
热门标签
热门文章
- 1Dubbo集群容错方案
- 2npm i 卡在reify:rxjs: timing reifyNode
- 3基于粤嵌gec6818开发板嵌入式电子相册,智能家居,音乐播放,灯光控制,2048游戏_粤嵌开发板相册
- 4python网站开发案例_基于Python-Flask实现的网站例子
- 5【附源码】Java计算机毕业设计校园订餐管理系统(程序+LW+部署)_学校食堂管理系统javaweb课程设计
- 6Ubuntu18.04安装docker和docker-compose_ubuntu18.04安装docker-compose
- 7【Microsoft Message Queuing远程代码执行漏洞(CVE-2023-21554)漏洞修复】
- 8[Python] 机器学习 - 常用数据集(Dataset)之糖尿病(diabetes)数据集介绍,数据可视化和使用案例
- 9Vue3的几款UI组件库:Naive UI、Element Plus、 Ant Design Vue、Arco Design_ant-design-vue3级联组件
- 10模板匹配 解决模板旋转以及重复检测问题_模板匹配如何针对旋转
当前位置: article > 正文
xgboost实现蘑菇数据分类预测demo
作者:小蓝xlanll | 2024-02-16 22:50:38
赞
踩
xgboost实现蘑菇数据分类预测demo
数据集下载:
- import xgboost as xgb
- import numpy as np
- # 自己实现loss function,softmax函数
- def log_reg(y_hat, y):
- p = 1.0 / (1.0 + np.exp(-y_hat))
- g = p - y.get_label()
- h = p * (1.0 - p)
- return g, h
- # 自己实现错误率计算
- def error_rate(y_hat, y):
- return 'error', float(sum(y.get_label() != (y_hat > 0.5))) / len(y_hat)
-
- if __name__ == '__main__':
- # 读取数据
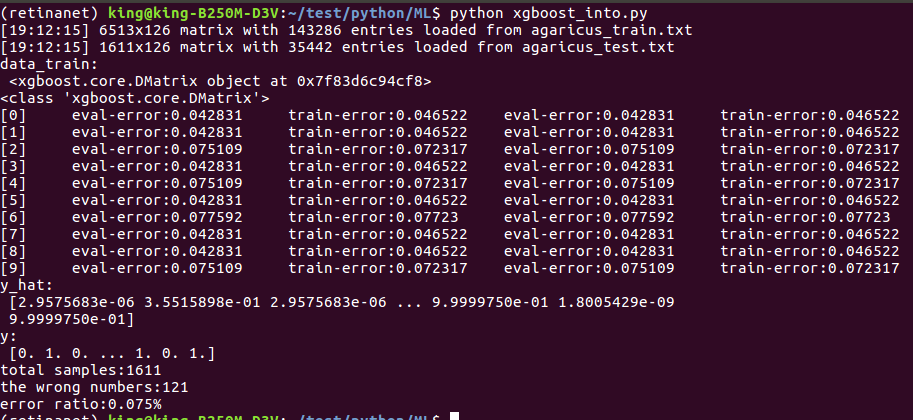
- data_train = xgb.DMatrix('agaricus_train.txt')
- data_test = xgb.DMatrix('agaricus_test.txt')
- print('data_train:\n', data_train)
- print(type(data_train))
-
- # 设定相关参数
- param = {'max_depth':2, 'eta':1, 'silent':1, 'objective':'binary:logistic'}
- # param = {'max_depth':2, 'eta':1, 'silent':1, 'objective':'reg:logistic'}
- watchlist = [(data_test, 'eval'), (data_train, 'train')]
- n_round = 10
- bst = xgb.train(param, data_train, num_boost_round=n_round, evals=watchlist, obj=log_reg, feval=error_rate)
-
- # 计算错误率
- y_hat = bst.predict(data_test)
- y = data_test.get_label()
- print('y_hat:\n', y_hat)
- print('y:\n', y)
-
- error = sum(y != (y_hat > 0.5))
- error_rate = float(error) / len(y_hat)
-
- print('total samples:%d' % len(y_hat))
- print('the wrong numbers:%d' % error)
- print('error ratio:%.3f%%' % error_rate)

我们加入logistic回归作对比:
- import xgboost as xgb
- import numpy as np
- import pandas as pd
- import scipy.sparse
- from sklearn.linear_model import LogisticRegression
- from sklearn.model_selection import train_test_split
-
- # 自己实现loss function,softmax函数
- def log_reg(y_hat, y):
- p = 1.0 / (1.0 + np.exp(-y_hat))
- g = p - y.get_label()
- h = p * (1.0 - p)
- return g, h
- # 自己实现错误率计算
- def error_rate(y_hat, y):
- return 'error', float(sum(y.get_label() != (y_hat > 0.5))) / len(y_hat)
-
- def read_data(path):
- y = []
- row = []
- col = []
- values = []
- r = 0 # 首行
- for d in open(path):
- d = d.strip().split() # 以空格分开
- y.append(int(d[0]))
- d = d[1:]
- for c in d:
- key, value = c.split(':')
- row.append(r)
- col.append(int(key))
- values.append(float(value))
- r += 1
- x = scipy.sparse.csr_matrix((values, (row, col))).toarray()
- y = np.array(y)
- return x, y
-
- if __name__ == '__main__':
- # 读取数据
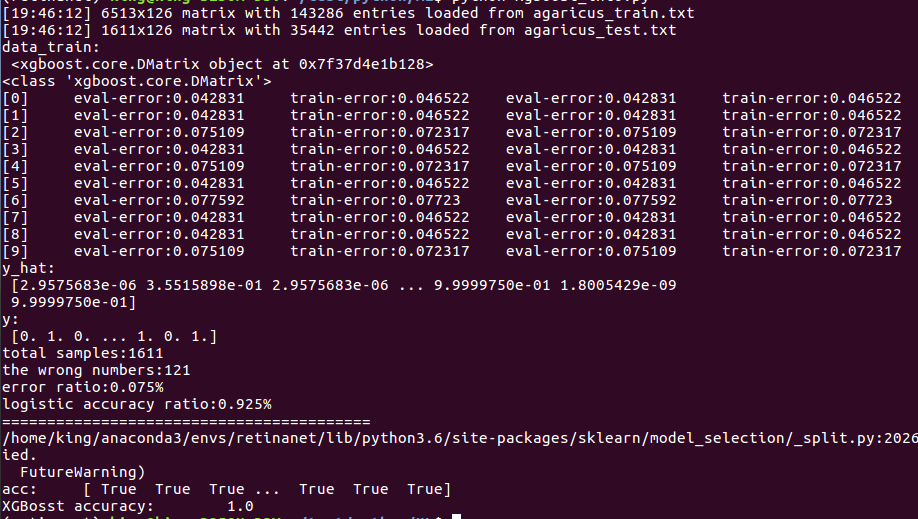
- data_train = xgb.DMatrix('agaricus_train.txt')
- data_test = xgb.DMatrix('agaricus_test.txt')
- print('data_train:\n', data_train)
- print(type(data_train))
-
- # 设定相关参数
- param = {'max_depth':2, 'eta':1, 'silent':1, 'objective':'binary:logistic'}
- # param = {'max_depth':2, 'eta':1, 'silent':1, 'objective':'reg:logistic'}
- watchlist = [(data_test, 'eval'), (data_train, 'train')]
- n_round = 10
- bst = xgb.train(param, data_train, num_boost_round=n_round, evals=watchlist, obj=log_reg, feval=error_rate)
-
- # 计算错误率
- y_hat = bst.predict(data_test)
- y = data_test.get_label()
- print('y_hat:\n', y_hat)
- print('y:\n', y)
-
- error = sum(y != (y_hat > 0.5))
- error_rate = float(error) / len(y_hat)
- print('total samples:%d' % len(y_hat))
- print('the wrong numbers:%d' % error)
- print('error ratio:%.3f%%' % error_rate)
- print('logistic accuracy ratio:%.3f%%' % (1 - error_rate))
- print('=========================================')
-
- # logistic regression
- x, y = read_data('agaricus_train.txt')
-
- x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.7, random_state=1)
- lr = LogisticRegression(penalty='l2')
- lr.fit(x_train, y_train.ravel())
- y_hat = lr.predict(x_test)
- acc = y_hat.ravel() == y_test.ravel()
- print('acc:\t', acc)
- print('XGBosst accuracy:\t', float(acc.sum()) / y_hat.size)
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小蓝xlanll/article/detail/97466
推荐阅读
相关标签

