
- 1C#中wpf调试时关于imagesource路径报错问题
- 2VideoCrafter - 文本生成视频
- 3Android将View转换为图片_android 将view转成图片
- 4掌握大模型这些优化技术,优雅地进行大模型的训练和推理!_大模型的训练和推理,有多机并行,推理加速的经验
- 5微信小程序入门04-后端脚手架搭建_微信小程序脚手架
- 6opencv 实现图片亮度增强和图片美白_ffmpeg opencv 美白
- 7DevEco Studio 代码自动跳转(HarmonyOS鸿蒙开发基础知识)_deveco无法跳转代码
- 8where 1=1的作用
- 9浏览器域名解析步骤_chrome浏览器解析域名的次序
- 10IDEA中启动Tomcat后不会自动跳转浏览器页面_idea运行之后不弹出浏览器
2024年AI行业专题报告:AI巨轮滚滚向前_人工智能最新进展成果
赞
踩
2024年AI行业专题报告:AI巨轮滚滚向前。

1 Sora、Gemini 1.5 Pro 相继发布,AIGC 新时代已至
1.1 大模型 Sora 震撼登场,AI 生成视频领域里程碑
OpenAI 在 2024 年 2 月 16 日发布文生视频模型 Sora,突破了 AIGC 的高地,该模 型完美继承 DALL·E 3 的画质和遵循指令能力,并利用了 GPT 扩写,具备超长生 成时间(60s,Pika 1.0 为 3s)、单视频多角度镜头、理解物理世界三大突出优 势。除文生视频外,该模型还能支持通过现有的静态图像生成视频,并能准确、 细致地对图像内容进行动画处理;提取现有视频,对其进行扩展或填充缺失的帧。 优势 1#超长生成时间。Sora 支持 60s 视频生成,一镜到底,不仅主人物稳定, 背景中的人物表现也十分稳定,可实现从大中景无缝切换到脸部特写。相比之下, Pika 1.0 的视频生成时间为 3s(可通过 Add 4s 功能增加 4s),Sora 支持时长远 超目前市场上已有的文生视频模型。
优势 2#单视频多角度镜头。Sora 生成的视频中,在有多角度镜头的情况下仍然 能保证一致性,即使主体暂时离开视野也可保持不变。OpenAI 展示了如下提示词 的生成的视频:一个美丽的剪影动画展示了一只狼对着月亮嚎叫,感到孤独,直 到它找到狼群,该视频实现了多镜头无缝切换且保持了主体的一致。
优势 3#理解物理世界。目前 Sora 已经能生成具有多个角色、包含特定运动的复 杂场景,不仅能理解用户在提示中提出的要求,还了解这些物体在物理世界中的 存在方式。我们看到 Sora 生成的视频与世界互动,例如,画家可以在画布上留 下新的笔触,并随着时间的推移而持续存在,一个人可以吃汉堡并留下咬痕。在 汽车在山路上行驶的视频中,其汽车的阴影、树影等随镜头变化带来的光影变换 也符合物理世界。我们认为 Sora 已具备理解物理世界的能力。
Sora 不仅能通过文字来生成视频,还支持图片生成视频、扩展生成的视频、视频 编辑以及视频连接。1)图片生成视频:Sora 能够生成提供图像和提示作为输入 的视频;2)扩展生成的视频:Sora 还能够在时间上向前或向后扩展视频,虽然 视频的结局都是相同的,但起始视频并不相同;3)视频编辑:扩散模型启用了多 种根据文本提示编辑图像和视频的方法,使 Sora 能够零镜头地改变输入视频的 风格和环境;4)视频连接:Sora 可以在两个输入视频之间逐帧进行插值,从而 在具有完全不同主题和场景构成的视频之间创建无缝过渡。
我们认为 Sora 震撼效果的原因主要有:1)训练端:基于 Transformer 架构的扩 散模型,降维并通过 Patche 进行训练;采样的灵活性与独特的训练路径(原始 尺寸、时长训练);利用 DALL·E 3 re-captioning 功能,给训练用的视频素材 都加上高质量文本描述;2)输入端:利用 GPT 先将用户输入的提示词精准详尽 扩写,再将扩写后的提示词交给 Sora。 基于 Transformer 架构的扩散模型,降维并通过 Patche 进行训练。Sora 是一种 扩散模型,可在学习大量先作的时候,学会图像内涵与图像之间的关系,采用 Transformer 架构(主流视频生成扩散模型较多采用 U-Net 架构),OpenAI 认为 之前在大语言模型上的成功得益于 Token,Token 可以把代码、数学以及各种不 同的自然语言进行统一,进而方便规模巨大的训练,因此 OpenAI 创造了对应 Token 的 Patche,用于训练 Sora。为减少 Transformer 带来的计算量压力,OpenAI 开发了一个视频压缩网络,把视频先降维到潜空间(latent,用更少的信息去表 达信息的本质),然后再去拿这些压缩过的视频数据去生成 Patche,这样就能使 输入的信息变少。
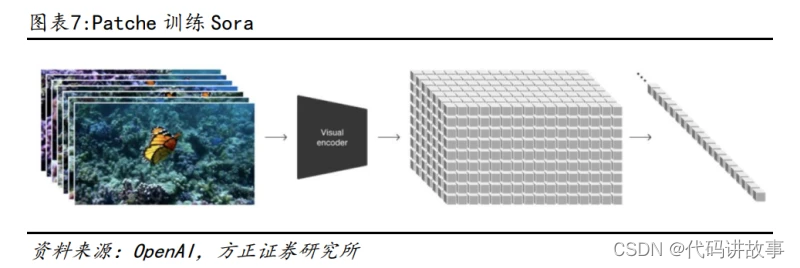
训练中具有采样的灵活性,并通过原始尺寸、时长训练。Sora 可以采样宽屏 1920x1080p 视频、垂直 1080x1920 视频以及介于两者之间的所有视频,这使得 Sora 可以直接以其原生宽高比为不同设备创建内容。与业内常用的把视频截取成 预设标准尺寸、时长后再训练的路径不同,OpenAI 选择了原始尺寸、时长训练, 这使得 Sora 生成的视频能更好地自定义时长、更好地自定义视频尺寸、视频会 有更好的取景和构图。
Sora 是技术与路径迭代的成果。从语言理解来看,在训练端,OpenAI 利用 DALL·E 3 re-captioning 功能,给训练用的视频素材都加上了高质量文本描述,在输入 端,通过 GPT 先将用户输入的提示词精准详尽扩写,再将扩写后的提示词交给 Sora。我们认为,该模型完美继承 DALL·E 3 的画质和遵循指令能力,并利用了 GPT 扩写,Sora 震撼效果得益于 OpenAI 过去的工作,均具有很强的继承性与延 展性,是技术与路径迭代的成果。
除 Sora 之外, Runway、Pika 等也可支持文生视频: 1)Runway:支持文生视频,运动笔刷控制多物体运动 Runway 支持文生视频,时长为 4s。用“爆炸的宇宙 exploding universe”等简 单的提示词,点击 Generate 等待生成 4 秒视频,可以写视频脚本,把不同的 视频短画面合成长视频,点击 Extend 4s 按钮,在原视频上可以延长 4 秒;也可 以把图片直接拖进来,或者单击图片上传区域,在本地选择图片,通过图片来生 成视频。除此之外,Runway 还具有 Green Screen 绿幕去背、Blur Faces 模糊 人脸、Inpainting 移除影片物件等功能。
Runway Gen-2 视频模型的运动笔刷(Motion Brush)再进化,支持独立控制多达 5 个选定的区域。升级后的运动笔刷支持复杂空间运镜、人物表情控制、人物躯 体控制与多个角色控制,最多可独立控制 5 个选定的区域。通过分别控制《黑客 帝国》子弹瞬间的不同对象,可达到很强的立体空间感。除此之外,橡皮擦可对 选错的区域进一步微调,增加了易用性。
2)Pika:动画领域优势显著,DreamPropeller 提速 3D 生成
Pika 可单次生成 72 帧视频,成立迄今已有 70 多万用户。Pika 可以实现文生和 图生视频,一键最多生成长度为 3 秒的 24 帧视频,此外对于现有视频,可以支 持风格转换、幕布扩展(expand)、内容编辑、扩展剪辑长度(extend)等功能, 针对 Runway 短板进行升级。Pika 在单帧画面拟真程度上具有出色的表现,具备 良好的文生和图生视频能力,特别是在 2D、3D 动画领域。
分辨率比例、帧数可调整,视频输出灵活。“Aspect ratio”和“Farmes per second”功能可调整视频的分辨率比例、帧数。可选择的分辨率包括 16:9、9:16、 1:1、5:2、4:5、4:3,最高可生成 24 帧的视频,视频输出灵活。
DreamPropeller 基于分数蒸馏,助力文本到 3D 生成速度提高 4.7 倍。Pika 官方 账号披露了公司产品的技术细节,DreamPropeller 能够在几乎不损失生成质量的 情况下,将文本到 3D 的生成速度提升 4.7 倍。实验根据对 DreamFusion 图库中 的 30 个提示进行测试评估,新模型速度均提高了 4 倍以上。
在算力需求大、高质量数据集短缺、可控性较差等挑战下,文生视频是 AIGC 的 高地, 除 Runway、Pika 之外,Stability AI 也发布了 Stable Video Diffusion 视频模型,用户可根据需要调整各种参数,如迭代步数、重绘幅度等,以协助创 作者精确掌控画面生成过程, Meta 推出了两项基于 AI 的视频编辑新功能;在开 源上,AnimateDiff、MAKEAVIDEO、MagicAnimate 等也在布局 AI 视频生成赛道。 我们认为,从 Runway、Pika 到 Sora,文生视频大模型频出,视频长度从表情包 长度的 3s、4s 到主流短视频长度的 60s,模型对物理世界的理解愈加接近现实, 已具备强大的商业化落地价值,创作内容产业革命来临,AIGC 新时代已至。
1.2 Gemini 1.5 Pro 性能显著增强,长上下文理解取得突破
Gemini 1.5 Pro 性能显著增强,支持 100 万 token 上下文长度。2024 年 2 月 15 日谷歌发布 Gemini 1.5 Pro,支持 100 万 token 上下文长度,谷歌透露内部研究 版本已直冲 1000 万。Gemini 1.5 Pro 性能显著增强,在长上下文理解方面取得 突破,能仅靠提示词学会训练数据中没有的新语言,其性能与谷歌迄今为止最大 的模型 1.0 Ultra 相当,在对文本、代码、图像、音频和视频的综合评估面板上 进行测试时,在用于开发大语言模型的 87%的基准测试中,Gemini 1.5 Pro 优于 1.0 Pro。
Gemini 1.5 Pro 代码、文本和视频交互能力卓越。Gemini 1.5 Pro 能够摄取整 个大型代码库,如 JAX(746,152 个 token),并回答关于它们非常具体的查询。除 此之外,在给定 Les missamrables 全文的情况下具有回答图像查询的能力,原 生的多模式允许它从手绘草图中定位一个著名的场景,另外,Gemini 1.5 Pro 可 回答电影相关问题,如输入 45 分钟的整部电影,该模型在检索时刻和时间戳精 确到一秒的同时可无缝回答问题。
Gemini 1.5 Pro 新技能学习能力强大,有望提升稀有语言的翻译质量。Gemini 1.5 Pro 仅基于其输入中给出的参考材料学习新语言的能力,输入一整本语法书, Gemini 1.5 Pro 就能在翻译全球不到 200 人使用的卡拉曼语上达到人类水平, 在英语到卡拉曼语的翻译中,Gemini Pro 1.5 的 ChrF 达到了 58.3,略高于 MTOB 论文报告的 57.0 ChrF 人类基准。而 GPT-4 Turbo 和 Claude 2.1 一次只能看完 半本书,必须要微调或者使用外部工具。
1.3 AI 生产力革命如火如荼,产业链上下游协同发展
AI 生产力革命如火如荼,产业链上下游协同发展。我们看到,AI 大模型的发展 正在不断加速 AGI 通用人工智能的到来,纵观整个 AI 产业链,硬件和软件的配 合才能更好地实现多种终端应用的价值化落地,其中上游的基础层包括 AI 模型 生产工具(AI 算法框架+AI 开发平台+AI 开放平台+预训练大模型)、AI 算力基础 (AI 芯片+服务器+智算中心+云服务)、AI 数据资源(AI 基础数据服务+数据治 理),中游的技术层包括计算机视觉、智能语音、自然语言处理、知识图谱和机器 学习,下游的应用层则是百花齐放,以 AI+泛安防/泛互联网/媒体/金融/医疗/工 业/零售/政务为代表,还包括对话式 AI、机器人、自动驾驶、无人机等。可以预 见的是,未来的 AI 时代又是生产力的爆发式革命。 就硬件层面而言,我们针对性梳理了数据中心三大核心硬件产业链(服务器、光 模块、交换机),AI 的进步将促使硬件参数不断提升,相关产业链有望充分受益。
2 “AI+终端”智能化加速,手机、MR、机器人等新品迭出
2.1 三星 S24 系列引入 Galaxy AI,开启移动 AI 新时代
S24 系列引入 Galaxy AI,搭载骁龙 8 Gen3。 2024 年 1 月 18 日,三星电子正式 推出新一代高端旗舰 Galaxy S24 系列,产品包括 Galaxy S24 Ultra、Galaxy S24+和 Galaxy S24。该系列搭载第三代骁龙 8(for Galaxy)——高通首个专为 生成式 AI 而打造的移动平台,赋能 Galaxy AI,相比上一代 CPU 和 GPU 性能分别 提升 20%和 30%,NPU 性能显著提升。此外,三星在国内携手百度智能云,Galaxy AI 深度集成了百度文心大模型,而海外版建立在谷歌 AI 模型之上,均在智能文 本、通话翻译等方面提升用户体验。
AI 增强通话功能,为用户提供个人翻译。在沟通层面,S24 系列带来 Galaxy AI 全新通话实时翻译功能,通话时点击“通话辅助”,无需第三方应用即可实现双向 语音和文字翻译。实时翻译的过程基于完全离线的 AI 技术,效率高、稳定性强, 还保障了通话的隐私与安全。AI 驱动支持 13 种语言(17 个地区)的互译,除了 中英文,还包括法语、德语、日语、韩语等,也在短信与其他应用上通过写作助 手、转录助手进行翻译、转录等生成文本的工作。
“即圈即搜”颠覆传统在线搜索模式。在搜索层面,即圈即搜功能使得用户能够 圈选屏幕上的内容,包括视频、图像及文字,在无需离开当前页面的情况下,立 即获取更多相关信息。该功能不仅适用于网络浏览器和相册等应用,还可以在相 机应用的实时取景画面中使用。
超视觉影像、智能修图建议提升出片率。在影像拍摄上,搭载全新 AI 影像工具 套件——超视觉影像,超视觉夜拍功能升级,Galaxy S24 Ultra 的像素尺寸达到 1.4μm,相比前代机型提升了 60%,能够在昏暗环境下捕捉到更多光线;在影像 处理上,借助 Galaxy AI,可对照片进行清除、重新构图和重录等多种编辑。例 如,利用第三代骁龙 8(for Galaxy)认知 ISP 的强大算力,能自由移动被选中 的人物或物体的位置,通过生成式 AI 在原位智能生成自然、协调的背景。
2.2 大模型厂商创新不断,AI 加持多种应用场景
小米迈入“人车家全生态”,MWC 亮相在即。2023 年 10 月,小米推出了新系统小 米澎湃 OS,使 AI 大模型深入“人-车-家”整个生态系统。小米 14 系列的两款新 旗舰搭载该系统,是国内第一款能够在端侧运行 AI 大模型的智能手机,搭载了 小米自研的 60 亿参数级大模型,能够在手机上离线进行“文生图”、“AI 扩图” 与“AI 去除路人”。此外,小米“影像旗舰”14 Ultra 以及首款电动车——小 米 SU7 将亮相 MWC 2024,展示其“人车家全生态”操作系统。
OPPO 进入 AI 手机时代,推出 ColorOS AI 新春版。OPPO 在 2024 年 2 月 9 日的发 布会上,宣布正式进入 AI 手机时代,开启“千万用户 AI 尝鲜计划”。推出 ColorOS AI 新春版,可应用在 OPPO 的 16 款机型上,包括 OPPO Find X7 系列、Find X6 系列、Reno10 及 11 系列、一加 12 等。ColorOS AI 新春版带来 AI 消除、AI 通话 摘要、新小布助手、小布照相馆、小布 AI 贺卡等重大更新。其中,AI 通话摘要 可智能识别通话内容,生成重点信息摘要。
苹果全力加码人工智能,iPhone 16 有望包括 AI 功能。在主流手机厂商中,苹果 还未推出 AI 手机,正在全力加码人工智能,下一代 iPhone 和 iPad 软件更新有 望包括一系列新的 AI 功能。在最近的季度电话会议上,苹果 CEO 表示在 AI 计划 上投入大量时间与努力。苹果正接近完成 AI 软件开发工具,将作为其旗舰编程 软件 Xcode 新版本的一部分。 联想 AI PC 规模化落地。在 CES2024 上联想推出 AI PC: 1)两款旗舰产品 Yoga Pro 9i 和 Yoga 9i,配备 Yoga Creator Zone 生成式 AI 软件,可将基于文本的描述或草图转换为图像; 2)ThinkPad X1 Carbon AI、ThinkPad X1 二合一以及 IdeaPad Pro 5i 三款 AI PC 均搭载最新的英特尔酷睿 Ultra 处理器和 Windows 11 系统,作为英特尔 Evo 笔记本系列,兼具高效的电源管理、强大的性能以及深度沉浸的使用体验; 3)联想 LA AI 芯片是全新游戏阵容的关键核心,助力游戏本实现更流畅、自由 的游戏体验。
联想将在 MWC 上展示新款 AI PC。我们看到,联想针对不同产品定位进行 AI 赋 能。面向消费者的 Yoga 系列通过配备生成式 AI 软件协助创作;B 端产品则更注 重性能、体验、算力方面;游戏本方面则通过 AI 芯片助力体验。在即将举行的 MWC 上,联想将推出最新的人工智能设备和基础设施及解决方案组合,并展示两 款挑战传统个人电脑和智能手机外形的新概念产品。 华硕灵耀 14 双屏端侧 AI 性能出色。“灵耀 14 双屏”于 2024 年 2 月开售,配 备主副两块 2.8K 分辨率可触控的 OLED 屏。内置英特尔酷睿 Ultra9 处理器,借 助其三大 AI 引擎,能够本地运行 AI 工具应用,通过内置的上百亿参数大语言模 型,高效地完成文章总结、故事创作、文案翻译等繁琐任务。在视频编辑上,NPU 的强大性能让剪映智能抠像处理的速度提升了 2.6 倍。
AI+AR 深度融合,雷鸟 X2 Lite 问世。雷鸟 X2 Lite 搭载业内领先的双目全彩 MicroLED+光波导方案,支持全场景高透光、高亮度的全彩显示。此外,雷鸟 X2 Lite 配备了高通骁龙 AR1 平台,该芯片集成高通第三代 NPU,提供强大的 AI 处 理能力,为大模型应用提供了重要的运算基础。其内置的雷鸟自研大模型语音助 手 Rayneo AI(Beta 版),可实现多轮自然语言对话、行程规划、便捷百科问答、 头脑风暴等多项能力,给用户带来全新的“AI+AR”体验。
奔驰发布 MBUX 虚拟助理,宝马发布基于亚马逊大模型的智能个人助理。奔驰 MBUX 运用生成式 AI 和 3D 图形技术,实现更加自然、直观且高度个性化的人车互动; 宝马发布基于亚马逊Alexa大语言模型提供的生成式人工智能技术而打造的全新 一代 BMW 智能个人助理。智能助理化身一位宝马汽车专家,为驾乘人员提供更人 性化的帮助,及时解答有关车辆的疑问。
2.3 英伟达正式发布 AI 聊天机器人
近日英伟达正式发布Chat With RTX,这款应用适用于Windows平台,由TensorRTLLM 提供支持,并完全在本地运行。用户可以利用 Chat With RTX 以自己的内容 定制一个聊天机器人,从而体验独特的本地化系统设计和强大的功能。 我们看到,Chat With RTX 的功能主要包括: 1) 文件处理:支持多种文件格式,如文本、pdf、doc/docx 和 xml 等。用户只需 将包含所需文件的文件夹指向给定目录,Chat with RTX 会在几秒钟内将其 加载到数据库中。 2) 视频内容处理:能够加载 YouTube 播放列表的 URL,并提供视频转录服务, 以便用户快速查询视频内容。 3) 个性化 AI 对话:允许用户以自己的资料(如文档、笔记、视频或其他数据) 定制聊天机器人,使 AI 对话更具个性化。用户可以与这个自定义的聊天机器 人进行对话,快速灵活地获得聊天机器人根据用户内容给出的见解。
此次 Chat With RTX 的发布具有重要的意义,加速了 AI 的普及和应用。同时此 款应用改变人与 AI 的交互方式,用户可以根据自己的需求定制聊天机器人,这 使得 AI 的使用更加灵活和便捷。Chat With RTX 也代表了大型语言模型技术发 展的一个重要方向,即为本地化、个性化、隐私保护的 AI 应用提供了新的可能。
2.4 诸多新品亮相 CES,AI 终端时代来临
2.4.1 英伟达:AI 技术加持新显卡,生成式 AI 改造游戏 NPC
AI 技术加持,GPU 性能更胜一筹。英伟达发布了全新的 GeForce RTX 40 SUPER 系列显卡,包含了 GeForce RTX 4080 SUPER、GeForce RTX 4070 Ti SUPER 和 GeForce RTX 4070 SUPER 三款芯片,其中 Ti SUPER 的组合第一次出现在 GeForce 的命名规则中。RTX 40 SUPER 系列借助深度学习超级采样技术(DLSS),游戏画 面中八分之七的像素都可以由 AI 生成,有效地降低了 GPU 渲染压力、提升了游 戏帧率。
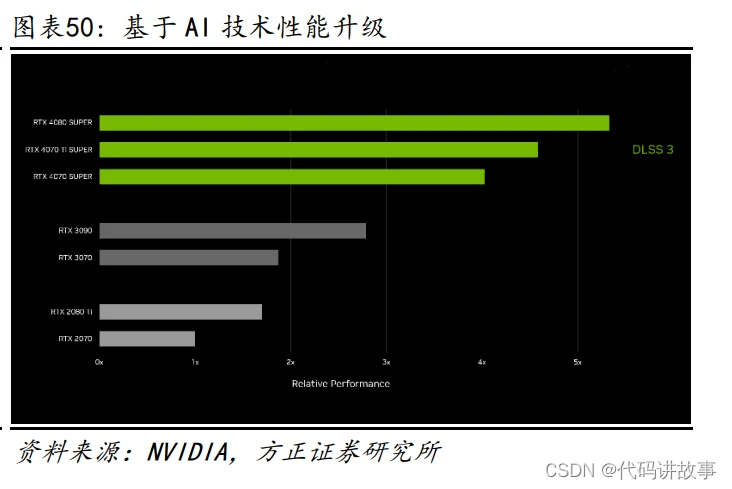
1)RTX 4070 SUPER:以进阶级价格获得超越旗舰的性能。与 RTX 4070 比较,该 芯片增加 20%的 CUDA 核心。与上代旗舰 RTX 3090 相比,在图形密集度最高的游 戏中,其运行速度更快,而功耗却只有几分之一,在开启 DLSS 3 的情况下速度 更是快了 1.5 倍。RTX 4070 SUPER 于 2024 年 1 月 17 日开售,售价人民币 4899 元起,以进阶级价格获得超越旗舰的性能。
2)RTX 4070 Ti SUPER:更多 CUDA 核心和更多内存,存储扩增至 256-bit 的 16GB GDDR6X。该芯片能将高刷新率 1440p 面板性能发挥到极致,甚至可以在 4K 分辨 率下游戏。此外,创作者也会乐于用它来编辑视频和渲染大型 3D 场景。与 RTX 3070 Ti 相比,速度快 1.6 倍,配合 DLSS 3 时速度快 2.5 倍。RTX 4070 Ti SUPER 于 2024 年 1 月 24 日开售,售价人民币 6499 元起。
3)RTX 4080 SUPER:配备了更多 CUDA 核心,以及运行速度高达 23Gbps 的全球 最快 GDDR6X 视频内存(VRAM),是 4K 光追游戏和要求最苛刻的生成式 AI 应用的 完美选择。与 RTX 3080 Ti 相比:在对图形性能要求非常高的游戏中,速度快 1.4 倍;凭借 836TOPs 的 AI 算力,速度快 2 倍;生成视频的速度快 1.5 倍,生成 AI 图像的速度快 1.7 倍。RTX 4080 SUPER 售价人民币 8099 元起,于 2024 年 1 月 31 日开售。
ACE 微服务使虚拟角色栩栩如生。英伟达推出 ACE(Avatar Cloud Engine)微服 务,将 A2F 和 RIVA ASR 这些 AI 模型融入游戏,前者使玩家能够通过麦克风与 AI 角色对话,后者通过音频源为游戏角色生成丰富的面部动画。在此次活动中,英 伟达展示了与开发平台——Convai 的最新合作成果:玩家与新一代 AI NPC 之间 动态对话等交互能力。ACE 微服务不仅可以应用在游戏领域,也可用于虚拟客服 等通过虚拟化身提供服务的领域。现已开始采用 ACE 的开发者除了 Convai,还有 Charisma.AI、Inworld、米哈游、网易游戏、掌趣科技、腾讯游戏、育碧和 UneeQ。
可以看到,英伟达如今正处于最新技术变革的中心:生成式人工智能(Generative AI),在 CES 2024 上发布了从 RTX GPU 到软件应用、开发工具等一系列重磅新品, 均与高性能生成式 AI 功能相关,未来将继续挖掘出 AI 驱动的生产潜力。
2.4.2 AMD:全新桌面 APU 发布,推动高性能计算发展
锐龙 8000G 系列开辟台式机 AI 新时代。上一代桌面 APU 锐龙 5000G 系列发布于 2021 年,时隔两年九个月,AMD 终于更新了桌面 APU 处理器锐龙 8000G 系列。锐 龙 8000G 系列结合了独立显卡的强大性能与 Zen4 CPU 核心,实现了高能效比。 其中,锐龙 7 8700G 和锐龙 5 8600G 集成锐龙 AI 引擎,是首款搭载 NPU 的台式 电脑处理器,在台式机领域率先具备加速 AI 软件,优化 AI 工作负载,提高 AI 处 理效率,并开启了 AI 降噪等多项功能。
新型号锐龙 5000 处理器延长 AM4 平台寿命。AMD 继续推出新型号锐龙 5000 处理 器,延长基于 AM4 架构非凡的平台使用寿命,为用户在构建生产力、游戏或内容 创作的个人电脑系统时提供更多选择。新产品包括新的锐龙 7 5700X3D,利用强 大的 3D V-Cache 技术,在游戏性能方面有巨大提升。
全新锐龙 8040 系列处理器带来个人 AI 处理的飞跃。AMD 在上个月 Advancing AI 大会上发布锐龙8040系列移动处理器,该系列将人工智能置于前沿和中心位置, 在部分机型上集成了锐龙 AI NPU,带来个人 AI 处理的下一个飞跃。其中 AI 性 能算力从 10TOPS 提升至 16TOPS,升幅高达 60%,并使总算力从 30TOPS 增至 39TOPS。 宏碁、华硕、联想、惠普和雷蛇等 AMD 合作伙伴将推出更多搭载 Windows 11 的 笔记本电脑和手持游戏系统,这些产品均采用 Ryzen 8040 系列处理器。
AMD 新款 RX 7600 XT 显卡 16GB 大显存可处理 1440p 游戏。AMD 还推出新款 Radeon RX 7600 XT 显卡,配备 16GB 高速 GDDR6 显存,适用于 1440p 游戏或带有光追的 1080p 游戏。与 RX 7600 相比,显存从 8GB 提升至 16GB,时脉从 2.25GHz-2.66GHz 提升至 2.47GHz-2.76GHz,为此整卡功耗从 165W 提高至 190W。预计 2024 年 1 月 24 日上市,售价 329 美元(2353 元人民币)。
综上产品可以看到,AMD 一直致力于推动高性能计算的发展边界,全新锐龙 8000G 系列处理器将高性能计算带入下一个层次:游戏、AIPC 和超小型设备。AMD 未来 将继续与整个 AI 生态系统深度合作,助力生成式 AI。
2.4.3 高通:AI 处理器赋予 XR 新体验,开启出行全新时代
骁龙 XR2+ Gen2 支持超 4K 分辨率,大大提升画面精细度。在 XR 方面,高通发布 了骁龙 XR2+ Gen 2 芯片,与上一代骁龙 XR2 Gen 2 相比,从支持单眼 3K 分辨率 提升至单眼 4.3K,每秒传输帧数达到 90 帧,CPU 频率、GPU 频率分别提升了 20%和 15%,带来了 25%的性能提升以及 50%的能效提升,同时 AI 性能提升了 8 倍。 其中,最关键的提升在于超 4K 分辨率,带来画面精细度提高,将一定程度上提 高整个智能头戴设备行业的水平。歌尔宣布与高通合作,三星和谷歌也计划在将 骁龙 XR2+ Gen 2 应用在安卓系统上运行的虚拟现实产品上。
骁龙数字底盘为下一代生成式 AI 赋能。在汽车领域,高通展示了骁龙数字底盘 解决方案的突破创新,该组合产品为下一代生成式 AI 提供赋能,涵盖数字座舱、 车联网技术、网联服务、先进驾驶辅助与自动驾驶系统等多个方面。其中一项升 级是“下一代生成式 AI 的数字座舱”,用于边缘生成人工智能,这意味着根据不 同的品牌和应用产品,汽车可以运行生成式 AI 应用程序,动态更新与驾驶员在 路上相关的信息。博世基于高通的 Ride Flex SoC,以单颗 SoC 同时支持数字座 舱、ADAS 和 AD 功能,实现下一代软件定义汽车。
2.5 MR 是 AI 的最佳落地形式,高度赋能内容生态
2.5.1 Meta 发布 AnyMAL,研究成果有望整合入元宇宙产品线
AnyMAL 实现图像/视频/音频/IMU 运动传感器数据等多模态数据转换,创造新的 SOTA。Meta 推出经过训练的多模态编码器集合 AnyMAL(Any-Modality Augmented Language Model),可实现各种模态(包括图像、视频、音频和 IMU 运动传感器数据)的数据转换至 LLM 的文本嵌入空间,数据集包含包含 2 亿张图像、220 万 段音频、50 万 IMU 时间序列、2800 万段视频等多种模态数据,利用图像、视频、 音频跨三种模式的多模态指令集对模型进行微调。AnyMAL 创造了新的 SOTA:在 VQAv2 上提高了 7.0%的相对准确率,在零误差 COCO 图像字幕上提高了 8.4%的 CIDEr,在 AudioCaps 上提高了 14.5% 的 CIDEr。从 AnyMAL 的输出示例来看, 除了简单的 QA 外,还能很好的解决灵感与建议、创新写作、图像字幕、隔行扫描 形式、音频信号推理、运动传感器推理等多种不受拘束的任务。
图像标题生成表现、多模态推理任务人工评估胜率优于基线。我们看到 AnyMAL13B 和 AnyMAL-70B 性能差距较小,底层 LLM 能力对图像标题生成任务影响较小, 两个变体在 COCO 和标有「详细描述」任务(MM-IT-Cap)的 MM-IT 数据集上表现 均明显优于基线。在多模态推理任务的人工评估中,AnyMAL 性能强劲,与人工标 注的实际样本的差距较小,完整指令集微调的模型表现出最高的优先胜率。
VQAv2 提高 7.0%的相对准确率,音频字幕生成能力优秀。我们看到 AnyMA 在 6 个 不同的 VQA 数据集(H-Meme:hate Meme, S-QA: Science QA)上基于 Zeroshot image 的 QA 结果,与基线视觉语言模型相比,AnyMAL 展示了具有竞争力的多模 态推理能力,VQAv2 提高 7.0%的相对准确率,在视频 QA 中的 STAR 中 AnyMA 表现 也较为优秀。从 AnyMAL 的音频字幕生成能力来看,AnyMAL 的表现明显优于 CIDEr +10.9pp,SPICE +5.8pp,支持多音道音频字幕生成能力,如婴儿哭泣和女性说话 同时进行。

Meta 还推出测试版的聊天机器人 Meta AI,可以支持在 Quest 3 上面使用。Meta AI 利用了 Llama 2 的技术和最新的大型语言模型研究,能生成文本回复及图像, 可以通过与微软必应搜索引擎的合作获得实时信息。可以使用的 App 包括 Whats App、Messenger 和 Instagram 等。
Meta 发布 AnyMAL,研究成果有望整合入元宇宙产品线。AnyMAL 于 2023 年 9 月 28 日发布,而 Meta Quest 3 于同日发布,两者在时间上相近,且 Meta Quest 3 可收集多模态数据,将真实世界和虚拟世界无缝融合,实现 Meta Reality 体验, 我们认为 AnyMAL 相关研究成果有望为 Meta 的元宇宙产品线提供支持并应用到消 费者市场。
2.5.2 MR 为 AI 最佳落地终端,高度赋能 MR 内容与硬件
MR 为 AI 最佳落地终端,高度赋能 MR 内容与硬件。近期 intiny 开发的《完蛋! 我被美女包围了》火速霸榜 Steam 国区热销第一名、全球第四,销量破百万,真 人互动游戏爆火下,我们认为 MR 是 AI 最佳落地终端,泛社交、B 端应用拓展也 拥有想象空间:
1)办公场景: Workrooms 是一个身临其境的虚拟办公室,无论是戴着 Meta Quest 头戴式耳 机,还是从 2D 屏幕上加入,都可以在这里与队友会面、集思广益、分享演示文 稿并完成工作。同时,Workrooms 还支持 Zoom,让连接更方便。 表情丰富的虚拟化身:让虚拟的形象看起来、行动起来和表现得与参会者一 模一样,并通过自然的面部表情和手势丰富非语言交流。 定制环境:用图像和徽标定制办公室。无论是在海滩边破冰,还是在城市上 空进行协作,都能为会议营造合适的氛围。 持久白板:在会议室或虚拟个人办公室使用虚拟白板,勾画想法或附加便笺, 下次签到时,白板上的内容依然存在。
2)政府服务: 首尔市政府正式开展元宇宙服务,建立涵盖经济、教育、税务和行政等领域的行 政服务平台。该市还打算在接下来的五年里陆续推出更多涉及政府、商业、旅游 和文化的服务。首尔市政府向媒体透露,社会正在经历巨大的变革,非接触式服 务日益普及,信息通讯技术不断进步,数字世代成为主导力量,首尔市政府就是 基于这样的形势,提出了“元宇宙首尔”这一创新的行政服务理念。该平台以自 由、同行、联接为核心价值,旨在包含各种公共服务,创建创意与沟通空间、平 等的超现实空间、融合现实空间。
3)金融服务: 中国工商银行虚拟营业厅率先构建 “VR 智能眼镜+元宇宙+智慧金融”场景。在 虚拟营业厅中,用户仿佛置身于真实的全景环境,不仅能体验行走的空间感、纵 深感,对网点的格局、设施、产品展示、展品细节、空间的大小也都能一目了然。 工商银行虚拟营业厅融合了虚拟数字人技术,客户在虚拟空间中以第一人称视角 参观虚拟网点,与人工智能虚拟数字人客服进行交互通过看、听、说等多维度交 互方式获得更直接丰富的全新体验。
4)医疗场景: 内置 AI 医疗系统的 AR 眼镜可以用于病情诊断、远程会诊和医疗教学:
病情诊断:利用内置 AI 医疗系统的 AR 眼镜,医生可以直观地观察患者身体 的状况,并实时获取患者的生命体征分析,从而做出更加精准的病情诊断。 这种技术的应用,不仅可以提升医生的诊断水平,也可以节约医生的时间和 精力。AR 眼镜能够支持远程会诊的功能。
远程会诊:通过 AR 眼镜,患者和医生可以进行实时的视频交流,同时 AR 眼 镜可以传送患者身体的数据和医生的指导建议。这种技术可以增强患者和医 生之间的沟通效果和效率,同时也可以让医生更深入地了解患者的病情,从 而更好地进行诊断和治疗。医疗教学领域也可以利用 AR 眼镜的技术。
医疗教学:医生可以通过 AR 眼镜向学生实时传达指导和建议,同时学生可 以通过 AR 眼镜观察患者的身体情况和医生的操作过程。这种方式可以让学 生更加深入地了解患者的病情和治疗方法,同时也可以让医生更好地进行指 导和教学。
3 AI 驱动全球算力硬件环节创新与需求共振
3.1 英伟达:H200 出货在即,定制芯片业务储备中
首款搭载 HBM3E 的 GPU H200 于 2023 年 11 月发布,预计 24Q2 实现出货。2023 年 11 月 13 日,英伟达发布首款提供 HBM3e 的 GPU,作为一种更快、更大的内 存,HBM3e 可加速生成式 AI 和大型语言模型,同时能推进 HPC 工作负载的科 学计算。借助 HBM3e,NVIDIA H200 能以每秒 4.8 TB 的速度提供 141GB 内存, 与前前一代的 NVIDIA A100 相比,容量几乎翻倍,带宽增加 2.4 倍,在用于推 理或生成问题答案时,性能较 H100 提高了 60%至 90%,采用 HBM3e 内存技术的 H200 在处理 700 亿参数的大模型时,推理速度较 H100 快了整整一倍,能耗降低 了一半。受 HBM3E 供应限制,预计 H200 将于 24Q2 实现出货。
H200 具备超过 460 万亿次的浮点运算能力,可支持大规模的 AI 模型训练和复杂 计算任务。HGX H200 采用了 NVIDIA NVLink 和 NV Switch 高速互连技术,为各种 应用工作负载提供最高性能,包括对超过 1750 亿个参数的最大模型进行的 LLM 训练和推理。借助 HBM3e 技术的支持,H200 能够显著提升性能。在 HBM3e 的加持 下,H200 能够将 Llama-70B 推理性能提升近两倍,并将运行 GPT3-175B 模型的性 能提高了 60%。对于具有 700 亿参数的 Llama2 大模型,H200 的推理速度比 H100 快一倍,并且推理能耗降低了一半。此外,H200 在 Llama2 和 GPT-3.5 大模型上 的输出速度分别是 H100 的 1.9 倍和 1.6 倍。
H200 芯片支持高达 48GB 的 GDDR6X 内存,其内存带宽可达 936GB/s,有效提高了 数据传输速度并降低了延迟。对比 H100 的 SXM 版本,显存从 80GB 提升 76%,带 宽从每秒 3.35TB 提升了 43%。对于模拟、科学研究和人工智能等内存密集型 HPC 应用,H200 的更高内存带宽可以确保高效地访问和操作数据。与传统的 CPU 相 比,使用 H200 芯片可以将获取结果的时间加速多达 110 倍。
静待 B100 发布,展望 X100。英伟达 B100 的原计划发布时间为 2024 年第四季度, 但由于 AI 需求的火爆,已经提前至第二季度,目前已经进入供应链认证阶段, B100 将能够轻松应对 1730 亿参数的大语言模型,比当前型号 H200 的两倍还要 强大。此外,B100 将采用更高级的 HBM 高带宽内存规格,有望在堆叠容量和带宽 上继续突破,超越现有的 4.8TB/s。根据英伟达产品路线图,预计 2025 年将推出 X100,进一步丰富 GPU 产品矩阵,巩固英伟达 AI 芯片龙头地位。
英伟达进军定制 AI 芯片领域。根据 CNBC,英伟达目前正在策划建立全新部门旨 在为云计算企业和其企业提供定制化芯片业务。根据 CNBC,定制化芯片或将专注 于满足特定设备或者系统的性能和功耗要求,其中或将包含特定的处理单元,传 感器集成、专用硬件加速器,以满足特定领域的需求。目前根据 CNBC,英伟达已 经和亚马逊、Meta、微软、谷歌和 OpenAI 商议定制 AI 芯片的相关合作。 在定制化 AI 芯片领域,谷歌旗下 TPU 已经实现多次迭代,目前迭代至 Cloud TPU v5 系列,其中 Cloud TPU v5p 为系列中性能最强 TPU,含有 8960 个芯片,芯片 互联速度可达 4800 Gbps,在训练 LLM 模型时速度相较于上一代 TPU v4 快 1.9~2.8 倍。
3.2 AMD:MI300 正式发布,2024 年销售收入上调
2023 年 12 月 6 日,AMD 在 Advancing AI 活动上宣布推出 Instinct MI300X,采 用了 AMD CDNA3 架构,搭载了 8 块 HBM3,容量达 192GB。与 MI250X 相比,计算 单元增加了约 40%、内存容量增加 1.5 倍、峰值理论内存带宽 3 增加 1.7 倍。在 某些工作环境中,性能可达 H100 的 1.3 倍。
MI300 采用 3.5D 封装,I/O 密度进一步提升。MI300X 采用 3.5D 封装,即通过混 合键合技术实现 XCD、I/Odie 的 3D 堆叠,其次在硅中介层上实现与 HBM 的集成, 从而实现了超过 1500 亿个晶体管的高密度封装。该封装方案由台积电提供,搭 配 SoIC 技术与 CoWoS 技术共同实现。
SoIC 技术升级,MI300 带宽升至 V-Cache 的 7 倍。AMD 3D V-Cache 中的 SoIC 尺 寸大小约为 7x10mm,逻辑芯片放置在垂直结构的下方;CCD 为 5nm 节点,X3D 为 7nm 节点,通过 SoIC 可提供高达 2.5 TB/s 的垂直带宽。在 MI300 中,SoIC 技术 迎来进一步升级,尺寸扩大至 13x29mm(面积约为此前的 5 倍),逻辑芯片放置在 了垂直结构的顶部以更好的散热,5nm 的 XCD/CCD 堆叠在 6nm 节点的 IOD 上,垂 直带宽提升至 17TB/s(为 3D V-Cache 的 7 倍)。
根据 AMD 2023Q4 法说会,目前 MI300 已经成为 AMD 历史产品中收入增速最快的 产品,同时 AMD 法说会中表示,2024 年 MI 芯片销售收入超过 35 亿美金,高于此 前预测 20 亿美金。
3.3 AI 浪潮推动光模块、交换机配套升级
根据 Coherent,2023 年主要下游应用市场规模达 640 亿美元。公司产品主要下 游应用市场包括工业、通信、电子、使用仪器,2023 年通信市场规模达 230 亿美 元,2023-2028 年 CARG 为 14%,其次为工业市场,2023 年工业市场规模达 220 亿 美元,2023-2028 年 CARG 为 9%,电子器件市场规模达 140 亿美元,CARG 为 20%, 使用仪器市场规模为 50 亿美元,CARG 为 8%,四大主要市场合计市场规模将达 640 亿美元,2023-2028 年 CARG 为 14%,其中通信方面 AI 将为主要驱动力。
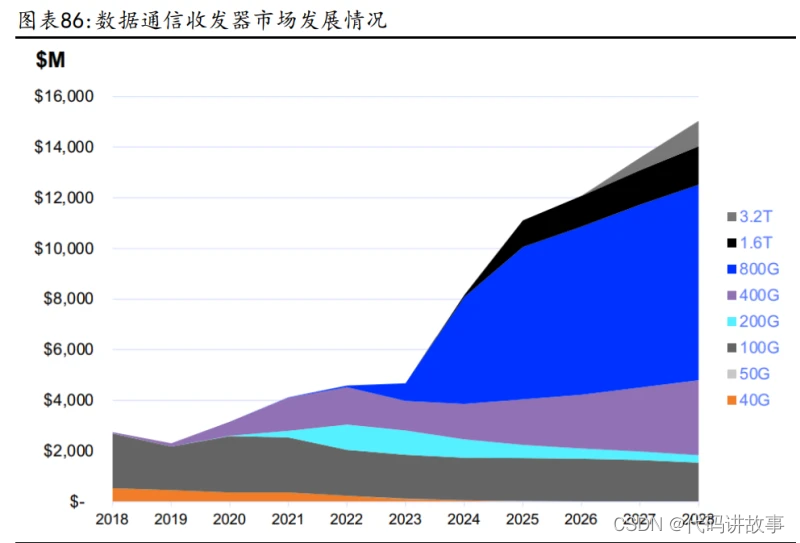
数据通信收发器向高传输速率演进,2028 年 800G 及以上产品市场占比将超 65%。 根据 LightCounting 数据,数据通信收发器市场规模将由 2023 年的 51 亿美元增 长至 2028 年 153 亿美元,2023-2028 年 CARG 为 24.6%,其中 800G 产品自 2023 年起进入高速发展阶段,800G 及以上产品预计 2028 年占数据通信收发器市场 65% 以上份额,2023-2028 年 CARG 将达 65%。从细分产品来看,EML 产品占比快速提 升,其中 AI 用 EML 产品 2028 年预计占整个市场 33%,市场规模达 50 亿美元,较 2023 年的 6 亿美元较大提升,且市场占比由 12%提升至 33%。
以太网交换机市场潜力巨大。Arista 于 2023Q4 宣布推出下一代 7130 系列交换 机,用于超低延迟切换,加速 25G 网络。凭借三个新的 25G 优化系统、增强的光 学性能、25G 就绪 FPGA 应用程序和 FDK(FPGA 开发套件)更新,Arista 满足了 25G 市场数据分发和高频交易(HFT)环境的需求。对于 400G,客户群已从 2022 年的 600 名增加到 2023 年的约 800 名。
IB 交换机 2024 年有望持续高增。对 AI 应用的聚焦推动了英伟达 2023 年数据中 心产品的销售。与 2022 年相比,2023 年 IB 交换机的 ASIC 销量增长预计近三倍, 同时 LIGHT COUNTING 预计 2024 年 IB 交换机仍将维持强劲增长,预计 2023-2028 年均复合增长率将达 24%,对应 2028 年 IB 交换机市场销售规模将超 30 亿美元。
作为全球光模块、交换机代表企业,Coherent 和 Arista 业绩向好,其中: Coherent:AI 驱动 800G 环比持续高增,1.6T 有望于 2025 年商业化 Coherent FY24Q2 收入环比增长超预期,AI/ML 产品需求强劲。FY2024Q2 Coherent 实现收入 11.31 亿美元,高于指引中值,yoy-17.45%,qoq+7.41%;毛利润 3.51 亿美元,yoy-14.60%,qoq+14.33%。分部门看,激光器部门收入 3.54 亿美元, yoy-6.60%,qoq+5.36%;网络部门收入 5.24 亿美元,yoy-13.96%,qoq+10.78%; 材料部门收入 2.54 亿美元,yoy-33.51%,qoq+3.67%。受益于人工智能的蓬勃发展, AI/ML 相关数据收发器连续第三季获得强劲订单,800G 产品季度收入突破 1 亿美元,环比增长超 100%,800G 出货量持续强劲增长,FY2024 年公司预计超 过 50% 的数据通信收发器收入将来自人工智能相关应用,2025 年向 1.6T 产品 商业化发展前进以顺应 AI 发展,公司数据通信收发器龙头地位稳定。
Arista:云、数据中心业务发展迅猛。 Arista 公司季度营收向好。2023Q4 Arista 公司营收 15.4 亿美元,环比增长 2.1%, 同比增长 20.8%。GAAP 毛利率为 64.9%,环比提升 2.5pcts,同比提升 4.6pcts。 GAAP 净收入为 6.1 亿美元,同比提升 43.7%。分产品来看,云、人工智能和数据 中心产品组成的核心业务占营收 65%,公司交换机产品占 100、200 和 400G 端口 交换领域 40%以上的份额,位居第一,预计 400G 和 800G 比特以太网将成为 AI 后 端 GPU 集群的重要试点,公司作为交换机龙头,有望深度受益于 AI 驱动下,数 据中心以太网交换机市场的增长,实现营收进一步上升。
云、AI 和数据中心核心业务发展势头迅猛。Arista 在 2023 年的核心业务由云、 Al 和数据中心产品组成,建立在高度差异化的 Arista 可扩展操作软件系统堆栈 上,部署了 10G、25G、100G、200G 和 400G 的速度。Arista 云网络产品提供了节 能、高可用的区域,而不会增加冗余成本,因为数据中心对前端、后端存储和计算集群的带宽容量和网络速度都有很高需求。Arista 预计 400 和 800 千兆以太 网将成为 Al 后端 GPU 集群的重要试点,预计 2025 年实现 Al 网络收入至少 7.5 亿美元。
4 国产算力把握机遇进展迅速
全球 AI 产业快速发展背景下,算力芯片重要性日益凸显,英伟达等行业巨头公 司持续进行新品迭代,国产厂商同样把握机遇快速发展。我们梳理了英伟达及部 分国内主流 AI 芯片厂商产品参数,从产品性能来看,尽管国内厂商由于起步较 晚,产品性能整体落后于英伟达当前主流料号,但我们也看到如华为昇腾 910B 等 产品性能已可比肩英伟达 A100 的参数性能。我们看好随着国内厂商产品持续迭 代,国内 AI 芯片与海外的差距将逐步缩小。
1)华为昇腾:目前昇腾产品线共有两个系列产品:昇腾 310 和昇腾 910,其中昇 腾 910 是基于自研华为达芬奇架构 3D Cube 技术,在算力方面完全达到设计规 格,半精度(FP16)算力 320 TFLOPS,整数精度(INT8)算力 640 TOPS,功耗 310W。同时根据科大讯飞公告,目前昇腾 910B 能力已经基本做到可对标英伟达 A100。
昇腾 AI 平台:昇腾全栈 AI 软硬件平台可以分为硬件层、架构层、框架层、应用 层,其中硬件层涵盖开发者套件、加速模块、加速卡等产品;架构层核心为 CANN 异构计算架构;框架层则以昇思 MindSpore 为核心。
昇腾赋能计算中心。在建设计算中心方面,昇腾 AI 提供了从底层硬件到顶层应 用使能的人工智能全栈能力,以“1 中心+4 平台”赋能产业发展。在硬件层面主 要由 Atlas 900 AI 集群构成,其涵盖数千颗昇腾 910 处理器,总算力最大可拓 展至 3.2 EFLOPS。
2)燧原科技:燧原科技成立于 2018 年 3 月,专注于 AI 云端算力产品,涵盖芯 片、板卡、智算一体机、液冷算力集群以及配套的软件系统。2019 年 12 月,公 司成功发布第一代训练产品“云燧 T10”;2020 年 12 月,公司发布第一代推理 产品“云燧 i10”;2021 年 7 月,公司发布第二代训练产品“云燧 T20/T21”, 并于同年的 12 月发布第二代推理产品“云燧 i20”。 云燧 T20 和 i20 均基于邃思 2.0 打造,邃思 2.0 是同期国内最大的 AI 计算芯片, 采用日月光 2.5D 封装,在国内率先支持 TF32 精度,单精度张量 TF32 算力可达 160TFLOPS。同时,邃思 2.0 也是国内同期首个支持 HBM2E 的产品,最高容量达 64GB,传输速率达 1.8TB/s。
燧原科技产品历经成熟商业化打磨。根据燧原科技,公司的芯片在出货后就已应 用于腾讯不同的业务部门、产品线上。同时,燧原科技还联合之江实验室,共同 构建了超千卡规模的 AI 液冷集群。2023 年 10 月 25 日,弘信电子向燧原科技下 发 9152 片芯片采购订单,计划于 2023 年底前完成全部芯片的交付,快速形成国 产算力落地。
3)景嘉微:景嘉微是国内首家成功研制国产 GPU 芯片并实施大规模工程应用的 公司。景嘉微掌握了一系列关键技术,包括芯片底层逻辑/物理设计、超大规模电 路集成验证、模拟接口设计、GPU 驱动程序设计等。在 GPU 体系结构、图形绘制 高效处理算法、高速浮点运算器设计、可复用模块设计、快速大容量存储器接口 设计、低功耗设计等方面拥有丰富的技术积累。景嘉微先后成功研制出具有自主 知识产权的高性能 GPU 芯片,如 JM5 系列、JM7 系列、JM9 系列等,为国内 GPU 技 术的突破和发展做出了杰出的贡献。
4)寒武纪:成立于 2016 年,提供云边端一体、软硬件协同、训练推理融合、具 备统一生态的系列化智能芯片产品和平台化基础系统软件。根据寒武纪官网,目 前寒武纪具有智能加速卡、智能加速系统、智能边缘计算模组、终端智能处理器 IP、软件开发平台共 5 大业务。其中公司智能加速卡思元 370 系列采用 7nm 制程, 使用 chiplet 技术,集成 390 亿个晶体管,最大算力高达 256TOPS(INT8)。
5)沐曦集成电路:成立于 2020 年 9 月,其核心成员平均拥有近 20 年的高性能 GPU 产品端到端研发经验,并曾主导开发和量产了多款世界主流的高性能 GPU 产 品。沐曦推出了曦思 N 系列 GPU 产品,专为 AI 推理而设计;曦云 C 系列 GPU 产 品,用于千亿参数的 AI 大模型训练和通用计算;以及曦彩 G 系列 GPU 产品,用 于图形渲染,以满足数据中心对于高能效和高通用性算力需求的要求。沐曦的产 品采用完全自主研发的 GPU IP,拥有完全自主知识产权的指令集和架构,并配备 与主流 GPU 生态兼容的完整软件栈,具备高能效和高通用性的天然优势。根据沐 曦官微,2023 年 6 月,旗下产品曦云 C500 仅用 5 小时便完成功能测试。
6)壁仞科技:成立于 2019 年,专注于开发独创的通用计算体系,并构建高效的 软硬件平台,同时提供智能计算领域的一体化解决方案。公司的发展路径首先聚 焦于云端通用智能计算,并逐步超越现有解决方案,在人工智能训练、推理和图形渲染等多个领域实现国产高端通用智能计算芯片的突破。在 2022 年,壁仞科 技推出了旗下的首款旗舰 GPU 芯片:BR100。该芯片采用了 7nm 制程,并支持 PCIe 5.0 接口。根据壁仞科技发布会的介绍,BR100 的 16 位浮点算力超过 1000T,8 位 定点算力超过 2000T,单芯片的峰值算力达到了 PFLOPS 级别。
7)摩尔线程:成立于 2020 年 10 月,专注于研发设计全功能 GPU 芯片及相关产 品。他们的产品支持多种组合工作负载,包括 3D 图形渲染、AI 训练与推理加速、 超高清视频编解码、物理仿真与科学计算等。摩尔线程注重算力与算效的平衡, 旨在为中国科技生态合作伙伴提供强大的计算加速能力,并在数字经济的多个领 域广泛发挥作用。根据摩尔线程官网的信息,旗下的 MTT S3000 产品具有 GPU 核 心频率 1.9GHz,32GB 容量的 DDR6 显存,支持 FP32、FP16、INT8 等多种计算精 度同时其 FP32 算力达到了 15.2TFLOPS。
产品迭代与国产化需求催生优质先进算力企业。通过梳理 2023 年 IC 先进算力公 司公告及业务进展近况我们发现:目前国内 IC 先进算力公司在产品迭代、产能 建设、斩获大额订单进展迅猛,其中产品迭代以及产能建设主要集中在算力核心 硬件以及 AI 相关芯片中,同时从部分公司目前斩获的订单来看,主要集中在国 产化算力相关项目中。我们认为,核心公司业务进展近况进一步印证了现阶段板 块发展两个核心要素:AI 方向的持续产品迭代、庞大的国产化算力需求。
5 HBM4 实现逻辑存储垂直堆叠,混合键合助力带宽提升
高性能计算功耗问题突出。最开始数据中心通过提高 CPU、GPU 的性能进而提高 算力,但处理器与存储器的工艺、封装、需求不同,导致二者之间的性能差距逐 步加大。英伟达创始人黄仁勋曾表示计算性能扩展的最大弱点就是内存带宽。以 谷歌第一代 TPU 为例,其理论算力值为 90TFOPS,但最差真实值仅 1/9,即 10TFOPS 算力,因为其相应内存带宽仅 34GB/s。此外,在传统架构下,数据从内存到计算 单元的传输功耗是计算本身能耗的约200倍,仅用于计算的能耗和时间占比很低, 数据在内存与处理器之间的频繁迁移带来严重的功耗问题。
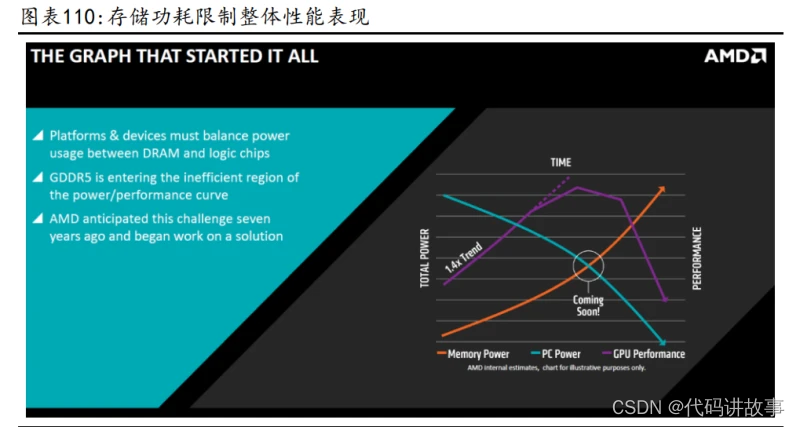
HBM 打破内存带宽及功耗瓶颈。不同于传统的内存与处理器基于 PCB 互联的形 式,HBM 是基于与处理器相同的“Interposer”中介层互联实现近存计算,从而 显著减少数据传输时间,节省布线空间。而基于 TSV 工艺的 DRAM 堆叠技术则显 著提升了带宽,并降低功耗和封装尺寸。根据 SAMSUNG,3D TSV 工艺较传统 POP 封装形式节省了 35%的封装尺寸,降低了 50%的功耗,并且带来了 8 倍带宽提升。
HBM 正成为 HPC 军备竞赛的核心。英伟达早在 2019 年便已推出针对数据中心和 HPC 场景的专业级 GPU Tesla P100,当时号称“地表最强”的并行计算处理器, DGX-1 服务器就是基于单机 8 卡 Tesla P100 GPU 互连构成。得益于采用搭载 16GB 的 HBM2 内存,Tesla P100 带宽达到 720GB/s,而同一时间推出的同样基于 Pascal 架构的 GTX 1080 则使用 GDDR5X 内存,带宽为 320GB/s。此后英伟达数据中心加 速计算 GPU V100、A100、H100 均搭载 HBM 显存。最新的 H100 GPU 搭载 HBM3 内 存,容量 80Gb,带宽超 3Tb/s,为上一代基于 HBM2 内存 A100 GPU 的两倍。而作 为加速计算领域追赶者的 AMD 对于 HBM 的使用更为激进,其最新发布的 MI300X GPU 搭载容量高达 192GB 的 HBM3 显存,为 H100 的 2.4 倍,其内存带宽达 5.2TB/s, 为 H100 的 1.6 倍,HBM 正成为 HPC 军备竞赛的核心。
高性能计算驱动 HBM 加速迭代,HBM3 升级,HBM3E 已在路上。高性能计算驱动数 据中心 HBM 需求井喷,HBM 升级速度近年明显加快。SK 海力士于 2021 年 10 月宣布成功开发出容量为 16GB 的 HBM3 DRAM,2022 年 6 月初即宣布量产。仅过去 10 个月,SK 海力士官网再次宣布已成功开发出垂直堆叠 12 个颗 DRAM 芯片、容量高 达 24GB 的 HBM3 新品,并正在接受客户公司的性能验证。与此同时,海力士第五 代 HBM 内存 HBM3E 已在路上。英伟达于 2023 年 8 月 8 日发布的最新 GH200 预计 将搭载 HBM3E 内存,并将于 2024 年 Q2 出货。根据公开信息披露,该 HBM3E 芯片 单 pin 最大带宽达 8Gb/s,单栈最大带宽达 1Tb/s,较上一代 HBM3 提升 25%。
HBM 通过 TSV 技术垂直堆叠多个 DRAM,与 GPU 通过中介层互联封装在一起,已成 为数据中心新一代内存解决方案。HBM 制造商主要包括 SK 海力士、三星和美光, XPU 由英伟达、AMD、博通等设计后交由台积电、三星、英特尔等 Foundry 厂商生 产,再通过 2.5D 封装技术如 CoWoS 进行封装整合。
5.1 SK 海力士:携手台积电合作开发 HBM4,资本开支回升
SK 海力士 23Q4 单季收入同环比改善明显,DRAM/NAND 产品 ASP 环比提升。SK 海 力士2023Q4实现收入11.3万亿韩元,YoY+47%,QoQ+25%;毛利率20%,QoQ+17pcts; 净利率-12%,QoQ+12pcts。分产品看,DRAM 收入占比 65%,ASP QoQ+18-19%, NAND 收入占比 27%,ASP QoQ+40%。DRAM 方面,公司聚焦扩大销售 HBM 和高密度 DDR5 等高附加值产品以提高盈利能力,NAND 方面,公司减少了低毛利产品的销 售,扩大了移动存储和 eSSD 产品的销售。2023 年 DDR5 销量同比增长了 4 倍以 上,HBM3 销量同比增长了 5 倍以上,受供需情况改善及下游 AI 产品复苏驱动, 23Q4 营收同环比改善。
展望 2024 年,AI 应用驱动存储需求上升,供需格局进一步优化。PC 端受换机及 Windows 系统升级,叠加 AI PC 后续大规模量产,PC 出货量有望以中个位数百分 比增长,且 AI PC DRAM 容量比普通 PC 高一倍以上,将长期推动 PC 出货量和容 量增长。智能手机方面,随着搭载 AI 应用的智能手机的普及与消费者购买力的 恢复,预计高密度与性能存储产品需求强劲。服务器方面,AI 厂商 Capex 的恢复 及推理模型的持续演进,AI 服务器出货量持续上升,AI 投资 24 年有望复苏。综 上,SK 海力士预计 2024 年 DRAM/NAND 位同比增长有望达 15%-18%,DRAM 库存于 24H1 达到正常水平,NAND 于 24H2 实现供需格局优化。
HBM3E 已实现量产,资本开支同比回升。海力士预计 2025 年 HBM 市场将增长 40%, 预计 HBM 长期需求增长率超 60%,立足需求可见性,海力士已量产 2024 年需求有 望大幅增长的 HBM3E 产品,预计 2024 年 TSV 同比产能翻倍,同时拓展 AI 服务器 模组如 MCR DIMM 产品。2023 年公司资本开支同比下降 50%以上,2024 年资本开 支同比回升,重点关注 HBM 等先进工艺的高需求高附加值产品,保障产品扩产及 研发动作顺利进行,优先考虑扩大先进工艺产品量产及 TSV 与基础设施建设。 SK 海力士携手台积电,合作开发 HBM4。SK 海力士制定“一个团队战略”,其重要 组成部分是与台积电建立 AI 芯片联盟,合作开发第六代 HBM 芯片(HBM4),HBM4 拟升级到更宽的 2048 位内存接口,以解决 1024 位内存接口“宽但慢”的问题, 需要台积电先进封装技术验证HBM4的布局和速度,预计台积电将负责封装工艺, 以提升产品兼容性。根据目前规划及进展,海力士将于 2026 年实现 HBM4 量产。 同时 SK 海力士计划在美国印第安纳州建立 HBM 内存封装工厂,届时有望与台积 电亚利桑那州工厂合作,助力英伟达实现在美国生产 GPU。
5.2 三星电子:DRAM 业务转盈,TSV 产能加速扩张
存储业务复苏,三星电子 23Q4 DRAM 业务转盈。三星电子 23Q4 合计营收 67.8 万 亿韩元,环比增长 0.6%,同比下降 3.8%;营业利润为 2.8 万亿韩元,同比-34.6%, 环比+16.7%。单季度毛利率 32%,同比+1.0pct,环比+1.1pcts;营业利润率 4.2%, 同比-1.9pcts,环比+0.6pct。Q4 存储业务营收为 15.71 万亿韩元,环比+49%, 同比+29%。四季度期间,三星重点扩大 HBM、DDR5、UFS 4.0 等高附加值产品销 售,推动 DRAM 和 NAND 的库存加速正常化,DRAM 业务在 23Q4 恢复盈利。 高端产品供给有限,客户端需求持续强劲拉动内存市场进一步复苏。服务器长期 以来相对低迷需求已出现复苏迹象,2023 年因预算紧缩导致的服务器更换推迟需 求恢复。AI 驱动,商用 PC 和旗舰智能手机单机价值增长,且产品更换周期临近, 换货需求促进出货量上升。产品 ASP 上涨及库存情况改善下,预计公司 24Q1 内 存业务恢复盈利,其中 DRAM 库存于 24Q2 回归正常,NAND 于 24H1 实现正常化, 2024 年内存业务持续复苏。
扩大 TSV 产量,加速推出 HBM 产品。三星通过推出业界首个基于 1Bnm 的行业最 高容量 32G DDR5,增强公司在高密度 DDR5 市场的领导地位。生成式 AI 的普及拉 动市场对先进 HBM 性能和容量需求的不断增长,公司计划利用 TSV 产能的竞争 力,进一步扩产以巩固公司 HBM 的竞争力。此外,公司将适时推出新一代 HBM3E, 并于 24H2 加速向 3E12i 过渡。
5.3 美光:HBM3E 验证进入尾声,有望于 2024 年初量产
DRAM/NAND 价格走强,AI 及数据中心业务驱动美光业绩增长。美光 FY24Q1 收入 47.3 亿美元,QoQ+18%,YoY+16%;NON-GAAP 毛利率 1%,QoQ+10pcts,YoY-22pcts, 业绩增长受 DRAM/NAND 价格回升影响,预计伴随搭载 AI 的智能手机、PC 等产品 的大规模生产,终端存储库存进一步调整,2024 年 DRAM/NAND 价格将持续走强, 供需结构进一步健康化。公司利用业界领先的数据中心解决方案组合来把握人工 智能激增带来的机遇,其中包括 HBM3E、D5、多种类型的高容量服务器内存模块、 LPDRAM 和数据中心 SSD,其中 HBM3E 目前处于在 NVIDIA 下一代 Grace Hopper GH200 和 H200 平台验证的最后阶段,有望在 2024 年初量产,预计 2024 年 Capex 位于 75-80 亿美金,以支撑 HBM3E 产量提升。
6 SK 海力士先进封装持续发力,助力 HBM 性能领先
SK 海力士引领 HBM 市场,HBM4 将于 2026 年问世。SK 海力士于 2015 年推出首代 HBM,对应 2GB 的容量和 1.0Gbps 的带宽;于 2022 年推出 HBM3,是全球第一家且 是唯一一家实现量产的公司,可实现 12 层的堆叠和 5.6Gbps 的带宽;2024 年预 计将量产 HBM3E,容量、带宽、散热性能和能耗进一步优化。下一代 HBM4 将搭载 混合键合技术,并与 Foundry 厂进行合作,预计将于 2026 年问世。
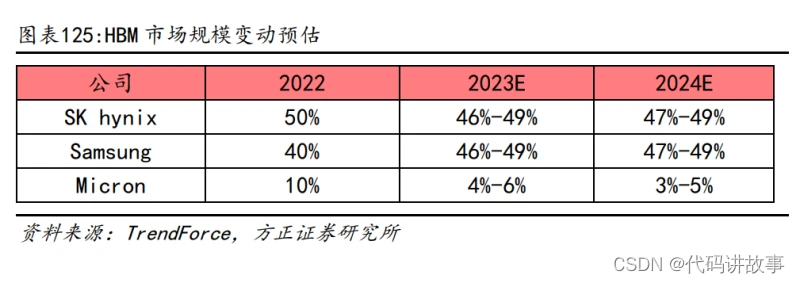
HBM 市场格局:三分天下,海力士领先。从市场格局来看,HBM 的市场份额仍由 三大家所主导。根据 TrendForce,2022 年全年 SK 海力士占据了 HBM 全球市场规 模的 50%。其次是三星,占 40%,美光占 10%。TrendForce 预测,2023 年海力士 和三星的 HBM 份额占比约为 46-49%,而美光的份额将下降至 4%-6%,并在 2024 年进一步压缩至 3%-5%。
SK 海力士深耕先进封装技术,HBM 性能领先。SK 海力士 HBM 产品的升级主要体 现在:更多层数 DRAM 的堆叠、更高的带宽以及更好的散热性能。SK 海力士引领 HBM 产品性能不断升级,HBM3/3E 的散热性能相较于 HBM2 实现了一倍的性能提升, 背后是公司精细的 DRAM 层间高度控制、热性能更好的塑封技术和凸点密度最大 化等先进封装技术的持续迭代。
取代 TC-NCF,MR-MUF 提高散热性能。传统的 HBM 芯片堆叠多数通过 TC-NCF(the thermo-compression bonding with non-conductive film,非导电膜的热压缩 键接)工艺完成,但受限于材料流动性以及 bump 数量限制,存在导热以及其他 工艺缺陷等问题。MR-MUF(Mass reflow bonding with molded underfill,批量 回流模制底部填充)是海力士的高端封装工艺,通过将芯片贴附在电路上,在堆 叠时,在芯片和芯片之间使用一种称为液态环氧树脂塑封(Liquid epoxy Molding Compound,LMC)的物质填充并粘贴。对比 NCF,MR-MUF 能有效提高导 热率,并改善工艺速度和良率。
MR-MUF 工艺的核心难点在于堆叠芯片过程中产生的热翘曲问题(LMC 与硅片之间 的热收缩差异导致),以及芯片中间部位的空隙难以填充。LMC 是 SK 海力士 HBM产品的核心材料,本身具备可中低温固化、低翘曲、模塑过程无粉尘、低吸水率 以及高可靠性等优点,通过大量的材料配方调试及热力学验证解决热收缩差异问 题。另一方面,公司通过改变 EMC 与芯片的初始对齐方式以及图案形状有效解决 了填充存在缝隙的问题。
SK 海力士亦考虑在内存产品中采用 FO-WLP,2.5D 扇出方案提供高性价比。通过 将两个 DRAM 器件并排放置,该方案不再使用基板和中介层,预计将显著缩小封 装尺寸和减薄封装厚度,从而堆叠更多的芯片。FO-WLP 也省略了 TSV 工艺,从而 大大降低成本。随着布线长度的减少,电气特性同样得到改善。SK 海力士预计将 FOWLP 方案用于图形或移动应用,与 HBM 方案相比,FO-WLP 的成本优势更大。
7 HBM4 或与处理器 3D 堆叠,混合键合、TSV、散热需求提升
据 Joongang.co.kr 报道,SK 海力士已开始招聘 CPU 和 GPU 等逻辑芯片设计人员, 或希望将高带宽内存 HBM4 直接堆叠在处理器上。KAIST 电气与电子系教授 Kim Jung-ho 表示这种存储器与处理器的直接堆叠会对散热带来挑战,如果散热问题 能够比目前晚两到三代得到解决,HBM 和 GPU 将能够在没有中介层的情况下进行 堆叠。我们认为。从结构上看这一方案的核心变化在于去掉目前 CoWoS-S 结构中 的硅 interposer(中介层),由目前的 GPU/CPU/ASIC 处理器与 HBM 在 xy 轴放置 的这种 2.5D 结构,向二者在 z 轴直接堆叠的 3D 结构升级。
从增量环节来看,我们认为: 1)混合键合 hybrid-bonding 设备用量提升:先进封装升级的一项核心指标就是 凸显尺寸/间距的不断缩小,目前的倒装技术回流焊技术最小可实现 40-50um 左 右的凸点间距,当凸点间距进一步缩小到 20um 时,目前部分龙头厂商采用 TCB 热 压键合设备解决应力与热循环方面的问题,当凸点间距达到 10um 甚至无凸点 (bumpless)的情况下,则需要用到混合键合设备。 2)TSV 工艺难度和工序提升:硅通孔技术(TSV)是通过在芯片和芯片之间、晶 圆和晶圆之间制作垂直导通,实现芯片之间互连的技术,通过垂直互联减小互联 长度、信号延迟,降低电容、电感,实现芯片间的低功耗、高速通讯。在集成度 提升的过程中,TSV 的密度、孔径的深宽比会进一步提高,从而带来 TSV 制造工 艺难度和工序数的提升。电镀填孔环节是 TSV 制造中难度较大的环节,TSV 填充 效果直接关系到后续器件的电学性能和可靠性,因此我们认为对相关的电镀设备、 电镀液材料都会带来更多的挑战和机遇。 3)散热需求提升:高性能算力芯片、高带宽内存的堆叠可能需要更复杂的方式解 决散热问题,由于新技术、新产品目前还没有明确方案细则,但是从逻辑上推演我们认为芯片层间材料 EMC(特种环氧树脂),以及芯片间(液冷/浸润)整体电 源管理方案(PMIC)具有潜在升级空间。
综上,我们看到未来随着封装集成度进一步提升,HPC 领域算力芯片由当前主流 的 2.5D 封装形式向 3D 升级是目前台积电、SK 海力士、三星等龙头半导体厂商积 极布局的方向。在节省中介层成本的情况下,对混合键合、TSV、散热等环节带来 更高要求,从而有望驱动相关环节供应链升级。 混合键合成为趋势,可实现 10um 以内的凸点间距。随着芯片制造节点不断缩小, 封装尺寸和凸点间距也需要相应缩小。目前主流倒装技术为回流焊,最小可实现 40-50um 左右的凸点间距,若进一步缩小凸点间距会带来翘曲和精度问题,回流 焊不再适用,而是转用热压键合(TCB)的方式。当凸点间距缩小至 10um 时,TCB 工艺中会产生金属间化合物,导致导电性能下滑。为了在高集成度(凸点间距 10um 以内)的芯片封装中解决这些问题,混合键合技术正在得到越来越多的青睐。
混合键合是一种永久键合工艺,其将介电键合(SiOx)与嵌入式金属(Cu)结合起来 形成互连,在业界被称为直接键合互连(DBI)。混合键合通过键合界面中的嵌入 式金属焊盘扩展了熔合键合,从而允许晶圆面对面连接。混合键合可分为芯片到 晶圆(Die to Wafer,D2W)以及晶圆到晶圆(Wafer to Wafer,W2W)的键合。 目前来看 W2W 量产进度更快(良率更高),但上下晶圆尺寸和节点要求一致,适 用于高产量的小芯片。而 D2W 更为灵活,在芯片尺寸较大时反而具有成本效益。
混合键合工艺流程可分为焊盘形成、键合和键合后工艺三个部分。键合后工艺包 括减薄、划片、塑封等,与其他封装的工艺较为类似。而焊盘形成相关工艺则与 前道工艺较为类似,设备供应商主要为应用材料、北方华创等平台型公司。键合 过程相较于倒装等技术对精度的要求更高,除了 BESI、ASMPT、Shibaura 等后道 设备供应商以外,TEL、EVG 等公司也有相关设备可以提供。
混合键合推动键合步骤和设备单价增加。以 AMD 的 EPYC 为例,从 2017 年的第一 代霄龙处理器到 2023 年最新发布的第四代产品,生产过程中所需键合步骤从 4 次提升到了超 50 次。键合技术从倒装迭代至混合键合+倒装,对键合设备也提出 了更高的要求,Besi 相应开发了 8800 Ultra 以提供混合键合的键合功能,相比 原来的倒装键合机单价提升了 3-5 倍。
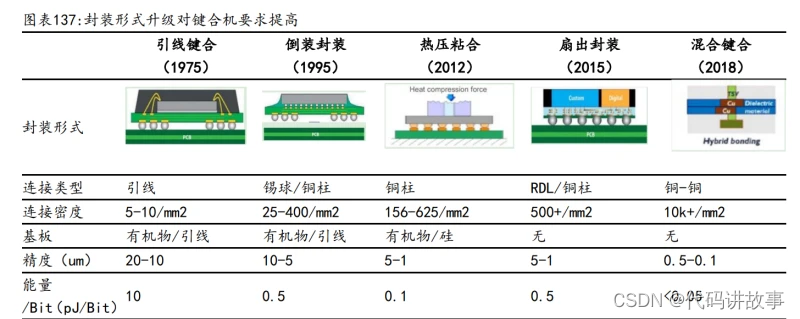
封装形式演变下,键合机需要更高的精度和更精细的能量控制。封装技术经历了 引线框架到倒装(FC)、热压粘合(TCB)、扇出封装(Fan-out)、混合封装(Hybrid Bonding)的演变,以集成更多的 I/O,实现更薄厚度,从而承载更多复杂的芯片 功能和适应更轻薄的移动设备。在最新的混合键合技术下,键合密度从 5-10/mm2提升到 10k+/mm2,精度从 20-10um 提升至 0.5-0.1um,与此同时,能量/Bit 则进 一步缩小至 0.05pJ/Bit,键合设备的控制精度和工作效率都需达到新高度。
混合键合拉动键合设备需求,存储应用爆发值得期待。根据华卓精科招股书,1 万片晶圆/月的产能需要配置 4-5 台晶圆级键合设备。Besi 预计 2024 年混合键 合系统累计需求达 100 套,预计 2025 年后随着混合键合技术在存储中的应用, 2026 年累计需求将超 200 套(保守口径)。


