
- 1html让text变成线,text-decoration属性(CSS设置文本的修饰线外观)
- 2bat文件无法双击运行
- 3六、查询数据_select 结果用逗号分割
- 4uni-app创建并运行微信小程序项目_uniapp运行微信小程序
- 5优酷鸿蒙开发实践 | 鸿蒙卡片开发_鸿蒙元服务卡片怎么开发前端js
- 6Locale 及Locale.getDefault()
- 7ACL2022 事件抽取_小样本事件抽取
- 8Mac(M1)下配置Maven的安装与使用_mac m1配置maven
- 9php qq接口开发,PHP调用QQ互联接口实现QQ登录网站功能示例
- 10TP6整合unipush_uniapp unipush thikphp6
什么是ETCD
赞
踩
ETCD
什么是 ETCD
etcd是使用go语言编写的分布式、高可用的一致性键值存储系统,用于提供可靠的分布式键值存储、配置共享和服务发现等功能。
特性
-
简单:
- 易使用:基于
HTTP+JSON的API让你用curl就额可以轻松使用
- 易使用:基于
-
易部署:使用go语言编写,跨平台,部署和维护简单
-
可靠:
- 强一致性:使用raft算法,充分保证了分布式数据的强一致性;
-
高可用:具有容错能力,假设集群中有n个节点,当(n-1)/2个节点发生故障,依然能够提供服务
-
持久化:数据更新后,会通过
WAL格式数据持久化到磁盘,支持SnapShot快照 -
快速:每个实例每秒支持一千次操作,极限写性能可达
10KQPS -
安全:可选
SSL客户认证方式
整体框架
根据功能可以将etcd分为4个主要部分:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Yos2glPS-1678965265335)(file://E:\文档\分享文档\etcd分享\image-165276812324614.png?msec=1678965192612)]](https://img-blog.csdnimg.cn/abb40e5d407b4dce8c9f71ee7585b510.png)
-
HTTP Server: 用于处理用户发送的HTTP请求,以及其他ETCD节点的同步与心跳信息请求。 -
Store: 用于处理etcd支持各类功能的事务、包括数据索引、节点变更、监控与反馈、时间处理与执行等,是etcd对用户提供大多数API功能的具体实现。 -
Raft:Raft强一致性算法具体实现,是etcd的核心。 -
WAL: Write Ahead Log(预写式日志),是etcd用于持久化存储的日志格式,或者说是etcd的数据存储方式。除了在内存中所有数据的状态以及节点的索引以外,etcd就通过WAL进行持久化存储,WAL中所有的数据提交前都会事先记录日志,SnapShot是为了放置数据过多而进行的状态快照,Entry表示存储的具体日志内容。
**Raft**协议
设计目标
- 可用性:可用性是分布式系统的核心需求,其用于衡量一个分布式系统持续对外提供服务的能力
- 可扩展性:增加机器后不会改变或极少改变系统行为,并且能获得近似线性的性能提升
- 容错性:系统发生错误时,具有对错误进行规避以及从错误中恢复的能力
- 性能:对外服务的响应延时和吞吐率要能满足用户的需求
分布式中的CAP原理
- C:Consistency(一致性)。强一致性,所有节点上的数据时刻保持同步。
- A:Availability(可用性)。任何非故障节点,都应该在有限时间内给出请求响应,不论请求是否成功
- P:Tolerance to the partition of network(分区容忍性)。当发生网络分区时,在丢失任意多消息的情况下,系统仍然能够正常工作
相信大家都非常清楚CAP原理的指导意义:在任何分布式系统中,可用性、一致性和分区容忍性这三个方面都是相互矛盾的,三者不可兼得,最多只能取其二。
基本概念
角色
-
Leader(领袖):领袖由群众投票选举得出每次选举,只能选举一名领袖,对系统的所有修改都要经过Leader -
Candidate(候选人):当没有领袖时,某些群众会成为候选人,然后去竞选领袖的位置;会向其他节点 拉选票 ,如果得到大部分票则成为Leader,这个过程就叫做Leader选举(Leader election) -
Follower(群众):吃瓜群众,所有节点的开始状态都是Follower,如果超期没有收到Leader的消息则会变成candidate状态。
选举过程几个重要的概念
Leader Election(领导人选举):简称选举,就是从候选人中选出领袖
Term(任期):实质上就是一个单调递增的数值,每一次任期斗殴会重新发起一次领导人选举
Election Timeout(选举超时):实质上是一个超时时间,当群众超时未收到领袖的心跳时,会重新进进行选举。
角色转换
Etcd的节点之间存在如下几种常见的类型转换,可以简单总结如下:
-
群众->候选人:当开始选举,或者选举超时
-
候选人->候选人:当选举超时,或者开始新的任期
-
候选人->领袖:当该候选人获得大多数投票时
-
候选人->群众:其它节点成为领袖,或者开始新的任期
-
领袖->群众:发现自己的任期ID比其他节点任期ID小时,会自动放弃领袖位置
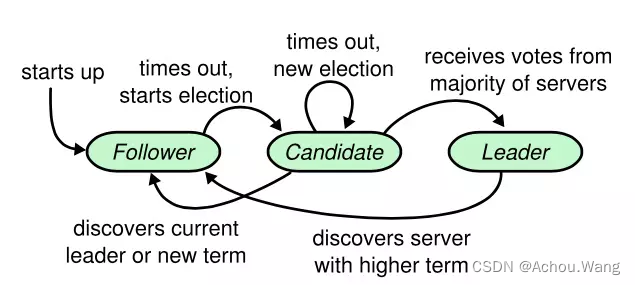
raft算法选举实现动态演示(对应keeper的主节点选取):
动画演示:
单步演示选举过程:
示例代码
只实现了选举,但是很快会结束任期开启下一次选举.
package main
import (
"bufio"
"fmt"
"io"
"log"
"math/rand"
"net"
"strconv"
"strings"
"time"
)
const (
LEADER = iota
CANDIDATE
FOLLOWER
)
// Addr 地址结构体
type Addr struct {
Host string
Port int
Addr string
}
// RaftServer Raft结构体
type RaftServer struct {
Role int
Nodes []Addr
Port int
HeartbeatChan chan bool
ElectChan chan bool
IsElecting bool
ETO int `election time out`
Votes int `total vote for me`
NoVote int `current No. Vote`
HasVote bool
}
// Heartbeat 心跳循环
func (rs *RaftServer) Heartbeat() {
for {
<-rs.HeartbeatChan
log.Println("Leader starts Heartbeat")
for _, n := range rs.Nodes {
if n.Port == rs.Port {
continue
}
c, err := net.Dial("tcp", n.Addr)
if err != nil {
log.Println(err)
} else {
_, err = fmt.Fprintf(c, "LEADER-HEARTBEAT-SYNC\n")
if err != nil {
return
}
line, err := bufio.NewReader(c).ReadString('\n')
if err != nil && err != io.EOF {
log.Println(err)
} else {
log.Println("Heartbeat Reply:" + strings.TrimRight(line, "\n"))
}
err = c.Close()
if err != nil {
return
}
}
}
}
}
// Elect 选举
func (rs *RaftServer) Elect() {
for {
log.Println("wait to elect")
<-rs.ElectChan
//clear the votes
rs.Votes = 0
rs.NoVote += 1
rs.IsElecting = true
log.Println("start elect:vote" + strconv.Itoa(rs.NoVote))
for _, n := range rs.Nodes {
if n.Port == rs.Port {
continue
}
c, err := net.Dial("tcp", n.Addr)
if err != nil {
log.Println(err)
} else {
_, err = fmt.Fprintf(c, "NoVote"+strconv.Itoa(rs.NoVote)+"\n")
if err != nil {
return
}
line, err := bufio.NewReader(c).ReadString('\n')
if err != nil {
log.Println(err)
} else {
log.Println("Elect Reply:" + strings.TrimRight(line, "\n"))
if strings.HasPrefix(line, "OK") {
log.Println("Receive Vote from:", c)
rs.Votes += 1
}
}
err = c.Close()
if err != nil {
return
}
}
}
if (rs.Votes+1)*2 > len(rs.Nodes) {
rs.ChangeRole(LEADER)
}
rs.IsElecting = false
}
}
// ResetETO 选举超时时间(1500 - 3000) 随机,这里扩大时间是为了打印效果,ETCD里面是(150-300)
func (rs *RaftServer) ResetETO() {
rs.ETO = 1500 + rand.Intn(1500)
}
func (rs *RaftServer) ChangeRole(role int) {
switch role {
case LEADER:
log.Println("我当前是 Leader!")
case CANDIDATE:
log.Println("我当前是 candidate!")
case FOLLOWER:
log.Println("我当前是 follower!")
}
rs.Role = role
}
// EelectTimer 每个node都需要等随机的时间,再开始下次选举
func (rs *RaftServer) EelectTimer() {
for {
for rs.ETO != 0 {
oldeto := rs.ETO
rs.ETO = 0
time.Sleep(time.Duration(oldeto) * time.Millisecond)
}
if rs.ETO == 0 {
log.Println("EelectTimer timed out!")
if rs.Role != LEADER && !rs.IsElecting {
rs.ElectChan <- true
rs.ChangeRole(CANDIDATE)
}
}
rs.ResetETO()
}
}
// HeartbeatTimer 主节点要定时向FOLLOWER发送心跳
func (rs *RaftServer) HeartbeatTimer() {
for {
if rs.Role == LEADER {
rs.HeartbeatChan <- true
}
time.Sleep(500 * time.Millisecond)
}
}
// CanVote 投票
func (rs *RaftServer) CanVote(vote string) bool {
noVote, _ := strconv.Atoi(strings.Replace(vote, "NoVote", "", -1))
if rs.Role == LEADER {
if noVote > rs.NoVote {
rs.NoVote = noVote
}
return false
}
if noVote > rs.NoVote {
rs.NoVote = noVote
rs.HasVote = true
return true
} else if noVote == rs.NoVote {
if !rs.HasVote {
rs.HasVote = true
return true
}
}
return false
}
func (rs *RaftServer) Run() {
ln, err := net.Listen("tcp", ":"+strconv.Itoa(rs.Port))
if err != nil {
log.Fatal(err)
}
log.Println("Listening as " + strconv.Itoa(rs.Port))
go rs.Elect()
go rs.Heartbeat()
go rs.EelectTimer()
go rs.HeartbeatTimer()
for {
conn, err := ln.Accept()
if err != nil {
// handle error
continue
}
go func(c net.Conn) {
// Echo all incoming data.
line, err := bufio.NewReader(c).ReadString('\n')
if err != nil {
log.Println(err)
err := c.Close()
if err != nil {
return
}
return
} else {
log.Println("Server Receive:" + strings.TrimRight(line, "\n"))
if strings.HasPrefix(line, "LEADER-HEARTBEAT-SYNC") {
if rs.Role != FOLLOWER {
rs.ChangeRole(FOLLOWER)
}
rs.ResetETO()
_, err = fmt.Fprintf(c, "FOLLOWER ACK\n")
if err != nil {
return
}
} else if strings.HasPrefix(line, "NoVote") {
if rs.CanVote(line) {
_, err = fmt.Fprintf(c, "OK\n")
if err != nil {
return
}
} else {
_, err = fmt.Fprintf(c, "NOTOK\n")
if err != nil {
return
}
}
}
}
//io.Copy(c, c)
// Shut down the connection.
err = c.Close()
if err != nil {
return
}
}(conn)
}
}
func NewNode() *RaftServer {
rs := RaftServer{}
rs.ChangeRole(FOLLOWER)
rs.ElectChan = make(chan bool)
rs.HeartbeatChan = make(chan bool)
rs.ResetETO()
rs.Nodes = []Addr{
{"127.0.0.1", 5000, ":5000"},
{"127.0.0.1", 5001, ":5001"},
{"127.0.0.1", 5002, ":5002"},
}
return &rs
}
func (rs *RaftServer) Start(port int) {
rs.Port = port
rs.Run()
}
func main() {
log.SetFlags(23)
//port := flag.Int("p", 5000, "listening port")
//flag.Parse()
for i := 0; i < 4; i++ {
go func(i int) {
rs := NewNode()
rs.Start(5000 + i)
}(i)
}
for {
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
日志复制
复制状态机
复制状态机的基本思想是一个分布式状态机,系统有多个复制单元组成,每个复制单元均是一个状态机,他的状态保存在操作日志中。
服务器上一致性模块负责接收外部命令,然后追加到自己的操作日志中,它与其他服务器上的一致性模块进行通信,以保证每一个服务器上的操作日志最终都以相同的顺序包含相同的指令。一旦指令被正确复制,那么每一个服务器的状态机都将按照操作日志的顺序处理它们,然后将输出结果返回给客户端。
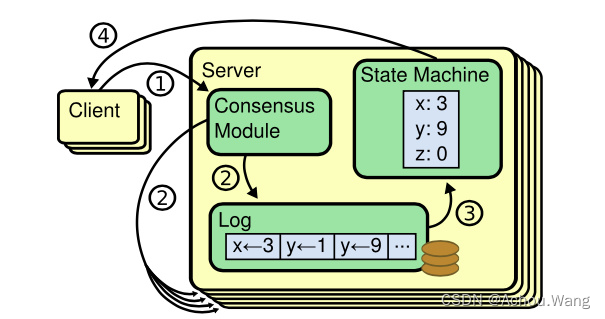
Server:服务器
Client:客户端
Consensus Module:一致性模块
Log:操作日志
State Machine:状态机
一致性可能出现问题
一致性算法的目标就是保证集群上所有节点的状态一致,节点要执行的指令可以分为两种,读与写。只有写指令会改变节点状态,因此为了保证集群各个节点状态的一致,那就必须将写指令同步给所有节点。
理想状态下,我们期望任意节点发生写命令都会立即的在其他节点上变更状态,这其中没有任何时延,所有节点都好像是单机一样被变更状态。
网络延迟要远远慢于内存操作,写入命令不可能被同时执行,因此如果在不同节点发生不同的写命令,那么在其他节点上这些写命令被应用的顺序很可能完全不同。
如果我们不要求所有节点的写命令立即被执行,而仅仅是保证所有的写命令在所有的节点上按同样的顺序最终被执行呢? 第一, 仅仅允许一个节点处理写命令,第二,所有的节点维护一份顺序一致的日志。
每个节点上的状态机按照自己的节奏,逐条应用日志上的写命令来变更状态。
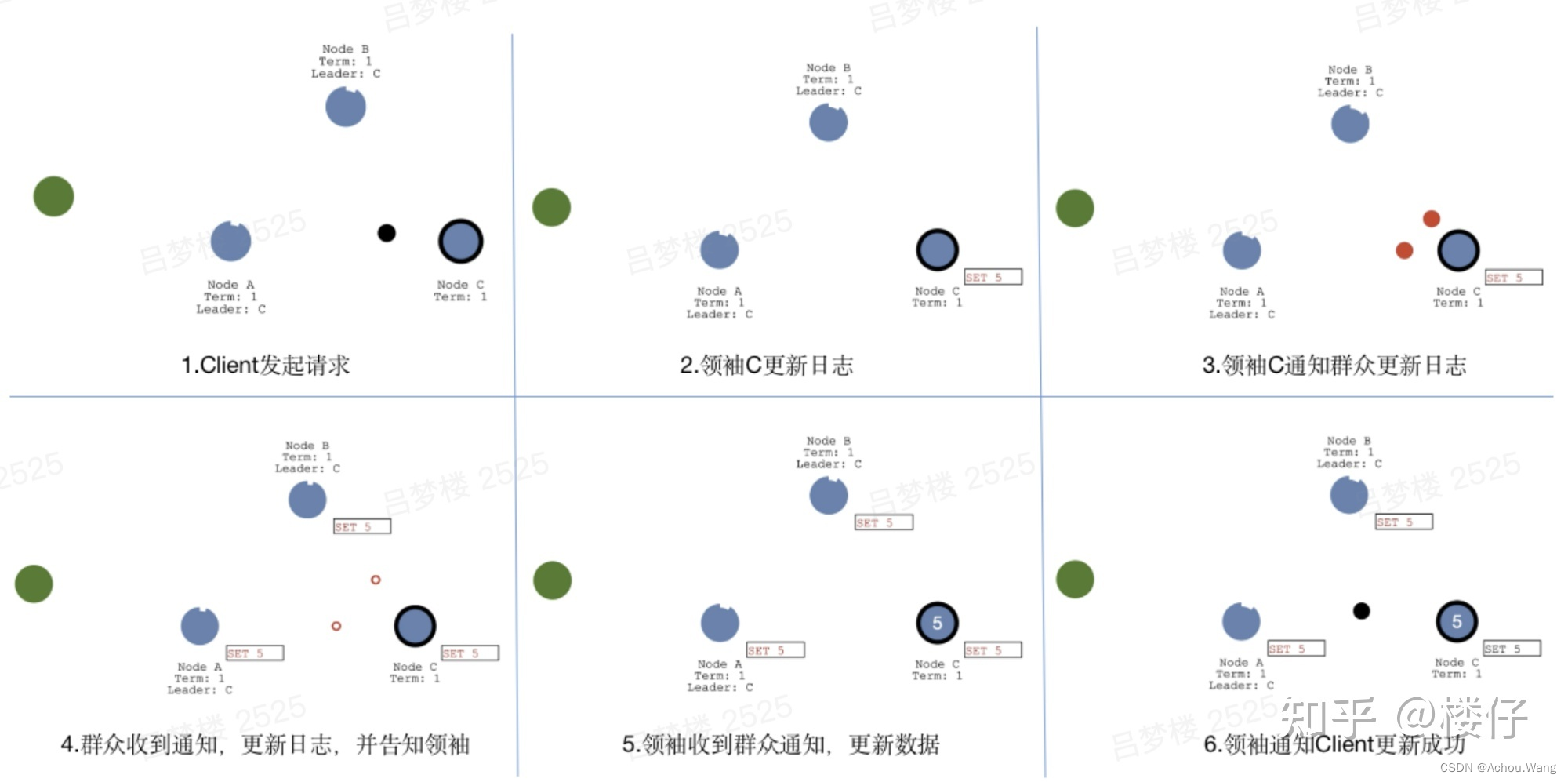
数据同步流程
数据同步流程,借鉴了“复制状态机”的思想,都是先“提交”,再“应用”。当Client发起数据更新请求;
- 请求会先到领袖节点C,节点C会更新日志数据
- 然后领袖C通知群众节点也更新日志
- 当群众节点更新日志成功后,会返回成功通知给领袖C,至此完成了“提交”操作;
- 当领袖C收到通知后,会更新本地数据,并通知群众也更新本地数据,同时会返回成功通知给Client,至此完成了“应用”操作,如果后续Client又有新的数据更新操作,会重复上述流程。
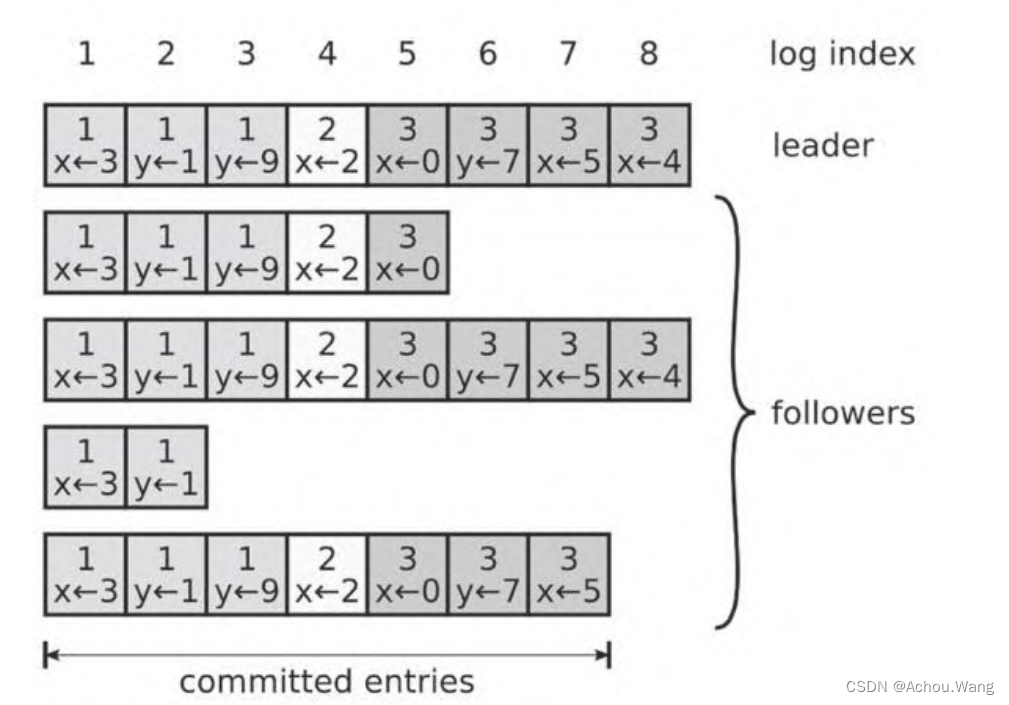
日志组成
每一个日志条目一般包含三个属性:整数索引(Log Index)、任期号Term和指令
Commond,每个条目所包含的整数索引即该条目在日志中的槽位;
任期号:对应到图中就是每个方块中的数字,用于检测不同服务器上日志不一致问题;
指令:即用于被状态机执行的外部命令,图中就是带箭头的数字。
日志原理实现比较繁琐:参考https://zhuanlan.zhihu.com/p/369777462
常见问题
**ETCD**的应对情况
一个raft系统异常的情况通常可以范围两大类:领导人异常和追随者/候选人异常。
追随者和候选人异常问题的解决方法比领导人异常简单得多。
由于raft算法的强领导特性,因此能够保证在领导人出现故障的情况下还能保证不影响数据一致性就显的格外的重要, 正常的全流程如下所示:
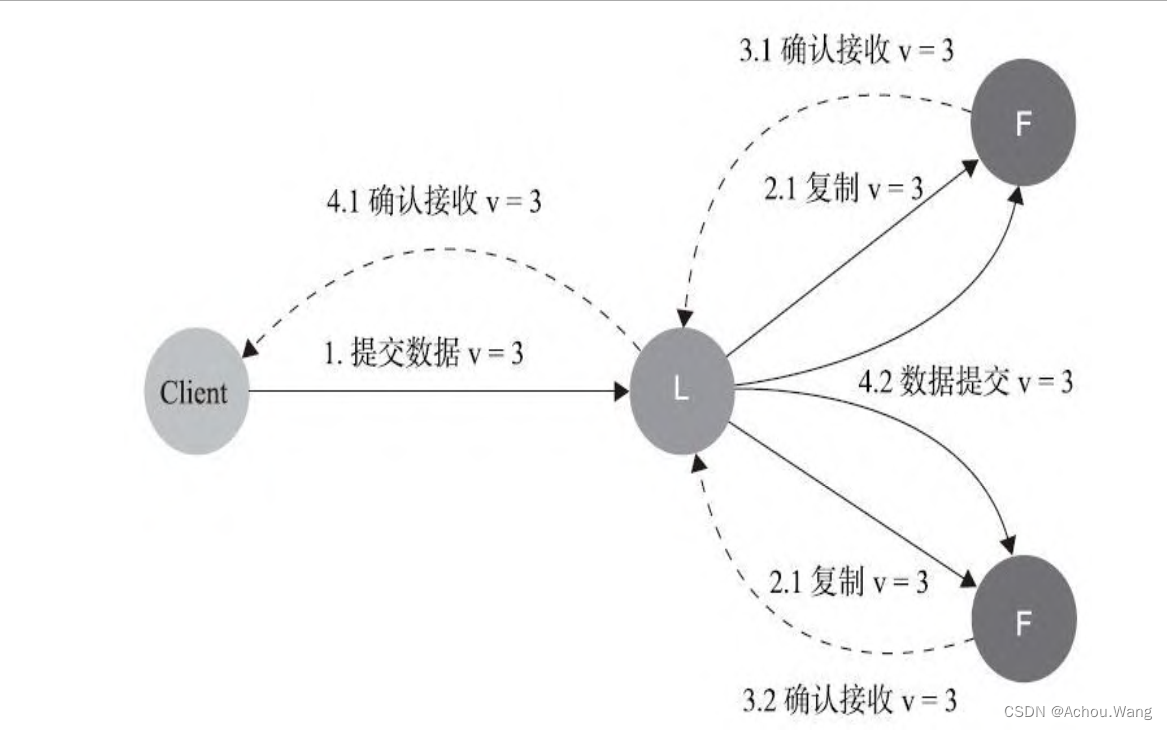
正常过程中,领导人可能在任意阶段出现崩溃,根据崩溃的时间点,
ETCD将会出出现以下常见问题。
1. 数据到达**Leader**前
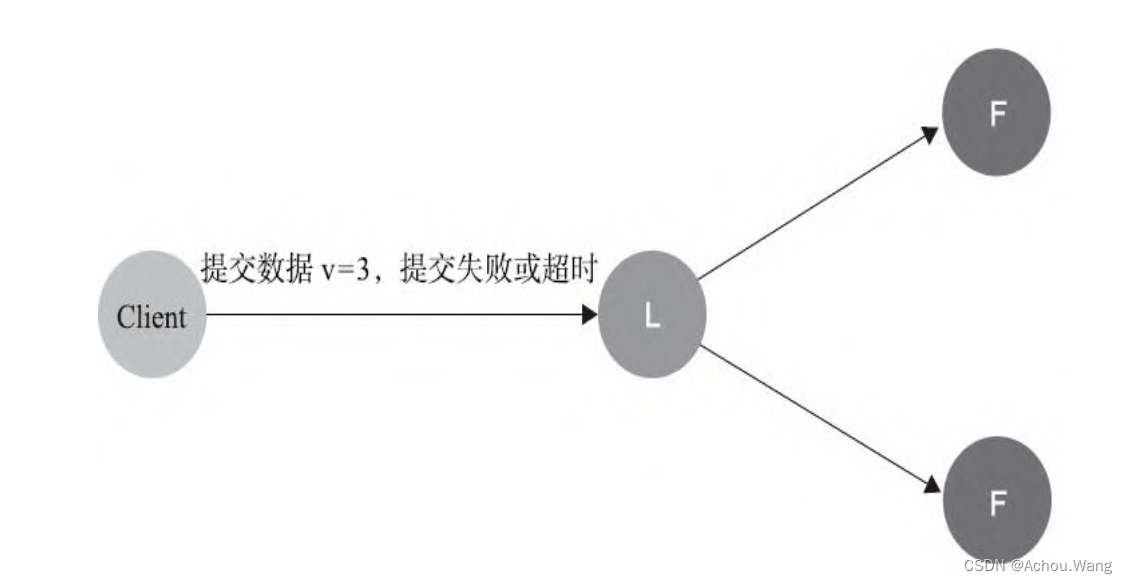
这个阶段会直接导致数据提交失败,不会影响数据一致性
2. 数据到达**Leader**节点,但是未复制到**Follower**节点
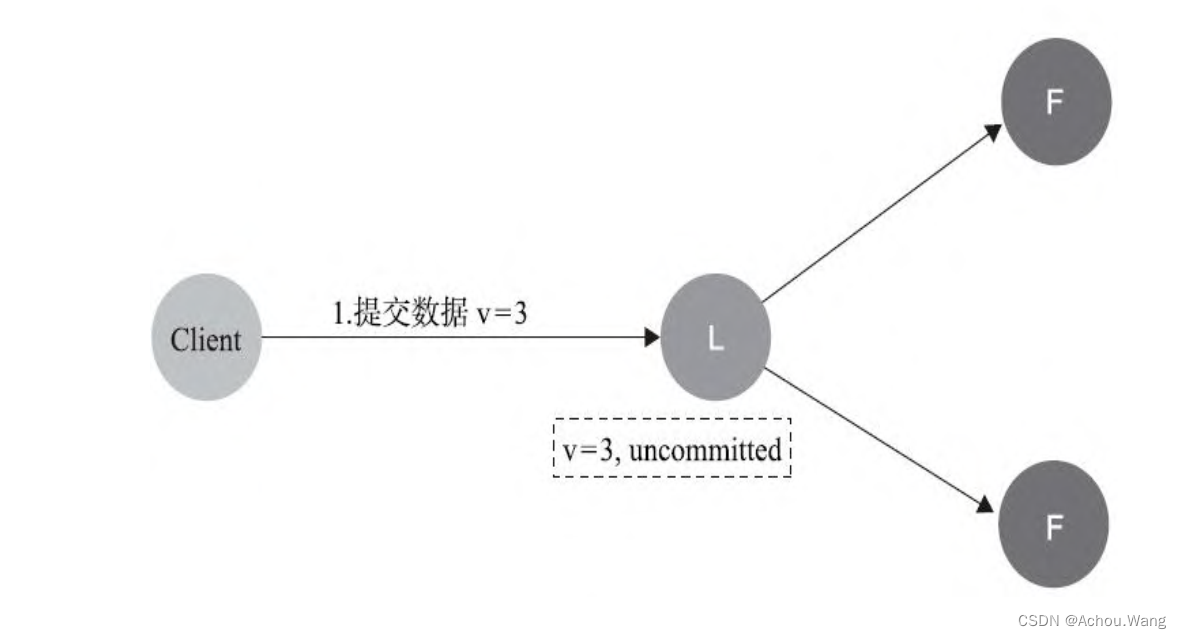
如果在这个阶段出现leader故障,此时数据属于未提交状态,那么Client不会收到ACK,而是会认为超时失败可安全发起重试。Follower节点上没有该数据,重新选主后Client重试从新提交即可成功。原来的Leader节点恢复之后将作为Follower加入集群,重新从当前任期的新Leader处同步数据与Leader数据强制保持一致。
3. 数据到达Leader节点扣成功复制到Follower的部分节点上,但还未向Leader节点响应接收
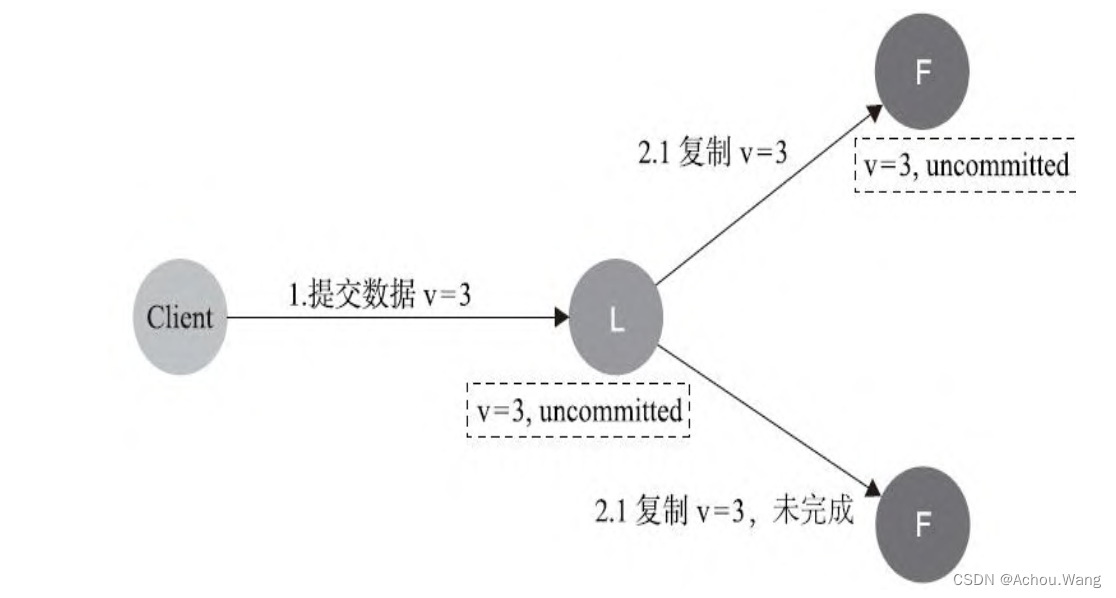
如果这个阶段Leader出现故障,此时数据在Follower节点处于未提交状态(Uncommitted)且不一致,那么Raft协议要求投票只能投给拥有最新数据的节点。所以拥有最新数据的节点会被选为Leader,再将数据强制同步到Follower,数据不会丢失且能保证最终一致。
4. 数据到达Leader节点,成功复制到Follower的所有节点上,但是还未向Leader响应接收
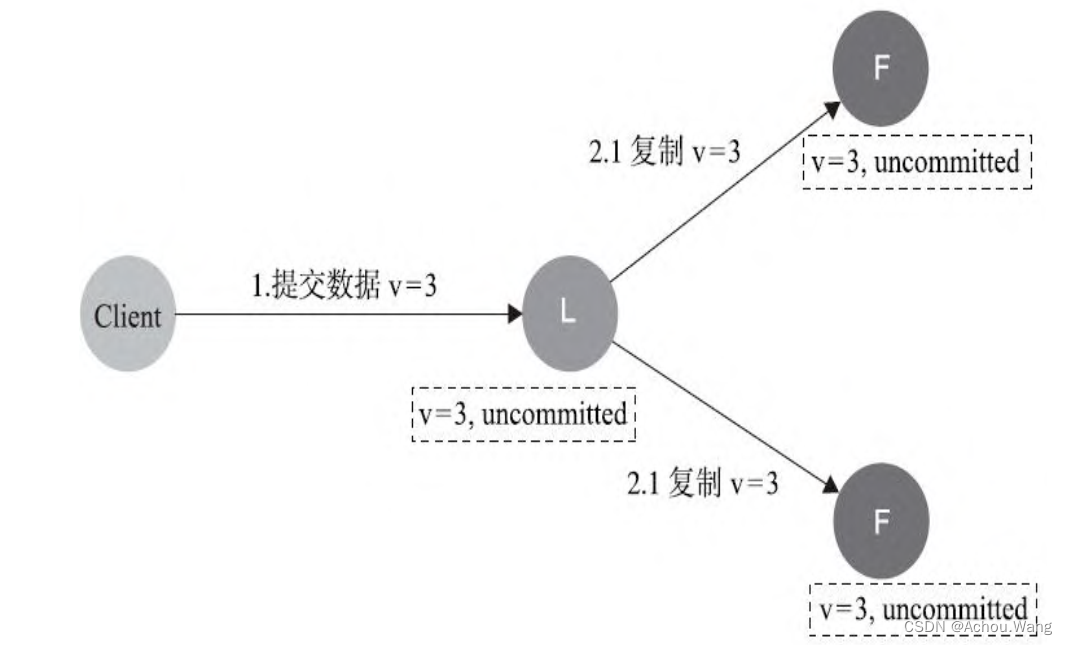
如果在这个阶段Leader出现故障,虽然此时数据在Follower节点处于未提交状态(
Uncommited),但也能保持一致,那么重新选出Leader后即可完成数据提交,由于此时客户端不知到底有没有提交成功,因此可重试提交,针对这种情况,raft要求
RPC请求实现幂等性,也就是要实现内部去重机制。
5. 数据到达Leader节点,成功复制到Follower的所有或者大多数节点上,数据在Leader上处于已提交状态,但在Follower上处于未提交状态
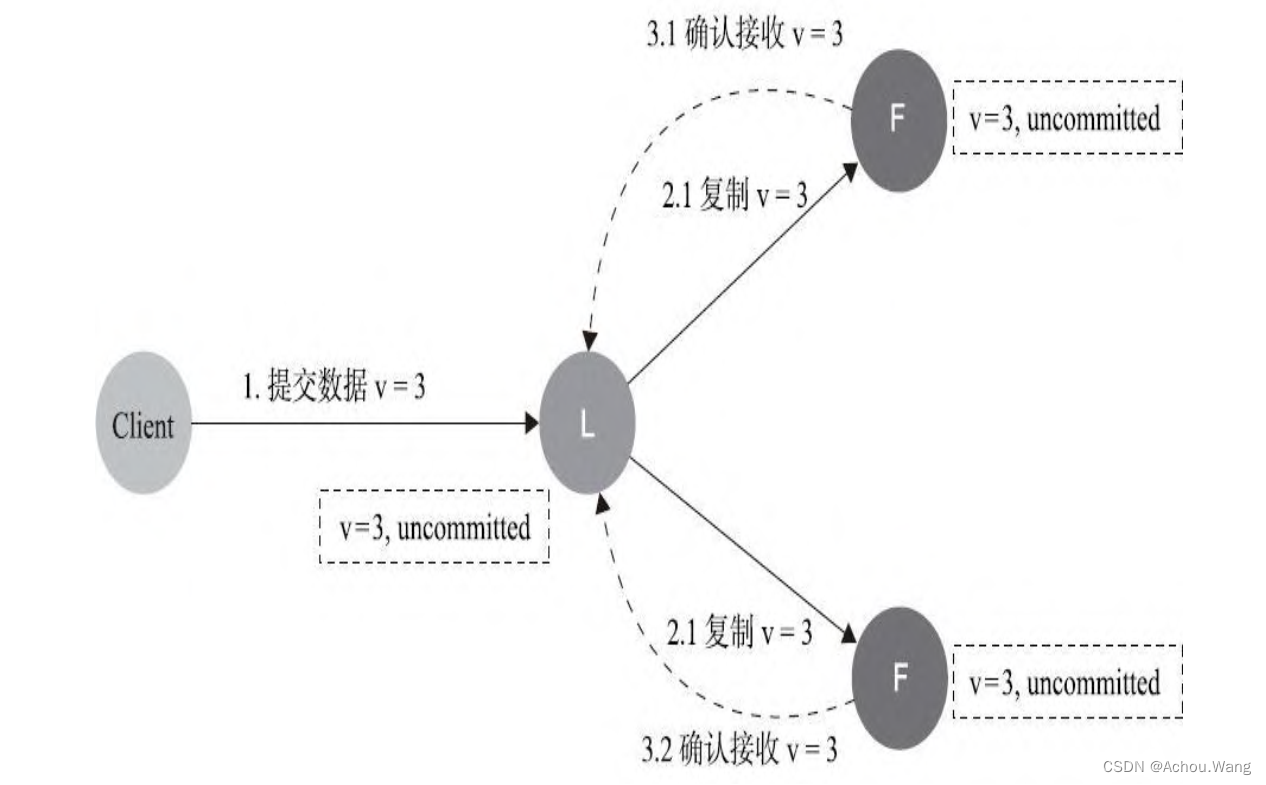
如果在这个阶段出现Leader异常,那么重新选举新的Leader后的处理流程与阶段3一样
6. 数据到达Leader节点,成功复制到Follower的所有或者大多数节点上,数据在所有的节点都处于已提交状态,但是还未响应Client
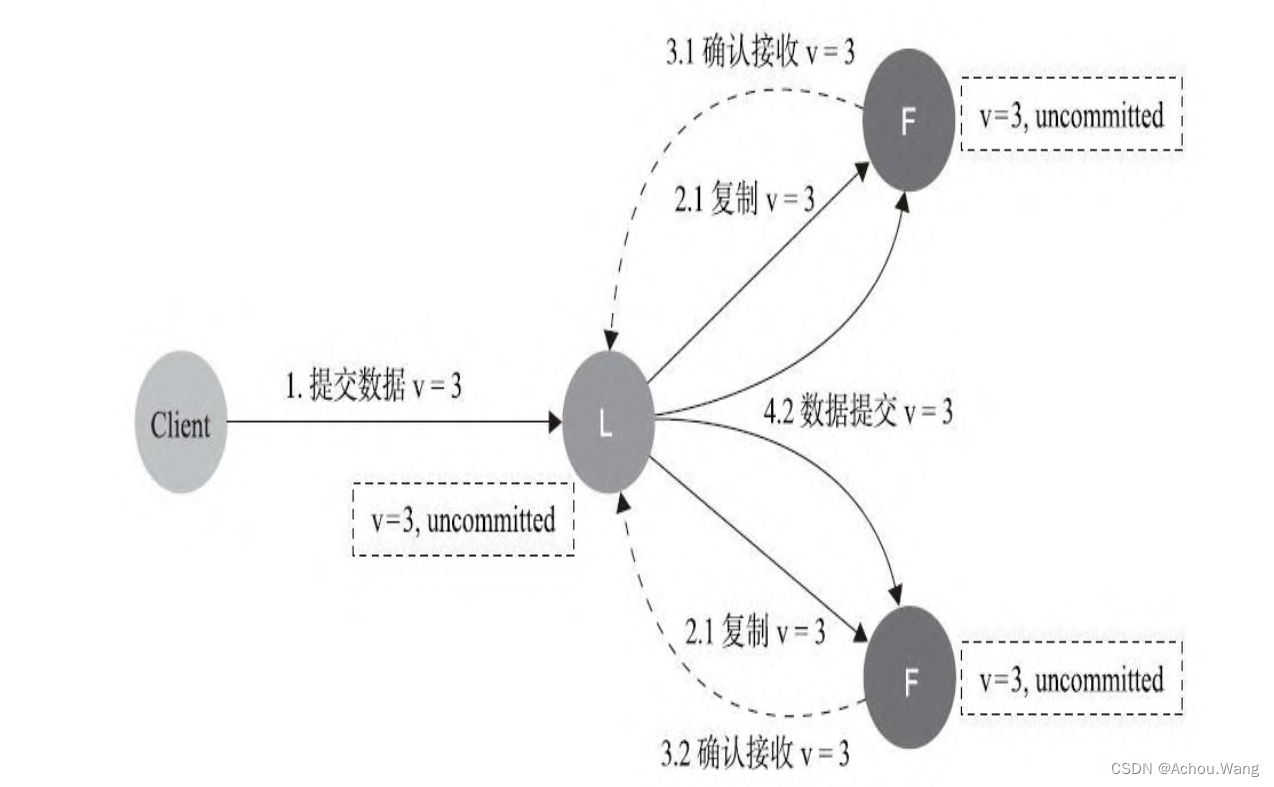
如果在这个节点出现Leader故障,此时集群内部数据其实已经是一致的,那么Client重复重试基于幂等策略对一致性无影响。
幂等策略:一次和多次请求某一个资源 对于资源本身 应该具有同样的副作用(网络超时等问题除外)。也就是说, 其任意多次执行对资源本身所产生的影响均与一次执行的影响相同
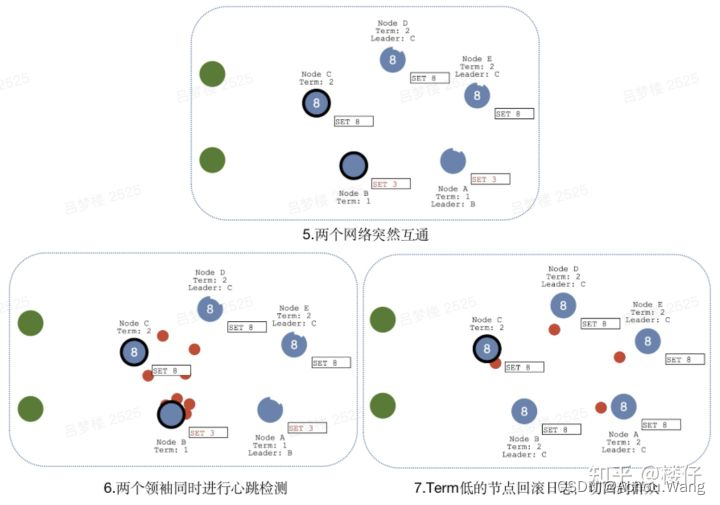
网络分区导致的脑裂情况,出现双Leader
当网络问题导致脑裂,出现双Leader情况时,每个网络可以理解为一个独立的网络,因为原先的Leader独自在一个区,所以向他提交的数据不可能被复制到大多数节点上,所以数据永远都不会提交,这个可以在第4幅图中提现出来(SET 3没有提交)。
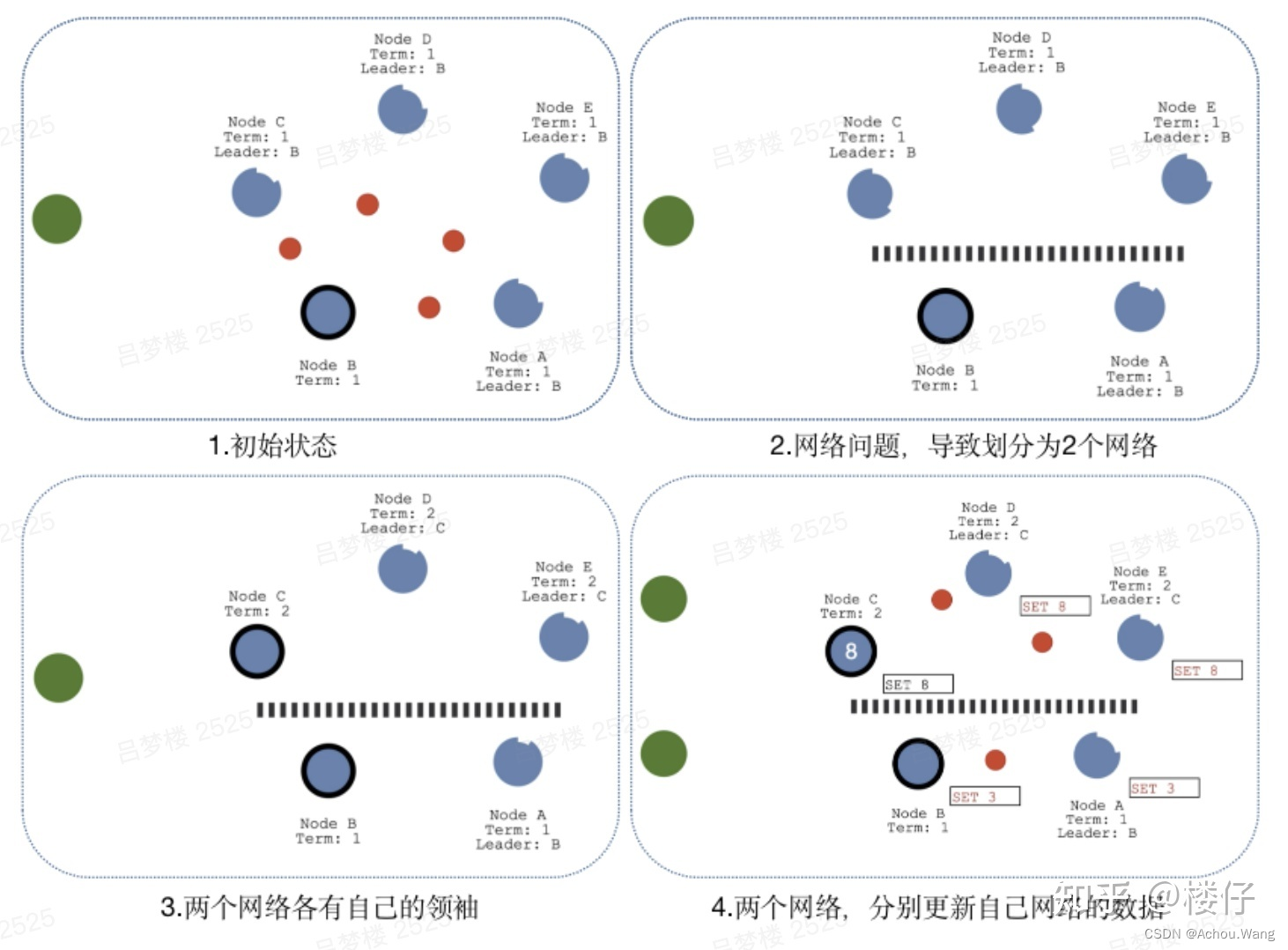
当网络恢复之后,旧的Leader发现集群中的新Leader的Term比自己大,则自动降级为Follower,并从新Leader处同步数据达成集群数据一致
配置参数说明:
--name节点名称
默认:“default”
环境变量: ETCD_NAME
--data-dir数据存储目录
默认:“${name}.etcd”
环境变量:ETCD_DATA_DIR
--advertise-client-urls用于通知其它
ETCD节点,客户端介入本节点的监听地址,一般来说
adverstise-client-urls是
listen-client-urls的子集
--listen-client-urls本节点的访问地址,可以多个使用逗号隔开,如果配置成http://0.0.0.0:2379将不限制node访问地址
--listen-peer-urls本节点与其他节点进行数据交换(选举,数据同步)的监听地址,地址写法是 scheme://IP:port,可以多个并用逗号隔开,如果配置是http://0.0.0.0:2379,将不限制node访问地址
--initial-advertise-peer-urls通知其他节点与本节点进行数据交换(选举,同步)的地址,URL可以使用domain地址。
与–listener-peer-urls不同在于listener-peer-urls用于请求客户端的接入控制,initial-advertise-peer-urls是告知其他集群节点访问哪个URL,一般来说,initial-advertise-peer-urlsl将是listenen-peer-urls的子集
--initial-cluster集群所有节点配置,多个用逗号隔开。
--initial-cluster-token集群唯一标识,相同标识的节点将视为在一个集群内。
--initial-cluster-state节点初始化方式,new 表示如果没有集群不存在,创建新集群,existing表示如果集群不存在,节点将处于加入集群失败状态。
etcd和consul对比表格
| etcd | zookeeper | Consul | NewSQL(Cloud Spanner、CockroachDB、TiDB) | |
|---|---|---|---|---|
| 并发原语 | 锁和选举的远端过程调用,锁命令行提供锁和选举命令,GO语言支持 | 需要引入外部的Apache curator框架,java语言支持 | 原生锁API | 即使有也很少 |
| Linearizable Read | Y | N | Y | 有时候 |
| 多版本并发控制 | Y | N | N | 有时候 |
| 事务 | 数据内容比较、读或写 | 版本检查、写 | 数据内容比较、读或写 | SQL式的事务 |
| 用户权限 | 基于角色的权限控制 | 访问控制列表 | 访问控制列表 | 每个数据库的权限和每个表的单独授权 |
| 数据更新通知 | 历史和当前建范围 | 当前键和目录 | 当前键(支持缀) | |
| HTTP/JSON API | Y | N | Y | 很少 |
| 节点关系重配置 | Y | >3.5.0 | Y | Y |
| 最大数据库大小 | 几GB | 几百MB到几GB | 几百MB以上 | 几TB |
| 最小线性读时延 | 网络RTT | 不支持线性读 | 网络RTT+fsync | 取决于系统和网络时钟 |
Raft单个日志请求执行流程
-
Leader收到Client的请求,写入本地Log,之后并行地向所有Follower通过AppendEntry请求发送该Log Entry;
-
Follower对收到的Entry进行验证,包括验证其之前的一条Log Entry项是不是和Leader相同,验证成功后写入本地Log并返回Leader成功;
-
Leader收到超过半数的Follower答复成功后,将当前Log Commit(如写入状态机),之后返回客户端成功;
-
后续的AppendEntry及HeartBeat都会携带主的Commit位置,Follower会提交该位置之前的所有Log Entry。
Follower在接受AppendEntry时会检查其前一条的Log是否与Leader相同,利用数学归纳法可以很简单的证明Leader和Follower上的Log一致。另外,由于只需要过半数的节点成功即可返回,也就在保证一致性的前提下尽可能的提高了集群的可用性。
当前主节点挂掉之后如何保证新节点的日志能够一致
- Leader Crash后,新的节点成为Leader,为了不让数据丢失,我们希望新Leader包含所有已经Commit的Entry。为了避免数据从Follower到Leader的反向流动带来的复杂性,Raft限制新Leader一定是当前Log最新的节点,即其拥有最多最大term的Log Entry。
- 通常对Log的Commit方式都是Leader统计成功AppendEntry的节点是否过半数。在节点频发Crash的场景下只有旧Leader Commit的Log Entry可能会被后续的Leader用不同的Log Entry覆盖,从而导致数据丢失。造成这种错误的根本原因是Leader在Commit后突然Crash,拥有这条Entry的节点并不一定能在之后的选主中胜出。这种情况在论文中有详细的介绍。Raft很巧妙的限制Leader只能对自己本Term的提案采用统计大多数的方式Commit,而旧Term的提案则利用“Commit的Log之前的所有Log都顺序Commit”的机制来提交,从而解决了这个问题。另一篇博客中针对这个问题有更详细的阐述Why Raft never commits log entries from previous terms directly
日志和存储
日志记录还有落盘是否是事务型事件?
日志数据是在客户端提交之后,就马上落盘到WAL文件中的,不会等到日志在集群中达成一致。
这样会带来一个问题,比如:
节点A认为自己还是集群的leader节点,此时收到客户端日志之后,将数据落盘到WAL文件中。
落盘之后,节点A将日志同步给集群的其它节点,但是发现自己已经不再是集群的leader节点了。
在这种情况下,显然第一步已经落盘的日志是无效的,需要进行修复,这时候是怎么操作的呢?
etcd raft的做法是不回退日志,继续走正常的流程,用新的、正确的日志添加在错误的日志后面,这样回放数据的时候恢复数据。
-
由客户端提交给服务器(注:只有leader节点才能接收客户端提交的日志数据,其他节点需转发给leader)。
-
服务器收到之后,首先调用
raftLog.append函数保存到unstable_log中,此时日志还是在内存中的,并未落地。 -
通过
newReady函数构建Ready结构体时,将上一步保存下来的日志数据保存到Ready结构体的Entries。 -
应用层收到
Ready结构体之后,调用wal的WAL.Save接口保存日志数据。这一步做完之后,可以认为日志数据已经落盘了。 -
由于数据已经落盘到WAL日志中,所以在应用层通过
Node.Advance接口回调通知raft库时,暂存在unstable_log中的日志就可以通过函数raftLog.stableTo删除了。
// store raft entries to wal, then publish over commit channel
case rd := <-rc.node.Ready():
rc.wal.Save(rd.HardState, rd.Entries) // wal 落盘
if !raft.IsEmptySnap(rd.Snapshot) { // 如果没有快照文件就先创建,并发布
rc.saveSnap(rd.Snapshot)
rc.raftStorage.ApplySnapshot(rd.Snapshot)
rc.publishSnapshot(rd.Snapshot)
}
rc.raftStorage.Append(rd.Entries)
rc.transport.Send(rd.Messages)
if ok := rc.publishEntries(rc.entriesToApply(rd.CommittedEntries)); !ok {
rc.stop()
return
}
rc.maybeTriggerSnapshot()
rc.node.Advance()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
总结:
-
日志落盘部分,包括wal文件以及快照文件读写这两部分内容,etcd将这两部分统一到
Storage接口统一对外服务。 -
raft算法是在收到客户端日志之后就立即落盘日志到wal文件中保存的,如果后面发现出错,就走正常的同步正确日志的流程,将正确的日志添加到后面,这样恢复时重放整个日志,最终节点达成一致的正确状态。
https://www.codedump.info/post/20210628-etcd-wal/
关键字段说明
数据索引:通知到应用层最大的日志索引,当前已经提交的日志的最大索引,快照索引,日志索引用来日志记录和提交,快照索引用来每次生成新快照,将老的索引的快照进行删除
监控与反馈、时间处理与执行提供prometheus监控反馈接口
walFsyncSec.Observe(time.Since(start).Seconds())
walFsyncSec = prometheus.NewHistogram(prometheus.HistogramOpts{
Namespace: "etcd",
Subsystem: "disk",
Name: "wal_fsync_duration_seconds",
Help: "The latency distributions of fsync called by WAL.",
// lowest bucket start of upper bound 0.001 sec (1 ms) with factor 2
// highest bucket start of 0.001 sec * 2^13 == 8.192 sec
Buckets: prometheus.ExponentialBuckets(0.001, 2, 14),
})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
节点变更?存储里面没有处理
参考资料:
ETCD说明:
https://zhuanlan.zhihu.com/p/383499555
Raft算法实现:
https://ny5odfilnr.feishu.cn/docs/doccndywf4WUkrVtuufO4qjRt4e#
关注微信公众号 [码上有话] 了解更多详细信息
【一文入门ETCD】https://juejin.cn/post/6844904031186321416
【etcd:从应用场景到实现原理的全方位解读】https://www.infoq.cn/article/etcd-interpretation-application-scenario-implement-principle
【Etcd 架构与实现解析】http://jolestar.com/etcd-architecture/
【linux单节点和集群的etcd】https://www.jianshu.com/p/07ca88b6ff67
【软负载均衡与硬负载均衡、4层与7层负载均衡】https://cloud.tencent.com/developer/article/1446391
【Etcd Lock详解】https://tangxusc.github.io/blog/2019/05/etcd-lock%E8%AF%A6%E8%A7%A3/
【etcd基础与使用】https://zhuyasen.com/post/etcd.html
【ETCD核心机制解析】https://www.cnblogs.com/FG123/p/13632095.html
【etcd watch机制】http://liangjf.top/2019/12/31/110.etcd-watch%E6%9C%BA%E5%88%B6%E5%88%86%E6%9E%90/
【ETCD 源码学习–Watch(server)】https://www.codeleading.com/article/15455457381/
【etcdV3—watcher服务端源码解析】https://blog.csdn.net/stayfoolish_yj/article/details/104497233
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

