
- 1termux从入门到入坑_termux使用教程
- 2Proxy代理数据拦截方法_proxy {
: {…}, : {…} } - 3程序员在晚上才敢偷偷看的10个网站,建议私藏!_晚上看的你明白的我的意思网站
- 4WinForm,可能是Windows上手最快的图形框架了
- 5蓝桥杯:螺旋矩阵
- 6JavaScript 二进制数组(ArrayBuffer、Typed Array、DataView)_js 二进制数组
- 7c++: 单例模式(Singleton)的最优写法_c++ 最优单例模式
- 8next(iter())在机器学习中的用法
- 9CentOS 下Nginx版本升级_centos 升级nginx
- 10C#实现S2算法_s2 geometry
Azure机器学习——数据集01:数据集的存储和交互_azure blob 文件作为 训练数据集
赞
踩
数据集的存储和交互(Azure Blob存储和Datastore类)
本节主要介绍数据集在Azure云上的存储以及数据集如何在本地和Azure云之间进行交互。
数据集在Azure机器学习(AML)中占有重要地位,是Azure机器学习工作区的重要组成部分。

图1 工作区及其组件(图片来自官网)
数据集在Azure机器学习中的管理和使用主要包括:
- 数据集在云上的存储以及与本地和AML工作区的交互;
- 在Azure机器学习工作区中注册数据集;
- 在模型训练中使用数据集;
- 数据集的版本控制和跟踪;
- 图像数据的标记和使用。
本节主要介绍数据集在云上的存储以及与本地和工作区的交互。

图2 数据集在Azure机器学习中的管理和使用
在开始本节内容之前,你需要:
- Azure 订阅和Azure机器学习工作区。创建方法:Azure机器学习(实战篇)——创建Azure机器学习服务
- 配置Azure机器学习开发环境。配置方法:Azure机器学习(实战篇)——配置 Azure 机器学习开发环境
一、数据集存储位置
Azure Blob 存储
如果你有大量数据,你可以将其存储在Azure Blob 存储中。Azure Blob 存储是 Microsoft 提供的适用于云的对象存储解决方案,最适合存储巨量的非结构化数据,可以帮你在机器学习试验期间节省数据输入输出成本。
Blob是Azure中一种数据存储方式,若要深入了解,请查看此链接。
如果要使用Blob存储,需要有一个存储账户(创建 Azure 存储帐户)。存储账户中数据的存储方式有容器、数据共享、表和队列四种。容器对一组 blob 进行组织,类似于文件系统中的目录。 我们一般将非结构化数据存储在存储账户的容器中。
一个存储帐户可以包含无限数量的容器,一个容器可以存储无限数量的 Blob。他们之间的关系如下图所示。
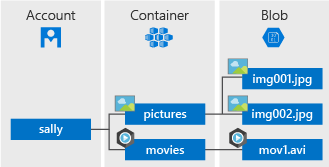
图3 存储账户、容器和Blob之间的关系(图片来自官网)
将数据移至 Blob 存储
有许多用于将现有数据迁移到 Blob 存储的解决方案,具体请看官网链接。下面主要介绍几种我经常用到的数据迁移方案。
portal
可以直接在portal上对Blob存储进行数据的上传和下载。
点击:portal主页——>某个已创建好的存储账户——>容器。
可以看到容器中的文件以及在容器中上传、下载和删除等操作。
优点:直接在portal上操作,适合进行小批量数据交互操作。

图4 portal中上传下载数据
Azure 存储资源管理器
这是一个免费的客户端工具,可通过 Windows、macOS 或 Linux 轻松管理任何位置的 Azure 云存储资源:上传、下载和管理 Azure blob、文件、队列和表,以及 Azure Cosmos DB 和 Azure Data Lake Storage 实体。方便易用,功能强大,下载链接。
优点:批量上传文件或者文件夹,存储数据实时更新,管理器中可以添加多个存储账户,方便管理。

图5 Azure 存储资源管理器
Azcopy
AzCopy 是一个命令行实用工具,可用于在存储帐户中复制 blob 或文件。
Azcopy安装、连接存储账户、传输文件教程。
优点:传输速度特别快,适合超大容量数据传输。
二、Azure机器学习访问Blob存储数据
Azure机器学习和Azure Blob存储是Azure中两个不同的服务。假设我们已经将数据集保存在了Azure Blob存储中,要想在Azure机器学习中使用这些数据集,还需要在这两个服务之间建立一种连接。
这种连接可以通过数据存储(Datastore)实现。
Datastore是一个类,使用此类可执行管理操作,包括注册、列出、获取和删除数据存储。下面提到的数据存储(Datastore)都是指这个类或其实例。
使用 Azure 机器学习数据存储(Datastore)可以轻松访问 Azure Blob存储服务中的数据。 数据存储(Datastore)用于存储连接信息,如订阅 ID 和令牌授权。 当你使用数据存储(Datastore)时,你可以访问存储,而无需在脚本中对连接信息进行硬编码。

图6 AML工作区和Blob存储通过Datastore类交换数据
除了Azure Blob存储,数据存储(Datastore)目前还支持其他的Azure存储服务。
以下演示如何使用数据存储(Datastore),首先我们连接Azure机器学习工作区:
———————————————————————————————————————————————————————————————
注意:为了确保能够连接成功,在连接工作区之前建议先使用az login登陆Azure,具体步骤如下:
- 下载和安装 Azure CLI。
- 如果使用Azure China,那么在Windows cmd或者Linux终端中输入:
az cloud set --name AzureChinaCloud
- 1
将Azure设置为AzureChina。
如果要切换成AzureGlobal,则输入:
az cloud set --name AzureCloud
- 1
- 在Windows cmd或者Linux终端中输入
az login
- 1
将打开默认浏览器进入Azure登陆页面。登陆后一般就能正常连接到工作区。
———————————————————————————————————————————————————————————————
通过 Python SDK 使用现有工作区,导入 Workspace 和 Datastore 类,然后从使用函数 from_config()从config.json 文件中加载订阅信息。 默认情况下,这将在当前目录中查找 JSON 文件,但你也可以使用 from_config(path=“your/file/path”)指定路径参数以指向该文件。
import azureml.core
from azureml.core import Workspace, Datastore
ws = Workspace.from_config(path="config.json")
- 1
- 2
- 3
- 4
本地文件"config.json"中包含了需要连接的工作区的workspace_name、subscription_id和resource_group这三个信息。ws是要连接的工作区。
访问默认数据存储(Datastore)
在Azure机器学习介绍中,我们介绍过在创建工作区的同时,系统会自动创建一个存储账户,该账户内的Blob存储用作工作区的默认数据存储(Datastore)。
我们可以使用以下代码来访问该默认数据存储(Datastore):
datastore = ws.get_default_datastore()
- 1
该数据存储(Datastore)在存储账户中的位置如下图所示:

图7 工作区默认数据存储在存储账户种的位置]
可以通过数据存储(Datastore)的upload()和download()方法往该Blob存储中上传和下载文件:
使用 Python SDK 将单个文件的列表上载到数据存储(Datastore)。
datastore.upload_files(files = ['./dataset/iris.csv'], ##本地文件位置
target_path = 'data_for_demo/tabular/', ##Blob存储中文件位置
overwrite = True,
show_progress = True)
- 1
- 2
- 3
- 4
输出:
Uploading an estimated of 1 files
Uploading ./dataset/iris.csv
Uploaded ./dataset/iris.csv, 1 files out of an estimated total of 1
Uploaded 1 files
- 1
- 2
- 3
- 4
target_path 参数指定要上传的文件共享(或 blob 容器)中的位置。 默认为 None,因此数据上传到 root。 如果 overwrite=True,则将覆盖 target_path 上的任何现有数据。
还可以通过datastore.upload()方法将目录或单个文件上传到数据存储(Datastore)。
可以在portal存储账户的Blob存储中看到‘iris.csv“文件已上传成功。

图8 Blob存储中的文件
将数据从数据存储(Datastore)下载到本地文件系统:
datastore.download(target_path='./dataset',
prefix='data_for_demo/tabular', #下载Blob存储中这个文件夹下的所有文件
show_progress=True)
- 1
- 2
- 3
输出:
Downloading data_for_demo/tabular/iris.csv
Downloaded data_for_demo/tabular/iris.csv, 1 files out of an estimated total of 1
- 1
- 2
target_path 参数是要将数据下载到其中的本地目录的位置。 若要在文件共享(或 blob 容器)中指定要下载到的文件夹路径,请提供 prefix 的路径。 如果 None``prefix,则将下载文件共享(或 blob 容器)的所有内容。
将其他Blob存储注册为数据存储(Datastore)
可能已经上传的数据并不在默认数据存储(Datastore)中,或者出于项目或者其他原因需要将数据集保存在不同的Blob存储中。这时可以将非默认的Blob存储注册为工作区的数据存储(Datastore),从而访问这些Blob存储中的数据。
若要将 Azure blob 容器注册为数据存储(Datastore),请使用register_azure_blob-container()。
以下代码创建 blob_datastore_name 数据存储(Datastore)并将其注册到 ws 工作区。 此数据存储(Datastore)使用提供的帐户密钥访问 my-account-name 存储帐户上的 my-container-name blob 容器。
blob_datastore_name='my_datastore01' # Name of the datastore to workspace
container_name=os.getenv("BLOB_CONTAINER", "<my-container-name>") # Name of Azure blob container
account_name=os.getenv("BLOB_ACCOUNTNAME", "<my-account-name>") # Storage account name
account_key=os.getenv("BLOB_ACCOUNT_KEY", "<my-account-key>") # Storage account key
blob_datastore = Datastore.register_azure_blob_container(workspace=ws,
datastore_name=blob_datastore_name,
container_name=container_name,
account_name=account_name,
account_key=account_key)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
container_name、account_name、account_key可以在要注册的存储账户的"概述" 和"设置-访问密钥"中查的,如下图所示。

图9 container_name、account_name

图10 account_key
注册成功后可以使用以下代码查看工作区下的数据存储(Datastore):
# List all datastores registered in the current workspace
datastores = ws.datastores
for name, datastore in datastores.items():
print(name, datastore.datastore_type)
- 1
- 2
- 3
- 4
输出:
my_datastore01 AzureBlob
azureml_globaldatasets AzureBlob
workspaceblobstore AzureBlob
workspacefilestore AzureFile
- 1
- 2
- 3
- 4
可见”my_datastore01“这个数据存储(Datastore)已经注册成功。
若要获取在当前工作区中注册的某个数据存储(Datastore),请对 Datastore 类使用get()静态方法:
# Get a named datastore from the current workspace
datastore = Datastore.get(ws, datastore_name='your datastore name')
- 1
- 2
若要将某个数据存储(Datastore)定义为当前工作区的默认数据存储(Datastore),请对工作区对象使用set_default_datastore()方法:
# Define the default datastore for the current workspace
ws.set_default_datastore('your datastore name')
- 1
- 2
如果想在Azure机器学习studio中创建数据存储(Datastore),请参照此链接。
三、总结
- 介绍了数据集在Azure上的存储方式,以及几种数据集在本地和Azure之间交互的方法。
- 介绍了Azure机器学习工作区如何通过Datastore类访问Azure存储中的数据。Python SDK和机器学习studio是使用Azure机器学习的2种方式,这里主要介绍了使用Python SDK这种方式。

