
- 1数字锁相环的原理与FPGA实现_fpga实现数字锁相环
- 2Java程序员转到AI大模型开发的路线_java转ai
- 3asp.net c#大型仓库管理系统源码MVC+BootstrapC#源码_c# mvc bootstrap
- 4代码随想录【day 14 二叉树】| 层序遍历 226.翻转二叉树 101.对称二叉树
- 520240328 每日AI必读资讯
- 6大数据人工智能技术全攻略(一)_ai大数据平台学习
- 7《Agents: An Open-source Framework for Autonomous Language Agents》一个自主语言智能体的开源框架
- 8IDEA 热部署_idea预加热
- 9论文AI率多少正常:揭秘学术写作中的AI使用边界
- 10Windows基线安全检测-安全配置检测_win 安全检查
Rasa中文聊天机器人开发指南(2):NLU篇_rasa nlu 明天天气
赞
踩
文章目录
RASA 开发中文指南系列博文:
- Rasa中文聊天机器人开发指南(1):入门篇
- Rasa中文聊天机器人开发指南(2):NLU篇
- Rasa中文聊天机器人开发指南(3):Core篇
- Rasa中文聊天机器人开发指南(4):RasaX篇
- Rasa中文聊天机器人开发指南(5):Action篇
注:本系列博客翻译自Rasa官方文档,并融合了自己的理解和项目实战,同时对文档中涉及到的技术点进行了一定程度的扩展,目的是为了更好的理解Rasa工作机制。与本系列博文配套的项目GitHub地址:ChitChatAssistant,欢迎star和issues,我们共同讨论、学习!
1. 什么是NLU
自然语言理解技术(NLU,natural language understanding)是人机对话产品中的重要一环,是指机器能够理解执行人类所期望的某些语言功能,换句话说就是人与机器交流的桥梁。语言理解通常分为三个层次:词法分析、句法分析、语义分析,其中,词法分析是自然语言理解过程的第一层,它的性能直接影响到后面句法和语义分析的成果,主要包括自动分词、词性标注、中文命名实体标注三方面内容;句法分析的目标是自动推导出句子的句法结构,实现这个目标首先要确定语法体系,不同的语法体系会产生不同的句法结构,常见语法体系有短语结构语法、依存关系语法;语义分析就是指分析话语中所包含的含义,根本目的是理解自然语言。分为词汇级语义分析、句子级语义分析、段落/篇章级语义分析,即分别理解词语、句子、段落的意义。
(1)语义理解含义
语言理解主要包括以下方面内容:
-
能够理解句子的正确次序规则和概念,又能理解不含规则的句子;
-
知道词的确切含义、形式、词类及构词法;
-
了解词的语义分类、词的多义性、词的歧义性;
-
指定和不定特性及所有特性;
-
问题领域的结构知识和实践概念;
-
语言的语气信息和韵律表现;
-
有关语言表达形式的文字知识;
-
论域的背景知识。
(2)自然语言理解一般过程
注:该图来源于自然语言处理(NLP)的一般处理流程,还提供了百度脑图查看点击链接。
2. NLU训练数据
2.1 NLU样本格式
Rasa框架提供了两种NLU模型训练样本数据格式,即Markdown或JSON,我们可以将NLU训练数据保存到单独的文件或者多个文件的目录。由于JSON的可读性不是很好,通常我们使用Markdown来存储训练数据。
## intent:request_phone_business - 查个手机号 - 查电话号码[19800222425](phone_number) - [余额](business) - 查下[腾讯视频流量包](mobile_data_package) - 你好!请帮我查询一下电话[12260618425](phone_number)的[账户余额](business) - 帮我查个手机号[19860612222](phone_number)的[话费](business) - 查下号码[19860222425](phone_number)的[抖音免流包](mobile_data_package) ## synonym:余额 - 余额 - 话费 - 话费余额 - 账户余额 ## regex:phone_number - ((\d{3,4}-)?\d{7,8})|(((\+86)|(86))?(1)\d{10}) ## lookup: mobile_data_package data/lookup_tables/DataPackage.txt

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
nlu.md训练数据包含四部分:
在NLU训练样本文件中,Common examples是唯一必须的,它是NLU模型的核心,也是训练NLU模型的基础。Common examples由三部分组成:intent、text和entities,其中,text表示用户自然语言文本,即用户Message;intent表示某个意图,它应于某些text相对应;entities表示将要被提取的目标实体,我们需要在text文本中标出(如果该text存在实体的话)。Common Examples一般格式如下:
## intent:你的意图名称
- text
- 1
- 2
注:text中可以不包括实体,但如果包含需要用
[entityText](entityName)进行标志。
(2)synonyms
同义词,顾名思义,对于同义词来说,在实体提取时会统一被解析成同一个意思。比如:
## synonym:余额
- 余额
- 话费
- 话费余额
- 账户余额
- 1
- 2
- 3
- 4
- 5
在我们说账户余额、话费等词语时,NLU在提取实体时会能够成功被捕获,并被统一解析成余额。需要注意的是,为了在训练数据中使用同义词,需要pipeline中包含EntitySynonmMapper组件。
(3)Regular Expression Features
正则表达式特征有助于意图分类和实体提取,但是它并不参与实体和意图的定义,仅仅是提供规则来协助意图分类和实体提取,因此,在训练文本text中,该添加的实体和意图样本需要照样添加。比如当需要用户输入的手机号实体时,我们可以再nlu.md文件中添加正则表达式特征支持,当用户输入的Message包含符合手机号正则表达式规则的内容时,Rasa可以更加容易地将其提取出来。Regular Expression Features一般格式如下:
## regex:phone_number
- ((\d{3,4}-)?\d{7,8})|(((\+86)|(86))?(1)\d{10})
- 1
- 2
注意:
phone_number表示的既不是实体名也不是意图名,它只是一个便于我们阅读的标志而已。除了实体识别,我们还可以编写符合意图分类的正则表达式,这里就不演示了。另外,需要注意的是,对于实体提取来说,目前只有CRFEntityExtractor实体提取器支持正则特征,像``MitieEntityExtractor和SpacyEntityExtractor目前还不支持;对于意图分类器,目前均已支持正则特征。最后,为了使用正则特性,我们需要在pipline中添加RegexFeaturizer`组件。
查找表有利于在加载训练数据时,生成与Regular Expression Features相同的正则特征。当在训练数据中提供查找表时,内容被组合成一个大型、不区分大小写的regex模式,该模式在训练示例中查找精确匹配。这些正则表达式匹配多个token,其处理与训练数据中直接指定的正则表达式模式相同。查找表可以包括在训练数据中,如果外部提供的数据必须要以换行进行分隔。比如data/lookup_tables/DataPackage.txt可以包含:
腾讯视频流量包
爱奇艺会员流量包
网易免流包
抖音免流包
流量月包
酷狗定向流量包
- 1
- 2
- 3
- 4
- 5
- 6
对该查找表在nlu.md文件中加载如下:
## lookup: mobile_data_package
data/lookup_tables/DataPackage.txt
- 1
- 2
注意:
mobile_data_package表示实体名。为了查找表能够有效的被使用,训练数据中必须要有一些示例被匹配上。否则,模型不会使用查找表特征向查找表添加数据时必须小心,比如如果表中有误报或其他噪声,就会影响性能,因此请确保查找表包含干净的数据。
2.2 验证数据有效性
检查domian.yml、NLU data和Story data是否有错误。
2.2.1 使用命令
python m rasa data validate
- 1
参数说明:
usage: rasa data validate [-h] [-v] [-vv] [--quiet] [--fail-on-warnings] [-d DOMAIN] [--data DATA] optional arguments: -h, --help show this help message and exit --fail-on-warnings Fail validation on warnings and errors. If omitted only errors will result in a non zero exit code. (default: False) -d DOMAIN, --domain DOMAIN Domain specification (yml file). (default: domain.yml) --data DATA Path to the file or directory containing Rasa data. (default: data) Python Logging Options: -v, --verbose Be verbose. Sets logging level to INFO. (default: None) -vv, --debug Print lots of debugging statements. Sets logging level to DEBUG. (default: None) --quiet Be quiet! Sets logging level to WARNING. (default: None)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2.2.2 使用代码
import logging
from rasa import utils
from rasa.core.validator import Validator
logger = logging.getLogger(__name__)
utils.configure_colored_logging('DEBUG')
validator = Validator.from_files(domain_file='domain.yml',
nlu_data='data/nlu_data.md',
stories='data/stories.md')
validator.verify_all()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2. Rasa NLU Components
2.1 词向量资源(Word Vector Sources)
2.1.1 MitieNLP
| MitieNLP | 说明 |
|---|---|
| Short: | MITIE initializer,即Mitie是MITIE initializer的简称。 |
| Outputs: | 无 |
| Requires: | 无 |
| Description: | 初始化mitie结构。每个mitie组件都依赖于此,因此应该将其放在任何使用mitie组件的每个管道(pipline)的开头 |
| Configuration: | MITIE 需要一个语言模型(.dat),且必须在configs.yml配置中指定。示例如下: |
在configs.yml中应如下配置:
pipeline:
- name: "MitieNLP"
# 语言模型
model: "data/total_word_feature_extractor_zh.dat"
- 1
- 2
- 3
- 4
2.1.2 SpacyNLP
| SpacyNLP | 说明 |
|---|---|
| Short: | spacy language initializer,即spacy语言初始化 |
| Outputs: | 无 |
| Requires: | 无 |
| Description: | 初始化spacy结构。每个spacy组件都依赖于此,因此应该将其放在任何使用mitie组件的每个管道(pipline)的开头 |
| Configuration: | Spacy需要配置语言模型,默认将使用配置的语言。如果要使用的spacy模型的名称不同于language标记(“en”、“de”等),则可以使用配置变量指定模型名称,将名称将传递给模型:space.load(name)。示例如下: |
在configs.yml中应如下配置:
pipeline:
- name: "SpacyNLP"
# 指定语言模型
model: "en_core_web_md"
# 设定在检索单词向量时,这将决定单词的大小写是否相关
# 当为false时,表示不区分大小写。比如`hello` and `Hello`
# 检索到的向量是相同的。
case_sensitive: false
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.2 分词(Tokenizers)
2.2.1 WhitespaceTokenizer
| WhitespaceTokenizer | 说明 |
|---|---|
| Short: | 分词器以空格(whitespaces)作为分词间隔 |
| Outputs: | 无 |
| Requires: | 无 |
| Description: | 为每个以空格分隔的字符序列创建token,得到token可用于MITIE实体提取器。 |
| Configuration: | 如果想把意图分成多个标签,例如,为了预测多个意图或为分层的意图结构建模,使用intent_split_symbol标志。可以通过case_sensitive设置是否大小写敏感,默认true(敏感)。示例如下: |
在configs.yml中应如下配置:
pipeline:
- name: "WhitespaceTokenizer"
# 指定是否大小写敏感,默认true为敏感
case_sensitive: false
- 1
- 2
- 3
- 4
2.2.2 JiebaTokenizer
| JiebaTokenizer | 说明 |
|---|---|
| Short: | 使用Jieba作为 Tokenizer,对中文进行分词 |
| Outputs: | 无 |
| Requires: | 无 |
| Description: | 用于中文的Tokenizer,对于其他语种Jieba会如WhitespaceTokenizer般工作。JiebaTokenizer可为MITIE实体抽取器定义token。 |
| Configuration: | 用户的自定义字典文件可以通过特定的文件目录路径dictionary_path自动加载,但是需要在配置文件中进行配置。示例如下: |
在configs.yml中应如下配置:
pipeline:
- name: "JiebaTokenizer"
# 指定自定义词典
dictionary_path: "path/to/custom/dictionary/dir"
- 1
- 2
- 3
- 4
2.2.3 MitieTokenizer
| MitieTokenizer | 说明 |
|---|---|
| Short: | 使用Mitie进行分词 |
| Outputs: | 无 |
| Requires: | 需要先配置MitieNLP,参照2.1.1 |
| Description: | 用MITIE tokenizer创建tokens,从而服务于 MITIE 实体抽取 |
| Configuration: | 示例如下: |
在configs.yml中应如下配置:
pipeline:
- name: "MitieTokenizer"
- 1
- 2
2.2.4 SpacyTokenizer
| SpacyTokenizer | 说明 |
|---|---|
| Short: | 使用Spacy进行分词 |
| Outputs: | 无 |
| Requires: | 需要先配置SpacyNLP,参照2.1.2 |
| Description: | 用Spacytokenizer创建tokens,从而服务于Spacy 实体抽取 |
| Configuration: | 示例如下: |
在configs.yml中应如下配置:
pipeline:
- name: "SpacyTokenizer"
- 1
- 2
2.2.5 ConveRTTokenizer
| SpacyNLP | 说明 |
|---|---|
| Short: | 使用ConveRt进行分词 |
| Outputs: | 无 |
| Requires: | 无 |
| Description: | 用ConveRT Tokenizer创建tokens,从而服务于ConveRTFeaturizer 实体抽取 |
| Configuration: | 示例如下: |
在configs.yml中应如下配置:
pipeline:
- name: "ConveRTTokenizer"
- 1
- 2
2.3 文本特征化(Text Featurizers)
2.3.1 MitieFeaturizer
| MitieFeaturizer | 说明 |
|---|---|
| Short: | MITIE intent featurizer,即使用MITIE特征化意图信息 |
| Outputs: | 无,作为意图分类器的输入(例如SklearnIntentClassifier) |
| Requires: | 需要先配置MitieNLP,参照2.1.1 |
| Type: | 稠密featurizer |
| Description: | 使用MITIE featurizer为意图分类创建特征。需要注意的是:MitieIntentClassifier组件中并没有使用。目前,只有SklearnIntentClassifier能够使用预先计算的特性。 |
在configs.yml中应如下配置:
pipeline:
- name: "MitieFeaturizer"
- 1
- 2
2.3.2 SpacyFeaturizer
| SpacyFeaturizer | 说明 |
|---|---|
| Short: | spacy intent featurizer,即使用Spacy特征化意图信息 |
| Outputs: | 无,作为意图分类器的输入(例如SklearnIntentClassifier) |
| Requires: | 需要先配置SpacyNLP,参照2.1.2 |
| Type: | 稠密featurizer |
| Description: | 使用spacy featurizer为意图分类创建特征。 |
在configs.yml中应如下配置:
pipeline:
- name: "SpacyFeaturizer"
- 1
- 2
2.3.3 ConveRTFeaturizer
| ConveRTFeaturizer | 说明 |
|---|---|
| Short: | 使用ConveRT模型创建用户消息和响应(如果指定的话)的向量表示 |
| Outputs: | 无,作为意图分类器和response selectors的输入,分别对应意图特征和响应特征。比如EmbeddingIntentClassifier和ResponseSelector |
| Requires: | 需要配置ConveRTTokenizer,参见2.2.5小节 |
| Type: | 稠密featurizer |
| Description: | 为意图分类和响应选择创建特征,使用默认签名来计算输入文本的向量表示。 需要注意:(1)由于ConveRT模型仅在英语语料上训练,因此只有当训练数据是英语语言时才能使用这个featurizer。 (2)使用之前需要安装tensorflow_text和tensorflow_hub),可以通过pip install rasa[convert]来安装。 |
在configs.yml中应如下配置:
pipeline:
- name: "ConveRTFeaturizer"
- 1
- 2
2.3.4 RegexFeaturizer
| RegexFeaturizer | 说明 |
|---|---|
| Short: | 创建正则表达式特征以支持意图和实体分类 |
| Outputs: | text_features 和 tokens.pattern |
| Requires: | 无 |
| Type: | 稀疏 featurizer |
| Description: | 为实体提取和意图分类创建特征。在训练期间,regex intent featurizer 以训练数据的格式创建一系列正则表达式列表。对于每个正则,都将设置一个特征,标记是否在输入中找到该表达式,然后将其输入到intent classifier / entity extractor 中以简化分类(假设分类器在训练阶段已经学习了该特征集合,该特征集合表示一定的意图)。将Regex特征用于实体提取目前仅CRFEntityExtractor组件支持。注意:在 regex featurizer 之前,需要先进行tokenizer操作。 |
在configs.yml中应如下配置:
pipeline:
- name: "RegexFeaturizer"
- 1
- 2
2.3.5 CountVectorsFeaturizer
| CountVectorsFeaturizer | 说明 |
|---|---|
| Short: | 创建用户信息和标签(意图和响应)的词袋表征 |
| Outputs: | 无,用作意图分类器的输入,输入的意图特征以词袋表征(如EmbeddingIntentClassifier) |
| Requires: | 无 |
| Type: | 稀疏 featurizer |
| Description: | 为意图分类和 response selection创建特征。使用sklearn的CountVectorizer创建用户消息和标签特征的词袋表征。所有token仅由数字组成(如123和99,但不会存在a123d)将被分配到相同的功能。 |
在configs.yml中应如下配置:
pipeline:
- name: "CountVectorsFeaturizer"
"use_shared_vocab": False,
analyzer: 'word'
token_pattern: r'(?u)\b\w\w+\b'
strip_accents: None
stop_words: None
min_df: 1
max_df: 1.0
min_ngram: 1
max_ngram: 1
max_features: None
lowercase: true
OOV_token: None
OOV_words: []
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2.4 意图分类(Intent Classifiers)
2.4.1 MitieIntentClassifier
| MitieIntentClassifier | 说明 |
|---|---|
| Short: | MITIE intent classifier(使用text categorizer) |
| Outputs: | intent |
| Requires: | tokenizer 和 featurizer |
| Description: | 该分类器使用MITIE进行意图分类。底层分类器使用的是具有稀疏线性核的多类线性支持向量机(可以查看MITIE trainer code) |
- 在
configs.yml中应如下配置:
pipeline:
- name: "MitieIntentClassifier"
- 1
- 2
- 输出示例:
{
"intent": {"name": "greet", "confidence": 0.98343}
}
- 1
- 2
- 3
2.4.2 SklearnIntentClassifier
| SklearnIntentClassifier | 说明 |
|---|---|
| Short: | sklearn intent classifier |
| Outputs: | intent 和 intent_ranking |
| Requires: | A featurizer |
| Description: | 该sklearn意图分类器训练一个线性支持向量机,该支持向量机通过网格搜索得到优化。除了其他分类器,它还提供没有“获胜”的标签的排名。spacy意图分类器需要在管道中的先加入一个featurizer。该featurizer创建用于分类的特征。 |
- 在
configs.yml中应如下配置:
pipeline:
- name: "SklearnIntentClassifier"
# 指定SVM训练时要尝试的参数
# 通过运行超参数搜索,以找到最佳的参数集
C: [1, 2, 5, 10, 20, 100]
# 指定C-SVM使用的内核
# 它与GridSearchCV中的“C”超参数一起使用
kernels: ["linear"]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 输出示例:
{
"intent": {"name": "greet", "confidence": 0.78343},
"intent_ranking": [
{
"confidence": 0.1485910906220309,
"name": "goodbye"
},
{
"confidence": 0.08161531595656784,
"name": "restaurant_search"
}
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
2.4.3 EmbeddingIntentClassifier
| EmbeddingIntentClassifier | 说明 |
|---|---|
| Short: | Embedding intent classifier |
| Outputs: | intent 和intent_ranking |
| Requires: | A featurizer |
| Description: | 嵌入式意图分类器将用户输入和意图标签嵌入到同一空间中。Supervised embeddings通过最大化它们之间的相似性来训练。该算法基于StarSpace的。但是,在这个实现中,损失函数略有不同,添加了额外的隐藏层和dropout。该算法还提供了未“获胜”标签的相似度排序。在embedding intent classifier之前,需要在管道中加入一个featurizer。该featurizer创建用以embeddings的特征。建议使用CountVectorsFeaturizer,它可选的预处理有SpacyNLP和SpacyTokenizer。 |
- 在
configs.yml中应如下配置:
pipeline:
- name: "EmbeddingIntentClassifier"
# Embedding算法的控制参数非常多
# 具体参照官方文档,这里以指定训练次数为例
epochs: 500
- 1
- 2
- 3
- 4
- 5
- 输出示例:
{
"intent": {"name": "greet", "confidence": 0.8343},
"intent_ranking": [
{
"confidence": 0.385910906220309,
"name": "goodbye"
},
{
"confidence": 0.28161531595656784,
"name": "restaurant_search"
}
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2.4.4 KeywordIntentClassifier
| KeywordIntentClassifier | 说明 |
|---|---|
| Short: | 简单的关键字匹配意图分类器,适于小型、短期的项目 |
| Outputs: | intent |
| Requires: | nothing |
| Description: | 该分类器通过搜索关键字的消息来工作。默认情况下,匹配是大小写敏感的,只精确匹配地搜索用户消息中关键字。意图的关键字是NLU训练数据中意图的例子。这意味着整个示例是关键字,而不是示例中的单个单词。注意:此分类器仅用于小型项目或入门级项目。如果你有很少的NLU训练数据,则可以试试管道选择中一个管道。 |
在configs.yml中应如下配置:
pipeline:
- name: "KeywordIntentClassifier"
case_sensitive: True
- 1
- 2
- 3
- 输出示例:
{
"intent": {"name": "greet", "confidence": 1.0}
}
- 1
- 2
- 3
2.5 选择器(Selectors)
2.5 Response Selector
| Response Selector | 说明 |
|---|---|
| Short: | 一个字典,关键字为direct_response_intent,value属性包含response和ranking |
| Outputs: | intent |
| Requires: | A featurizer |
| Description: | 该分类器通过搜索关键字的消息来工作。默认情况下,匹配是大小写敏感的,只精确匹配地搜索用户消息中关键字。意图的关键字是NLU训练数据中意图的例子。这意味着整个示例是关键字,而不是示例中的单个单词。注意:此分类器仅用于小型项目或入门级项目。如果你有很少的NLU训练数据,则可以试试管道选择中一个管道。 |
- 在
configs.yml中应如下配置:
pipeline:
- name: "KeywordIntentClassifier"
# 算法支持很多参数配置,详情见文档
case_sensitive: True
- 1
- 2
- 3
- 4
- 输出示例:
{ "text": "What is the recommend python version to install?", "entities": [], "intent": {"confidence": 0.6485910906220309, "name": "faq"}, "intent_ranking": [ {"confidence": 0.6485910906220309, "name": "faq"}, {"confidence": 0.1416153159565678, "name": "greet"} ], "response_selector": { "faq": { "response": {"confidence": 0.7356462617, "name": "Supports 3.5, 3.6 and 3.7, +"recommended version is 3.6"}, "ranking": [ {"confidence": 0.7356462617, "name": "Supports 3.5, 3.6 and 3.7, +"recommended version is 3.6"}, {"confidence": 0.2134543431, "name": "You can ask me about how +"to get started"} ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
2.6 实体提取(Entity Extractors)
Here is a summary of the available extractors and what they are used for:
| Component | Requires | Model | Notes |
|---|---|---|---|
CRFEntityExtractor | sklearn-crfsuite | conditional random field | good for training custom entities |
SpacyEntityExtractor | spaCy | averaged perceptron | provides pre-trained entities |
DucklingHTTPExtractor | running duckling | context-free grammar | provides pre-trained entities |
MitieEntityExtractor | MITIE | structured SVM | good for training custom entities |
EntitySynonymMapper | existing entities | N/A | maps known synonyms |
2.6.1 MitieEntityExtractor
| MitieEntityExtractor | 说明 |
|---|---|
| Short: | MITIE entity extraction (using a MITIE NER trainer) |
| Outputs: | entities |
| Requires: | 需要先配置MitieNLP,参照2.1.1 |
| Description: | 用 MITIE entity extraction抽取语句中的实体。底层分类器使用具有稀疏线性核和自定义特征的多类线性支持向量机。该MITIE组件不提供实体置信值。 |
在configs.yml中应如下配置:
pipeline:
- name: "MitieEntityExtractor"
- 1
- 2
- 输出示例
{
"entities": [{"value": "New York City",
"start": 20,
"end": 33,
"confidence": null,
"entity": "city",
"extractor": "MitieEntityExtractor"}]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.6.2 SpacyEntityExtractor
| SpacyEntityExtractor | 说明 |
|---|---|
| Short: | spaCy entity extraction |
| Outputs: | entities |
| Requires: | 需要先配置SpacyNLP,参照2.1.2 |
| Description: | 该组件使用spaCy来预测消息的实体。spacy使用统计BILOU转移模型。到目前为止,该组件只能使用spacy内置的实体提取模型,不能进行再训练。此提取器不提供任何置信评分。配置spacy组件应该提取哪些维度,比如实体类型。可用维度的完整列表可以在spaCy文档中找到。不指定维度选项将提取所有可用维度。 |
在configs.yml中应如下配置:
pipeline:
- name: "SpacyEntityExtractor"
# dimensions to extract
dimensions: ["PERSON", "LOC", "ORG", "PRODUCT"]
- 1
- 2
- 3
- 4
- 输出示例
{
"entities": [{"value": "New York City",
"start": 20,
"end": 33,
"entity": "city",
"confidence": null,
"extractor": "SpacyEntityExtractor"}]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.6.3 EntitySynonymMapper
| EntitySynonymMapper | 说明 |
|---|---|
| Short: | 将同义词映射到同一个值 |
| Outputs: | 修改以前的实体提取组件找到的现有实体 |
| Requires: | 无 |
| Description: | 如果训练数据包含已定义的同义词(通过对实体示例使用value属性)。此组件将确保检测到的实体值映射到相同的值。 |
在configs.yml中应如下配置:
pipeline:
- name: "EntitySynonymMapper"
- 1
- 2
- 训练数据与实体提取示例
[{ "text": "I moved to New York City", "intent": "inform_relocation", "entities": [{"value": "nyc", "start": 11, "end": 24, "entity": "city", }] }, { "text": "I got a new flat in NYC.", "intent": "inform_relocation", "entities": [{"value": "nyc", "start": 20, "end": 23, "entity": "city", }] }]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
在上述例子中,该组件将实体New York City和NYC映射到nyc。即使消息包含NYC,实体提取将返回nyc。当该组件更改现有实体时,它将自己附加到该实体的处理器列表中。
2.6.4 CRFEntityExtractor
| CRFEntityExtractor | 说明 |
|---|---|
| Short: | 条件随机场实体抽取器 |
| Outputs: | entities |
| Requires: | A tokenizer |
| Description: | 此组件使用条件随机场来进行命名实体识别。CRFs可以被认为是一个无向的马尔可夫链,其中时间步长是单词,状态是实体类别。单词的特征(大写,词性标注POS,等等)给出了特定实体类别的概率,就像相邻实体标记之间的转换一样:然后计算并返回最可能的标记结果。如果使用POS功能(pos或pos2),则必须安装spaCy。如果想使用额外的功能,如预训练的词嵌入,稠密的featurizer,则可以使用“text_dense_features”。确保在相应的featurizer中将“return_sequence”设置为True。 |
在configs.yml中应如下配置:
pipeline:
- name: "CRFEntityExtractor"
features: [["low", "title"], ["bias", "suffix3"], ["upper", "pos", "pos2"]]
# 决定是否使用BILOU_flag
BILOU_flag: true
# 在训练前将该参数设定给sklearn_crfcuite.CRF tagger
max_iterations: 50
# 指定L1正则化系数
# 在训练前将该参数设定给sklearn_crfcuite.CRF tagger
L1_c: 0.1
# 指定L2正则化系数
# 在训练前将该参数设定给sklearn_crfcuite.CRF tagger
L2_c: 0.1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 输出示例
{
"entities": [{"value":"New York City",
"start": 20,
"end": 33,
"entity": "city",
"confidence": 0.874,
"extractor": "CRFEntityExtractor"}]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.6.5 DucklingHTTPExtractor
| DucklingHTTPExtractor | 说明 |
|---|---|
| Short: | 借助Duckling可以提取诸如日期、金额、距离等常见实体,且适用于多种语言 |
| Outputs: | entities |
| Requires: | 无 |
| Description: | 为了使用该组件需要启动一个duckling server。最简单的选择是使用docker container:docker run -p 8000:8000 rasa/duckling。另外,也可以直接在机器上安装Duckling再启动服务。Duckling可以识别日期、数字、距离和其他结构化实体和规范。请注意,duckling 试图提取尽可能多的实体类型,但没有提供排名。例如,对于文本I will be there in 10 minutes。如果在duckling组件内同时指定number和time维度,则该组件将提取两个实体:10作为数字和10 minutes作为时间。在这种情况下,应用程序必须决定哪些实体类型是正确的。抽取器将始终返回1.0的置信度,因为这是一个基于规则的系统。 |
在configs.yml中应如下配置:
pipeline:
- name: "DucklingHTTPExtractor"
# duckling server的url
url: "http://localhost:8000"
# 指定提取哪些维度,即实体类型
dimensions: ["time", "number", "amount-of-money", "distance"]
# 配置语言环境
locale: "de_DE"
# 指定时区
timezone: "Europe/Berlin"
# 访问ducking server超时时间
timeout : 3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 输出示例
{
"entities": [{"end": 53,
"entity": "time",
"start": 48,
"value": "2017-04-10T00:00:00.000+02:00",
"confidence": 1.0,
"extractor": "DucklingHTTPExtractor"}]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3. Rasa NLU Pipline
在上一小节中,我们详细地介绍了Rasa NLU框架中提供的各种组件(Component),本节将继续讲解如何使用这些组件将准备好的样本数据(nlu.md)训练得到NLU模型。在Rasa NLU模块中,提供了一种名为Pipline(管道)配置方式,传入的消息(Message)通过管道中一系列组件处理后得到最终的模型。管道(Pipline)由多个组件(Component)构成,每个组件有各自的功能,比如实体提取、意图分类、响应选择、预处理等,这些组件在管道中一个接着一个的执行,每个组件处理输入并创建输出,并且输出可以被该组件之后管道中任何组件使用。当然,有些组件只生成管道中其他组件使用的信息,有些组件生成Output属性,这些Output属性将在处理完成后返回。下图为"pipeline": ["Component A", "Component B", "Last Component"]训练时调用顺序:
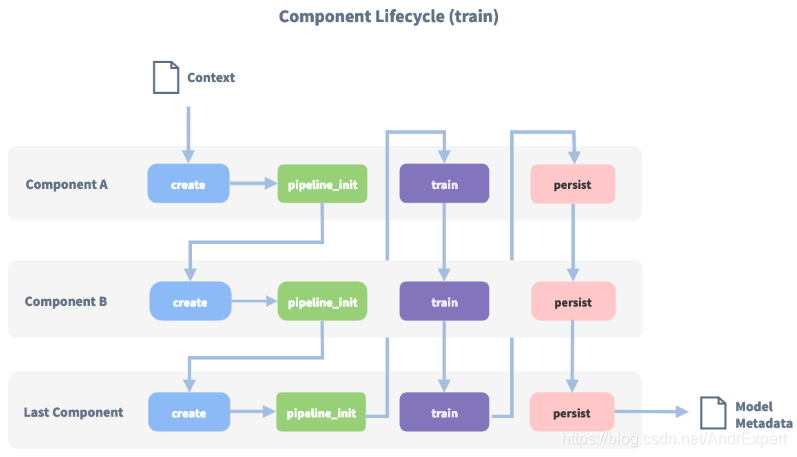
在Rasa NLU模块中,已为我们提供了几种模板(Template) Pipline,比如pretrained_embeddings_spacy、supervised_embeddings等,每一种Pipline组件构成不同,可以根据训练数据的特性选择使用。当然,Pipline的配置非常的灵活,我们可以自定义Pipline中的组件,实现不同特性的Pipline。
3.1 使用Template Pipline
3.1.1 pretrained_embeddings_spacy
在config.yaml文件中配置如下:
language: "en"
pipeline: "pretrained_embeddings_spacy"
- 1
- 2
- 3
当然,上述配置等价于:
language: "en"
pipeline:
- name: "SpacyNLP" # 预训练词向量
- name: "SpacyTokenizer" # 文本分词器
- name: "SpacyFeaturizer" # 文本特征化
- name: "RegexFeaturizer" # 支持正则表达式
- name: "CRFEntityExtractor" # 实体提取器
- name: "EntitySynonymMapper" # 实体同义词映射
- name: "SklearnIntentClassifier" # 意图分类器
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
pretrained_embeddings_spacy管道使用GloVe或 fastText的预训练词向量,因此,它的优势在于当你有一个训练样本如I want to buy apples,Rasa会预测意图为get pears。因为模型已经知道“苹果”和“梨”是非常相似的。如果没有足够大的训练数据,这一点尤其有用。
3.1.2 supervised_embeddings
在config.yaml文件中配置如下:
language: "en"
pipeline: "supervised_embeddings"
- 1
- 2
- 3
当然,上述配置等价于:
language: "en"
pipeline:
- name: "WhitespaceTokenizer" # 分词器
- name: "RegexFeaturizer" # 正则
- name: "CRFEntityExtractor" # 实体提取器
- name: "EntitySynonymMapper" # 同义词映射
- name: "CountVectorsFeaturizer" # featurizes文本基于词
- name: "CountVectorsFeaturizer" # featurizes文本基于n-grams character,保留词边界
analyzer: "char_wb"
min_ngram: 1
max_ngram: 4
- name: "EmbeddingIntentClassifier" # 意图分类器
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
supervised_embeddings 管道不使用任何的预训练词向量或句向量,而是针对自己的数据集特别做的训练。它的优势是面向自己特定数据集的词向量(your word vectors will be customised for your domain),比如,在通用英语中,单词“balance” (平衡)与单词 “symmetry”(对称)意思非常相近,而与单词"cash"意思截然不同。但是,在银行领域(domain),“balance”与"cash"意思相近,而supervised_embeddings训练得到的模型就能够捕捉到这一点。该pipline不需要任何指定的语言模型,因此适用于任何语言,当然,需要指定对应的分词器。比如默认使用WhitespaceTokenizer,对于中文可以使用Jieba分词器等等,也就是该Pipline的组件是可以自定义的。
3.1.3 pretrained_embeddings_convert
在config.yaml文件中配置如下:
language: "en"
pipeline: "pretrained_embeddings_convert"
- 1
- 2
- 3
当然,上述配置等价于:
language: "en"
pipeline:
- name: "ConveRTTokenizer"
- name: "ConveRTFeaturizer"
- name: "EmbeddingIntentClassifier"
- 1
- 2
- 3
- 4
- 5
- 6
pretrained_embeddings_convert使用预训练的句子编码模型ConveRT以抽取用户输入句子的整体向量表征。该pipeline使用ConveRT模型抽取句子表征,并将句子表征输入到EmbeddingIntentClassifier以进行意图分类。使用pretrained_embeddings_convert的好处是不独立地处理用户输入句子中的每个词,而是为完整的句子创建上下文向量表征。比如,句子can I book a car?Rasa 会预测意图为I need a ride from my place。由于这两个示例的上下文向量表征已经非常相似,因此对它们进行分类的意图很可能是相同的。如果没有足够大的训练数据,这也很有用。需要注意的是,由于ConveRT模型仅在英语语料上进行训练,因此只有在训练数据是英语时才能够使用该pipeline。
3.1.4 MITIE
在config.yaml文件中配置如下:
language: "en" # 1. 使用SklearnIntentClassifier意图分类器 # 这里的模型为英文 pipeline: - name: "MitieNLP" # 预训练词向量 model: "data/total_word_feature_extractor.dat" - name: "MitieTokenizer" # 分词器 - name: "MitieEntityExtractor" # 实体提取器 - name: "EntitySynonymMapper" # 同义词映射 - name: "RegexFeaturizer" # 正则 - name: "MitieFeaturizer" # 特征化 - name: "SklearnIntentClassifier" # 意图分类器 # 2. 使用MitieIntentClassifier意图分类器 # 数据量大的时候,训练非常慢(不推荐) # pipeline: # - name: "MitieNLP" # model: "data/total_word_feature_extractor.dat" # - name: "MitieTokenizer" # - name: "MitieEntityExtractor" # - name: "EntitySynonymMapper" # - name: "RegexFeaturizer" # - name: "MitieIntentClassifier"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
Rasa NLU模块支持在Pipline中使用Mitie,但是在使用前需要训练词向量,然后使用MitieNLP组件指定。MITIE后端对于小型数据集执行得很好,但是如果数据量超过几百个示例,则训练可能需要很长时间。Rasa官网不建议使用它,因为mitie支持在将来的版本中可能会被弃用。
3.2 使用Custome Pipline
3.2.1 zh_jieba_mitie_sklearn
language: "zh"
pipeline:
- name: "MitieNLP" # 使用中文词向量模型
model: "data/total_word_feature_extractor_zh.dat"
- name: "JiebaTokenizer" # 使用jieba分词
- name: "MitieEntityExtractor"
- name: "EntitySynonymMapper"
- name: "RegexFeaturizer"
- name: "MitieFeaturizer"
- name: "SklearnIntentClassifier"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
NLU识别结果示例:
Received user message '"广州明天的天气怎么样"' with
intent
'{'name': 'request_weather', 'confidence': 0.5182071733645418}'
and entities
'[{'entity': 'address', 'value': '广州', 'start': 1, 'end': 3,
'confidence': None, 'extractor': 'MitieEntityExtractor'},
{'entity': 'date-time', 'value': '明天', 'start': 3, 'end': 5, 'confidence':
None,'extractor': 'MitieEntityExtractor'}]'
confidence': None, 'extractor': 'MitieEntityExtractor'}
]'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
由于Rasa NLU模块提供的模板Pipline主要适用于英文,假如我们需要训练中文NLU模型的话,就需要使用中文分词器,比如jieba分词器,因此,我们修改MITIE Pipline将分词器改为Jieba,并修改MitieNLP预训练词向量模型为中文模型,其他不变,如MitieEntityExtractor,SklearnIntentClassifier等。根据NLU识别结果可知,输入文本经过处理后输出的intent和entities,从而可知,intent意图识别和entities实体识别是相互独立的。
3.2.2 zh_crf_supervised_embeddings
language: "zh"
pipeline:
- name: "JiebaTokenizer" # 使用jieba分词
- name: "RegexFeaturizer"
- name: "CRFEntityExtractor"
- name: "EntitySynonymMapper"
- name: "CountVectorsFeaturizer"
- name: "CountVectorsFeaturizer"
analyzer: "char_wb"
min_ngram: 1
max_ngram: 4
- name: "EmbeddingIntentClassifier"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
NLU识别结果示例1:
Received user message '"广州明天的天气怎么样"' with
intent
'{'name': 'request_weather', 'confidence': 0.9965207576751709}'
and entities
'[{'start': 1, 'end': 3, 'value': '广州', 'entity': 'address',
'confidence': 0.4974091477686857, 'extractor': 'CRFEntityExtractor'},
{'start': 3, 'end': 5, 'value': '明天', 'entity': 'date-time',
'confidence': 0.8807040793780636, 'extractor': 'CRFEntityExtractor'}]'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
NLU识别结果示例2:
Received user message '"查下138383834381的账户余额"' with
intent
'{'name': 'request_phone_business', 'confidence': 0.9994893074035645}'
and entities
'[{'start': 3, 'end': 15, 'value': '138383834381', 'entity': 'phone_number',
'confidence': 0.5848492378103071, 'extractor': 'CRFEntityExtractor'},
{'start': 16, 'end': 20, 'value': '余额', 'entity': 'business',
'confidence': 0.9023286498337025, 'extractor': 'CRFEntityExtractor',
'processors': ['EntitySynonymMapper']}]'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
该Pipline修改自模板管道supervised_embeddings,由于该模板默认支持英文,为了实现支持中文,我们将分词器由WhitespaceTokenizer改为JiebaTokenizer,其他配置不变。经过测试可知,在意图分类方面,CountVectorsFeaturizer、EmbeddingIntentClassifier组合意图提取置信度高于MitieFeaturizer、SklearnIntentClassifier组合;在实体提取方面。CRFEntityExtractor也优于MitieEntityExtractor。另外,supervised_embeddings不需要任何指定的语言模型,因此适用于任何语言,并且完全依赖于训练数据,因此训练得到的模型拥有更好的适应性,训练的时间也非常快。但是,目前我遇到的有一点就是,有可能在训练数据不足时,在实体提取时可能会出现无法提取到实体的问题,当然,这只是我的推测,有待进一步验证。
当然,除了对已有的模板Pipline进行重新组合,我们完全可以自定义Pipline中的组件,定制你想要的功能和改进每个环节,这或许就是Rasa的优秀之处,非常灵活。比如,我们只希望支持实体识别,不做意图分类,那么我们可以这样自定义一个Pipline:
pipeline:
- name: "SpacyNLP"
- name: "CRFEntityExtractor"
- name: "EntitySynonymMapper"
- 1
- 2
- 3
- 4
4. 改进ChitChatAssistant项目
4.1 改进nlu.md
... ## intent:request_phone_business - 查电话[19820618425](phone_number) - 我想知道电话号码为[19860612425](phone_number) - 查[11160222425](phone_number) - 查电话号码[19800222425](phone_number) - [机主](business) - 号码是[谁的](business) - 这个号码是[属于谁](business) - 谁是这个号码的[拥有者](business) - 查下[机主信息](business) - [机主](business)是谁 - 我要查这个号码的[账户余额](business) - 帮我查[余额](business) - 查[话费](business) - 能告诉我现在的[话费余额](business)还剩多少 - 我想查电话号码[19860618422](phone_number)的[账户余额](business) - 我要查下[19822618425](phone_number)的[机主](business)是谁 - 你好!请帮我查询一下电话[12260618425](phone_number)的[账户余额](business) - 查一下手机号码[19862228425](phone_number)的[机主信息](business) - 帮我查个手机号[19860612222](phone_number)的[余额](business) - [19860222425](phone_number)是[谁的](business) - ## synonym:机主 - 机主信息 - 机主 - 拥有者 - 谁的 - 属于谁 ## synonym:余额 - 余额 - 话费 - 话费余额 - 账户余额 ## regex:phone_number - ((\d{3,4}-)?\d{7,8})|(((\+86)|(86))?(1)\d{10})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
相比于ChitChatAssistant V1.0.0.2020.02.15版本,我们在样本文件nlu.md中,演示了如何使用同义词synonym、正则表达式regex和查找表look-up table来改进我们的NLU训练样本数据,即使得构建NLU样本数据更加灵活,同时提高了实体提取和意图分类的命中率。
4.2 改进config.yml
language: "zh" # zh_jieba_supervised_embeddings pipeline: - name: "JiebaTokenizer" dictionary_path: "data/dict" - name: "RegexFeaturizer" # 支持正则 - name: "CRFEntityExtractor" - name: "EntitySynonymMapper" # 支持同义词识别 - name: "CountVectorsFeaturizer" - name: "CountVectorsFeaturizer" analyzer: "char_wb" min_ngram: 1 max_ngram: 4 - name: "EmbeddingIntentClassifier" policies: ...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
ChitChatAssistant v1.0使用的是Mitie pipline,经过上面的学习可以知道,Mitie将在未来会被Rasa弃用。因此,这里我们使用pipline模板supervised_embeddings,但该pipline默认分词器WhitespaceTokenizer,只适合于英文,这里我们将分词器改为jieba分词器,并添加自定义用户词典,通过dictionary_path指定。自定义用户词典的作用就是,分词器会把原来可能不是一个常规词的词,分成一个词。userdict.txt如下:
谁的 5 n
属于谁 5 n
- 1
- 2
4.3 效果演示
当Rasa Server、Action Server和Server.py运行后,在浏览器输入:
http://127.0.0.1:8088/ai?content="13870468866的话费余额还有多少"
- 1
或者在APP端调用接口,效果如下:
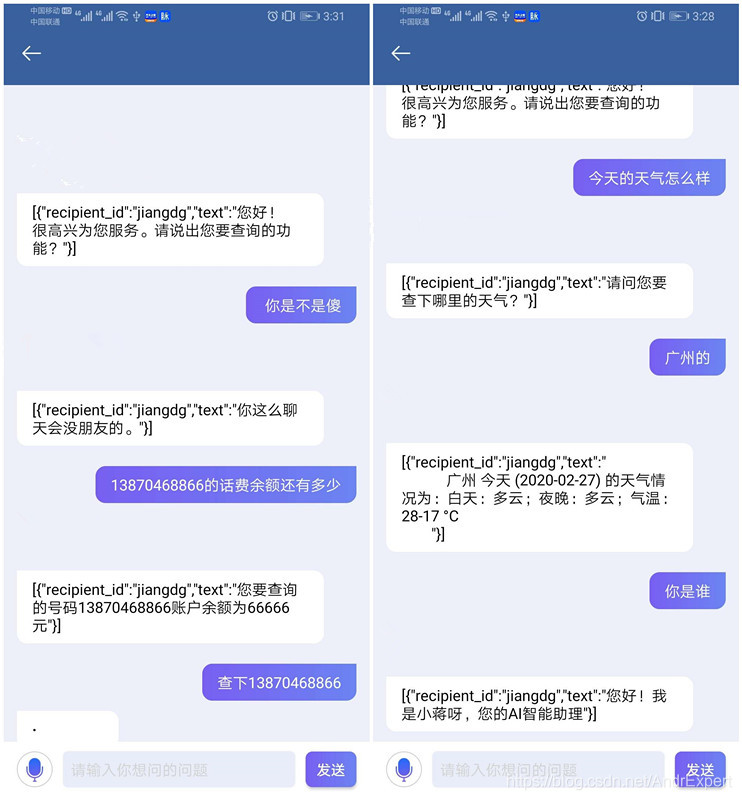
GitHub地址:ChitChatAssistant,欢迎star和issues,我们共同讨论、学习!

