
- 1跟我学Python图像处理丨图像分类原理与案例_图像分类案例
- 2zabbix监控交换机_zabbix添加锐捷交换机
- 3双目项目实战---测距(获取三维坐标和深度信息)_双目相机求解三维坐标点
- 4微信小程序访问webservice(wsdl)+ axis2发布服务端(Java)
- 5chromedriver和selenium的下载以及安装教程(114/116/117.....121版本)_chromedriver 121
- 6Window系统命令行调用控制面板程序_programs|and|features
- 701-Node.js 简史_nodejs历史版本
- 8【STM32】FSMC—扩展外部 SRAM 初步使用 1_stm32 外接 ram
- 9python爬虫爬取淘宝商品并保存至mongodb数据库_tbsearch?refpid=mm_26632258_3504122_32554087
- 10OpenWrt 软路由IPv6 DDNS Socat 端口映射_openwrt socat
终极攻略!如何彻底防止Selenium被检测!_selenium规避检测
赞
踩
在使用Selenium进行爬虫时,许多朋友都会遇到各种反爬措施。
实际上,在绝大多数情况下,网站轻而易举地能够检测出你正在使用WebDriver而非标准浏览器。
本文将详细介绍如何有效防止检测的方法。
在一篇公众号文章《别去送死了。Selenium 与 Puppeteer 能被网站探测的几十个特征》中,我们知道目前网上的反检测方法几乎都是掩耳盗铃,因为模拟浏览器有几十个特征可以被检测,仅仅隐藏 webdriver 这一个值是没有任何意义的。
今天我们就来说说应该如何正确解决这个问题。我们首先给出解决方案。然后再说明这个解决方案,我是通过什么方式找到的。
解决这个问题的关键,就是一个 js 文件,叫做stealth.min.js。这个文件的获取有点复杂,具体可以搜索一下,这里不详细介绍。
我们需要设定,让 Selenium在打开任何页面之前,先运行这个 Js 文件。
就可以避免被检测到。
论证过程如下:
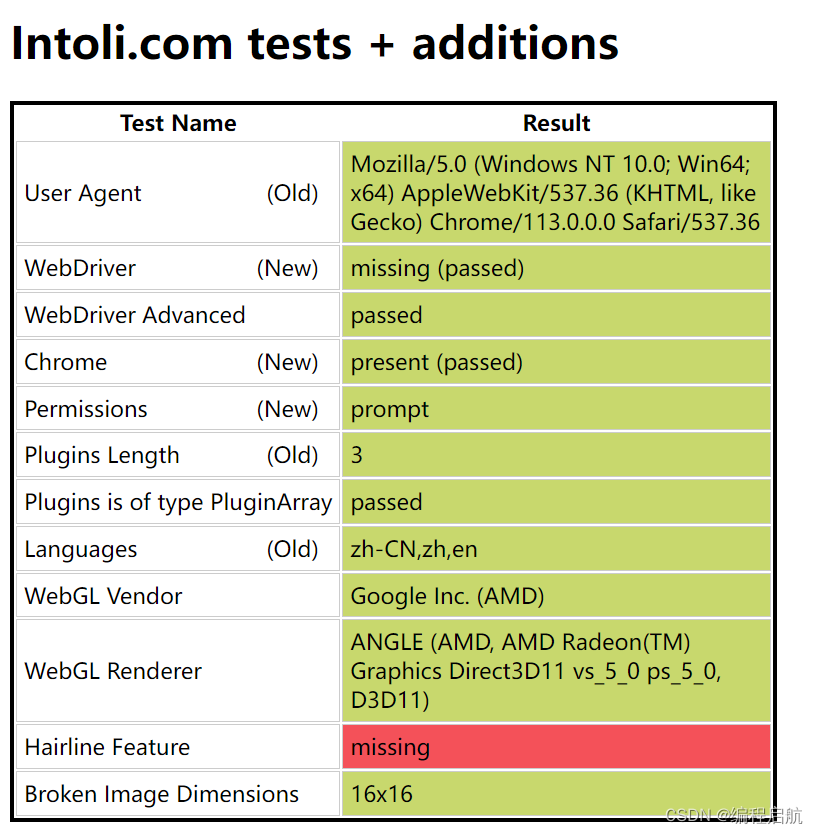
首先,我们直接在浏览器输入网址访问这个网站:
https://bot.sannysoft.com/
这些选项其实就是浏览器的特征
但我们如果使用selenium就会得到不一样的结果,如下:
代码:
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = Chrome(executable_path='./chromedriver', options=chrome_options)
driver.get('https://bot.sannysoft.com/')
driver.save_screenshot('screenshot.png')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
结果如下:
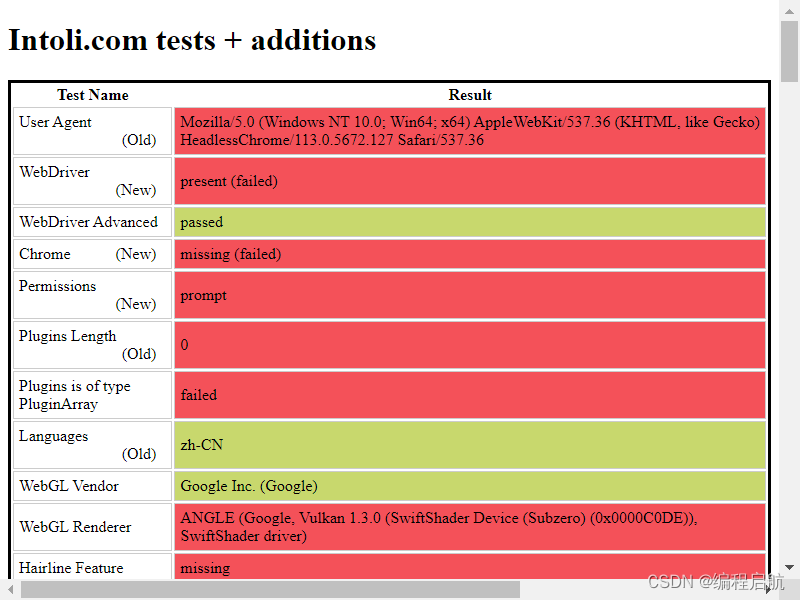
下面我们加载这个js文件后再来访问这个网站,查看特征值:
代码:
import time
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument('user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36')
driver = Chrome(executable_path='./chromedriver', options=chrome_options)
with open('./stealth.min.js') as f:
js = f.read()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
driver.get('https://bot.sannysoft.com/')
time.sleep(5)
driver.save_screenshot('walkaround.png')
source = driver.page_source
with open('result.html', 'w') as f:
f.write(source)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
结果:
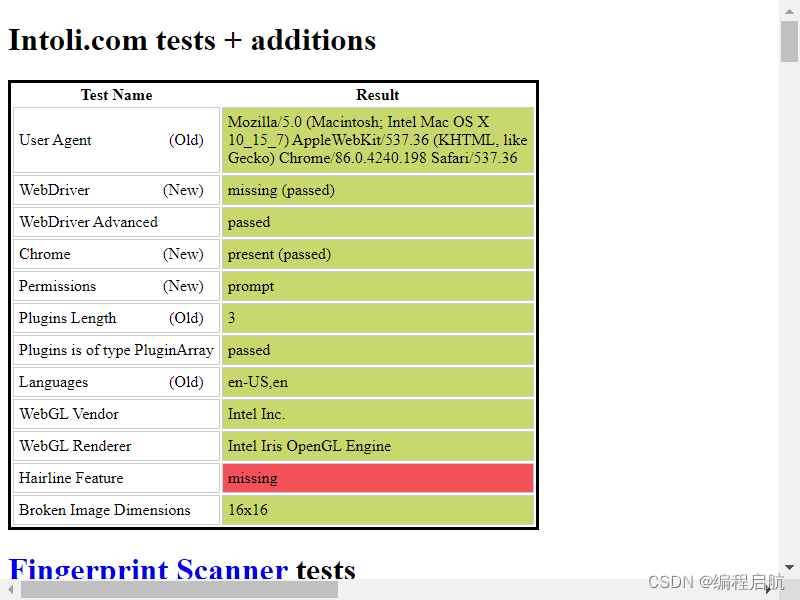
我们可以发现结果与第一种情况一模一样
js文件获取方式,公众号编程启航回复selenium反检测
更多宝藏
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/很楠不爱3/article/detail/168351
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

