- 1Mybatis查询数据返回多条_mybatis查询前10条数据
- 2鸿蒙ArsTS项目创建打包发布流程_鸿蒙打包教程
- 3CVPR‘2023 | Cross-modal Adaptation: 基于 CLIP 的微调新范式_clip做微调
- 4内存溢出的多种原因及优化方法_改善内存溢出导致系统频繁宕机的问题
- 5安科瑞智慧安全用电云平台【无人化数据监控 远程控制 运维管理】
- 6Android/iOS APP备案:遇到的问题汇总指南!
- 7[Qt 教程之Widgets模块] —— QDialogButtonBox按钮框
- 8开发者进阶宝典,HarmonyOS 职业认证全奉上
- 9通过sql获取数据库表设计信息_sql 获取设计页面注释
- 10使用DrawerLayout,FragmentTabHost实现测滑式底部菜单栏界面_drawerlayout 底部滑动
一文详解什么是可解释AI_rise神经网络可解释性
赞
踩
摘要:本文带来什么是可解释AI,如何使用可解释AI能力来更好理解图片分类模型的预测结果,获取作为分类预测依据的关键特征区域,从而判断得到分类结果的合理性和正确性,加速模型调优。
1. 为什么需要可解释AI?
在人类历史上,技术进步、生产关系逻辑、伦理法规的发展是动态演进的。当一种新的技术在实验室获得突破后,其引发的价值产生方式的变化会依次对商品形态、生产关系等带来冲击,而同时当新技术带来的价值提升得到认可后,商业逻辑的组织形态在自发的调整过程中,也会对技术发展的路径、内容甚至速度提出诉求,并当诉求得到满足时适配以新型的伦理法规。在这样的相互作用中,技术系统与社会体系会共振完成演进,是谓技术革命。
近10年来,籍由算力与数据规模的性价比突破临界点,以深度神经网络为代表的联结主义模型架构及统计学习范式(以后简称深度学习)在特征表征能力上取得了跨越级别的突破,大大推动了人工智能的发展,在很多场景中达到令人难以置信的效果。比如:人脸识别准确率达到97%以上;谷歌智能语音助手回答正确率,在2019年的测试中达到92.9%。在这些典型场景下,深度学习在智能表现上的性能已经超过了普通人类(甚至专家),从而到了撬动技术更替的临界点。在过去几年间,在某些商业逻辑对技术友好或者伦理法规暂时稀缺的领域,如安防、实时调度、流程优化、竞技博弈、信息流分发等,人工智能(暨深度学习)取得了技术和商业上快速突破。
食髓知味,技术发展的甜头自然每个领域都不愿放过。而当对深度学习商业化运用来到某些对技术敏感、与人的生存或安全关系紧密的领域,如自动驾驶、金融、医疗和司法等高风险应用场景时,原有的商业逻辑在进行技术更替的过程中就会遇到阻力,从而导致商业化(及变现)速度的减缓甚至失败。究其原因,以上场景的商业逻辑及背后伦理法规的中枢之一是稳定的、可追踪的责任明晰与分发;而深度学习得到的模型是个黑盒,无法从模型的结构或权重中获取模型行为的任何信息,从而使这些场景下责任追踪和分发的中枢无法复用,导致人工智能在业务应用中遇到技术和结构上的困难。
举2个具体的例子:
- 在金融风控场景,通过深度学习模型识别出来小部分用户有欺诈嫌疑,但是业务部门不敢直接使用这个结果进行处理,因为难以理解结果是如何得到的,从而无法判断结果是否准确,担心处理错误;而且缺乏明确的依据,如果处理了,也无法向监管机构交代;
- 例2,在医疗领域,深度学习模型根据患者的检测数据,判断患者有肺结核,但是医生不知道诊断结果是怎么来的,不敢直接采用,而是根据自己的经验,仔细查看相关检测数据,然后给出自己的判断。从这2个例子可以看出,黑盒模型严重影响模型在实际场景的应用和推广。
要解决模型的这些问题,就需要打开黑盒模型,透明化模型构建过程和推理机理。那么可解释AI是实现模型透明化的有效技术。
2. 什么是可解释AI?
可解释AI (eXplainable AI(XAI)),不论是学术界还是工业界都没有一个统一的定义。这里列举3种典型定义,供大家参考讨论:
①可解释性就是希望寻求对模型工作机理的直接理解,打破人工智能的黑盒子。
②可解释AI是为AI算法所做出的决策提供人类可读的以及可理解的解释。
③可解释的AI是确保人类可以轻松理解和信任人工智能代理做出的决策的一组方法。
可见,关注点在于对模型的理解,黑盒模型白盒化以及模型的可信任。
MindSpore团队根据自身的实践经验和理解,将可解释AI定义为:一套面向机器学习(主要是深度神经网络)的技术合集,包括可视化、数据挖掘、逻辑推理、知识图谱等,目的是通过此技术合集,使深度神经网络呈现一定的可理解性,以满足相关使用者对模型及应用服务产生的信息诉求(如因果或背景信息),从而为使用者对人工智能服务建立认知层面的信任。
3. 可解释AI解决什么问题?
按DARPA(美国国防部先进研究项目局)的说法,可解释AI的目的,就是要解决用户面对模型黑盒遇到问题,从而实现:
①用户知道AI系统为什么这样做,也知道AI系统为什么不这样做。
②用户知道AI系统什么时候可以成功,也知道AI系统什么时候失败。
③用户知道什么时候可以信任AI系统。
④用户知道AI系统为什么做错了。
MindSpore实现的可解释AI计划主要解决如下两类问题:
①解决深度学习机制下技术细节不透明的问题,使得开发者可以通过XAI工具对开发流程中的细节信息进行获取,并通过获取到的可理解信息,帮助开发者进行模型故障排除或性能提升;
②提供深度学习技术与服务对象的友好的认知接口(cognitive-friendly interface),通过该接口,基于深度学习的服务提供者可以有合适工具对深度学习服务进行商业化逻辑的操作,基于深度学习的人工智能服务的消费者可以获得必要的释疑并建立信任,也可以为AI系统的审核提供能力支持。
4. 实现可解释AI的方法
从前面的介绍,大家可以感觉到可解释AI很高大上,那么具体如何实现呢?结合业界的研究成果,我们认为实现可解释AI主要有3类方法:
第一类是基于数据的可解释性,通常称为深度模型解释,是最容易想到的一种方法,也是很多论文里面经常涉及的一类技术;主要是基于数据分析和可视化技术,实现深度模型可视化,直观展示得到模型结果的关键依据。
第二类是基于模型的可解释性,这类方法也称为可解释模型方法,主要是通过构建可解释的模型,使得模型本身具有可解释性,在输出结果的同时也输出得到该结果的原因。
第三类是基于结果的可解释性,此类方法又称为模型归纳方法,思路是将已有模型作为一个黑盒,根据给定的一批输入和对应的输出,结合观察到模型的行为,推断出产生相应的结果的原因,这类方法的好处是完全与模型无关,什么模型都可以用。
5. MindSpore1.1版本的可解释AI能力
MindSpore1.1开源版本,在MindInsight部件中集成了的可解释AI能力:显著图可视化(Saliency Map Visualization),也称为关键特征区域可视化。这部分归属于第一类基于数据的可解释性方法,后续我们将陆续开源更多的解释方法,除了第一类,还将包括第二类基于模型的可解释方法和第三类基于结果的可解释方法。
当前显著图可视化主要是CV领域的模型解释,在1.1版本中,我们支持6种显著图可视化解释方法:Gradient、Deconvolution、GuidedBackprop、GradCAM、RISE、Occlusion。
其中:Gradient、Deconvolution,、GuidedBackprop和GradCAM等4种方法属于基于梯度的解释方法。这种类型的解释方法,主要利用模型的梯度计算,来突显关键特征,效率比较高,下面简要介绍下这4种方法:
- Gradient,是最简单直接的解释方法,通过计算输出对输入的梯度,得到输入对最终输出的“贡献”值;而Deconvolution和GuidedBackprop是对Gradient的延展和优化;
- Deconvolution,对原网络中ReLU进行了修改使其成为梯度的ReLU,从而过滤负向梯度,仅关注对输出起到正向贡献的特征;
- GuidedBackprop,是在原网络ReLU基础上对负梯度过滤,仅关注对输出起到正向贡献的且激活了的特征,能够减少显著图噪音;
- GradCAM,针对中间激活层计算类别权重,生成对类别敏感的显著图,可以得到类别相关的解释。
另外2种方法:Occlusion和RISE,则属于基于扰动的解释方法,该类型方法的好处是,仅需利用模型的输入和输出,可以做到模型无关,具体说明下:
- RISE,使用蒙特卡洛方法,对随机掩码进行加权(权重为遮掩后的模型的输出)平均得到最终显著图;
- Occlusion,通过遮掩特定位置的输入,计算模型输出的改变量来得到该位置的“贡献”,遍历全部输入,得到显著图。
那么对于具体场景,该如何选择合适的解释方法来解释对应的模型呢?
为了满足这个诉求,MindSpore1.1版本提供了可解释AI的度量框架,同时还提供了4种度量方法:Faithfulness、Localization、Class sensitivity、Robustness,针对不同解释方法的解释效果进行度量,帮助开发者或用户选择最合适的解释方法。简单描述下这4种度量方法:
- Faithfulness,可信度。按照重要度从大到小移除特征,并记录特定标签概率的减少量。遍历所有特征之后,比较置信度减少量的分布和特征重要性的分布相似性。与黑盒模型越契合的解释,两个分布情况应当越相似,该解释方法具有更好的可信度。
- Localization,定位性。基于显著图的解释具有目标定位的能力(即给定感兴趣的标签,显著图高亮图片中与标签相关的部分),localization借助目标检测数据集,对于同一图片同一个标签,通过显著图高亮部分和Ground Truth的重合度,来度量显著图的定位能力。
- Class sensitivity,分类敏感度,不同分类对应的图中的对象的显著图高亮部分应该明显不同。将概率最大和最小标签的显著图进行比较,如果两个标签的显著图差异越大,解释方法的分类敏感度越好。
- Robustness,健壮性。该指标反映解释方法在局部范围的抗扰动能力,Lipschitz值越小,解释收扰动影响越小,健壮性越强。
下面结合MindSpore1.1版本中已支持的显著图可视方法的其中3种解释方法:Gradient 、GradCAM和RISE,介绍如何使用可解释AI能力来更好理解图片分类模型的预测结果,获取作为分类预测依据的关键特征区域,从而判断得到分类结果的合理性和正确性,加速模型调优。
6、常见显著图可视解释方法介绍
6.1 Gradient解释方法
Gradient,是最简单直接的基于梯度的解释方法,通过计算输出对输入的梯度,得到输入对最终输出的“贡献”值,用于解释预测结果的关键特征依据。
对深度神经网络,这个梯度计算可通过后向传播算法获得,如下图所示:
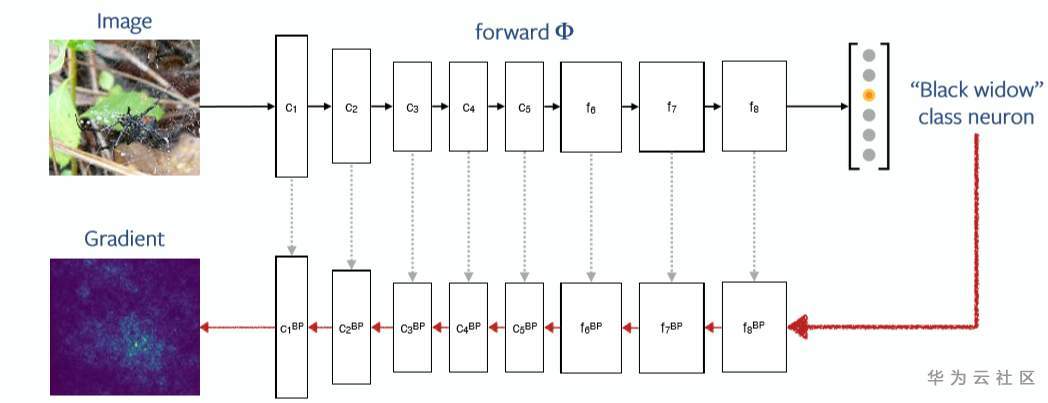
Source:Understanding models via visualizations and attribution
注:Gradient解释方法会遇到梯度饱和问题,即某个特征的贡献一旦达到饱和后,由于该特征不再对结果的变化产生影响,会导致该特征的梯度为0而出错。
Gradient解释效果如下图所示:
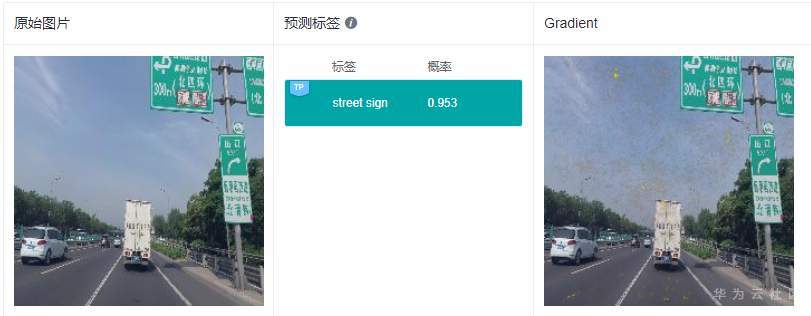
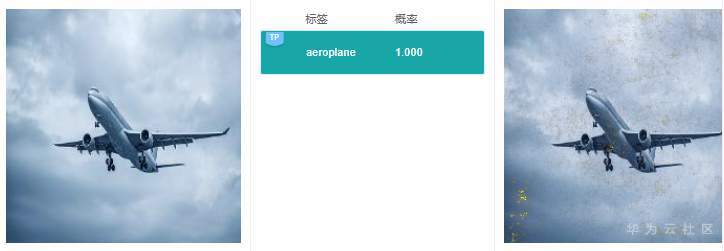
注:所有解释效果图片均来源于MindInsight截图
从上面2张图中可以看出,Gradient的解释结果可理解性较差,显著图高亮区域成散点状,没有清晰明确的特征区域定位,很难从中获取到预测结果的具体特征依据。
6.2 GradCAM解释方法
GradCAM,是Gradient-weighted Class Activation Mapping的简写,一般翻译为:加权梯度的类激活映射,是一种基于梯度的解释方法;该解释方法通过对某一层网络各通道激活图进行加权(权重由梯度计算得到),得到影响预测分类结果的关键特征区域。
GradCAM解释结果过程的概览,如下图:
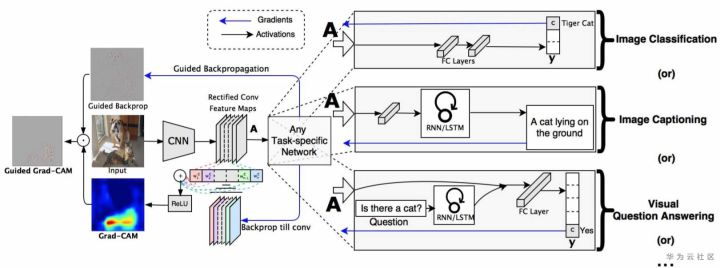
Source:Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
这里给出2个实际的例子,来看看GradCAM具体的解释效果:
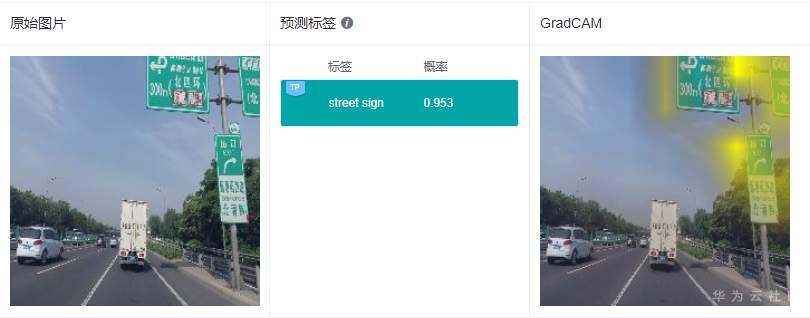
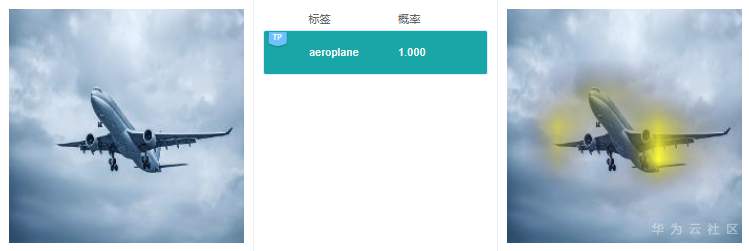
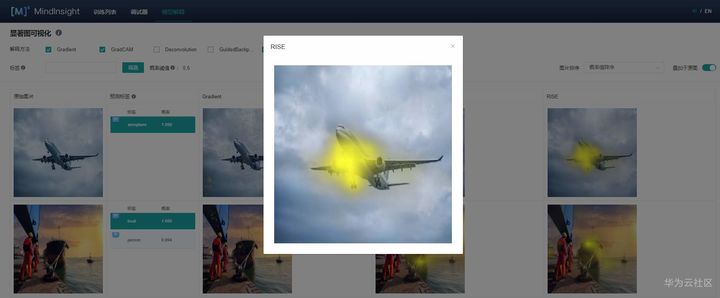
可以看到GradCAM的解释结果定位性和可理解性比较好,高亮区域集中在具体的特征上,用户可以通过高亮区域判断出和预测结果相关的特征。对于标签“路牌”,图像中的路牌被高亮,对于标签“飞机”,图像中的飞机被高亮,即GradCAM认为路牌区域和飞机区域是2个分类结果的主要依据。
6.3 RISE解释方法
RISE,是Randomized Input Sampling for Explanation的简写,即基于随机输入采样的解释,是一种基于扰动的解释,与模型无关;主要原理:使用蒙特卡洛采样产生多个掩码,然后对随机掩码进行加权(权重为遮掩后的模型的输出)平均得到最终显著图。
RISE方法解释过程的概览图,如下:
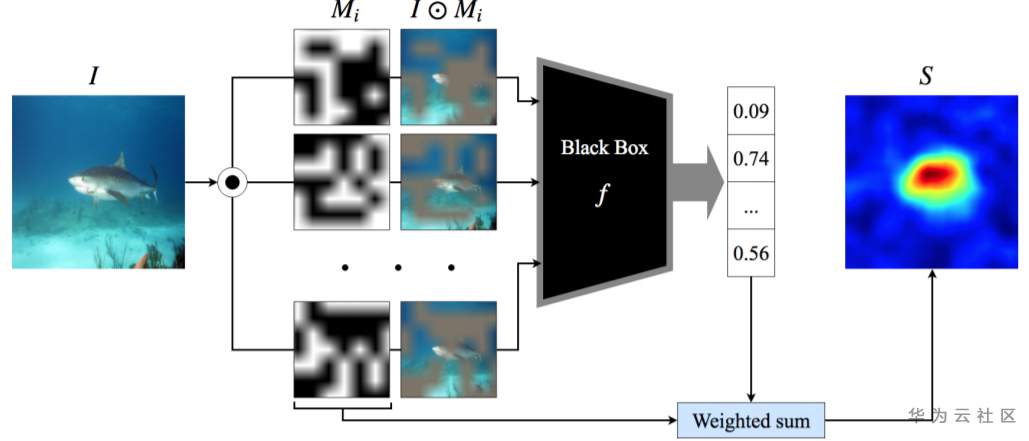
Source:RISE: Randomized Input Sampling for Explanation of Black-box Models
同样给出2个示例,展示下解释效果:
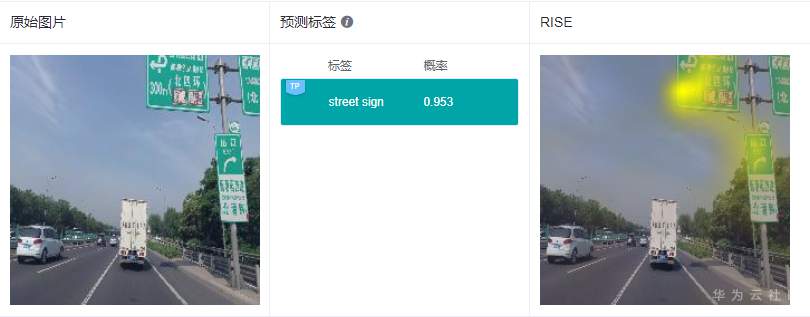
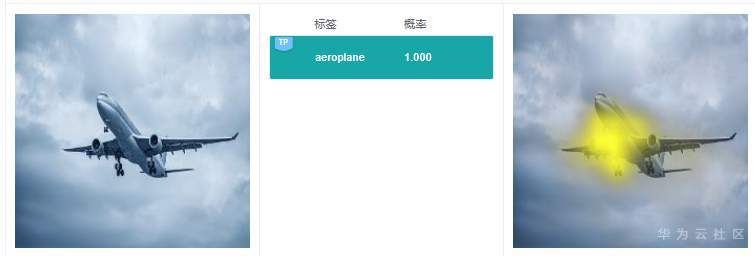
RISE采用遮掩的方法得到与分类结果相关的特征区域,解释结果的可理解性和定位性不错,和GradCAM类似,RISE准确地高亮了路牌区域和飞机区域。
7、MindSpore解释方法如何解释图片分类模型?
在实际应用中,上面介绍的3种解释方法的解释效果如何呢?根据预测结果和解释的有效性,我们将解释结果分为3类,并分别找几个典型的例子来看看实际的效果。
说明:下面所有示例图中的解释结果,都是MindSpore的MindInsight部件中的模型解释特性展现出来的。
7.1 预测结果正确,依据的关键特征合理的例子
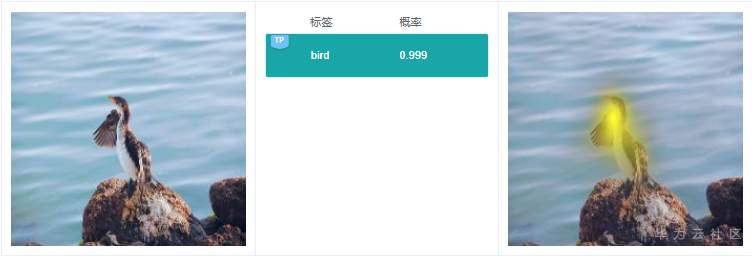
例7.1.1:上图预测标签是“bird”,右边给出依据的关键特征在鸟身上,说明这个分类判断依据是合理的。
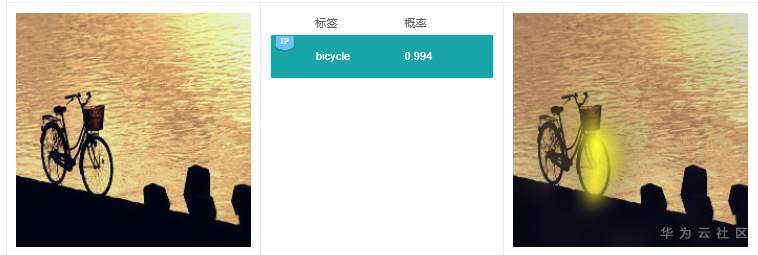
例7.1.2:上图预测标签是“bicycle”,右边解释的时候,将自行车车轮高亮,这个关键特征同样较为合理。
7.2 预测结果正确,但给出的关键特征依据可能是错误的例子
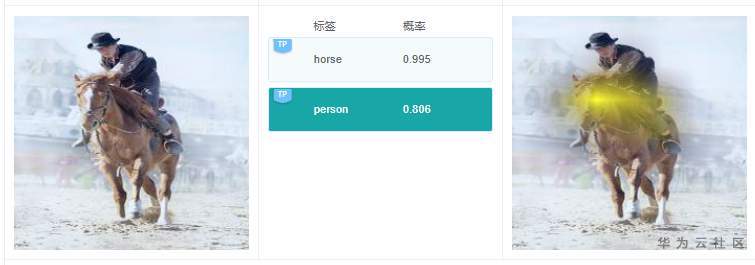
例7.2.1:原图中,有人,在预测标签中有1个标签是“person”,这个结果是对的;但是选择“person”标签,在查看右边解释的时候,可以看到高亮区域在马头上,那么这个关键特征依据很可能是错误的。
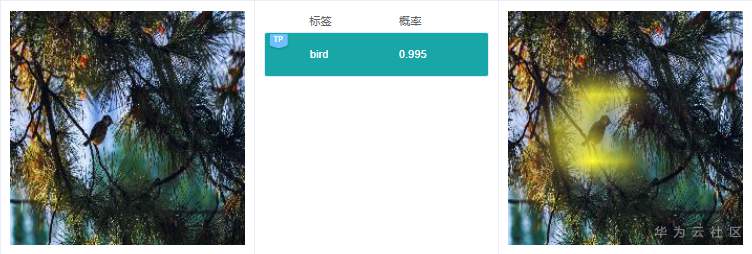
例7.2.2:原图中,有一只鸟,预测结果“bird”是对的,但是右边解释的时候,高亮区域在树枝和树叶上,而不是鸟的身上,这个依据也很可能是错的。
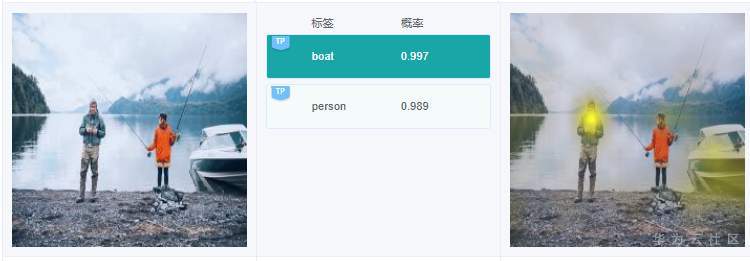
例7.2.3:上图中,有1艘小艇,有个标签是“boat”,这个没错。不过在右边针对标签“boat”的解释,高亮区域却在人身上,这个偏差有点大。
仔细分析上面的3个例子,这种高亮标识出来作为分类依据的关键特征,出现错误的情况,一般出现在图像中存在多目标的场景中。根据调优经验,往往是因为在训练过程中,这些特征经常与目标对象共同出现,导致模型在学习过程中,错误将这些特征识别为关键特征。
7.3 预测结果错误,结合依据的关键特征分析错因的例子
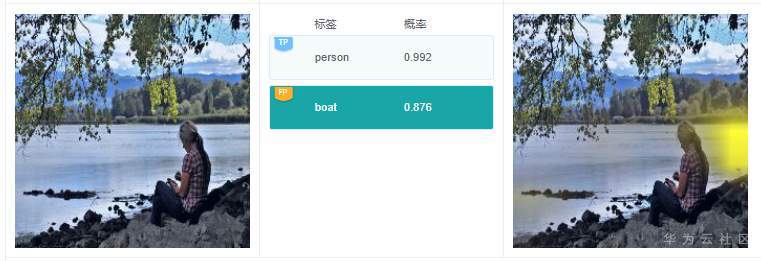
例7.3.1:在上图中,有个预测标签为“boat”,但是原始图像中并没有船只存在,通过图中右侧关于标签“boat”的解释结果可以看到模型将水面作为分类的关键依据,得到预测结果“boat”,这个依据是错误的。通过对训练数据集中标签为“boat”的数据子集进行分析,发现绝大部分标签为“boat”的图片中,都有水面,这很可能导致模型训练的时候,误将水面作为“boat”类型的关键依据。基于此,按比例补充有船没有水面的图片集,从而大幅消减模型学习的时候误判关键特征的概率。
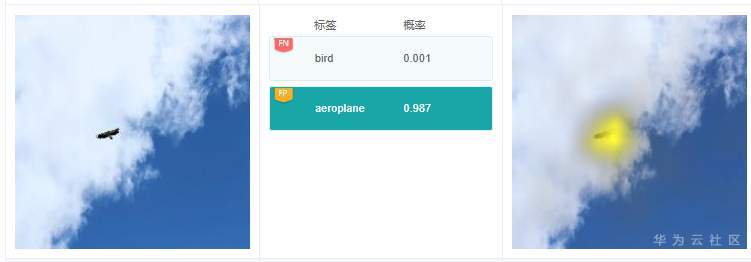
例7.3.2:图中有一个分类预测结果是“aeroplane”,但图中并没有飞机。从标签“aeroplane”的解释结果看,高亮区域在鹰的身上。打开飞机相关的训练数据子集,发现很多情况下训练图片中飞机都是远处目标,与老鹰展翅滑翔很像,猜测可能是这种原因导致模型推理的时候,误将老鹰当做飞机了。模型优化的时候,可以考虑增加老鹰滑翔的图片比例,提升模型的区分和辨别能力,提高分类准确率。
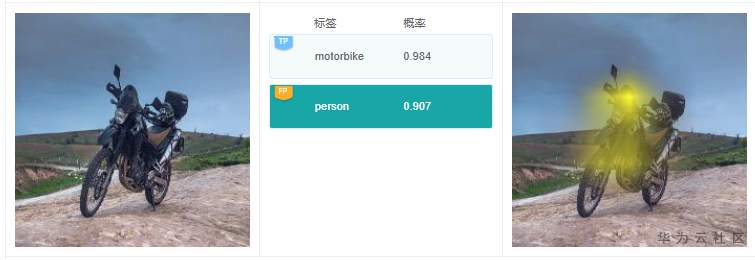
例7.3.3:这个例子中,有个预测标签是“person”,仔细看图中没有人。根据标签“person”的解释结果,高亮区域在摩托车的前部;在原图中,乍一看,还真像一个人趴着;猜测是分类模型推理的时候,误将这部分当做人了。
8、如何部署和使用MindSpore解释方法?
在MindSpore官网的模型解释教程中,详细介绍了如何部署和使用MindSpore提供的解释方法,链接请见:
https://www.mindspore.cn/tutorial/training/zh-CN/r1.1/advanced_use/model_explaination.html
下面,对部署和使用方法,做简要介绍:
先使用脚本调用MindSpore 提供的python API进行解释结果的生成和收集,然后启动MindInsight对这些结果进行展示,整体流程如下图:

具体步骤如下:
8.1 准备脚本
通过调用解释方法Python API对模型预测结果进行解释,已提供的解释方法可以在mindspore.explainer.explanation包中获取。用户准备好待解释的黑盒模型和数据,在脚本中根据需要实例化解释方法,调用API用于收集解释结果。
MindSpore还提供mindspore.explainer.ImageClassificationRunner接口,支持自动化运行所有解释方法。用户事先将实例化的解释方法进行注册,即可在该接口调用后自动运行解释方法,生成及保存包含解释结果的解释日志。
下面以ResNet50为例,介绍如何初始化explanation中解释方法,调用ImageClassificationRunner进行解释。其样例代码如下:
- ```
- import mindspore.nn as nn
- from mindspore.explainer.explanation import GradCAM, GuidedBackprop
- from mindspore.explainer import ImageClassificationRunner
-
- from user_defined import load_resnet50, get_dataset, get_class_names
-
-
- # load user defined classification network and data
- network = load_resnet50()
- dataset = get_dataset()
- classes = get_class_names()
- data = (dataset, classes)
-
- runner = ImageClassificationRunner(summary_dir='./summary_dir', network=network, activation_fn=nn.Sigmoid(), data=data)
-
- # register explainers
- explainers = [GradCAM(network, layer='layer4'), GuidedBackprop(network)]
- runner.register_saliency(explainers)
-
- # run and generate summary
- runner.run()
- ```
8.2 使用MindInsight进行结果展示
8.2.1 启动MindInsight
启动MindInsight系统,在顶部选择进入“模型解释”模块。可以看到所有的解释日志路径,当日志满足条件时,操作列会有“显著图可视化”的功能入口。
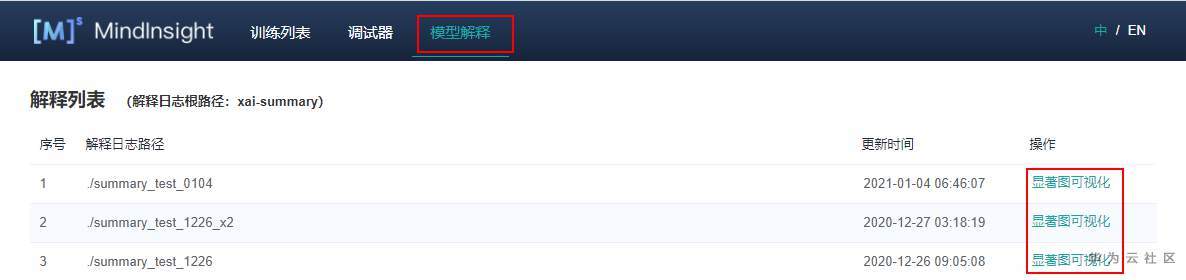
8.2.2 各项功能介绍
显著图可视化用于展示对模型预测结果影响最为显著的图片区域,通常高亮部分可视为图片被标记为目标分类的关键特征。
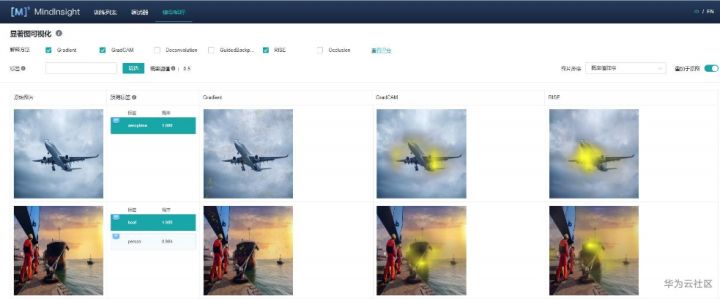
进入显著图可视化界面,如上图,会展现:
- 用户通过Dataset的Python API接口设置的目标数据集。
- 真实标签、预测标签,以及模型对对应标签的预测概率。根据具体情况,系统会在对应标签的左上角增加TP, FP,FN(含义见界面提示信息)的旗标。
- 选中的解释方法给出的显著图。
界面操作介绍:
1.通过界面上方的解释方法勾选需要的解释方法;
2.通过切换界面右上方的“叠加于原图”按钮,可以选择让显著图叠加于原图上显示;
3.点击不同标签,显示对不同标签的显著图分析结果,对于不同的分类结果,通常依据的关键特征区域也是不同的;
4.通过界面上方的标签筛选功能,筛选出指定标签图片;
5.通过界面右上角的图片排序改变图片显示的顺序;
6.点击图片可查看放大图。