
- 1mysql 更改端口号踩的坑_ubuntu mysql 端口不生效
- 2华为OD机试真题-智能成绩表-2023年OD统一考试(C卷)---Python3--开源
- 3SEO实战密码(第3版) 60天网站流量提高20倍-3_seo实战密码第3版.pdf
- 4微信小程序支付功能 C# .NET开发_小程序微信支付开发+c#
- 5COMM1190 R数据分析 data analysis
- 6uni-file-picker 上传图片至服务器
- 7cmd输入python但是打开microsoft store问题_为什么安装好了python环境变量在终端执行python命令却给我弹出microsoft store
- 8LPIPS图像相似性度量标准:The Unreasonable Effectiveness of Deep Features as a Perceptual Metric
- 9Chrome阅读.md格式文件——Markdown Preview Plus_chrome 阅读本地 md 插件
- 10免费看电影_jdav
语音识别模型whisper的参数说明_whisper模型
赞
踩
一、whisper简介:
Whisper是一种通用的语音识别模型。它是在各种音频的大型数据集上训练的,也是一个多任务模型,可以执行多语言语音识别、语音翻译和语言识别。
二、whisper的参数
1、-h, --help
查看whisper的参数
2、--model {tiny.en,tiny,base.en,base,small.en,small,medium.en,medium,large-v1,large-v2,large}
选择使用的模型,默认值:small
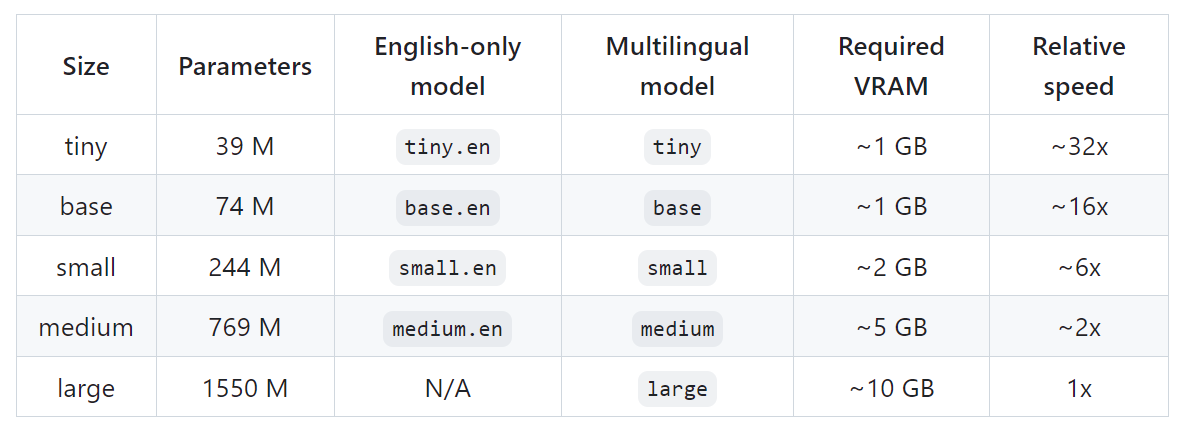
3、--model_dir MODEL_DIR
模型文件的保存路径,默认值:~/.cache/whisper
4、--device DEVICE
PyTorch接口使用的设备,默认值:CPU
5、--output_dir OUTPUT_DIR, -o OUTPUT_DIR
输出结果保存的目录,默认值:当前目录
6、--output_format {txt,vtt,srt,tsv,json,all}, -f {txt,vtt,srt,tsv,json,all}
输出文件的格式,默认值:all
7、--verbose VERBOSE
是否打印进展和debug信息,默认值:true
8、--task {transcribe,translate}
transcribe:语音转文字
translate:语音转英语
默认值:transcribe
9、--language {af,am,ar,as,az,ba,be,bg,bn,bo,br,bs,ca,cs,cy,da,de,el,en,es,et,eu,fa,fi,fo,fr,gl,gu,ha,haw,he,hi,hr,ht,hu,hy,id,is,it,ja,jw,ka,kk,km,kn,ko,la,lb,ln,lo,lt,lv,mg,mi,mk,ml,mn,mr,ms,mt,my,ne,nl,nn,no,oc,pa,pl,ps,pt,ro,ru,sa,sd,si,sk,sl,sn,so,sq,sr,su,sv,sw,ta,te,tg,th,tk,tl,tr,tt,uk,ur,uz,vi,yi,yo,zh,Afrikaans,Albanian,Amharic,Arabic,Armenian,Assamese,Azerbaijani,Bashkir,Basque,Belarusian,Bengali,Bosnian,Breton,Bulgarian,Burmese,Castilian,Catalan,Chinese,Croatian,Czech,Danish,Dutch,English,Estonian,Faroese,Finnish,Flemish,French,Galician,Georgian,German,Greek,Gujarati,Haitian,Haitian Creole,Hausa,Hawaiian,Hebrew,Hindi,Hungarian,Icelandic,Indonesian,Italian,Japanese,Javanese,Kannada,Kazakh,Khmer,Korean,Lao,Latin,Latvian,Letzeburgesch,Lingala,Lithuanian,Luxembourgish,Macedonian,Malagasy,Malay,Malayalam,Maltese,Maori,Marathi,Moldavian,Moldovan,Mongolian,Myanmar,Nepali,Norwegian,Nynorsk,Occitan,Panjabi,Pashto,Persian,Polish,Portuguese,Punjabi,Pushto,Romanian,Russian,Sanskrit,Serbian,Shona,Sindhi,Sinhala,Sinhalese,Slovak,Slovenian,Somali,Spanish,Sundanese,Swahili,Swedish,Tagalog,Tajik,Tamil,Tatar,Telugu,Thai,Tibetan,Turkish,Turkmen,Ukrainian,Urdu,Uzbek,Valencian,Vietnamese,Welsh,Yiddish,Yoruba}
音频文件的语言设置,设置为无则会进行语言检测
默认值:无
10、--temperature TEMPERATURE
用于取样的温度
默认值:0
11、--best_of BEST_OF
在非零温度下采样时的候选数量
默认值:5
12、--beam_size BEAM_SIZE
beam search 算法中beams的数量,只适用于temperature为0的情况
默认值:5
13、--patience PATIENCE
选项patience值用在beam解码,参考https://arxiv.org/abs/2204.05424, 默认情况下(1.0)相当于传统beam搜索
默认值:无
14、--length_penalty LENGTH_PENALTY
可选令牌长度惩罚系数(alpha)参考https://arxiv.org/abs/1609.08144,默认情况下使用简单长度规格化
默认值:无
15、--suppress_tokens SUPPRESS_TOKENS
要在采样期间抑制的以逗号分隔的令牌ID列表;'-1'将抑制除常见标点符号以外的大多数特殊字符默认值:-1
16、--initial_prompt INITIAL_PROMPT
可选的文本作为第一个窗口的提示词
默认值:无
17、--condition_on_previous_text CONDITION_ON_PREVIOUS_TEXT
如果为true,则前一个模型的输出会作为下一个窗口的提示,禁用可能导致窗口之间的文本不一致,但该模型不太容易陷入故障循环
默认值:true
18、--fp16 FP16
是否使用FP16
默认值:true
19、--temperature_increment_on_fallback TEMPERATURE_INCREMENT_ON_FALLBACK
当解码失败遇到下面任意一个的阈值回退的时候温度将增加
默认值: 0.2
20、--compression_ratio_threshold COMPRESSION_RATIO_THRESHOLD
如果gzip压缩率大于这个值,认为解码失败
默认值:2.4
21、--logprob_threshold LOGPROB_THRESHOLD
如果平均对数概率低于此值,认为解码失败
默认值:-1.0
22、--no_speech_threshold NO_SPEECH_THRESHOLD
如果|nospeech|的概率高于此值并且因为 `logprob_threshold`解码失败,认为此片段没有声音
默认值:0.6
23、--word_timestamps WORD_TIMESTAMPS
提取单词级别的时间戳,并根据它们细化结果 (实验性质的)
默认值:False
24、--prepend_punctuations PREPEND_PUNCTUATIONS
如果word_timestamps设置为true,将这些标点符号与后一个单词合并
默认值:"'“¿([{-
25、--append_punctuations APPEND_PUNCTUATIONS
如果word_timestamps设置为true,将这些标点符号与前一个单词合并
默认值:"'.。,,!!??::”)]}、
26、--highlight_words HIGHLIGHT_WORDS
在srt和vtt中说出的每个单词下面加下划线(条件:--word_timestamps True)
默认值: false
27、--max_line_width MAX_LINE_WIDTH
换行之前,一行最大多少个字符 (条件:--word_timestamps True)
默认值: 无
28、--max_line_count MAX_LINE_COUNT
一个片段中最大包含几行 (条件:--word_timestamps True)
默认值: 无
29、--threads THREADS
在CPU接口下,torch使用的线程数量,取代 MKL_NUM_THREADS/OMP_NUM_THREADS

