
- 1FastMVSNet自定义测试数据集网络实现流程(二)_mvsnet训练自己的数据集
- 2Kafka学习---分区与副本原理解析_kafka分区和副本理解
- 3银行木马卷土重来、开发者破坏开源库影响数千应用程序|1月10日全球网络安全热点
- 4Redis-stack 初体验_redis stack
- 5[Bug0014] Hexo+Github 搭建博客报错 :remote: Support for password authentication was removed on August 13, ...
- 6Android网络基础1——网络分层_android 开发七层模型
- 7数据全生命周期保护基本要求_数据生命周期安全防护,2024年最新2024年展望网络安全原生开发的现状_数据安全 一般数据 全生命周期保护措施
- 8使用Docker Compose一键部署前后端分离项目(图文保姆级教程)_docker-compose部署前后端项目
- 9【利器篇】前端40+精选VSCode插件,总有几个你未拥有!_vscode 前端开发必备插件
- 10【2024浙江省蓝桥杯C++B组省赛】题解A-D(含题面)_有一个数组,包含 1 到 n 这 n 个整数,初始为一个从小到大的有序排列:{1, 2, 3
Java性能优化
赞
踩
文章目录
- 一、JVM内存模型
- 二、性能调优
- 三、Java API调用优化建议
- 3.1 面向对象及基础类型
- 3.2 集合类概念
- 3.3 字符串概念
- 3.4 引用类型概念
- 3.5 其他相关概念
- 四、程序设计优化建议
- 4.1、常用算法
- 4.2、Java算法
- 4.3、设计模式
- 4.3.1 设计模式6准则:solid
- 4.3.2 [23种设计模式](http://blog.csdn.net/paincupid/article/details/46993573)
- 4.3.2.0 简单工厂
- 4.3.2.1 [工厂方法模式(Factory Method)](http://blog.csdn.net/paincupid/article/details/43803497)
- 4.3.2.2 [抽象工厂模式(Abstract Factory)](http://blog.csdn.net/paincupid/article/details/43803497)
- 4.3.2.3[单例模式]( )http://blog.csdn.net/paincupid/article/details/46689193)
- 4.3.2.4 [建造者模式(builder pattern) - 创建型模式](http://blog.csdn.net/paincupid/article/details/43865915)
- 4.3.2.5 [原型模式](http://blog.csdn.net/paincupid/article/details/46860283)
- 4.3.2.6 [适配器模式](http://blog.csdn.net/paincupid/article/details/46884927)
- 4.3.2.7 [装饰者模式 - 结构型模式](http://blog.csdn.net/paincupid/article/details/44038877)
- 4.3.2.8 [代理模式(结构型模式)](http://blog.csdn.net/paincupid/article/details/43926757)
- 4.3.2.9 [外观模式 - 结构型模式,也称之为门面模式。](http://blog.csdn.net/paincupid/article/details/44164411)
- 4.3.2.10 [桥连接模式 - 结构型模式](http://blog.csdn.net/paincupid/article/details/43538887)
- 4.3.2.11 [组合模式:结构型模式](http://blog.csdn.net/paincupid/article/details/44178215)
- 4.3.2.12 [享元模式 - 结构型模式](http://blog.csdn.net/paincupid/article/details/46896653)
- 4.3.2.13 [策略模式 - 行为模式](http://blog.csdn.net/paincupid/article/details/46897043)
- 4.3.2.14 [模板方法 - 行为模式](http://blog.csdn.net/paincupid/article/details/46900891)
- 4.3.2.15 [观察者模式 - 行为模式](http://blog.csdn.net/paincupid/article/details/46941917)
- 4.3.2.16 [迭代模式 - 行为模式](http://blog.csdn.net/paincupid/article/details/44943831)
- 4.3.2.17 [责任链模式 - 行为模式](http://blog.csdn.net/paincupid/article/details/46943547)
- 4.3.2.18 [命令模式 - 行为模式](http://blog.csdn.net/paincupid/article/details/46947957)
- 4.3.2.19 [备忘录模式 - 行为模式](http://blog.csdn.net/paincupid/article/details/46983185)
- 4.3.2.20 []状态模式 - 行为模式](http://blog.csdn.net/paincupid/article/details/46984077)
- 4.3.2.21 [访问者模式 - 行为模式](http://blog.csdn.net/paincupid/article/details/46988559)
- 4.3.2.22 [中介者模式 - 行为模式](http://blog.csdn.net/paincupid/article/details/46991371)
- 4.3.2.23 [解释器模式 - 行为模式](http://blog.csdn.net/paincupid/article/details/46991977)
- 4.3.2.24 空对象模式 - 行为模式
- 4、其它优化
- 五、Java并行程序优化建议
- 六、JVM性能测试及监控
- 七、JVM性能调优
- Reference
一、JVM内存模型
多核时代的到来,基于高速缓存的存储交互很好的解决了处理器与内存之间的矛盾,也引入了新的问题:缓存一致性问题。在多处理器系统中,每个处理器有自己的高速缓存,而他们又共享同一块内存(下文成主存,main memory 主要内存),当多个处理器运算都涉及到同一块内存区域的时候,就有可能发生缓存不一致的现象。
为了解决这一问题,需要各个处理器运行时都遵循一些协议,在运行时需要将这些协议保证数据的一致性。这类协议包括MSI、MESI、MOSI、Synapse、Firely、DragonProtocol等。如下图所示

JVM内存模型大体分5部分:程序计数器(Program Counter Register)、JVM虚拟机栈(JVM Stacks)、本地方法栈(Native Method Stacks)、堆(Heap)、方法区(Method Area)
如果按是否共享分:
线程共享内存区:Java堆、方法区、运行时常理池
线程私有内存区:PC寄存器、Java栈、本地方法栈(Native Method Stack)
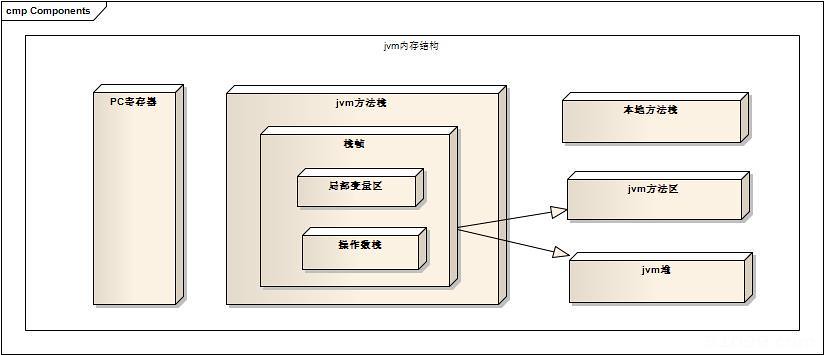
1.1、程序计数器(Program Counter Register)
这是一块比较小的内存,不在Ram上,而是直接划分在CPU上的,程序员无法直接操作它,它的作用是:** JVM在解释字节码文件(.class)时,存储当前线程所执行的字节码的行号,只是一种概念模型,各种JVM所采用的方式不同,字节码解释器工作时,就是通过改变程序计数器的值来选取下一条要执行的指令,分支、循环、跳转、等基础功能都是依赖此技术区完成的。 ** 还有一种情况,就是我们常说的Java多线程方面的,多线程就是通过现程轮流切换而达到的,同一时刻,一个内核只能执行一个指令,所以,对于每一个程序来说,必须有一个计数器来记录程序的执行进度,这样,当现程恢复执行的时候,才能从正确的地方开始,所以,每个线程都必须有一个独立的程序计数器,这类计数器为线程私有的内存。
如果一个线程正在执行一个Java方法,则计数器记录的是字节码的指令的地址,如果执行的一个Native方法,则计数器的记录为空。
程序计数器是唯一一个在Java规范中没有任何OutOfMemoryError情况的区域。
1.2、JVM虚拟机栈(JVM Stacks)
VM虚拟机栈就是我们常说的堆栈的栈(我们常常把内存粗略分为堆和栈),和程序计数器一样,也是线程私有的,生命周期和线程一样,每个方法被执行的时候会产生一个栈帧。
栈用于存储局部变量表、动态链接、操作数栈、方法出口等信息。
栈用于存储局部变量表即:Java 8种数据类型,及引用类型(存放的是指向各个对象的内存地址)
操作数据栈作用
1、解析常量池里面的数据
2、方法执行完后处理方法返回,恢复调用方现场
3、方法执行过程中抛出异常时的异常处理,存储在一个异常表,当出现异常时虚拟机查找相应的异常表看是否有对应的Catch语句,如果没有就抛出异常终止这个方法调用
方法的执行过程就是栈帧在JVM中出栈和入栈的过程。
内存空间可以在编译期间就确定,运行期不在改变。这个内存区域会有两种可能的Java异常:StackOverFlowError和OutOfMemoryError。
1.3、本地方法栈(Native Method Stacks)
用来处理Java中的本地方法的,Java类的祖先类Object中有众多Native方法,如hashCode()、wait()等,他们的执行很多时候是借助于操作系统,但是JVM需要对他们做一些规范,来处理他们的执行过程。
在SUN的HOT SPOT虚拟机中,不区分本地方法栈和虚拟机栈。因此,也会抛出StackOverFlowError和OutOfMemoryError
1.4、堆(Heap)
因为Java性能的优化,主要就是针对这部分内存的。几乎(JIT除外)所有的对象实例及数组都是在堆上面分配的,可通过-Xmx和-Xms来控制堆的大小。
堆内存是垃圾回收的主要区域

JIT 是 just in time 的缩写, 也就是即时编译编译器。使用即时编译器技术,能够加速 Java 程序的执行速度。
对于 Java 代码,刚开始都是被编译器编译成字节码文件,然后字节码文件会被交由 JVM 解释执行,所以可以说 Java 本身是一种半编译半解释执行的语言。Hot Spot VM 采用了 JIT compile 技术,将运行频率很高的字节码直接编译为机器指令执行以提高性能,所以当字节码被 JIT 编译为机器码的时候,要说它是编译执行的也可以。也就是说,运行时,部分代码可能由 JIT 翻译为目标机器指令(以 method 为翻译单位,还会保存起来,第二次执行就不用翻译了)直接执行。
1.5、方法区(Method Area)
方法区是所有线程共享的内存区域,用于存储已经被JVM加载的类信息、常量、静态变量等数据,一般来说,方法区属于持久代。
方法区中一个重要的概念:运行时常量池。主要用于存放在编译过程中产生的字面量(字面量简单理解就是常量)和引用。
一般情况,常量的内存分配在编译期间就能确定,但不一定全是,有一些可能就是运行时也可将常量放入常量池中,如String类中有个Native方法intern()
在JVM内存管理之外的一个内存区:直接内存。在JDK1.4中新加入类NIO类,引入了一种基于通道与缓冲区的I/O方式,它可以使用Native函数库直接分配堆外内存,即我们所说的直接内存,这样在某些场景中会提高程序的性能。
参考:http://blog.csdn.net/zhangerqing/article/details/8214365
1.6 其它延伸
一般认为new出来的对象都是被分配在堆上,但是这个结论不是那么的绝对,通过对Java对象分配的过程分析,可以知道有两个地方会导致Java中new出来的对象并一定分别在所认为的堆上。这两个点分别是Java中的逃逸分析和TLAB(Thread Local Allocation Buffer)。
1.6.1 逃逸分析
在计算机语言编译器优化原理中,逃逸分析是指分析指针动态范围的方法,它同编译器优化原理的指针分析和外形分析相关联。当变量(或者对象)在方法中分配后,其指针有可能被返回或者被全局引用,这样就会被其他过程或者线程所引用,这种现象称作指针(或者引用)的逃逸(Escape)。
逃逸分析的基本行为就是分析对象动态作用域:当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他地方中,称为方法逃逸。
通过逃逸分析,Java Hotspot编译器能够分析出一个新的对象的引用的使用范围从而决定是否要将这个对象分配到堆上。
编译器可以使用逃逸分析的结果,对程序进行一下优化
- 堆分配对象变成栈分配对象。一个方法当中的对象,对象的引用没有发生逃逸,那么这个方法可能会被分配在栈内存上而非常见的堆内存上,该对象所占用的内存空间就可以随栈帧出栈而销毁,就减轻了垃圾回收的压力。
- 消除同步。线程同步的代价是相当高的,同步的后果是降低并发性和性能。逃逸分析可以判断出某个对象是否始终只被一个线程访问,如果只被一个线程访问,那么对该对象的同步操作就可以转化成没有同步保护的操作,这样就能大大提高并发程度和性能。
- 矢量替代。逃逸分析方法如果发现对象的内存存储结构不需要连续进行的话,就可以将对象的部分甚至全部都保存在CPU寄存器内,这样能大大提高访问速度。
1.6.2 TLAB
JVM在内存新生代Eden Space中开辟了一小块线程私有的区域,称作TLAB(Thread-local allocation buffer)。默认设定为占用Eden Space的1%。在Java程序中很多对象都是小对象且用过即丢,它们不存在线程共享也适合被快速GC,所以对于小对象通常JVM会优先分配在TLAB上,并且TLAB上的分配由于是线程私有所以没有锁开销。因此在实践中分配多个小对象的效率通常比分配一个大对象的效率要高。
也就是说,Java中每个线程都会有自己的缓冲区称作TLAB(Thread-local allocation buffer),每个TLAB都只有一个线程可以操作,TLAB结合bump-the-pointer技术可以实现快速的对象分配,而不需要任何的锁进行同步,也就是说,在对象分配的时候不用锁住整个堆,而只需要在自己的缓冲区分配即可。
二、性能调优
三、Java API调用优化建议
3.1 面向对象及基础类型
1、大对象采用clone方式
2、常用的工具类使用静态方法替代实例方法
3、有条件的使用final关键字(final会告诉编译器该方法不会被重载)
4、避免不需要的instanceof
5、建议多使用局部变量
6、运算效率最高的方式–位运算
>>>和>>区别:在执行运算时,>>>操作数高位补0,而>>运算符的操作数高位移入原来高位的值。
- 1
7、用一维数组代替二维数组
8、布尔运算代替位运算
9、在switch语句中使用字符串
10、在Java7中,数值字面量,不管是整数还是浮点数,都允许数字之间插入任意多个下画线,主要目的是方便阅读。例如:
98_3__1, 5_6.3_4
11、针对基本类型的优化
Java7后整数比较:Integer.compare(x,y);Java7 -128~127的数字对应的包装类对象始终指向相同的对象,即通过==进行判断时结果为true,如果希望设置更多的值,通过虚拟机启动参数:Java.lang.Integer.Integer-Cache.high来进行设置。
3.2 集合类概念
- 1、ArrayList初始化快,再次新增慢、删除巨慢;LinkedList删除新增快,遍历慢,LinkedList绝对不要使用get方法。
- 2、在使用配置Map时,如果键值非常小,应该考虑使用EnumSet或者EnumMap。
- 3、TreeMap有着比HashMap更为强大的功能,实现了SortedMap接口,它可以对元素进行排序。
3.3 字符串概念
1、拼接静态字符串时,用量用+;拼接动态字符串时尽量用StringBuffer或StringBuilder的apend,减少构造过多的String对象。
2、查找单个字符的话,charat()代替startswith()
3、字符相加时,如果字符只有一个的话,建议使用单引号替代双引号。
4、StringTokenizer处理速度快于split
5、正则表达式不是万能的,如果是在计算密集型代码中使用正则表达式,至少要将Pattern缓存下来,避免反复编译Pattern
3.4 引用类型概念
强引用(Strong Reference)
软引用(Soft Reference)
弱引用(Weak Reference)
ThreadLocal内部存储使用WeakReference。WeakHashMap的Key是弱引用,Value不是。WeakHashMap不会自动释放失效的弱引用,仅当包含了expungeStaleEntries()的共有方法被调用的时候才会释放。
虚引用(Phantom Reference)
弱引用就是在GC的时候就会立刻回收掉的,软引用是内存不够用的时候,GC才会去回收的。
但这里有一个前提:是没有任何强引用对象的时候才会去做的。
3.4.1 区别
A weak reference, simply put, is a reference that isn’t strong enough to force an object to remain in memory. Weak references allow you to leverage the garbage collector’s ability to determine reachability for you, so you don’t have to do it yourself. You create a weak reference like this:
WeakReference weakWidget = new WeakReference(widget);
and then elsewhere in the code you can use weakWidget.get() to get the actual Widget object. Of course the weak reference isn’t strong enough to prevent garbage collection, so you may find (if there are no strong references to the widget) that weakWidget.get() suddenly starts returning null.
A soft reference is exactly like a weak reference, except that it is less eager to throw away the object to which it refers. An object which is only weakly reachable (the strongest references to it are WeakReferences) will be discarded at the next garbage collection cycle, but an object which is softly reachable will generally stick around for a while.
SoftReferences aren’t required to behave any differently than WeakReferences, but in practice softly reachable objects are generally retained as long as memory is in plentiful supply. This makes them an excellent foundation for a cache, such as the image cache described above, since you can let the garbage collector worry about both how reachable the objects are (a strongly reachable object will never be removed from the cache) and how badly it needs the memory they are consuming.
3.5 其他相关概念
1、org.apache.commons.lang3.exception.ExceptionUtils
ExceptionUtils.getStackTrace(e)返回的是一个String;直接调用Exception返回的是一个StackTraceElement[]
commons-lang提供了一个ExceptionUtils.getRootCause() 方法来轻松获得异常源。
2、尽量不要在循环体中调用同步方法。如果必须同步的话,推荐以下方式
sychronized{
for(int i = 0; list.size(); i++){
method();
}
}
- 1
- 2
- 3
- 4
- 5
2.2 优化循环,减少循环次数
3、使用System.arrayCopy()进行数组的复制。
public static void arraycopy(Object src,
int srcPos,
Object dest,
int destPos,
int length)
- 1
- 2
- 3
- 4
- 5
src:源数组;srcPos:源数组要复制的起始位置;
dest:目的数组;destPos:目的数组放置的起始位置;length:复制的长度。
注意:src and dest都必须是同类型或者可以进行转换类型的数组.
System.arraycopy(array, 0, arraydstination, 0, size)
- 1
4、使用Buffer进行I/O操作
5、使用clone()代替new
四、程序设计优化建议
4.1、常用算法
4.1.1 FIFO算法(First in First out)先进先出算法
LinkedHashMap类是基于FIFO实现的
LinkedBlockingQueue、ArrayBlockingQueue是FIFO队列
4.1.2 LFU算法(Least Frequently Used)最近最多使用
LFU(Least Frequently Used)算法根据数据的历史访问频率来淘汰数据,其核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。
一般来说,LFU效率要优于LRU,且能够避免周期性或者偶发性的操作导致缓存命中率下降的问题。但LFU需要记录数据的历史访问记录,一旦数据访问模式改变,LFU需要更长时间来适用新的访问模式,即:LFU存在历史数据影响将来数据的“缓存污染”效用。
4.1.3 LRU算法(Least Recently Used)最近最少使用
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
4.1.4 LRU-K
LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到K次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。
4.1.5 2Q
Two queues(以下使用2Q代替)算法类似于LRU-2,不同点在于2Q将LRU-2算法中的访问历史队列(注意这不是缓存数据的)改为一个FIFO缓存队列,即:2Q算法有两个缓存队列,一个是FIFO队列,一个是LRU队列。
当数据第一次访问时,2Q算法将数据缓存在FIFO队列里面,当数据第二次被访问时,则将数据从FIFO队列移到LRU队列里面,两个队列各自按照自己的方法淘汰数据。
4.1.6 LIRS
LIRS,Low Inter-reference Recency Set,主要通过比较IRR(Inter-Reference Recency )来决定哪些块被替换出cache。LIRS也是目标实现一个低开销,不需要额外参数设置,并且性能优异于其它同类型的cache替换算法。
4.1.7 总结
LRU-K,2Q,LIRS三种算法都基于倒数第二次的访问时间,以此推断块的访问频率,从而替换出访问频率低的块。从空间额外消耗来看,除了LRU-K需要记录访问时间外,LIRS需要记录块状态(HIR/LIR等),2Q并不需要太多的访问信息记录,因此2Q>LIRS>LRU-K。从时间复杂度来看,LRU-K是O(logN),2Q和LIRS都是O(1),但LIRS的"栈裁剪"是平均的O(1),因此2Q>LIRS>LRU-K。从实现复杂来看,LIRS只需要两个队列,2Q和LRU-K的完整实现都需要3个队列,因此LIRS>2Q=LRU-K。最后,LIRS是唯一参数不需要去按照实际情况进行调整(尽管仍然有LIR和HIR的cache大小参数),2Q和LRU-K都需要进行细微的参数调整,因此LIRS>2Q=LRU-K。从性能角度来看,LIRS论文看得出还是有一定的提升,LIRS>2Q>LRU-K。
缓存算法参考:
http://www.sapv.cn/?p=87
http://flychao88.iteye.com/blog/1977653
http://blog.csdn.net/pun_c/article/details/50920469
http://www.jianshu.com/p/036f82975f81
4.2、Java算法
Array类中主要有二分法查找(binarySearch方法)算法和归并排序(sort方法)两种。
当数据量很大的时候,宜采用二分法查找算法
sort()方法针对引用类型数据采用的是归并排序;针对整形数据采取的是快速排序算法。
4.2.1 快速排序 QuickSort
是对冒泡排序的改进,基本思想是:
1.先从数列中取出一个数作为基准数。
2.分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
3.再对左右区间重复第二步,直到各区间只有一个数。
4.2.2 选择排序 SelectionSort
1.在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。
2.再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
3.以此类推,直到所有元素均排序完毕。
4.2.3 插入排序 InsertionSort
插入排序的工作原理是,对于每个未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
1.从第一个元素开始,该元素可以认为已经被排序
2.取出下一个元素,在已经排序的元素序列中从后向前扫描
3.如果被扫描的元素(已排序)大于新元素,将该元素后移一位
4.重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
5.将新元素插入到该位置后
6.重复步骤2~5
4.2.4 希尔排序 ShellSort
希尔排序,也称递减增量排序算法,实质是分组插入排序。由 Donald Shell 于1959年提出。希尔排序是非稳定排序算法。
基本思想是:将数组列在一个表中并对列分别进行插入排序,重复这过程,不过每次用更长的列(步长更长了,列数更少了)来进行。最后整个表就只有一列了。将数组转换至表是为了更好地理解这算法,算法本身还是使用数组进行排序。
4.2.5 归并排序 MergeSort
归并排序是采用分治法的一个非常典型的应用。归并排序的思想就是先递归分解数组,再合并数组。
先考虑合并两个有序数组,基本思路是比较两个数组的最前面的数,谁小就先取谁,取了后相应的指针就往后移一位。然后再比较,直至一个数组为空,最后把另一个数组的剩余部分复制过来即可。
再考虑递归分解,基本思路是将数组分解成left和right,如果这两个数组内部数据是有序的,那么就可以用上面合并数组的方法将这两个数组合并排序。如何让这两个数组内部是有序的?可以再二分,直至分解出的小组只含有一个元素时为止,此时认为该小组内部已有序。然后合并排序相邻二个小组即可。
4.2.6 堆排序 HeapSort
1.构造最大堆(Build_Max_Heap):若数组下标范围为0~n,考虑到单独一个元素是大根堆,则从下标n/2开始的元素均为大根堆。于是只要从n/2-1开始,向前依次构造大根堆,这样就能保证,构造到某个节点时,它的左右子树都已经是大根堆。
2.堆排序(HeapSort):由于堆是用数组模拟的。得到一个大根堆后,数组内部并不是有序的。因此需要将堆化数组有序化。思想是移除根节点,并做最大堆调整的递归运算。第一次将heap[0]与heap[n-1]交换,再对heap[0…n-2]做最大堆调整。第二次将heap[0]与heap[n-2]交换,再对heap[0…n-3]做最大堆调整。重复该操作直至heap[0]和heap[1]交换。由于每次都是将最大的数并入到后面的有序区间,故操作完后整个数组就是有序的了。
3.最大堆调整(Max_Heapify):该方法是提供给上述两个过程调用的。目的是将堆的末端子节点作调整,使得子节点永远小于父节点 。
4.2.7 DualPivotQuicksort算法
JDK1.7中新增java.util.DualPivotQuicksort类,改进了Qucksort算法。Collections.sort()和Arrays.sort()实现部分使用了这个类。
4.3、设计模式
4.3.1 设计模式6准则:solid
- 单一职责原则(Single Responsibility Principle,SRP)
规定每个类都应该有一个单一的功能,并且该功能应该由这个类完全封装起来。简单地说,就是保持单纯,别想那么多,做好一件事就好了。反过来,如果一个类承担的职责过多,就等于把这些职责耦合在一起
- 开闭原则(Open Close Principle)
对修改关闭,对扩展开放
- 里氏替换原理(Liskov Substitution Principle)
子类可以扩展父类功能,但不能改变父类原有的功能。
- 接口隔离原则(Interface Segregation Principle,ISP)
接口尽量细化,别让一个接口太臃肿,接口中的方法尽量少。类间的依赖关系,应该建立在最小接口上。这样的好处就在于,改变实现接口时,不会对现有逻辑造成干扰。
- 依赖倒转原则(Dependence Inversion Principle)
依赖于抽象而不依赖于具体,减少类之间的耦合性
- 迪米特法则(Law of Demeter,LoD)
最少知道原则,核心观念就是类间解耦,弱耦合。
4.3.2 23种设计模式
1、创建型模式(原工单抽建/建造单例工厂,抽象原型)
共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。
2、结构型模式(享代装适组外桥/享元装饰外观,代理桥接适配组合)
共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
3、行为型模式 (中访观模状解策命责迭备)
共十一种:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
创建型模式
4.3.2.0 简单工厂
0)简单工厂模式(Simple Factory): 简单工厂模式是类的创建模式,又叫做静态工厂方法(Static Factory Method)模式。简单工厂模式是由一个工厂对象决定创建出哪一种产品类的实例。
简单工厂模式是由一个具体的类去创建其他类的实例,父类是相同的,父类是具体的。
4.3.2.1 工厂方法模式(Factory Method)
工厂方法模式是有一个抽象的父类定义公共接口,子类负责生成具体的对象,这样做的目的是将类的实例化操作延迟到子类中完成。
Define an interface for creating an object,but let the subclasses decide which class to instantiate.Factory Method lets a class defer instantiation to subclasses 翻译,“定义一个创建对象的接口,但是让子类来觉得该实例化那个类。工厂方法让一个类推迟实例化至它的子类中。”
4.3.2.2 抽象工厂模式(Abstract Factory)
抽象工厂模式提供一个创建一系列相关或相互依赖对象的接口,而无须指定他们具体的类。它针对的是有多个产品的等级结构。而工厂方法模式针对的是一个产品的等级结构。
Provide an interface for creating families of related or dependent objects without specifying their concrete classes
翻译,“为创建一组相关或相互依赖的对象提供一个接口,无需指定它们的具体类”。
4.3.2.3单例模式http://blog.csdn.net/paincupid/article/details/46689193)
Ensure that only one instance of a class is created.
Provide a global point of access to the object.
Singleton单例模式目的在于确保一个类只有唯一的一个实例,并且这个唯一实例只有一个全局访问点。它确保类被实例一次,所有这个类的请求都指向这个唯一的实例。
4.3.2.4 建造者模式(builder pattern) - 创建型模式
Separate the construction of a complex object from its representation so that the same construction process can create different representations.
将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。
4.3.2.5 原型模式
specifying the kind of objects to create using a prototypical instance
creating new objects by copying this prototype
不是基本类型,所以成员变量不会被拷贝,需要我们自己实现深拷贝。
深拷贝与浅拷贝问题中,会发生深拷贝的有java中的8中基本类型以及他们的封装类型,另外还有String类型。其余的都是浅拷贝。
使用原型模式创建对象比直接new一个对象在性能上要好的多,因为Object类的clone方法是一个本地方法,它直接操作内存中的二进制流,特别是复制大对象时,性能的差别非常明显。
使用原型模式复制对象不会调用类的构造方法。因为对象的复制是通过调用Object类的clone方法来完成的,它直接在内存中复制数据,因此不会调用到类的构造方法。不但构造方法中的代码不会执行,甚至连访问权限都对原型模式无效。
利用序列化实现深度拷贝。把对象写到流里的过程是串行化(Serilization)过程,又叫对象序列化,而把对象从流中读出来的(Deserialization)过程叫反序列化。应当指出的是,写在流里的是对象的一个拷贝,而原对象仍然存在于JVM里面,因此在Java语言里深复制一个对象,常常可以先使对象实现Serializable接口,然后把对象(实际上只是对象的一个拷贝)写到一个流里,再从流里读出来便可以重建对象。
结构型模式
4.3.2.6 适配器模式
Convert the interface of a class into another interface clients expect.
Adapter lets classes work together, that could not otherwise because of incompatible interfaces.
将一个类的接口转换成客户希望的另外一个接口。Adapter模式使得原本由于接口不兼容而不能一起工作的那些类可以在一起工作。
类适配器使用对象继承的方式,是静态的定义方式;而对象适配器使用对象组合的方式,是动态组合的方式。
4.3.2.7 装饰者模式 - 结构型模式
动态地将责任附加到对象上,若要扩展对象,装饰者模式提供了比继承更弹性的替代方案。
装饰者和被装饰对象有相同的超类型。
OutputStream,InputStream,Reader,Writer等都用到了Decorator模式
4.3.2.8 代理模式(结构型模式)
对其他对象提供一种代理以控制对这个对象的访问。(Provide a surrogate or placeholder for another object to control access to it)。代理模式也叫做委托模式。
比较:代理则控制对对象的访问;装饰者为对象添加一个或多个功能;适配器为它所适配的对象提供了一个不同的接口
4.3.2.9 外观模式 - 结构型模式,也称之为门面模式。
为子系统中的一组接口提供一个一致的接口, Facade模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。
Provide a unified interface to a set of interface in a subsystem.Facade defines a higher-lever interface that make the subsystem easier to use.
4.3.2.10 桥连接模式 - 结构型模式
将抽象部分与实现部分分离,使它们都可以独立的变化。
The intent of this pattern is to decouple abstraction from implementation so that the two can vary independently.
桥接模式的做法是把变化部分抽象出来,使变化部分与主类分离开来,从而将多个维度的变化彻底分离。最后,提供一个管理类来组合不同维度上的变化,通过这种组合来满足业务的需要
4.3.2.11 组合模式:结构型模式
允许你将对象组合成树形来表达结构来表现“整体/部分”层次结构。组合能让用户以一致的方式处理个别对象及对象组合。
包含其他组件的组件为组合对象;不包含其他组件的组件为叶节点对象。
4.3.2.12 享元模式 - 结构型模式
The intent of this pattern is to use sharing to support a large number of objects that have part of their internal state in common where the other part of state can vary.
运用共享技术有效地支持大量细粒度的对象.
享元模式的作用在于节省内存开销,对于系统内存在的大量相似的对象,通过享元的设计方式,可以提取出可共享的部分,将其只保留一份进而节省大量的内存开销。
享元模式的本质是:分离和共享。分离的是对象状态中变与不变的部分,共享的是对象中不变的部分。
行为型模式
4.3.2.13 策略模式 - 行为模式
Define a family of algorithms, encapsulate each one, and make them interchangeable. Strategy lets the algorithm vary independently from clients that use it.
定义一系列的算法,把每一个算法封装起来, 并且使它们可相互替换。本模式使得算法可独立于使用它的客户而变化。也称为政策模式(Policy)。
4.3.2.14 模板方法 - 行为模式
Define the skeleton of an algorithm in an operation, deferring some steps to subclasses.
Template Method lets subclasses redefine certain steps of an algorithm without letting them to change the algorithm’s structure.
模板方法Gof的定义是:在一个方法里定义算法的骨架,将一些步骤延迟到其子类。
模板方法模式中,抽象类的模板方法应该声明为final的。因为子类不能覆写一个被定义为final的方法。从而保证了子类的逻辑永远由父类所控制。子类必须实现的方法定义为abstract。而普通的方法(无final或abstract修饰)则称之为钩子。
** 队列同步器是基于模板方法模式的 **
4.3.2.15 观察者模式 - 行为模式
Defines a one-to-many dependency between objects so that when one object changes state, all its dependents are notified and updated automatically.
定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
4.3.2.16 迭代模式 - 行为模式
Provide a way to access the elements of an aggregate object sequentially without exposing its underlying representation.
它提供一种方法访问一个容器对象中各个元素,而又不需要暴露该对象的内部细节
4.3.2.17 责任链模式 - 行为模式
It avoids attaching the sender of a request to its receiver, giving this way other objects the possibility of handling the request too.
The objects become parts of a chain and the request is sent from one object to another across the chain until one of the objects will handle it.
使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止。
4.3.2.18 命令模式 - 行为模式
encapsulate a request in an object
allows the parameterization of clients with different requests
allows saving the requests in a queue
将一个请求封装为一个对象,从而使你可用不同的请求对客户进行参数化;对请求排队或者记录请求日志,以及支持可撤消的操作。命令模式又称为动作(Action)模式或事务(Transaction)模式。
命令模式的本质是: 封装请求
4.3.2.19 备忘录模式 - 行为模式
The intent of this pattern is to capture the internal state of an object without violating encapsulation and thus providing a mean for restoring the object into initial state when needed.
备忘录模式: 在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。这样就可以将该对象恢复到原先保存的状态。
备忘录模式又叫做快照模式(Snapshot Pattern)或Token模式,是对象的行为模式。
备忘录对象是一个用来存储另外一个对象内部状态的快照的对象。备忘录模式的用意是在不破坏封装的条件下,将一个对象的状态捕捉(Capture)住,并外部化,存储起来,从而可以在将来合适的时候把这个对象还原到存储起来的状态。备忘录模式常常与命令模式和迭代子模式一同使用。
4.3.2.20 []状态模式 - 行为模式](http://blog.csdn.net/paincupid/article/details/46984077)
Allow an object to alter its behavior when its internal state changes. The object will appear to change its class.主要解决的是当控制一个对象状态转换的条件表达式过于复杂时的情况。把状态的判断逻辑转移到表示不同的一系列类当中,可以把复杂的逻辑判断简单化。
状态模式:当一个对象的内在状态改变时允许改变其行为,这个对象看起来像是改变了其类。
4.3.2.21 访问者模式 - 行为模式
Represents an operation to be performed on the elements of an object structure. Visitor lets you define a new operation without changing the classes of the elements on which it operates.
访问者模式:访问者模式是对象的行为模式。访问者模式的目的是封装一些施加于某种数据结构元素之上的操作。一旦这些操作需要修改的话,接受这个操作的数据结构则可以保持不变。
4.3.2.22 中介者模式 - 行为模式
Define an object that encapsulates how a set of objects interact. Mediator promotes loose coupling by keeping objects from referring to each other explicitly, and it lets you vary their interaction independently.
中介者模式:定义一个中介对象来封装系列对象之间的交互。中介者使各个对象不需要显示地相互引用,从而使其耦合性松散,而且可以独立地改变他们之间的交互。
中介者模式的本质在于“封装交互”
中介者模式的目的,就是封装多个对象的交互,这些交互的多在中介者对象里实现。 只要是实现封装对象的交互,就可以使用中介者模式,不必拘泥于模式结构。
4.3.2.23 解释器模式 - 行为模式
Given a language, define a representation for its grammar along with an interpreter that uses the representation to interpret sentences in the language. Map a domain to a language, the language to a grammar, and the grammar to a hierarchical object-oriented design
解释器模式: 给定一个语言,定义它的文法的一种表示,并定义一种解释器,这个解释器使用该表示来解释语言中的句子。
4.3.2.24 空对象模式 - 行为模式
Provide an object as a surrogate for the lack of an object of a given type.
空对象模式: 提供一个对象,作为一个缺少类型对象的代理。
4、其它优化
一般来说,要出现死锁问题需要满足以下条件:
- 1.互斥条件:一个资源每次只能被一个线程使用。
- 2.请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
- 3.不剥夺条件:进程已获得的资源,在未使用完之前,不能强行剥夺。
- 4.循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
只要破坏死锁 4 个必要条件之一中的任何一个,死锁问题就能被解决。
五、Java并行程序优化建议
并行程序优化概述
5.1、SimpleDateFormat线程不安全
使用Joda-Time类库
5.2、估算线程池大小的经验公式
Nthreads=NcpuUcpu(1+W/C)
Ncpu=CPU数量
Ucpu=目标CPU的使用率,Ucpu的值在0~1之间
W/C=等待时间与计算时间的比率
5.3 锁机制对比
5.3.1 锁知识储备
5.3.1.1
Java对象的内存布局
Bit意为“位”或“比特”,是计算机运算的基础;
Byte意为“字节”,是计算机文件大小的基本计算单位;
Bit 位
Byte (字节)
1B=8 Bit
1KB=1024B
1MB=1024KB
Java对象的内存布局:对象头(Header),实例数据(Instance Data)和对齐填充(Padding)。
虚拟机的对象头包括两部分信息,第一部分用于存储对象自身的运行时数据,如hashCode、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等。这部分数据的长度在32位和64的虚拟机(未开启指针压缩)中分别为4B和8B,官方称之为”Mark Word”。
对象的另一部分是类型指针(klass),即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是那个类的实例。另外如果对象是一个Java数组,那再对象头中还必须有一块用于记录数组长度的数据,因为虚拟机可以通过普通Java对象的元数据信息确定Java对象的大小,但是从数组的元数据中却无法确定数组的大小。
对象头在32位系统上占用8B,64位系统上占16B。 无论是32位系统还是64位系统,对象都采用8字节对齐。Java在64位模式下开启指针压缩,比32位模式下,头部会大4B(mark区域变位8B,kclass区域被压缩),如果没有开启指针压缩,头部会大8B(mark和kclass都是8B),换句话说,
HotSpot的对齐方式为8字节对齐:(对象头+实例数据+padding)%8 等于0 且 0<=padding<8。以下说明都是以HotSpot为基准。
5.3.1.2 synchronized
synchronized给出的答案是在软件层面依赖JVM,而Lock给出的方案是在硬件层面依赖特殊的CPU指令。
synrhronized使用广泛。其应用层的语义是可以把任何一个非null对象作为"锁",
当synchronized作用在方法上时,锁住的便是对象实例(this);
当作用在静态方法时锁住的便是对象对应的Class实例,因为Class数据存在于永久带,因此静态方法锁相当于该类的一个全局锁;
当synchronized作用于某一个对象实例时,锁住的便是对应的代码块。
在HotSpot JVM实现中,锁有个专门的名字:对象监视器。
5.3.1.3 线程状态及状态转换
当多个线程同时请求某个对象监视器时,对象监视器会设置几种状态用来区分请求的线程:
Contention List:所有请求锁的线程将被首先放置到该竞争队列
Entry List:Contention List中那些有资格成为候选人的线程被移到Entry List
Wait Set:那些调用wait方法被阻塞的线程被放置到Wait Set
OnDeck:任何时刻最多只能有一个线程正在竞争锁,该线程称为OnDeck
Owner:获得锁的线程称为Owner
!Owner:释放锁的线程
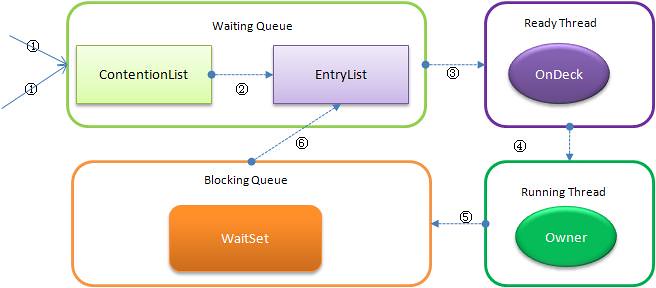
5.3.1.4 重入锁机制
重入锁机制:每个锁都关联一个请求计数器和一个占有他的线程,当请求计数器为0时,这个锁可以被认为是unheld的,当一个线程请求一个unheld的锁时,JVM记录锁的拥有者,并把锁的请求计数加1,如果同一个线程再次请求这个锁时,请求计数器就会增加,当该线程退出syncronized块时,计数器减1,当计数器为0时,锁被释放(这就保证了锁是可重入的,不会发生死锁的情况)。
5.3.1.5 同步的基础
Java中的每一个对象都可以作为锁。
对于同步方法,锁是当前实例对象。
对于静态同步方法,锁是当前对象的Class对象。
对于同步方法块,锁是Synchonized括号里配置的对象。
当一个线程试图访问同步代码块时,它首先必须得到锁,退出或抛出异常时必须释放锁。
5.3.1.6 同步的原理
JVM规范规定JVM基于进入和退出Monitor对象来实现方法同步和代码块同步,但两者的实现细节不一样。
代码块同步是使用monitorenter和monitorexit指令实现,而方法同步是使用另外一种方式实现的,细节在JVM规范里并没有详细说明,但是方法的同步同样可以使用这两个指令来实现。
monitorenter指令是在编译后插入到同步代码块的开始位置,而monitorexit是插入到方法结束处和异常处, JVM要保证每个monitorenter必须有对应的monitorexit与之配对。
任何对象都有一个 monitor 与之关联,当且一个monitor 被持有后,它将处于锁定状态。线程执行到 monitorenter 指令时,将会尝试获取对象所对应的 monitor 的所有权,即尝试获得对象的锁。
5.3.1.7 对象头
锁存在Java对象头里。如果对象是数组类型,则虚拟机用3个Word(字宽)存储对象头,如果对象是非数组类型,则用2字宽存储对象头。在32位虚拟机中,一字宽等于四字节,即32bit。(下面这个表格讲的很清楚)
| 长度 | 内容 | 说明 |
|---|---|---|
| 32/64bit | Mark Word | 存储对象的hashCode或锁信息等。 |
| 32/64bit | Class Metadata Address | 存储到对象类型数据的指针 |
| 32/64bit | Array length | 数组的长度(如果当前对象是数组) |
Java对象头里的Mark Word里默认存储对象的HashCode,分代年龄和锁标记位。
32位JVM的Mark Word的默认存储结构如下:
| 25 bit | 4bit | 1bit 是否是偏向锁 | 2bit 锁标志位 | |
|---|---|---|---|---|
| 无锁状态 | 对象的hashCode | 对象分代年龄 | 0 | 01 |
在运行期间Mark Word里存储的数据会随着锁标志位的变化而变化。Mark Word可能变化为存储以下4种数据:
| 锁状态 | 25 bit | 4 bit | 1 bit | 2 bit | |
| 23 bit | 2 bit | 是否是偏向锁 | 锁标志位 | ||
| 偏向锁 | 线程ID | Epoch | 对象分代年龄 | 1 | 01 |
| 轻量级锁 | 指向栈中锁记录的指针 | 00 | |||
| 重量级锁 | 指向互斥量(重量级锁)的指针 | 10 | |||
| GC标记 | 空 | 11 | |||
在64位虚拟机下,Mark Word是64bit大小的,其存储结构如下:
| 锁状态 | 25 bit | 31 bit | 1 bit | 4 bit | 1 bit | 2 bit |
| cms_free | 分代年龄 | 偏向锁 | 锁标志位 | |||
| 无锁 | unused | hashCode | 0 | 01 | ||
| 偏向锁 | ThreadID(54bit) ThreadID(54bit) Epoch(2bit) | 1 | 01 | |||
5.3.1.8 锁的升级
Java SE1.6里锁一共有四种状态,无锁状态,偏向锁状态,轻量级锁状态和重量级锁状态,它会随着竞争情况逐渐升级。
锁可以升级但不能降级,意味着偏向锁升级成轻量级锁后不能降级成偏向锁。
5.3.2 自旋锁(Spin Lock)
在一个线程获取锁的时候,先进行自旋,尝试。虽然对ContentionList中的线程不尽公平,但是效率可以大大提升。
那些处于ContetionList、EntryList、WaitSet中的线程均处于阻塞状态,阻塞操作由操作系统完成(在Linxu下通过pthread_mutex_lock函数)。
线程被阻塞后便进入内核(Linux)调度状态,这个会导致系统在用户态与内核态之间来回切换,严重影响锁的性能
缓解上述问题的办法便是自旋,其原理是:
- 当发生争用时,若Owner线程能在很短的时间内释放锁,则那些正在争用线程可以稍微等一等(自旋),在Owner线程释放锁后,争用线程可能会立即得到锁,从而避免了系统阻塞。
- 但Owner运行的时间可能会超出了临界值,争用线程自旋一段时间后还是无法获得锁,这时争用线程则会停止自旋进入阻塞状态(后退)。
基本思路就是自旋,不成功再阻塞,尽量降低阻塞的可能性,这对那些执行时间很短的代码块来说有非常重要的性能提高。
自旋锁有个更贴切的名字:自旋-指数后退锁,也即复合锁。很显然,自旋在多处理器上才有意义。
自旋锁详细介绍
还有个问题是,线程自旋时做些啥?其实啥都不做,可以执行几次for循环,可以执行几条空的汇编指令,目的是占着CPU不放,等待获取锁的机会。所以说,自旋是把双刃剑,如果旋的时间过长会影响整体性能,时间过短又达不到延迟阻塞的目的。显然,自旋的周期选择显得非常重要,但这与操作系统、硬件体系、系统的负载等诸多场景相关,很难选择,如果选择不当,不但性能得不到提高,可能还会下降,因此大家普遍认为自旋锁不具有扩展性。
对自旋锁周期的选择上,HotSpot认为最佳时间应是一个线程上下文切换的时间,但目前并没有做到。
经过调查,目前只是通过汇编暂停了几个CPU周期,除了自旋周期选择,HotSpot还进行许多其他的自旋优化策略,具体如下:
如果平均负载小于CPUs则一直自旋
如果有超过(CPUs/2)个线程正在自旋,则后来线程直接阻塞
如果正在自旋的线程发现Owner发生了变化则延迟自旋时间(自旋计数)或进入阻塞
如果CPU处于节电模式则停止自旋
自旋时间的最坏情况是CPU的存储延迟(CPU A存储了一个数据,到CPU B得知这个数据直接的时间差)
自旋时会适当放弃线程优先级之间的差异
那synchronized实现何时使用了自旋锁?
答案是在线程进入ContentionList时,也即第一步操作前。
线程在进入等待队列时首先进行自旋尝试获得锁,如果不成功再进入等待队列。这对那些已经在等待队列中的线程来说,稍微显得不公平。
还有一个不公平的地方是自旋线程可能会抢占了Ready线程的锁。自旋锁由每个监视对象维护,每个监视对象一个。
jdk1.6可配置自旋锁开关,jdk1.7参数被取消,由虚拟机自动调整
在JDK1.6中,Java虚拟机提供-XX:+UseSpinning参数来开启自旋锁,使用-XX:PreBlockSpin参数来设置自旋锁等待的次数。
在JDK1.7开始,自旋锁的参数被取消,虚拟机不再支持由用户配置自旋锁,自旋锁总是会执行,自旋锁次数也由虚拟机自动调整。
5.3.3 偏向锁(Biased Lock)
5.3.3.1 偏向锁目的
偏向锁(Biased Lock)主要解决无竞争下的锁性能问题.
首先我们看下无竞争下锁存在什么问题:
按照之前的HotSpot设计,每次加锁/解锁都会涉及到一些CAS操作(比如对等待队列的CAS操作),CAS操作会延迟本地调用。
偏向锁通过消除资源无竞争情况下的同步原语,进一步提高了程序的运行性能。
偏向锁会偏向于第一个访问锁的线程,如果在接下来的运行过程中,该锁没有被其他的线程访问,则持有偏向锁的线程将永远不需要触发同步。
如果在运行过程中,遇到了其他线程抢占锁,则持有偏向锁的线程会被挂起,JVM会尝试消除它身上的偏向锁,将锁恢复到标准的轻量级锁。
5.3.3.2 偏向锁流程
偏向锁,简单的讲,就是在锁对象的对象头中有个ThreaddId字段,这个字段如果是空的,第一次获取锁的时候,就将自身的ThreadId写入到锁的ThreadId字段内,将锁头内的是否偏向锁的状态位置1.
这样下次获取锁的时候,直接检查ThreadId是否和自身线程Id一致,如果一致,则认为当前线程已经获取了锁,因此不需再次获取锁,略过了轻量级锁和重量级锁的加锁阶段。提高了效率。
但是偏向锁也有一个问题,就是当锁有竞争关系的时候,需要解除偏向锁,使锁进入竞争的状态。
一旦偏向锁冲突,双方都会升级为轻量级锁。
在JVM中使用-XX:+UseBiasedLocking
在激烈竞争的场合,可以尝试使用 -XX:-UseBiastedLocking 参数禁用偏向锁。
5.3.4 轻量级锁
轻量级锁就是为了在无多线程竞争的环境中使用CAS来代替mutex,一旦发生竞争,两条以上线程争用一个锁就会膨胀。
轻量级锁会一直保持,唤醒总是发生在轻量级锁解锁的时候,因为加锁的时候已经成功CAS操作;而CAS失败的线程,会立即锁膨胀,并阻塞等待唤醒。
轻量级锁加锁
线程在执行同步块之前,JVM会先在当前线程的栈桢中创建用于存储锁记录的空间,并将对象头中的Mark Word复制到锁记录中,官方称为Displaced Mark Word。然后线程尝试使用CAS将对象头中的Mark Word替换为指向锁记录的指针。如果成功,当前线程获得锁,如果失败,表示其他线程竞争锁,当前线程便尝试使用自旋来获取锁。
(我觉得和偏向锁差不多,只不过粒度大了。相同处:把"对象头"换成"存储锁记录的空间",把"ThreadId"换成了"Mark Word")
轻量级锁解锁:轻量级解锁时,会使用原子的CAS操作来将Displaced Mark Word替换回到对象头,如果成功,则表示没有竞争发生。如果失败,表示当前锁存在竞争,锁就会膨胀成重量级锁。
如果有两条以上的线程争用同一个锁,那轻量级锁就不再有效,要膨胀为重量级锁,锁标志的状态值变为”10”,Mark Word中存储的就是指向重量级(互斥量)的指针。
轻量级锁具体实现
一个线程能够通过两种方式锁住一个对象:
1、通过膨胀一个处于无锁状态(状态位001)的对象获得该对象的锁;
2、对象已经处于膨胀状态(状态位00)但LockWord指向的monitor record的Owner字段为NULL,
则可以直接通过CAS原子指令尝试将Owner设置为自己的标识来获得锁。
总结
轻量级锁能提高程序同步性能的依据是“对于绝大部分的锁,在整个同步周期内都是不存在竞争的”,这是一个经验数据。如果没有竞争,轻量级锁使用CAS操作避免了使用互斥量的开销,但如果存在锁竞争,除了互斥量的开销外,还额外发生了CAS操作,因此在有竞争的情况下,轻量级锁会比传统的重量级锁更慢。
偏向锁与轻量级锁理念上的区别
轻量级锁:在无竞争的情况下使用CAS操作去消除同步使用的互斥量。
偏向锁:在无竞争的情况下把整个同步都消除掉,连CAS操作都不做了。
注意:偏向锁的锁标记位和无锁是一样的,都是01,但是有单独一位偏向标记设置是否偏向锁。
再复习一下,轻量级锁00,重量级锁10,GC标记11,无锁 01.
5.3.5 锁的优缺点对比
| 锁 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 偏向锁 | 加锁和解锁不需要额外的消耗,和执行非同步方法比仅存在纳秒级的差距。 | 如果线程间存在锁竞争,会带来额外的锁撤销的消耗。 | 适用于只有一个线程访问同步块场景。 |
| 轻量级锁 | 竞争的线程不会阻塞,提高了程序的响应速度。 | 如果始终得不到锁竞争的线程使用自旋会消耗CPU。 | 追求响应时间。同步块执行速度非常快。 |
| 重量级锁 | 线程竞争不使用自旋,不会消耗CPU。 | 线程阻塞,响应时间缓慢。 | 追求吞吐量。同步块执行速度较长。 |
5.3.6 类锁和对象锁
类锁:在方法上加上static synchronized的锁,或者synchronized(xxx.class)的锁。如下代码中的method1和method2:
对象锁:参考method4, method5,method6.
public class LockStrategy{
public Object object1 = new Object();
public static synchronized void method1(){}
public void method2(){
synchronized(LockStrategy.class){}
}
public synchronized void method4(){}
public void method5(){
synchronized(this){}
}
public void method6(){
synchronized(object1){}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
下面做一道习题来加深一下对对象锁和类锁的理解.
有一个类这样定义:
public class SynchronizedTest{
public synchronized void method1(){}
public synchronized void method2(){}
public static synchronized void method3(){}
public static synchronized void method4(){}
}
- 1
- 2
- 3
- 4
- 5
- 6
那么,有SynchronizedTest的两个实例a和b,对于一下的几个选项有哪些能被一个以上的线程同时访问呢?
A. a.method1() vs. a.method2()
B. a.method1() vs. b.method1()
C. a.method3() vs. b.method4()
D. a.method3() vs. b.method3()
E. a.method1() vs. a.method3()
- 1
- 2
- 3
- 4
- 5
答案是什么呢?BE
根据下面的代码自行修改,分别验证下面的几种情况:
synchronized(class)
synchronized(this)
->线程各自获取monitor,不会有等待.
synchronized(this)
synchronized(this)
->如果不同线程监视同一个实例对象,就会等待,如果不同的实例,不会等待.
synchronized(class)
synchronized(class)
->如果不同线程监视同一个实例或者不同的实例对象,都会等待.
5.3.6 读写锁
读写锁 ReadWriteLock读写锁维护了一对相关的锁,一个用于只读操作,一个用于写入操作。只要没有writer,读取锁可以由多个reader线程同时保持。写入锁是独占的。
与互斥锁相比,使用读写锁能否提升性能则取决于读写操作期间读取数据相对于修改数据的频率,以及数据的争用——即在同一时间试图对该数据执行读取或写入操作的线程数。
读写锁适用于读多写少的情况。
可重入读写锁 ReentrantReadWriteLock
属性ReentrantReadWriteLock 也是基于 AbstractQueuedSynchronizer 实现的
AQS以单个 int 类型的原子变量来表示其状态,定义了4个抽象方法( tryAcquire(int)、tryRelease(int)、tryAcquireShared(int)、tryReleaseShared(int),前两个方法用于独占/排他模式,后两个用于共享模式 )留给子类实现,用于自定义同步器的行为以实现特定的功能。
一点思考问题
- AQS只有一个状态,那么如何表示 多个读锁 与 单个写锁 呢?
- ReentrantLock 里,状态值表示重入计数,现在如何在AQS里表示每个读锁、写锁的重入次数呢?
- 如何实现读锁、写锁的公平性呢?
一点提示
- 一个状态是没法既表示读锁,又表示写锁的,不够用啊,那就辦成两份用了,状态的高位部分表示读锁,低位表示写锁,由于写锁只有一个,所以写锁的重入计数也解决了,这也会导致写锁可重入的次数减小。
- 由于读锁可以同时有多个,肯定不能再用辦成两份用的方法来处理了,但我们有 ThreadLocal,可以把线程重入读锁的次数作为值存在 ThreadLocal 里。
- 对于公平性的实现,可以通过AQS的等待队列和它的抽象方法来控制,在状态值的另一半里存储当前持有读锁的线程数。如果读线程申请读锁,当前写锁重入次数不为 0 时,则等待,否则可以马上分配;如果是写线程申请写锁,当前状态为 0 则可以马上分配,否则等待。
辦成两份AQS 的状态是32位(int 类型)的,辦成两份,读锁用高16位,表示持有读锁的线程数(sharedCount),写锁低16位,表示写锁的重入次数 (exclusiveCount)。状态值为 0 表示锁空闲,sharedCount不为 0 表示分配了读锁,exclusiveCount 不为 0 表示分配了写锁,sharedCount和exclusiveCount 肯定不会同时不为 0。
Be wary of readers/writer locks. If there is a novice error when trying to break up a lock, it is this: seeing that a data structure is frequently accessed for reads and infrequently accessed for writes, one may be tempted to replace a mutex guarding the structure with a readers/writer lock to allow for concurrent readers. This seems reasonable, but unless the hold time for the lock is long, this solution will scale no better (and indeed, may scale worse) than having a single lock. Why? Because the state associated with the readers/writer lock must itself be updated atomically, and in the absence of a more sophisticated (and less space-efficient) synchronization primitive, a readers/writer lock will use a single word of memory to store the number of readers. Because the number of readers must be updated atomically, acquiring the lock as a reader requires the same bus transaction—a read-to-own—as acquiring a mutex, and contention on that line can hurt every bit as much.
There are still many situations where long hold times (e.g., performing I/O under a lock as reader) more than pay for any memory contention, but one should be sure to gather data to make sure that it is having the desired effect on scalability. Even in those situations where a readers/writer lock is appropriate, an additional note of caution is warranted around blocking semantics. If, for example, the lock implementation blocks new readers when a writer is blocked (a common paradigm to avoid writer starvation), one cannot recursively acquire a lock as reader: if a writer blocks between the initial acquisition as reader and the recursive acquisition as reader, deadlock will result when the recursive acquisition is blocked. All of this is not to say that readers/writer locks shouldn’t be used—just that they shouldn’t be romanticized.
初学者常干的一件事情是,一见到某个共享数据结构频繁读而很少写,就把mutex替换为rwlock。甚至首选rwlock来保护共享状态,这是不正确的。
-
1、从正确性方面来说,一种典型的易犯错误是在持有read lock的时候修改了共享数据。这通常发生在程序的维护阶段,为了新增功能,程序猿不小心在原来read lock保护的函数中调用了会修改状态的函数。这种错误的后果跟无保护并发读写共享数据是一样的。
-
2、从性能方面来说,读写锁不见得比普通mutex更高效。无论如何reader lock加锁的开销不会比mutex lock小,因为他要更新当前reader的数目。如果临界区很小,锁竞争不激烈,那么mutex往往会更快。(XXL:如果临界区设置的很大,说明程序本身是有问题的)
-
3、reader lock可能允许提升(upgrade)为writer lock,也可能不允许提升(Pthread rwlock不允许提升)。如果允许把读锁提升为写锁,后果跟使用recursive mutex(可重入)一样,会造成程序其他问题。如果不允许提升,后果跟使用non-recursive mutex一样,会造成死锁。我宁愿程序死锁,留个“全尸”好查验。
-
4、通常reader lock是可重入的,writer lock是不可重入的。但是为了防止writer饥饿,writer lock通常会阻塞后来的reader lock,因此reader lock在重入的时候可能死锁。另外,在追求低延迟读取的场合也不适用读写锁。
XXL:补充一下rwlock死锁的问题,线程1获取了读锁,在临界区执行代码;这时,线程2获取写锁,在该锁上等待线程1完成读操作,同时线程2阻塞了后续的读操作;线程1仍在进行剩余读操作,但是它通过函数调用等间接方式,再次获取那个读锁,此时,线程1阻塞,因为线程2已经上了写锁;同时,线程2也在等待线程1释放读锁,才能进行写操作。因此发生了死锁,原因就在于,读锁是可重入的。
假设
1、有writer在等待写锁时,后续的读锁请求会被阻塞
2、允许读锁upgrade成写锁
3、不允许写锁直接downgrade成读锁。
那么在哪些情况下会产生死锁?
e.g.
1、A 获得x的读锁,B获得y的读锁。
2、A获得y的读锁,B获取x的读锁。
3、A获取y的写锁,B获取x的写锁。此时死锁!
1、A 获得x的读锁,B获得x的读锁
2、A企图upgrade成写锁,B也做如此操作
Java里的读写锁里的读锁有什么用?
如果一个线程给某个对象加了读锁,另一个线程不能再给这个对象+写锁。写锁和读锁是互斥的
读锁:共享锁
写锁:排它锁
http://queue.acm.org/detail.cfm?id=1454462
java 可重入读写锁 ReentrantReadWriteLock 详解
5.4 增加程序并行性
5.4.1 并发计数器 LongAdders
5.4.2 jdk8针对Thread类更新
5.4.3 Fork/Join框架
5.4.4 Executor框架
5.5 队列同步器(AbstractQueuedSynchronizer)
共享式的获取同步状态和独占式获取的主要区别:在同一时刻可以有多个线程获取到同步状态
5.5 JDK类库使用
六、JVM性能测试及监控
6.1 监控计算机设备层
Linux
6.1.1 CPU 监控
- GNOME System monitor图形化工具
- vmstat命令 (优于iostat,因为vmstat命令滚动的)
- Sar(System Activity Reporter)是目前Linux上最为全面的系统性能分析工具之一
- mpstat命令,以列表的方式展示每个虚拟处理器的CPU
6.1.2 内存 监控
- free命令
- JMap
- atop
- vmstat命令
- Sar工具
6.1.3 磁盘 监控
- iostat命令
- df命令
- vmstat命令
- Sar工具
6.1.4 网络 监控
- Netstat命令
- ifstat工具
- iftop工具
- nload工具
6.2 监控JVM活动
如果GC时间超过1~3秒,或者频繁GC,则必须优化。
如果满足以下指标,则一般不需要进行GC:
- 1、Minor GC 执行时间不到50ms;
- 2、Minor GC 执行不频繁,约10秒一次;
- 3、Full GC 执行时间不到1s
- 4、Full GC 执行频率不算频繁,不低于10分钟1次。
6.2.1 GC垃圾回收报告分析
6.2.1.1 verbosegc
-verbosegc来打印GC的日志。
6.2.1.2 JConsole
JConsole是一个JMX(Java Management Extensions)兼容的GUI工具
七、JVM性能调优
7.1 JVM相关概念
7.2 JVM系统架构
7.3 垃圾回收机制相关
根搜索算法:JVM一般使用的标记算法,把对象的引用看作图结构,由根节点集合出发,不可达的节点即可回收,其中根节点集合包含的如下5种元素:
1、Java栈中的对象引用;
2、本地方法栈中的对象引用;
3、运行时常量池的对象引用;
4、方法区中静态属性的对象引用;
5、所有Class对象;
《Java虚拟机》必知必会——十四个问题总结(内存模型+GC)
7.4 实用JVM实验
八、其他优化建议
九、JDK要看的源码
9.1 AbstractQueuedSychronizer
9.2 ConcurrentMap
9.3 HashMap
9.4 ThreadLocal
9.5 LongAdders
9.6 LongAccumulator
9.7 StampledLock实现乐观锁
9.8 CopyOnWriteArrayList
适用于并发读多写少的场景
9.9 queue
9.9.1 ConcurrentLinkedQueue
9.9.2 BlokingQueue
9.9.2.1 LinkedBlokingQueue
9.9.2.2 ArrayBlockingQueue
9.9.2.3 PriorityBlockingQueue
9.9.2.4 DelayQueue
9.9.2.5 SynchronousQueue
9.10 JDK并发包
9.10.1 CountDownLatch
9.10.2 CyclicBarrier
9.10.3 Semaphore
9.7 FIFO
Reference
Java中的锁机制 synchronized & 偏向锁 & 轻量级锁 & 重量级锁 & 各自优缺点及场景 & AtomicReference
Java对象锁和类锁全面解析(多线程synchronized关键字)
Java对象锁和类锁全面解析(多线程synchronized关键字)
synchronized(this)与synchronized(class)
Java synchronized中设定监视器时易犯的错

