
热门标签
热门文章
- 1Plugin “GsonFormat“ is incompatible supported only in IntelliJ IDEA_plugin 'gsonformat' (version 1.5.0) was explicitly
- 2ChatGPT一键私有部署,全网可用,让访问、问答不再受限,且安全稳定!
- 3使用C++实现二叉查找树(二叉搜索树)的创建、查找、插入、删除等操作_二叉搜索树 创建与插入 c++
- 4JavaWeb——Requst&Response案例(用户登录、注册)_irestresponse 怎么使用
- 52023 华为 Datacom-HCIE 真题题库 01/12--含解析_hcie安全题库
- 6【AI语音】九联UNT402A_通刷_纯净精简_免费线刷固件包
- 7Android Camera预览左右上下镜像_camera transformmatrixtoglobal 设置镜像
- 8Android 分渠道批量打包 常用插件工具_安卓多渠道打包工具
- 9Pod 中的健康检查liveness,readiness,startupProbe_liveness 容器中是什么意思
- 10OpenHarmony应用签名 - 系统应用签名(4.0-Release)_openharmoney系统签名
当前位置: article > 正文
基于cnn的卷机神经网络的项目毕业课题实践应用(毕业选题-深度学习-卷及神经网络)
作者:很楠不爱3 | 2024-03-15 18:23:22
赞
踩
基于cnn的卷机神经网络的项目毕业课题实践应用(毕业选题-深度学习-卷及神经网络)
往期热门项目回顾:
图像分类:

图像物体识别(如猫狗分类、花卉识别)
医学影像诊断(如肺部CT图像的肺癌筛查)
道路标志识别系统
手写数字识别(MNIST数据集)
行人检测
车辆类型识别
地球遥感图像分类
目标检测:
实时行人检测系统
自动驾驶汽车的障碍物检测
安防监控系统中的异常行为检测
农作物病虫害识别与定位
微表情识别与情绪分析

可以拿来使用的项目链接代码和原理
医学影像分析:
磁共振成像(MRI)脑肿瘤分割
心脏超声图像分析
X光片骨折检测
视网膜病变检测
视频动作识别:
可以参考的项目链接:代码和原理 ↓
运动姿态估计
体育比赛动作识别与分析
监控视频中的人体行为分析
自然语言处理(NLP):
可以拿来用的项目链接:有用的项目链接-原理+代码-点我
文本图像识别(OCR)
词云图像的情感分析
图像文字识别(如街景招牌的文本识别)
人脸识别与认证:

代码
#--------------------联系 方式>> qq1309399183 import argparse import time from pathlib import Path import cv2 import torch import torch.backends.cudnn as cudnn from numpy import random from models.experimental import attempt_load from utils.datasets import LoadStreams, LoadImages from utils.general import check_img_size, non_max_suppression, apply_classifier, scale_coords, xyxy2xywh, \ strip_optimizer, set_logging, increment_path from utils.plots import plot_one_box from utils.torch_utils import select_device, load_classifier, time_synchronized def detect(save_img=False): source, weights, view_img, save_txt, imgsz = opt.source, opt.weights, opt.view_img, opt.save_txt, opt.img_size print('weights: ', weights) webcam = source.isnumeric() or source.endswith('.txt') or source.lower().startswith( ('rtsp://', 'rtmp://', 'http://')) # Directories save_dir = Path(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok)) # increment run (save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir # Initialize set_logging() device = select_device(opt.device) half = device.type != 'cpu' # half precision only supported on CUDA # Load model model = attempt_load(weights, map_location=device) # load FP32 model imgsz = check_img_size(imgsz, s=model.stride.max()) # check img_size if half: model.half() # to FP16 # Second-stage classifier classify = False if classify: modelc = load_classifier(name='resnet101', n=2) # initialize modelc.load_state_dict(torch.load('weights/resnet101.pt', map_location=device)['model']).to(device).eval() # Set Dataloader vid_path, vid_writer = None, None if webcam: view_img = True cudnn.benchmark = True # set True to speed up constant image size inference dataset = LoadStreams(source, img_size=imgsz) else: save_img = True dataset = LoadImages(source, img_size=imgsz) # Get names and colors names = model.module.names if hasattr(model, 'module') else model.names colors = [[random.randint(0, 255) for _ in range(3)] for _ in names] # Run inference t0 = time.time() img = torch.zeros((1, 3, imgsz, imgsz), device=device) # init img _ = model(img.half() if half else img) if device.type != 'cpu' else None # run once for path, img, im0s, vid_cap in dataset: img = torch.from_numpy(img).to(device) img = img.half() if half else img.float() # uint8 to fp16/32 img /= 255.0 # 0 - 255 to 0.0 - 1.0 if img.ndimension() == 3: img = img.unsqueeze(0) # Inference t1 = time_synchronized() pred = model(img, augment=opt.augment)[0] # Apply NMS pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms) t2 = time_synchronized() # Apply Classifier if classify: pred = apply_classifier(pred, modelc, img, im0s) # Process detections for i, det in enumerate(pred): # detections per image if webcam: # batch_size >= 1 p, s, im0, frame = path[i], '%g: ' % i, im0s[i].copy(), dataset.count else: p, s, im0, frame = path, '', im0s, getattr(dataset, 'frame', 0) p = Path(p) # to Path save_path = str(save_dir / p.name) # img.jpg txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # img.txt s += '%gx%g ' % img.shape[2:] # print string gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh if len(det): # Rescale boxes from img_size to im0 size det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round() # Print results for c in det[:, -1].unique(): n = (det[:, -1] == c).sum() # detections per class s += f'{n} {names[int(c)]}s, ' # add to string # Write results for *xyxy, conf, cls in reversed(det): if save_txt: # Write to file xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh line = (cls, *xywh, conf) if opt.save_conf else (cls, *xywh) # label format with open(txt_path + '.txt', 'a') as f: f.write(('%g ' * len(line)).rstrip() % line + '\n') if save_img or view_img: # Add bbox to image label = f'{names[int(cls)]} {conf:.2f}' plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=3) # Print time (inference + NMS) print(f'{s}Done. ({t2 - t1:.3f}s)') # Stream results if view_img: cv2.imshow(str(p), im0) if cv2.waitKey(1) == ord('q'): # q to quit raise StopIteration # Save results (image with detections) if save_img: if dataset.mode == 'image': cv2.imwrite(save_path, im0) else: # 'video' if vid_path != save_path: # new video vid_path = save_path if isinstance(vid_writer, cv2.VideoWriter): vid_writer.release() # release previous video writer fourcc = 'mp4v' # output video codec fps = vid_cap.get(cv2.CAP_PROP_FPS) w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH)) h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*fourcc), fps, (w, h)) vid_writer.write(im0) if save_txt or save_img: s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else '' print(f"Results saved to {save_dir}{s}") print(f'Done. ({time.time() - t0:.3f}s)') if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument('--weights', nargs='+', type=str, default='./weights/yolov5s.pt', help='model.pt path(s)') parser.add_argument('--source', type=str, default='data/images', help='source') # file/folder, 0 for webcam parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)') parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold') parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS') parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu') parser.add_argument('--view-img', action='store_true', help='display results') parser.add_argument('--save-txt', action='store_true', help='save results to *.txt') parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels') parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3') parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS') parser.add_argument('--augment', action='store_true', help='augmented inference') parser.add_argument('--update', action='store_true', help='update all models') parser.add_argument('--project', default='runs/detect', help='save results to project/name') parser.add_argument('--name', default='exp', help='save results to project/name') parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment') opt = parser.parse_args() print(opt) with torch.no_grad(): if opt.update: # update all models (to fix SourceChangeWarning) for opt.weights in ['yolov5s.pt', 'yolov5m.pt', 'yolov5l.pt', 'yolov5x.pt']: detect() strip_optimizer(opt.weights) else: detect()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
多模态生物识别系统
社交媒体用户头像验证
虚拟现实/增强现实:
VR/AR环境中的手势识别
环境感知和实时场景理解
艺术与创意:
AI绘画创作(基于图像生成模型)
老照片修复与色彩化
遥感与地理信息系统:
土地覆盖分类
城市扩张监测
智能家居与物联网:
智能家居设备手势控制
基于视觉的物品抓取与放置机器人
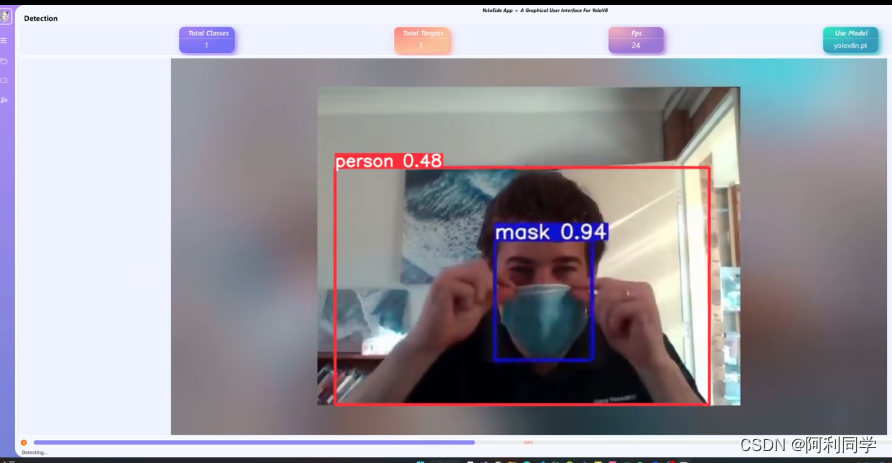
时尚与零售:
服装款式识别及推荐系统
商品图片自动标注与分类
游戏开发:
游戏角色动作识别与智能NPC设计
实时环境感知以增强沉浸式体验
无人机航拍图像分析:
林火监测与预警
农田病虫害面积评估
基因组学:
基因序列图像识别与分类

移动应用:
手机摄像头的菜品识别与营养成分估算
植物识别与智能园艺助手
最后:计算机视觉、图像处理、毕业辅导、作业帮助、代码获取,私聊会回复!↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
qq1309399183
- 1
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/很楠不爱3/article/detail/243589
推荐阅读
相关标签

