
- 1基于OpenCV的图像颜色与形状识别的原理_opencv 图像识别原理
- 2开源中文大语言模型汇总_中文大模型
- 3TF-IDF_ti-idf
- 4聊天机器人的革命性进步:ChatGPT-4 的新功能一览_chatgpt4新功能
- 5异地远程访问本地SQL Server数据库【无公网IP内网穿透】_sql 本地连接
- 6import spacy报错
- 7【深度学习】【机器学习】用神经网络进行入侵检测,NSL-KDD数据集,基于机器学习(深度学习)判断网络入侵_nsl-kdd 数据集
- 82.3 调用智谱 API_智谱清言api
- 9蓝桥杯14届(2023)省赛 C/C++ B组 C:冶炼金属_蓝桥杯冶炼金属c语言
- 10springboot集成mockito与powermock_springboot powermockito
又火一个惊艳的AI项目,开源了!_instantid python1.12
赞
踩
大家好,我是 Jack。
今天又是分享开源项目的一天。
一、开源项目
1、InstantID
Stable Diffusion 大家都很熟悉了,想要固定生成一个人的图片,需要训练 LoRA 模型。
而训练模型,需要做小样本的微调,需要一定的训练成本。
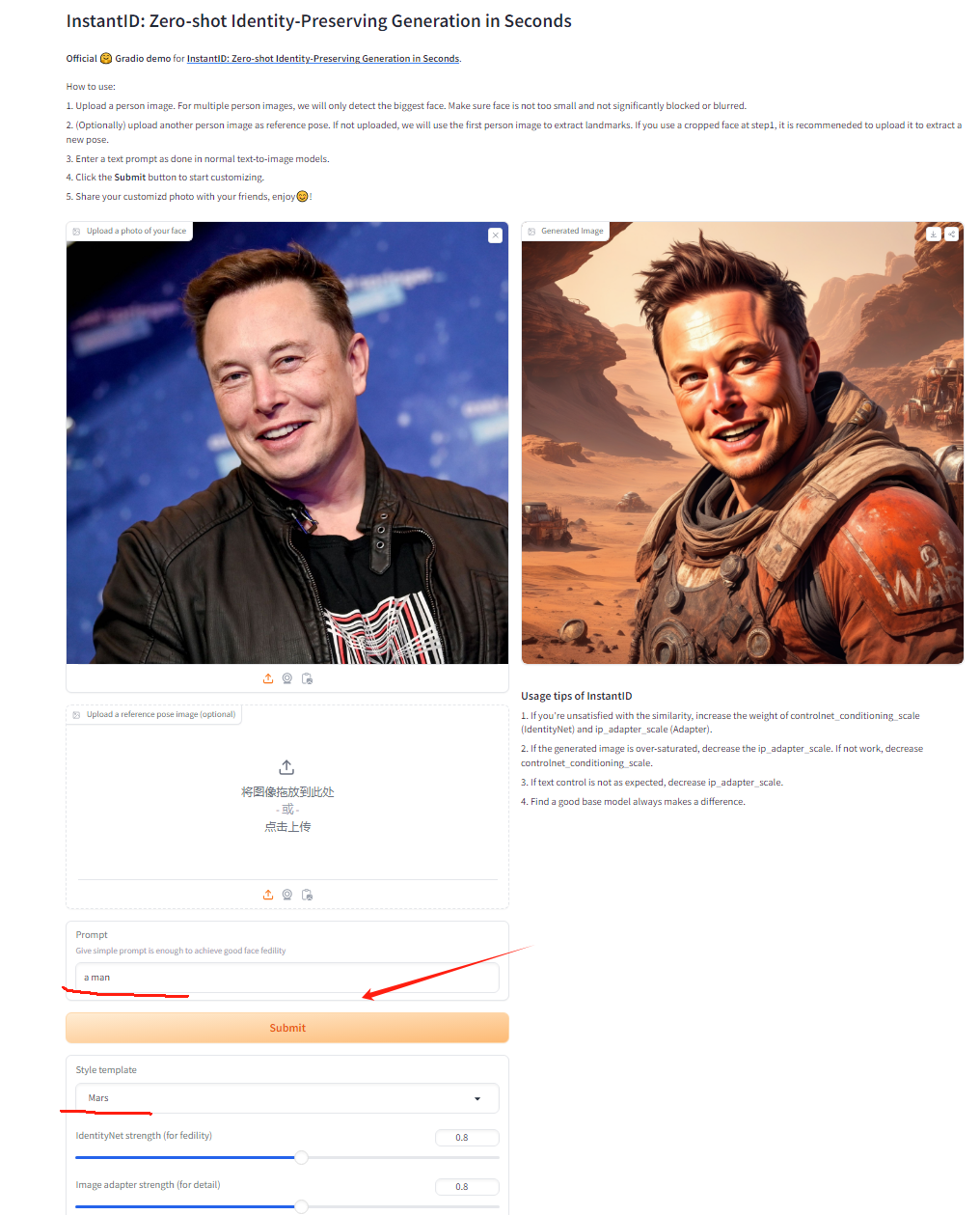
而 InstantID 只需要一张图片,无需训练,Zero-shot 生成个人写真。
这是一张项目组同学的照片:

风格一键迁移:

多种风格,切换自如:


不需要训练各个风格的 LoRA,InstantID 只需要一张照片,再加上一个 prompt 描述,就能生成各种个人写真。
更多例子,直接看这张大图吧:

同时还跟 LoRA 的效果进行了对比:

同时,也可以用来 AI 换脸,用这张图片当作底板:

换上寡姐的照片:

就得到了这张图:

项目可以在 hugginface 在线体验:
上传一张照片,选择风格,输入 prompt。这效果很有喜感。
想要私有化部署也可以,项目的代码和模型都已经开源,项目地址:
2、Depth-Anything
记得我刚学深度估计算法的时候,深度估计的状态还是各个垂类都有一个算法,有室内的深度估计,有街道场景的深度估计。
每个模型还都不能通用,室内场景的模型拿到室外场景用,效果直接不忍直视。
为什么要分开?因为泛化性差,只能是针对单一场景优化。
深度估计的泛化性一直是一个研究方向,最近发布的 Depth-Anything 就有效地解决了这个问题。
一个模型通吃室内:

室外:

深度估计算法应用非常官方,自动驾驶、VR/AR 眼镜等。
为了降低成本,各个厂家一般是不会用价格昂贵的高精度深度摄像头的,而是选择价格便宜的普通摄像头 + 单目深度估计方案。
这个项目也可以直接在 hugginface 上在线体验:
对应的开源项目:
二、最后
最近这段时间,连肝了三期视频。
有 Bert-VITS2、GPT-SoVITS 教学视频:
视频地址:
https://www.bilibili.com/video/BV1dV411D7Pp
现在越来越多的人想玩 AI 算法,但是不知道用什么显卡,所以又出了一期显卡测评视频。展示了 Stable Diffusion + AnimateDiff + prompt travel 生成视频的能力:

视频地址:
https://www.bilibili.com/video/BV1LW4y1c7TP
上面两个算法的一键启动包我也都发出来了,读者朋友里应该有一些人已经体验过了。
最后呢,又出了一期一键搭建幻兽帕鲁云服务搭建的教学视频。
展示用的是阿里云的服务器,我也算是阿里云的老用户了,我那小网站就是用得阿里云服务:
17 年到现在,不知不觉用了 7 年。
阿里云对新用户超级无敌大方,如果你也有跟好友联机玩帕鲁,当“资本家”的需求,可以看看阿里云的一键部署幻兽帕鲁游戏的服务,操作简单,价格非常香。当然仅对阿里云新用户,活动地址:
https://click.aliyun.com/m/1000389005/
我的对应视频教程:
https://www.bilibili.com/video/BV1Fe411J76f
好了,今天就聊这么多吧。
我是 Jack,我们下期见!

