
- 1zip的压缩和解压命令
- 2pyechart 饼状图 图片丢失问题_在进行pie图时数据类型一样图片显示不出来
- 3数据结构知识点总结-线性表(1)-线性表的定义、基本操作、顺序表表示
- 4Hadoop 集群维护过程中遇到的报错信息和解决办法_is not sending heartbeats
- 5使用docker自建vaultWarden服务器并实现全平台https访问_vaultwarden docker
- 6apple macbook M系列芯片安装 openJDK17_mac openjdk17
- 7Pyecharts+django 官方样例图片不显示_django pyechart图无法显示
- 8LeetCode 69. x 的平方根_leetcode 69. x 的平方根 c++
- 9基于springboot仓库管理系统开题报告范文
- 10php直播系统app吗,ThinkPHP完美运营版安卓苹果双端直播系统APP源码 带主播连麦PK功能源码...
虎博开源大模型TigerBot-70B发布_tigerbot-70b-chat-v2
赞
踩
我们很高兴地发布Tigerbot-70b,继续开源和免费商用,包括:
-
Tigerbot-70b-base: 在Llama-2-70b的基础上继续预训练,模型综合能力在mmlu等10项主流基准测试中,优于Llama-2-70b,达到业内SOTA。
-
用高质量的300GB token多语言数据,
-
算法上使用了GQA, flash-attn, RoPE, holistic-training等技术,
-
训练采用了tensor/pipeline-partition技术,计算效率达到Llama-2 paper中报告的SOTA。
-
-
Tigerbot-70b-chat: 在Tigerbot-70b-base基础上,用20M指令完成数据进行sft,和10K人类标注的gold set进行rejection-sampling对齐。
-
同步开放Tigerbot-70b-chat-api,继续对教育和科研开发者免费。
模型训练
Tigerbot-70b是在Llama-2-70b的基础上用高质量的多语言数据300B tokens继续预训练,如下图第一部分训练数据的收敛曲线所示,比之前7b和13b呈现出更好的loss收敛。
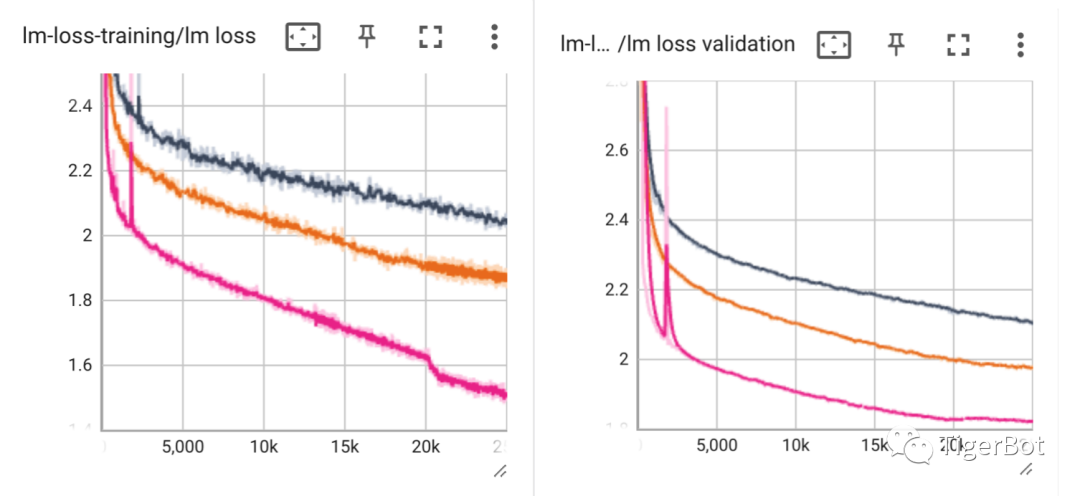
我们认为在算法出色的基础上,数据的质量直接影响到模型能力,因此,我们此次训练启用了新的数据mix,以达到模型对知识、数理、通用型任务等纬度更综合的性能提升。对于中文网络数据,我们采用了新的清洗算法,去除网络口语化、低知识密度等问题。对于30b以上的大模型,我们认为计算性能和模型能力的权衡至关重要,因此,我们采用了GQA (group-query-attention), flash-attention (flash-attention), RoPE (rotary-position-embedding), holistic-training等前沿算法,分布式训练上采用了tensor/pipeline-partition技术,并在正式训练前用geometric search快速找到在我们有限算力下的最佳权衡训练参数。
在指令微调阶段,我们采用了20M指令完成数据进行SFT,然后采用人类标注的10K gold-set数据进行rejection-sampling的对齐微调。对于指令微调数据,我们进行了基于任务类型去重和扩充,人类标注的gold-set来自于真实用户prompt,模型randomly sample生成后,并经过reward model ranking和最终人类标注。微调训练阶段的validation和test sets也由人类标注挑选,如下图所示,tigerbot-70b-chat训练达到业内SOTA的~1.2的training loss和~0.5的validation loss。

模型评测
我们以业内主流的10项基准测试集对模型的阅读理解、推理、世界知识、常识问答、数理和代码等能力进行评测,包括:mmlu, arc, squad_v2, squad, mrqa, web_questions, openbook_qa, commonsense_qa, trivia_qa, wiki_qa。评测结果如下图所示,Tigerbot-70b综合能力优于Llama-2-70b,也领先于国内外开源大模型。

后续
Tigerbot会一如既往地推出更优质的模型,分享算法和工程上的突破和经验,以我们绵薄之力提倡open innovation!
TigerBot demo 在线体验:
https://tigerbot.com/chat
Github 项目:
https://github.com/TigerResearch/TigerBot
微信讨论群


