
热门标签
热门文章
- 1docker操作_docker 查看容器中安装包
- 2【centos rootfs】记录一次基于arm64(aarch64) Centos7.9.2009文件系统移植过程
- 3【python小课堂专栏】python小课堂39 - 用 with 优雅的读写文件_with 方式读写文件
- 4华为od项目_华为od面试手撕代码
- 5【考研数据结构题型分类讲解练习】1-2线性表--选择题--答案讲解篇_对于一个线性表既要求能够进行较快的插入和删除,又要求存储结构能够反应数据之间
- 6Lottie 动画库使用_setimageassetsfolder
- 7C++ //练习 9.34 假定vi是一个保存int的容器,其中有偶数值也有奇数值,分析下面循环的行为,然后编写程序验证你的分析是否正确。
- 8从零开始,搭建边缘计算服务器并配置 Docker:只需三步(ARM平台)_如何用docker模拟边缘服务器
- 9VT驱动开发_vmxon
- 10Scp 服务器文件拷贝与下载_scpsl下载
当前位置: article > 正文
AlexNet卷积神经网络-笔记_epoch: 0, batch_id: 0, loss is: [2.3784869], acc i
作者:小丑西瓜9 | 2024-02-18 03:20:59
赞
踩
epoch: 0, batch_id: 0, loss is: [2.3784869], acc is: [0.203125]什么意思
AlexNet卷积神经网络-笔记
AlexNet卷积神经网络2012年提出
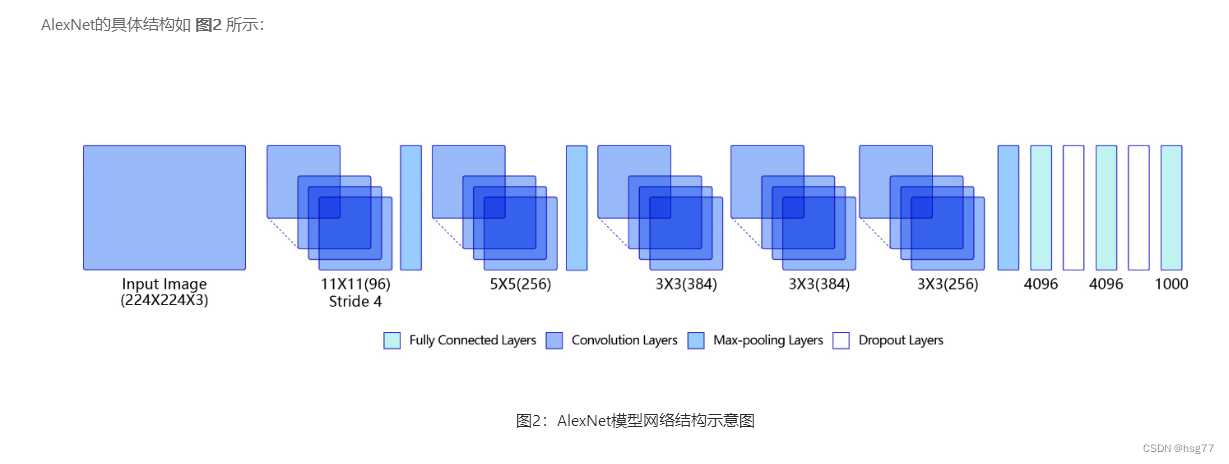
测试结果为:
通过运行结果可以发现,
在眼疾筛查数据集iChallenge-PM上使用AlexNet,loss能有效下降,
经过5个epoch的训练,在验证集上的准确率可以达到94%左右。
实测准确率为:0.92到0.9350
[validation] accuracy/loss: 0.9275/0.1661
[validation] accuracy/loss: 0.9350/0.2233
S E:\project\python> & D:/ProgramData/Anaconda3/python.exe e:/project/python/PM/AlexNet_PM.py W0803 14:19:51.270619 6520 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 6.1, Driver API Version: 12.2, Runtime API Version: 10.2 W0803 14:19:51.290621 6520 gpu_resources.cc:91] device: 0, cuDNN Version: 7.6. start training ... epoch: 0, batch_id: 0, loss is: 1.0486 epoch: 0, batch_id: 20, loss is: 0.5316 [validation] accuracy/loss: 0.9275/0.2720 epoch: 1, batch_id: 0, loss is: 0.2918 epoch: 1, batch_id: 20, loss is: 0.2479 [validation] accuracy/loss: 0.9250/0.3421 epoch: 2, batch_id: 0, loss is: 1.7486 epoch: 2, batch_id: 20, loss is: 0.1236 [validation] accuracy/loss: 0.9350/0.2233 epoch: 3, batch_id: 0, loss is: 0.2802 epoch: 3, batch_id: 20, loss is: 0.3339 [validation] accuracy/loss: 0.9275/0.2186 epoch: 4, batch_id: 0, loss is: 0.0429 epoch: 4, batch_id: 20, loss is: 0.1188 [validation] accuracy/loss: 0.9275/0.1661

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
W0803 14:34:45.152906 17400 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 6.1, Driver API Version: 12.2, Runtime API Version: 10.2 W0803 14:34:45.173938 17400 gpu_resources.cc:91] device: 0, cuDNN Version: 7.6. #AlexNet 子图层结构 [Conv2D(3, 96, kernel_size=[11, 11], stride=[4, 4], padding=5, data_format=NCHW), MaxPool2D(kernel_size=2, stride=2, padding=0), Conv2D(96, 256, kernel_size=[5, 5], padding=2, data_format=NCHW), MaxPool2D(kernel_size=2, stride=2, padding=0), Conv2D(256, 384, kernel_size=[3, 3], padding=1, data_format=NCHW), Conv2D(384, 384, kernel_size=[3, 3], padding=1, data_format=NCHW), Conv2D(384, 256, kernel_size=[3, 3], padding=1, data_format=NCHW), MaxPool2D(kernel_size=2, stride=2, padding=0), Linear(in_features=12544, out_features=4096, dtype=float32), Dropout(p=0.5, axis=None, mode=upscale_in_train), Linear(in_features=4096, out_features=4096, dtype=float32), Dropout(p=0.5, axis=None, mode=upscale_in_train), Linear(in_features=4096, out_features=2, dtype=float32)] (10, 3, 224, 224) [10, 3, 224, 224] #AlexNet子图层shape[N,Cout,H,W],w参数[Cout,Ci,Kh,Kw],b参数[Cout] conv2d_5 [10, 96, 56, 56] [96, 3, 11, 11] [96] max_pool2d_3 [10, 96, 28, 28] conv2d_6 [10, 256, 28, 28] [256, 96, 5, 5] [256] max_pool2d_4 [10, 256, 14, 14] conv2d_7 [10, 384, 14, 14] [384, 256, 3, 3] [384] conv2d_8 [10, 384, 14, 14] [384, 384, 3, 3] [384] conv2d_9 [10, 256, 14, 14] [256, 384, 3, 3] [256] max_pool2d_5 [10, 256, 7, 7] linear_3 [10, 4096] [12544, 4096] [4096] dropout_2 [10, 4096] linear_4 [10, 4096] [4096, 4096] [4096] dropout_3 [10, 4096] linear_5 [10, 2] [4096, 2] [2] PS E:\project\python>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
注意:
conv2d_5 [10, 96, 56, 56] [96, 3, 11, 11] [96]
中H=56,W=56的计算方法如下:
H=((Hold+2P-K)/S)+1=((224+2*5-11)/4)+1=56.75=>56
同理W=56
测试源代码如下所示:
#AlexNet在眼疾筛查数据集iChallenge-PM上具体实现的代码如下所示: # -*- coding:utf-8 -*- # 导入需要的包 import paddle import numpy as np from paddle.nn import Conv2D, MaxPool2D, Linear, Dropout ## 组网 import paddle.nn.functional as F # 定义 AlexNet 网络结构 2012年 class AlexNet(paddle.nn.Layer): def __init__(self, num_classes=1): super(AlexNet, self).__init__() # AlexNet与LeNet一样也会同时使用卷积和池化层提取图像特征 # 与LeNet不同的是激活函数换成了‘relu’ self.conv1 = Conv2D(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding=5) self.max_pool1 = MaxPool2D(kernel_size=2, stride=2) self.conv2 = Conv2D(in_channels=96, out_channels=256, kernel_size=5, stride=1, padding=2) self.max_pool2 = MaxPool2D(kernel_size=2, stride=2) self.conv3 = Conv2D(in_channels=256, out_channels=384, kernel_size=3, stride=1, padding=1) self.conv4 = Conv2D(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding=1) self.conv5 = Conv2D(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1) self.max_pool5 = MaxPool2D(kernel_size=2, stride=2) self.fc1 = Linear(in_features=12544, out_features=4096) self.drop_ratio1 = 0.5 self.drop1 = Dropout(self.drop_ratio1) self.fc2 = Linear(in_features=4096, out_features=4096) self.drop_ratio2 = 0.5 self.drop2 = Dropout(self.drop_ratio2) self.fc3 = Linear(in_features=4096, out_features=num_classes) def forward(self, x): x = self.conv1(x) x = F.relu(x) x = self.max_pool1(x) x = self.conv2(x) x = F.relu(x) x = self.max_pool2(x) x = self.conv3(x) x = F.relu(x) x = self.conv4(x) x = F.relu(x) x = self.conv5(x) x = F.relu(x) x = self.max_pool5(x) x = paddle.reshape(x, [x.shape[0], -1]) x = self.fc1(x) x = F.relu(x) # 在全连接之后使用dropout抑制过拟合 x = self.drop1(x) x = self.fc2(x) x = F.relu(x) # 在全连接之后使用dropout抑制过拟合 x = self.drop2(x) x = self.fc3(x) return x #数据处理 #============================================================================================== import cv2 import random import numpy as np import os # 对读入的图像数据进行预处理 def transform_img(img): # 将图片尺寸缩放道 224x224 img = cv2.resize(img, (224, 224)) # 读入的图像数据格式是[H, W, C] # 使用转置操作将其变成[C, H, W] img = np.transpose(img, (2,0,1)) img = img.astype('float32') # 将数据范围调整到[-1.0, 1.0]之间 img = img / 255. img = img * 2.0 - 1.0 return img # 定义训练集数据读取器 def data_loader(datadir, batch_size=10, mode = 'train'): # 将datadir目录下的文件列出来,每条文件都要读入 filenames = os.listdir(datadir) def reader(): if mode == 'train': # 训练时随机打乱数据顺序 random.shuffle(filenames) batch_imgs = [] batch_labels = [] for name in filenames: filepath = os.path.join(datadir, name) img = cv2.imread(filepath) img = transform_img(img) if name[0] == 'H' or name[0] == 'N': # H开头的文件名表示高度近似,N开头的文件名表示正常视力 # 高度近视和正常视力的样本,都不是病理性的,属于负样本,标签为0 label = 0 elif name[0] == 'P': # P开头的是病理性近视,属于正样本,标签为1 label = 1 else: raise('Not excepted file name') # 每读取一个样本的数据,就将其放入数据列表中 batch_imgs.append(img) batch_labels.append(label) if len(batch_imgs) == batch_size: # 当数据列表的长度等于batch_size的时候, # 把这些数据当作一个mini-batch,并作为数据生成器的一个输出 imgs_array = np.array(batch_imgs).astype('float32') labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1) yield imgs_array, labels_array batch_imgs = [] batch_labels = [] if len(batch_imgs) > 0: # 剩余样本数目不足一个batch_size的数据,一起打包成一个mini-batch imgs_array = np.array(batch_imgs).astype('float32') labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1) yield imgs_array, labels_array return reader # 定义验证集数据读取器 def valid_data_loader(datadir, csvfile, batch_size=10, mode='valid'): # 训练集读取时通过文件名来确定样本标签,验证集则通过csvfile来读取每个图片对应的标签 # 请查看解压后的验证集标签数据,观察csvfile文件里面所包含的内容 # csvfile文件所包含的内容格式如下,每一行代表一个样本, # 其中第一列是图片id,第二列是文件名,第三列是图片标签, # 第四列和第五列是Fovea的坐标,与分类任务无关 # ID,imgName,Label,Fovea_X,Fovea_Y # 1,V0001.jpg,0,1157.74,1019.87 # 2,V0002.jpg,1,1285.82,1080.47 # 打开包含验证集标签的csvfile,并读入其中的内容 filelists = open(csvfile).readlines() def reader(): batch_imgs = [] batch_labels = [] for line in filelists[1:]: line = line.strip().split(',') name = line[1] label = int(line[2]) # 根据图片文件名加载图片,并对图像数据作预处理 filepath = os.path.join(datadir, name) img = cv2.imread(filepath) img = transform_img(img) # 每读取一个样本的数据,就将其放入数据列表中 batch_imgs.append(img) batch_labels.append(label) if len(batch_imgs) == batch_size: # 当数据列表的长度等于batch_size的时候, # 把这些数据当作一个mini-batch,并作为数据生成器的一个输出 imgs_array = np.array(batch_imgs).astype('float32') labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1) yield imgs_array, labels_array batch_imgs = [] batch_labels = [] if len(batch_imgs) > 0: # 剩余样本数目不足一个batch_size的数据,一起打包成一个mini-batch imgs_array = np.array(batch_imgs).astype('float32') labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1) yield imgs_array, labels_array return reader # -*- coding: utf-8 -*- # 识别眼疾图片 import os import random import paddle import numpy as np DATADIR = './PM/palm/PALM-Training400/PALM-Training400' DATADIR2 = './PM/palm/PALM-Validation400' CSVFILE = './PM/labels.csv' # 设置迭代轮数 EPOCH_NUM = 5 # 定义训练过程 def train_pm(model, optimizer): # 开启0号GPU训练 use_gpu = True paddle.device.set_device('gpu:0') if use_gpu else paddle.device.set_device('cpu') print('start training ... ') model.train() # 定义数据读取器,训练数据读取器和验证数据读取器 train_loader = data_loader(DATADIR, batch_size=10, mode='train') valid_loader = valid_data_loader(DATADIR2, CSVFILE) for epoch in range(EPOCH_NUM): for batch_id, data in enumerate(train_loader()): x_data, y_data = data img = paddle.to_tensor(x_data) label = paddle.to_tensor(y_data) #print('image.shape=',img.shape) # 运行模型前向计算,得到预测值 logits = model(img) loss = F.binary_cross_entropy_with_logits(logits, label) avg_loss = paddle.mean(loss) if batch_id % 20 == 0: print("epoch: {}, batch_id: {}, loss is: {:.4f}".format(epoch, batch_id, float(avg_loss.numpy()))) # 反向传播,更新权重,清除梯度 avg_loss.backward() optimizer.step() optimizer.clear_grad() model.eval() accuracies = [] losses = [] for batch_id, data in enumerate(valid_loader()): x_data, y_data = data img = paddle.to_tensor(x_data) label = paddle.to_tensor(y_data) # 运行模型前向计算,得到预测值 logits = model(img) # 二分类,sigmoid计算后的结果以0.5为阈值分两个类别 # 计算sigmoid后的预测概率,进行loss计算 pred = F.sigmoid(logits) loss = F.binary_cross_entropy_with_logits(logits, label) # 计算预测概率小于0.5的类别 pred2 = pred * (-1.0) + 1.0 # 得到两个类别的预测概率,并沿第一个维度级联 pred = paddle.concat([pred2, pred], axis=1) acc = paddle.metric.accuracy(pred, paddle.cast(label, dtype='int64')) accuracies.append(acc.numpy()) losses.append(loss.numpy()) print("[validation] accuracy/loss: {:.4f}/{:.4f}".format(np.mean(accuracies), np.mean(losses))) model.train() paddle.save(model.state_dict(), 'palm.pdparams') paddle.save(optimizer.state_dict(), 'palm.pdopt') # 定义评估过程 def evaluation(model, params_file_path): # 开启0号GPU预估 use_gpu = True paddle.device.set_device('gpu:0') if use_gpu else paddle.device.set_device('cpu') print('start evaluation .......') #加载模型参数 model_state_dict = paddle.load(params_file_path) model.load_dict(model_state_dict) model.eval() eval_loader = data_loader(DATADIR, batch_size=10, mode='eval') acc_set = [] avg_loss_set = [] for batch_id, data in enumerate(eval_loader()): x_data, y_data = data img = paddle.to_tensor(x_data) label = paddle.to_tensor(y_data) y_data = y_data.astype(np.int64) label_64 = paddle.to_tensor(y_data) # 计算预测和精度 prediction, acc = model(img, label_64) # 计算损失函数值 loss = F.binary_cross_entropy_with_logits(prediction, label) avg_loss = paddle.mean(loss) acc_set.append(float(acc.numpy())) avg_loss_set.append(float(avg_loss.numpy())) # 求平均精度 acc_val_mean = np.array(acc_set).mean() avg_loss_val_mean = np.array(avg_loss_set).mean() print('loss={:.4f}, acc={:.4f}'.format(avg_loss_val_mean, acc_val_mean)) #============================================================================================== # 创建模型 model = AlexNet() # 启动训练过程 opt = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters()) train_pm(model, optimizer=opt) # 输入数据形状是 [N, 3, H, W] # 这里用np.random创建一个随机数组作为输入数据 x = np.random.randn(*[10,3,224,224]) x = x.astype('float32') # 创建LeNet类的实例,指定模型名称和分类的类别数目 model = AlexNet(2) # 通过调用LeNet从基类继承的sublayers()函数, # 查看LeNet中所包含的子层 print(model.sublayers()) print(x.shape) x = paddle.to_tensor(x) print(x.shape) for item in model.sublayers(): # item是LeNet类中的一个子层 # 查看经过子层之后的输出数据形状 try: x = item(x) except: x = paddle.reshape(x, [x.shape[0], -1]) x = item(x) if len(item.parameters())==2: # 查看卷积和全连接层的数据和参数的形状, # 其中item.parameters()[0]是权重参数w,item.parameters()[1]是偏置参数b print(item.full_name(), x.shape, item.parameters()[0].shape, item.parameters()[1].shape) else: # 池化层没有参数 print(item.full_name(), x.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/104207
推荐阅读
相关标签

