
- 1MVCC如何实现提交读和可重复读?_mvcc在提交读
- 2Android中ELF文件结构浅析(一)_安卓elf文件
- 3Docker入门5——Docker镜像、容器数据卷_dockerfile ntfs
- 4用python实现决策树分类-实验报告_c4.5决策树实验报告
- 597年世界编程大赛一等奖作品代码--太牛了,偶像!_编程大赛冠军源代码
- 642个来自《 CSS世界》中的实用技巧
- 7Git常用命令merge_gitmerge命令
- 8BIM+GIS工程管理系统——BIM与GIS的跨界合作_基于bim(+gis)的智能工地业务管理集成系统
- 9鸿蒙Harmony应用开发—ArkTS(@Prop装饰器:父子单向同步)
- 10解决Linux报错JCE cannot authenticate the provider BC
各种文字生成图片的AIGC模型(openAI、谷歌、stable、Midjourney等)_文本生成图像模型
赞
踩
1 前言
AIGC,全名“AI generated content”,又称生成式AI,意为人工智能生成内容。例如AI文本续写,文字转图像的AI图、视频等。
本文主要描述文字生成图片的模型。而且目前扩散模型(Diffusion Models)流行,所以下面列的大部分是基于扩散模型的,而基于GAN(GenerativeAdversarialNetworks,中文叫生成式对抗网络)的较少。
文字生成图片示例如下:

模型汇总如下,时间以论文(arxiv)的时间为主:
| 模型 | 公司或机构 | 时间 | 备注 |
| DALL·E | openAI | 2021年2月 | dVAE |
| GLIDE | openAI | 2022年3月 | 指导扩散(guided diffusion) |
| DALL·E2 | openAI | 2022年4月 | unclip、扩散模型 |
| Imagen | | 2022年5月23日 | 扩散模型 |
| Parti | | 2022年6月 | ViT-VQGAN |
| Stable Diffusion | Stability AI | 2022年4月 | 开源 |
| Midjourney | Midjourney | 2022年3月 | 未公开技术 |
| Make-A-Scene | Meta(facebook) | 2022年3月 | |
| ERNIE-ViLG 2.0 | 百度 | 2023年3月 | 扩散模型 |
| CogView | 清华 | 2021年11月 | VQ-VAE |
| CogView2 | 清华 | 2022年5月 | VQ-VAE |
| Disco Diffusion | Accomplice | 2021年10月 |
2 openAI
2.1 DALL·E:
DALL-E还没有使用扩散模型,使用的dVAE(discrete variational autoencoder离散变分自动编码器)。
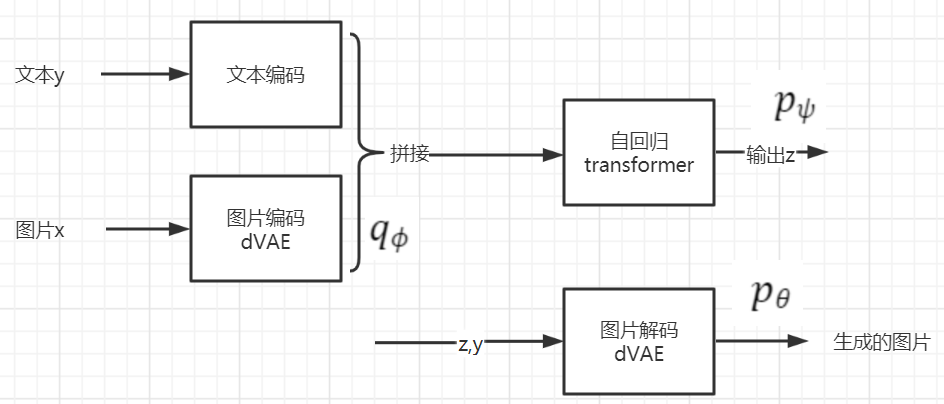
详见:DALL·E:OpenAI第一代文本生成图片模型DALL·E:OpenAI第一代文本生成图片模型_AI强仔的博客-CSDN博客
2.2 GLIDE
DALL-E 的参数量是 120 亿,而 GLIDE 仅有 35 亿参数。GLIDE指 Guided Language to Image Diffusion for Generation and Editing 。
在新模型 GLIDE 中,OpenAI 将指导扩散(guided diffusion)应用于文本生成图像的问题。首先该研究训练了一个 35 亿参数的扩散模型,使用文本编码器以自然语言描述为条件,然后比较了两种指导扩散模型至文本 prompt 的方法:CLIP 指导和无分类器指导。通过人工和自动评估,该研究发现无分类器指导能够产生更高质量的图像。
论文地址:《GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models 》https://arxiv.org/pdf/2112.10741.pdf
2.3 DALL·E 2
DALL·E 2:虚线上面部分是CLIP。虚线之下是我们文本到图像生成过程,一个CLIP text embedding输入到autoregressive或者扩散模型(prior部分)来生成一个image embedding,然后这个embedding输入到扩散模型decoder,生成最终的图像.

详见:DALL·E 2 :OpenAI第二代文本生成图片模型(unCLIP--基于CLIP的文本生成图像模型)DALL·E 2 :OpenAI第二代文本生成图片模型(unCLIP--基于CLIP的文本生成图像模型)_AI强仔的博客-CSDN博客
3 Google
3.1 Imagen
使用了一个文字转图片的diffusion模型,然后使用了2个超分diffusion模型。

3.2 Parti
Parti,全名叫「Pathways Autoregressive Text-to-Image」,是谷歌大脑老大Jeff Dean提出的多任务AI大模型蓝图Pathway的一部分。
Parti是文本-图片的序列到序列模型,包括编码器和解码器。
使用 ViT-VQGAN。
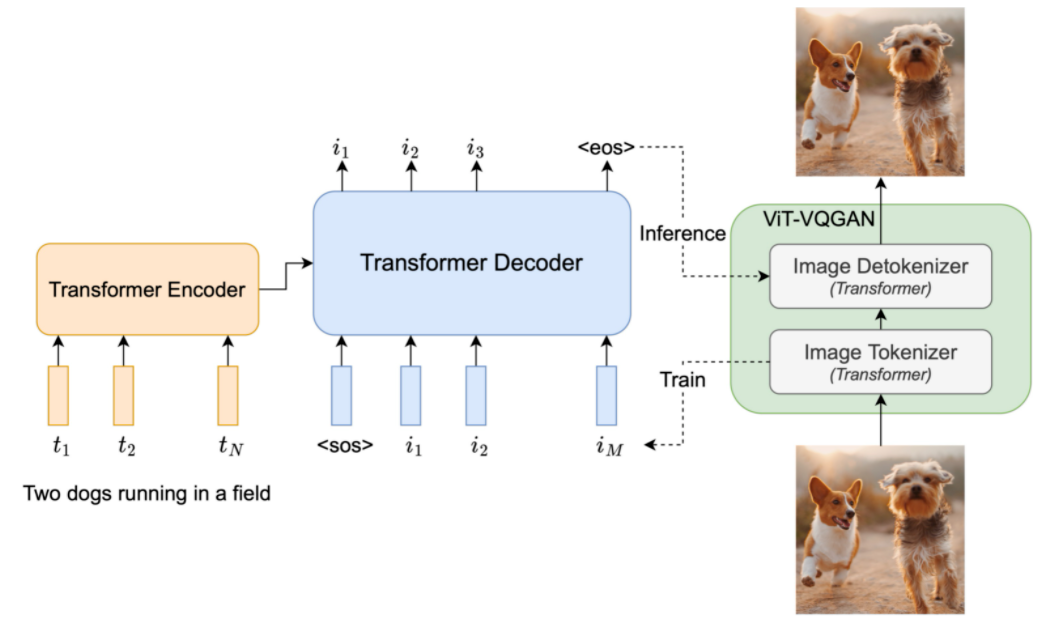
4 Stability AI
独立研究机构Stability AI成立于2020年,背后出资人是数学家,计算机科学家,著名投资人莫斯塔克(Emad Mostaque)。
Stable Diffusion让用户使用消费级的显卡便能够迅速实现文生图。Stable Diffusion 完全免费开源,所有代码均在 GitHub 上公开,任何人都可以拷贝使用。
4.1 Stable Diffusion(LDM)
Stable diffusion是一个基于Latent Diffusion Models(潜在扩散模型,LDMs)的文图生成(text-to-image)模型。出自《High-Resolution Image Synthesis with Latent Diffusion Models 》https://arxiv.org/pdf/2112.10752.pdf。
模型latent diffusion models (LDMs)是两阶段的。第一部分就是下面左半部分(红色),对图片进行压缩,将图片压缩为隐变量表示(latent),这样可以减少计算复杂度;第二部分还是扩散模型(diffusion与denoising),中间绿色部分。此外引入了cross-attention机制,下图右半部分,方便文本或者图片草稿图等对扩散模型进行施加影响,从而生成我们想要的图片,比如根据文本生成我们想要的图片。
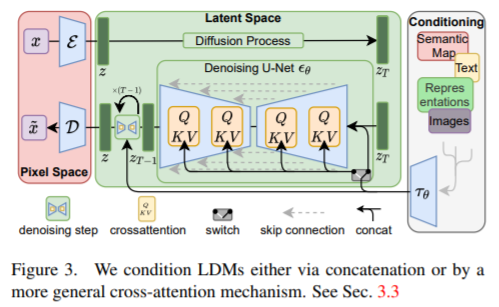
详见stable diffusion(LDM)--图片生成模型_AI强仔的博客-CSDN博客
5 MidJourney
Midjourney是一款2022年3月面世的AI绘画工具,创始人是David Holz。Midjourney 正式团队成员十分精简,共 11 人。除了 CEO 之外,有 8 位研究与工程师,2 位财务与法务。
目前采取 SaaS 订阅制模式,价格为 10 – 60 美元/月。
Midjourney 最有力的竞争对手是 Stability.AI,与 Midjourney 的闭源不同,其模型 Stable Diffusion 因开源模式受到了广泛关注。
6 Meta(facebook)
6.1 Make-A-Scene
可以在用户创作的粗略草图的基础上,结合文本提示生成具象的图像,即使用者可以通过草图控制最终图像的具体效果。

论文:https://arxiv.org/pdf/2203.13131.pdf
7 百度
7.1 ERNIE-ViLG 2.0
百度文心一言文本生成图像模型。ERNIE-ViLG 2.0是一个大规模中文-图像扩散模型。

参见ERNIE-ViLG 2.0:百度文心一言文本生成图像模型:ERNIE-ViLG 2.0:百度文心一言文本生成图像模型_AI强仔的博客-CSDN博客。
8 清华大学
8.1 CogView
CogView: Mastering Text-to-Image Generation via Transformers。清华大学唐杰团队出品。
使用VQ-VAE将图像压缩为token序列特征,可以输入到transformer中进行生成训练。

论文:https://arxiv.org/pdf/2105.13290.pdf
8.2 CogView2
cogview2来提升cogview的效果,这次的效果也对标DALL-E2。相比cogview,cogview2采用分层Transformer以及并行自回归的方式进行生成,并且也训练了国产跨模态的生成模型CogLM.
论文:https://arxiv.org/pdf/2204.14217.pdf

9 Disco Diffusion
Disco Diffusion具有一个强大的开源 CLIP-Guided Diffusion 模型,可以创建详细、逼真的图像。上线于2021年10月29日,由Accomplice开发,Accomplice是一家创立于2016年的公司,致力于帮助每个团队和个人找到适合他们的 AI 驱动的图像工作流程。
- 开源,免费。Disco Diffusion
10 Tiamat
国内首家 AI 生成技术服务商「Tiamat」。
青柑,Tiamat创始人、CEO。00后创业者,毕业于上海科技大学计算机科学与技术专业。于2021年创立生成式AI平台Tiamat,专注AI图像生成领域的应用解决方案。将科技与技术结合的深刻理解付诸实践,致力于通过人工智能生成技术,拓阔人类想象力边界。
11 参考
- Midjourney:AIGC现象级应用,一年实现1000万用户和1亿美元营收 :Midjourney:AIGC现象级应用,一年实现1000万用户和1亿美元营收_产品化_技术_Discord

