
- 1原生微信小程序全流程(基础知识+项目全流程)_微信小程序原生开发
- 2【转载】EEG中常用的功能连接指标汇总_eegx
- 3MyBatis全局配置属性_mybatis org.apache.ibatis.parsing.propertyparser.e
- 4在windows通过VS Code开发Linux内核驱动程序_vscode如何编译虚拟机的linux驱动
- 5LaTeX绘图GUI工具介绍_latex draw
- 6第一次机器学习经历_tensorflow how_many_training_steps
- 7史上最全的Unity面试题(含答案)_unity 面试题
- 8(二进制安装)k8s1.9 证书过期及开启自动续期方案.md_10250端口证书过期了怎么处理呢
- 9Android Canvas的使用_android canvas.drawcolor
- 10软考中级系统集成项目管理工程师自学好不好过,怎么备考,给点经验
为何GPU可以用于加速人工智能或者机器学习的计算速度(并行计算能力)_搜索算法等均可采用gpu加速计算
赞
踩
一、Why GPU
其实GPU计算比CPU并不是“效果好”,而是“速度快”。
计算就是计算,数学上都是一样的,1+1用什么算都是2,CPU算神经网络也是可以的,算出来的神经网络放到实际应用中效果也很好,只不过速度会很慢罢了。
GPU的起源
GPU全称叫做graphics processing unit,图形处理器,顾名思义就是处理图形的。
电脑显示器上显示的图像,在显示在显示器上之前,要经过一些列处理,这个过程有个专有的名词叫“渲染”。以前的计算机上没有GPU,渲染就是CPU负责的。渲染是个什么操作呢,其实就是做了一系列图形的计算,但这些计算往往非常耗时,占用了CPU的一大部分时间。而CPU还要处理计算机器许多其他任务。因此就专门针对图形处理的这些操作设计了一种处理器,也就是GPU。这样CPU就可以从繁重的图形计算中解脱出来。
由于GPU是专门为了渲染设计的,那么他也就只能做渲染的那些事情。
渲染这个过程具体来说就是几何点位置和颜色的计算,这两者的计算在数学上都是用四维向量和变换矩阵的乘法,因此GPU也就被设计为专门适合做类似运算的专用处理器了。为什么说专用呢,因为很多事情他做不了。
CPU通用性强,但是专用领域性能低。工程就是折衷,这项强了,别的就弱了。再后来游戏、3D设计对渲染的要求越来越高,GPU的性能越做越强。论纯理论计算性能,要比CPU高出几十上百倍。
人们就想了,既然GPU这么强,那用GPU做计算是不是相比CPU速度能大大提升呢?于是就有了GPGPU(general purpose GPU,通用计算GPU)这个概念。但我们前面提到了,GPU是专门为了图像渲染设计的,他只适用于那些操作。但幸运的是有些操作和GPU本职能做的那些东西非常像,那就可以通过GPU提高速度,比如深度学习。
深度学习中一类成功应用的技术叫做卷积神经网络CNN,这种网络数学上就是许多卷积运算和矩阵运算的组合,而卷积运算通过一定的数学手段也可以通过矩阵运算完成。这些操作和GPU本来能做的那些图形点的矩阵运算是一样的。因此深度学习就可以非常恰当地用GPU进行加速了。
以前GPGPU(通用GPU)概念不是很火热,GPU设计出来就是为了图形渲染。想要利用GPU辅助计算,就要完全遵循GPU的硬件架构。而现在GPGPU越来越流行,厂家在设计和生产GPU的时候也会照顾到计算领域的需求了。比如今年英伟达发布M40和P100的时候,都在说”针对深度学习设计“,当然其实这里面炒概念的成分更大了,但至少可以看出厂家越来越多地看重通用GUGPU计算了。
二、GPGPU与GPU的区别
GPU的产生是为了解决图形渲染效率的问题,但随着技术进步,GPU越来越强大,尤其是shader出现之后(这个允许我们在GPU上编程),GPU能做的事越来越多,不再局限于图形领域,也就有人动手将其能力扩展到其他计算密集的领域,这就是GP(General Purpose)GPU。
三、为什么快
比如说你用美图xx软件,给一张图片加上模糊效果的时候,CPU会这么做:
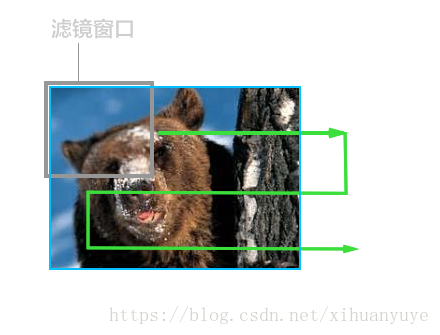
使用一个模糊滤镜算子的小窗口,从图片的左上角开始处理,并从左往右,再从左往右进行游走处理,直到整个图片被处理完成。因为CPU只有一个或者少数几个核,所以执行这种运算的时候,只能老老实实从头遍历到最后。
但是有一些聪明的读者会发现,每个窗口在处理图片的过程中,都是独立的,相互没有关系的。那么同时用几个滤镜窗口来处理是不是更快一些? 于是我们有了GPU, 一般的GPU都有几百个核心,意味着,我们可以同时有好几百个滤镜窗口来处理这张图片。
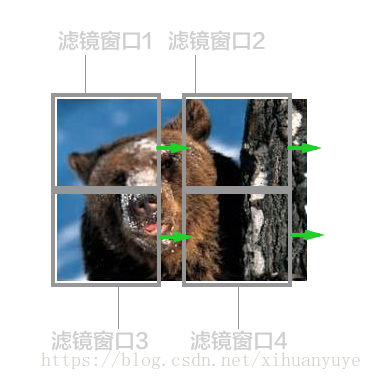
所以说,GPU起初的设计目标就是为了处理这种图形图像的渲染工作,而这种工作的特性就是可以分布式、每个处理单元之间较为独立,没有太多的关联。而一部分机器学习算法,比如遗传算法,神经网络等,也具有这种分布式及局部独立的特性(e.g.比如说一条神经网络中的链路跟另一条链路之间是同时进行计算,而且相互之间没有依赖的),这种情况下可以采用大量小核心同时运算的方式来加快运算速度。


