
- 1Python 教学 | Pandas 分组聚合与数据排序_python聚合并按聚合值从大到小排序
- 2unity 粒子插件_收藏就完事了!Oculus Quest和Unity创意开源项目,你不码住嘛?!...
- 3乌班图初识命令小字典(欢迎补充)_乌班图指令
- 4has been injected into other beans[XXXXXXXXXX] in its raw version as part of a circular reference
- 5anaconda创建并切换多版本python环境_python是3.8,anaconda中是3.10
- 6微服务--实用篇-笔记大全_给黑马旅游添加排序功能
- 7推荐几款便宜幻兽帕鲁(Palworld)联机服务专用服务器_幻兽帕鲁 华为云服务器
- 8Xss(跨站脚本攻击)漏洞解析_xss 攻击, 转义
- 9Java 18中简单 Web 服务器
- 10编程笔记 Golang基础 026 函数
alexnet的loss在一个epoch内没有稳定下降_机器学习 101:一文带你读懂梯度下降
赞
踩

原标题 | Machine Learning 101: An Intuitive Introduction to Gradient Descent
作者 | Thalles Silva
译者 | 汪鹏(重庆邮电大学)、通夜(中山大学)
编辑:王立鱼
英语原文:https://towardsdatascience.com/machine-learning-101-an-intuitive-introduction-to-gradient-descent-366b77b52645

梯度下降无疑是大多数机器学习(ML)算法的核心和灵魂。我绝对认为你应该花时间去理解它。因为对于初学者来说,这样做能够让你更好地理解大多数机器学习算法是如何工作的。另外,想要培养对复杂项目的直觉,理解基本的概念也是十分关键的。
为了理解梯度下降的核心,让我们来看一个运行的例子。这项任务是这个领域的一项老任务——使用一些历史数据作为先验知识来预测房价。
我们的目标是讨论梯度下降。所以我们让这个例子简单一点,以便我们可以专注于重要的部分。
但是在我们开始之前,你可以点击此处获取代码
基本概念
假设你想爬一座很高的山,你的目标是最快到达山顶,可你环顾四周后,你意识到你有不止一条路可以走,既然你在山脚,但似乎所有选择都能让你离山顶更近。
如果你想以最快的方式到达顶峰,所以你要怎么做呢?你怎样才能只迈出一步,而能够离山顶最近?
到目前为止,我们还不清楚如何迈出这一步!而这就是梯度的用武之地。
正如可汗学院的这段视频所述,梯度获取了一个多变量函数的所有偏导数。
让我们一步步来看看它是如何工作的。
用更简单的话来说,导数是一个函数在某一点的变化率或斜率。
以f(x)=x²函数为例。f(x)的导数就是另一个函数f'(x)在一个定点x的值,f'(x)就是f(x)的斜率函数。在这种情况下,当x=2时,f(x) = x²的斜率是2 x,也就是2*2=4。
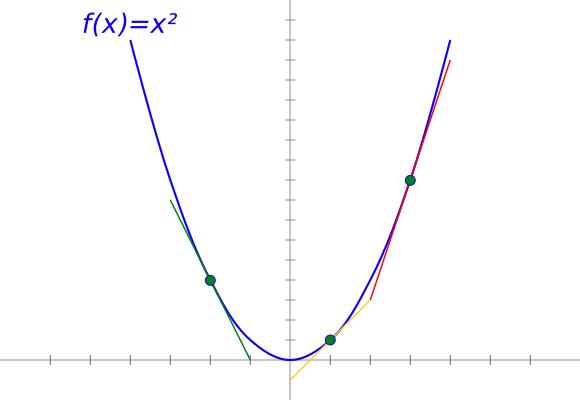
f(x) = x²在不同点的斜率。
简单地说,导数指向上升最陡的方向。恰巧的是,梯度和导数基本上是一样的。除了一点,即梯度是一个向量值函数,向量里包含着偏导数。换句话说,梯度是一个向量,它的每一个分量都是对一个特定变量的偏导数。
以函数f(x,y)=2x²+y²为另一个例子。
这里的f(x,y)是一个多变量函数。它的梯度是一个向量,其中包含了f(x,y)的偏导数,第一个是关于x的偏导数,第二个是关于y的偏导数。
如果我们计算f(x,y)的偏导数。
得到的梯度是以下这样的向量:
请注意,其中每个元素都指示了函数里每个变量的最陡上升方向。换句话说,梯度指向函数增长最多的方向。
回到爬山的例子中,坡度指向的方向是最快到达山顶的方向。换句话说,梯度指向一个面更高的地方。
同样的,如果我们有一个有四个变量的函数,我们会得到一个有四个偏导数的梯度向量。通常,一个有n个变量的函数会产生一个n维梯度向量。
但是对于梯度下降,我们不想让f函数尽快地最大化,我们想让它最小化。
所以让我们先定义我们的任务,让目标变得更清晰明确一点。
房价预测
我们的目标是基于历史数据来预测房价。而想要建立一个机器学习模型,我们通常需要至少3个要素——问题T、性能度量P和经验E,我们的模型将从这其中学习到一些模式知识。
为了解决问题T,我们将使用一个简单的线性回归模型。该模型将从经验E中学习,经过训练,模型就能将其知识推广到未知数据中。
线性模型是一个很好的学习模型。它是许多其他ML算法的基础,比如神经网络和支持向量机。
在本例中,经验E就是房屋数据集。房屋数据集包含了圣路易斯奥比斯波县及其周边地区最近的房地产清单。
数据集包含了781条数据记录,可以在原文下载CSV格式的数据文件。为了简便,在数据的8个特征中,我们只关注其中的两个特征 : 房屋大小和价格。在这781条记录中,每一条记录的房屋大小(以平方英尺为单位)将是我们的输入特征,而价格则是我们的预测目标值。
此外,为了检查我们的模型是否正确地从经验E中学习到了模式知识,我们需要一个机制来衡量它的性能。因此,我们将平方误差(MSE)的均值作为性能度量P。

多年来,MSE一直是线性回归的标准。但从理论上讲,任何其他误差测量方法,比如绝对误差,都是可用的。而MSE的一些优点是,它对误差的衡量比绝对误差更好。
现在我们已经公式化了我们的学习算法,让我们深入研究代码。
首先,我们使用pandas在python中加载数据,并分离房屋大小和价格特征。之后,我们对数据进行标准化,以防止某些特征的大小范围与其他特征不同。而且,标准化过的数据在进行梯度下降时,收敛速度比其他方法快得多。
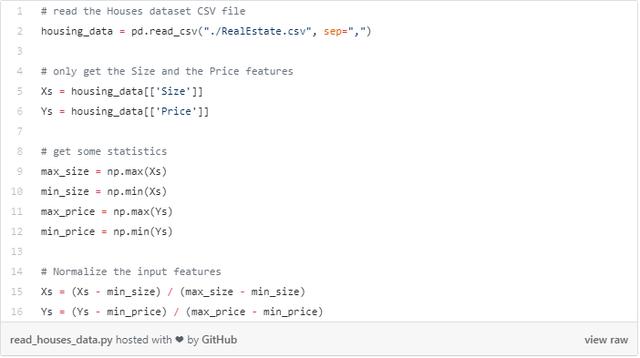
下面,你可以看到以平方米为单位的房价分布。
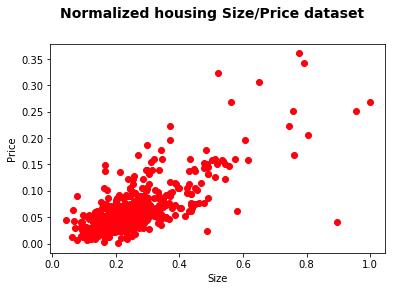
按面积计算的房价分布。数据被标准化到了[0,1]区间。
线性回归模型的工作原理是在数据上画一条线。因此,我们的模型由一个简单的直线方程表示。
线性方程,m和b分别是斜率和y轴的截距,x变量是输入值。
对于线性模型,斜率m和y轴的截距b是两个自由的参数。我们则要通过改变这两个参数来找到最好的直线方程。
我们将对它们迭代执行一些细小的改变,这样它就可以沿着误差曲面上最陡的下降方向走。在每次迭代之后,这些权重变化将改善我们的模型,使得它能够表示数据集的趋势。
在继续往下看之前,请记住我们要取梯度的反方向来进行梯度下降。
你可以把梯度下降想象成一个球滚下山谷。我们想让它落在最深的山谷里,然而很明显,我们看到实际情况可能会出错。

打个比方,我们可以把梯度下降想象成一个球滚下山谷。最深的山谷是最优的全局最小值,这是我们的目标。
根据球开始滚动的位置,它可能停在某一个山谷的底部。但不是最低的。这叫做局部极小值,在我们的模型中,山谷就是误差面。
注意,在类比中,并不是所有的局部极小值都是糟糕的。实际上其中一些几乎和最低的(全局)一样低(好)。事实上,对于高维误差曲面,最常见的方法是使用这些局部极小值中的一个(其实也不是很糟糕)。
类似地,我们初始化模型权重的方法可能会导致它停留在局部极小值。为了避免这种情况,我们从均值为零且方差较小的随机正态分布中初始化两个权值向量。
在每次迭代中,我们将取数据集的一个随机子集,并将其与权重线性组合。这个子集称为迷你批处理(mini-batch)。在线性组合后,我们把得到的向量输入MSE函数,计算新的误差。
利用这个误差,我们可以计算出误差的偏导数,然后得到梯度。
首先,我们得到关于W0的偏导数:
W0的偏导数
接下来,我们求W1的偏导数
W1的偏导数
由这两个偏导数,我们可以得到梯度向量:
梯度向量
其中Err是MSE错误函数。
有了这个,我们的下一步是使用梯度更新权重向量W0和W1,以最小化误差。
我们想要更新权重,以便它们可以在下一次迭代中将错误降低。我们需要使它们遵循每个相应梯度信号的相反方向。为此,我们将在这个方向上采取小尺寸η的小步骤。
步长η是学习率,它控制学习速度。根据经验,一个好的起点是0.1。最后,更新步骤规则设置为:
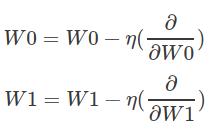
在代码中,完整的模型看起来像这样。查看两个梯度DW0和DW1前面的减号。这保证了我们将在与梯度相反的方向上采取步骤。
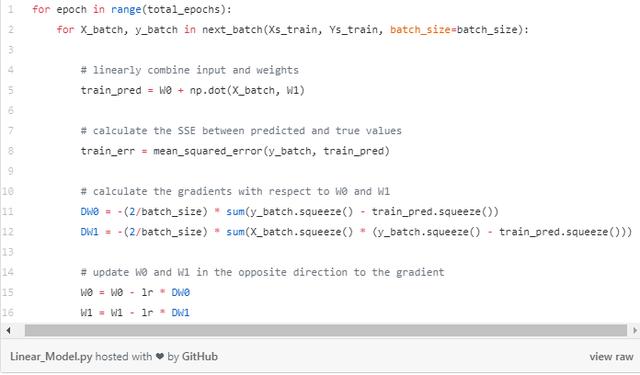
更新权重后,我们使用另一个随机小批量重复该过程,就是这样。
逐步地,每次重量更新导致线路中的小的移动朝向其最佳表示。最后,当误差方差足够小时,我们就可以停止学习。
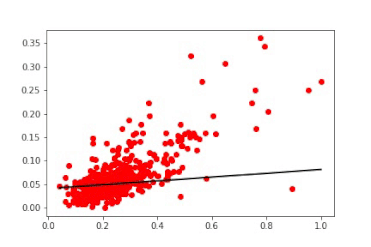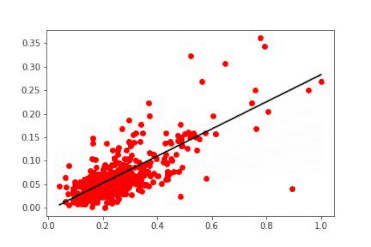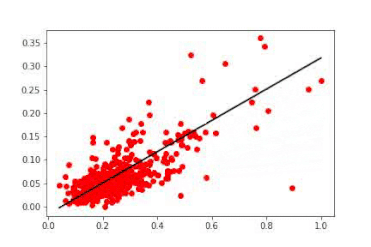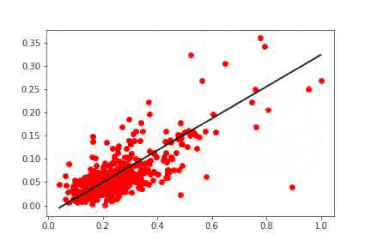
随时间变换的线性模型。第一次权重更新使线条快速达到理想的表示。
此版本的梯度下降称为迷你批处理(Mini-Batch)随机梯度下降。在这个版本中,我们使用一小部分训练数据来计算梯度。每个小批量梯度提供最佳方向的近似值。即使梯度没有指向确切的方向,实际上它也会收敛到非常好的解决方案。
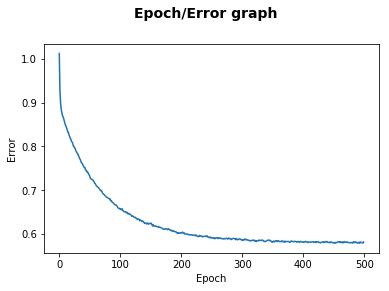
每一个Epoch的错误信号。请注意,在非常快地减小误差信号之后,模型会减慢并收敛。
如果你仔细观察错误图表,你会注意到,在开始时学习速度会更快。
然而,在经过一些Epoch之后,它会放慢速度并保持平稳。这是因为,在开始时,指向最陡下降的梯度向量的幅度很长。结果,两个权重变量W0和W1遭受更大的变化。
接着,随着它们越来越靠近误差表面的顶点,梯度逐渐变得越来越小,这导致了权重的非常小的变化。
最后,学习曲线稳定,并且过程完成。雷锋网雷锋网雷锋网
想要继续查看该篇文章相关链接和参考文献?
点击【机器学习101:一文带你读懂梯度下降】即可访问!
今日博客推荐:「元学习」解析:学习如何梯度下降与学习新的算法
本文作者 Cody Marie Wild,她是一位机器学习领域的数据科学家,在生活中还是名猫咪铲屎官,她钟爱语言和简洁优美的系统。在这篇文章中,Cody 介绍了元学习的基本概念和方法类别,讨论了「元学习」到底在学什么、又有哪些限制。
详情查看点击:https://ai.yanxishe.com/page/blogDetail/5798

