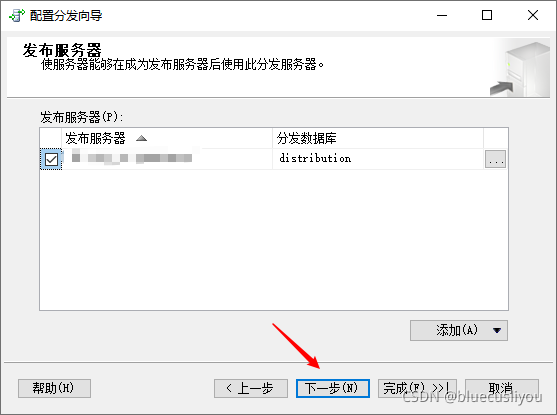
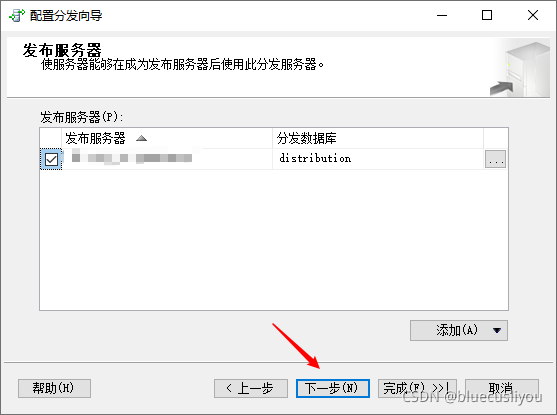
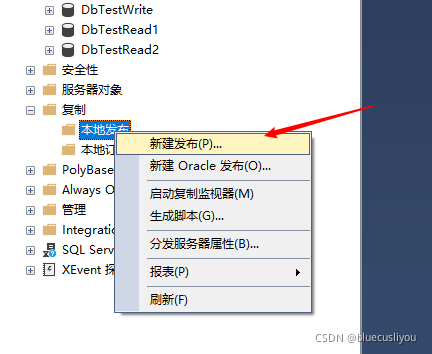
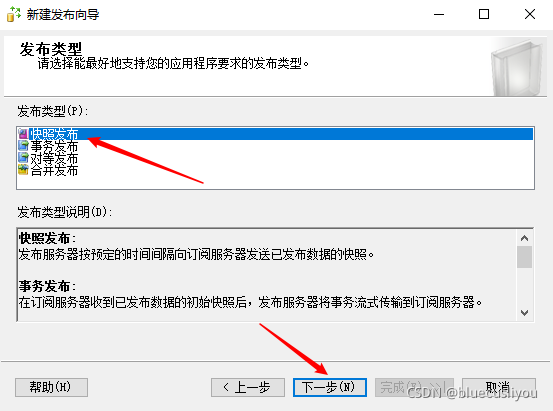
数据库–SQLServer详解
零、文章目录
一、数据库概念
1、数据库基本概念
(1)数据库(DataBase:DB)
数据库是是按照数据结构来组织、存储和管理数据的仓库。---->存储和管理数据的仓库
(2)数据库管理系统(Database Management System:DBMS)
是专门用于管理数据库的计算机系统软件。数据库管理系统能够为数据库提供数据的定义、建立、维护、查询和统计等操作功能,并完成对数据完整性、安全性进行控制的功能。
注意:我们一般说的数据库,就是指的DBMS
2、数据库技术发展历程
(1)层次数据库和网状数据库技术阶段
使用指针来表示数据之间的联系。
(2)关系型数据库技术阶段
经典的里程碑阶段,代表的DBMS有:Oracle、DB2、MySQL、SQL Server、SyBase等。
(3)后关系型数据库技术阶段
由于关系型数据库中存在数据模型、性能、拓展伸缩性差的缺点,所以出现了ORDBMS(面向对象数据库技术),NoSQL(结构化数据库技术)。
3、常见关系型数据库
- Oracle:运行稳定,可移植性高,功能齐全,性能超群。适用于大型企业领域。
- DB2:速度快、可靠性好,适于海量数据,恢复性极强。适用于大中型企业领域。
- SQL Server:全面,效率高,界面友好,操作容易,但是不跨平台。适用于中小型企业领域。
- MySQL:开源,体积小,速度快。适用于中小型企业领域。
4、常见NoSQL数据库
- 键值存储数据库:Oracle BDB、Redis、BeansDB
- 列式储数数据库:HBase、Cassandra、Riak
- 文档型数据库:MongoDB、CouchDB
- 图形数据库:Neo4J、InfoGrid、Infinite Graph
5、结构化查询语言(SQL)
Structured Query Language,即SQL,SQL是关系型数据库标准语言,其特点:简单,灵活,功能强大。SQL包含6个部分:
(1)数据查询语言(DQL)
其语句,也称为“数据检索语句”,用以从表中获得数据,确定数据怎样在应用程序给出。保留字SELECT是DQL(也是所有SQL)用得最多的动词,其他DQL常用的保留字有WHERE,ORDER BY,GROUP BY和HAVING。这些DQL保留字常与其他类型的SQL语句一起使用。
(2)数据操作语言(DML)
其语句包括动词INSERT,UPDATE和DELETE。它们分别用于添加,修改和删除表中的行。也称为动作查询语言。
(3)事务处理语言(TPL)
它的语句能确保被DML语句影响的表的所有行及时得以更新。TPL语句包括BEGIN TRANSACTION,COMMIT和ROLLBACK。
(4)数据控制语言(DCL)
它的语句通过GRANT或REVOKE获得许可,确定单个用户和用户组对数据库对象的访问。某些RDBMS可用GRANT或REVOKE控制对表单个列的访问。
(5)数据定义语言(DDL)
其语句包括动词CREATE和DROP。在数据库中创建新表或删除表(CREAT TABLE 或 DROP TABLE);为表加入索引等。DDL包括许多与人数据库目录中获得数据有关的保留字。它也是动作查询的一部分。
(6)指针控制语言(CCL)
它的语句,像DECLARE CURSOR,FETCH INTO和UPDATE WHERE CURRENT用于对一个或多个表单独行的操作。
二、数据库安装
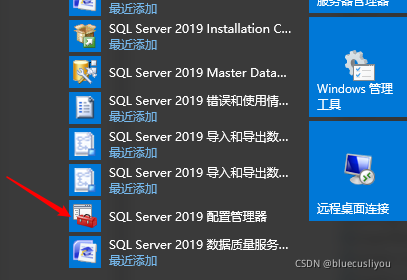
1、SqlServer2019
下载路径:https://www.microsoft.com/zh-cn/sql-server/sql-server-downloads
直接下载Developer版本,下载后:是一个镜像文件—直接解压,就可以去执行Exe文件安装了
2、SQL Server Management Studio
3、docker安装SqlServer2019
拉取镜像
docker pull mcr.microsoft.com/mssql/server:2019-latest
- 1
- 1
查看镜像
docker images
- 1
- 1
启动容器
docker run -e "ACCEPT_EULA=Y" -e "SA_PASSWORD=密码" -u 0:0 -p 1433:1433 --name mssql -v /data/mssql:/var/opt/mssql -d mcr.microsoft.com/mssql/server:2019-latest
- 1
- 1
| 参数 | 说明 |
|---|---|
| -e ‘ACCEPT_EULA=Y’ | 设置此参数说明同意 SQL SERVER 使用条款 , 否则无法使用 |
| -e ‘SA_PASSWORD=密码’ | 此处设置 SQL SERVER 数据库 SA 账号的密码 |
| -p 1433:1433 | 将宿主机 1433 端口映射到容器的 1433 端口 |
| –name mssql | 设置容器名为 mssql |
| -v /data/mssql:/var/opt/mssql | 将宿主机 /data/mssql 映射到容器 /var/opt/mssql , 方便备份数据 |
检查容器是否启动
docker ps -a
- 1
- 1
检查STATUS 是不是 Up 状态,如果是 Exited 状态的话,可以尝试使用 docker logs mssql 查看日志,日志内会提供相对应的代码,以及解决链接。
服务器本地连接测试
docker exec -it mssql /bin/bash
- 1
- 1
不报错就是连接成功
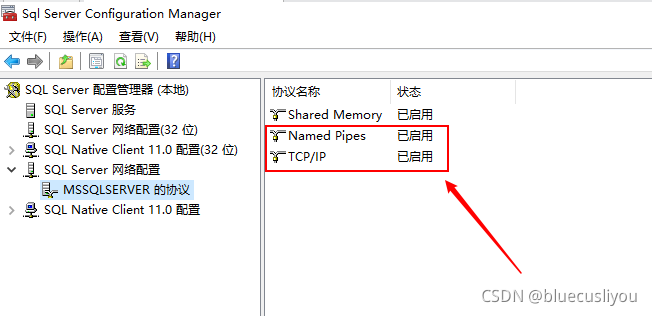
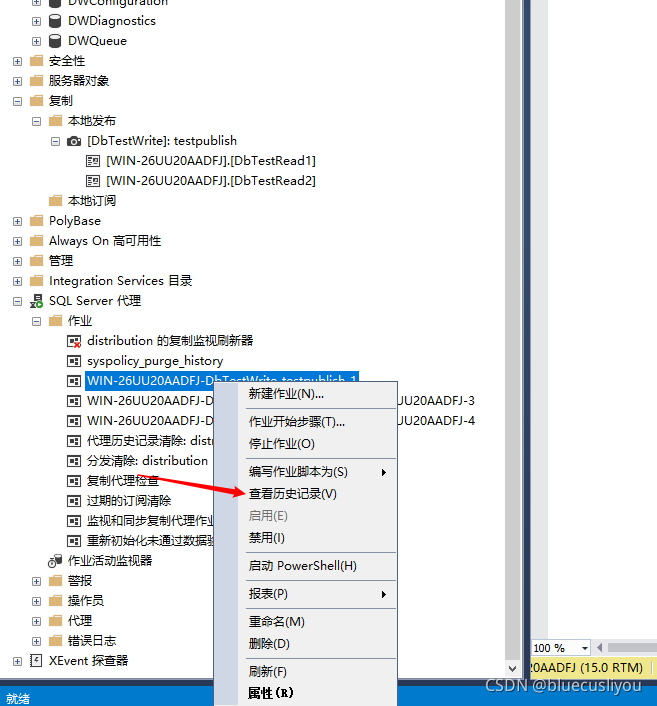
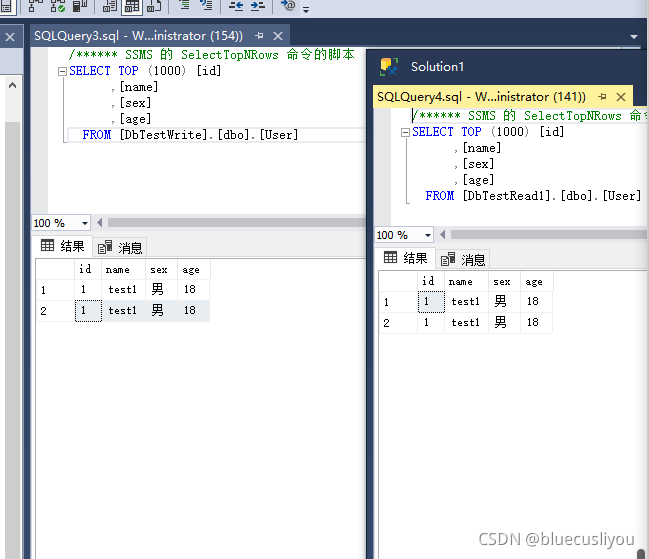
SSMS连接测试
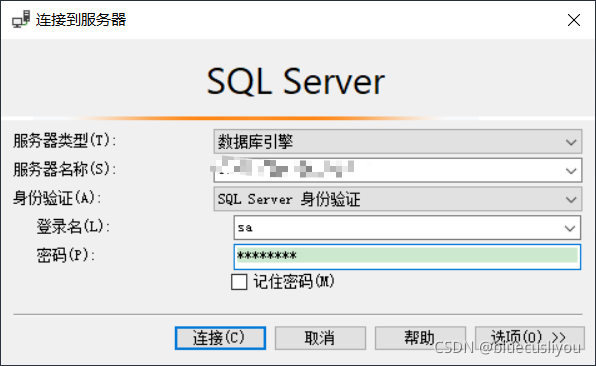
三、数据库设计
1、设计的重要性
(1)提高开发效率
(2)节省空间,硬件资源
(3)直接关乎到数据库的性能
2、设计的流程
(1)确定需求
(2)创建E-R图,可视化数据展示
(3)数据库字段的设计
3、PowerDesigner实操
(1)PowerDesigner16.5下载安装
链接:https://pan.baidu.com/s/1y65sOlVhMyDRrTXxFbq1yg
提取码:1234
(2)PD生成SQL脚本
建议先画E-R图,再生成数据库
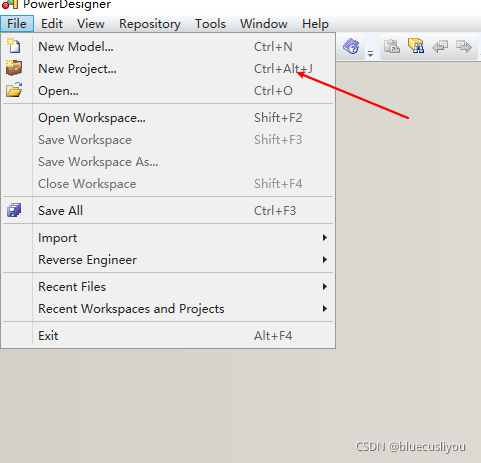
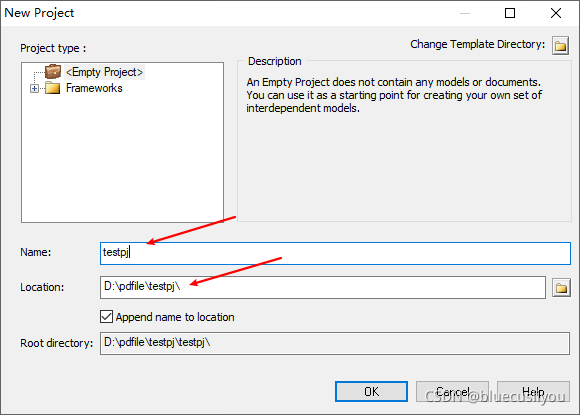
创建项目,填写项目名称,选择保存目录
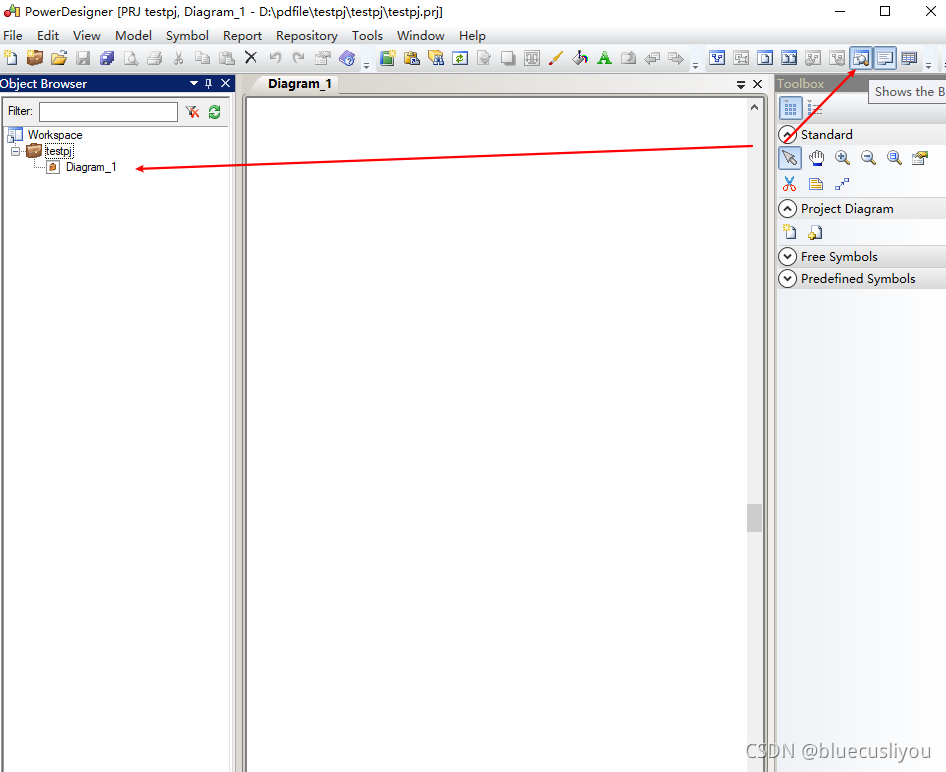
创建模型文件
创建表,添加字段
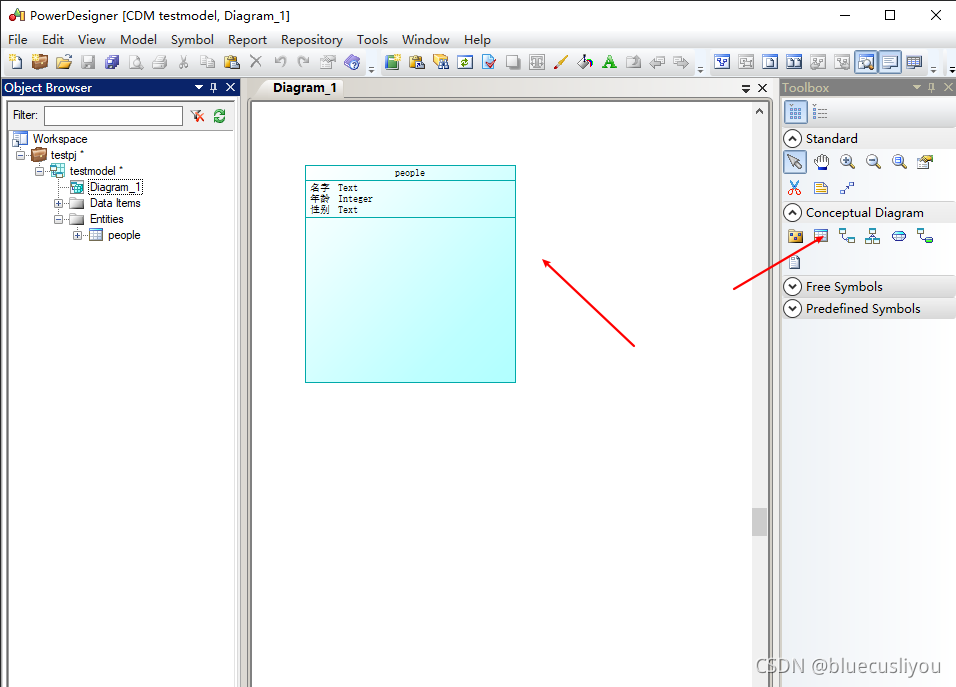
可以显示字段说明

生成物理数据模型
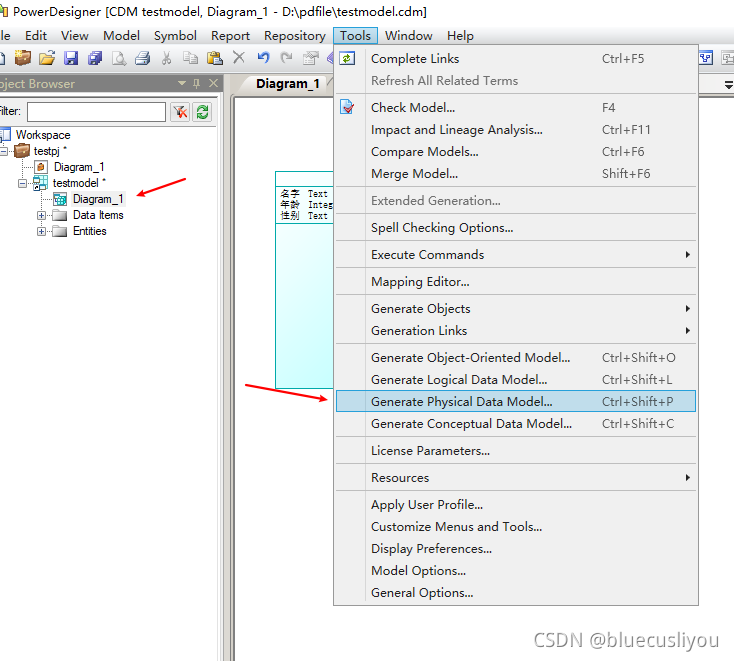
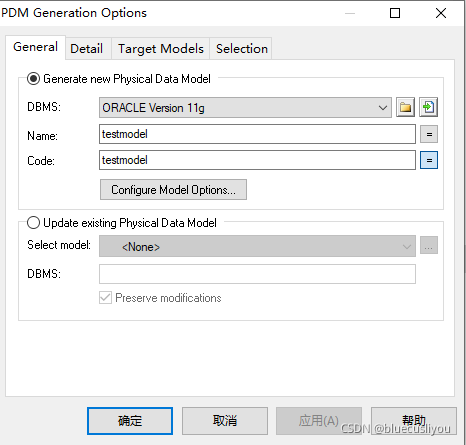
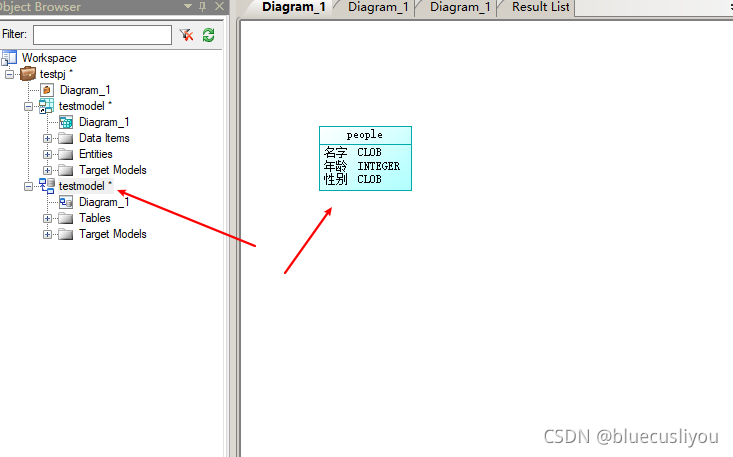
生成SQL脚本
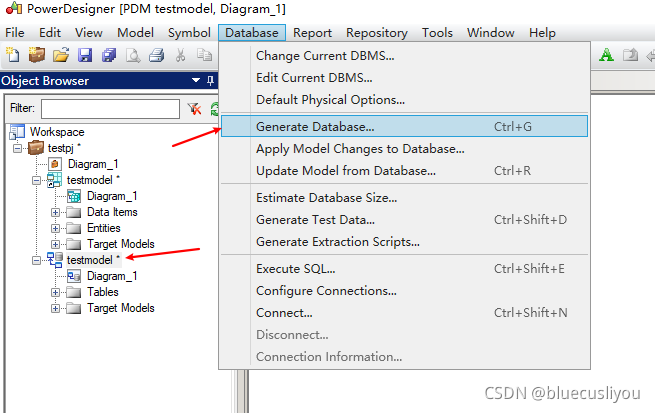
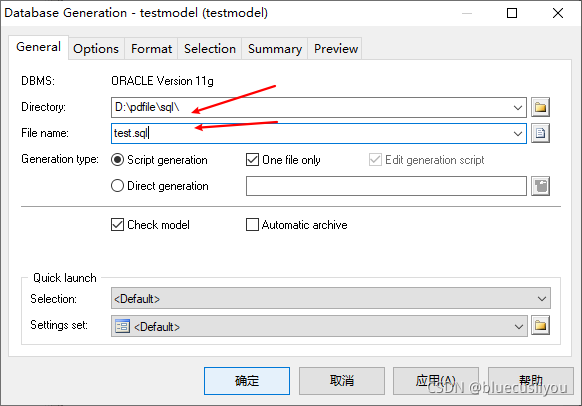
(3)PD从数据库生成模型
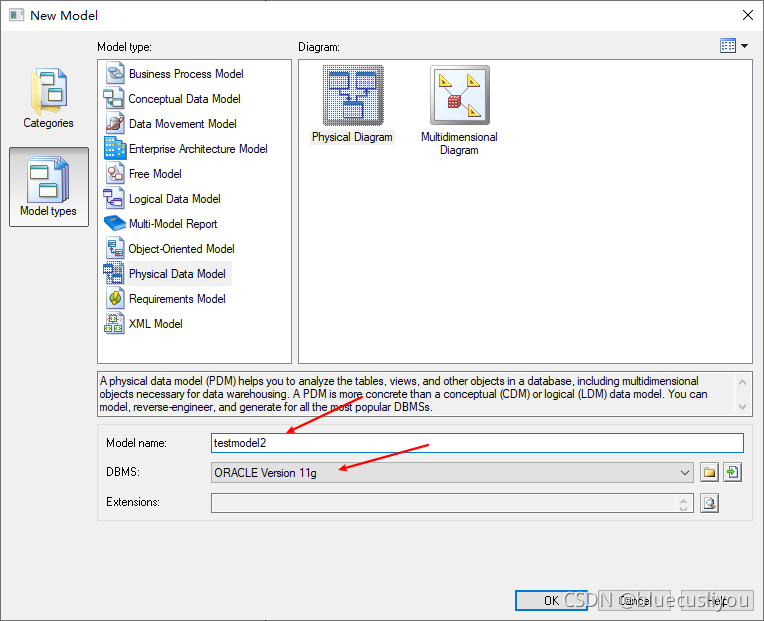
创建模型,选择数据库类型
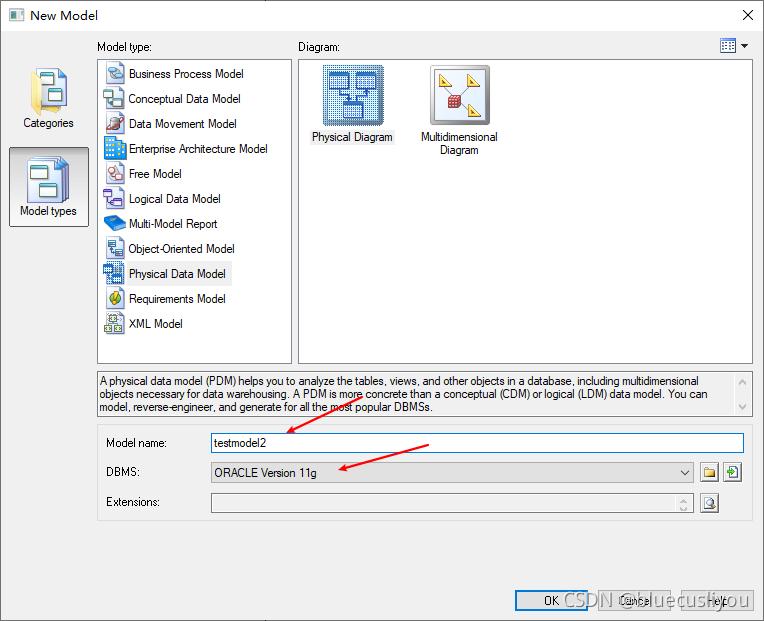
配置数据库连接导出模型
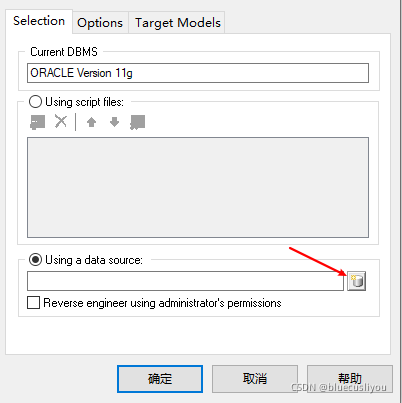
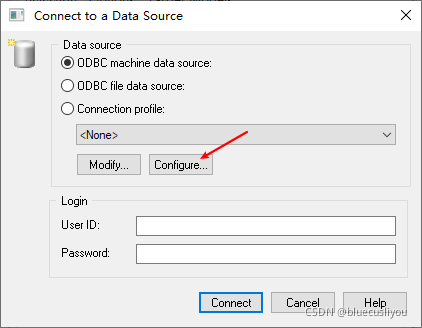
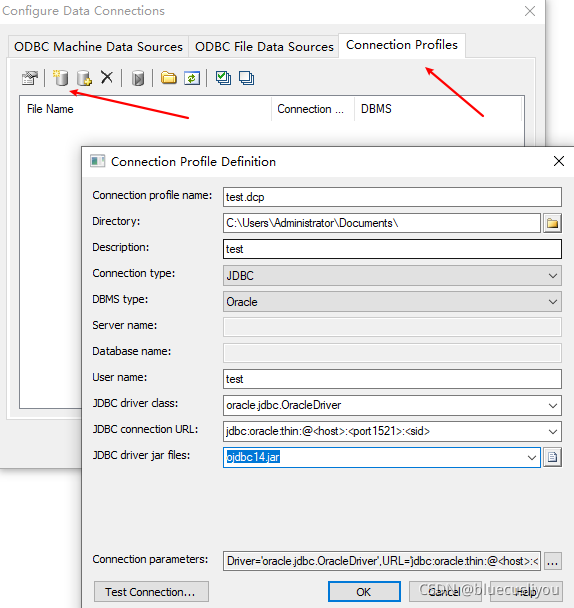
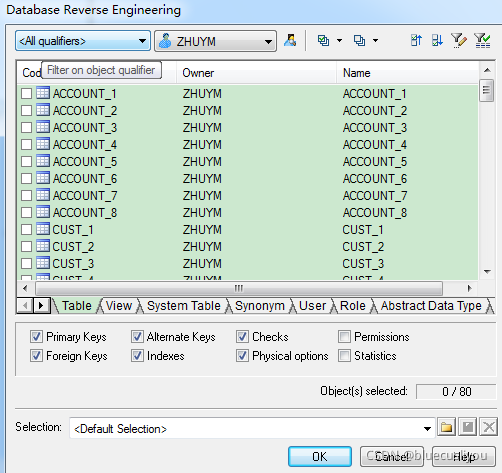
(4)PD数据类型说明
| Standard data type | DBMS-specific physical data type | Content | Length |
|---|---|---|---|
| Integer | int / INTEGER | 32-bit integer | — |
| Short Integer | smallint / SMALLINT | 16-bit integer | — |
| Long Integer | int / INTEGER | 32-bit integer | — |
| Byte | tinyint / SMALLINT | 256 values | — |
| Number | numeric / NUMBER | Numbers with a fixed decimal point | Fixed |
| Decimal | decimal / NUMBER | Numbers with a fixed decimal point | Fixed |
| Float | float / FLOAT | 32-bit floating point numbers | Fixed |
| Short Float | real / FLOAT | Less than 32-bit point decimal number | — |
| Long Float | double precision / BINARY DOUBLE | 64-bit floating point numbers | — |
| Money | money / NUMBER | Numbers with a fixed decimal point | Fixed |
| Serial | numeric / NUMBER | Automatically incremented numbers | Fixed |
| Boolean | bit / SMALLINT | Two opposing values (true/false; yes/no; 1/0) | — |
| Standard data type | DBMS-specific physical data type | Content | Length |
|---|---|---|---|
| Characters | char / CHAR | Character strings | Fixed |
| Variable Characters | varchar / VARCHAR2 | Character strings | Maximum |
| Long Characters | varchar / CLOB | Character strings | Maximum |
| Long Var Characters | text / CLOB | Character strings | Maximum |
| Text | text / CLOB | Character strings | Maximum |
| Multibyte | nchar / NCHAR | Multibyte character strings | Fixed |
| Variable Multibyte | nvarchar / NVARCHAR2 | Multibyte character strings | Maximum |
| Standard data type | DBMS-specific physical data type | Content | Length |
|---|---|---|---|
| Date | date / DATE | Day, month, year | — |
| Time | time / DATE | Hour, minute, and second | — |
| Date & Time | datetime / DATE | Date and time | — |
| Timestamp | timestamp / TIMESTAMP | System date and time | — |
| Standard data type | DBMS-specific physical data type | Content | Length |
|---|---|---|---|
| Binary | binary / RAW | Binary strings | Maximum |
| Long Binary | image / BLOB | Binary strings | Maximum |
| Bitmap | image / BLOB | Images in bitmap format (BMP) | Maximum |
| Image | image / BLOB | Images | Maximum |
| OLE | image / BLOB | OLE links | Maximum |
| Other | — | User-defined data type | — |
| Undefined | undefined | Undefined. Replaced by the default data type at generation. | — |
4、三大范式
数据库的设计范式是数据库设计所需要满足的规范,满足这些规范的数据库是简洁的、结构明晰的。
(1)第一范式(1NF)列不可再分
- 每一列属性都是不可再分的属性值,确保每一列的原子性
- 两列的属性相近或相似或一样,尽量合并属性一样的列,确保不产生冗余数据
(2)第二范式(2NF)属性完全依赖于主键
- 第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。
- 第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。这个惟一属性列被称为主键。
(3)第三范式(3NF)属性不依赖于其它非主属性 属性直接依赖于主键
- 数据不能存在传递关系,即每个属性都跟主键有直接关系而不是间接关系。
- 比如Student表(学号,姓名,年龄,性别,所在院校,院校地址,院校电话)应该拆解成两张表(学号,姓名,年龄,性别,所在院校)+(所在院校,院校地址,院校电话)
(4)平衡范式与冗余
- 冗余是以存储换取性能,范式是以性能换取存储。
- 模型设计时,这两方面的具体的权衡,首先要以企业提供的计算能力和存储资源为基础。其次,建模也是以任务驱动的,因此冗余和范式的权衡需要符合任务要求。
5、表和表关系
(1)一对一
- 单个表存储
- 两个表存储:两个表之间,数据记录是一对一的关系,通过同一个主键来约束
(2)一对多
- 单个表存储
- 两个表存储:(推荐)主表的一条记录对应从表中的多条记录,通过主外键关系来关联存储
(3)多对多
- 单个表存储
- 两个表存储
- 三个表存储:(推荐)两个数据主要保存数据,关系表保存关系数据
6、设计习惯
以公司为单位,定制的一些内部的规范,统一的习惯对这个团队来说,会有促进作用
(1)命名规范
- 驼峰命名法: 指当变量名和方法名称是由二个或二个以上单词连结在一起,首个单词首字母小写,其他单词首字母大写,而构成的唯一识别字时,用以增加变量和函式的可读性。
- 帕斯卡命名法:指当变量名和方法名称是由二个或二个以上单词连结在一起,每个单词首字母大写。而构成的唯一识别字时,用以增加变量和函式的可读性。
- 坚决抵制中文,提倡使用英文单词,建议不要用汉语拼音 ,坚决抵制使用拼音首字母,建议不要太长,意思明确
(2)常用公共字段
- ID:表的物理ID
- CreateBy:行记录创建人
- CreateTime:行记录创建时间
- UpdateBy:行记录更新人
- UpdateTime:行记录更新时间
- UserIP:操作人IP
- TS:时间戳,版本号,乐观锁更新用
- ISDEL:假删除标识
四、数据库数据类型
1、整数类型
(1)int
存储在4个字节中,其中1个二进制位表示符号位,其它31个二进制位表示长度和大小,可以表示-231~231-1范围内的所有整数。
(2)bigint
存储在8个字节中,其中1个二进制位表示符号位,其它63个二进制位表示长度和大小,可以表示-263~263-1范围内的所有整数。
(3)smallint
存储在2个字节中,其中1个二进制位表示符号位,其它15个二进制位表示长度和大小,可以表示-215~215-1范围内的所有整数。
(4)tinyint
存储在1个字节中,可以表示0~255范围内的所有整数。
2、 浮点类型
浮点数据类型存储十进制小数,浮点数据为近似值,Sql Server中采用了只入不舍的方式进行存储,即当要舍入的数是一个非零数时,就进1。
(1)real
存储在4个字节中,可以存储正的或者负的十进制数值,它的存储范围从-3.40E+38~-1.18E-38、0以及 1.18E-38~3.40E+38。
(2)float
- float数据类型可以写成float(n)的形式,n为指定float数据的精度,n为1-53之间的整数值。n的默认值为53,占用8个字节的存储空间,其范围从-1.79E+308-2.23E-308、0以及2.23E+308~1.79E-308。
- 当n取1-24时,实际上定义了一个real类型的数据,系统用4个字节存储它。
- 当n取25-53时,系统认为其是float类型,用8个字节存储它。
(3)decimal[(p[,s])] 和 numeric[(p[,s])
- 带固定精度和小数位数的数值数据类型。使用最大精度时,有效值从-1038+1–1038-1。numeric在功能上等价于decimal。
- p(精度):指定了数值的总位数,包括小数点左边和右边的位数,该精度必须是从1~38之间的值,默认精度为18。
- s(小数位数):指定小数点右边数值的最大位数,小数位数必须是从0到p之间的值,仅在指定精度后才可以指定小数的位数,默认小数位数是0;
3、字符串类型
(1)前缀说明
- var:表示是实际存储空间是变长的,不带var,存储长度不足时,空格补足。带var节省空间,但效率低,不带var,浪费空间,但效率高。
- n:表示为Unicode字符,字符中,英文字符只需要一个字节存储就足够了,但汉字众多,需要两个字节存储,英文与汉字同时存在时容易造成混乱,Unicode字符集就是为了解决字符集这种不兼容的问题而产生的,它所有的字符都用两个字节表示,即英文字符也是用两个字节表示。
(2)char(n)
- 固定长度,存储ANSI字符,不足的补英文半角空格。若插入字段的数据过长,则会截掉其超出部分,数据库不会异常。
- n的取值为1~8000。最多8000个英文,4000个汉字,如不指定n的值,系统默认n的值为1。
(3)varchar(n)
- 可变长度,存储ANSI字符,根据数据长度自动变化。
- n的取值为1~8000。最多8000个英文,4000个汉字,如不指定n的值,系统默认n的值为1,但可根据实际存储的字符数改变存储空间。存储大小是输入数据的实际长度加2个字节。加的两个字节是用来存储字段长度的。
(4)nchar(n)
- 固定长度,存储Unicode字符,不足的补英文半角空格。
- n值必须在1~4000。最多4000个英文或者汉字,如不指定n的值,系统默认n的值为1。
(5)nvarchar(n)
- 可变长度,存储Unicode字符,根据数据长度自动变化。
- n值必须在1~4000。最多4000个英文或者汉字,如不指定n的值,系统默认n的值为1。但可根据实际存储的字符数改变存储空间。存储大小是输入数据的实际长度加2个字节。加的两个字节是用来存储字段长度的。
4、日期和时间类型
(1)date
存储用字符串表示的日期数据,可以表示0001-01-01~9999-12-31(公元元年1月1日到公元9999年12月31日)间的任意日期值。数据格式为“YYYY-MM-DD”,该数据类型占用3个字节的空间。
YYYY:表示年份的四位数字,范围为0001~9999。
MM:表示指定年份中月份的两位数字,范围为01~12。
DD:表示指定月份中某一天的两位数字,范围为01~31(最高值取决于具体月份)。
(2)time
以字符串形式记录一天的某个时间,取值范围为00:00:00.0000000~23:59:59.9999999,数据格式为“hh:mm:ss[.nnnnnnn]”,存储时占用5个字节的空间。
hh:表示小时的两位数字,范围为0~23。
mm:表示分钟的两位数字,范围为0~59。
ss:表示秒的两位数字,范围为0~59。
n:是07位数字,范围为09999999,它表示秒的小部分。
(3)datetime
用于存储时间和日期数据,从1753年1月1日到9999年12月31日,默认值为 1900-01-01 00:00:00,当插入数据或在其它地方使用时,需用单引号或双引号括起来。可以使用“/”、“-”和“.”作为分隔符。该类型数据占用8个字节的空间。
(4)datetime2
datetime的扩展类型,其数据范围更大,默认的最小精度最高,并具有可选的用户定义的精度。默认格式为:YYYY-MM-DD hh:mm:ss[.fractional seconds],日期的存取范围是0001-01-01~9999-12-31(公元元年1月1日到公元9999年12月31日)。
(5)smalldatetime
smalldatetime类型与datetime类型相似,只是其存储范围是从1900年1月1日到2079年6月6日,当日期时间精度较小时,可以使用smalldatetime,该类型数据占用4个字节的存储空间。
(6)datetimeoffset
用于定义一个采用24小时制与日期相组合并可识别时区的时间。默认格式是:“YYYY-MM-DD hh:mm:ss[.nnnnnnn][{+|-}hh:mm]”。
hh:两位数,范围是-14~14。
mm:两位数,范围为00~59。
这里hh是时区偏移量,该类型数据中保存的是世界标准时间(UTC)值,eg:要存储北京时间2011年11月11日12点整,存储时该值将是2011-11-11 12:00:00+08:00,因为北京处于东八区,比UTC早8个小时。存储该数据类型数据时默认占用10个字节大小的固定存储空间。
5、文本和图像类型
(1)text
用于存储文本数据,服务器代码页中长度可变的非Unicode数据,最大长度为2的31次方-1(2147 483 647)个字符。当服务器代码页使用双字节字符时,存储仍是2147 483 647字节。
(2)ntext
与text类型作用相同,为长度可变的非Unicode数据,最大长度为 2^30-1 (1073 741 283)个字符。存储大小是所输入字符个数的两倍。
(3)image
长度可变的二进制数据,范围为 :0—2^31-1个字节。用于存储照片、目录图片或者图画,容量也是2147 483 647个字节,由系统根据数据的长度自动分配空间,存储该字段的数据一般不能使用insert语句直接输入。
6、货币类型
(1)money
用于存储货币值,取值范围为正负922 337 213 685 477.580 8之间。money数据类型中整数部分包含19个数字,小数部分包含4个数字,因此money数据类型的精度是19,存储时占用8个字节的存储空间。
(2)smallmoney
与money类型相似,取值范围为正负214 748.346 8之间,smallmoney存储时占用4个字节存储空间。
7、位数据类型
bit 称为位数据类型,只取0或1为值,长度1字节。bit值经常当作逻辑值用于判断true(1)或false(0),输入非0值时系统将其替换为1。
8、二进制类型
(1)binary(n)
长度为n个字节的固定长度二进制数据,其中n是从1~8000的值。存储大小为n个字节。在输入binary值时,必须在前面带0x,可以使用0xAA5代表AA5,如果输入数据长度大于定于的长度,超出的部分会被截断。
(2)varbinary(n)
可变长度二进制数据。其中n是从1~8000的值,存储大小为所输入数据的实际长度+2个字节。
9、其它数据类型
(1)rowversion
每个数据都有一个计数器,当对数据库中包含rowversion列的表执行插入或者更新操作时,该计数器数值就会增加。此计数器是数据库行版本。一个表只能有一个rowversion列。每次修改或者插入包含rowversion列的行时,就会在rowversion列中插入经过增量的数据库行版本值。
公开数据库中自动生成的唯一二进制数字的数据类型。rowversion通常用作给表行加版本戳的机制。存储大小为8个字节。rowversion数据类型只是递增的数字,不保留日期或时间。
(2)timestamp
时间戳数据类型,timestamp的数据类型为rowversion数据类型的同义词,提供数据库范围内的唯一值,反映数据修改的唯一顺序,是一个单调上升的计数器,此列的值被自动更新。在create table或alter table语句中不必为timestamp数据类型指定列名。
(3)uniqueidentifier
16字节的GUID(Globally Unique Identifier,全球唯一标识符),是Sql Server根据网络适配器地址和主机CPU时钟产生的唯一号码,其中,每个为都是09或af范围内的十六进制数字。例如:6F9619FF-8B86-D011-B42D-00C04FC964FF,此号码可以通过newid()函数获得,在全世界各地的计算机由此函数产生的数字不会相同。
(4)cursor
游标数据类型,该类型类似与数据表,其保存的数据中的包含行和列值,但是没有索引,游标用来建立一个数据的数据集,每次处理一行数据。
(5)sql_variant
用于存储除文本,图形数据和timestamp数据外的其它任何合法的Sql Server数据,可以方便Sql Server的开发工作。
(6)table
用于存储对表或视图处理后的结果集。这种新的数据类型使得变量可以存储一个表,从而使函数或过程返回查询结果更加方便、快捷。
(7)xml
存储xml数据的数据类型。可以在列中或者xml类型的变量中存储xml实例。存储的xml数据类型表示实例大小不能超过2GB。
五、数据库和表操作
1、数据库相关
(1)创建数据库
create database database_name
[ on
[primary] [<filespec> [,...n] ]
]
[ log on
[<filespec>[,...n]]
];
- 1
- 2
- 3
- 4
- 5
- 6
- 7