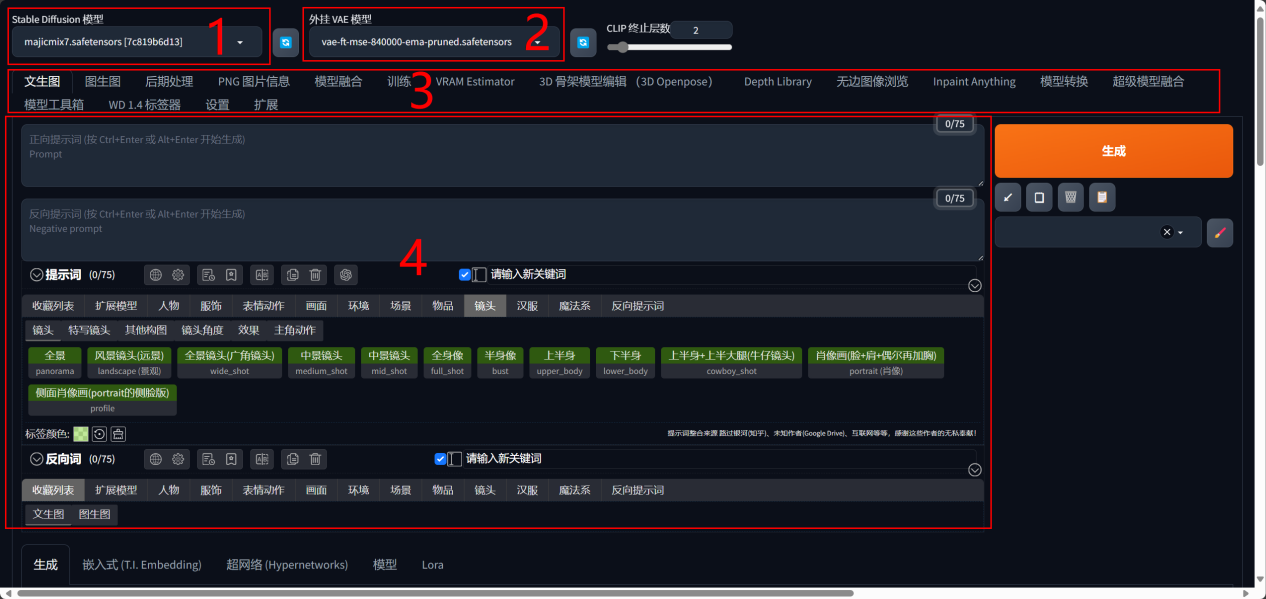
1.选择大模型,模型安装后在这里刷新;
2.VAE,默认就好;
3.导航
4.提示词文本框
现在的提示词并不复杂,输入会自动关联提示词,也可用deelp.com或有道翻译。
注意提示词先后顺序和权重。
通用反面词:
(worst quality:2),(low quality:2),(normal quality:2),lowres,bad anatomy,bad hands,text,error,missing fingers,extra digit,fewer digits,cropped,jpeg artifacts,signature,watermark,username,blurry,bad_pictures,DeepNegativeV1.x_V175T,nsfw,
nsfw是防黄设置。
如有需要,可以自行下载其它模型,以下是模型下载推荐网站:
https://civitai.com/ C站(推荐)
吐司 tusi.cn | 可在线生图的 AI 模型分享社区,还是免费的!
这里有份入门手册,特别详细:
Stable Diffusion入门修炼手册_stable diffusion checkpoint-CSDN博客
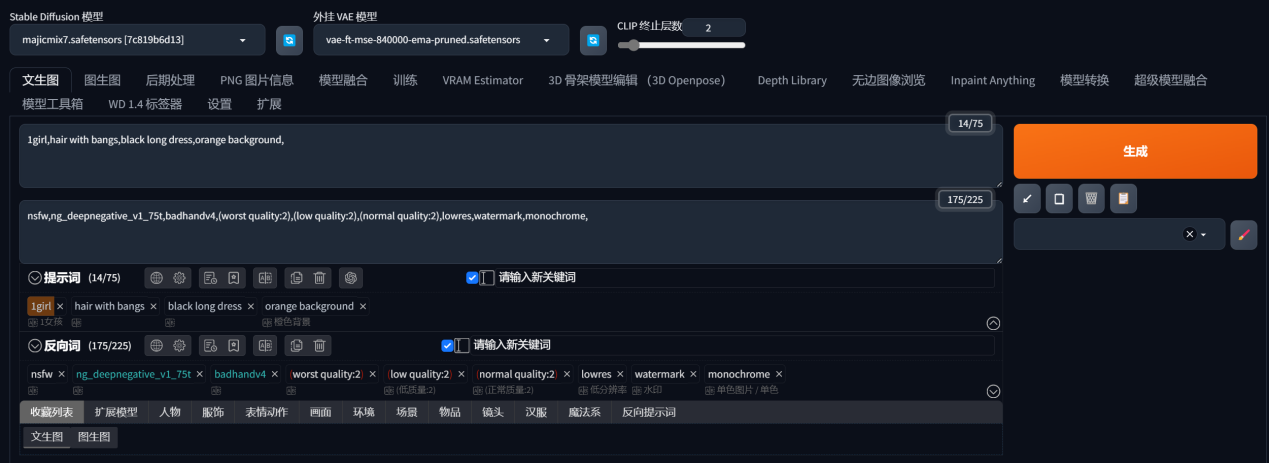
在上图中,我安装了以下这些checkpoint模型:
Detail Asian Realistic - v5.0 | Stable Diffusion Checkpoint | Civitai
AgainMix - v1.8 | Stable Diffusion Checkpoint | Civitai
majicMIXlux麦橘辉耀 - v3 | 吐司 TusiArt.com
majicMIX realistic麦橘写实 - v7 | 吐司 TusiArt.com
我常用的是majic v7这个模型,你可以按照你自己的需要去下载。
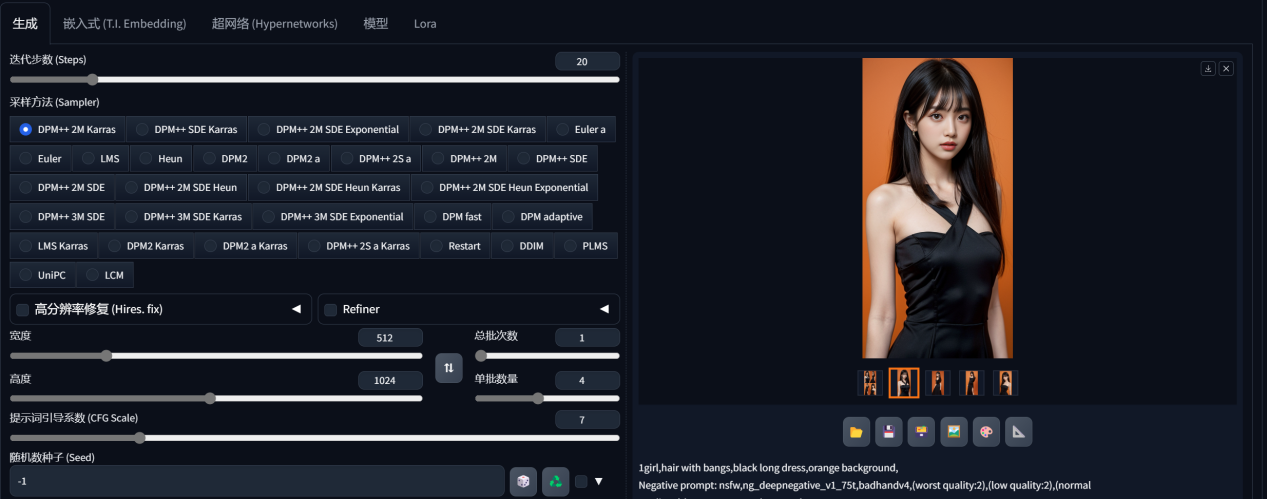
图片变化公式:迭代步数*重绘幅度,这两个数调越大变化越大。
采样方式默认就好DPM++ 2M Karras。
提示词引导系数:默认7,但很多情况下需要调高提示词,否则会生成怪物或不理想图片。
随机数种子:在未生成之前不存在种子,生成后觉得好的图片想要延伸其它,可以保留种子再生成,-1即是随机。
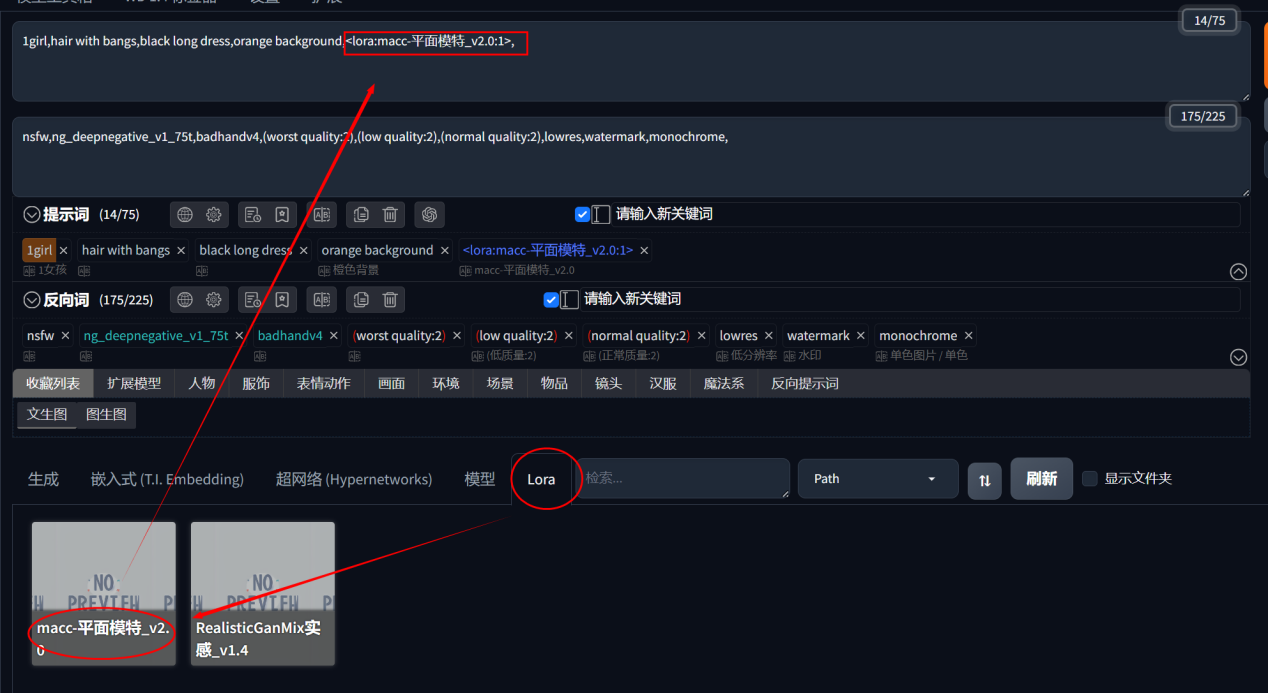
如果你要添加Lora,就按图中操作,在正向提示词文本框就会自动生成一组提示词。
<lora:macc-平面模特_v2.0:1>最后的数字是调整权重,比如:
<lora:macc-平面模特_v2.0:1.2>
再往下看,你会发现有很多选项,这些都是插件:
如果你按我上面说的安装,那么有些插件你是没有的,你还要再补充,当然,有些你并不需要。
3.插件安装方法

从这里可以看到各种扩展,可安装也可删除。
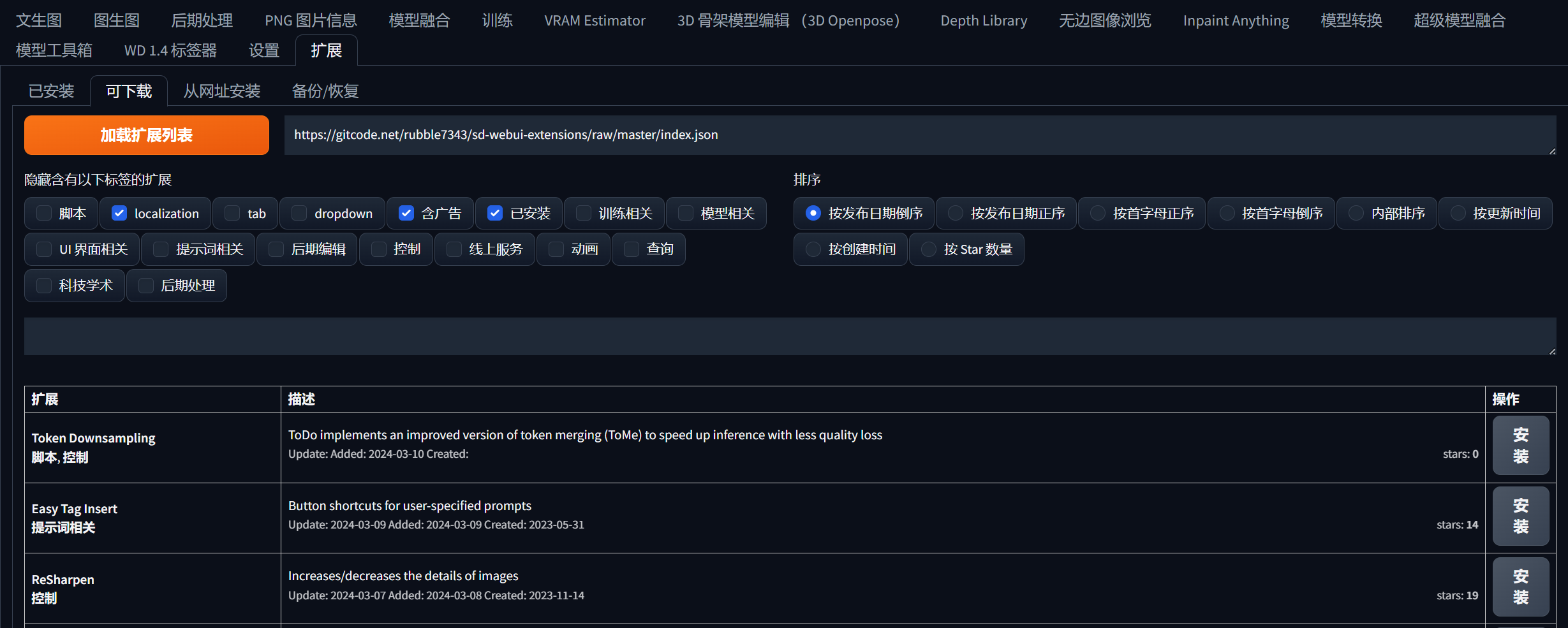
点击“可下载”再点击“加载扩展列表”可以看到插件列表。
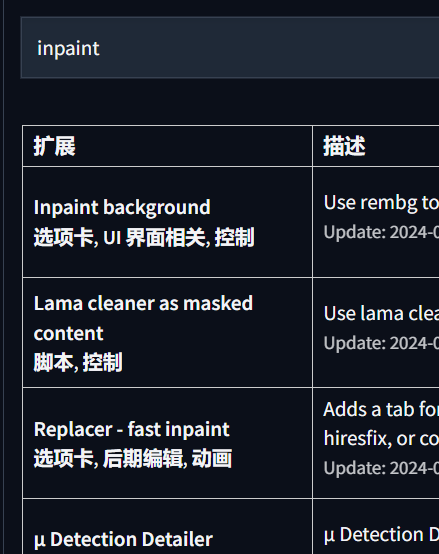
在文本框中也可以输入插件名进行安装。
如果你在别的地方找到一些插件,列表中没有的,可以点击“从网址安装”,输入代码托管平台的网址即可安装。
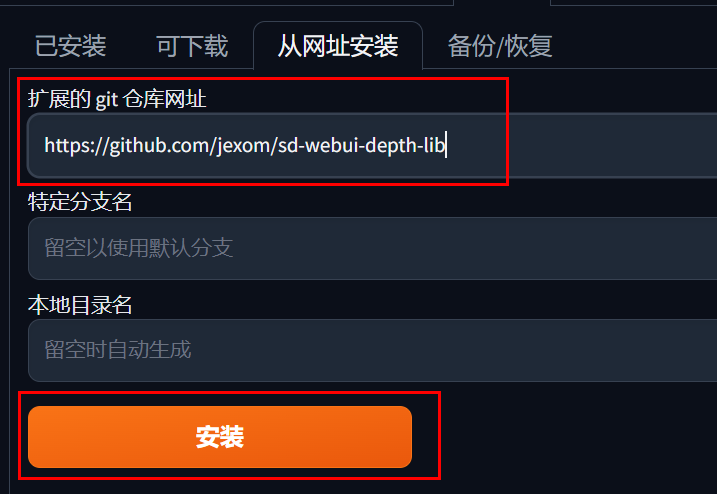
注意:如果处于共享网络可访问状态,是无法安装的,要先退出后去启动器那边把共享网络关掉:
4.如何在其它的机器访问你的SD?
有两种方式,一种是局域网内访问你的SD,一种是通过内网穿透后其它网络也可以访问。
这里说说局域网的。
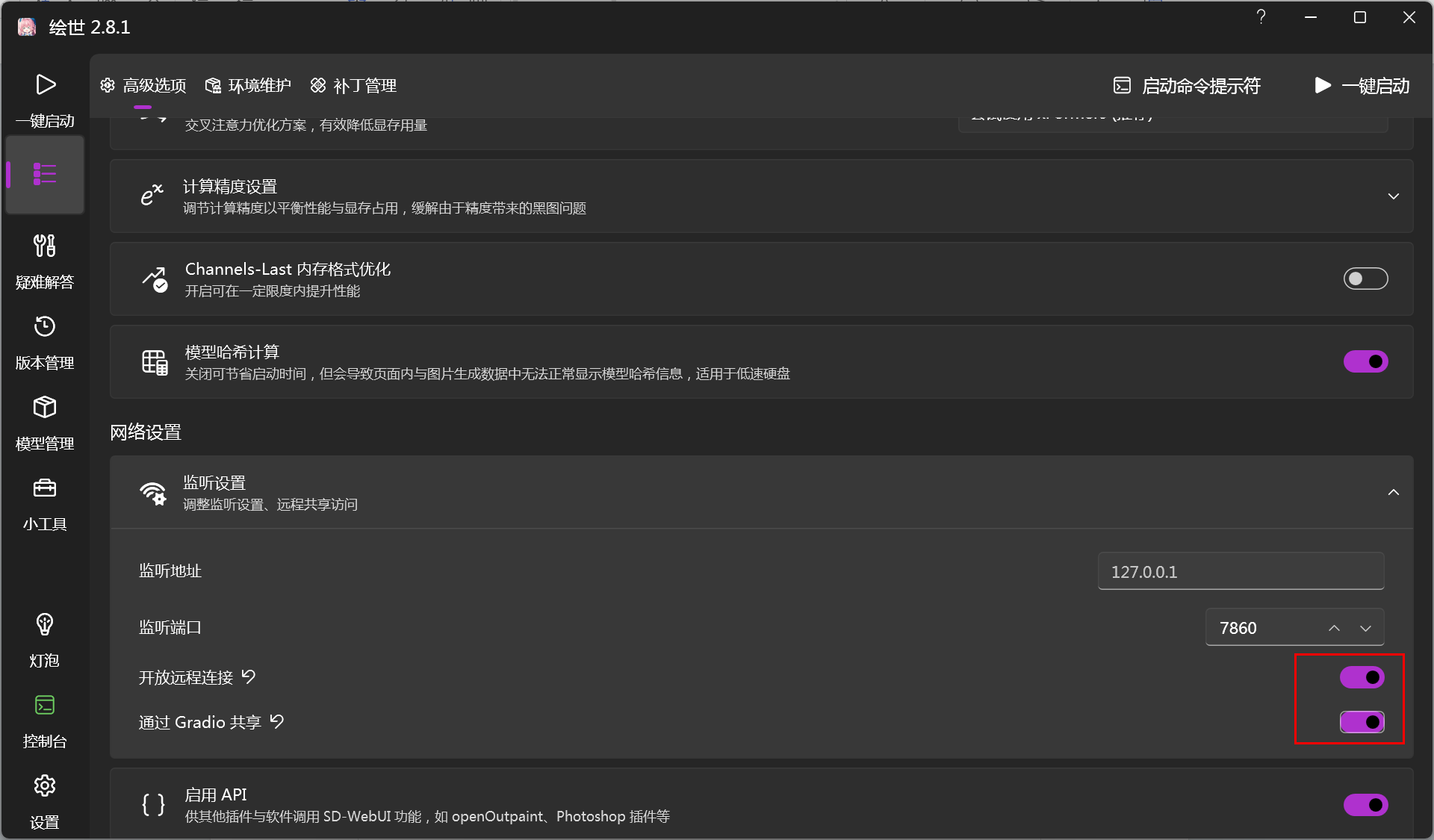
在启动器的主界面把这两个打开。
然后键盘按下Win+R,输入cmd进行命令行模式,在命令行中输入ipconfig,获得本机IP地址。
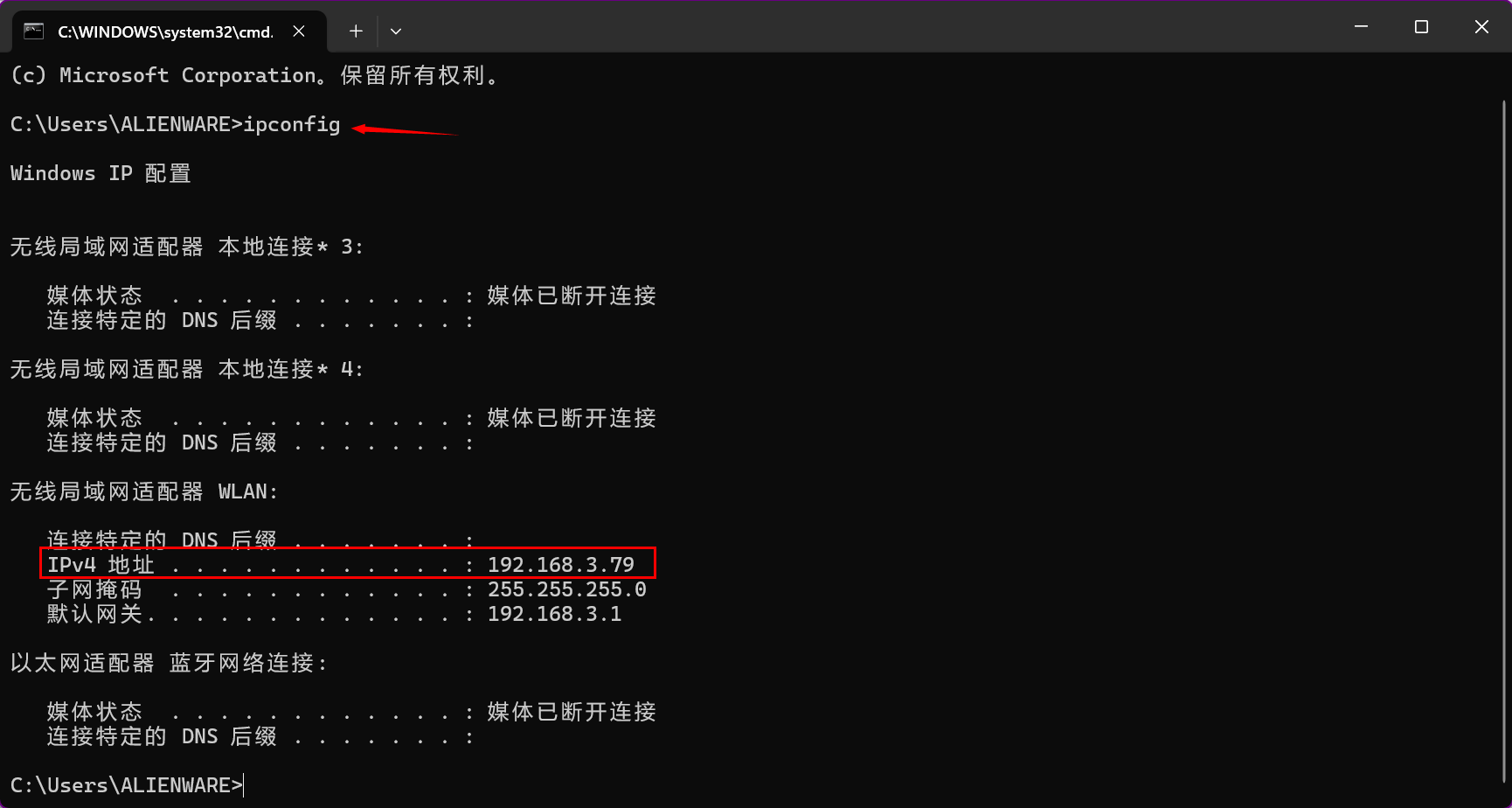
这样可以看到我本机的IP地址是:192.168.3.79,所以,在局域网内的其它机器采用这个网址即可访问:http://192.168.3.79:7860
四、关于插件
1.ADetailer(修复脸、手、身)
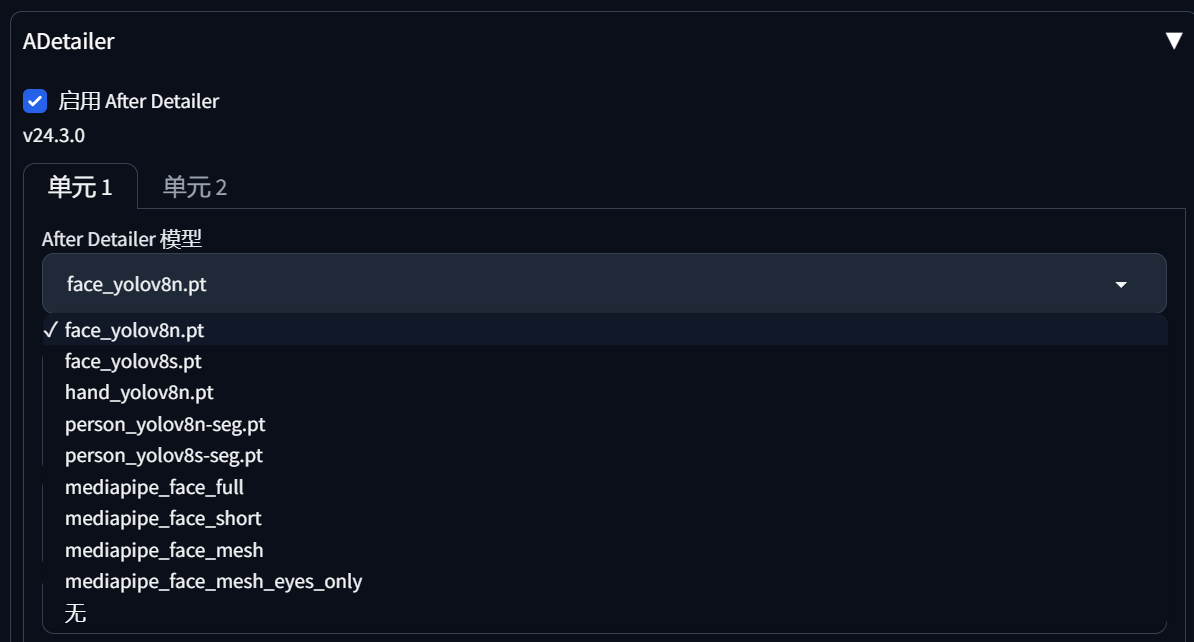
ADetailer是脸、手、身修复插件,以下是教程:
Stable Diffusion 必装插件之 ADetailer,修脸修手无敌,各种参数详解 - 知乎 (zhihu.com)
可以下拉框中选模型,有face的是脸,hand是手,person是身体。
注意事项:
先调试好参数,确认没有问题后,在生成时,先点选ADetailer脸部修复,这样能一次性生成完整图片。
ADetailer修复身体会造成衣服变化,而手部越修越糟糕。
ADetailer后期生成,就不要用高清图,因为高清图会在ADetailer变得不清晰,并且文件还很大。
2.Tiled Diffusion和Tiled VAE
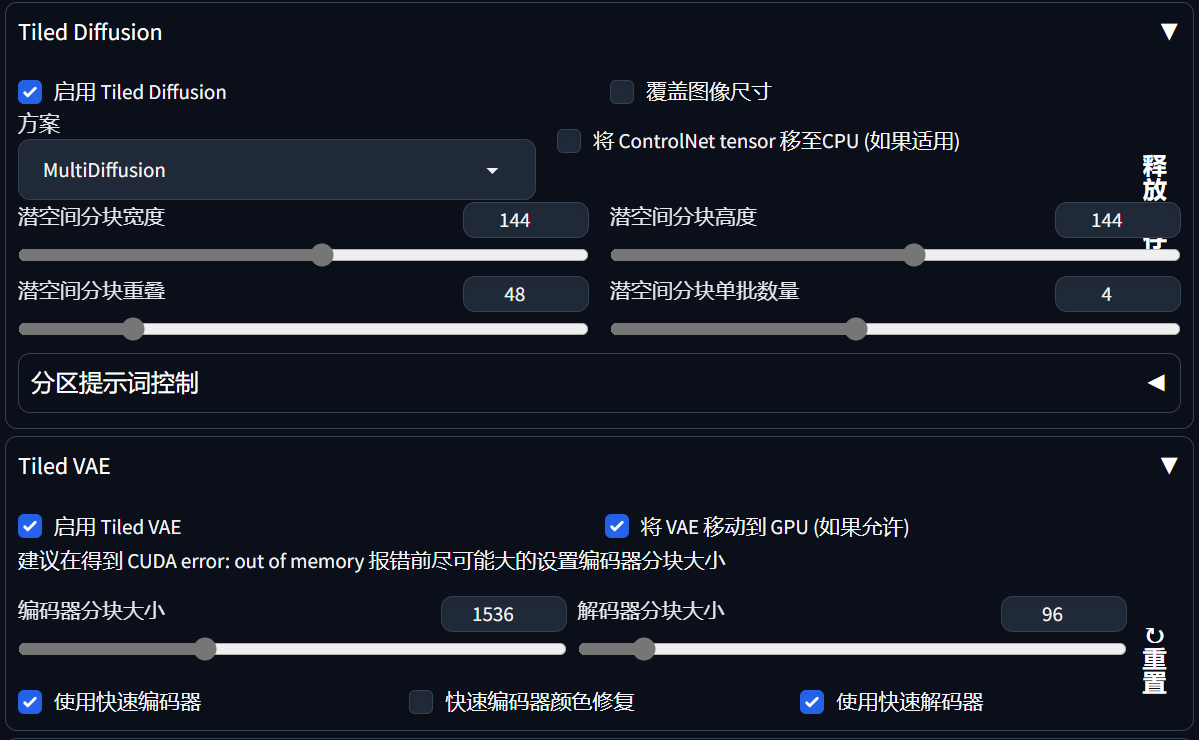
想要高清图可以选这两项,下面是相关教程:
Stable diffusion生成细节度拉满的超高分辨率画面|Ultimate SD upscale|Tiled Diffusion教程_哔哩哔哩_bilibili
3.ControlNet控制图像(常用)
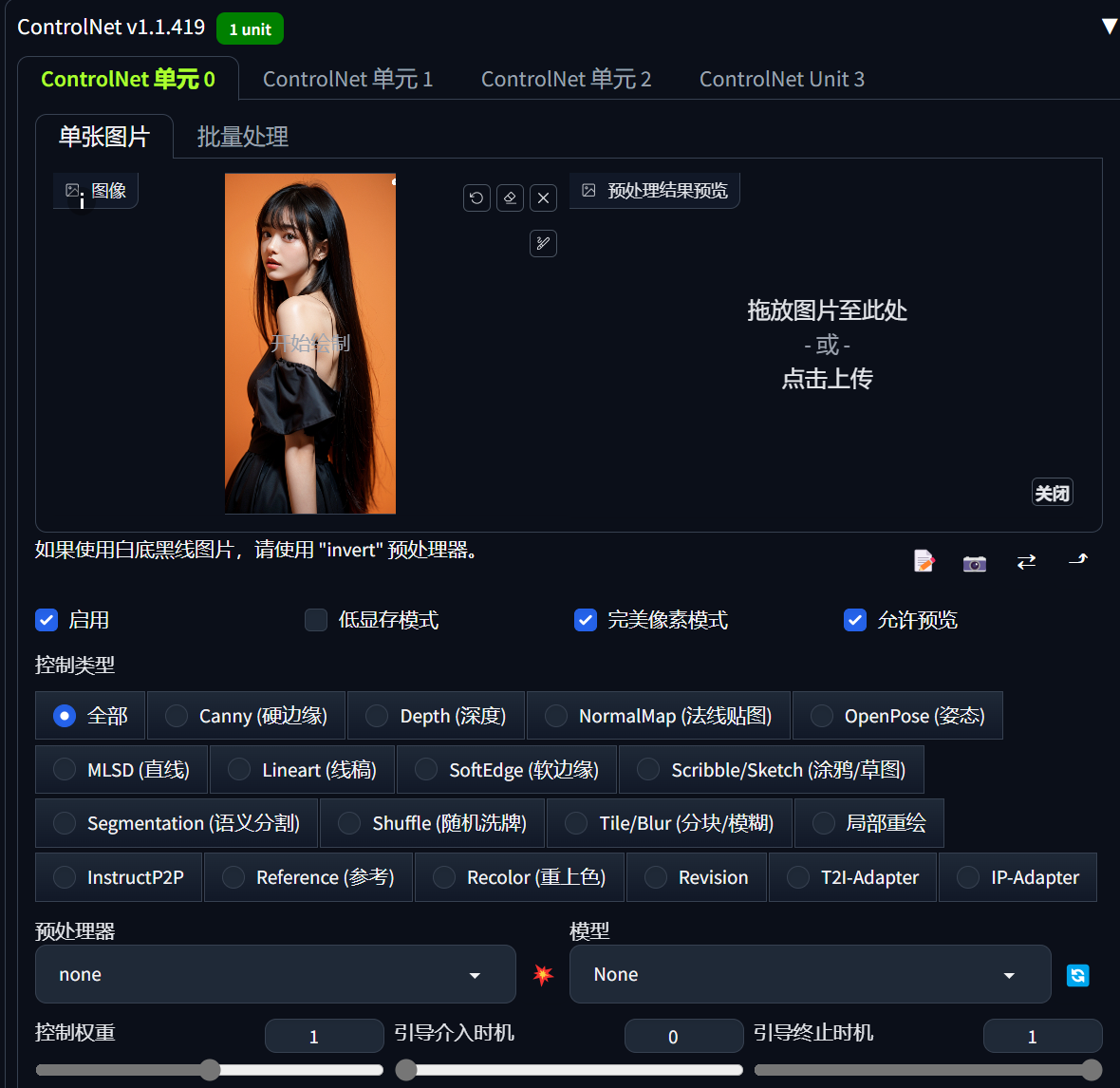
这是很常用的功能,也非常重要。
关于控制类型可以查看详细教程:AI绘画,一文讲清楚ControlNet实用教程 - 知乎 (zhihu.com)
选项卡中有单元1、单元2……就是指同时可以添加多种控制,我自己在生成模特的时候,一般 常用的就是OpenPose和canny或softEdge,其它的都没怎么用。
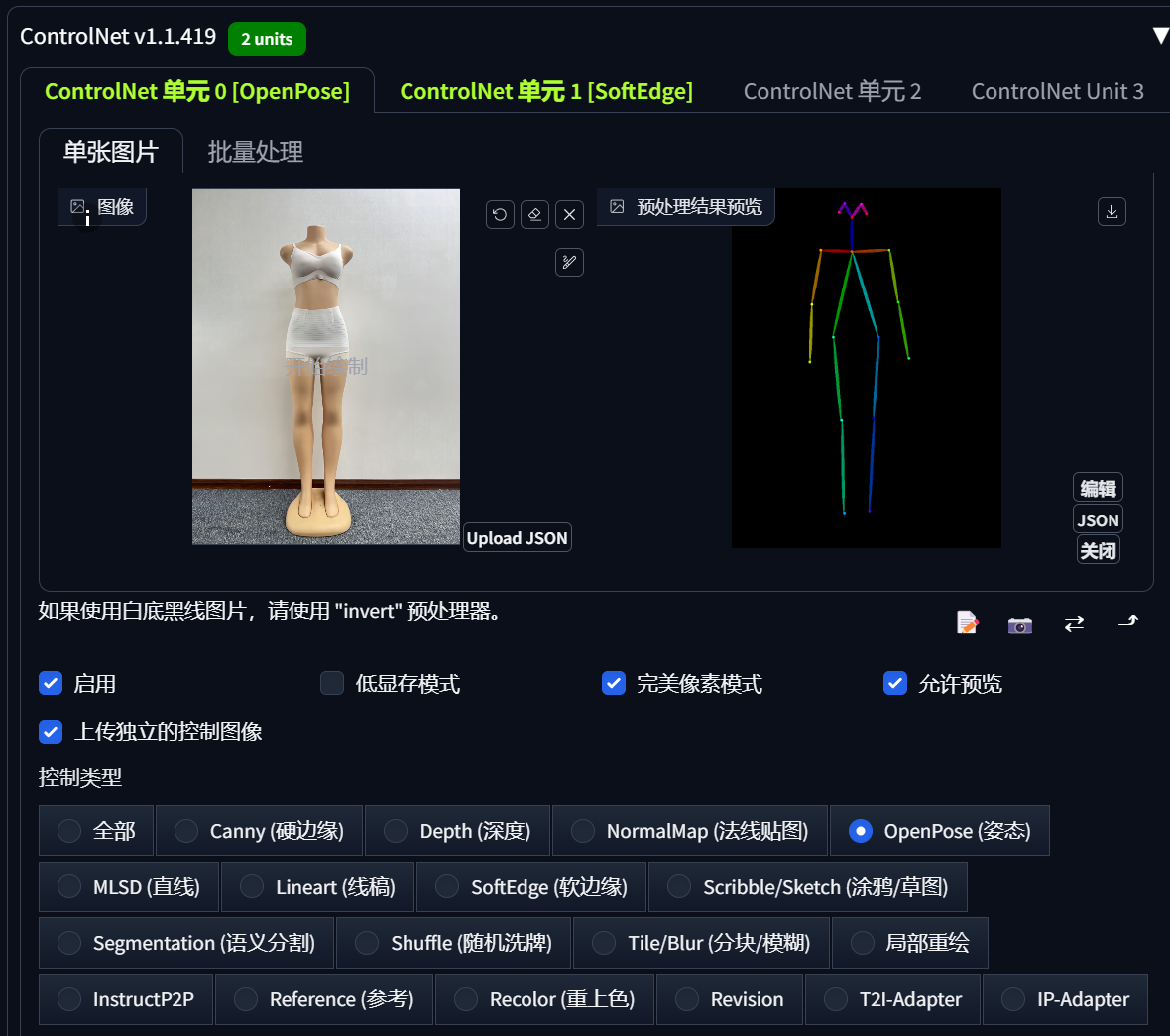
可以定位好姿势。
还有Tile也是生成高清图需要用到的。
这是关于Tile的教程:stable diffusion中tile模型的应用技巧,看完后我终于明白了它的原理和使用场景! - 知乎 (zhihu.com)
4.Segment Anything蒙版
链接:https://pan.baidu.com/s/1sDML8ve-LX3lcUFl5QuJFA?pwd=XYSD
提取码:XYSD
里面有三个文件,都是类似这样的文件名:sam_vit_h_4b8939.pth
注意看中间的字母h,这是什么意思呢?
很简单:显存10G+用h,6-10用l,小于的用b
下载后放置到这个文件夹中:\extensions\sd-webui-segment-anything\models\sam
然后重新加载界面:
来到segment anything中:

鼠标左键点击想要蒙版部分(黑点),右键点击不想要蒙版的部分(红点)
这样会生成多张高清蒙版供选择。
5.后期处理
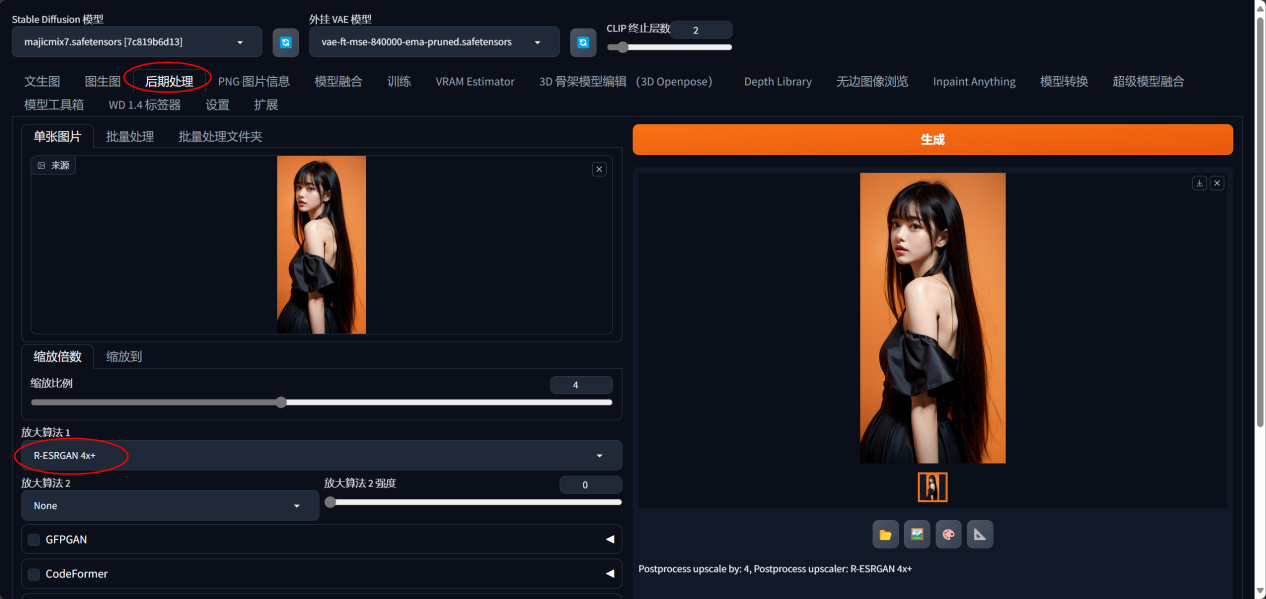
点击总导航选项卡中的“后期处理”,可以把图片放大。
注意选择好放大算法。
6.PNG图片信息
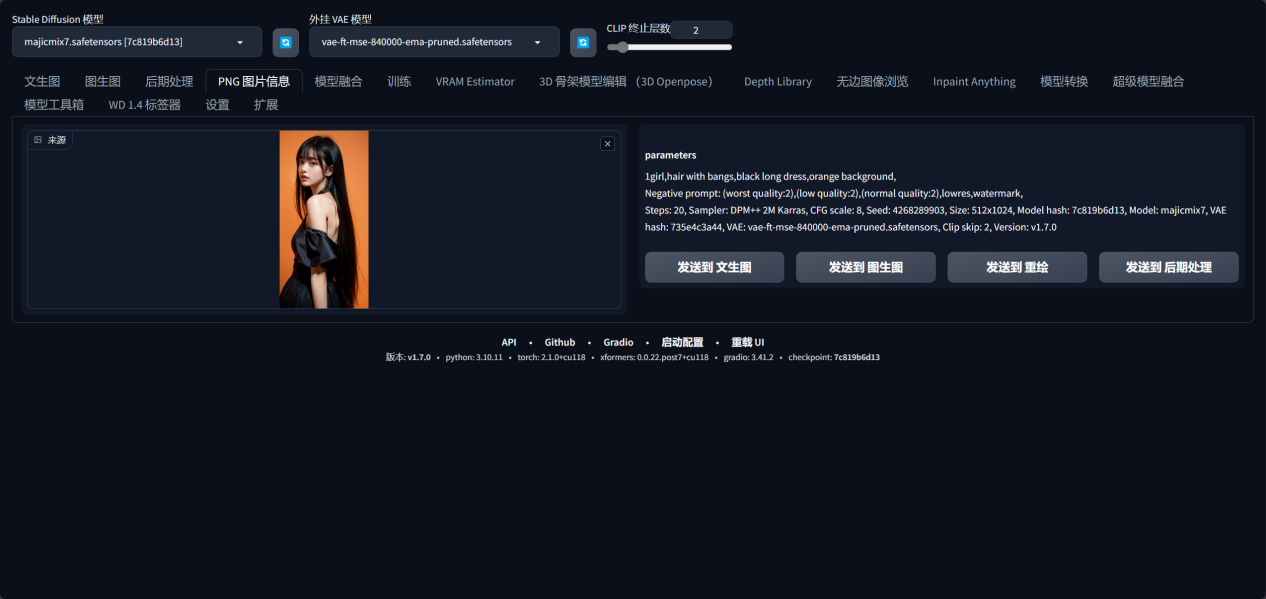
由SD生成的png图片你忘词了?可以在这里提取出来。
7.VRAM Estimator
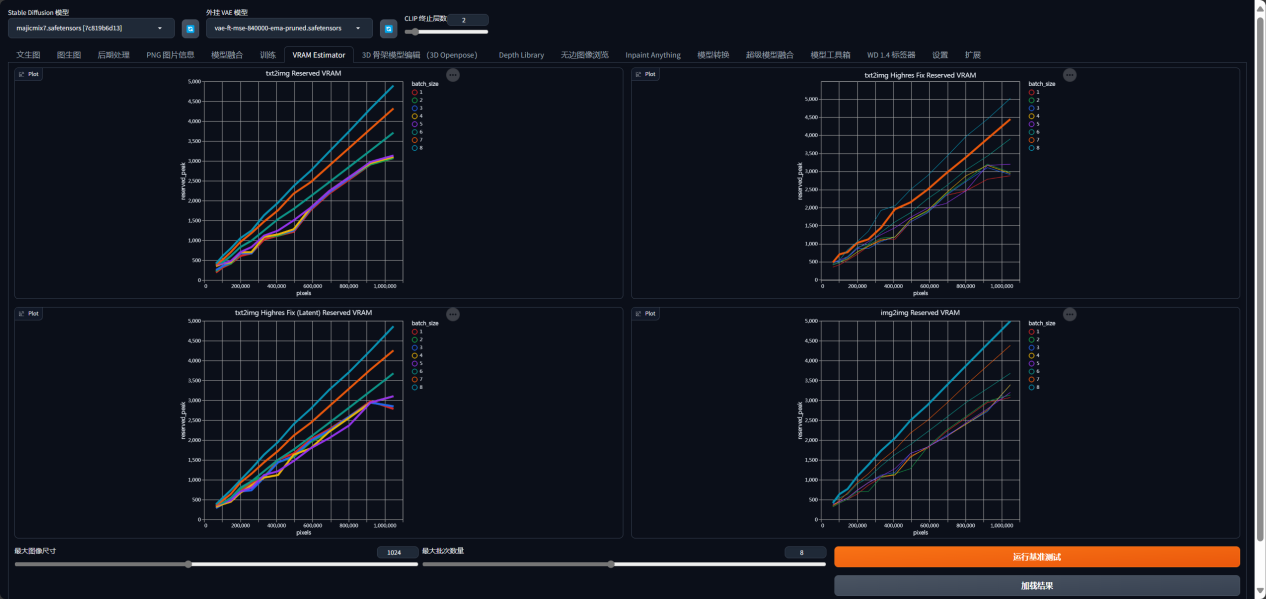
经常出现爆显存?可以安装好这个插件,然后运行基准测试,运行约15分钟至数小时不等,这是测试你显卡的性能。然后会生成图表,你不用去看这些图表,它的作用是当你每次设置完准备跑图的时候,就会给你计算出你的显存是否能跑:
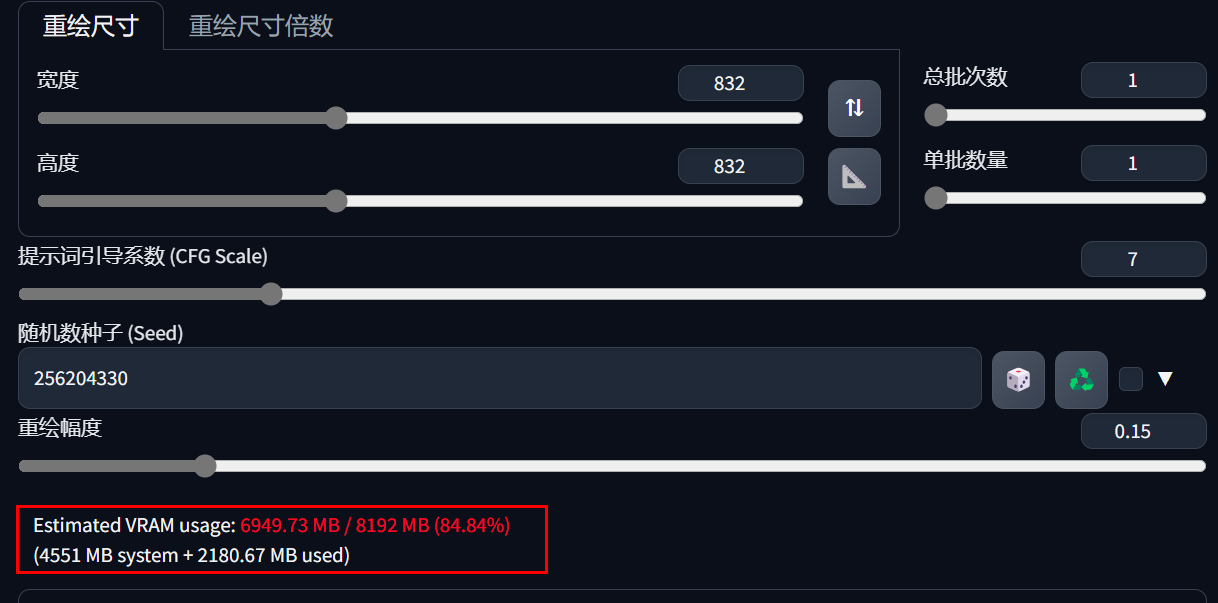
比如我这个这次跑图是占到84.84%
如果超太多,就跑不了了。
8.3D OpenPose
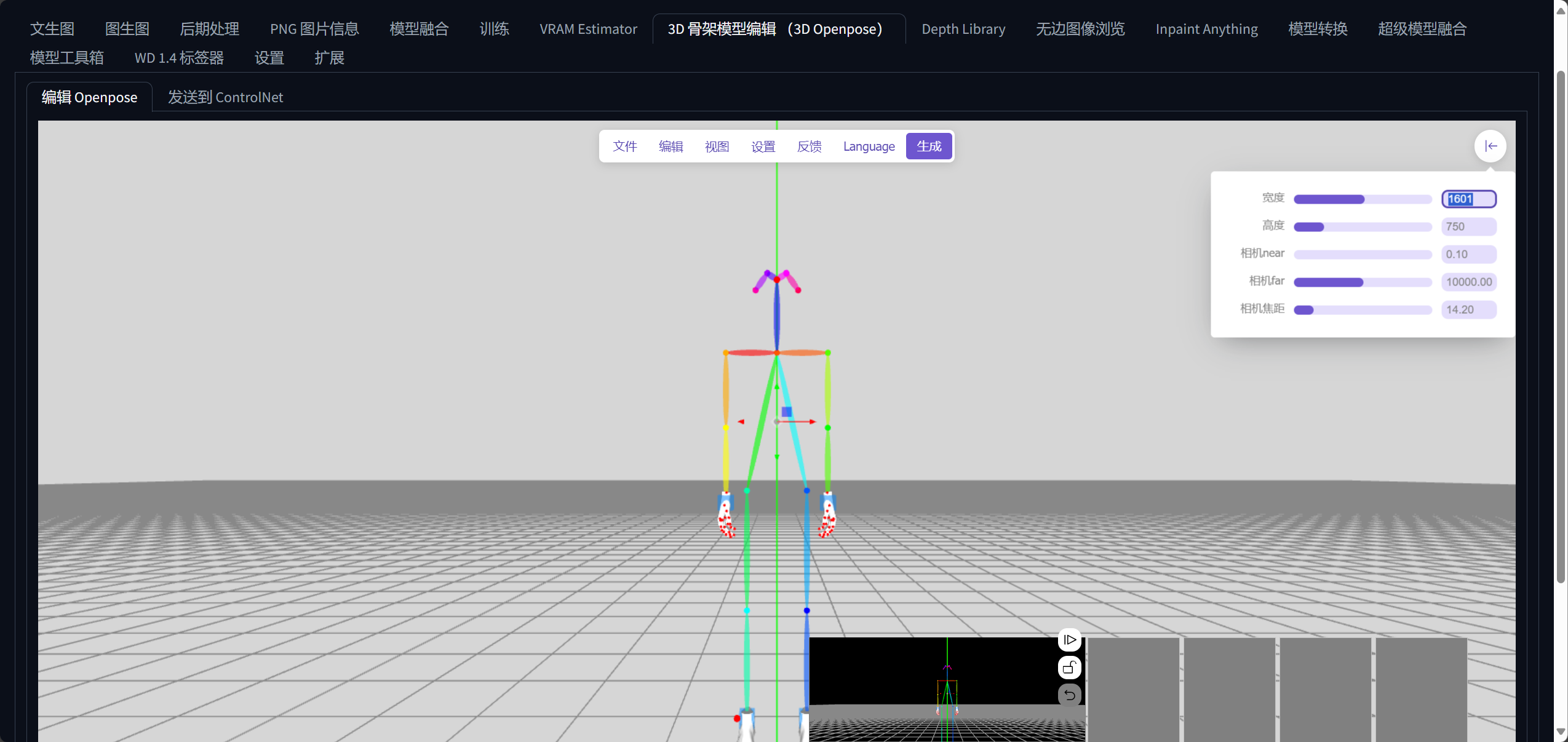
当你上传图片之后,它就会自动调整图片中的骨架结构。
3D OpenPose它有别于ControlNet中的OpenPose,它支持更多角度的姿势调节。
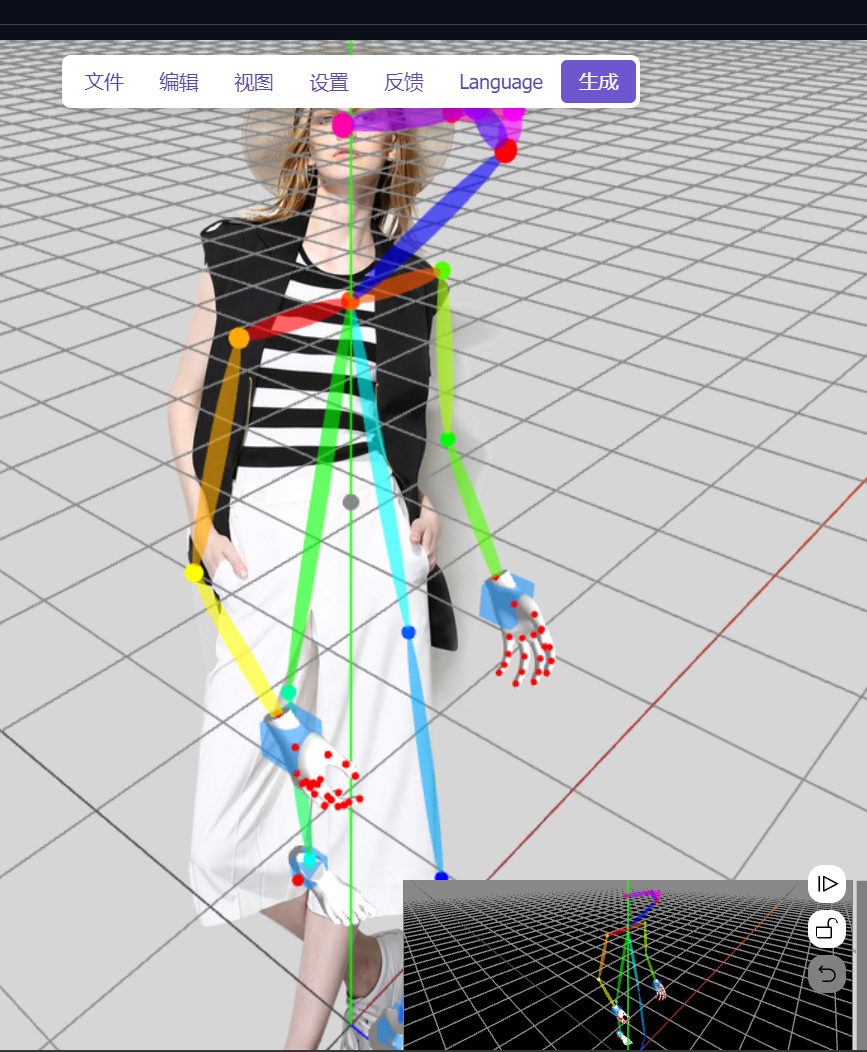
不过使用不是很顺手,骨架的操作比较难。
9.Depth Library手指调整
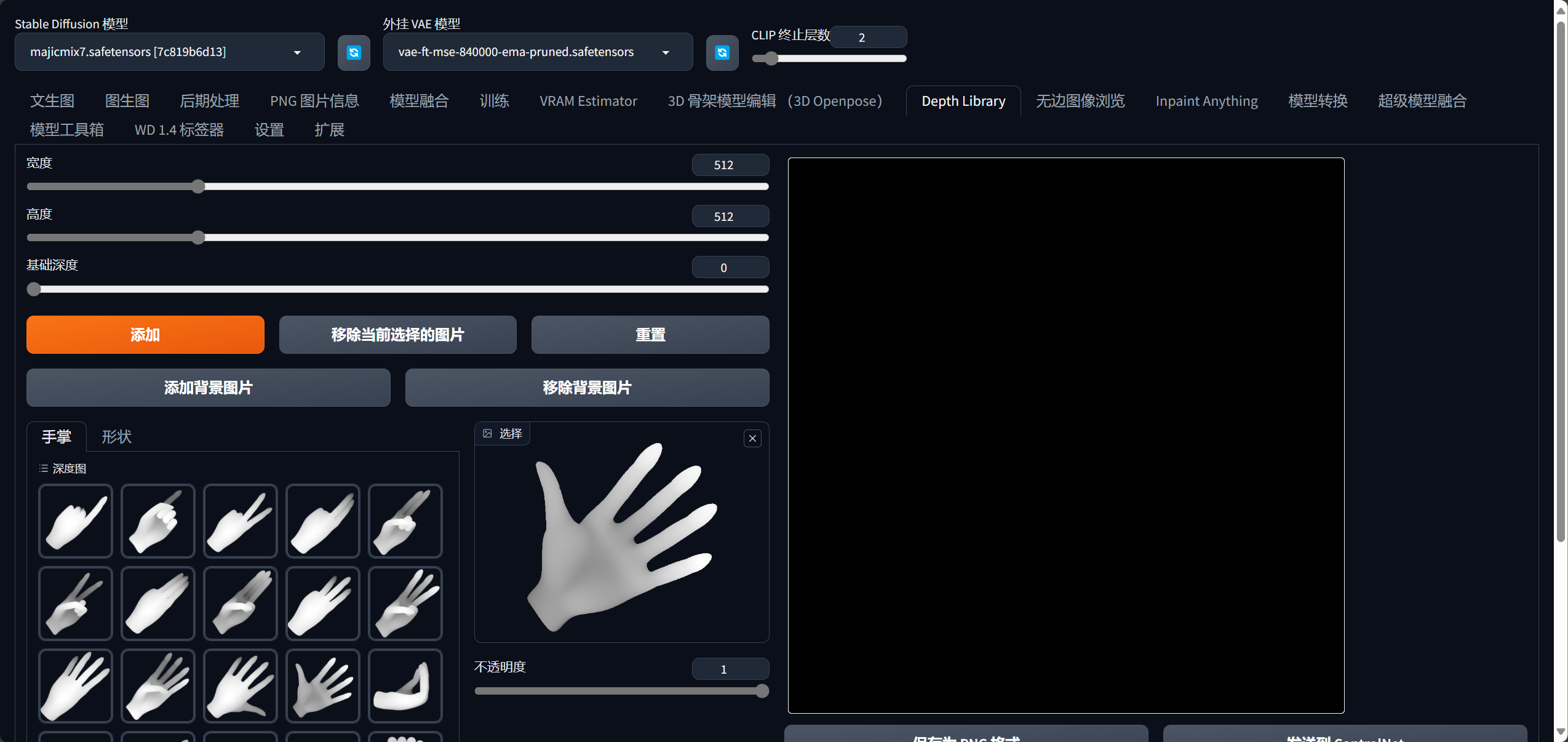
生成的图片如果出现坏手,那么可以用这个工具手动去调整。
其实关于调整手部有很多方法,建议可下这个教程:
stablediffusion手指修复方法 各种手势姿态调整,controlnet openpose教程_哔哩哔哩_bilibili
10.Inpaint Anything蒙版
我觉得它这个蒙版比之前那个Segment Anything要容易操作很多。
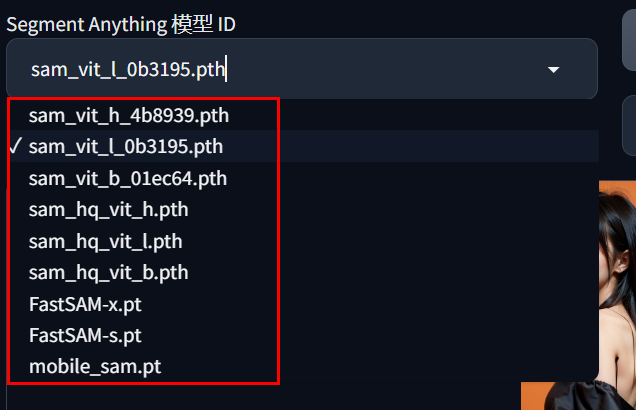
先在这里选好模型,老样子,带10G以上显存的用h,6~10的用l,小的用b。

左侧上传图片,点击下方按钮,右边会呈现色块,用鼠标点击色块代表选中蒙版。
比如我们要替换图片中的黑色衣服,每个色块都要点,右上角的笔标可以调整笔尖大小。
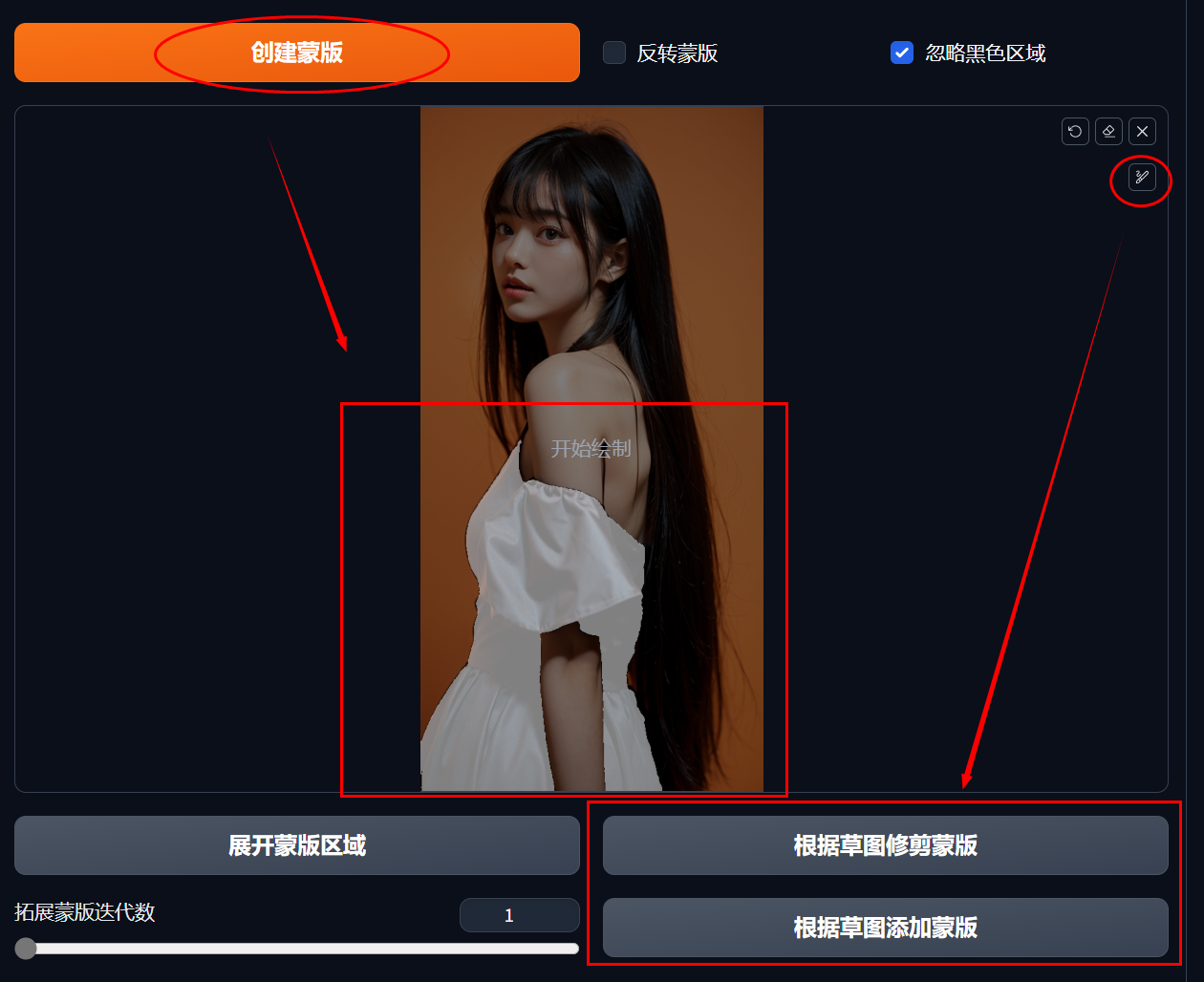
点击“创建蒙版”按钮,在下方就会生成蒙版。
右上角同样有毛笔可以修剪或添加蒙版内容。
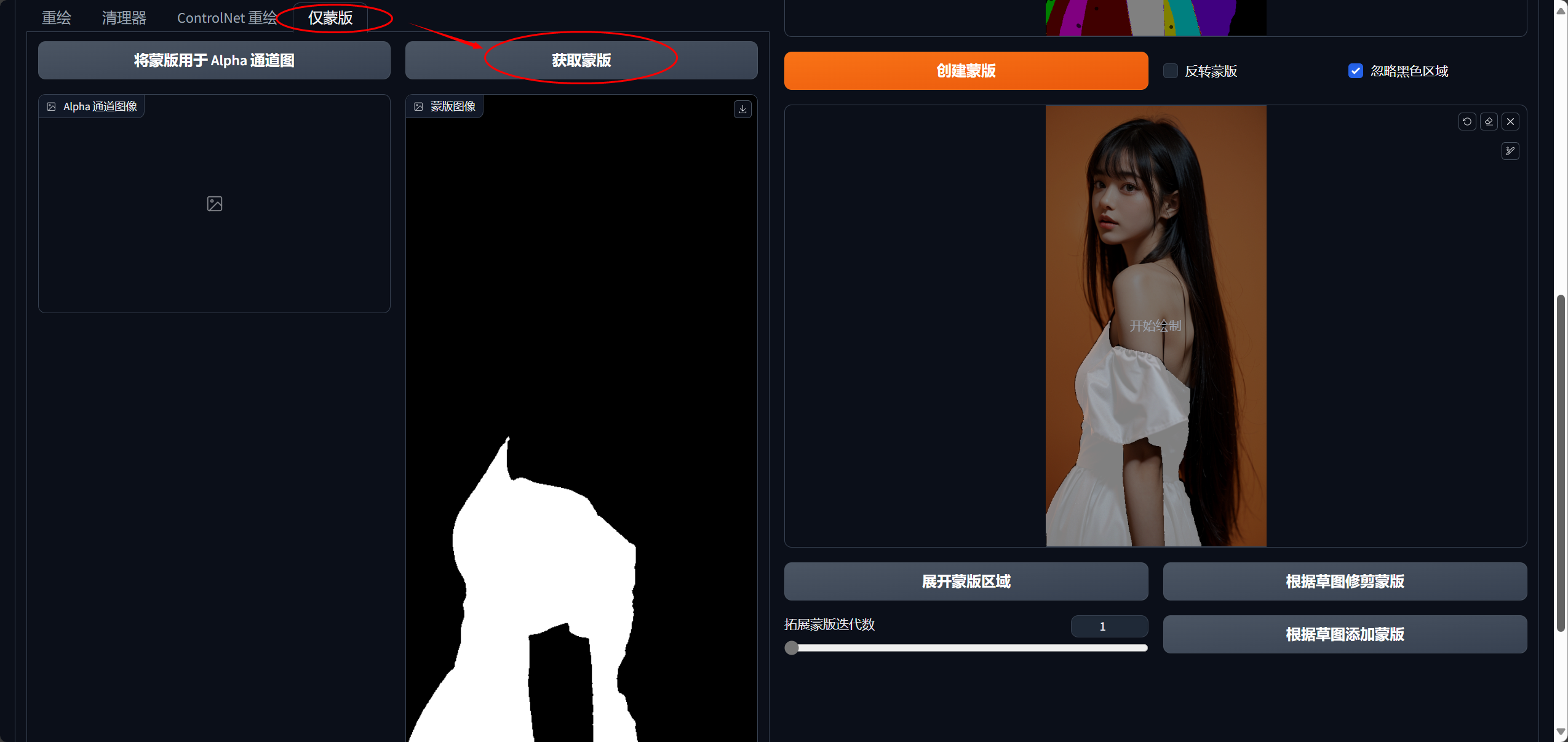
确定好蒙版之后,再回到左右点击选项卡“仅蒙版”,点击“获取蒙版”,这样就完成了。

在蒙版下方可点击发送到图生图,这样就大功告成了!
11.WD1.4场景器(反推提示词)

当你在左右上传一张图片后,会自动根据图片帮你反推提示词。
结语
教程我有空就会更新,模型训练方面我还没有时间研究,所以一些功能我还不知道怎么使用,后续工作上有用到就会逐渐更新。
接下来可能会更新一些案例,以及视频生成和工作流的方法,敬请期待。
最近自己开发了一套自动化办公软件pluglink,如果你有兴趣可下载开源一起交流:
Github地址:https://github.com/zhengqia/PlugLink
Gitcode地址:GitCode - 开发者的代码家园
应用版下载:
链接:https://pan.baidu.com/s/19tinAQNFDxs-041Zn7YwcQ?pwd=PLUG
提取码:PLUG
软件说明:https://drgphlxsfa.feishu.cn/wiki/GeuMwglQdi65BbkclgLcBUCFnRf

