
- 1数码管的静态显示(二)
- 2java的lambda表达式_java lambda中可以抛出异常吗
- 3#HarmonyOS:UIAbility组件生命周期--UIAbility组件启动模式_uiability的生命周期有哪几个状态?
- 4模板方法模式_模版方法模式利用方法hook实现反向控制结构
- 5GitHub标星1w+超牛的微服务项目,开发脚手架_身份认证中台 github
- 6基于单片机的自动售货机系统设计
- 7基于Android平台的记事本软件(Android Studio项目+报告+app文件)_基于移动应用系统开发技术的记事本app的致谢
- 8树状数组的应用_树状数组求左侧小于该元素的元素个数
- 9redis防止表单重复提交
- 10Python读写Excel数据(指定某行某列)_python读取excel指定行列
UNeXt:基于 MLP 的快速医学图像分割网络_unext csdn
赞
踩
UNeXt是约翰霍普金斯大学在2022年发布的论文。它在早期阶段使用卷积,在潜在空间阶段使用 MLP。通过一个标记化的 MLP 块来标记和投影卷积特征,并使用 MLP 对表示进行建模。对输入通道进行移位,可以专注于学习局部依赖性。
UNeXt
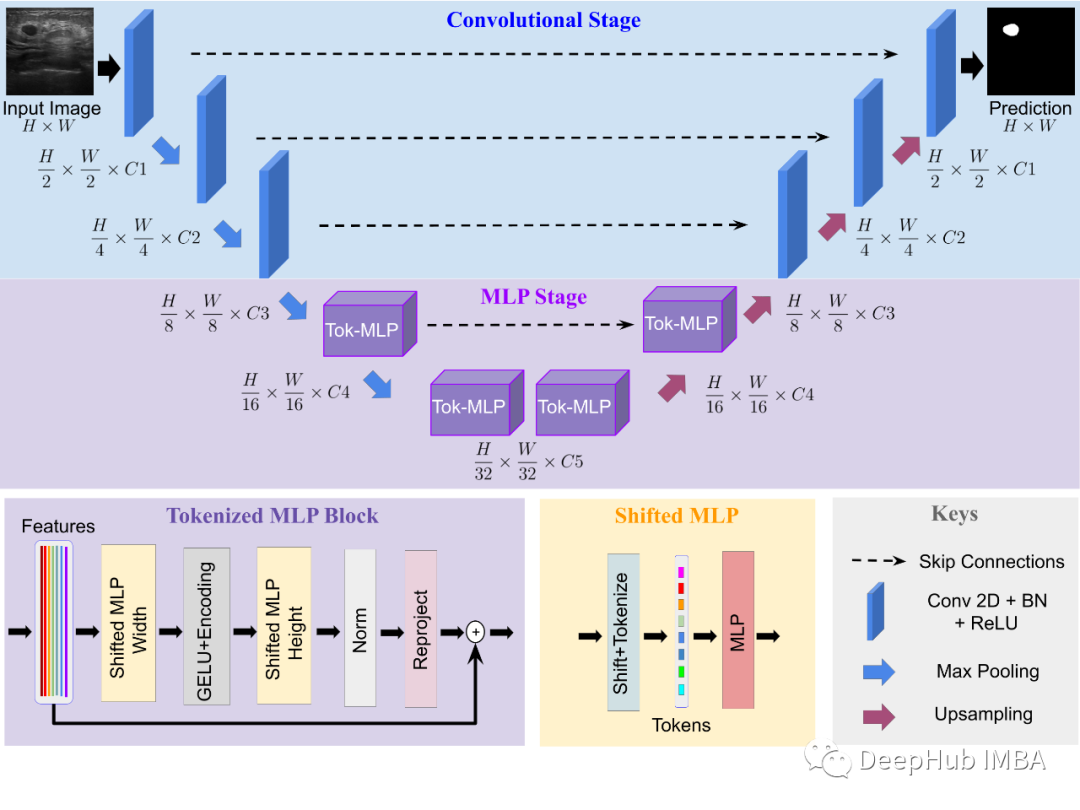
基本架构
UNeXt 是一种编码器-解码器架构,具有两个阶段:
1、卷积阶段,2、标记化 MLP 阶段。
输入图像通过编码器,前 3 个块是卷积块,接下来的 2 个是标记化 MLP 块。
解码器有 2 个标记化 MLP 块,后跟 3 个卷积块。
每个编码器块使用具有窗口 2×2 的最大池化层将特征分辨率降低 2,每个解码器块使用双线性插值将特征分辨率增加 2。编码器和解码器之间也包含跳过连接。每个块的通道数是一个超参数,表示为 C1 到 C5。在实验中,除非另有说明,否则 C1=32、C2=64、C3=128、C4=160 和 C5=256。
每个卷积块时标准的一个卷积层、一个批量归一化层和 ReLU 激活层。内核大小为 3×3,步长为 1。
带位移的 MLP

conv特征的通道轴线在标记(Tokenized)之前首先移位。这有助于MLP只关注conv特征的某些位置,从而诱导块的局部性。论文作者说,这里与Swin Transformer类似。由于Tokenized MLP块有2个MLP,因此特征在一个块中跨宽度移动,在另一个块中跨高度移动,就像Axial-DeepLab中的轴向注意力一样。这样特征被分割到h个不同的分区,并根据指定的轴移动j=5个位置。
标记化(Tokenized) MLP阶段
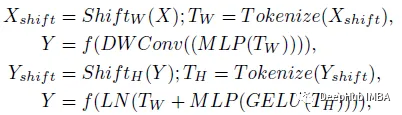
首先使用大小为 3 的内核将通道数更改为嵌入维度 E(标记数)。然后将这些标记令牌传递给一个带移位的MLP(跨宽度),其中包含MLP的隐藏维度,默认H=768。
接下来,使用深度卷积层(DWConv)。它有助于对位置信息进行编码,像SegFormer中所建议的,当训练/测试分辨率不同时,它比ViT具有更好的性能。并且它使用更少的参数,可以提高了效率。
激活函数使用GELU,因为在ViT和BERT在使用GELU的情况下表现更好。
特征通过另一个移位的MLP(跨高度)传递,该MLP将维度从H转换为O。
最后还是用了残差连接将原始标记令牌添加到残差。然后使用层归一化(LN),将输出特征传递给下一个块。
损失函数
使用二元交叉熵(BCE)和dice 损失的组合:
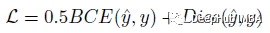
结果展示
SOTA对比
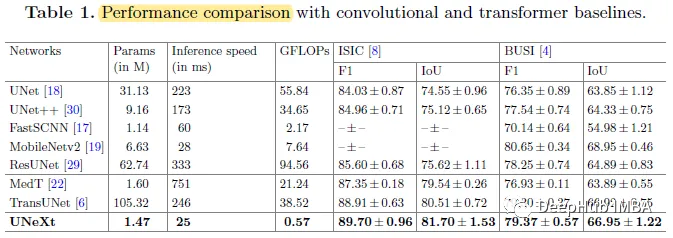
UNeXt获得了比所有基线更好的分割性能,计算量比第二的TransUNet少得多。UNeXt在计算复杂度方面明显优于所有其他网络。
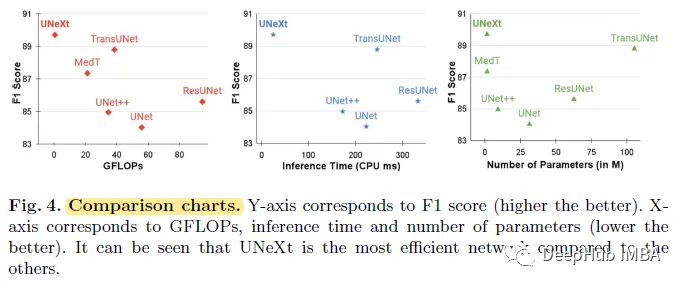
swing - unet(图中未显示)有41.35 M个参数,计算也很复杂有11.46 GFLOPs。
作者还实验了MLP-Mixer作为编码器和普通卷积解码器,它只有大约11M个参数,但是分割的性能不是最优的。
定性结果

与其他方法相比,UNeXt产生了具有竞争力的分割预测。
消融实验
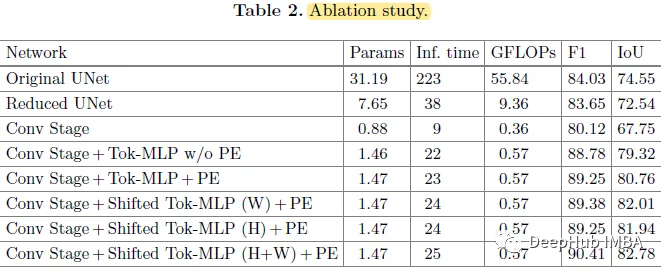
当深度减小,仅使用3级架构,也就是说只使用Conv阶段时,参数数量和复杂度显著减少,但性能下降4%。当使用标记化的MLP块时,它可以显着提高性能。
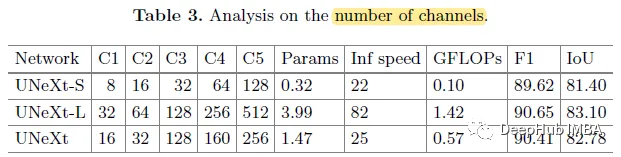
增加通道(UNeXt-L)进一步提高了性能,同时增加了计算开销。减少通道(UNeXt-S)会降低性能(降低幅度并不大),但我们得到了一个非常轻量级的模型。
论文:
https://avoid.overfit.cn/post/addeb0eacf624e4b92e0c9775c40fb0a
本文作者:Sik-Ho Tsang

