
- 1LeetCode分享-字符串匹配_leetcode 单词匹配
- 2ABC193 C - Unexpressed(思维+暴力)_[abc193c] unexpressed
- 3AI之DL:人工智能领域—深度学习的简介(包括相关术语概念)、常用算法、常用框架、应用场景之详细攻略_dl深度学习
- 4静态代码块,静态方法,构造方法的执行顺序_静态方法和静态代码块的执行顺序
- 5window安装php swoole,如何在windows系统下安装swoole(Docker环境)
- 6系列文章 如何使用PaddleDetection做一个完整项目(三)_paddledetection实战项目
- 7[DOCKER]Windows设置daemon.json内容_windows docker tool如何配置daemon.json
- 8基于GEC6818的电子相册_基于gec6818电子相册
- 9燃气智能巡检系统与GIS管网巡检系统App
- 10docker系列学习(一):整体认识_chengcode docker
【愚公系列】2023年07月 Pandas数据分析(Series 和 Index)_pandas series index
赞
踩
前言
Pandas 是一种用于数据分析的 Python 库,它提供了两个基本的数据结构——Series 和 DataFrame。
1.Series
Series 是一种一维数组,可以存储任意类型的数据 (整数、浮点数、字符串、Python 对象等),并且每个值都有一个索引。索引在 Pandas 中非常重要,它是用来对数据进行标识和访问数据的。Series 对象可以通过传递一个列表或数组创建。例如:
import pandas as pd
data = [1, 2, 3, 4]
s = pd.Series(data)
print(s)
- 1
- 2
- 3
- 4
- 5
输出结果:
0 1
1 2
2 3
3 4
dtype: int64
- 1
- 2
- 3
- 4
- 5
Index 对象是 Pandas 中另一个重要的数据结构,它可以用来表示 Series 或 DataFrame 中的行或列的标签。Index 对象是不可变的,因此可以用作字典中的键。Index 对象可以通过传递一个列表或数组创建。例如:
import pandas as pd
data = [1, 2, 3, 4]
index = ['a', 'b', 'c', 'd']
s = pd.Series(data, index=index)
print(s)
- 1
- 2
- 3
- 4
- 5
- 6
输出结果:
a 1
b 2
c 3
d 4
dtype: int64
- 1
- 2
- 3
- 4
- 5
在上面的例子中,我们使用了一个列表来创建 Series,并将 Index 对象设置为 [‘a’, ‘b’, ‘c’, ‘d’]。这样,我们可以通过这些标签来访问 Series 中的值,例如 s[‘a’] 返回 1。
2.DataFrame
Pandas中的DataFrame是一种二维数组对象,可以存储多种类型的数据,并且可以在每个轴上指定标签。以下是DataFrame 的基本使用:
- 创建DataFrame
可以通过传入一个字典、列表、二维数组或其他数据类型来创建DataFrame。
例如,创建一个包含三个列和四个行的DataFrame:
import pandas as pd
data = {'name': ['Tom', 'Jack', 'Steve', 'Ricky'],
'age': [28, 34, 29, 42],
'gender': ['M', 'M', 'M', 'F']}
df = pd.DataFrame(data)
print(df)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出:
name age gender
0 Tom 28 M
1 Jack 34 M
2 Steve 29 M
3 Ricky 42 F
- 1
- 2
- 3
- 4
- 5
- 查看DataFrame
可以使用head()和tail()方法查看DataFrame的前几行和后几行。
例如,查看DataFrame的前两行:
print(df.head(2))
- 1
输出:
name age gender
0 Tom 28 M
1 Jack 34 M
- 1
- 2
- 3
可以使用shape属性查看DataFrame的维度大小:
print(df.shape)
- 1
输出:
(4, 3)
- 1
- 索引和选择
可以使用列名称进行列的选择,并且可以使用切片来选择行。
例如,选择name列:
print(df['name'])
- 1
输出:
0 Tom
1 Jack
2 Steve
3 Ricky
Name: name, dtype: object
- 1
- 2
- 3
- 4
- 5
选择前两行:
print(df[:2])
- 1
输出:
name age gender
0 Tom 28 M
1 Jack 34 M
- 1
- 2
- 3
- 修改DataFrame
可以通过赋值的方式修改DataFrame中的值。
例如,将第一行的年龄改为30:
df.loc[0, 'age'] = 30
print(df)
- 1
- 2
输出:
name age gender
0 Tom 30 M
1 Jack 34 M
2 Steve 29 M
3 Ricky 42 F
- 1
- 2
- 3
- 4
- 5
- 删除DataFrame
可以使用drop()方法删除DataFrame中的行或列。
例如,删除gender列:
df = df.drop('gender', axis=1)
print(df)
- 1
- 2
输出:
name age
0 Tom 30
1 Jack 34
2 Steve 29
3 Ricky 42
- 1
- 2
- 3
- 4
- 5
以上是Pandas中DataFrame的基本使用,很多高级用法和技巧需要结合实际业务场景来使用。
一、Pandas 数据分析(Series 和 Index)
1.Series原理分析
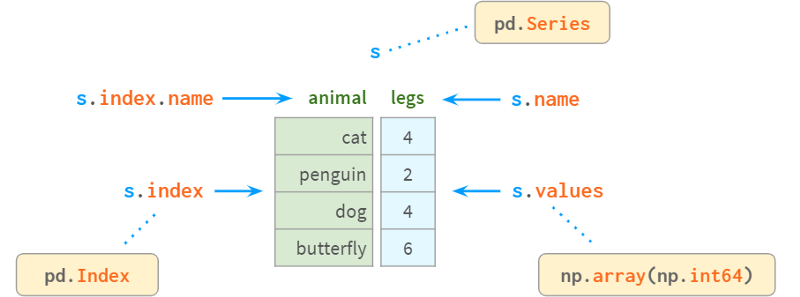
Series是NumPy中的一维数组,是表示其列的DataFrame的基本组成部分。
在内部,Series将值存储在普通的NumPy vector中。因此,它继承了它的优点(紧凑的内存布局、快速的随机访问)和缺点(类型同质、缓慢的删除和插入)。最重要的是,Series允许使用类似于字典的结构index通过label访问它的值。标签可以是任何类型(通常是字符串和时间戳)。它们不必是唯一的,但唯一性是提高查找速度所必需的,许多操作都假定唯一性。

如你所见,现在每个元素都可以通过两种替代方式寻址:通过label(=使用索引)和通过position(=不使用索引):

按“位置”寻址有时被称为“位置索引”,这只是增加了混淆。
一对方括号是不够的。特别是:
- S[2:3]不是解决元素2最方便的方式
- 如果名称恰好是整数,s[1:3]就会产生歧义。它可能意味着名称1到3包含或位置索引1到3不包含。
为了解决这些问题,Pandas还有两种“风格”的方括号,你可以在下面看到:

.loc总是使用标号,并且包含间隔的两端。
.iloc总是使用“位置索引”并排除右端。
使用方括号而不是圆括号的目的是为了访问Python的切片约定:你可以使用单个或双冒号,其含义是熟悉的start:stop:step。像往常一样,缺少开始(结束)意味着从序列的开始(到结束)。step参数允许使用s.iloc[::2]引用偶数行,并使用s[‘Paris’:‘Oslo’:-1]以相反的顺序获取元素。
它们还支持布尔索引(使用布尔数组进行索引),如下图所示:
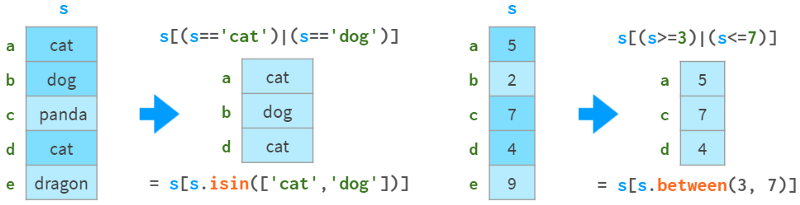
你可以在下图中看到它们如何支持fancy indexing(用整数数组进行索引):

2.索引(Index)
负责通过标签获取元素的对象称为index。它非常快:无论你有5行还是50亿行,你都可以在常量时间内获取一行数据。
指数是一个真正的多态生物。默认情况下,当创建一个没有索引的序列(或DataFrame)时,它会初始化为一个惰性对象,类似于Python的range()。和range一样,几乎不使用任何内存,并且与位置索引无法区分。让我们用下面的代码创建一个包含一百万个元素的序列:
>>> s = pd.Series(np.zeros(10**6))
>>> s.index
RangeIndex(start=0, stop=1000000, step=1)
>>> s.index.memory_usage() # in bytes
128 # the same as for Series([0.])
- 1
- 2
- 3
- 4
- 5
现在,如果我们删除一个元素,索引隐式地转换为类似于dict的结构,如下所示:
>>> s.drop(1, inplace=True)
>>> s.index
Int64Index([ 0, 2, 3, 4, 5, 6, 7,
...
999993, 999994, 999995, 999996, 999997, 999998, 999999],
dtype='int64', length=999999)
>>> s.index.memory_usage()
7999992
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
该结构消耗8Mb内存为了摆脱它,回到轻量级的类range结构,添加如下代码:
>>> s.reset_index(drop=True, inplace=True)
>>> s.index
RangeIndex(start=0, stop=999999, step=1)
>>> s.index.memory_usage()
128
- 1
- 2
- 3
- 4
- 5
3.按值查找元素
Series内部由一个NumPy数组和一个类似数组的结构index组成,如下所示:
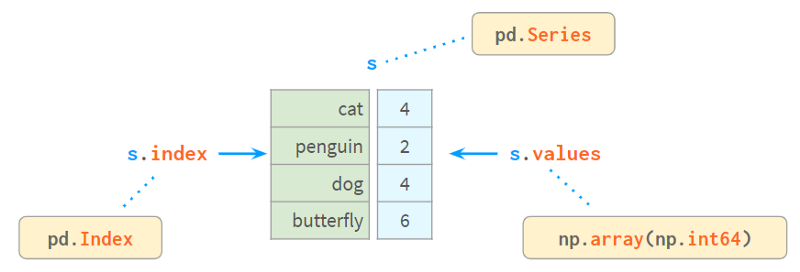
Index提供了一种通过标签查找值的方便方法。那么如何通过值查找标签呢?
s.index[s.tolist().find(x)] # faster for len(s) < 1000
s.index[np.where(s.values==x)[0][0]] # faster for len(s) > 1000
- 1
- 2
可以使用pdi中find()和findall()两个简单的封装器,它们运行速度快(因为它们会根据序列的大小自动选择实际的命令),而且使用起来更方便。代码如下所示:
>>> import pdi
>>> pdi.find(s, 2)
'penguin'
>>> pdi.findall(s, 4)
Index(['cat', 'dog'], dtype='object')
- 1
- 2
- 3
- 4
- 5
4.缺失值
Pandas开发人员特别关注缺失值。通常,你通过向read_csv提供一个标志来接收一个带有NaNs的dataframe。否则,可以在构造函数或赋值运算符中使用None(尽管不同数据类型的实现略有不同,但它仍然有效)。这张图片有助于解释这个概念:
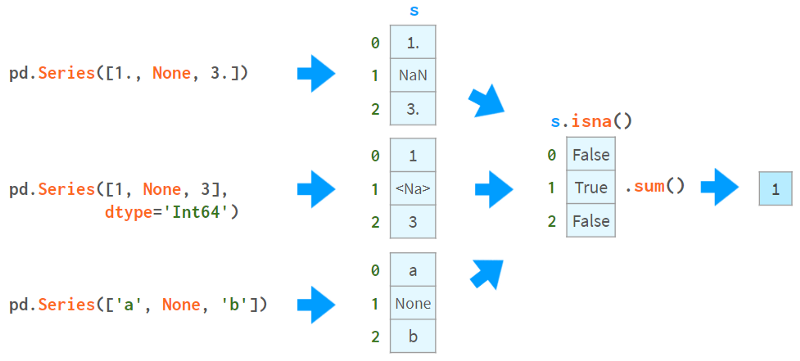
你可以使用NaNs做的第一件事是了解你是否有NaNs。从上图可以看出,isna()生成了一个布尔数组,而.sum()给出了缺失值的总数。
现在你知道了它们的存在,你可以选择用常量值填充它们或通过插值来一次性删除它们,如下所示:
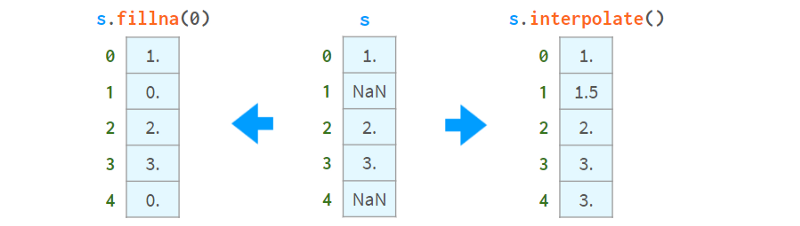
另一方面,你可以继续使用它们。大多数Pandas函数会很高兴地忽略缺失值,如下图所示:
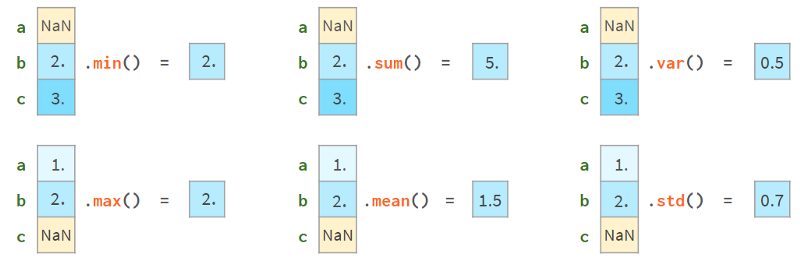
更高级的函数(median、rank、quantile等)也可以做到这一点。
算术运算与索引对齐:
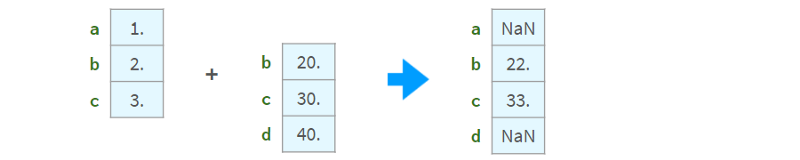
如果索引中存在非唯一值,则结果不一致。不要对索引不唯一的序列使用算术运算。
5.比较
比较有缺失值的数组可能会比较棘手。下面是一个例子:
>>> np.all(pd.Series([1., None, 3.]) ==
pd.Series([1., None, 3.]))
False
>>> np.all(pd.Series([1, None, 3], dtype='Int64') ==
pd.Series([1, None, 3], dtype='Int64'))
True
>>> np.all(pd.Series(['a', None, 'c']) ==
pd.Series(['a', None, 'c']))
False
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
为了正确地比较nan,需要用数组中一定没有的元素替换nan。例如,使用-1或∞:
>>> np.all(s1.fillna(np.inf) == s2.fillna(np.inf)) # works for all dtypes
True
- 1
- 2
或者,更好的做法是使用NumPy或Pandas的标准比较函数:
>>> s = pd.Series([1., None, 3.])
>>> np.array_equal(s.values, s.values, equal_nan=True)
True
>>> len(s.compare(s)) == 0
True
- 1
- 2
- 3
- 4
- 5
这里,compare函数返回一个差异列表(实际上是一个DataFrame), array_equal则直接返回一个布尔值。
当比较混合类型的DataFrames时,NumPy比较失败(issue #19205),而Pandas工作得很好。如下所示:
>>> df = pd.DataFrame({'a': [1., None, 3.], 'b': ['x', None, 'z']})
>>> np.array_equal(df.values, df.values, equal_nan=True)
TypeError
<...>
>>> len(df.compare(df)) == 0
True
- 1
- 2
- 3
- 4
- 5
- 6
6.追加、插入、删除
虽然Series对象被认为是size不可变的,但它可以在原地追加、插入和删除元素,但所有这些操作都是:
慢,因为它们需要为整个对象重新分配内存和更新索引。
非常不方便。
下面是插入值的一种方式和删除值的两种方式:

第二种删除值的方法(通过drop)比较慢,并且在索引中存在非唯一值时可能会导致复杂的错误。
Pandas有df.insert方法,但它只能将列(而不是行)插入到dataframe中(并且对series不起作用)。
添加和插入的另一种方法是使用iloc对DataFrame进行切片,应用必要的转换,然后使用concat将其放回。我实现了一个名为insert的函数,可以自动执行这个过程:

注意(就像在df.insert中一样)插入位置由位置0<=i<=len(s)指定,而不是索引中元素的标签。如下所示:

要按元素的名称插入,可以合并pdi。用pdi查找。插入,如下所示:
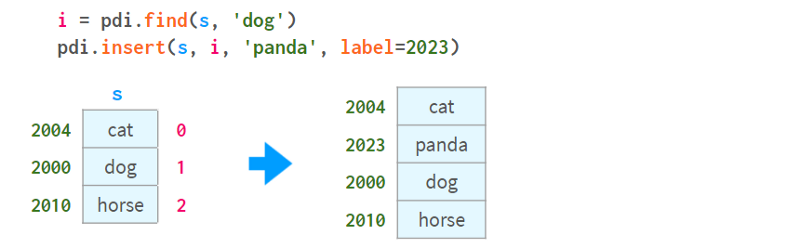
请注意,unlikedf.insert、pdi.insert返回一个副本,而不是原地修改Series/DataFrame
7.统计数据
Pandas提供了全方位的统计函数。它们可以让您了解百万元素序列或DataFrame中的内容,而无需手动滚动数据。
所有Pandas统计函数都会忽略NaNs,如下所示:

注意,Pandas std给出的结果与NumPy std不同,如下所示:
>>> pd.Series([1, 2]).std()
0.7071067811865476
>>> pd.Series([1, 2]).values.std()
0.5
- 1
- 2
- 3
- 4
这是因为NumPy std默认使用N作为分母,而Pandas std默认使用N-1作为分母。两个std都有一个名为ddof (delta degrees of freedom)的参数,NumPy默认为0,Pandas默认为1,这可以使结果一致。N-1是你通常想要的值(在均值未知的情况下估计样本的偏差)。这里有一篇维基百科的文章详细介绍了贝塞尔的修正。
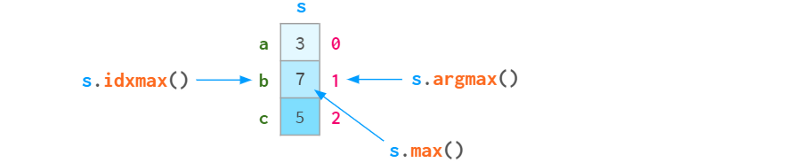
由于序列中的每个元素都可以通过标签或位置索引访问,因此argmin (argmax)有一个姐妹函数idxmin (idxmax),如下图所示:
下面是Pandas的自描述统计函数供参考:
-
std:样本标准差
-
var,无偏方差
-
sem,均值的无偏标准误差
-
quantile分位数,样本分位数(s.quantile(0.5)≈s.median())
-
oode是出现频率最高的值
-
默认为Nlargest和nsmallest,按出现顺序排列
-
diff,第一个离散差分
-
cumsum 和 cumprod、cumulative sum和product
-
cummin和cummax,累积最小值和最大值
以及一些更专业的统计函数:
-
pct_change,当前元素与前一个元素之间的变化百分比
-
skew偏态,无偏态(三阶矩)
-
kurt或kurtosis,无偏峰度(四阶矩)
-
cov、corr和autocorr、协方差、相关和自相关
-
rolling滚动窗口、加权窗口和指数加权窗口
8.重复数据
在检测和处理重复数据时需要特别小心,如下图所示:
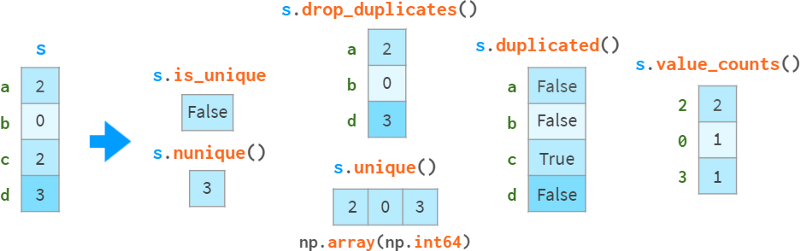
drop_duplicates和duplication可以保留最后一次出现的副本,而不是第一次出现的副本。
请注意,s.a uint()比np快。唯一性(O(N) vs O(NlogN)),它会保留顺序,而不会返回排序结果。独特的。
缺失值被视为普通值,有时可能会导致令人惊讶的结果。
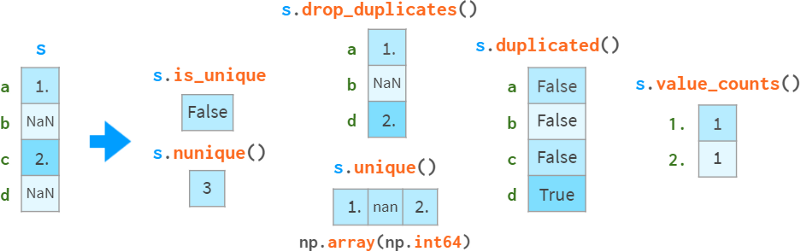
如果你想排除nan,需要显式地这样做。在这个例子中,是s.l opdropna().is_unique == True。
还有一类单调函数,它们的名字是自描述的:
-
s.is_monotonic_increasing ()
-
s.is_monotonic_decreasing ()
-
s._strict_monotonic_increasing ()
-
s._string_monotonic_decreasing ()
-
s.is_monotonic()。这是意料之外的,出于某种原因,这是s.is_monotonic_increasing()。它只对单调递减序列返回False。
9.分组
在数据处理中,一个常见的操作是计算一些统计量,不是针对整个数据集,而是针对其中的某些组。第一步是通过提供将一系列(或一个dataframe)分解为组的标准来定义一个“智能对象”。这个智能对象没有立即的表示,但可以像Series一样查询它,以获得每个组的某个属性,如下图所示:

在这个例子中,我们根据数值除以10的整数部分将序列分成三组。对于每个组,我们请求每个组中元素的和、元素的数量以及平均值。
除了这些聚合函数,您还可以根据特定元素在组中的位置或相对值访问它们。如下所示:
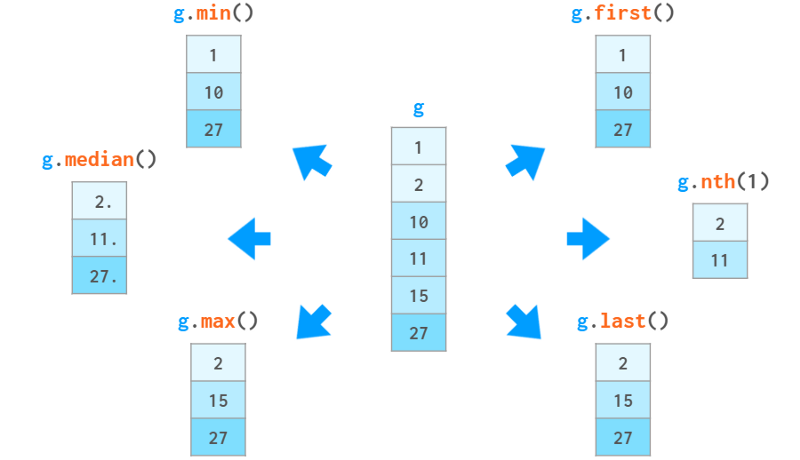
你也可以使用g.ag ([‘min’, ‘max’])一次调用计算多个函数,或者使用g.c describe()一次显示一堆统计函数。
如果这些还不够,你还可以通过自己的Python函数传递数据。它可以是:
一个函数f,它接受一个组x(一个Series对象)并生成一个值(例如sum())与g.eapply (f)一起使用。
一个函数f,它接受一个组x(一个Series对象),并与g.transform(f)生成一个大小与x相同的Series对象(例如cumsum())。

在上面的例子中,输入数据是有序的。groupby不需要这样做。实际上,如果分组中的元素不是连续存储的,它也同样有效,因此它更接近于collections.defaultdict,而不是itertools.groupby。它总是返回一个没有重复项的索引。
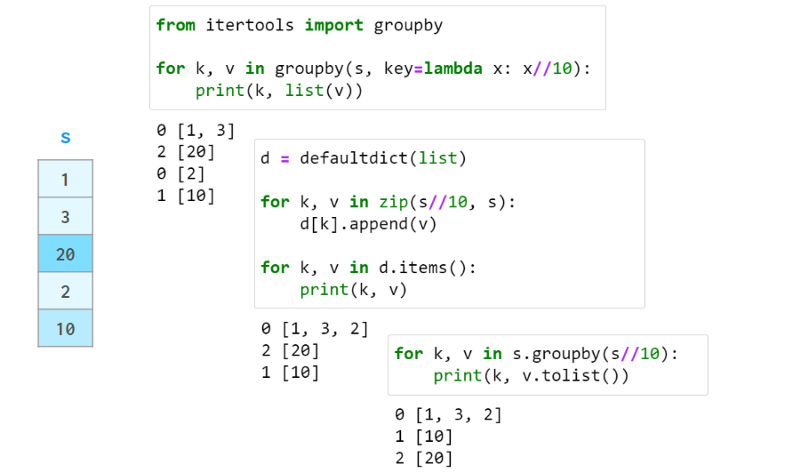
与defaultdict和关系数据库GROUP BY子句不同,Pandas groupby按组名对结果进行排序。可以用sort=False来禁用它。
免责声明:实际上,g.apply(f)比上面描述的更通用:
- 如果f(x)返回与x大小相同的序列,它可以模拟transform
- 如果f(x)返回一系列不同大小或不同的dataframe,则会得到一个具有相应多索引的序列。
但文档警告说,这些使用方法可能比相应的transform和agg方法慢,所以要小心。

