
- 1Faster R-CNN 较Fast R-CNN的改进之处与第一阶段设计细节_faster r-cnn 较 fast r-cnn改进
- 2数据结构(C语言版)严蔚敏->二叉树(链式存储结构)的构造及其几种遍历方式(先序、中序、后序、层次)和线索二叉树_构造先(根)序线索二叉树构造中(根)序线索二叉树构造后(根)序线索二叉树
- 3关于鸿蒙 DevEco Studio 使用报错 The Huawei Lite Simulator supports only Lite projects_deveco studio 虚拟机打不开
- 4测试岗面试必背的185道技术题,我看还有谁不知道!_测试工程师面试必背题
- 5ChatGPT助力AI办公
- 6Kali Linux虚拟机无法连网_kali虚拟机无法联网
- 7大模型学习笔记(一):部署ChatGLM模型以及stable-diffusion模型
- 8android实战项目开发八---当前的项目为java工程,如何引入第三方项目kotlin工程_android java项目引入kotlin
- 9mac使用命令行连接无线网(切换WIFI)_mac命令行连接wifi
- 10SVN管理工具Cornerstone之:代码合并_connerstone 代码合并
基于pyqt的YOLOv5目标训练和检测界面实现(含图片爬虫下载、数据集标注、数据一键配置、训练、图片、视频和摄像头实时检测)_yolov5测试视频流 python
赞
踩
目录
近期学习目标检测很火的YOLOv5框架,将源码进行封装,并利用pyqt实现了训练+检测2个部分的界面功能。训练部分,从图片爬虫下载、数据标注、数据集配置到最后的训练;检测部分,从检测参数设置(支持实时设置置信度和IOU等)、数据选择(支持图片、视频和多种摄像头)到结果显示。全部实现界面开发和多线程调度处理。
下面,重点从开发环境配置、目标的训练、目标的检测、程序发布4个方面进行分享,不对的地方关注、私聊,源码将整理后上传,供大家下载。
一、开发环境配置
操作系统Win10 64位 内存16G,显卡N卡 GTX1060 6G显存。开发环境:pycharm 2021版;pytorch版本为2.1.
关于anaconda、cuda、pytorch等安装,网上资料很多。windows系统经常踩坑(Linux系统就不会有这么多困扰了,所以今早变换赛道。),这里简要分享下笔者遇到的几个问题:
(一)显卡驱动安装
进入NVIDIA官网,按照自己电脑的显卡型号、操作系统版本等,查找驱动版本,下载studio稳定版本,我安装的是546.01版本。

(二)cuda安装
安装cuda tool,需要根据自己显卡驱动版本进行查询,网上能够查到。

下面知乎文章可以参考下:
笔者安装的cuda版本为12.1,最后通过nvcc -V验证是否安装成功。
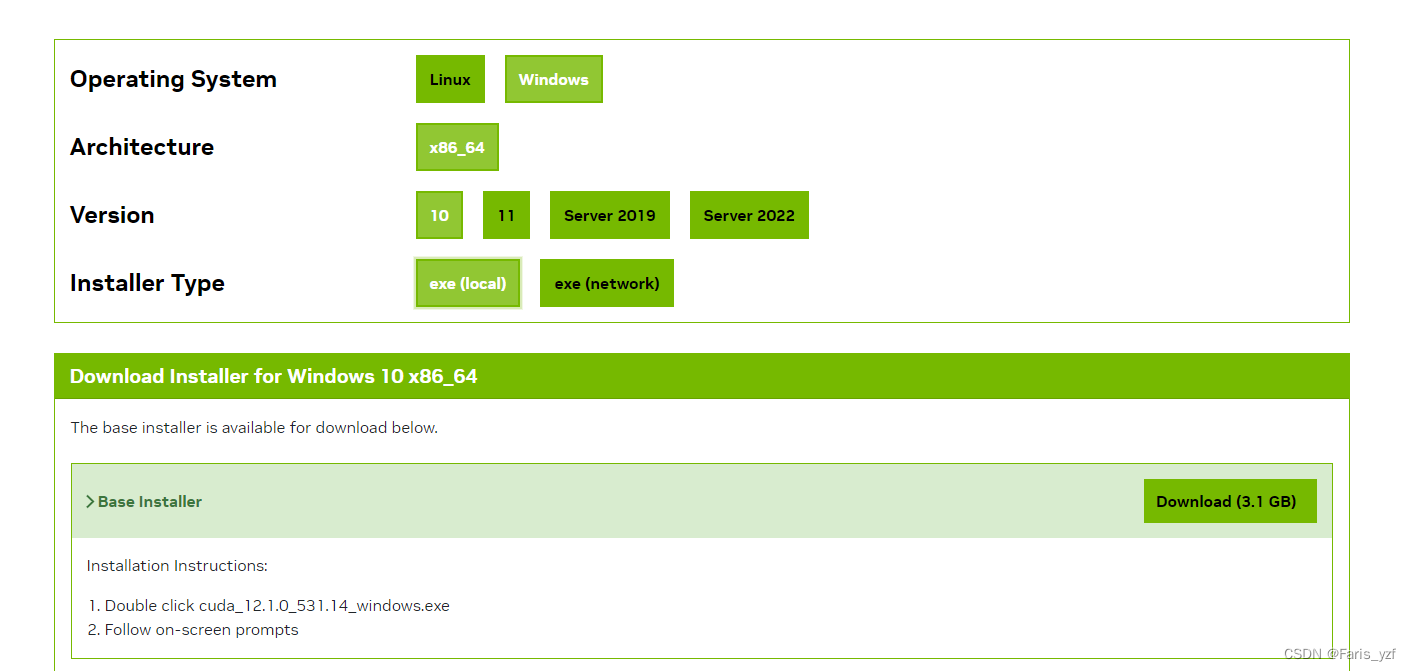
(三)cudnn安装
安装cudnn,需要登录英伟达并注册一个账号,运行bandwidthTest.exe测试是否安装成功。
(四)pytorch安装
pytorch安装需要使用anaconda,创建虚拟环境,实现版本可控。虚拟环境创建、激活、删除等操作这里不再赘述。关于pytorch版本,跟上述软件版本有关系,通过pytorch官网可查,官网下载比较慢,会导致pytorch安装失败,这里介绍一种先下载whl包,再安装的方法,亲测有效,当然也可以找到相应的torchaudio和torchvision版本。

通过https://download.pytorch.org/whl/torch_stable.html![]() https://download.pytorch.org/whl/torch_stable.html,查找需要安装的pytorch等版本(笔者安装的是2.1版本),直接在conda里面安装。Cd到下载的位置,pip install 文件名即可安装相应的依赖项。同样需要检验下是否安装成功:
https://download.pytorch.org/whl/torch_stable.html,查找需要安装的pytorch等版本(笔者安装的是2.1版本),直接在conda里面安装。Cd到下载的位置,pip install 文件名即可安装相应的依赖项。同样需要检验下是否安装成功:
输入 :python
输入 :import torch
输入 torch.__version__
会显示安装版本。(在激活的虚拟环境里面测试)
(五)QT designer安装
界面设计需要使用QT,下载安装designer即可。不再赘述。
(六)pycharm开发环境配置
一是配置Python解释器。打开pycharm,在设置里面,配置需要的Python解释器。
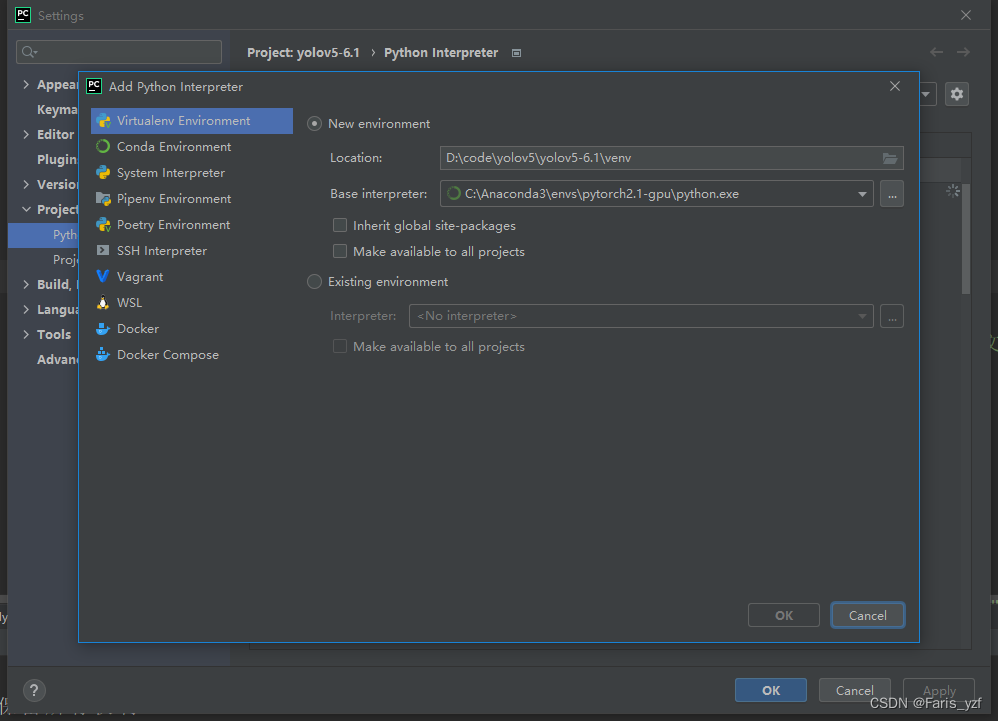
自动检测到环境下安装好的各种包。

二是配置QT工具。主要是QT designer和pyuic,前者是在pycharm里可以打开qt designer界面工具,制作控件,后者是将qt的ui界面文件编译成py文件,实现Python代码调动。网上资料很多。
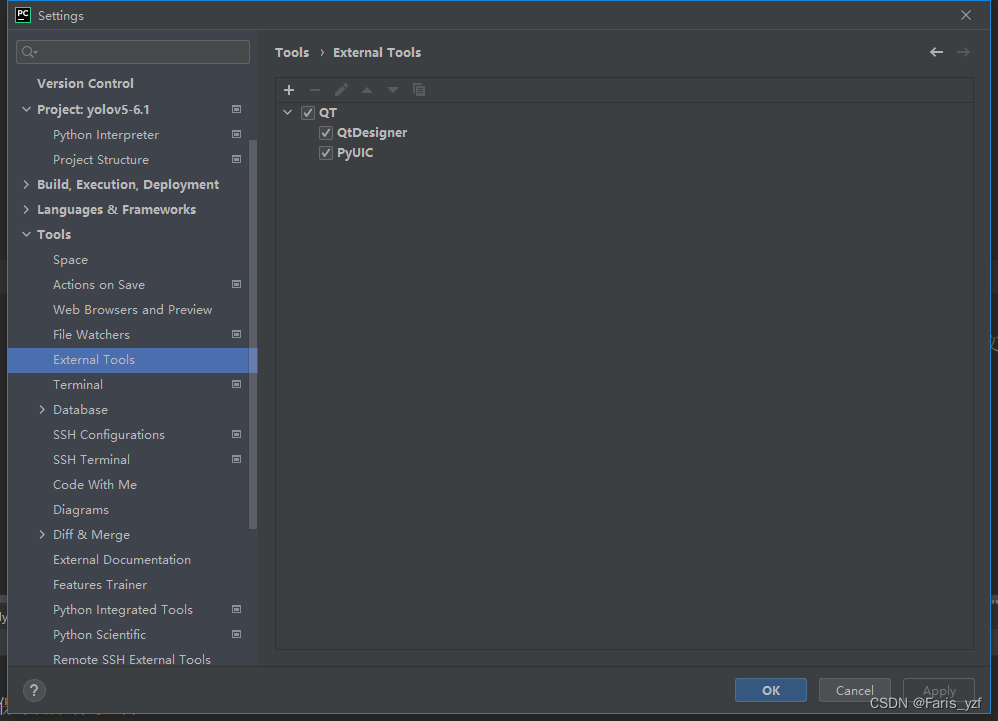
三是YOLO源代码下载。笔者用的是6.1版本,可以去GitHub上下载,如果不稳定,可以在这里下载。
二、目标训练部分
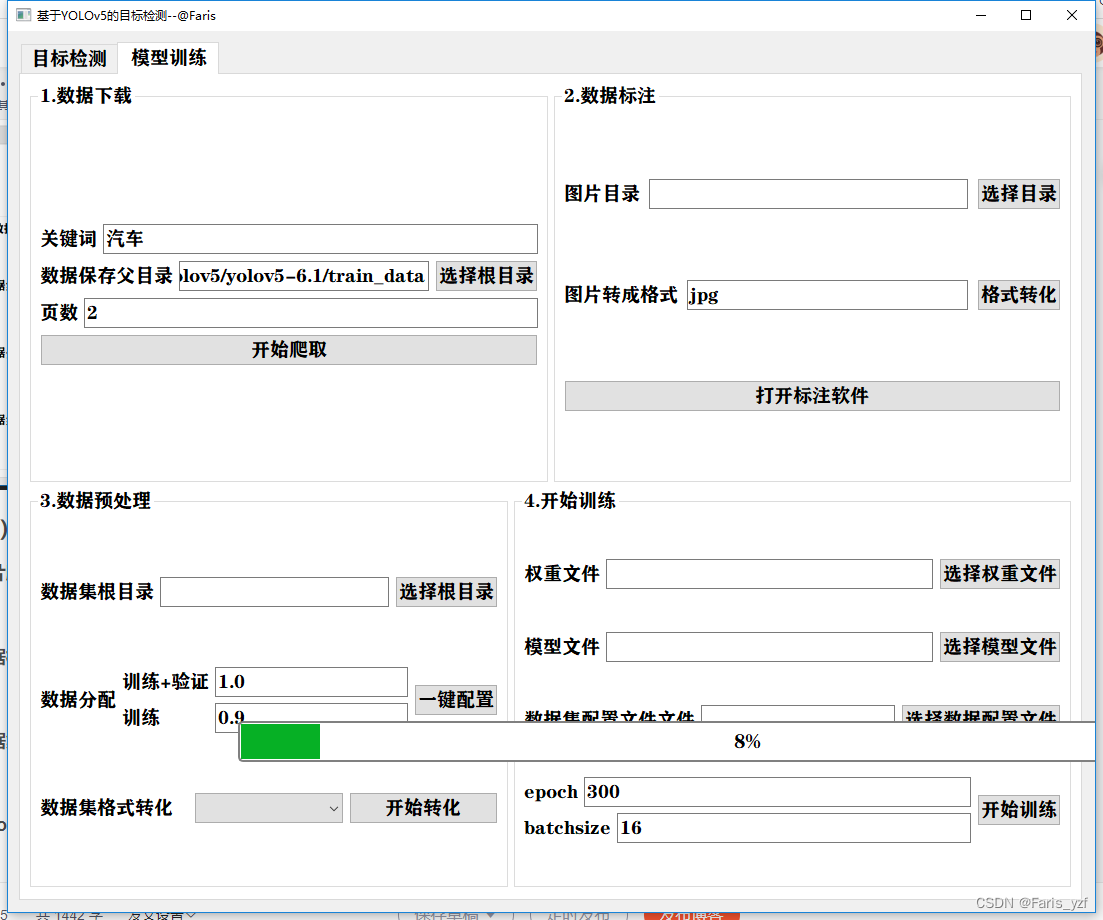
(一)总体效果
训练部分从数据下载、标注、配置到开始训练,实现一站式界面集成开发。涉及爬虫、多线程开发、进度条显示以及文本、图像读写操作等。效果如下:
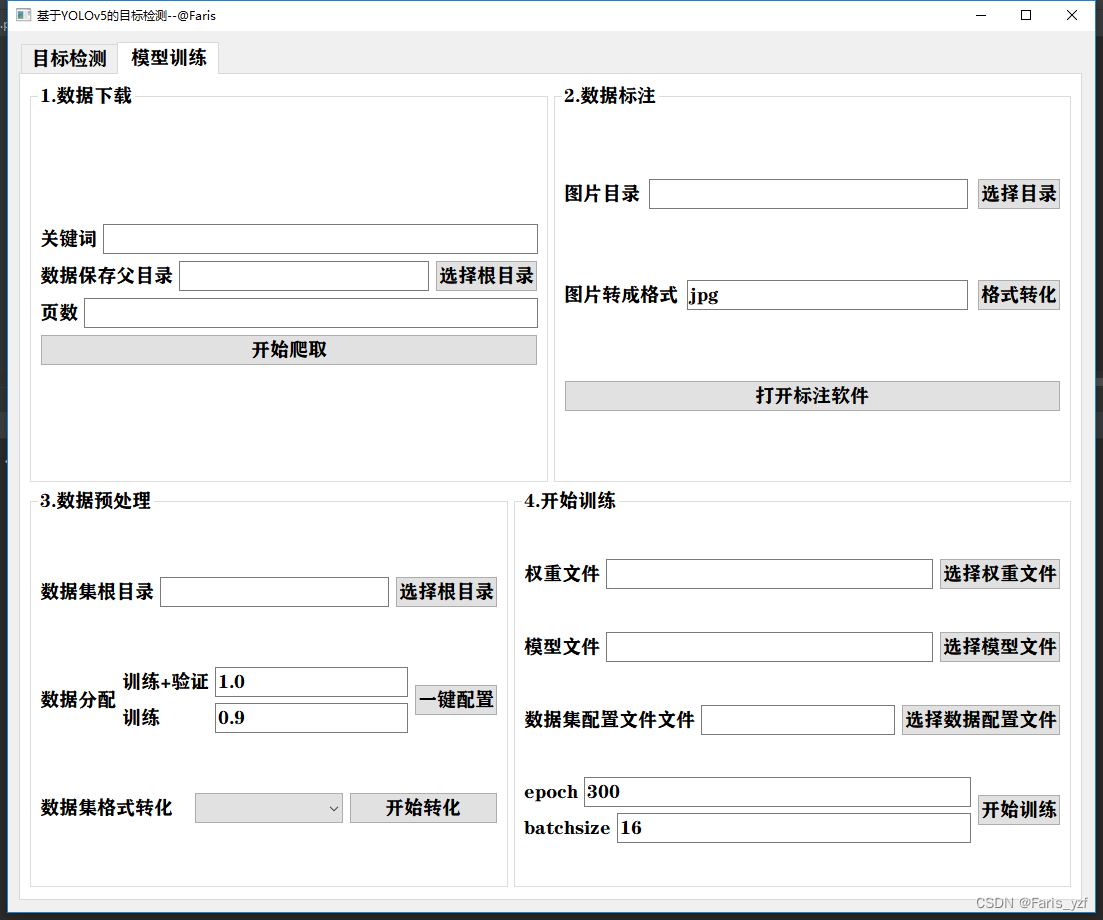
(二)总体架构

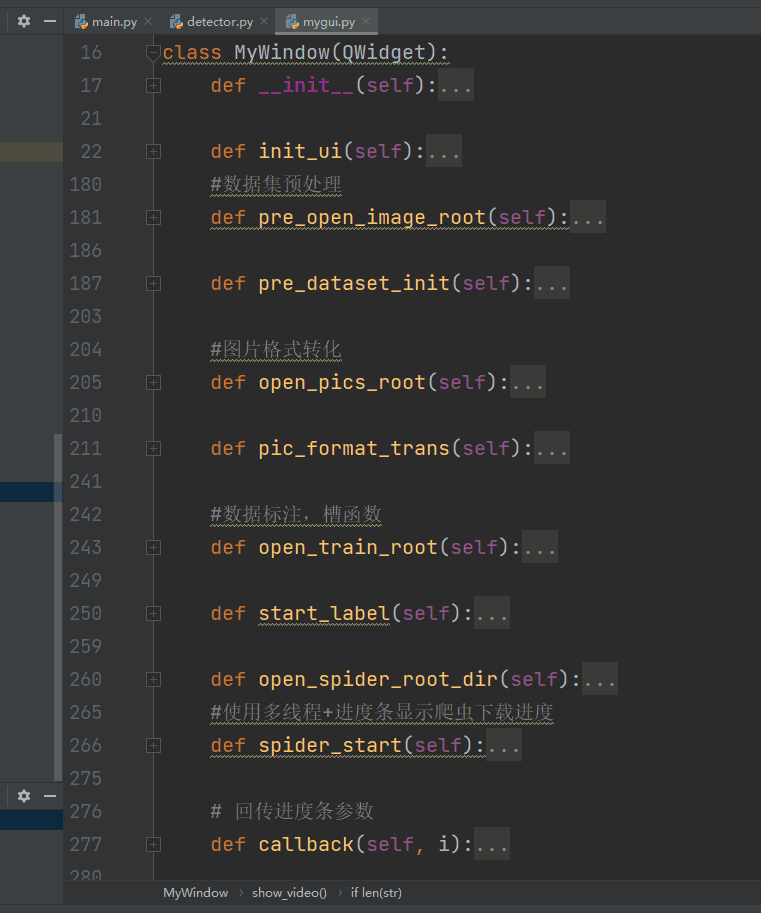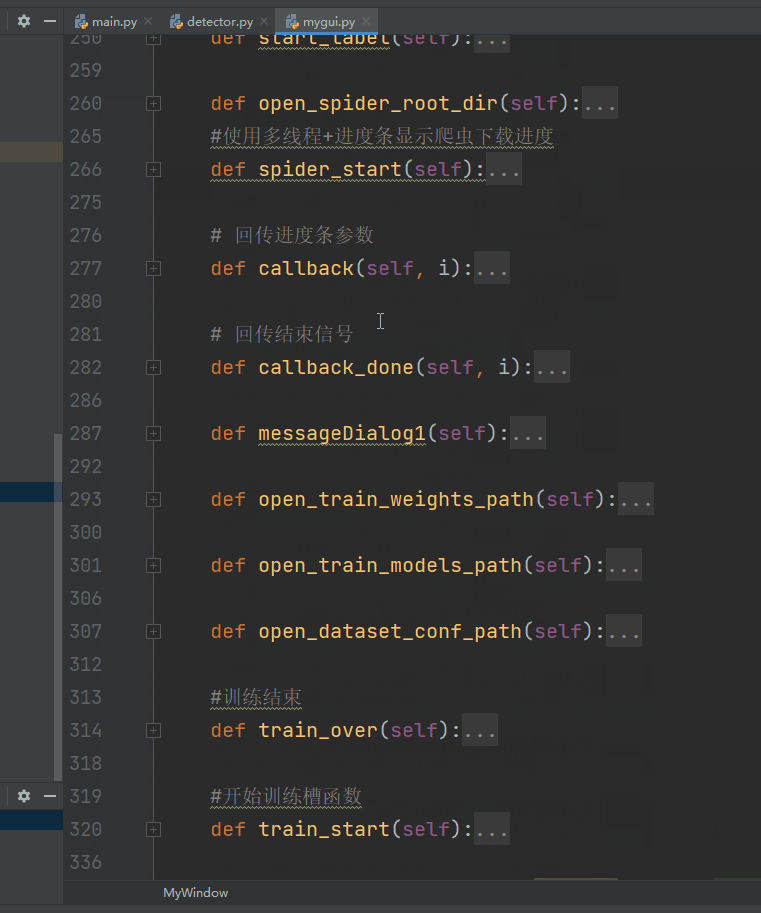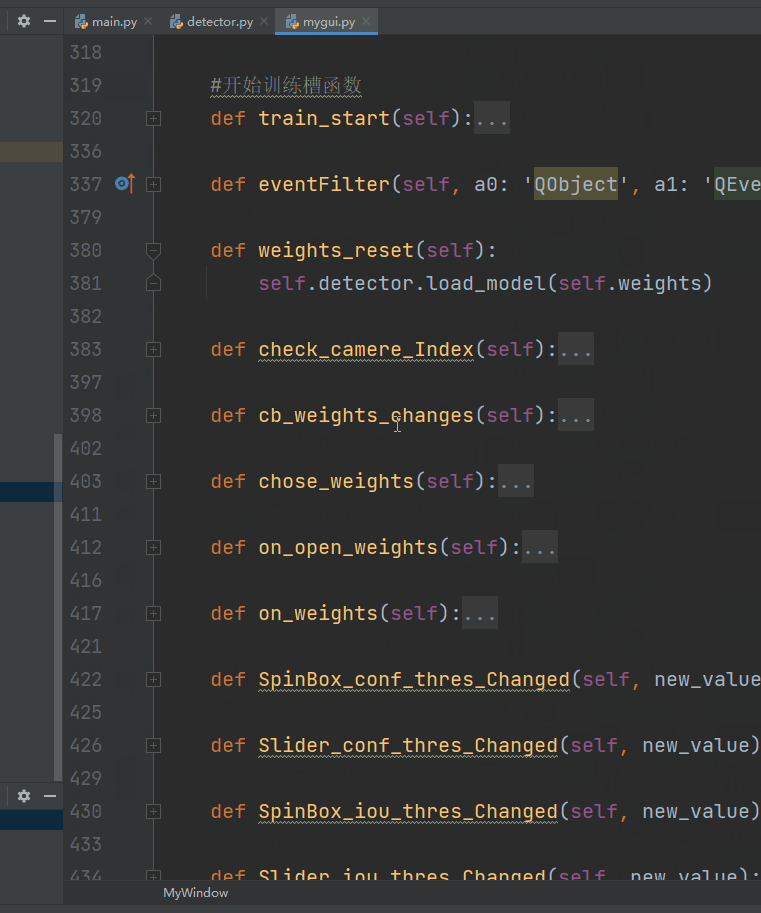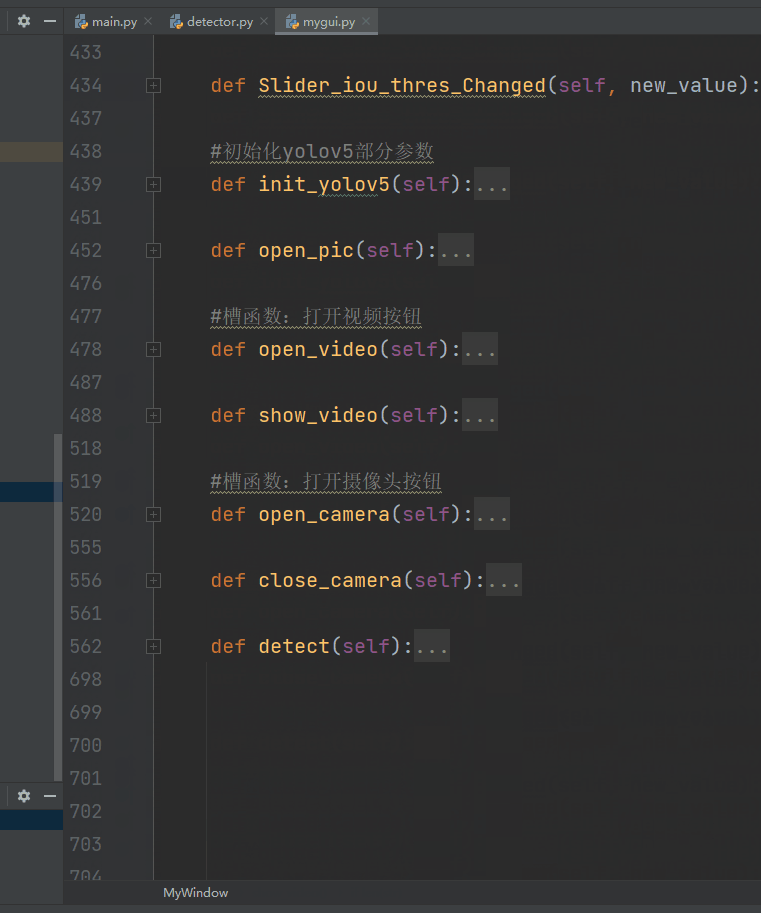
1.mygui.py
通过
self.ui = uic.loadUi("./ui/my_yolov5.ui",self)
进行动态加载ui文件,这里建议使用pyuic工具进行自动生成py文件,笔者全部自己定义控件对象和绑定信号和槽,工作量很大,只能说很大。。。。
2.trainer.py
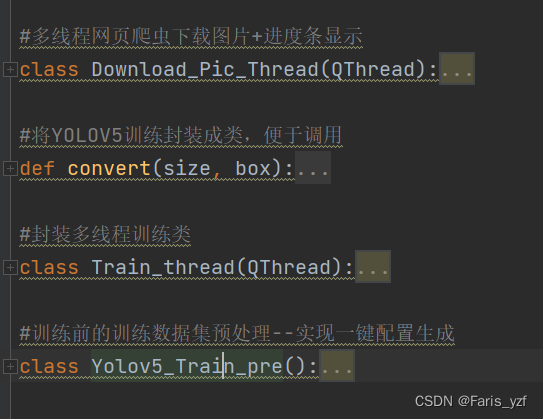
3. detector.py
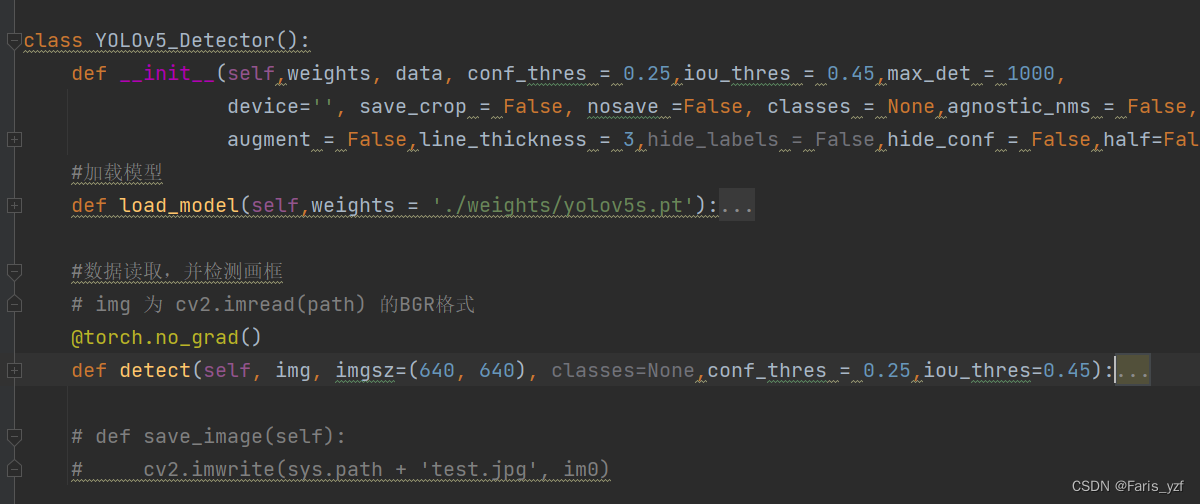
(三)各个模块
1.图片爬虫下载
输入:关键词、图片保存位置、下载页数;
输出:爬虫下载的带顺序编号的图片。
考虑到爬虫爬取时间比较久,导致界面卡死,这里使用多线程+进度条的方式进行实现。编写一个类,初始化代码如下:
- #多线程网页爬虫下载图片+进度条显示
- class Download_Pic_Thread(QThread):
- progressBarValue = pyqtSignal(int) # 更新进度条
- signal_done = pyqtSignal(int) # 是否结束信号
-
- def __init__(self, root_dir,keyword, page):#初始化
- super(Download_Pic_Thread, self).__init__()
- self.root_dir = root_dir
- self.keyword = keyword
- self.page = page
通过重载多线程的run()函数,实现某度图片的爬取下载(使用request库爬取),通过信号发射进度条的进度值给槽函数,用来更新进度条显示。部分代码段如下:
- if request.status_code == 200:
- print('Request success.')
- request.encoding = 'utf-8'
- # 正则方式提取图片链接
- html = request.text
- image_url_list = re.findall('"thumbURL":"(.*?)",', html, re.S)
- length = len(image_url_list)*1.0
- i=0
- for image_url in image_url_list:
- self.progressBarValue.emit(int(i / (length * self.page) * 100)) # 发送进度条的值信号
- image_data = requests.get(url=image_url, headers=header).content
- with open(os.path.join(dir, f'{n:06d}.jpg'), 'wb') as fp:
- fp.write(image_data)
- n = n + 1
- i+=1
另外,在调用该线程类对象时,需要将信号和槽绑定,然后实现槽函数。如下:
信号与槽绑定:
- self.thread_1.progressBarValue.connect(self.callback)
- self.thread_1.signal_done.connect(self.callback_done)
槽函数实现:
- # 回传进度条参数
- def callback(self, i):
- self.pb.setValue(i)
- self.pb.show()
-
- # 回传结束信号
- def callback_done(self, i):
- self.is_done = i
- if self.is_done == 1:
- self.messageDialog1()
-
- #结束隐藏进度条
- def messageDialog1(self):
- msg_box = QMessageBox(QMessageBox.Information, '通知', '数据处理已结束')
- self.pb.setValue(100)
- msg_box.exec_()
- self.pb.hide()

2.数据标注

对数据进行标注时,可能下载的图片或者图片格式来源比较乱,什么格式都有,后面训练的时候,代码默认图片格式是jpg格式,所以,写了一个小功能,实现对图片进行批量改格式。
这边要注意的是,opencv读写图片时,不支持中文路径名,虽然不会抛出异常,但是读入后,在处理时会异常,隐蔽性比较强,需要多加注意!!!要使用cv2.imdecode和cv2.imencode进行读写。
- for name in names:
- suffixs = name.split('.')
- suffix = suffixs.pop()
- if suffix == toext:
- pass
- elif suffix in ['bmp', 'png', 'jpg','jpeg','gif']:
- # print(f'{pic_dir}/{name}')
- try:
- cv_img = cv2.imdecode(np.fromfile(f'{pic_dir}/{name}', dtype=np.uint8), -1)
- if cv_img is not None:
- cv2.imencode(f'.{toext}', cv_img)[1].tofile(f'{pic_dir}/{suffixs[0]}.{toext}')
- os.remove(f'{pic_dir}/{name}')
- except Exception as e:
- os.remove(f'{pic_dir}/{name}')
数据标注使用 labelImg 软件,直接用os.system和多线程进行调用
- def start_label(self):
- file_path = os.path.abspath("labelImg/labelImg.exe")
- if not os.path.exists(file_path):
- widget = QWidget()
- QMessageBox.warning(widget, '警告', '标注软件不存在!', QMessageBox.Close, )
- return
-
- thread = threading.Thread(target = os.system,args = (file_path,))
- thread.start()
3.数据集配置

网上关于标注后的数据集的分配、格式转化、模型配置等介绍很多也很全了。比如下面:
https://www.cnblogs.com/wxfb/p/16654592.html![]() https://www.cnblogs.com/wxfb/p/16654592.html这边通过封装一个 Yolov5_Train_pre 类实现一键自动配置。
https://www.cnblogs.com/wxfb/p/16654592.html这边通过封装一个 Yolov5_Train_pre 类实现一键自动配置。
- #一键数据初始化
- def data_initial(self):
- # 1.数据分配
- self.data_split(self.root_dir,trainval_percent = self.trainval_percent,train_percent = self.train_percent)
- #2.格式转化
- self.dataset_path_labels_generate(self.root_dir,self.classes)
- #3.数据集配置
- self.dataset_conf(self.root_dir,self.classes_file)
- #4.模型配置
- self.model_conf(self.root_dir,self.model_file,self.classes_file)
输入:数据集根目录、类别文件(txt,包含类的名称)、训练、验证、测试比例以及模型yaml文件(用于修改成自己数据集的yaml文件)
输出:数据集配置文件(yaml)、模型文件(yaml)、xml标注文件转成的txt标注文件、数据集分配后的图片路径文件等。
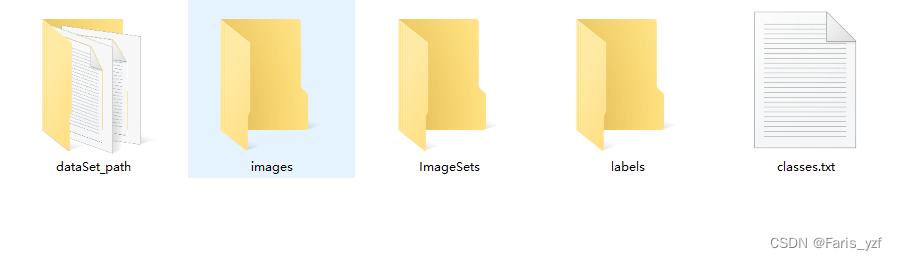
4.yolov5训练
考虑训练时间比较长,采用多线程实现。封装Train_thread(QThread)类。
输入:预训练权重文件,数据集配置文件、模型文件、epoch、batchsize等值
输出:训练权重结果、精度等文件。
部分代码段如下:
- class Train_thread(QThread):
- def __init__(self,weights_str,dataset_str,models_str,epochs,batchsize):
- super(QThread,self).__init__()
- self.weights_str = weights_str
- self.dataset_str = dataset_str
- self.models_str = models_str
- self.epochs = epochs
- self.batchsize = batchsize
重写run()函数,直接调用YOLOv5训练的代码。
- def run(self):
- #开始训练
- mytrain.myrun(self.weights_str,self.dataset_str,self.models_str,self.epochs,self.batchsize)
- self.finished.emit()
训练的实现这里不再赘述,下步争取把训练源码精简。
- def myrun(weights_str,dataset_str,models_str,epochs,batchsize):#尝试实现logging重定向
- opt = parse_opt(True)
-
- setattr(opt, 'weights', weights_str)
- setattr(opt, 'data', dataset_str)
- setattr(opt, 'cfg', models_str)
- setattr(opt, 'epochs', epochs)
- setattr(opt, 'batch_size', batchsize)
- main(opt)
- return opt
三、目标检测部分
(一)总体效果
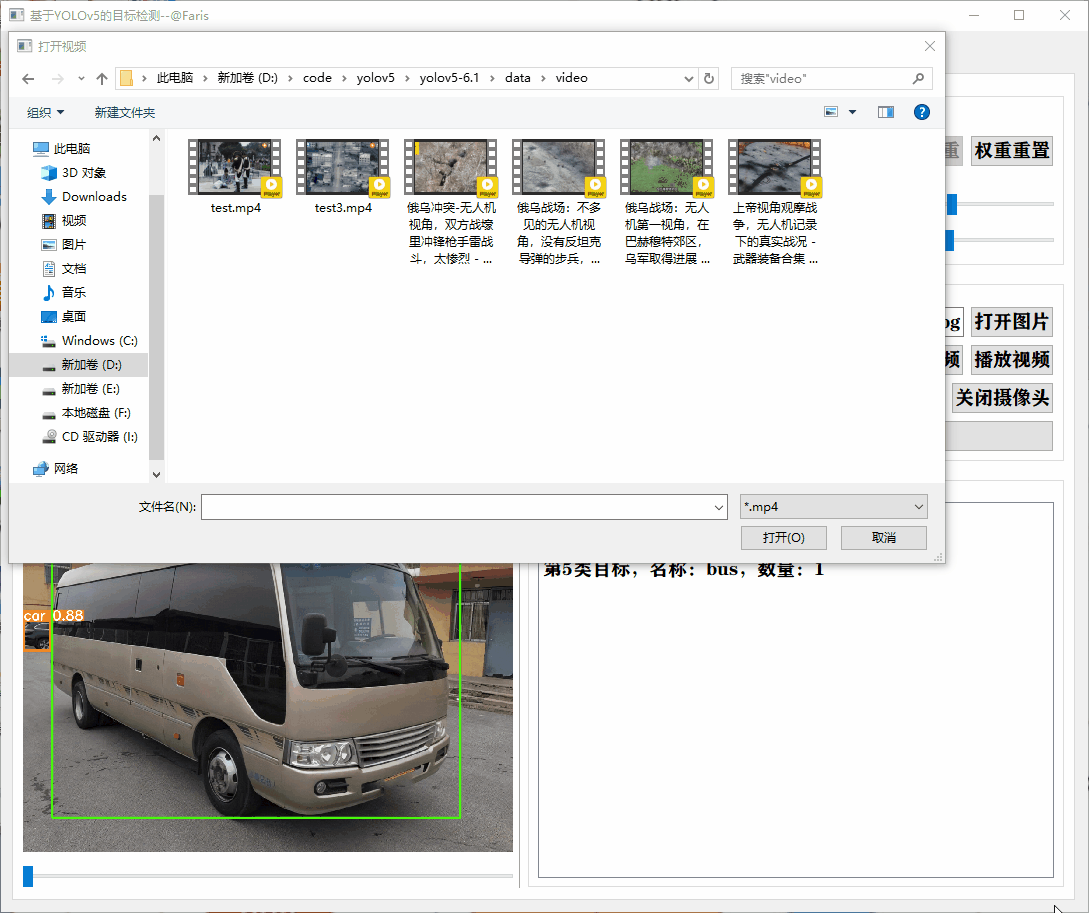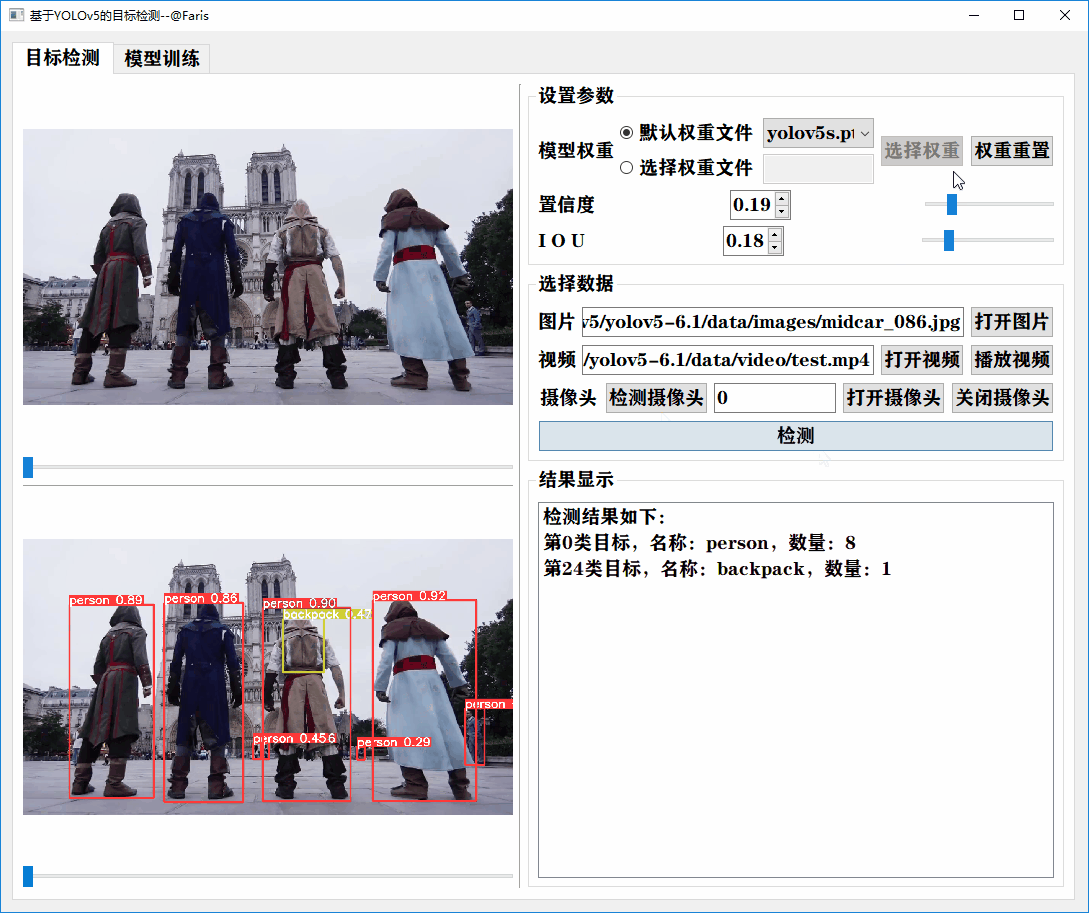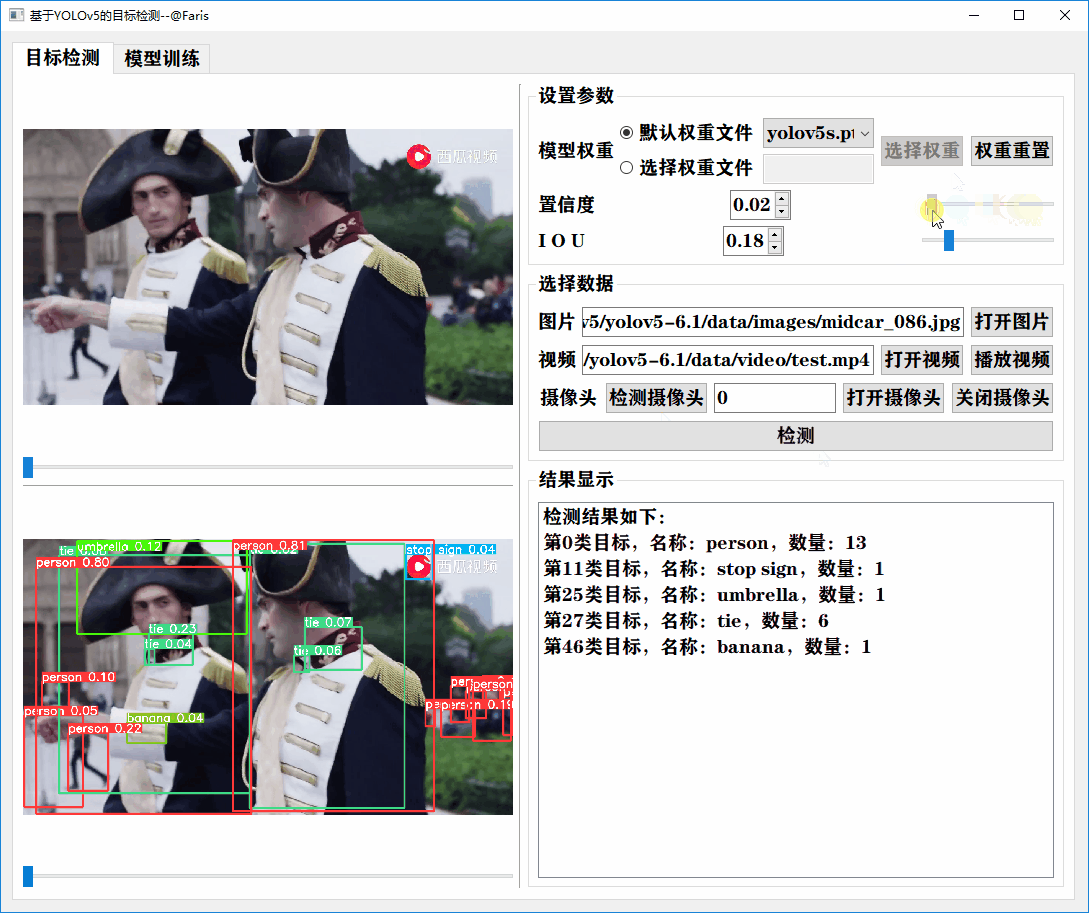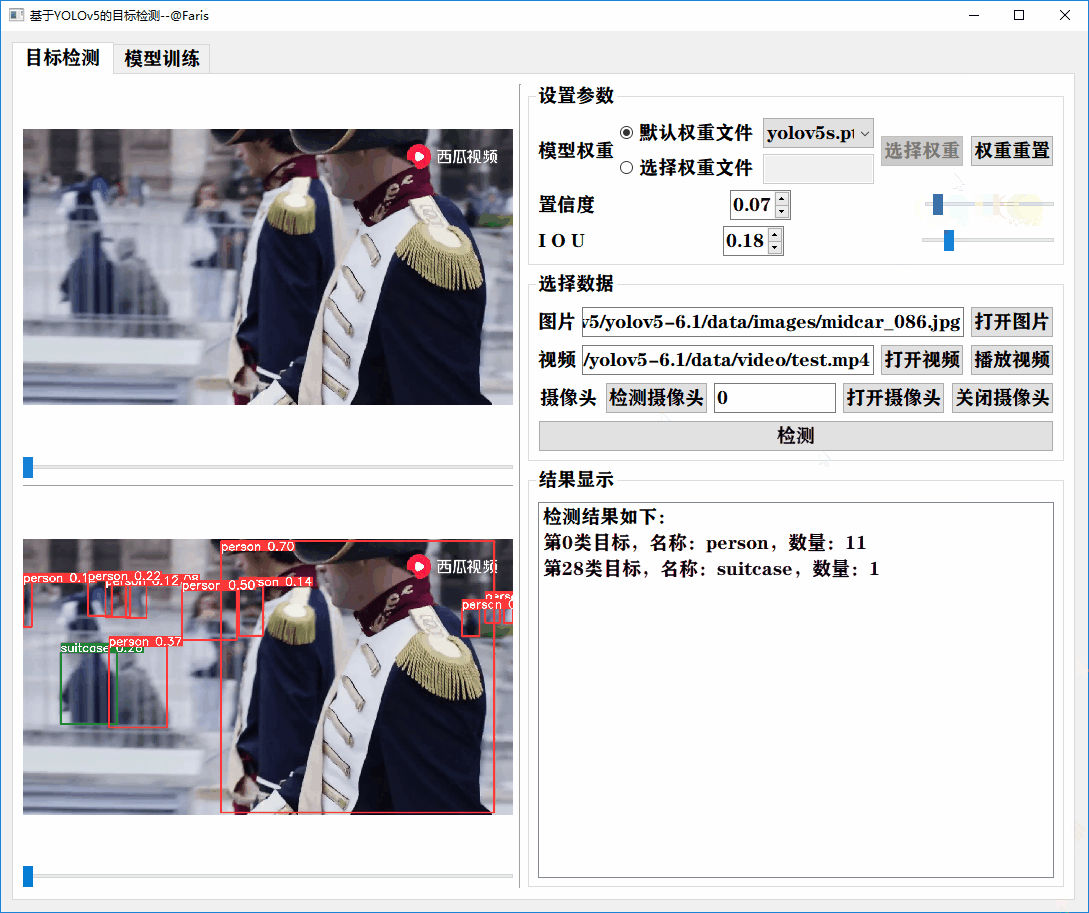
通过设置权重文件、置信度、iou等值,实现对图片、视频和摄像头视频流等格式进行实时的检测,并把检测类别和数量显示在列表里面。
(二)各个模块
总体上,封装了目标检测的类 YOLOv5_Detector,实现数据的读取和检测2个接口。

1.参数设置
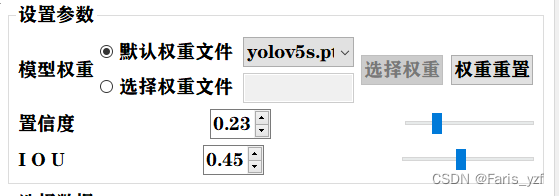
该部分主要是QT控件的实现。重点设计radiobutton、combox、doublespinbox和slider等控件的基本操作实现,其中,还实现radiobutton控制控件灰色不可用功能。
特别注意的是,slider的最值不能是小数,在跟doublespinbox联动时,需要进行转换!!!
- def SpinBox_conf_thres_Changed(self, new_value):
- self.conf_thres = new_value
- self.horizontalSlider_conf_thres.setValue(new_value*100)
-
- def Slider_conf_thres_Changed(self, new_value):
- self.conf_thres = new_value/100
- self.doubleSpinBox_conf_thres.setValue(new_value/100)
-
- def SpinBox_iou_thres_Changed(self, new_value):
- self.iou_thres = new_value
- self.horizontalSlider_iou_thres.setValue(new_value*100)
-
- def Slider_iou_thres_Changed(self, new_value):
- self.iou_thres = new_value/100
- self.doubleSpinBox_iou_thres.setValue(new_value/100)
2.数据选择及检测
yolo检测步骤:
一是初始化参数。
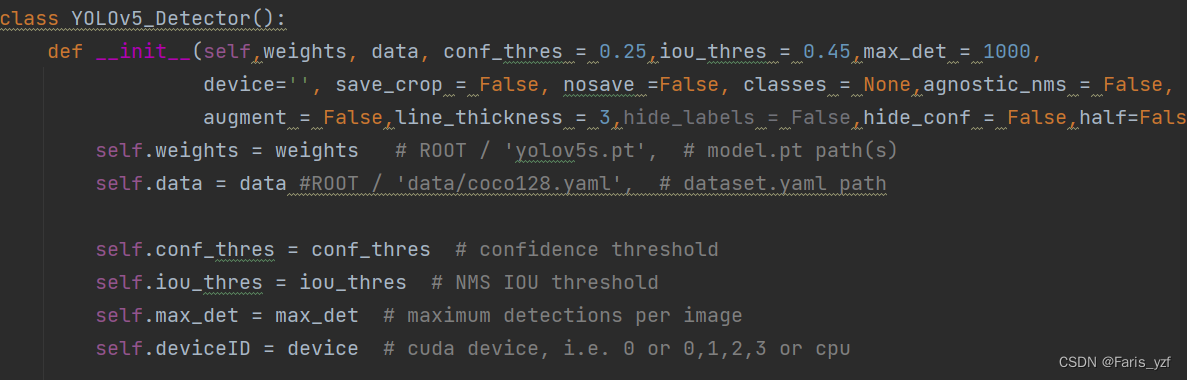
二是选择处理设备。
- # self.device = select_device(device)
-
- cuda = torch.cuda.is_available()
- self.device = torch.device('cuda:0' if cuda else 'cpu')
这里要特别特别特别注意的是:如果要用pyinstall转成exe时,这里必须要改成代码中的,不能用select_device()方法,不然编译时会报找不到pytorc-util.pyc等错误!!!亲测有效!!!
三是加载模型。
- def load_model(self,weights = './weights/yolov5s.pt'):
- # device = select_device(self.device)
- self.model = DetectMultiBackend(weights, device=self.device, dnn=self.dnn, data=self.data)
- self.stride, self.names, self.pt, self.jit, self.onnx, self.engine = self.model.stride, self.model.names, \
- self.model.pt, self.model.jit, self.model.onnx, self.model.engine
- # imgsz = check_img_size(imgsz, s=stride) # check image size
- # Half
- half = self.half and (self.pt or self.jit or self.onnx or self.engine) and self.device.type != 'cpu' # FP16 supported on limited backends with CUDA
- if self.pt or self.jit:
- self.model.model.half() if half else self.model.model.float()
四是NMS检测。
- @torch.no_grad()
- def detect(self, img, imgsz=(640, 640), classes=None,conf_thres = 0.25,iou_thres=0.45):
- cal_detect = []
- # device = select_device(self.device)
- # names = self.model.module.names if hasattr(self.model, 'module') else self.model.names # get class names
-
- # Set Dataloader
- # Padded resize
-
- im = letterbox(img, imgsz, self.stride, self.pt)[0]
-
- # Convert
- ...
-
- pred = self.model(im, self.augment)
-
- pred = non_max_suppression(pred, conf_thres, iou_thres, self.classes, self.agnostic_nms, self.max_det)
-
- # 第0类,名称:人,数量:5
- #用于显示检测结果,形式为:第*类:,名称:,数量:
- listview_str =['检测结果如下:']
- # Process detections
- for i, det in enumerate(pred): # detections per image
- # annotator = Annotator(img, self.line_thickness, example=str(self.names))
- if len(det):
- # Rescale boxes from img_size to im0 size
- det[:, :4] = scale_coords(im.shape[2:], det[:, :4], img.shape).round()
-
- for c in det[:, -1].unique():
- #类别:names[int(c)] 有 n个数量
- n = (det[:, -1] == c).sum() # detections per class
- str = '第%d类目标,名称:%s,数量:%d'%(int(c),self.model.names[int(c)],n)
- listview_str.append(str)
-
- # Write results
- for *xyxy, conf, cls in reversed(det):
- c = int(cls) # integer class
- label = None if self.hide_labels else (self.names[c] if self.hide_conf else f'{self.names[c]} {conf:.2f}') #结果显示的标签
- # annotator.box_label(xyxy, label, color=colors(c, True))
- box = xyxy
- p1, p2 = (int(box[0]), int(box[1])), (int(box[2]), int(box[3]))
- # im = (im[:, :, ::-1] * 255.0).astype(np.uint8)
- cv2.rectangle(img, p1, p2, colors(c, True), self.line_thickness, lineType=cv2.LINE_AA)
- # cv2.imwrite('test.jpg', img)
- if label:
- tf = max(self.line_thickness - 1, 1) # font thickness
- w, h = cv2.getTextSize(label, 0, fontScale=self.line_thickness / 3, thickness=tf)[0] # text width, height
- outside = p1[1] - h - 3 >= 0 # label fits outside box
- p2 = p1[0] + w, p1[1] - h - 3 if outside else p1[1] + h + 3
- cv2.rectangle(img, p1, p2, colors(c, True), -1, cv2.LINE_AA) # filled
- lw = self.line_thickness or max(round(sum(im.shape) / 2 * 0.003), 2) # line width
- cv2.putText(img, label, (p1[0], p1[1] - 2 if outside else p1[1] + h + 2), 0, lw / 3,
- (255, 255, 255),thickness=tf, lineType=cv2.LINE_AA)
-
- # cv2.imwrite('test.jpg', img)
- #保存框中的内容
- # if self.save_crop:
- # save_one_box(xyxy, imc, file=save_dir / 'crops' / self.names[c] / f'{p.stem}.jpg', BGR=True)
-
- return img,listview_str
3结果显示
区分2个部分。
一是图像显示部分。通过数据类型来判断检测和显示的数据类型。实质还是检测单张图片或者单帧画面,并显示。检测画面的显示使用QLabel,将pixmap贴到label上面。以图片为例:
- if self.data_type == 1:
- if self.cap:
- self.cap.release()
- #opencv imread 识别不了中文路径
- self.image0 = cv2.imdecode(np.fromfile(self.lineEdit_pic_path.text(), dtype=np.uint8), -1)
-
- # #绘制原图
- height, width, depth = self.image0.shape
-
- image_det,listview_str = self.detector.detect(self.image0, conf_thres=self.conf_thres, iou_thres=self.iou_thres)
-
- # 获取图像的宽和高 Format_BGR888
- self.image1 = QtGui.QImage(image_det, width, height, width*depth,QtGui.QImage.Format_BGR888) # 如果没有depth*width,图像可能会扭曲
- self.pixmap1 = QtGui.QPixmap(self.image1) # 创建相应的QPixmap对象
- # 根据图像与label的比例,最大化图像在label中的显示
-
- ratio = max(width / self.label_detect_show.width(), height / self.label_detect_show.height())
- self.pixmap1.setDevicePixelRatio(ratio)
-
- self.label_detect_show.setPixmap(self.pixmap1) # 显示图像
- self.label_detect_show.setAlignment(Qt.AlignCenter) # 图像居中
- # 显示结果列表框
- # 创建字符串列表模型
- listview_model = QStringListModel(listview_str)
-
- # 将字符串列表模型设置为QListView控件的模型
- self.listView_detect_result.setModel(listview_model)
-
- # 显示QListView控件
- self.listView_detect_result.show()
特别指出的是,这边还对计算机的摄像头进行检测,能控制指定的摄像头开启和关闭(如外接的USB摄像头),代码如下:
- def check_camere_Index(self):
- cameras = []
- for i in range(10): # 尝试获取前10个摄像头
- #cv2.CAP_DSHOW 打开摄像头快很多
- cap = cv2.VideoCapture(i,cv2.CAP_DSHOW)
- if cap.isOpened():
- cameras.append(i)
- cap.release()
- else:
- break
-
- str_arr = "".join(str(x)+'、' for x in cameras)
- str_arr = str_arr[0:len(str_arr) - 1]
- self.lineEdit_camera_Index.setText(str_arr)
二是结果列表显示部分。
用的是ListView控件,需要创建模型如下:
- # 显示结果列表框
- # 创建字符串列表模型
- listview_model = QStringListModel(listview_str)
- # 将字符串列表模型设置为QListView控件的模型
- self.listView_detect_result.setModel(listview_model)
-
- # 显示QListView控件
- self.listView_detect_result.show()
检测结果数组如下:
- for c in det[:, -1].unique():
- #类别:names[int(c)] 有 n个数量
- n = (det[:, -1] == c).sum() # detections per class
- str = '第%d类目标,名称:%s,数量:%d'%(int(c),self.model.names[int(c)],n)
- listview_str.append(str)
四、程序发布
主要介绍pyinstall进行生成可执行文件。pyinstall的安装和使用不再进行赘述,这里主要是讲几个出现的问题及笔者解决方法。

一是多线程。因为使用了多线程开发,需要用到下面的语句。
multiprocessing.freeze_support()二是提示pytorch找不到pyc文件。上面已经讲过不再阐述。
最后,码字分享不易,请大家点赞、加关注、评论。

